基于扩散模型的图像去噪方法研究
2023-10-24薛永航
薛永航,白 帆,李 娜
(沈阳理工大学,辽宁 沈阳 110168)
0 引言
在实际工程中,图像采集和传输过程中会受到外界因素干扰,尤其噪声的影响,从而导致图像特征提取不准确。因此,如何能够有效去除图像中的噪声,在图像处理领域具有重要意义。传统去噪方法容易造成信息丢失、计算复杂度高和参数选择困难等问题。随着深度学习的发展[1],从卷积神经网络、循环神经网络、到变分神经网络。这些方法从图像特征角度处理噪声,难以学习时频图像噪声分布,由此导致时频图噪声去除时边缘信息丢失多,效果较差[2]。为了提高神经网络在时频图像的噪声去除效果,通过Wigner-Ville(Wigner-Ville Distibution,WVD)分布算法[3],提供了时频图像在时域和频域上的局部信息,使得在时间和频率上同时具有较高的分辨率[4]。让网络学习到噪声图像和无噪声图像的特征,极大降低了该算法在通用数据集上的敏感程度,有效提升了模型泛化能力。
本文通过基于LoRA 的扩散模型神经网络结构[5],将其应用于时频图像去噪,解决了在复杂工况下时频图像噪声难以去除的问题,通过学习含噪信号及无噪信号图像概率分布,达到去除噪声的目的。实验结果表明,相对于传统深度学习去噪模型,该模型能够有效去除时频图像的噪声。
1 算法原理
1.1 基于LoRA 的去噪扩散模型
该算法将扩散模型以及LoRA 网络结构相结合,用于时频信号图像的去噪,整个网络分为两大部分,训练阶段和采样阶段。
(1)训练阶段
首先,使用已预训练的自编码器将时频图像从像素空间映射到潜在空间,以学习时频图像的隐式表达,同时压缩图像尺寸,减少计算该网络计算复杂度和模型的参数量。然后,由文本编码器对含有噪声的时频图像的提示文本进行编码,生成大小为[B,K,E] 的嵌入文本词。其中,B 表示批次大小,K 表示文本的最大编码长度,E 表示嵌入的维度,嵌入文本能够有效捕捉时频图像语义特征。基于LoRA 的扩散模型输出噪声∊θ,通过计算时频图像与真实噪声之间的误差作为损失函数。通过反向传播算法,更新模型中的参数。
(2)采样阶段
采样阶段包括对时频图像文本编码和时频图像解码过程。在文本编码过程中,文本编码器由输入的描述文本标签,对时频图像的描述文本进行编码,包括时频噪声生成与恢复潜在表示,随机产生大小为[B,Z,H/8,W/8] 的噪声,利用训练好的模型,对网络中参数进行迭代,逐步去除时频图像中的噪声,恢复时频图像的潜在表示。
1.2 LoRA 结构应用
LoRA 预训练模型(Pretrianed Weight)可以用于时频图像去噪任务的模块中,通过调整替换矩阵A和B,可以达到冻结共享模型的作用,能够有效的切换不同训练任务,即训练时频图像和图像描述文本,从而显著的降低数据参数存储需求,使得LoRA 的训练更加有效。
通过训练时频图像的提示文本,可以替代整个扩散模型的参数训练,在原有对图像特征提取的基础上,可以使该算法识别到噪声图像的准确率有效提升。

图1 LoRA 结构
1.3 扩散过程
扩散过程中将随机噪声添加到数据中,从噪声中构造所需的数据样本。与VAE 模型不同,扩散模型是通过固定过程学习,并且潜在变量具有与原始数据相同方法。
(1)前向过程
逐步添加高斯噪声到图像中,得到一个含有噪声的时频图像。其中,Xt时刻的分布等于Xt-1时刻的分布加上高斯分布的噪声。
式中:Xt表示t时刻图像,其中t∊[1,T],αt是噪声的衰减值,Z表示高斯噪声。
重复迭代后,可由初始状态X0得任意t时刻分布:
(2)逆向过程
在此过程中,逐步从噪声中复原出原始时频图。由贝叶斯公式可知:
q(Xt-1|Xt)为给定Xt时Xt-1的概率分布,由于q(Xt-1)分布无法直接求取,因此用条件概率分布q(Xt-1|Xt,X0)近似求解,如(4)式所示。
在已知X0的情况下,可以求出Xt-1时刻的分布。
重复迭代后,最终可预测出X0时刻的分布。
式中:βt= 1 -αt,∊θ(Xt,t)表示t时刻模型预测的噪声,σt表示预测的噪声方差。
2 实验结果与分析
2.1 实验流程
为了验证该算法去噪性能,本次研究采用一组工况数据集,该数据是两相电流信号,维度是2×10000,首先,对该数据维度进行处理,然后,将二维信号处理成一维信号,截取部分信号数据,通过WVD 算法,将该数据转成时频图,以便于更好捕捉信号在不同频率上的瞬时特性。并且,对原始数据添加均值为0.2 和标准差为0.35 的高斯噪声,以验证算法的可靠性。整个训练过程,选择Adam(Adaptive Moment Estimation)参数优化器,学习率设置为0.001,训练150 个周期。
2.2 评价指标
(1)峰值信噪比计算(Peak signal-to-noise ratio,PSNR):
峰值信噪比通过均方差(MSE)进行定义,方差定义为:
由方差可知,峰值信噪计算公式如下:
(2)结构相似度计算(Structural Similarity,SSIM):
通过从图像的亮度、对比度、结构三个方面度量图像相似性,计算如下:
其中,μX,μY分别表示图像X和Y的均值,σX,σY分别表示图像X和Y的方差,σX σY表示图像X和Y的协方差,C1、C2、C3表示一个常数。SSIM 的取值范围在[0,1]之间,它的值越大,表示图像的失真越小。
2.3 实验结果
通过WVD 算法处理后的时频图像,数据信息被压缩,时频图像特征信息区分不明显,在VAE 算法中,首先对原始时频图图像进行编码,输入的时频图像X 通过编码器输出两个M 维向量,这两个向量是潜在空间Z 的两个参数。其次,在潜在空间Z 中增加约束条件,这个约束条件迫使潜在空间Z 产生服从单位正态分布的潜在变量。最后,Z 通过解码器生成一个样本,由于是随机采样,从而导致潜在空间Z 的不确定性,变分后验难以选择。因此,当时频图像中噪声分布不均匀时,实际输出时频图像数据和输入图像数据出现较大偏差,导致VAE 难以学习原时频图像分布,无法近似真实后验,网络模型去噪效果差,且容易引入新的噪声。由图2 可知,a 图噪声去除但时频信息损失较多,b 图噪声仍分布于中间区域,未去除完全。图像的峰值信噪难以达到20,其结构相似度低于0.9。
相较于VAE 算法,采用基于LoRA 的扩散模型去噪方法,先对随机噪声样本进行采样,通过逐步采样噪声样本,将采样后的噪声样本进行嵌入,包括时间嵌入以及文本嵌入,时间嵌入即上文提到的扩散过程,通过前向过程和逆向过程,对时频图像进行加噪和去噪,从而能够有效还原时频图像的峰值信息,其次,文本嵌入引入LoRA 语言模型,极大增强了网络对时频图像噪声的理解,弥补了网络在时频图像的低峰值区域的不敏感程度,使得该网络能够有效理解时频图像输入信息以及噪声水平,该方法在时频图像去噪中效果更好,通过将去噪图像与原始噪声图像对比分析可知,该时频图像细节恢复较高,噪声去除效果显著。不同于VAE 算法中高斯采样,基于LoRA 的扩散模型去噪方法采样方式更多,有Euler 一阶采样器以及扩散概率模型求解器(Dirichlet Process Mixture,DPM),数据表明DPM++采样方式效果最优,该算法相较于VAE,峰值信噪比提升20.2%,结构相似度提升11%,训练时间缩短0.7 h。由图3 可知,在a 图及b图中,该算法针对时频信号图像,去除了大部分噪声并保留了原始图像的边缘信息。VAE 去噪算法以及基于LoRA 扩散模型去噪算法,计算峰值信噪比和结构相似度指标见表1。该算法去噪效果见图2 和图3。
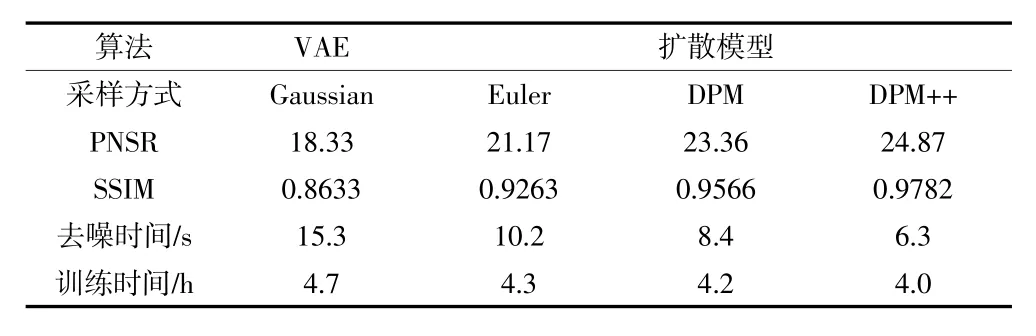
表1 VAE 及扩散模型在时频信号图中PSNR 和SSIM 指标

图3 基于LoRA 的扩散模型去噪效果
3 结语
针对时频图像的噪声分布,本研究采用基于LoRA 微调的扩散模型对时频图像去噪,在时频图像恢复中取得了显著的效果。该模型通过深度神经网络模型,学习含有噪声的时频图像分布,成功地降低了噪声对时频图像的影响,并恢复了原始时频图像的细节,提高了时频图像的清晰度。
该算法在峰值信噪比和结构相似度评价指标上表现出较为理想的结果,验证了在时频图像去噪任务上的有效性和可靠性。通过对比原始噪声图像和去噪图像,可以明显看出时频图像噪声显著减少,去噪质量显著提高。在未来研究中可以考虑优化网络结构、增加训练数据量、引入更多微调方式进行模型训练,以进一步提升去噪效果。
