轻量化Transformer目标跟踪数据标注算法
2023-10-24赵洁袁永胜张鹏宇王栋
赵洁,袁永胜,张鹏宇,王栋
大连理工大学信息与通信工程学院,大连 116024
0 引言
单目标视觉跟踪作为计算机视觉领域的基础研究之一,近年来已有了显著的进展(孟琭和杨旭,2019)。现有的各类型跟踪算法(王蒙蒙 等,2022)已在各个跟踪数据集上展现出鲁棒的跟踪性能,例如基于孪生网络的生成式方法SiamRPN++(Siamese region proposal network++)(Li 等,2019)、Ocean(object-aware anchor-free network)(Zhang 等,2020),辨别式跟踪方法BTCF(background-temporal-aware correlation filter)(朱建章 等,2019)、ATOM(accurate tracking by overlap maximization)(Danelljan 等,2019)、DiMP(discriminative model prediction)(Bhat等,2019),以及最新的基于Transformer 模型的方法TransT(Transformer tracking)(Chen 等,2021)、Mix-Former(mixed Transformer)(Cui 等,2022)。这些跟踪算法多是基于深度模型,需要大规模的有精确目标框标注的视频数据用于训练以保证模型的高性能跟踪。然而,人工逐帧标注目标框会耗费大量的人力资源和时间成本,现有的可用于跟踪模型训练的大规模视频数据集仍然存在很大的缺口,这成为跟踪性能进一步提升的瓶颈之一。因此如何高效地生成高质量的大规模视频数据标注成为该领域亟需解决的问题。
现有的大规模跟踪数据集中,LaSOT(largescale single object tracking)(Fan 等,2019)、GOT-10k(generic object tracking benchmark)(Huang 等,2021)和TrackingNet(large-scale tracking dataset)(Müller等,2018)最常用于跟踪算法中的模型训练。其中,LaSOT 和GOT-10k 均使用逐帧人工标注。LaSOT 包含1 400 个长序列,共70 类,超过3.5 M 视频帧中的目标框由人工标注。GOT-10k 包含10 000 个短视频序列,共有超过1.5 M的人工标注目标框。而TrackingNet 虽然包含超过30 000 个序列,但其使用稀疏人工标注,即每秒标注一帧,其他帧的目标框通过跟踪器STAPLECA(Mueller等,2017)生成。由于没有跟踪结果的质量筛选机制,该数据集存在标注质量不可靠的局限性,一定程度上影响跟踪模型的训练性能。由于人工标注的昂贵成本,目前能够用于跟踪模型训练的高质量大规模视频数据集仍不能满足鲁棒性跟踪算法的需求。
为减轻视频标注的人力和时间成本,目前已有若干方法尝试实现视频的自动目标框标注。现有方案的基本思路通常是先稀疏标注视频序列的若干关键帧,再通过插值的方式去自动补全其他帧的目标框标注。其中,插值方式主要分为3 类。1)基于几何信息的线性插值,例如LabelMe(Yuen 等,2009)。该类方法假定目标运动模式单一,仅依据目标的几何线索来获取其他帧的目标标注;2)基于视觉信息的复杂插值,例如,VATIC(video annotation tool from Irvine,California)(Vondrick 等,2010)通过提取目标实体的视觉特征,利用更复杂的动态插值方式生成目标标注;3)基于现有跟踪算法的插值,例如,TrackingNet 每隔1 s 标注1 帧,并利用跟踪器STAPLECA获得每一段子序列的前向反向跟踪结果,最终通过简单的基于时序的权重结合前向和反向的轨迹,获得最终的视频目标标注。此外,根据关键帧的获取方式,现有的视频标注方法可以分为两类,一类是采用固定的帧率进行人工稀疏标注,例如LabelMe,TrackingNet 等;另一类则通过算法去预测序列的关键帧,从而达到更好的插值效果。例如,Vondrick 和Ramanan(2011)提出了基于主动学习的视频标注方法,该方法通过迭代动态决定需要由人工标注的帧。而Kuznetsova 等人(2021)设计了一个排序模型,预测剩余帧的重要程度,分数越高则表示标注该帧将会带来更高的插值性能增益。
尽管不同的插值方式和关键帧的捕获方案会在一定程度上提高视频标注的质量和效率,但上述方法均未考虑标注的校正问题。当面对复杂的跟踪场景时,例如目标运动模式复杂、存在干扰物、背景复杂或目标受到局部遮挡等,现有的跟踪器及其他插值方式均有可能导致标注结果不可靠。设计有效的标注质量评估模块,并对自动生成的标注进行人工校正,将进一步提升自动标注的准确性和可靠性。针对这一问题,VASR(video annotation via selection and refinement)(Dai 等,2021)提出了一个全新的基于选择和细化的自动标注流程,其中选择模块用于对前向和反向的跟踪结果进行质量评估,根据跟踪结果的分数选择最终的目标标注,并筛选出跟踪错误的帧进行人工校正。细化模块则引入了几何参数预测模型来生成更准确的目标框标注。该方法虽然能够有效提升标注质量,但存在以下不足。首先,该方法的模型训练与执行前向反向跟踪的跟踪方法强绑定,并依赖现有的方法Alpha-Refine(Yan 等,2021b)生成目标分割掩码,标注生成过程复杂且没有通用性;其次,该工作选择基于在线更新的速度较低的跟踪算法DiMP进行插值,并且需要额外生成目标分割掩码,导致生成标注的过程效率较低,对于LaSOT量级的数据集,需要约两周时间。
针对上述不足,本文提出一个泛化性强的轻量化视频自动标注方法,并引入Transformer 模型融合基于视觉和运动的时序信息,实现对初始的前向反向跟踪结果的质量评估,并进一步优化目标框标注。本文提出的方法在训练阶段与具体的跟踪算法进行解耦,能够充分利用现有的轻量化跟踪器,例如STARK-Lightning(spatial-temporal Transformer)(Yan等,2021a)、HCAT(hierarchical cross-attention Transformer)(Chen 等,2022)等,实现简单且高效的视频自动标注。
本文主要贡献如下:1)设计了一个基于Transformer 模型的轻量化视频标注模型TLNet(Transformer-based label network),该模型包含质量评估子网络和回归子网络,通过Transformer 模型来融合时序的视觉和目标运动信息,结合前反向的跟踪结果,对每一帧进行标注质量评估,并进一步优化标注目标框。该模型与具体跟踪算法解耦,具有强泛化性。2)提出一个简单高效的视频标注算法,能够应用现有的任意跟踪器,包括高速的轻量化跟踪器,对稀疏标注序列的其他帧进行插值标注,使用TLNet 评估每一帧的标注质量,筛选出低质量帧进行人工标注,并自动优化剩余帧的目标框,保证了标注的质量和效率。3)在LaSOT 和TrackingNet 数据集上生成自动标注,验证了TLNet 自动标注算法的有效性和高效性。与人工逐帧标注相比,TLNet 生成的自动标注在LaSOT数据集上节省超过91%的人力成本,并使最终标注的平均重叠率(mean intersection over union,mIoU)达到0.871,完整的自动标注过程仅需约43 h。4)在TrackingNet数据集上自动生成标注,并重新训练了3 种跟踪算法,在3 个跟踪数据集上进行性能测试与评估。实验表明,相较于TrackingNet 的原始标注,使用本文自动生成的标注能够训练出更加鲁棒的跟踪模型。
1 相关技术
1.1 Transformer模型
Transformer 模型(Vaswani 等,2017)由于其强大的捕获全局语义信息的能力,广泛应用于序列任务,例如自然语言处理(Devlin 等,2019)。近年来,Transformer 模型逐渐被挖掘出处理视觉信息的强大能力,取代卷积神经网络,应用于计算机视觉的各个领域,例如图像分类(Dosovitskiy 等,2021)、目标检测(Carion 等,2020)、视觉跟踪(Chen 等,2021)。该模型包含编码器和解码器,图1 展示了编码器和解码器共有的基本单元结构,主要由多头注意力模块(multi-head attention)和前馈神经网络(feedforward network)两个组件构成。每个组件的输出均采用了残差连接(He 等,2016)和层标准化(Ba等,2016)来保证模型的收敛。多头注意力模块(Attention)的核心操作为

图1 Transformer模型基本单元结构Fig.1 Architecture of Transformer model
式中,对于输入的维度为dk的向量Q、K 和V 分布表示query、key、value,计算K 和Q 的相似性权重并加权至V。前馈神经网络则由两层线性层和非线性激活函数(rectified linear unit,ReLU)构成。此外,引入位置编码用于捕捉序列的位置信息。
最常见的基于Transformer模型的图像处理方式是将图像分割为若干图像块并按照空间位置排序,每一个图像块作为一个词向量(token)输入Transformer 模型,通过融合各图像块提取图像特征,用于下游任务。与分割图像块方式不同的是,本文尝试充分利用Transformer 模型处理序列信息的能力,将每一个视频帧的目标作为一个整体,结合其视觉特征和运动特征并作为一个词向量,引入Transformer模型来挖掘连续T帧的目标特征,学习目标的外观变化与运动模式。
1.2 像素级互相关操作
互相关操作(cross-correlation)广泛应用于视觉跟踪领域,尤其是基于孪生网络的跟踪算法,例如SiamFC(fully-convolutional Siamese network)(Bertinetto 等,2016),SiamRPN(Siamese region proposal network)(Li 等,2018),SiamFC++(fully-convolutional Siamese network++)(Xu等,2020)等。对初始帧的模板特征Z∈与当前帧的搜索区域特征X∈执行互相关操作,度量两特征的相似性,并输出对应响应图,其中高响应值处表示搜索区域中的前景,反之则为背景。C、H、W分别表示对应特征向量的通道数、高度和宽度。在本文中,各帧目标的视觉信息将由各帧的搜索区域与模板图像的互相关响应图表示。之后该响应图与目标运动信息结合,共同表示单帧的目标特征。
受Alpha-Refine(Yan 等,2021b)启发,为最大程度保留空间信息,实现后续精确的目标框预测,本文采用像素级互相关操作(pixel-wise correlation)(Wang等,2019)。首先将模板特征Z分解为HzWz个特征向量Zj∈RC×1×1,将其作为卷积核分别与搜索区域特征X 执行互相关操作,最终获得响应图M∈,该过程可表示为
2 视频自动标注算法
2.1 视频标注生成策略
现有的视频标注算法通常通过稀疏标注关键帧并插值的方式实现视频逐帧标注。由于缺少对标注质量的评估校正模块,生成的视频标注往往可靠性低。此外,通过与人工交互迭代的方式确认关键帧会使标注过程更加烦琐和冗余。为解决上述问题,受VASR 方法启发,本文提出了一个简单高效的视频标注算法,通过引入本文设计的端到端的基于Transformer的轻量化视频标注模型TLNet,对初始的目标标注进行质量评估和优化。相较于现有的视频标注算法,该算法主要有以下优势。首先,减少了标注过程中人工的参与,简化了标注流程;其次,强泛化性的轻量模型设计和轻量化跟踪器的选择,提升了视频标注的效率;此外,引入质量评估模块,保证了最终生成标注的可靠性。
本文提出的视频标注算法的具体流程图如图2所示。首先,以固定的帧率(本文采用30 帧)进行人工稀疏标注。序列将被切分为若干片段,每一个片段的首尾帧包含人工精确标注;之后选择任意跟踪器对每一个片段执行前向和反向跟踪,生成前向和反向跟踪结果,并作为剩余未标注帧的初始标注;本文提出的TLNet 将根据包含目标视觉和运动模式的序列信息,对每一帧的跟踪状态进行质量评估,根据质量分数筛选出跟踪失败的帧;失败帧将反馈给标注者进行人工标注,而其他可靠帧将通过TLNet 进行进一步优化,基于前向反向的初始标注,生成更加精确的目标框标注。通过整合人工标注和优化后的自动标注,最终得到可靠的逐帧视频标注。

图2 视频标注流程图Fig.2 Procedure of generating video annotations
值得注意的是,本文设计的TLNet 模型不依赖具体的跟踪器,泛化性强,可选择任意轻量化跟踪器高效率地生成前向反向初始标注;其次,本文的质量评估模块是帧级别,而非目标框级别,即本文针对当前帧的初始前向反向跟踪结果,并综合考虑前后帧的目标视觉与运动时序信息,给出当前帧整体的跟踪状态质量评估,而不是分别对前向和反向跟踪结果进行质量评估。该方案能够筛选出序列中挑战难度大的帧(即易跟踪失败的帧),执行人工标注,从而保障了标注的可靠性。
2.2 网络模型
本文设计的视频标注模型TLNet 框架如图3 所示。该模型通过一个Transformer时序网络融合来自前向跟踪和反向跟踪的目标视觉与运动模式的序列信息,回归分支和质量评估分支将分别处理融合后的特征,给出精确的目标框预测及每一帧跟踪状态的质量分数。TLNet可分为3个模块,分别是目标多维度特征提取模块,Transformer 时序特征融合模块和预测分支。
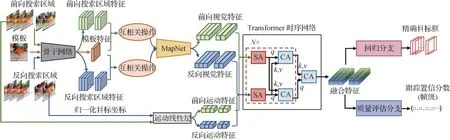
图3 视频标注模型TLNet框架图Fig.3 Framework of the proposed video annotation model TLNet
2.2.1 目标多维度特征提取
输入单帧模板图像、连续多帧的前向和反向搜索区域图像和对应的前向反向跟踪结果,该模块负责提取出连续多帧的目标的多维度特征,即视觉特征和运动特征。
对于视觉特征,本文通过执行模板与搜索区域的像素级互相关操作,生成目标的响应图,并将其作为目标的视觉特征。具体来讲,模板图像和前向反向搜索区域图像将分别通过骨干网络提取出模板特征Z、连续T帧的前向搜索区域特征和反向搜索区域特征Z分别与Xf和Xb执行式(2)所示的像素级互相关操作,生成对应的前向反向响应图Mf和Mb。通过像素级互相关操作,响应图记录了各搜索区域中目标与模板的视觉匹配度,可反映目标的外观变化。为挖掘响应图中的重要视觉信息,并减少计算量,实现轻量化设计,响应图将输入响应图网络(response map network,MapNet),并输出对应的序列前向和反向视觉特征向量,表示为其 中dv表示视觉特征向量的维度。MapNet 由3 层卷积核大小为3 的卷积层组成,每个卷积层后连接一个ReLU激活层和池化层。
对于运动特征,本文将序列的前向反向跟踪结果,即连续T帧的目标框坐标进行归一化,并输入运动线性层提取对应的前向反向运动特征向量,表示为,其中dm表示运动特征向量的维度。该运动特征向量记录了目标的运动模式和几何变化。
2.2.2 Transformer时序特征融合
Transformer 在视觉任务中往往切割图像块并将其作为一个词向量,通过融合不同图像块特征提取出具有辨别性的图像特征。与此不同的是,本文引入序列维度,将单帧图像的特征作为一个整体,挖掘不同帧图像之间的融合特征。即本文通过Transformer 模型来实现序列特征及前向反向特征的融合。该模型参照TransT 结构设计,由自注意力模块(self-attention,SA)和交叉注意力模块(crossattention,CA)组成。两个模块的结构图如图4所示。其中SA通过计算自注意力,在时序维度上分别融合各自的特征,而CA 则通过计算交叉注意力来融合前向和反向的特征,最终生成双向时序融合特征。注意力计算方式如式(1)所示。两个SA模块和两个CA 模块共同构成一个融合单元(图3 中虚线框),该融合单元重复执行N次,并在最后接入一个CA模块来融合两个分支的特征,解码出最终的融合特征,该特征融合了时序和方向两个维度上的目标信息。

图4 SA模块和CA模块结构图Fig.4 Architecture of the SA module and CA module
为了在特征融合过程中保持序列的顺序性,对每一帧定义位置编码并添加至对应目标特征向量中。位置编码(positional encoding,PE)定义为
式中,dmodel表示向量维度,pos表示位置。
2.2.3 预测分支
Transformer 时序网络生成的融合特征将分别输入质量评估和回归分支中。前者输出每一帧跟踪状态的质量分数,而后者则结合时序的前向和反向跟踪结果,输出更准确的目标框坐标。两个分支均由3 个全连接层实现,除最后一层外,其余每个全连接层后连接一个ReLU 层。其中质量评估分支为每帧输出1 维向量,表示质量分数;而回归分支输出4 维向量,分别表示预测目标左上角和右下角坐标。
将质量评估分支和回归分支设计为两个独立的子网络,即各自训练独立的任务,并最终生成独立的模型参数,多维度特征提取模块和Transformer 时序网络的参数不共享。通过实验验证了与共同训练两个子任务并共享特征提取及特征融合阶段的模型参数相比,分离两个子网络并分别训练会带来更高的性能收益。因此本文采用后者。猜测导致这一现象的原因是两个任务侧重点不同,因此需要从不同角度提取并融合特征。其中,质量评估分支的目的是评估当前帧的跟踪状态是否可靠,进而筛选出跟踪失败的帧,因此视觉特征将占据主导作用,运动特征则作为辅助用来检测运动模式是否异常。而回归分支则需要依赖前向和反向的运动特征回归出更准确的目标框,视觉特征在其中主要起到权重分配的作用。
2.3 损失函数
2.3.1 质量评估子网络
对于当前帧的跟踪状态质量评估将基于前向与反向跟踪结果与真值目标框的重叠率IoU。参照VASR方法,定义单个跟踪结果的质量分数为
式中,α和β为控制参数,其设置与VASR 相同,分别为50和2。相较于IoU,非线性函数f(IoU)将分数区间从[0,1]扩展至(-1,1),能更辨别性地表示不同跟踪结果的质量。由于本文尝试根据前向(forward)和反向(backward)的跟踪结果去评估单帧的跟踪状态质量,并基于此筛选出挑战难度大的难跟踪帧,因此对于前向和反向跟踪都失败的帧,被赋予低质量分数;而对于单向(前向或反向)跟踪失败的帧,由于仍存在可靠的单向跟踪结果,后续仍可根据回归子网络回归出精确目标框,因此基于跟踪成功的单向结果,仍被赋予较高分数。本文定义单帧的质量分数为前向和反向质量分数的最大值,该分数能够有效度量单帧的跟踪状态,低分数则表明该帧的前反向跟踪都会失败,为高难度帧,需要由人工标注。具体为
式中,下角f、b分别表示forward和backward。
输入T帧的序列数据,质量评估子网络会预测对应帧的质量分数{gi}i=1,2,…,T,该网络训练的损失函数采用均方误差损失,定义为
2.3.2 回归子网络
结合gIoU(generalized intersection over union)损失LgIoU(Rezatofighi 等,2019)和L1损失来训练回归子网络。回归分支损失函数定义为
式中,bi和分别表示预测的目标框和真值目标框。λ1和λ2为两个超参数,分别设置为2.0和5.0。
3 实验与分析
3.1 实现细节与评估指标
3.1.1 模型设计
为高效地生成视频标注,本文将TLNet 设计为轻量化模型。具体来说,骨干网络采用ResNet18(residual network)(He 等,2016),其中,第4 阶段下采样层的卷积步长更改为1,并输出第4阶段的特征图 。模板及双向搜索区域特征图∈RC×H×W,其中,H,W=H0,W0为输入图像的尺寸,C=256。通过互相关操作及Map-Net 生成的视觉特征向量维度dv=64,通过运动线性层提取的运动特征向量维度dm=16,结合两特征向量,最终得到维度为64 的,并输入Transformer 时序网络。对于Transformer 时序网络,本文设置多头注意力机制的头(head)数目为2,前馈神经网络维度为256,融合单元的层数N=4。
3.1.2 训练设置
TLNet 在大规模跟踪数据集LaSOT 和GOT-10k的训练集上训练,并生成LaSOT 和TrackingNet 训练数据集的标注。对于TrackingNet 数据集,使用LaSOT 和GOT-10k 所有序列进行训练;而对于LaSOT 数据集,为保证实验公平性,将LaSOT 训练集随机分割为2 个子集,使用一个子集和GOT-10k 训练模型,并生成另一个子集的数据集标注。本文采用稀疏度为30 的人工标注(即数据集官方标注),并选用轻量化跟踪器HCAT 生成每个片段的前向反向跟踪结果。训练过程中,随机选择一个序列中人工标注的帧裁剪模板图像,并随机选择连续T帧,基于前向和反向跟踪结果裁剪对应的搜索区域图像,其中序列长度T=20。为展现更多搜索区域中目标的细节,实现精确的目标框预测,模板图像和搜索图像均采用2 倍目标框范围进行裁剪,并缩放至统一大小,H0=W0=128。
本文算法使用深度学习框架PyTorch实现,并使用单个NVIDIA GTX2080Ti GPU 进行训练和测试。采用AdamW(Loshchilov 和Hutter,2019)优化器进行模型训练,初始学习率为10-4,每训练20 次降低10 倍,共迭代训练70 次。批大小(batch size)设置为16。
3.1.3 评估指标
由于LaSOT数据集的官方标注为人工逐帧精确标注,而TrackingNet 则为跟踪器插值方式生成的标注,存在噪声。因此本文设计两个标准分别评估两个数据集上生成的标注质量。
对于LaSOT 数据集,本文采用与真值目标框的平均重叠率mIoU 来评估数据集标注质量。此外,对于质量评估子网络,采用准确率(accurancy,Acc)、召回率Recall和特异度(true negative rate,TNR)来评估预测质量分数。Acc 表示正确分类的帧数占总帧数的比例,Recall表示跟踪成功的帧数中正确识别的比例,TNR表示跟踪失败的帧数中被识别出来的比例。
由于TrackingNet 数据集的官方标注存在噪声,导致上述评价标准不可靠,因此本文采用跟踪指标评估TrackingNet 数据集上生成的标注质量。即使用TrackingNet 官方标注和本文自动生成的标注分别重训现有的跟踪算法,并在不同的跟踪数据集上测试训练出的模型性能。本文选择3 个不同的跟踪算法进行重训,分别是ATOM(Danelljan 等,2019)、DiMP50(Bhat 等,2019)和PrDiMP50(probabilistic regression DiMP)(Danelljan 等,2020),并分别在LaSOT、TrackingNet 和GOT-10k 数据集上进行测试与评估。
3.2 LaSOT数据集标注评估
本文以轻量化跟踪算法HCAT 为例,生成LaSOT 训练数据集的标注。标注过程共分为3 个阶段,首先对稀疏标注(每隔30 帧标注,共3.3%标注帧)分割的每个片段执行前向和反向跟踪,生成初始的标注结果;然后通过本文质量评估子网络评估每一帧的标注质量,并通过阈值筛选出跟踪失败帧,进行人工标注;最后执行本文回归子网络,对目标框进行优化,生成最终的数据集标注。表1展示了各阶段生成的标注的质量评估结果。其中,mIoU 表示与真值目标框的平均重叠率,Rate<0.3、Rate<0.5和Rate>0.7分别表示重叠率低于0.3、低于0.5 和高于0.7 的帧数占总帧数的比例。由前向反向跟踪生成的初始标注的平均重叠率为0.824。在经过质量筛选(其中,5.4%的帧被判定为跟踪失败,并进行人工标注)后,mIoU 提升4%,重叠率低于0.3 和0.5 的帧分别下降至1.41%和2.52%。经过目标框优化后,最终的数据集标注的mIoU 提升至0.871,重叠率高于0.7 的帧数提升至92.9%。由此可见,本文提出的标注算法能节省91.3%(3.3%稀疏标注和5.4%筛选跟踪失败帧)的人工标注,并相较于跟踪算法插值的方式,使平均重叠率提升4.7%。

表1 LaSOT数据集的各阶段标注质量评估Table 1 Quality measurement of generated annotations from different steps on LaSOT dataset
为展示本文的质量评估网络能够有效筛选出挑战难度大的跟踪失败帧(即双向均跟踪失败),定义每一帧是否被跟踪成功的真值标签为
即当该帧的前向或反向跟踪结果与真值目标框的重叠率大于0.5 时,认为该帧能够被现有跟踪算法成功跟踪,属于跟踪成功帧,后续应通过回归网络对双向跟踪结果进行优化;否则认为该帧很难被跟踪算法成功跟踪,属于跟踪失败帧,后续应执行人工标注。而对于质量评估网络预测的分数,当分数大于设定的阈值时,预测该帧跟踪成功,否则预测为跟踪失败。值得注意的是,采用0.5作为IoU阈值的原因是与跟踪任务的性能评价指标保持一致,例如OTB(object tracking benchmark)(Wu 等,2013)及LaSOT(Fan等,2019)中的成功率阈值。
图5 绘制了不同分数阈值下,筛选的准确率Acc、召回率recall、特异度TNR以及筛选前后的平均重叠率mIoU。此外,为反映需人工标注的工作量,该图亦绘制了失败率Ratefail,即筛选出的失败帧占总帧数的比率。可以看出,对于不同的阈值设定,筛选出的失败帧比例介于2%~13%,随着筛选出的失败率增加,TNR 大幅提升,而Acc 和recall 小幅下降。相较于初始标注的mIoU,筛选后的mIoU 显著提升。当筛选出约12%失败帧时,TNR 高达0.926,这意味着绝大多数的标注失败帧均被筛选出来。为平衡人工标注的成本和最终标注的质量,本文将阈值设定为0.7,其中失败率为5.4%,TNR 为0.761,筛选失败帧后,mIoU 由0.811 提升至0.851。值得注意的是,与表1 的mIoU 不同,为公平评估模型的筛选能力,此处mIoU的统计不包含任何人工标注的帧。

图5 不同阈值的分数评估Fig.5 Score evaluation with different thresholds
3.3 TrackingNet数据集标注评估
由于TrackingNet 的训练集不是逐帧人工标注,存在噪声,因此本文通过间接评估跟踪性能来评估本文对于TrackingNet 的标注质量。本文选用了3个现有的跟踪算法,即ATOM、DiMP50和PrDiMP50,并分别使用TrackingNet 自身标注和本文标注对模型重训练,以下是在3 个跟踪数据集上的跟踪性能评估结果。其中“_GT”表示使用TrackingNet 官方标注进行训练,“_Ours”表示使用本文的TrackingNet 标注。为与VASR 方法(Dai 等,2021)进行对比,本文亦列出其对应的结果,表示为“_VASR”。值得注意的是,参考下文3.5.2中的耗时分析,对于LaSOT量级的数据集,本文的自动筛选及标注过程仅需约43 h,相较于VASR方法的约两周时间,时间成本有所缩减。
1)LaSOT。图6 展示了LaSOT 数据集上的跟踪性能比较,采用的评价指标为成功率和准确率。相较于使用TrackingNet 官方标注进行训练,使用本文的标注训练分别为ATOM、DiMP50 和PrDiMP50 在成功率上提升了0.5%、0.9%和2.2%。这间接表明了本文生成的标注质量更高,能训练出更加鲁棒的跟踪模型。此外,表2对比了本文方法和VASR方法的结果。对于ATOM 和DiMP50,本文在LaSOT 数据集的成功率上优于VASR 方法,PrDiMP50 的性能稍有下降。

表2 使用TrackingNet不同标注重新训练各跟踪器在不同数据集上的跟踪性能对比Table 2 Performance comparison of retrained trackers using different TrackingNet annotations

图6 使用TrackingNet数据集的不同标注训练的不同跟踪器在LaSOT数据集上的成功率和精确率曲线图Fig.6 Tracking performance on LaSOT dataset by using our trackingnet annotations(ours)and trackingnet official annotations(GT)((a)success plots;(b)precision plots)
2)TrackingNet。表2 列出了不同方法的不同训练模型在成功率和归一化准确率上的跟踪结果。相较于官方标注,本文标注可分别为ATOM、DiMP50和PrDiMP50 在成功率上带来0.7%、1.5%和2.5%的性能收益。虽然VASR 方法在该数据集上表现更好,但平衡时间成本后,本文能有效缩小时间成本并基本达到持平的跟踪性能。
3)GOT-10k。表2 最右两列展示了GOT-10k 上的跟踪性能,评估指标分别是平均重叠率(average overlap,AO)和阈值为0.75 的成功率(success rate,SR0.75)。在该数据集上,本文相较于使用官方标注训练的模型有大幅的性能提升,在SR0.75上分别为ATOM、DiMP50 和PrDiMP50 提升了4.3%、8.8%和7.9%。相较于VASR方法,本文会导致DiMP50方法在AO指标上下降0.1%,并导致PrDiMP50提升3.6%。
3.4 消融实验
在LaSOT数据上实验,探索不同融合模型、质量分数真值及序列长度对模型筛选能力的影响。
1)Transformer 时序模型。为验证Transformer 时序模型融合时序和双向数据能力,将Transformer 模型替换为长短期记忆网络(long short-term memory,LSTM)模型,筛选结果如表3所示。

表3 不同融合模型对于筛选能力的影响Table 3 Effect of different fusion models on filtering ability
从表3 可以看出,相较于Transformer 模型,LSTM模型识别失败帧的能力下降,在预测出相似失败帧比率的前提下,即人工标注成本相似,TNR 由76.1%降至65.7%,Acc 和recall 也有所下降,这说明LSTM 模型会错误地筛选出较多的成功帧,并存在较多的失败帧未被筛选出来。
2)帧级质量表示。设计每一帧的真值标注质量由前向和反向跟踪质量分数的最大值表示,如式(5)所示。为验证最大值操作的合理性,将最大值真值替换为平均真值,筛选结果如表4 所示。可以看出,替换成平均操作后,TNR下降超过3%。因此相比于平均真值,采用的最大值真值能筛选出更多的失败帧。

表4 不同质量分数真值对于筛选能力的影响Table 4 Effect of different fusion models and different quality score’s ground truth on the filtering ability
3)序列长度。为验证输入的序列长度对于性能的影响,本文使用不同长度的序列数据进行模型训练和生成标注,筛选结果如表5 所示。可以看出,当T=20 时,能更准确地识别出失败帧,得到更高质量的数据集标注。因此本文选择T=20。值得注意的是,当T=5时,TNR 最低,这主要是由于序列长度过低时,模型无法捕获长距离的目标视觉变化和运动模式,筛选能力较低。

表5 不同序列长度对于筛选能力的影响Table 5 Effect of sequence length on the filtering ability
3.5 实验分析
3.5.1 泛化性分析
由于在模型的训练过程中未使用前向反向跟踪过程中产生的中间结果,例如置信分数、响应图等,TLNet 不依赖于任何具体的跟踪算法,具有强泛化性。为验证TLNet 强大的泛化能力,将训练好的TLNet(HCAT 方法生成的前向反向跟踪结果作为训练数据)作用于STARK 方法(ResNet101 模型),根据STARK 算法产生的前向反向跟踪结果,进行质量筛选和优化目标框。生成的数据集标注质量如表6 所示。由于STARK 算法自身的高鲁棒性,初始标注结果已有较高质量,mIoU 为0.856。筛选后,仅2.9%的帧被识别为失败帧,进行人工标注,筛选后标注的mIoU 提升至0.879,其中Rate<0.3和Rate<0.5均有明显下降。值得注意的是,由于STARK 本身的跟踪结果已有较高的准确率,本文的回归子网络并未对其起到优化作用,但Rate<0.3有所下降,说明回归子网络对于优化质量极差的帧仍起到一定的作用。该结果说明回归子网络存在一定的优化上限,因此仅对性能相对较差的轻量化跟踪算法执行优化步骤。

表6 基于STARK跟踪结果的标注质量评估Table 6 Quality measurement of generated annotations based on the STARK’s tracking results
3.5.2 耗时分析
对于自动标注方法,除了保障标注的高质量外,标注的效率也是至关重要的。VASR 方法提出基于选择和细化的自动标注策略,简化了标注流程并节约了标注时间。本文对该方法进行改进后,进一步简化了标注流程,并缩减了生成标注的时间。
VASR 方法采用DiMP50 算法执行初始的前向反向跟踪,由于训练过程需要DiMP50方法和Alpha-Refine 方法生成对应的跟踪结果及分割掩码等数据,导致模型不具有泛化性,并且数据准备时间长。对于生成LaSOT 数据集量级的标注,选择不同的基准跟踪算法均需要重新进行数据准备和模型训练,共需耗费约两周时间(Dai等,2021)。该方法的耗时主要是由于跟踪算法的选择和模型的低泛化性。表7统计了不同跟踪方法的跟踪性能、在初始化阶段和单帧跟踪阶段的耗时,以及长度为30 帧的片段的平均耗时。此处将现有的两个轻量化跟踪算法与VASR 使用的DiMP50 算法进行对比,其中mIoU 为前向反向跟踪结果的平均mIoU。可以看出,虽然两个轻量化方法在跟踪性能上均低于DiMP50,但在执行前反向跟踪时能够节省约4 倍的时间,实现高效标注。
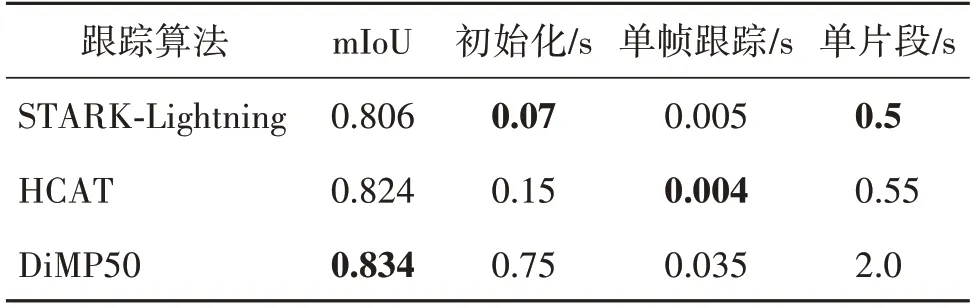
表7 不同跟踪算法在LaSOT数据集的耗时及性能分析Table 7 Time-consuming and performance analysis of different trackers on LaSOT dataset
此外,由于本文模型和具体的跟踪算法解耦,对于待标注的数据集,可任意选择现有的轻量化跟踪算法生成初始标注,而无需进行模型的重训练,因此仅需要考虑前向反向跟踪时间及TLNet 执行时间。对于生成LaSOT数据集量级(2.8 M)的标注,并采用现有的轻量化跟踪算法HCAT,前向反向跟踪需耗时约35 h,TLNet的速度约为200帧/s,执行筛选和优化过程需耗费约8 h,因此共耗费约43 h,相较于VASR 耗费的两周时间,本文方法在标注自动生成效率上有显著提升。
为公平对比本文方法与VASR方法,表8展示了在筛选出相似失败率(2.7%和2.9%)的前提下,本文方法与VASR 方法在标注质量和耗时方面的对比。可以看出,本文方法节约了大量的标注时间,约82%,并且本文方法对标注的mIoU 提升水平与VASR相当,分别提升了3.2%和3.1%。

表8 与VASR方法在标注质量和耗时方面的比较Table 8 Comparison with VASR on annotation quality and time-consuming
3.5.3 定性分析
为展示本文的质量评估网络能够通过预测帧级分数来有效地筛选出标注失败帧,图7 列举了LaSOT 数据集中的5 个序列的若干结果。其中绿色框被网络预测为标注成功帧;而红色框被预测为标注失败帧,后续反馈给标注者进行人工精确标注。可以看出,当前向和反向跟踪的目标框中有至少一个标注能够达到高精度的标准,质量评估网络就会预测出较高的分数;而当前向和反向的跟踪结果都较差时,质量评估网络会给出较低的分数,判定为失败帧。由于当前向或反向存在准确的标注时,说明该帧的跟踪难度较低,后续回归子网络仍可根据前反向结果生成准确的最终标注;而当前向和反向均跟踪失败时,说明该帧挑战难度大,需要由人工标注。与目标框级别的分数预测相比,这种帧级的分数预测更能准确地筛选出失败帧,并减少成功帧的错误识别,减轻人工标注的工作量。

图7 质量评估网络预测的分数图示Fig.7 Illustration of the scores output by the proposed quality evaluation network
此外,对本文生成的标注与TrackingNet 数据集的官方标注进行了定性比较,如图8 所示。可以看出,通过筛选失败帧及优化目标框,本文方法能更好地应对多种跟踪挑战,生成更高质量的视频标注。

图8 TrackingNet官方标注与本文标注的对比Fig.8 Comparison between the official annotations of TrackingNet dataset and our annotations
4 结论
训练现有的基于深度网络的跟踪算法需要大规模的具有精确标注的视频数据集,而逐帧标注大规模数据集会耗费大量的人力和时间成本。为减轻人力消耗,并平衡标注的质量,提出TLNet 网络来高效地自动生成高质量大规模数据集标注。该网络包含互相关模块及Transformer 时序模型,通过输入时序的目标视觉和运动信息,来提取并融合双向的初始跟踪结果,进而进行标注的评估和优化。通过筛选出失败帧并优化剩余目标框,生成高质量的标注。采用两种评价方式分别评估LaSOT 及TrackingNet数据集的标注质量。前者采用与真值目标框的平均重叠率以及筛选失败帧的准确率及特异度等指标进行直接评估;而后者由于自身标注存在噪声,通过重新训练跟踪算法并评估跟踪性能的方式进行间接评估。大量实验验证了本文方法具有强泛化性,能够利用任意轻量化跟踪算法实现高效的自动标注。本文工作的主要局限性在于回归子网络的目标框预测存在一定的性能上限,对于高性能跟踪算法生成的初始标签无法起到优化的作用。这主要是由于视觉特征的空间信息没有很好地保留,因此回归分支无法根据空间位置预测更精准的目标框。后续工作将从该点出发,尝试优化模型框架,尽可能保留更多目标的空间信息,实现更精确的目标框优化。
