自监督E-Swin的输电线路金具检测
2023-10-24张珂周睿恒石超君韩槊杜明坤赵振兵
张珂,周睿恒,石超君,2,韩槊,杜明坤,赵振兵,2
1.华北电力大学电子与通信工程系,保定 071003;2.华北电力大学河北省电力物联网技术重点实验室,保定 071003
0 引言
随着国家电网新规划的实施,我国电网建设不断加速,输电线路的覆盖范围逐步扩大。作为电力系统中最主要的基础设施,输电线路是否安全稳定运行对整个电力系统及人们日常生活有重要影响。而确保输电线路中关键部件(金具等)处于正常状态,是维持电力系统稳定的重要环节。金具是铝或铁制的金属附件,包含保护金具、接续金具、联接金具、耐张线夹以及悬垂线夹等,主要用于支持、固定、接续裸导线、导体及绝缘子(赵振兵 等,2019)。此类部件常年处于户外,面临的环境复杂,易出现位移、歪斜和破损等情况,影响导线及杆塔连接结构稳定,一旦发现不及时将造成重大电路损坏事故。评估金具运行状态并实现故障诊断,首先需对输电线路金具目标进行精确定位和识别(赵振兵 等,2021)。随着深度学习和无人机巡检技术的发展,传统人工巡检方式逐渐被取代。现阶段主要依靠无人机航拍获得金具图像、再结合深度学习技术进行自动分析,因此研究基于深度学习的输电线路金具检测模型对保证电网安全运行有重大意义。
目前,金具检测主流做法是把在公共数据集上表现良好的目标检测模型加以优化后,应用于电力视觉领域。近年来,基于有监督学习的输电线路金具检测模型已取得了较好效果。汤踊等人(2018)选用并改进了区域卷积神经网络Faster R-CNN(region convolutional neural network)(Ren 等,2017)作为输电线路部件识别模型,调整了卷积运算中卷积核的大小、并采用数据增广的方式扩充数据集,验证了这两种方法对提升精度的可行性。白洁音等人(2019)同样采用该网络作为主要模型,利用数据挖掘对检测目标进行定位,为复杂背景下的航拍图像多目标检测提供了参考。戚银城等人(2019)针对密集金具检测问题,提出了一种使用改进交并比(intersection over union,IoU)的单步多框目标检测模型(single shot multibox detector,SSD)(Liu 等,2016),该模型对目标尺度更加敏感,并针对密集目标加入斥力损失,获得了更好的密集检测效果。Wan等人(2020)针对现阶段研究未考虑上下文信息的问题,在基于区域的全卷积网络(region-based fully convolutional network,R-FCN)(Dai 等,2016)上做了改进,并采用可形变卷积模块和注意力模块,检测精度提高了4%。翟永杰等人(2022)则从目标检测模型与专业知识融合的角度,提出共现推理检测模型,采用图学习的方法,利用金具目标间的共现连接关系,构建结合外部专业知识的目标检测模型,在金具检测上取得较为显著的精度提升。赵振兵等人(2022)针对多类金具不同尺度变化较大的问题,提出了改进级联区域卷积神经网络(cascade region convolutional neural networks,Cascade R-CNN)(Cai 和Vasconcelos,2018)的模型,利用神经架构搜索获取空洞卷积的空洞率,扩大卷积计算的感受野,使其进行更优的多尺度特征提取,并结合递归金字塔进行特征优化,提高了检测精确度。
上述研究大多采用的是基于卷积神经网络(convolutional neural network,CNN)的目标检测模型,而近年来Transformer(Vaswani 等,2017)因其优异性能,在计算机视觉领域得到广泛应用。Dosovitskiy 等人(2021)提出了ViT(vision Transformer)模型,利用块划分的思想处理图像,使整幅图像输入Transformer 的序列不会过长,解决了将Transformer用在图像处理领域的困难,并验证了这种模型在视觉上作为主干网络的可行性。Beal 等人(2020)将ViT模型作为主干网络,结合Faster R-CNN模型的结构,构建检测模型,获得了不错的效果。针对目标检测任务需要多尺度特征层、但ViT 模型各层尺度相同的问题,Liu 等人(2021)提出了Swin Transformer(shifted windows Transformer)模型,利用卷积神经网络的层次化思想和滑动窗口的操作构建主干网络,其效果超越了以CNN 为主干网络的目标检测模型。该模型主要问题在于自注意力计算时,矩阵乘法计算量较大,导致模型运算效率较低,需针对计算进行改进。
现阶段金具检测模型大多依赖于有监督学习,即在模型训练之前需进行人为的数据标注。但随着无人机巡检的发展,采集的部件数据越来越多,全部进行人为标注需消耗大量资源。无监督方式是研究方向之一(张珂 等,2021)。输电线路大量数据的处理可利用Transformer 的自监督学习特性有效解决。自监督学习是无监督学习的一种方式,通过给无标注数据设计辅助任务,以进行主干网络预训练,挖掘数据自身的特征表示;再通过检测或分割等下游任务,用较少的有监督数据进行微调训练。
借鉴自然语言处理领域中单词预测的辅助任务,He 等人(2022)提出MAE(masked autoencoder)模型,利用Transformer结构的编码器和解码器,将图像随机遮盖一部分后输入,在解码器输出重构输入图像。通过较高的遮挡比率,例如75%,可显著减少编码器的计算量。在解码器端,预测结果与原图计算误差损失,得以进行自监督训练。自监督训练完成后,去掉解码器,将编码器作为一个已预训练的ViT 主干网络,用于下游任务的有监督微调训练。得益于ViT 的全局性,随机遮掩不会影响计算,但对基于局部窗口的Swin Transformer 等网络而言,随机遮掩导致局部窗口中的可见块数量不相等,妨碍了局部窗口的自注意力并行计算。针对这个问题,Xie等人(2022)提出的SimMIM(simple framework for masked image modeling)模型,采用了将未被遮盖的和被遮盖的图像块一同输入编码器的方法,而解码器只设置一个简单的线性层。虽然这样使编码器计算量变得较大,但可以训练基于局部自注意力的多尺度主干网络。Li等人(2022)提出的UM-MAE(uniform masking MAE)模型则利用了一种二次采样的方式,先均匀采样保证每个局部窗口得到等量图像块,再随机采样遮挡小部分,防止均匀采样减少自监督任务的难度导致最终效果变差。这种方式不增加编码器的计算量也可实现多尺度主干网络的自监督训练。
由于需要大量数据为支撑来挖掘数据自身的特征表示,自监督学习的主要问题在于训练的速度较慢、所需时间较长。让编码器只处理未被遮盖的部分图像可显著减少运算量,提高效率,而构建轻量级的解码器也可进一步缩短训练时间。同时,针对现有模型的损失函数进行改进,也有助于自监督学习的训练更快收敛。
本文以上述问题为出发点,提出一种高精度金具检测模型,主要贡献如下:首先,针对主干网络自注意力计算量较大的问题,提出轻量的高效特征提取网络E-Swin;然后,为了利用大量的无标注数据、并加强模型特征提取能力,采用自监督学习处理数据,预训练主干网络E-Swin,并设计轻量化、平滑的自监督方法解决推理速度较慢的问题;最后,为了提高检测定位精度,解决检测框不贴合目标的问题,设计一种高性能检测头。为提高推理速度,本文构建比Faster R-CNN 等二阶段模型更有效的一阶段模型,实现了对输电线路金具检测模型的优化。
1 本文方法
本文模型的实现过程如图1所示,主要分为3部分实现输电线路金具检测。首先,采用Swin Transformer 作为主干网络,并针对其计算量仍较大的问题,改进自注意力的计算方法,实现计算量更小、更高效的特征提取网络E-Swin;然后,为E-Swin主干网络设计自监督学习方法进行预训练,利用无标注图像重构的方式训练模型的特征提取能力,并设计轻量化解码器和平滑损失函数,以提高自监督学习的效率。自监督学习完成后,将E-Swin 作为检测模型的主干网络;最后,为了提高整个模型的性能、使模型能够输出更贴合目标的检测框,在主干网络基础上结合多尺度金字塔模块和高性能检测头,构建检测模型。在检测头部分添加分类和回归分支以外的交并比预测分支,对非极大值抑制(non-maximum suppression,NMS)分数利用预测框进行限制,使检测框更贴合目标。搭建模型后,在自监督训练的基础上,利用少量标注数据进行有监督微调训练,实现对应目标的检测。

图1 本文模型的实现过程Fig.1 The implementation process of our model
1.1 高效主干网络E-Swin
Swin Transformer 采用滑动窗口的策略提高Transformer 自注意力计算的效率。其他提高计算效率的方法则不采用局部窗口,直接将计算目标进行下采样,例如Wang 等人(2021)所提出的PVT(pyramid vision Transformer)模 型,以 及Zhang 和Yang(2021)所提出的ResT(residual efficient Transformer)模型等。本文利用ResTv2(residual efficient Transformer version2)(Zhang 和Yang,2022)的思想对Swin的计算模块进行改进,提出一种高效局部自注意力的主干网络E-Swin,减少冗余的计算量。
在Swin Transformer 中,输入特征图划分为不重叠的窗口,在每个窗口内独立计算自注意力,然后利用窗口的移位,计算窗口间自注意力,减少了计算量,同时通过特征图下采样,构建多尺度主干网络,使其更适用于检测和分割等下游任务。通过将注意力的计算限制在不重叠的窗口内,提高了计算效率。但其在窗口内仍采用标准的Transformer自注意力计算方式,对于有较多冗余信息的图像而言,计算量仍然稍大,计算式为
式中,Q,K,V为查询向量,dk是多头注意力的维度。自注意力计算的主要计算复杂度来源于Q,K,V 交互时的大量矩阵乘法运算。
在E-Swin 主干网络的自注意力计算中,仍采用滑动窗口进行局部划分。在局部窗口中,通过对K、V 进行下采样,有效减少矩阵相乘的计算量。同时,为了在减少计算量的基础上不丢失有效信息,对V进行上采样以重建信息。计算方式如图2所示。
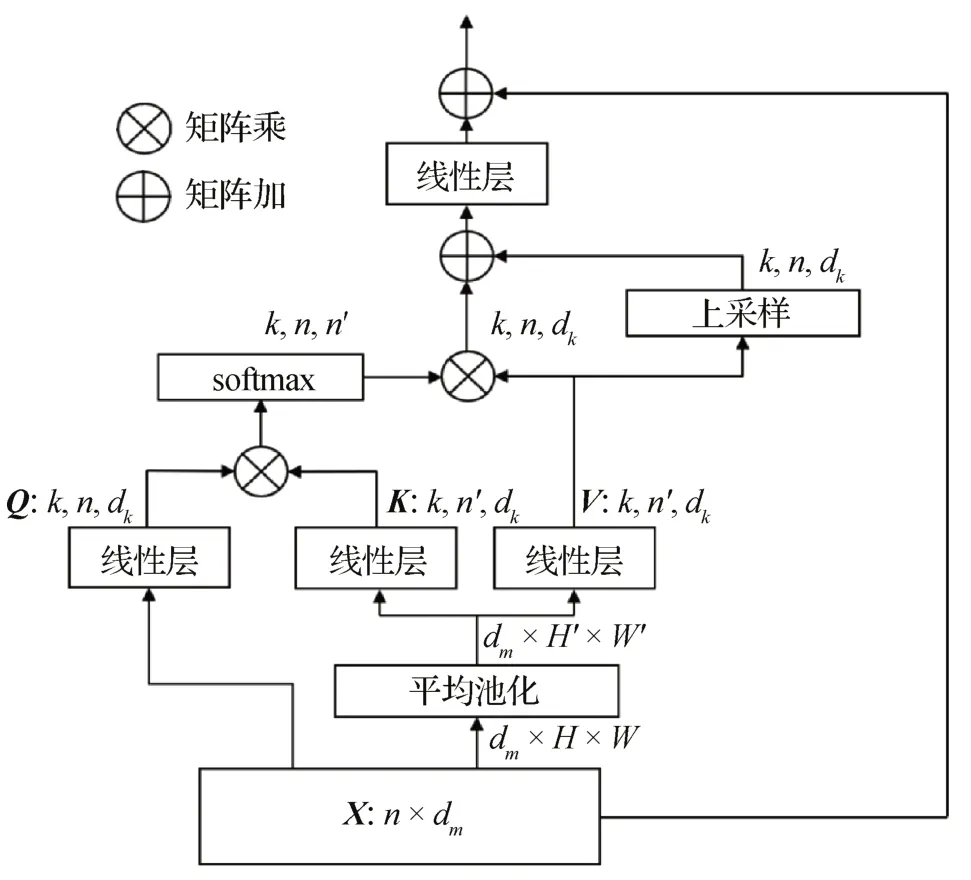
图2 改进后的自注意力计算过程Fig.2 Process of improved self-attention calculation
首先,与原始的多头自注意力计算类似,采用一组线性投影层将输入X∈转化为查询Q,其尺寸为(k,n,dk),其中n代表特征的空间维度,即特征图的大小为H×W,H、W为特征图的长、宽,dm代表输入通道数,k代表线性层(即头部)的个数,dk=dm/k代表头部的维度。而对于K和V,则采取不同的获得方式。先将X 重塑为二维特征图,其尺度为(dm,H,W),再利用一个尺度为s×s的平均池化层进行下采样,减少后续计算量,并使模型关注特征图中轮廓特征的有效信息。下采样后的特征尺寸得到缩减,为(dm,H′,W′),再经过线性投影层转换得到K和V,其尺寸为(k,n′,dk),n′=H′×W′。然后进行常规矩阵计算,不同图像块的Q 和K 进行交互,再与对应的V 相乘。改进后,在局部窗口的Q、K、V 交互中,计算复杂度为而在不进行下采样的原始计算中,计算复杂度为O(2n2dm+)。在取s>1 时,下采样可有效减少计算复杂度。
虽然下采样可以显著减少计算成本,但也将不可避免地丢失一部分特征信息。为了在实现高效计算的同时保证有效信息,在自注意力计算最后的线性层之前,对V值进行上采样,恢复为原尺寸,并加到计算结果上。计算方式采用像素洗牌(pixel shuffle),先扩大通道数,然后平均分配像素,达到上采样的效果。上采样分支可以高效地重建信息,并且几乎不增加计算复杂度。
本文在Swin Transformer 基于窗口的自注意力计算中,利用下采样减少计算量、提高网络对有效特征信息的提取能力。完成矩阵乘法计算后,在线性层前通过上采样的方式,重建下采样丢失的部分信息,构成高效的主干网络E-Swin。
1.2 轻量化平滑自监督学习方法
随着输电线路无人机巡检的广泛使用,收集到的图像数据也越来越多,对这些巡检数据进行人为标注会消耗大量资源。如何有效利用这部分无标注数据,成为近年来研究的一个新方向。
对上文提出的主干网络,本文采用自监督学习的方式进行预训练。自监督学习通过构建辅助任务,从大规模无标注数据中挖掘数据特征,并学习可以转移到下游任务的特征表示。MAE 方法设计图像重构辅助任务,对图像随机遮掩75%,再输入编码器和解码器中,并使输出结果重构原图,实现对普通ViT 主干网络的自监督训练。ViT 的全局性使得随机遮掩不会影响计算,但对Swin 这样的局部窗口网络而言,随机遮掩会导致每个局部窗口中的可见块数量不相等,妨碍了基于窗口的自注意力并行计算。
UM-MAE 方法是对MAE 的扩展,解决了MAE方法由于随机采样而无法用在多尺度主干网络上的问题。本文为了提高自监督学习效率,从解码器以及损失函数的角度进行优化,提出轻量化、平滑的自监督学习方法LS-UM(lightweight smooth uniform masking),用以训练前文所提出的E-Swin 主干网络,流程如图3所示。

图3 自监督学习流程Fig.3 Process of self-supervised learning
采用一种二次采样的方式,可以使MAE 方法适用于Swin 主干上。首先,对图像执行均匀采样,采样率为25%,即对每个2 × 2 的4 格单位采样1 格。类似于MAE,会有75%的图像块被遮蔽,并且不会输入编码器中,确保编码器的计算开销较小。同时,由于是均匀采样而不是随机采样,保证了在Swin 的每个局部窗口都能分配到等量的图像块,使移位窗口可以处理离散的图像块集合。然而,针对图像而言,利用周围的像素块可比较容易地推理出缺失部分的图像,所以相比于随机采样,均匀采样会降低辅助任务难度,导致学习质量下降。对此,在均匀采样的基础上进行二次遮蔽,将第1 步采样得到的图像块遮蔽小部分,并利用共享的掩码令牌表示。第2次采样所产生的掩码令牌仍会输入编码器,所以第2 次采样不会改变输入编码器的图像块数量,保证局部窗口的注意力计算不会受到影响。利用第2 次采样恢复了图像重构辅助任务的难度,使网络将重点放在学习图像的高质量表示上。
在本文训练流程中,图像在经过二次采样之后,以原图25%的比例输入编码器。编码器采用上文所提出的E-Swin 主干网络,提取图像的特征。经过编码器后,得到图像的特征表示,并利用上采样恢复尺寸。然后,将第1 次采样所遮蔽的75%图像块用一个可学习的向量表示,并与编码器所得到的特征表示一起输入解码器。解码器采用轻量化的单层Transformer 解码器,加上一个线性预测层构成,使输出重构原图像。利用图像重构的方式训练编码器的特征提取能力。自监督训练的损失利用预测得到的像素值和原本像素值进行计算,平滑损失函数计算为
式中,x代表预测值与真实值之差。平滑损失是结合了平均绝对值误差和均方误差的优化损失函数。平均绝对值误差损失的导数为常数,在训练后期预测值与真实值差异较小时不够平滑,导致损失函数在稳定值附近浮动,模型难以收敛。均方误差在x较小时比较平滑,但在训练初期预测值与真实值差异较大时梯度较大,导致部分离群点梯度爆炸,训练不稳定。平滑损失函数进行区间划分,综合这两种损失函数,有助于训练的稳定。LS-UM 方法通过设计轻量化的单层解码器和平滑的损失函数,提高了自监督学习的效率。
利用输电线路巡检图像,完成图像重构的自监督学习后,作为编码器的主干网络已经学习到了相应的图像特征表示。保留编码器作为目标检测模型的主干,构建检测模型,再利用少量有标注数据进行微调训练,即可完成自监督学习到下游任务的迁移。
1.3 结合交并比预测的检测头
基于上述内容,本文用自监督学习后的主干网络构建检测模型。为了简化计算并提高推理速度,采用一阶段目标检测模型RetinaNet(Lin 等,2017)的基本结构作为参考,并做改进。
在主干网络特征提取后采用特征金字塔模块进行多尺度特征融合。语义信息主要集中在主干网络所提取的高层特征图上,而位置信息则集中在底层特征图上。本文采用路径聚合特征金字塔(path aggregation feature pyramid network,PAFPN)(Liu 等,2018)结构,该结构在特征金字塔的基础上增加了自底向上的采样路径,通过反复采样以及结合堆叠,有效融合不同特征层的信息。
经特征融合后,将得到的信息输入最后的预测器,进行分类和回归预测,得到图像中目标类别和边界框的预测结果。但对不同尺度的输电线路金具而言,易出现边界框质量较差的问题。由于预测器中分类分支和回归分支缺少关联,导致质量较好的边界框可能遭到抑制。在非极大值抑制过程中,一个预测目标只会输出一组分类结果和边界框,所有针对该目标的预测都会按照分类得分降序排列,分类得分最高的预测框会抑制与它自身重叠程度高于一定阈值的其他预测框。但这默认采用了分类得分最高的预测框作为边界框,而没有考虑分类得分稍低、但预测框更接近真实框的样本,如图4 所示。图4中,浅色框代表真实框,深色框1和2代表两个预测。预测框1 的分类得分为0.9、与真实框的交并比为85%,预测框2 的分类得分为0.87、与真实框的交并比为90%。预测框2 更加贴近真实框,但它在NMS过程中由于与分类准确度更高的预测框1 的重叠超过阈值而被其所抑制。Tian等人(2019)利用中心距离(centerness 分支)改善此问题。添加额外分支预测真实框和预测中心点间的归一化距离,限制NMS得分计算,降低离真实框较远预测框的权重,过滤了部分较差的预测框。但此方法并未考虑预测框与真实框的交并比,交并比可更好地反映预测框和真实框之间的相关程度(Wu等,2020)。

图4 预测框的选择问题Fig.4 Problems of selecting prediction box
本文在分类和回归分支外,添加额外分支用于预测真实框和预测框的交并比。检测头结构如图5所示,其中,h,w代表输入特征层尺寸,N代表类别数,A代表预测锚框数。
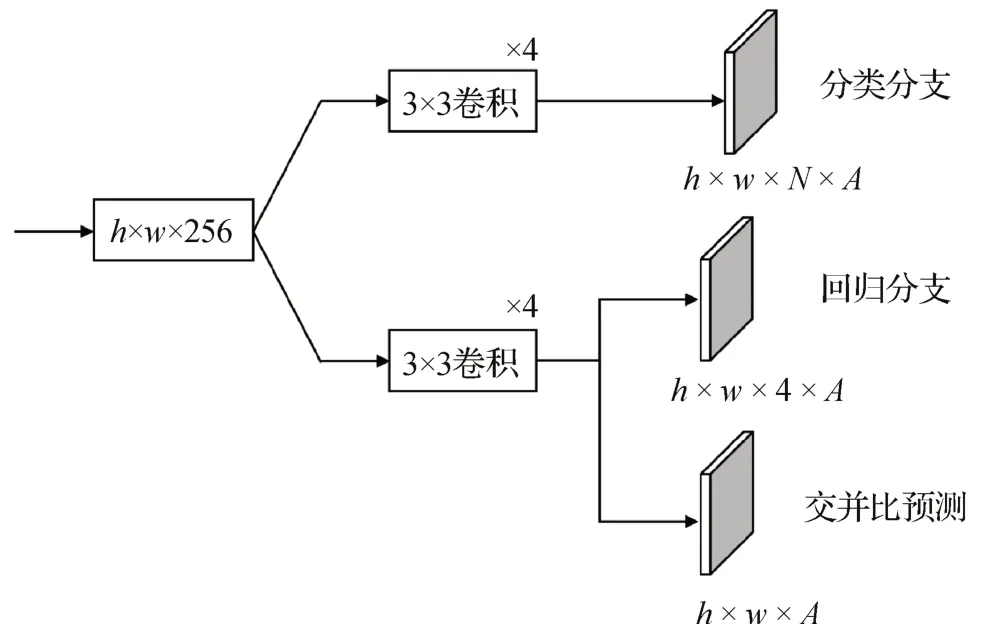
图5 检测头的结构Fig.5 Composition of the detector head
交并比检测头用于预测每个回归边界框和真实框之间的交并比,与回归分支平行连接到原分支的最后一层。在训练过程中,交并比预测部分和分类及回归预测部分联合训练。在推理的NMS 过程中,将每个检测框的分类分数和预测交并比相乘以获得置信度分数并依此排序。检测置信度由此可结合分类准确度和定位精度,提高边界框的定位准确率。
在训练过程中,分类损失采用RetinaNet 中的焦点损失(focal loss),该损失通过调节训练过程中困难样本的权重,将重心聚焦在困难样本上,用Lcls表示所有正、负样本的分类损失。回归损失采用DIoU(distance-IoU)(Zheng 等,2020)损失,综合考虑回归框的重叠区域、中心距离两个因素,用Lreg表示所有正样本的预测框和真实框之间的回归损失。交并比预测分支单独采用二进制交叉熵损失函数(binary crossentropy loss,BCE Loss),用于计算预测交并比和真实交并比的损失,Liou具体为
式中,Npos表示所有正样本的个数,IoU′i表示每个边界框与真实框的预测交并比,IoUi表示该框与真实框的实际交并比,利用二进制交叉熵损失函数进行训练。利用交并比预测损失和回归损失共同训练回归分支,提高检测的定位精度。总训练损失Ltrain为
推理过程中,将分类分数乘上对应检测框的预测交并比,得到用于非极大值抑制的排序得分。由此,置信度排序可同时结合分类分数及定位精度,提高分类和回归的相关性,使预测框定位更加精确。
2 实验结果与分析
2.1 输电线路金具数据集
本文的实验数据图像由输电线路无人机巡检拍摄得到,采用两个输电线路金具数据集对模型进行训练和评估。其一包含用于自监督学习的大量无标注数据;其二包含用于微调训练的有标注数据,包括约1 600 幅图像,按4∶1 划分为训练集和测试集。样本包括12 类金具,总共的标注目标为10 178 个,数据集示例图如图6所示,类别构成如表1所示。

表1 数据集构成Table 1 Composition of the dataset

图6 数据集示例Fig.6 Dataset examples((a)example 1;(b)example 2)
2.2 实验设置
本文实验采用Pytorch 框架实现,使用NVIDIA RTX3090 GPU 进行训练和推理测试,并对比不同的一阶段和二阶段目标检测模型。训练时,对输入图像进行随机剪裁和随机翻转做数据增强。在自监督预训练中,为了适配网络,将图像调整为256 × 256像素,学习率设置为0.001,进行1 600 轮图像重构的自监督训练,提升主干网络的特征提取能力。然后,将主干网络组建为RetinaNet 形式的一阶段检测模型,利用有标注数据进行微调训练,输入图像尺寸设置为1 024 × 1 024 像素,以适用于需要更高分辨率的目标检测任务,学习率设置为0.000 1,权重衰减为0.05,NMS的阈值设置为0.6。
2.3 对比实验
为了验证本文所提出模型的性能,将本文模型与RetinaNet、SSD、Faster R-CNN、YOLOv4(you only look once version4)(Bochkovskiy 等,2020)、Swin Transformer、DETR(detection Transformer)(Carion等,2020)等先进模型在有标注金具检测数据集上进行对比实验。采用各类平均精确度(average precision,AP)为评价指标。AP50、AP75在计算时选取预测框和真实框IoU 大于0.5 和0.75 的正样本,而AP50~95表示IoU 取值在0.5 到0.95 上的平均精度均值(mean average precision,mAP)。AP50在数值上更直观展示模型效果,而AP50~95则更具总体性。
表2展示了本文模型和普通一阶段RetinaNet模型在每一类检测目标上的检测结果。为了获得较全面的模型对比效果,表2 所示的指标为AP50~95。可以看出,本文模型对大部分金具的检测准确率提升在10%左右。对于屏蔽环、均压环、防震锤、U 型挂环等有明显轮廓特征和分布位置特征的金具,准确率提升更高。自监督学习增强了模型的特征提取能力,因此这类特征明显的样本有较显著的精度提升。对于并沟线夹和楔形线夹这类在数据集中出现次数较少的目标,其检测准确率也获得了较大提高,而样本同样较少的预绞式悬垂线夹准确率相对较低,在训练和测试样本分配上还有待改进。总体而言,相较于普通一阶段模型RetinaNet,本文模型对金具目标的检测准确率有较大提升。与其余模型的对比实验结果如表3 所示。可以看出,本文模型的检测效果相对其他模型有明显提升。其中Swin-T为普通的Swin 网络所构建的一阶段目标检测模型Swin-Tiny,未采用本文所提出的几种优化方法。Swin-T 的AP50~95指标为54.8%,本文模型为58.2%,提升了3.4%。同时,本文模型的AP50指标能够达到88.6%,提升5.4%,相比于传统的二阶段模型Faster R-CNN 和一阶段模型YOLOv4,也有12%左右的准确度提升。AP50指标的提高较为直观地表明,本文模型的改进对检测效果有较大提升,基本超越了传统模型。

表2 各类金具检测结果对比Table 2 Comparison of test results of various fittings /%

表3 与其他检测模型性能对比Table 3 Performance comparison with other models /%
2.4 消融实验
为验证本文所提出的高效主干网络、自监督学习方法以及检测头模块的有效性,设计了消融实验进行对比。
2.4.1 高效主干网络
为了验证改进后自注意力计算的高效性,本文设计了一阶段Swin-T基线模型和E-Swin模型的对比实验。采用每秒浮点运算数(floating-point operations per second,FLOPs)衡量模型运算量,输入尺寸设置为(3,1 024,1 024)。结果如表4所示。由表4可以看出,采用高效的自注意力计算可使模型的AP50~95和AP50提高0.9%、1.4%,并且浮点运算减少了8.1 GFLOPs(giga floating-point operations per second)。E-Swin 的下采样使模型关注轮廓特征,同时,得益于对K和V进行的下采样,模型矩阵乘法的计算量减少、计算复杂度降低。对V的上采样重建了部分丢失的信息,与矩阵乘法计算结果相加,使改进后模型的准确率略微上升。

表4 改进主干网络对结果的影响Table 4 The influence of improved backbone on results
2.4.2 自监督学习
为了验证自监督学习方法对本文模型的有效性,设计了不同的对比实验。表5 展示了使用Sim-MIM、UM-MAE 和本文提出的LS-UM 等3 种自监督学习方法对主干网络进行预训练并与普通Swin-T模型的对比结果。表5 中比较的指标包括不同自监督方式在不同训练轮次情况下的预训练时间和损失,以及在完成自监督学习和有监督微调训练之后的检测精度。精度指标采用较严格的AP50~95。

表5 不同自监督学习方式性能对比Table 5 Performance comparison of different self-supervised learning methods
由表5 可以看出,在针对Swin 主干网络的自监督预训练过程中,由于UM-MAE 的编码器只处理未被遮掩的图像块,即整个图像的25%,而SimMIM 将图像块全部处理,所以UM-MAE 的训练时间明显减少,大幅提升了效率,且最终精度提升约2%。而当预训练轮次从800 轮上升到1 600 轮时,虽然图像重构的损失并没有下降太多,但最终微调的精度有略微上升,说明了自监督学习可以充分挖掘图像的特征表达,并有继续提高特征提取能力的潜力。
另外,本文将UM-MAE 和优化后的LS-UM 方法进行对比,在1 600 轮预训练后进行微调训练,其对比效果如表5 所示。可以看出,得益于轻量化的解码器及平滑的损失函数,LS-UM 的损失以及预训练所需时间得以减小,收敛更快,最终的有监督微调效果也有0.3%的精度提升。
最后,为了比较使用不同无标注数据进行自监督学习的效果,本文设计了在LS-UM 方法下,利用无标签金具数据和ImageNet-1K 数据集做自监督学习的对比实验,以展示不同数据集对最终结果的影响,结果如表6所示。

表6 不同自监督数据集效果对比Table 6 Comparison of different self-supervised datasets
由表6 可以看出,采用ImageNet-1K 进行自监督预训练所需时间远大于使用无标注金具数据的时间。ImageNet-1K 的数据量太大,但得益于庞大的数据量,主干网络的特征提取能力得到了有效训练,其完成自监督学习后的微调训练也只需更少轮次。采用无标注金具数据做预训练时,所需微调轮次则相对较多。主要原因在于无标注数据的数量和质量上。金具数据的数量远不及ImageNet-1K,且数据中有效信息较少而背景冗余信息较多,导致其在自监督学习中提升的特征提取能力不大,微调时需更多时间。不过,使用金具数据做自监督学习可以使主干网络在特定任务上具有一定优势,最终微调精度提高0.4%,且自监督学习时间大幅减少,效率更高。
2.4.3 高精度检测头
为验证所提出的检测头对检测精度的影响,针对Swin-T主干构建了不同的模型,并进行对比实验,实验结果如表7 所示,其中,除Swin-T(二阶段)外均为一阶段模型。由表7 可以看出,用相同主干构建的二阶段模型,在未添加优化模块时,其性能较一阶段模型略有提升,但由于二阶段模型冗杂的计算处理方式,采用一阶段模型,训练和推理会更高效。对一阶段模型而言,额外分支采用centerness对边界框的选取进行限制,模型的AP50~95可以提升1.4%,AP50提升2.5%,且额外预测分支与回归分支并行训练,不需较多额外参数即可较明显地提升检测准确率。将额外分支改进为IoU 预测,可使检测效果进一步提升,AP50~95和AP50再提升1.3%和2.2%。在检测头中采用预测框与真实框的交并比作为边界框选择时的额外限制,检测精确度指标AP50为87.9%,模型在非极大抑制中能够选择更准确的预测框,使预测边界框更贴近真实框。

表7 改进检测头对检测结果的影响Table 7 Influence of improved detector head on detection results /%
2.5 可视化实验
为了更清晰地展示本文模型的改进对于金具检测效果的提升,设置了可视化实验展示结果。将巡检金具图像输入本文模型以及一阶段Swin-T 模型,对得到的检测结果进行对比分析,如图7 和图8所示。

图7 金具检测结果对比Fig.7 Comparison of fitting detection results((a)Swin-T;(b)ours)

图8 金具定位对比Fig.8 Comparison of fitting positioning((a)Swin-T;(b)ours)
图7 和图8 展示本文模型与一阶段Swin-T 模型部分检测结果的对比。如图7 所示,均压环、提包式悬垂线夹、U 型挂环等金具在一阶段Swin-T 模型的检测下均出现了漏检的情况。通过图7 中结果1、结果3、结果4 的对比可以看出,本文模型有效减少了漏检的情况,自监督学习有效把握了较为显著的各类金具特征。通过图中结果2 的对比可以看出,本文模型检测出了由于遮挡较为严重而易被漏检的线夹,在复杂遮挡环境下的检测准确率有所提高。
图8 展示了两种模型对检测框定位效果的对比。如图8(a)所示,当两个目标有相互重叠的部分时,普通模型对防震锤的定位出现了错误判断,仅识别到一个目标,并在另一个的干扰下得到了不精确的预测框;而在图8(b)中,本文模型的预测结果识别出了前后两个防震锤,并且预测框贴近实际目标,定位效果明显提升,检测更加准确。
3 结论
针对输电线路巡检所产生的无标注数据无法有效利用,以及金具检测准确率较低的问题,本文提出了一种基于自监督E-Swin 的金具检测模型。主要贡献如下:1)提出高效的E-Swin 主干网络,通过改进Swin 自注意力的计算方式,实现计算时间更短、更高效的特征提取。2)为了有效利用大量巡检数据,采用轻量化的平滑自监督学习方式LS-UM 预训练主干网络。通过图像重构辅助任务,挖掘大量无标注数据中的特征表示,从而提升主干网络的特征提取能力。3)构建高精度金具检测模型,利用增加额外分支的检测头,实现更加准确的边界框预测。实验表明,本文所提出的模型在金具检测上的表现优于主流模型。
本文同样存在一些需要解决的问题。自监督学习需利用大量的数据进行特征表达的学习,本文暂未收集到ImageNet-1K量级的数据,所以后续微调训练需要更久的时间。同时,输电线路航拍图像存在大量背景等冗余信息,目标信息分布不集中,不利于自监督学习的进行。为此,需对用于自监督学习的数据进行额外处理,例如结合生成对抗网络,进行额外的数据增强预处理等(黄鐄 等,2019),这也是下一步的研究方向。
