基于OTSU 图像分割算法的碎米检测
2023-10-24陈浩然范方辉牟天
陈浩然,范方辉,牟天
(1.深圳大学 化学与环境工程学院食品科学与工程系,广东 深圳 518060;2.深圳市食品大分子科学与加工重点实验室,广东 深圳 518060;3.深圳大学 医学部 生物医学工程学院,广东 深圳 518060)
我国是当今世界上大米产量和消耗量最高的国家[1],随着我国居民生活质量的提高,人们对大米的品质要求也逐渐提高。大米中碎米的含量是评估大米质量的重要指标,由于碎米与水的接触面积更大,碎米含量高的大米吸水率更高且碎米断面的淀粉更易溶于水中,因此米饭中的碎米含量增加会导致米饭的食味变差,米饭的咀嚼性和弹性也会随之下降[2]。掺杂较多碎米的大米口感与味道难以达到消费者的要求,因此大米的生产厂家会进一步追求有更高碎米筛分效率的方法以提高大米品质与销量。而且,筛分出来的碎米还能制成米粉、果葡糖浆、蛋白粉等副产物[3],可以提高大米资源的利用率与厂家的经济效益。因此,将大米中的碎米筛分出来变得尤为重要。在传统的碎米检测中,机械筛分是将碎米分离的主要方法,主要使用的机械筛分设备有分级平转筛和滚筒机[4]。传统的机械筛分技术需要大量的人力和物力资源,并且效率较低,筛分准确性也不高。大米的机械筛分效率最高能达到70%左右[5],而对于大米生产厂家,更高的筛分效率以及碎米的快速分离具有重要意义,因为这可以减少生产成本,提高产品质量。
近年来,基于图像分析算法构建的计算机视觉技术(computer vision technology,CV)在食品和农产品检测领域得到广泛应用。Zhang 等[6]提出了一种基于亮度自动校正和加权相关向量机(relevance vector machine,RVM)分类器的苹果缺陷检测算法。Patel 等[7]开发了一种算法,能够采用单色CV 系统检测芒果果实表面的各类缺陷。随着计算机视觉技术的发展,基于图像处理的碎米检测技术逐渐受到关注。这些技术通常使用数字图像处理算法和机器学习算法来实现快速、自动化的碎米检测。例如,Van Dalen[8]将平板滤波与图像分析相结合,检测了大米的面积、分布以及碎米的数量。Sharma 等[9]以色度学理论为基础,提取了碾米图像的颜色特征,并将碾米分为了微黄色、浅黄色、黄色和极黄色4 类。Zapotoczny 等[10]提出了利用图像算法与大麦籽粒的形态特征实现对大麦籽粒品种进行区分的方法。周显青等[11]提取了图像中大米的长轴、短轴、周长和面积4 个特征,并研究了4 个特征各自与碎米筛分效果的相关性。林萍等[12]将可见光谱与人工神经网络模型相结合,实现了对大米中垩白米粒的识别。尽管计算机视觉技术在碎米筛分中已经有了一定应用,有关核心算法的研究仍处于初级阶段。
图像分割(image segmentation)是图像处理和建立筛分算法的重要环节,目前有很多种图像分割算法,在大米图像及其他领域的图像上均有应用。基于区域的图像分割方法可以将图像分成具有相似特征的区域,特征可以是灰度值、颜色、形态等,孙金风等[13]通过区域分割算法提取出了图像中的网球轮廓。还有基于边缘的图像分割方法,该方法通过检测图像中的边缘来实现图像分割,于建宁[14]使用边缘分割的方法将图像中粘连的大米分割出来。此外,还有基于聚类的图像分割方法,该方法将图像中的像素分成不同的群组,使得每个群组内的像素具有相似的特征,Wu 等[15]使用K 均值(K-means)聚类算法实现了对麦芽糖晶体图像的分割。大津法(maximal variance between clusters,OTSU)又被称为最大类间方差法,是日本科学家大津展之提出的利用图像直方图选取全局阈值的一种算法[16-17]。OTSU 算法是一种常见的基于阈值的图像分割方法,该算法通过寻找最佳阈值,将图像分为背景和前景两部分,其优点是简单易懂、计算速度快,适用于大多数图像分割问题。因此,OTSU 算法在图像分割中得到了广泛的应用。吕婧等[18]将优化的OTSU 算法用于大米图像的分割,并且比较了优化的算法与原OTSU 算法的分割效率。戴天虹等[19]使用OTSU 算法得到清晰、连贯的木材缺陷图像,而金立军等[20]使用OTSU算法分割图像的背景用于后续输电线路异物识别。
本文针对碎米、整米筛分不够高效、准确的问题,借助OTSU 算法与逻辑回归模型,建立碎米检测算法,对3 种大米的碎米、整米进行筛分并与国标方法进行对比研究。本文所建立的方法具有广阔应用前景,以期为解决高效筛分大米中碎米、整米的问题提供理论依据。
1 材料与方法
1.1 试验材料
吉林小町香米(5 kg):沃尔玛(中国)投资有限公司;泰国香米(500 g):深圳盛宝联合谷物股份有限公司;五常大米(500 g):五常市旺达米业有限公司。
1.2 试验设备
HONOR 60 手机(14.0.1.430 版本):深圳市智信新信息技术有限公司;支架(带有环形灯、固定夹):徕兹光电科技(宁波)有限公司。
1.3 图像采集
将3 种米分别按全碎米、全整米以及整米与碎米的粒数比为1∶4、2∶3、3∶2、4∶1 4 个不同比例组进行图像采集,每组共50 粒米,总共采集900 粒米的图像。手机距离样品36 cm,以30 cm×30 cm 的黑色反光亚克力板为图像背景,拍摄图像时手机相机放大倍数1.8,拍摄条件:感光度(international organization for standardization,ISO)为160,快门速度为1/160 s。示意图见图1。
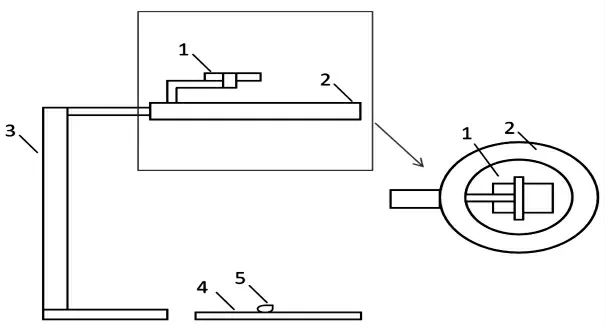
图1 大米图像采集的计算机视觉设备示意图Fig.1 Computer vision equipment used for rice image acquisition
设定好拍摄条件,保持手机与背景板的距离不变,对3 种大米进行拍摄,将大米按粒数比置于背景板上,点击上方被支架固定手机的拍摄键采集图像。得到图像后要对原始图像进行处理,使用Win 11 的画图软件将原始图像中大米部分的图像统一裁成分辨率为1 935 pixel×1 935 pixel 的图像,方便后续统一处理。图2 为输入算法中运算的大米样本图像之一,环形的亮圈是灯在背景板上的映射,后续要通过算法当作背景一同去除,其余图像与此类似,均在后续流程中做样本图像输入算法中运行。

图2 整米图像Fig.2 Images of head rice
试验将几种米得到的特征参数以及对应的标签数据混合起来,利用逻辑回归的方法进行分析,达到将每种米各自的碎米与整米区分开来的目的,并将其与国家标准仅通过长度区分碎米、整米的方法进行比较,试验的流程如图3 所示。
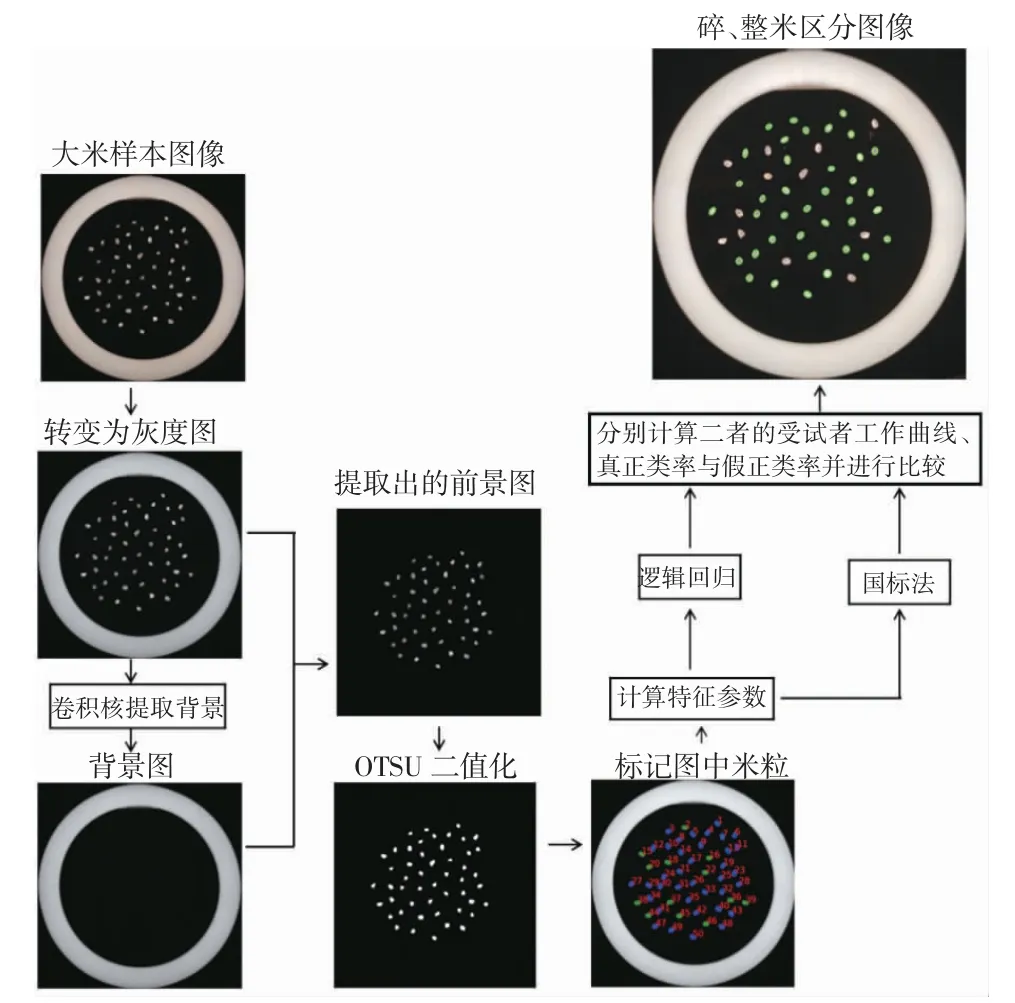
图3 基于OTSU 算法的碎米筛分过程示意图Fig.3 Broken rice screening process based on OTSU algorithm
1.4 图像分割
图4a~c 为读入样本图像的灰度图,目的是简化图像信息,减小代码处理的难度。然后,通过十字形卷积核提取出图像中的背景部分,得到如图4d~f。再用灰度图减去提取得到的背景图就可以得到如图4g~i 的大米前景图,光照的差异会影响后续的分割过程,这一步可以减小不均匀光照以及光斑的影响[21]。

图4 灰度图像、背景灰度图、前景米粒灰度图以及二值化图像Fig.4 Grayscale image,background grayscale image,foreground rice grain grayscale image,and binary image
前景灰度图需要进一步进行二值化处理,得到二值化图像。二值化可以将图像转变为只用0 与1 表示的二进制形式[22],而OTSU 二值化可以通过图像整体的直方图选择出阈值。将某一灰度值作为阈值,图像中小于阈值的点就是提取对象,而大于阈值的点则是需要去除的背景,而对象与背景会呈现双峰图像,OTSU 算法可以根据图像直方图计算出双峰图像的阈值[16-17,21],经过OTSU 算法处理后就能输出如图4j~l 的仅有0 值(黑色)和1 值(白色)的二值化图像。
1.5 特征提取
利用大米的二值化图像对输入的大米图像中的米粒进行标记。二值化图像上每一粒米就是一个独立的连通域,通过函数提取二值化图像上的连通域,可以返回连通域的数量、中心等信息,同时对每一个连通域附上标记,输出一个米粒带有标记的灰度图,标记图如图5a、c、e 所示。由于每粒大米都带有一个标记,因此可以根据标记对图像进行分割,提取出图像中的每一粒米,这一步对于计算每一粒米的特征十分重要。然后,利用循环语句将每粒米提取出来,计算每粒米的面积、长轴、短轴以及长短轴比4 个特征参数。米粒的长轴与短轴是通过拟合椭圆的方法得到的,先通过函数获得每粒米的边缘点集,再通过边缘点集进行椭圆拟合,椭圆的长轴作为米粒的长轴,而椭圆的短轴则作为米粒的短轴,图5b、d 和f 为拟合椭圆后得到的大米图像。拟合的椭圆还能够用于在图像上直观区分碎米与整米,通过改变椭圆的颜色,使碎米与整米拟合椭圆的颜色不同即可实现这一目的。将900 粒米的特征参数结合在一起,以.text 文本的格式输出,文本包括面积、长轴、短轴、长短轴比以及标签,此处的标签为0、1 标签,0 代表碎米,1 代表整米,标签对应米粒的真实情况。
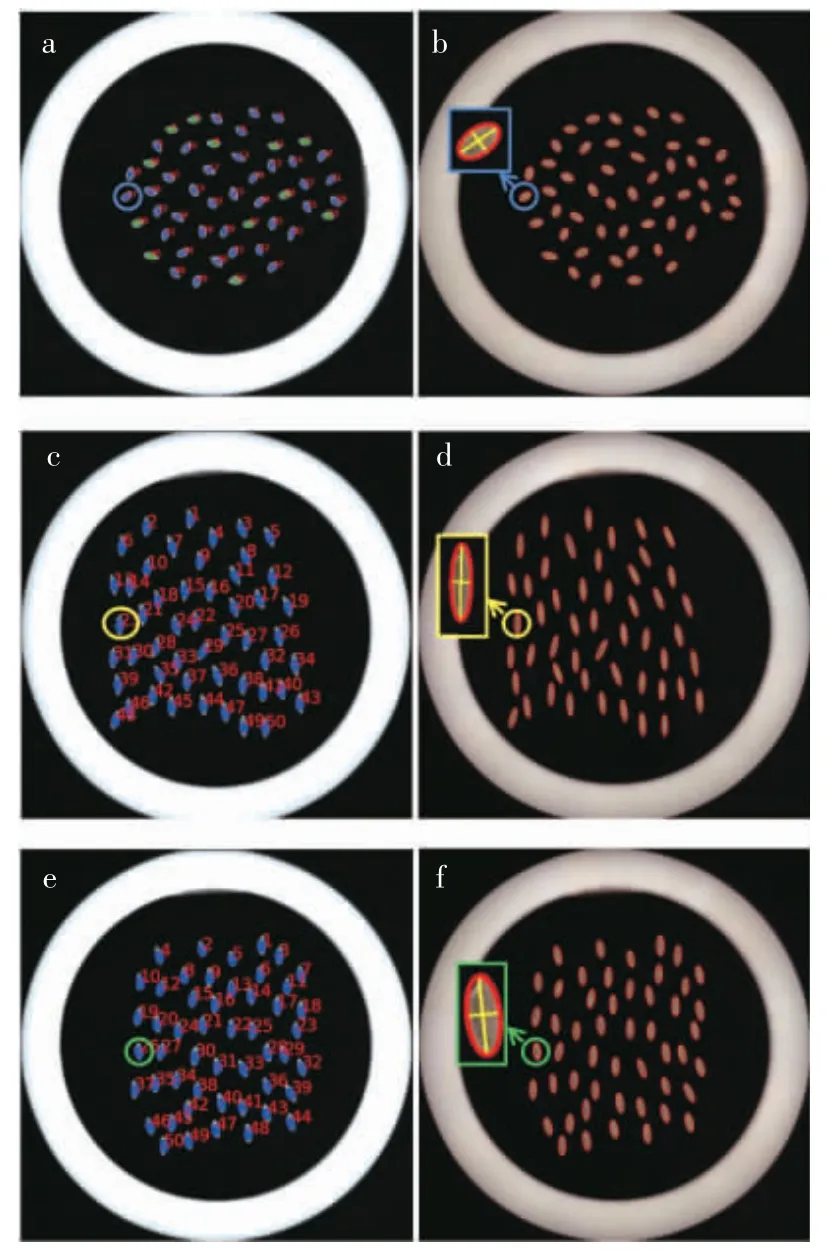
图5 标记图与拟合椭圆后的图像Fig.5 Marking diagram and image after fitting an ellipse
2 模型的建立与验证
2.1 数据处理
所有模型和算法均基于Python(3.10.7)与R 编程语言(4.2.0)在Win 11 环境下编写并测试。分别采用国标法和逻辑回归模型定性判别整米与碎米。
2.2 逻辑回归模型设计
逻辑回归模型是概率回归,是一种特殊的线性模型,可以用于预测概率与数据分类[23-24]。本文利用逻辑回归模型,以4 个特征变量来判断图像中的米粒是否为整米,属于二分类问题。
一般的线性模型假设因变量可由变量以线性函数的形式进行表达:z=θTx=θ0+θ1x1+θ2x2+…+θixi。(式中:T为对θ 向量的转置;θ 为权重系数,是模型经过训练后估计得到的参数;x 为变量,即大米的长轴、短轴、面积以及长短轴比4 个特征数值,每个变量都有对应的权重系数;i 为变量x 的第i 个变量。)
在逻辑回归模型中,线性函数采用的是sigmoid函数:hθ(x)=g(θTx)=1/[1+exp(-θTx)]=1/[1+exp(z)],式中:h(x)是概率,处在0~1 之间,每粒米都有其对应的概率,选取阈值进行判断,h(x)小于阈值的判断为0,即碎米;而h(x)大于阈值的则判断为1,即整米;z 为线性公式求得的函数值。
2.3 国标法分类
GB/T 1354—2018《大米》[25]中规定长度小于同批试样整米平均长度3/4 的米粒为碎米,可见国标主要通过长度来区别碎米与整米。将米粒长轴的像素单位转为毫米单位,统计得到3 种米(共900 粒)的长度为11~46 mm,判断阈值的区间为11~46,步长为2,通过国标法得到了19 组数据,以19 组数据作出柯尔莫可洛夫-斯米洛夫(Kolmogorov-Smirnov,KS)曲线与受试者工作特征(receiver operator characteristic,ROC)曲线,同时得到KS 值与曲线线下面积(area under the curve,AUC)值,将其与逻辑回归结果进行对比。
2.4 分类评价指标
利用混淆矩阵得到分类预测效能的各项定量指标(精确率、准确率、召回率、F1 分数等)。其中,真正类(true positive,TP)是米粒在真实中为整米,而在模型中被预测也是整米的数量;假正类(false positive,FP)是米粒在真实中为碎米,而在模型中被预测为整米的数量;假负类(false negative,FN)是米粒在真实中为整米,而在模型中被预测为碎米的数量;真负类(true negative,TN)则是米粒在真实中为碎米,而在模型中被预测也是碎米的数量。
使用准确率(accuracy)、精确率(precision)、召回率(recall)以及F1 分数(F1-score)4 个指标可以对模型进行标准化的衡量[26],其中F1 分数越接近1 代表输出的结果越好,可用于进行国标法与逻辑回归模型所得结果的对比。式(1)~(4)分别为准确率(A)、精确率(P)、召回率(R)以及F1-score(F)4 个指标的定义式。
式中:Z 为真正类数值;J 为假正类数值;N 为假负类数值;T 为真负类数值。
真正类率(true positive rate,TPR)与假正类率(false positive rate,FPR)的计算公式如式(5)、(6)所示。
式中:B 为真正类率;C 为假正类率。
每选择一个阈值就可以得到一组TPR 与FPR,不断的改变阈值可以得到多组的数据,本文将阈值从0取到1,步长为0.1,得到11 组数据。用阈值分别与TPR、FPR 作图,得到KS 曲线图,TPR 与FPR 两条曲线在同一阈值条件下相差最大的值为KS 值,KS 值处于0~1 之间,其越大表明区分程度越大;以TPR 与FPR作图,得到ROC 曲线图,计算x 轴与ROC 曲线间的面积则得到AUC 值,AUC 值越接近1 则表示模型越好。
3 结果与讨论
3.1 3 种米的特征参数
泰国香米、吉林小町香米与五常大米各有300 粒米,表1 是3 种米4 个特征参数的分布情况。

表1 3 种大米的面积、长轴、短轴以及长短轴比的分布情况Table 1 Distribution of area,long axis,short axis,and long-toshort axis ratio of three types of rice
由表1 可知,泰国香米最长,吉林小町香米最宽,五常大米的面积最大;按长短轴比数据来看,吉林小町香米的长轴与短轴最接近,说明吉林小町香米较短圆,而泰国香米的长短轴比数值较大,说明泰国香米是瘦长型的,五常大米处于二者之间,与图2 结果相一致。结果表明,特征参数与实际相符合,因此可以通过选取的4 个特征参数代表大米的实际形态用于逻辑回归分析以及碎米、整米的区分。
3.2 逻辑回归模型参数选择
将泰国香米、吉林小町香米以及五常大米得到的特征参数结合在一起,使用建立的逻辑回归模型处理大米的整体数据,考察逻辑回归方法对大米碎米、整米总体的区分效果。图6 为大米的长轴、面积、短轴、长短轴比的箱线图以及逻辑回归结果箱线图。

图6 3 种大米数据混合后得到的特征参数箱线图与逻辑回归结果箱线图Fig.6 Box plots of characteristic parameters and logistic regression results obtained from mixing three types of rice data
由图6a~d 可知,大米的碎米与整米在4 个特征参数上均有较大的重合部分,难以凭借单一的特征参数将碎米和整米很好地区分开;图6e 是大米特征参数经过步进法筛选出显著的影响变量,再经逻辑回归模型处理后得到的结果箱线图,通过筛选结果可以看出面积、长轴、短轴以及长短轴比均是显著的影响变量,在逻辑回归处理数据的过程中都显著影响到碎米、整米的区分结果,因此4 个特征参数的数据都要保留并在逻辑回归中使用。
大米数据经过逻辑回归处理后,得到了4 个特征参数对应的权重系数,长轴、面积、短轴以及长短轴比对应的权重系数分别是-5.35(θ1)、10.93(θ2)、2.86(θ3)和34.59(θ4),θ0的值为-139.97。同时,算法输出了一个.text 文本,其中是900 粒大米各自对应的概率值,由于经过了sigmoid 函数的处理,概率值均处于0~1 之间。
3.3 国标法与逻辑回归模型分类的对比
将逻辑回归模型输出得到的概率数值与阈值相比,得到大米的0、1 分布结果。逻辑回归模型输出的结果在不同阈值条件下,通过混淆矩阵计算得到的TPR与FPR 数值,总共有11 组TPR 与FPR 值,绘制出逻辑回归方法的KS 曲线和ROC 曲线。绘制得到的KS曲线与ROC 曲线如图7 所示。
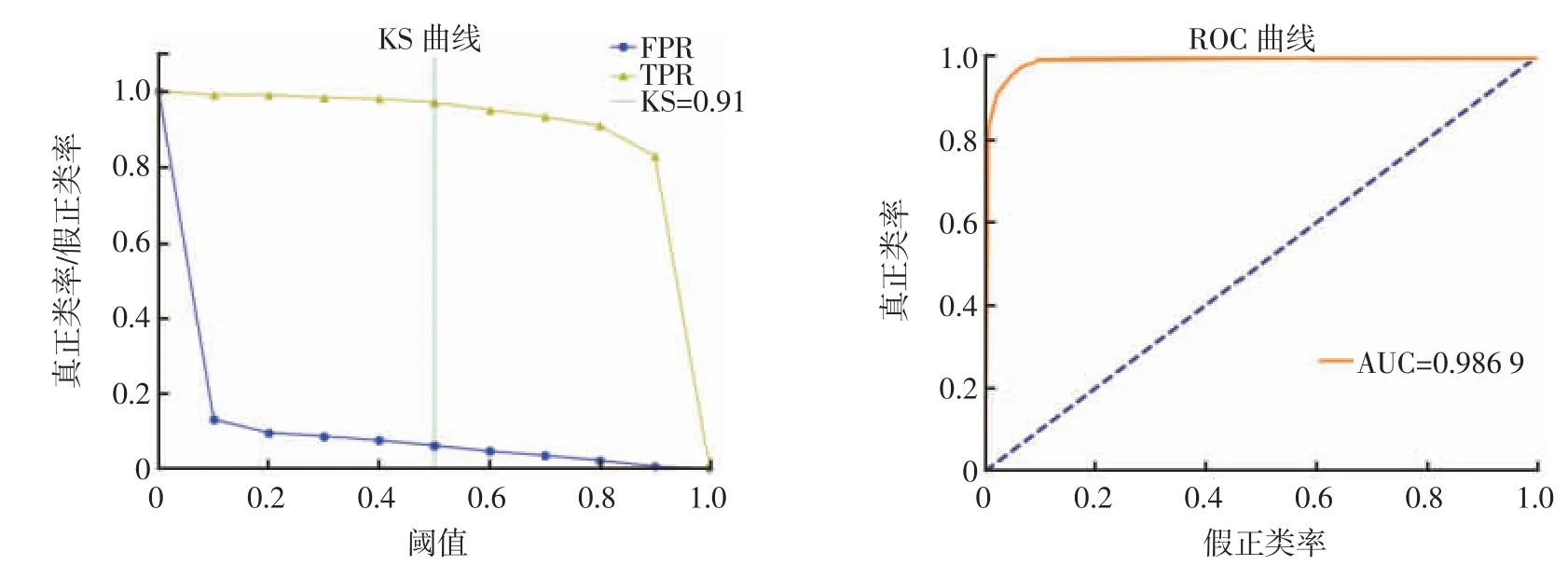
图7 逻辑回归模型的KS 曲线和ROC 曲线Fig.7 KS curve and ROC curve of logistic regression model
由图7 可知,KS 曲线图是以阈值为横坐标,TPR或FPR 值为纵坐标绘制的曲线图,TPR 曲线与FPR 曲线在阈值为0.5 时相差最大,因此KS=max(TPR-FPR)=0.909,即阈值为0.5 时,建立的逻辑回归方法对碎米与整米的区分效果最好。ROC 曲线是以FPR 值为横坐标,TPR 值为纵坐标绘制的曲线图,计算ROC 曲线的线下面积,得到逻辑回归方法的AUC 值为0.986 9,与1 非常接近,说明逻辑回归方法预测效果较好,对大米的碎米、整米区分有效果。
通过国标法运算处理大米数据同样能得到19 组FPR 与TPR 数据,绘制的KS 曲线与ROC 曲线如图8所示。
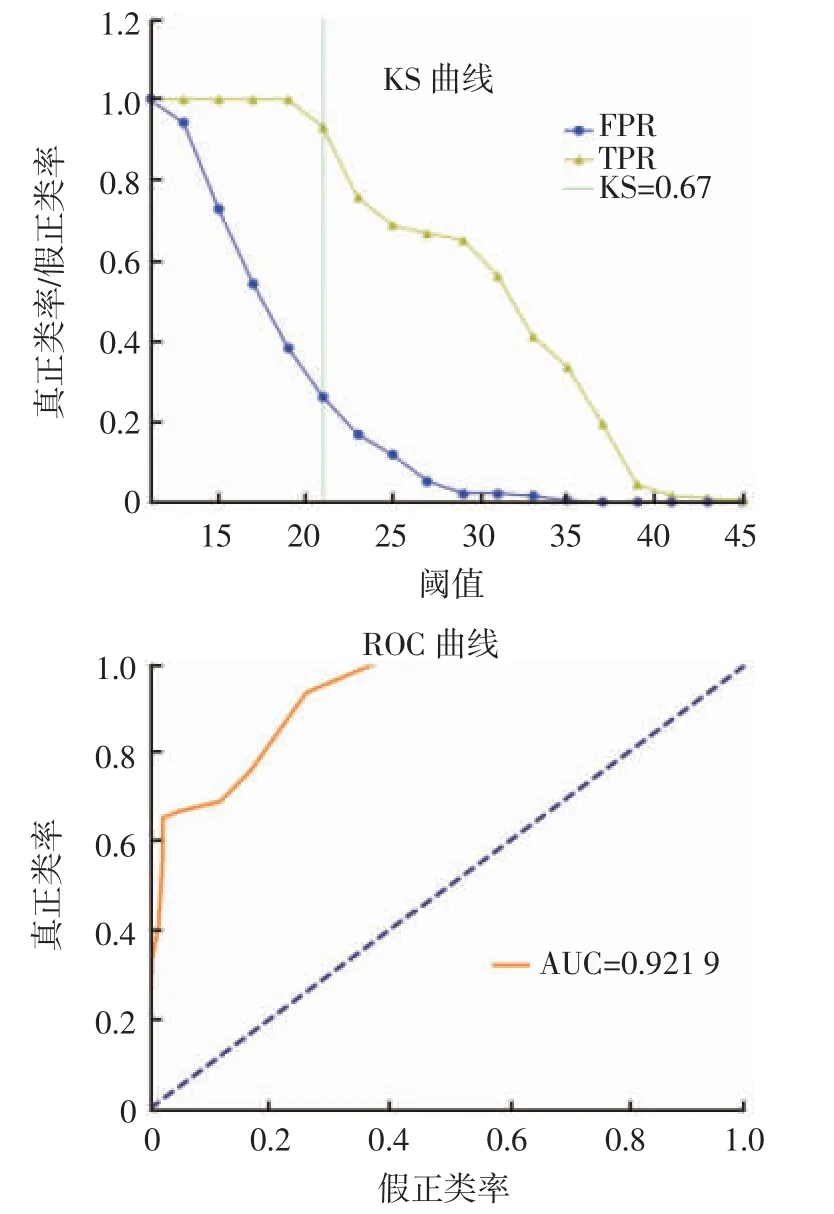
图8 国标法的KS 曲线和ROC 曲线Fig.8 KS curve and ROC curve of national standard method
由图8 可知,在阈值为21 时,TPR 曲线与FPR 曲线相差最大,KS=0.669;计算ROC 曲线的线下面积,得到国标法的AUC 值为0.921 9。
表2 为在最优阈值时,国标法和逻辑回归模型所得结果的4 个指标(准确率、精确率、召回率以及F1分数)。

表2 国标法与逻辑回归法的对比Table 2 Comparison between national standard method and logistic regression method
由表2 可知,逻辑回归模型的准确率、精确率和召回率都高于国标法,且逻辑回归模型的F1 分数更接近1,证明逻辑回归模型输出的结果更好,对碎米、整米区分效果优于国标法。将国标法与逻辑回归法得到的AUC 值以及在最佳阈值下的KS 值进行比较,逻辑回归法得到的KS 值比国标法的KS 值大,且逻辑回归法的AUC 值更接近于1,说明逻辑回归方法对碎米与整米的区分效果更好,得到的结果要优于国标法,因此采用逻辑回归方法对碎米、整米进行区分。
3.4 图像体现碎米与整米区分结果
逻辑回归法最终筛分结果可以通过图像得到更直观的体现。逻辑回归法得到的全部大米的概率结果以最优阈值0.5 进行判断,得到一个0、1 分布的最优碎米、整米区分结果,再将整体的区分结果按原顺序分开成为3 种大米各比例的区分结果,以.text 文本形式输出。以3 种大米4∶1 比例这一组的图像为例,将得到的区分结果输入椭圆拟合的算法,将结果为0 的米粒的拟合椭圆改为绿色,结果为1 的米粒的拟合椭圆保持原来的颜色不变,输出区分图像,将区分结果通过图像进行直观体现,如图9 所示。
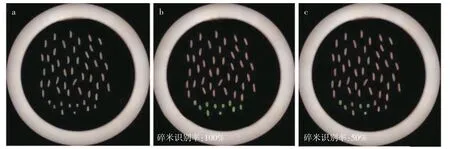
图9 原始图像、逻辑回归模型得到的碎米、整米区分图像以及国标法得到的碎米、整米区分图像Fig.9 Original image,broken rice and head rice images obtained from logistic regression model,and broken rice and head rice images obtained from national standard method
由图9 可知,绿色椭圆圈出的是碎米,红色椭圆圈出的是整米,区分图像可以体现出逻辑回归方法的效果较好。图9b 与原图像(图9a)进行对比可以看出,区分图中比例为4∶1 的50 粒泰国香米中10 粒碎米与40粒整米完全区分开。图9d、e 对比可知,4∶1 的50 粒五常大米中的10 粒碎米与40 粒整米也完全区分开。图9g、h 对比可知,50 粒吉林小町香米区分得到碎米有13 粒,整米37 粒,有3 粒整米被划分为了碎米,这表明建立的逻辑回归模型不能完全区分开碎米与整米,存在一定的误差。图9c、f、i 是由国标法得到的碎米与整米区分图像,50 粒泰国香米中的10 粒碎米只有5粒被识别出来,50 粒五常大米中的10 粒碎米只有8 粒被识别出来,还有1 粒整米被识别成了碎米;而50粒吉林小町香米中10 粒碎米都识别了出来,但是有7 粒整米被识别为了碎米。通过图像可以清晰地对比2 种方法的筛分效率,逻辑回归模型得到的筛分效果明显优于国标法的筛分效果。
4 结论
本文使用了逻辑回归模型对大米数据进行分析,通过对3 种大米各6 组图像进行碎米与整米筛分,发现使用逻辑回归法可以比国标法更好地区分碎米与整米。通过绘制KS 曲线与ROC 曲线,得到逻辑回归模型的AUC 值为0.987、KS 值为0.909,KS 值对应的阈值0.5 为最佳阈值。在阈值为0.5 时,长轴(x1)、面积(x2)、短轴(x3)与长短轴比(x4)四个特征参数都作为变量时逻辑回归方法的效果达到最优,对应的线性关系为z=-139.97-5.35x1+10.93x2+2.86x3+34.59x4。将逻辑回归方法输出的结果与图像相结合,可以得到更直观的碎米、整米区分图像。在未来的研究中可将建立的模型与机械臂相结合,通过机械臂挑取区分出的碎米,实现通过人工智能方法进行自动化、低成本的碎米快速检测与筛分。此模型还可以运用到水果、蔬菜等其他食品的筛分与分级中,具有较大的应用潜力。
