用于图像分类的深度卷积神经网络中的空间分割注意力模块
2023-10-24王方乔瑞萍
王方,乔瑞萍
(西安交通大学信息与通信工程学院,710049,西安)
卷积神经网络是一种著名的深度学习架构,其灵感来自于生物的自然视觉感知机制[1-2]。2012年,Alex等使用8层的深度卷积神经网络以绝对优势获得了ImageNet竞赛冠军[3],卷积神经网络在图像识别中达到了前所未有的准确度。卷积神经网络从此广泛应用于图像分类、目标检测、语义分割等计算机视觉领域[4]。
灵长类动物的视觉系统接受了大量的感官输入,这些感官输入远远超过了大脑能够完全处理的程度。然而,并非所有刺激的影响都是相等的。意识的聚集和专注使灵长类动物能够在复杂的视觉环境中将注意力引向感兴趣的物体[5]。人类可以自然有效地在复杂场景中找到突出区域,受这一观察的启发,注意力机制被引入计算机视觉[6]。
注意力机制可以使卷积神经网络关注于感兴趣的信息,同时抑制不必要的信息,基于输入特征完成权重的动态调整。注意力机制在许多视觉任务中取得了巨大成功[7-11]。研究结果表明:在网络中添加注意力机制可以有效地提高网络的表达能力[12]。
注意力机制可以分为通道注意力机制、空间注意力机制、通道空间混合注意力机制等。通道注意力机制旨在对卷积网络中不同通道赋予不同的重要性,其中经典算法就是挤压和激励注意力(SE)[13]模块,它通过建模特征通道之间的相互依赖关系,自适应地学习每个特征通道的重要程度[14]。空间注意力机制旨在对卷积网络的空间域不同位置赋予不同的重要性,例如借鉴非局部均值方法的非局部神经网络(Non-local Neural Networks)[15]。空间注意力机制和通道注意力机制可以同时加入到网络中,如卷积注意力机制模块(CBAM)[16],也取得了优异的效果。
纵观这些注意力机制方法,人们总是考虑压缩某一维度以获得所需要的信息,例如通道注意力模块一般是通过在特征图上进行空间维度压缩以得到不同通道的重要程度,而空间注意力模块在通道维度进行压缩以得到不同位置的重要程度。卷积神经网络的不同的通道通常代表着不同模式[17],特征图对不同输入的响应也应该不同。考虑了对每一张特征图分别获取其重要性,本文提出了一种新的轻量级空间分割注意力模块(SPAM),可以对每一张特征图分别进行建模,增强网络本身的特征表达能力。
1 空间分割注意力模块
1.1 相关工作
深度学习通过使用反向传播算法来发现大型数据集中的复杂结构,以指示机器应该如何改变其内部参数。一定程度上,卷积神经网络可以自适应地建模图像空间和通道维度的关系,当然这并不意味着它总是可以找到最佳方式。卷积神经网络会自适应地学习一些关系,注意力机制更像是加入了额外的约束,使网络向期待的方向训练优化。
注意力机制可以认为是对某些维度的建模,自适应地预测潜在的关键特征,例如SE在通道维度去强化重要的通道,抑制无用的通道。注意力机制近几年也有许多相关工作,例如有效通道注意力(ECA)[18]一文中,Wang等认为避免降维对于学习通道注意力非常重要,故而提出了一种不降维的局部跨信道交互策略;坐标注意力(CA)[19]一文中,Hou等认为位置信息对于生成空间选择性非常重要,因此将通道注意力分解为两个一维特征编码过程,分别沿两个空间方向聚合特征。
通道注意力机制总是直接压缩空间维度的信息以获取不同通道间的关联性,这会损失大量的空间信息,而使得在某些任务中效果较差。关注空间重要性的注意力机制中,例如非局部神经网络利用特征图中所有位置的特征加权信息计算出每一个位置的响应,计算量非常大,这也导致像素级的建模方法难以实际应用; CBAM等混合注意力机制在获取空间上重要性时先进行通道融合或通道压缩来减小计算量,再去获取特征图不同位置的重要性;CA则采取分别对X、Y方向建模的方法,再获取重要性。
通道融合或压缩时也会损失一些信息,同时每一幅特征图的空间上的注重点可能不同,本文考虑在不进行通道融合或压缩的情况下,同时简化像素级建模方法的运算,获取不同位置和不同通道特征的重要性。在空间金字塔池化(SPP)[20]网络中,SPP块采用了固定池化窗口数,改变池化窗口大小的池化方式,从而让任意尺寸的输入产生固定维度的输出;DC-SPP-YOLO[21]中提出了SPP-YOLO,其中的SPP块没有将特征图调整为具有固定维度的特征向量,而是使用固定尺寸的滑动窗口池化来提取并融合多尺度局部区域特征。可以认为特征图在某一部分上包含的特征数是固定值,而用一定的提取特征去表征它。本文通过将特征图压缩来获得特征,也即获取注意力时通过自适应的池化来提取空间上的特征。
网络获取空间注意力的部分大多是通过通道融合或压缩得到的,但不同通道通常表征不同模式,必然会有不同之处,这样的处理方式过于粗糙。本文方法考虑对每一张特征图分别进行建模,不考虑每一像素和其他所有像素之间的关系,而是考虑它在这张特征图中的重要程度,去突出空间中较为重要的部分,也即是特征所在位置。本文提出了一种简单有效的注意力模块SPAM。SPAM使用池化操作去提取空间块特征,并将其作为空间点特征,缩小特征图尺寸从而减小计算量。SPAM在不进行通道上的融合或其他操作的情况下,获得所有特征图的空间位置的重要性,通过对每张特征图进行空间位置的建模以最大程度地保留空间上的信息,同时对噪声等特异像素点进行抵抗。
1.2 SPAM获取注意力方法
SPAM可以分为特征提取、特征标定、通道重建和特征聚合4个步骤。SPAM结构示意图如图1所示,输入特征图经过一系列处理后会被重新加权,重要的特征更加明显,与大多数常见注意力机制相同,它可以方便地嵌入到多种CNN架构中。
对于输入张量的中间特征图F,尺寸为C×H×W,其中C表示特征通道数,H表示特征图的高度,W表示特征图的宽度,SPAM的处理过程如下。

F1=αFAvg+βFMax
(1)
步骤2使用实例标准化(IN)层获取注意力特征图。一般认为对网络响应值更高的地方更为重要,此处可以认为在原始特征图中的块状区域寻找特征是否会出现,或出现概率的高低,让网络关注到更重要的地方;同时IN层在全局上进行强化或抑制,可以进一步区分特征。接下来使用深度可分离卷积层学习空间位置上的重要性,由于IN层破坏了通道上的关系,所以此处不再采用普通卷积,同时可以节省参数和计算量。最终使用Sigmoid激活函数将学习到的权重归一化,并乘以输入F1,得到F2。处理过程如下式
F2=σ(DW-Conv(IN(F1)))F1
(2)
式中σ表示Sigmoid激活函数;DW-Conv表示深层卷积操作;IN表示实例标准化操作。
F3=σ(GroupConv(F2))
(3)
式中GroupConv表示分组卷积操作。
步骤4插值操作。当前的特征图F3大小为C×h×w。针对每一通道,在像素所在块的位置上得到了注意力权重。为了对原始特征图进行重标定,此处选择使用最近邻插值方式将其恢复成尺寸为C×H×W的特征图,并与输入特征图F相乘得到最终标定后的输出特征图,处理过程如下式
F4=Interpolate(F3)F
(4)
2 实验结果及分析
为了评估SPAM,在常用分类数据集ImageNet-1K[22]、CIFAR-100、Food-101上进行了实验。本节描述了实验设置,进行了一系列消融实验,以证明所提出的SPAM中每个组件对性能的贡献,从而证明了SPAM设计方案的有效性。将本文方法与之前的一些轻量级注意力机制进行了比较,获得了更好的性能,这证明了SPAM的强大。还在其他不同大小的数据集上进行了验证,以证明SPAM的鲁棒性。最后,采用Grad-CAM[23]工具直观地观察模型在预测时关注的图像区域,从而更好地理解网络的决策过程和预测依据。所有的实验网络均在PyTorch[24]框架下实现。
2.1 消融实验
在这些消融实验中,使用的是ImageNet-1K数据集,并选择ResNet50[25]作为注意力模块的主干模型。在训练期间,使用衰减和动量为0.9的标准SGD优化器来训练所有模型。权重衰减设置为0.000 01,初始学习率为0.02。使用1个NVIDIA GPU进行训练,批量大小设置为64。在没有额外声明时将ResNet50作为基线网络,所有模型都训练了90个Epoch。对于数据增强,使用与ResNet[25]中相同的方法。
在消融实验中,验证了SPAM中不同组件的有效性,并探索了特征提取方式和重建通道维度的方法对网络的影响,以促进SPAM达到最佳性能。
首先探究了不使用池化、在原始特征图上获取注意力的方法,也即去掉最开始特征提取和最后插值部分,直接生成注意力去标定特征图;IN层所起作用是在每张特征图上区分特征重要性,可以使网络获得全局性,此处也显示了去除IN层的结果;探究了去除通道重建部分的SPAM,结果是网络性能大幅下降。此处将这几种不同构建方法分别命名为SPAM(无池化)、SPAM(无IN层)、SPAM(无通道重建),实验结果见表1。注意力模块SPAM的组件每一部分都有其作用,可以使网络性能更佳。

表1 SPAM组件消融实验结果
在最初的特征提取模块中,使用了两个可训练参数α和β,用于平均池化特征和最大池化特征之间的自适应提取,这两个特征之间的自适应机制可以丰富特征图,并允许它们具有完整的关系。与只使用最大池化、只使用平均池化、组合无参数(平均池化和最大池化的特征图权重都取0.5)的方法作了比较。为了便于标记,这几种方法分别命名为SPAM(最大池化)、SPAM(平均池化)、SPAM(组合无参数)。不同池化方式的SPAM加入网络后进行分类实验的结果见表2,可以看到,在使用不同的池化特征时,虽然相较基线网络都有一定的提升,但SPAM所采用的自适应池化达到了最高的精度。

表2 不同池化方式的SPAM加入网络后进行分类实验的结果
在通道重建部分,采用分组卷积来简单重建通道之间的依赖关系。此处也使用了类似SE中的压缩激励方法,记为SPAM-SE。这两种方法的作用相同,参数也相差不大。对比了这两种方法在不同的组数g或压缩比率r时的情况。不同通道重建方式的SPAM加入网络后进行分类实验的结果见表3,SPAM使用简单分组卷积增加了少量参数,即可带来网络性能提升。

表3 不同通道重建方式的SPAM加入网络后进行分类实验的结果
在整个消融实验中,确定了SPAM的最终方案,SPAM采用所有配置中效果最佳的组件和参数。在下面的实验中,将使用SPAM与其他的注意力机制进行比较,以验证它的有效性。
2.2 与其他注意力机制的比较
将SPAM与其他轻量级注意力机制进行了比较,包括常用的SE、ECA、CBAM和CA。在ImageNet-1K数据集上进行图像分类实验,使用相同的网络和配置来严格评估注意力模块。遵循消融实验(第2.1节)中提到的训练规则,将不同的注意力模块嵌入网络架构。ImageNet-1数据集分类结果见表4,由表4可以看出,嵌入SPAM模型的网络相比基线网络有明显的提升,准确率提升了约1.08%,这表明SPAM确实可以提高网络的表示能力。此外,添加了这几种注意力机制的网络增加的参数与计算量都较小,在可接受的范围内,效果相比基线网络都有一定提升,这也体现了注意力机制的作用。在这几种注意力机制中,参数量和计算量最少的ECA对网络的提升效果最低,而紧随其后的SPAM增加了微量参数和计算量,达到了最好的效果,超出CA、SE、CBAM等方法。使用SPAM的模型达到了最高的精度,这表明本文提出的方法是有效的。
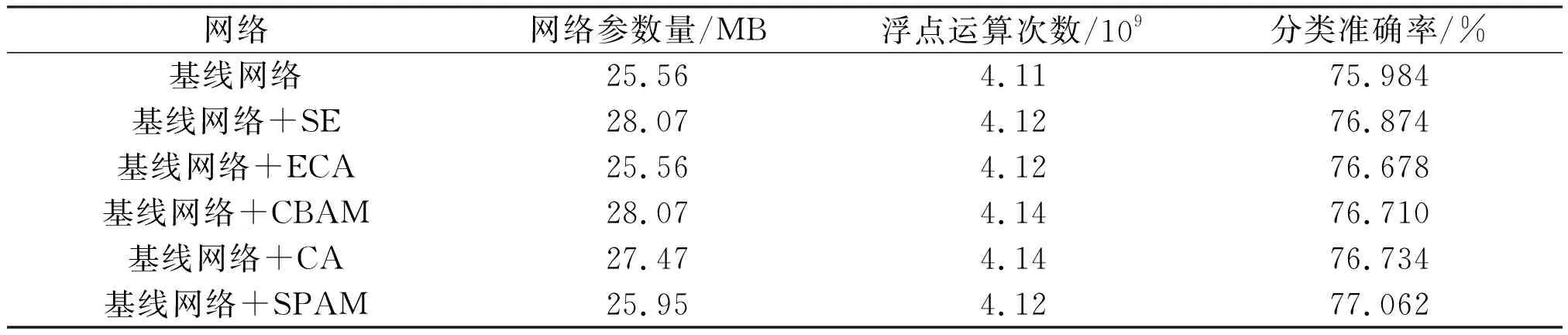
表4 ImageNet-1K数据集分类结果
2.3 在其他数据集上的分类结果
为了更全面地评估本文所提算法,也在其他的数据集上进行了图像分类实验,以下显示了在CIFAR-100和Food-101数据集上的分类结果。
CIFAR-100数据集是由100个类、60 000张3通道RGB彩色图像组成,每张图片尺寸为32×32像素,每类含有600张图像,其中含有50 000张训练图像和10 000张测试图像。采用基线网络为ResNet50(第一层使用的卷积核的大小为3×3、步长为1,并去掉了第一个最大池化层),在训练期间,使用衰减和动量为0.9的标准SGD优化器来训练所有模型。权重衰减设置为0.000 5,初始学习率为0.01,批量大小设置为128,共训练160轮次。CIFAR-100数据集分类结果见表5,可以看到SPAM在此数据集上相较基线网络准确率提升了约2.46%,相较其他注意力机制取得了最好的结果。

表5 CIFAR-100数据集分类结果
Food-101数据集是由101个类,101 000张3通道RGB彩色图像组成,每类含有1 000张图像,其中共含有75 750张训练图像和25 250张测试图像。此处所采用的基线网络为ResNet50,在训练期间,使用衰减和动量为0.9的标准SGD优化器来训练所有模型。权重衰减设置为0.000 5,初始学习率为0.01,批量大小设置为8,共训练100轮次。Food-101数据集分类结果见表6,可以看到SPAM在此数据集上相较基线网络准确率提升了约1.09%,相较其他注意力机制也取得了最好的结果。

表6 Food-101数据集分类结果
RegNet是Radosavovic等[26]于2020年提出的一种卷积神经网络架构,它结合了手动设计与神经架构搜索,最终得到的网络相比之前的在性能上有较大的提升。RegNet具有RegNetX和RegNetY两种不同架构,这两种架构的区别在于RegNetY中加入了SE模块,效果也更好一些。此处采用了和50层网络的ResNet50计算量最相近的浮点运算次数约为4.0×109的架构RegNetY-4.0GF作为基线网络,在Food-101数据集上进行训练与评估,并使用其他的注意力机制直接替换RegNetY-4.0GF中的SE模块以进行对比。改用其他注意力机制的网络分别记为RegNetY-ECA、RegNetY-CBAM、RegNetY-CA和RegNetY-SPAM,实验结果见表7。

表7 使用RegNetY的Food-101数据集分类结果
RegNet是通过神经架构搜索得到的,与ResNet等手动设计的网络有很大不同,例如很多时候RegNet的通道数增加并不是成倍增长,每阶段中的层数也不尽相同。从表7可见,RegNetY-4.0GF相较ResNet50所使用的参数量和计算量都稍少一些,最终的准确率却有相当大的增长,这体现了RegNet的强大性。相较原本使用SE模块的RegNetY-4.0GF网络,准确率增长较多的是使用了ECA和SPAM的新架构,因为它们都采用了不降维的方法,能够更好地适应网络的变化。SPAM相较缺少位置信息的ECA,提升效果更好,对于准确率已相当高的RegNetY-4.0GF网络,使用SPAM直接替换其中的SE模块仍能增加约0.72%的准确率。
表5、表6实验结果与表4得到的分布基本相符,而在表7中由于所采用基线网络的变化,不降维的方法更好。在这些不同的实验中,加入SPAM的网络都取得了最好的表现。在这几种不同大小数据集上以及应用了不同网络时的分类结果,证明了SPAM的鲁棒性良好,能够应用于不同情况。
2.4 Grad-CAM可视化
为了能够更直接地反映SPAM的优势,使用Grad-CAM作为可视化工具,在最后一个构建块中生成使用了不同注意力机制的模型特征图的可视化。Grad-CAM可以解释CNN如何通过使用梯度来计算卷积层的重要区域来进行分类决策。基于ImageNet-1K数据集中的图片将不同注意力机制的可视化结果进行了比较,结果如图2所示,在每张原始图像的顶部显示了它的真实标签。SPAM的可视化结果在覆盖目标类别区域方面优于其他网络。这说明了SPAM确实可以使网络学会专注于目标所在区域,且相较其他注意力方法能更精确地定位感兴趣的目标。可以推测,SPAM模块可以引导网络更加关注重要的特征,而忽略不重要的特征。
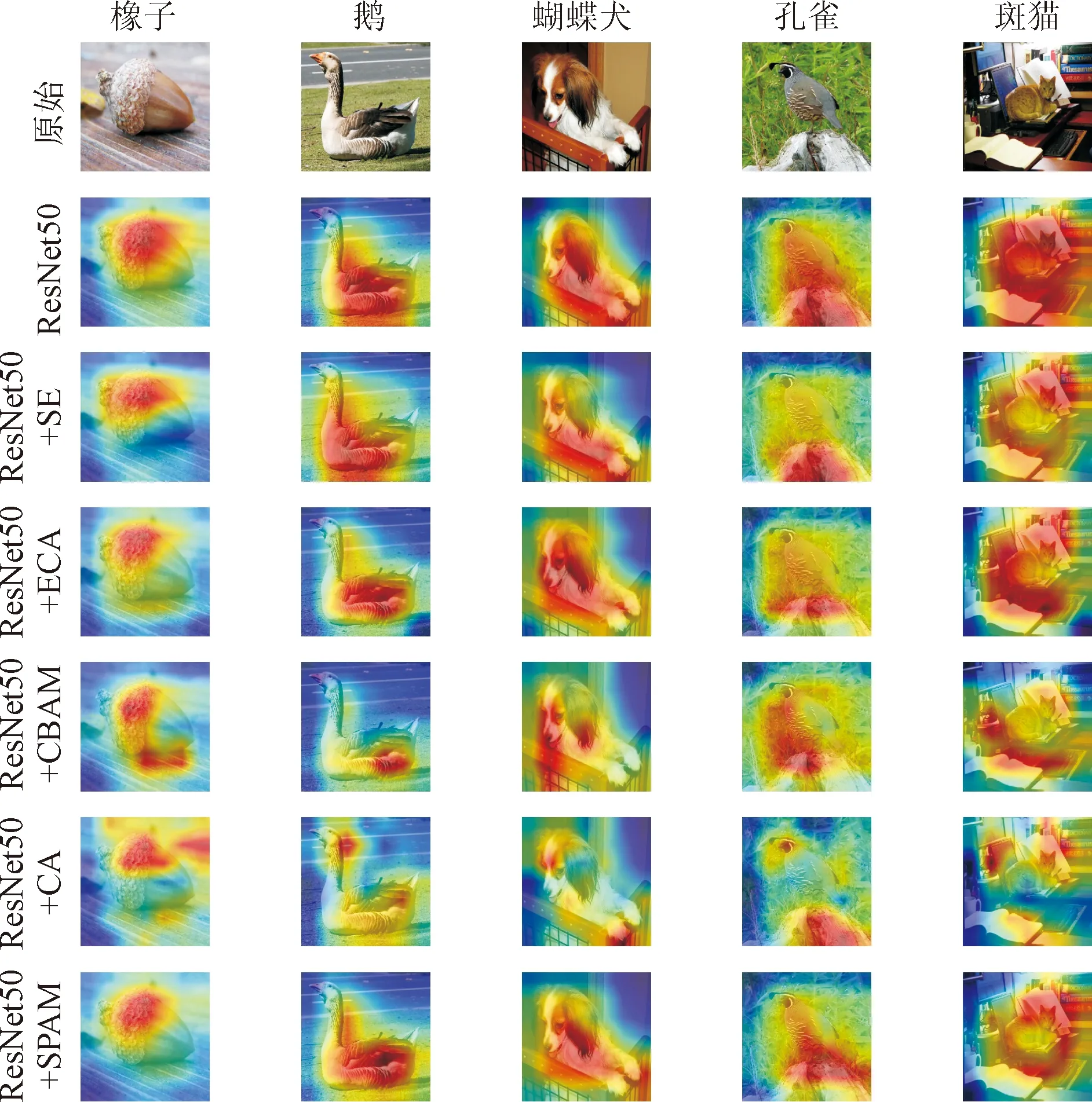
图2 Grad-CAM可视化结果Fig.2 The visualization results by Grad-CAM
3 结 论
本文对注意力机制进行了一些研究,提出了一种新的轻量级、有效的注意力模块SPAM,它通过池化操作先减少计算量,可以在不经过通道融合或压缩的情况下获取所有特征图的注意力。SPAM可以方便地嵌入CNN架构中,以显著提高网络性能。在特征提取方面,同时使用了平均池化和最大池化操作,并添加了自适应机制,以提取更为丰富、全面、有效的特征;通过先池化以局部块特征代替点特征实现空间注意力的获取,使用IN层和深层卷积捕获全局空间注意力;使用了分组卷积完成通道维度重建,插值恢复获得整体注意力。最终注意力模块可以使网络有效地关注目标所在区域,提高网络的性能。在ImageNet-1K数据集上进行的消融实验,证明了设计方案的有效性。为了评估SPAM的效果,将其与SE、ECA和CBAM、CA等轻量级注意力模块进行了比较,在ImageNet-1K、 CIFAR-100、Food-101数据集上进行验证,并使用Grad-CAM可视化了网络的关注区域。实验结果表明,SPAM有效提高了CNN的表达能力,且对不同的分类数据集和不同的网络架构具有鲁棒性。SPAM可以促使网络更加关注目标对象所在区域,这也是注意力机制的意义所在。SPAM有望作为一个重要组件应用于计算机视觉任务。
