基于CasEE的电子病历医疗事件抽取模型
2023-10-22王悦绮崔建峰
倪 昊,张 旭,马 帅,王悦绮,崔建峰
(1.厦门理工学院计算机与信息工程学院,福建 厦门 361024;2.厦门理工学院软件工程学院,福建 厦门 361024)
随着医疗行业信息化的快速发展,记录患者临床治疗信息的电子病历数据逐年增加。电子病历信息大多以自由文本形式存在,临床术语复杂多样且不规范,无法直接提取信息加以利用[1]。从电子病历文本中抽取事件信息结构化文本构建医疗事件数据库,不仅可以提高医生临床诊断的效率,还有利于医疗科研分析、智能诊疗、患者画像构建及病程追踪的发展。
事件抽取技术在新闻、财经、司法等领域均有广泛应用[2],在自然语言处理领域,有人先后提出基于模板与规则、机器学习和深度学习的自动抽取模型用于事件抽取任务的实现。研究早期,Kraus等[3]通过设计大量正则表达式来抽取电子医疗记录中的药品名、剂量等实体,该算法相对简单,但效率低,错误率高。针对这些缺陷,He 等[4]提出了基于机器学习的条件随机场(conditional random field,CRF)联合标签模型,采用序列标注的方法抽取事件。这种抽取方法虽然比基于规则的抽取方法效率和准确率更高,但无法提取长文本信息,且通用性较差,识别策略单一。为克服以上缺点,Yan 等[5]提出基于深度学习的BiLSTM-CRF 模型,采用BiLSTM 提取上下文的隐藏特征,再使用CRF层对输出结果进行约束,该模型可以提取长文本信息,通用性更高,具有强大的自学习能力[6]。但该模型属于管道式抽取模型,触发词提取的误差会传播至论元提取任务,且未充分利用触发词与论元的联系[7]。为解决此问题,研究人员提出了联合事件抽取模型,如Lu 等[8]提出的端到端抽取模型Text2Event。该模型的所有子任务均处于同一框架中,通过共同学习改善了误差传播问题[9],但对于文本中的重复事件抽取效果较差。为解决重复事件提取问题,Sheng 等[10]提出了基于级联解码的联合学习模型(novel joint learning framework with cascade decoding for event extraction,CasEE),该模型在重复事件抽取方面取得了良好的效果。但该模型主要面向通用领域,处理电子病历文本会造成性能损失,且无法提取医疗事件的发生状态,对医疗事件抽取任务的支持尚有改进空间。
综上所述,已有的医疗事件抽取模型存在误差传播且重复事件抽取效果不佳的问题,CasEE 虽解决了这2 个问题,但在医疗术语识别和发生状态提取方面存在缺陷,尚未提出较好的解决办法。为此,本文提出一种基于CasEE 的医疗事件联合抽取模型,对CasEE 中的编码层和事件分类器进行优化和改进,将编码层改为MC-BERT[11],实现对医疗术语的准确编码,并改造事件分类器,将其用于发生状态的提取。
1 问题定义
医疗事件抽取是医学数据处理中的一项关键任务,目标是从电子病历中抽取医疗事件的主体词、描述词、解剖部位和发生状态4个成分,其中主体词、描述词和解剖部位直接来源于病历文本,而发生状态分为“确定”“否定”和“不确定”3 种状态,需根据文本自行分类判断。每条电子病历可能包含一条或多条医疗事件,将其包含的所有医疗事件及相关成分逐一抽取,最终把非结构化的病历文本转化为结构化的病历数据加以存储。例如,对电子病历文本“患者无明显诱因出现尿色加深,如茶水样,偶有痰中带血,为鲜红色,量不等,无全身皮肤瘙痒等不适”进行事件抽取,抽取所得结构化文本如表1 所示。以表1中事件3“无全身皮肤瘙痒”为例,该事件的主体词为“瘙痒”,描述词为“全身”,解剖部位为“皮肤”,发生状态为“否定”。

表1 医疗事件抽取结果实例Table 1 Examples of medical event extraction results
2 模型设计
2.1 总体流程和模型结构
事件抽取任务处理流程如图1所示。具体抽取步骤如下:第1 步,将输入的一条电子病历文本进行词向量编码;第2步,将词向量输入事件分类器对该病历所包含的医疗事件进行分类,确定事件的发生状态;第3 步,将提取到的事件类别信息与词向量相融合,输入触发词提取器提取触发词(该触发词即为医疗事件的主体词);第4 步,将触发词信息嵌入到词向量并输入事件论元提取器中,分别对医疗事件的描述词和解剖部位进行提取;第5 步,将输出结果进行聚合,得到结构化的电子病历数据。
本文模型为联合抽取模型,通过层叠指针网络联合进行触发词提取和事件论元提取2 个子任务,可对文本中复杂的事件进行提取。与管道抽取模型相比,联合抽取模型可使2个任务损失优化的方向得以统一[12]。改进后的医疗事件抽取模型的结构如图2所示。
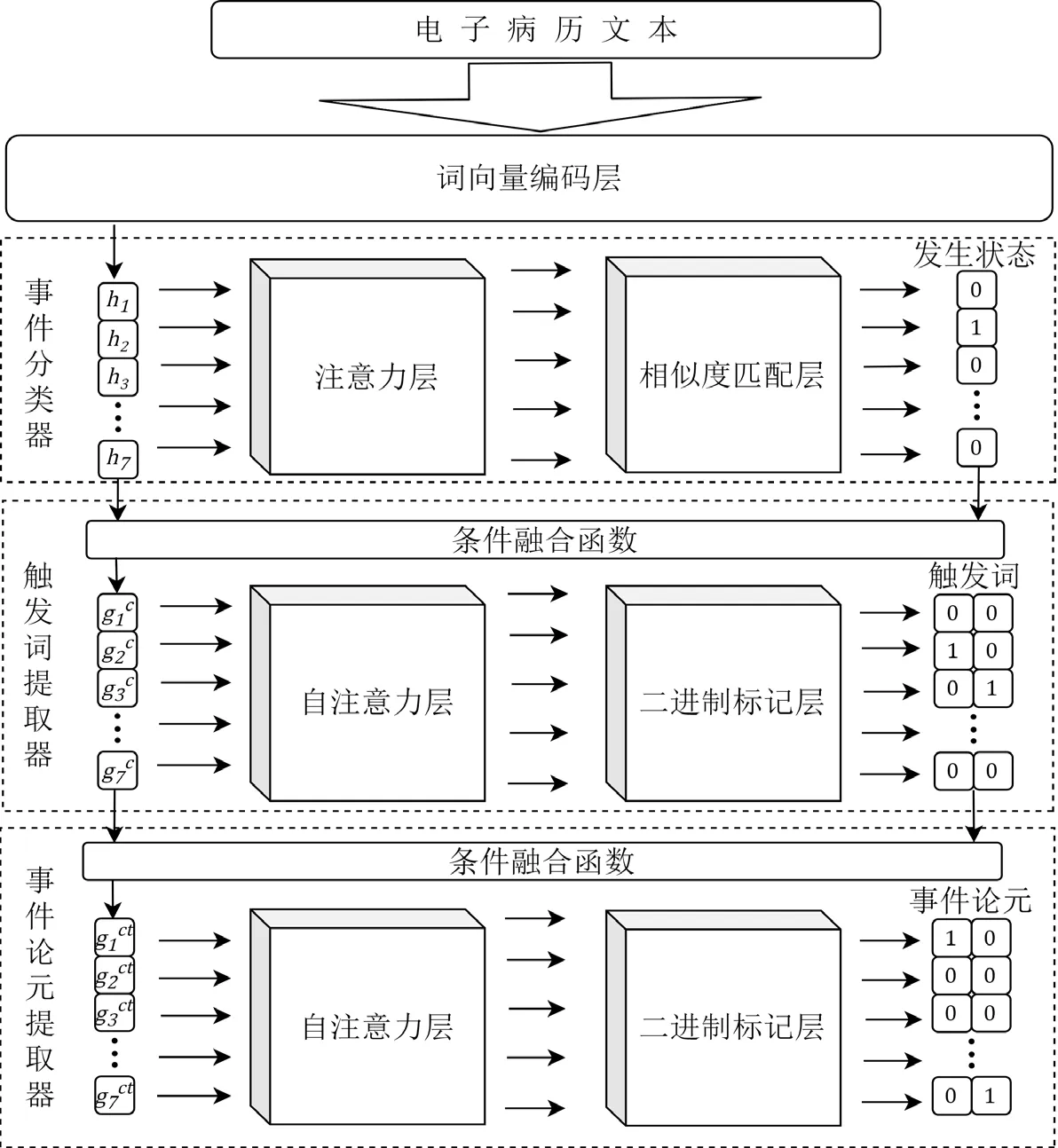
图2 改进后的医疗事件抽取模型的结构Fig.2 Improved medical event extraction model structure
2.2 数据增强
本文采用的数据集为第七届中国健康信息处理会议CHIP2021[13]所提供的电子病历数据集CHIPCDEE。该数据集共包含2 485条电子病历文本和与之相应的通过人工标注提取出的结构化数据。由于人工标注时部分主体词已经过标准化处理,与原文中所用词语不一致,且数据集包含的数据总量较少。本文通过近义词替换法对电子病历数据进行数据增强处理,以提高医疗事件抽取性能。
数据增强共分为3 个步骤:第1 步,筛选出结构化数据中与原文中不一致,映射失败的主体词,并查找这些词汇的近义词;第2步,用近义词替换未对应的主体词,将近义替换后的病历数据插入原始数据集中,得到增强后的数据集;第3步,在模型完成事件抽取后,对结果进行标准术语替换。本文的数据增强实例如表2所示。

表2 数据增强实例Table 2 Examples of data enhance results
本文以65%、15%、20%的比例将原数据划分为训练集、验证集和测试集,且仅对训练集和验证集的数据进行数据增强处理。数据分布统计情况如表3所示。

表3 数据分布表Table 3 Data distribution 单位:个
2.3 词向量编码层
原始CasEE 模型难以准确识别病历中的医疗术语,为此,本文将原始CasEE 模型的编码层改为MC-BERT,实现对医疗术语的准确编码。输入的电子病历文本首先通过词向量编码层进行向量化处理,编码后的向量依次被送入事件分类器、触发词提取器和事件论元提取器。
MC-BERT 编码层可以处理电子病历中复杂的语言结构和大量的医疗术语。MC-BERT 由多个Transformer 组成,是针对中文医疗任务优化改进的预训练模型,具体结构如图3 所示。图3 中,En表示输入电子病历中的每一个字符,Trm 表示Transformer 编码器,hn表示编码层最终输出的词向量。

图3 MC-BERT模型结构图Fig.3 MC-BERT model structure
MC-BERT 在预训练过程中注入了大量医疗实体和短语,可以更好地对电子病历进行编码。具体注入方法为:1)在掩码语言模型中使用全实体遮蔽方式对词语进行预测,例如对“布洛芬”等医疗领域专有实体词进行遮盖,将类似的医疗实体注入模型;2)在掩码语言模型中使用全跨度遮蔽方式对一些医学相关的短语进行预测,如“头有一点疼”等短语和医疗实体“头痛”有类似的含义,将该类短语作为医疗实体的扩充注入模型。
2.4 事件分类器
事件分类器负责预测医疗事件的类别,用于后续对重复事件的提取。为提取医疗事件的发生状态,本文对事件分类器进行改造,将医疗事件划分为确定事件、否定事件和不确定事件3类,使其在分类的同时实现发生状态提取功能。该模块通过注意力机制和相似度匹配实现类别预测。首先,随机初始化一个类型矩阵C并定义相似度函数δ,该函数可以计算类型c与词向量hi间的相关性得分。其次,分别计算句子中每个词向量hi与类别c的相关性得分,得出该语句对于该类别的向量表示sc。最后,通过δ函数计算类型c与sc间的相似度即可预测出事件的类型。具体计算过程为
式(1)~(3)中:W和v为可学习参数;c为类型矩阵C中的一个候选类型;hi为编码层输出的词向量;⊙为哈达玛乘积,表示符号前后两矩阵对应元素相乘;N为语句中包含的词向量总数;σ为sigmoid函数。
2.5 触发词提取器
为解决文本中重复事件较多的问题,触发词提取器以类别作为条件,对各类触发词进行分阶段抽取。该模块由条件融合函数、自注意力层和二进制标记器组成,将事件类型c与词向量hi通过条件融合函数φ进行融合,该函数通过条件层归一化[14]实现,通过该函数,可以获得包含事件类型信息的词向量。具体计算过程为
式(4)中:γc和βc分别为根据条件所动态生成的增益量和偏置量;μ、σ分别为hi的均值和标准差。
之后,将所得矩阵Gc输入自注意力层[15]进一步提取隐藏特征得到Zc。自注意力层由多个注意力头组成,各注意力头的输出相互连接,并通过参数化线性变换得到结果向量。具体计算过程为
式(5)~式(8)中:Gc是由向量组成的矩阵;Zc是由组成的矩阵;WV、WQ、WK为可学习参数矩阵;dz是矩阵WQ、WK的维度。
为了预测触发词,将自注意力层后接二进制标记器。对于每个字符wi,对其是否对应于触发词的开始或结束位置进行预测。为了获得触发词t,首先枚举句子中所有的起始点,再搜索起始点后距离最短的结束点,这两点之间的词语即为触发词。具体计算过程为
式(9)~式(10)中:是Zc中的第i个词向量。通过此种方式,该模型可以根据类型提取重复的触发词。最后可以得到句中所有类别为c的触发词集合Tc,s。
2.6 事件论元提取器
事件论元提取器分别以事件类别和论元类别为条件,依次提取不同类型的事件论元,以此解决重复论元的提取问题。该模块的结构与触发词提取器类似,由条件融合函数、自注意力层和二进制分类器所组成。
为预测与事件触发词t相关的论元,本模块先对触发词t的开始和结束位置求平均值,再使用条件融合函数φ将触发词信息嵌入到词向量中,使其感知到触发词信息。当该向量通过自注意力层后,再通过相对位置编码[16],将距离触发词的长度嵌入到每个词向量中得到Zct。具体计算过程为
式(11)~式(13)中:t表示触发词的边界位置平均值;Gct是由向量组成的矩阵;P为触发词的相对位置。
最后通过二进制标记器来获得与触发词相对应的论元提取结果。本任务需提取3 种论元,为此,由3个不同的二进制分类器分别对描述词、解剖部位和发生状态进行解析。
3 实验结果及分析
3.1 实验平台
本文所进行的实验基于Python 3.8语言和Pytorch深度学习框架,操作系统为64位Linux操作系统,CPU为Intel(R)Xeon(lice Lake)Platinum 8369R@2.90 GHz,CPU型号为NVIDIA A10,显存为24 GB。
3.2 实验评价指标
本文使用精确率(P)、召回率(R)和F1值作为评价指标分别对各模块的模型性能进行评估,其计算公式为:
式(14)~式(16)中:TP 代表真正例,即实际为正例且被模型预测为正例的属性数目;FP 代表假正例,即实际为负例而被模型预测为正例的属性数目;FN 代表假负例,即实际为正例而被模型预测为负例的属性数目。
本文评价指标使用事件属性来计算准确率、召回率和F1值,在电子病历中,若医疗事件的某个属性出现多个属性实体,只有当提取的所有属性都完全匹配时,才能统计为一个正确预测的样本。
3.3 模型参数
本实验所使用的详细参数如下:模型层数L=12,隐藏层维度H=768,采用多头自注意力机制数A=16,损失函数使用交叉熵损失函数,优化器采用Adam 优化器,采用的编码层学习率为0.000 02,其他模块学习率为0.000 1,学习率预热比率为10%,MC-BERT 隐藏层dropout为0.1,解码层dropout为0.3,最长序列长度为500,批处理大小为16,epoch 为20。
3.4 实验结果
3.4.1 训练loss变化和各模块实验结果
训练过程中各模块的loss 与F1值随epoch 变化如图4~图6 所示。由loss 及F1值变化曲线可知,事件分类器和触发词提取器在epoch=2时即收敛,F1值分别达到94.17%和89.41%,在之后的训练中没有明显变化。而事件论元提取器由于任务更难,收敛速度明显更慢,F1值在第1~6 个epoch 间稳步提升,后续F1值有所波动,最终在epoch=20时F1值稳定在77.73%。

图4 事件分类器训练损失与F1值变化曲线Fig.4 Event classifier training loss and F1 value change
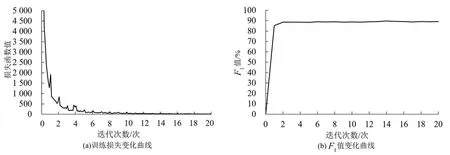
图5 触发词提取器训练损失与F1值变化曲线Fig.5 Trigger word extractor training loss and F1 value change
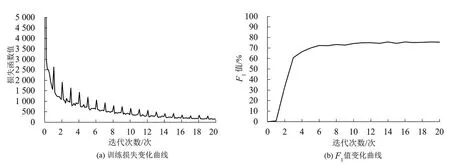
图6 事件论元提取器训练损失与F1值变化曲线Fig.6 Event argument extractor training loss and F1 value change
使用测试集数据测得各模块的精确率、召回率和F1值见表4。本模型中事件分类器的表现最好,F1值最终达到94.17%,触发词提取器表现次之,F1值达到89.41%,论元提取任务难度较高,因此该模块表现相对较差,F1值为77.73%,该模型在医疗事件抽取任务中的整体F1值为57.92%。

表4 各模块精确率、召回率和F1值的实验结果Table 4 Experimental results of accuracy,recall and F1 value by module 单位:%
3.4.2 对比实验
为了验证模型的有效性,本文选择了2 种管道式抽取模型和2 种联合抽取模型进行对比。其中模型1 和模型2 为管道式模型,分别是基于命名实体识别与关系分类的事件抽取模型和基于多范式融合的医疗事件抽取模型。模型3、模型4 和模型5 为联合抽取模型,分别是端到端(seq2seq)的医疗事件抽取模型、原始CasEE 模型和本文所提出的模型。所有实验均在CHIP-CDEE 数据集上进行训练和测试,对比实验结果见表5。
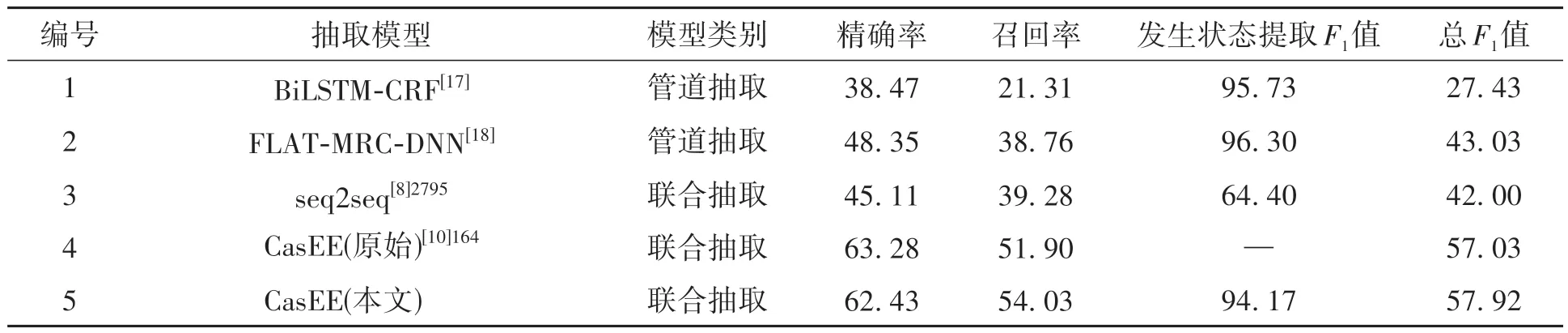
表5 不同抽取模型效果对比Table 5 Effect of extraction methods compared 单位:%
由表5可知,与管道式模型相比,联合抽取模型在召回率上普遍更高。原因是管道式模型将医疗事件抽取分为几个割裂的任务进行处理,使下游任务受上游任务误差的影响较大,存在误差积累问题[19],且上游任务无法根据下游任务的反馈调整参数权重。例如模型1将事件抽取任务一分为二,先通过BERT-BiLSTM-CRF 模型对文本进行实体识别,再通过BERT-DNN 模型对识别出的实体进行关系分类,得到完整医疗事件。该方法仅使用关系分类来确定事件触发词和论元间的关系,没有考虑实体的位置及上下文信息,因此精确率、召回率和总F1值都最低。模型2包含触发词提取、论元提取和极性预测3个模块,利用了上下文信息,精确率和总F1值比模型1优秀,但召回率不如另外两个联合抽取模型。模型3 为seq2seq 模型,使用不同的分隔符来区分医疗事件的不同属性,实现医疗事件的端到端抽取,召回率比管道式模型更高,达到39.28%,但该模型无法很好地处理电子病历中的词语嵌套和词汇重复的问题,总体效果不如模型4 和模型5。模型4 由于采用了级联解码方法,在解决误差积累问题的同时,改善了病历中嵌套事件和重复事件的抽取性能,精确率、召回率和总F1值达到63.28%、51.90%和57.03%。但模型4是针对通用领域设计的,无法准确识别电子病历中的大量医疗术语,也无法提取医疗事件的发生状态。模型5 针对模型4 存在的缺陷,改用了针对生物医学文本优化的编码层,同时在训练时进行了数据增强处理,减少了处理电子病历文本时的性能损失,精确率、召回率和总F1值远高于模型1、模型2 和模型3。与模型4 相比,除精确率由于数据增强的影响下降0.85%外,召回率和总F1值分别比模型4提高了2.13%和0.89%,达到54.03%和57.92%。同时,模型5对原始CasEE 模型的事件分类器进行了改造,将事件分类任务与发生状态提取任务合二为一,从而补全了模型4缺少的发生状态提取功能,总体效果最好。
对比表5中各模型提取医疗事件发生状态的效果可知,由于医疗事件发生状态仅有3 种类型,使用分类任务对其进行提取效果较好。模型1、模型2 和模型5 均使用分类任务提取发生状态,F1值分别为95.73%、96.30%和94.17%,模型3使用端到端方式提取发生状态,易受文本数据噪声的干扰,故F1值相对较低,为64.40%。
3.4.3 不同编码层对模型性能的影响
为验证不同编码层对模型的影响,本文在未经数据增强的情况下将模型的编码层替换为其他几种预训练语言模型进行对比,分别为BERT 基准模型[20]、中文医疗预训练模型PCL-MedBERT 和PCLMedBERT-wwm[21],实验结果见表6。在将模型的编码层由MC-BERT 改为BERT-base 后,模型的事件抽取性能下降明显。因为BERT-base模型是在一般领域的中文语料库进行预训练的,在处理中文电子病历文本时很难处理众多的专业词汇短语。将编码层改为PCL-MedBERT 模型性能有所提升,说明通过预训练过程中注入医疗词汇,可以更好地对医疗类实体进行编码。MC-BERT 在此基础上通过全跨度遮蔽显式注入了医疗类短语,作为编码层模型性能最好。实验结果表明,使用MC-BERT 作为模型编码层有效提升了医疗事件抽取效果。

表6 不同编码层对比实验结果Table 6 Experimental results of coding layers compared 单位:%
3.4.4 数据增强对模型性能的影响
为验证数据增强对模型性能的影响,将本文模型在CHIP-CDEE 原数据集和经增强后的数据集上分别进行训练,实验结果见表7。经过数据增强后,模型精确率下降1.77%,说明在事件抽取任务中引入数据增强会产生数据噪音,降低模型精确率。但模型召回率大幅提升2.08%,使总F1值提升0.49%。实验结果表明,本文引入数据增强改善病历数据量偏少的方案是有效的。

表7 数据增强对模型性能影响实验结果Table 7 Experimental results of effect of enhanced data on model function 单位:%
综上所述,本文提出的事件抽取模型优于其他模型,并补全了发生状态提取功能。事件分类和触发词提取阶段F1值较高,召回率也相对较高,引入的MC-BERT 编码层能有效提升医疗事件抽取效果。不过模型中论元提取器的召回率和F1值相对其他模块低20%左右,影响了整体任务的效果。不过对比其他方法,该模型在事件抽取各阶段实验效果仍然更好,最终实验结果表明,本文提出的模型比传统医疗事件抽取模型更具优势。
4 结论
本文提出了一种中文电子病历的医疗事件联合抽取模型,该模型通过在编码层注入医疗词汇,并使用类别信息辅助提取事件触发词,解决了中文电子病历中医疗术语难以准确识别和医疗事件发生状态难以提取的问题。同时,对数据集进行了数据增强处理,解决了电子病历数据量偏少的问题。本文提出的模型在医疗事件抽取任务中的F1值为57.92%,达到了较高水平。后续的研究将以取得的结构化病历数据为基础,探究中文电子病历中的数据挖掘和知识发现。
