融合数据增强和注意力机制的中医实体及关系联合抽取
2023-10-22杨延云杜建强罗计根
杨延云, 杜建强, 聂 斌, 罗计根, 贺 佳
(1 江西工程职业学院, 南昌 330025; 2 江西中医药大学计算机学院, 南昌 330004)
0 引 言
命名实体识别[1](Named Entity Recognition,NER)和关系抽取[2](Relation Extraction,RE)作为信息抽取的基础任务[3],旨在从半结构化、非结构化的文本中提取实体,并识别实体间的语义关系。中医药领域的实体及关系联合抽取就是提取中医文本中包含的中药名、方剂名、证型名、症状名等,并识别2 个实体间的关系类别。 高质量、精准的实体及关系抽取结果为后续知识图谱的构建、信息检索效率、智能问答系统的搭建等提供良好的数据基础[4-5]。
实现命名实体识别和关系抽取两个任务传统是基于流水线方法,分2 步执行。 第一步是实体识别,第二步将上一步结果作为关系抽取的输入进行后续关系抽取操作。 基于流水线方法易于建模且操作更加灵活,但也有局限性,会导致错误累积,忽略2 个子任务间的相关性,并产生冗余信息。 为解决流水线方法存在的问题,实体及关系联合抽取方法应运而生,充分考虑二者的相关性,同时提取实体及关系,组成形如<实体1,关系,实体2 >的三元组[6]。本文的研究主要针对将联合抽取任务转化为端对端的序列标注任务,并频繁应用循环神经网络(Recurrent Neural Network,RNN)[7]及其变体解决该问题。 2017 年,Zheng 等学者[8]首次将实体及关系联合抽取转化为序列标注任务,提出了一种基于新序列标注的联合抽取方法,还设计了带有偏置损失函数的端到端模型,实现了真正意义上的实体及关系联合抽取。 曹明宇等学者[9]借鉴Zheng 等学者[8]的研究思路,通过改进标注策略在DDI(drugdrug interactions)2013 语料上有效缓解了同一实体参与多个关系的重叠问题。 张军莲等学者[10]利用图卷积神经网络的编码局部特征和先验词间关系的能力,提升抽取实体和关系三元组的性能。
循环神经网络及其变体在序列标注任务上显示出巨大的优势,能够全面捕捉上下文序列语义特征,但却没有突出与当前信息有关上下文信息的关联性和依赖性。 Attention 机制旨在对输入序列依据其对目标任务结果的重要程度赋予相应不同的权重,强化重点,进而强调上下文信息与当前信息的关联和依赖,捕获更有效的上下文语义信息,Attention 机制既可以单独使用,也可以与其他神经网络模型融合训练。 2014 年,Google Deep-mind 团队[11]使用RNN 与Attention 机制的混合模型做图像识别,验证了Attention 机制在图像处理任务上的有效性。 随后,Bahdanau 等学者[12]实现了Attention 机制在自然语言处理领域的首次应用,在英语到法语翻译任务上效果可与当时最先进的方法相媲美。 文献[13]针对传统流水线方法的不足以及实体重叠问题提出了一种新颖的标记策略,并融入注意力机制为包含n个单词的句子针对每个查询位置生成对应的n条标注序列。 该模型在NYT 数据集上较Zheng等学者[8]提出的模型F1值提高4.3%。 模型LSTMLSTM-2AT-Bias[14]引入对抗训练增强模型的鲁棒性,并加入自注意力机制增强对文本信息的编码能力,在NYT 数据集上实验的F值为0.521±0.006。王勇超等学者[15]利用指针标注机制实现实体及其关系的联合抽取,引入注意力机制有助于捕捉文本内部信息的相互关联。
针对中医文本的实体及关系联合抽取任务而言,语料中存在着大量无标签数据,基于序列标注的实体及关系联合抽取方法虽克服了传统流水线的不足,但由于上述方法均是以标注语料作数据基础,数据打标消耗大量的人力、物力、财力,以及BiLSTMCRF 无法强调上下文信息与当前信息关联的问题。由此,本文提出了一种融合数据增强和注意力机制的中医实体及关系联合抽取方法(DA-BiLSTMAttention-CRF),利用数据增强改善领域标注数据缺乏问题,在BiLSTM - CRF 模型中加入注意力机制强化上下文信息与当前信息的关联性。
1 方法描述
融合数据增强和注意力机制的中医药领域的实体及关系联合抽取方法采用自训练方法多次实验,模型构建流程具体如下。
(1)第一阶段,模型训练。 训练步骤分述如下:
Step 1将已标注的中医语料按照7 ∶3 划分为训练集和测试集,并转化为200 维字词并联拼接向量作为序列标注模型BiLSTM-Attention-CRF 的输入,学习文本深层次特征,将已训练完成的模型记为BiLSTM-Attention-CRF_origin。
Step 2采用数据增强方法EDA 对无标签的训练集数据进行多倍增强。
Step 3使用BiLSTM-Attention-CRF_origin 预测增强后数据所对应标签,得到伪标注数据。
(2)第二阶段,模型训练。 训练步骤分述如下:
Step 4研究将训练集和伪标注数据作为训练数据重新训练模型,已训练完成的模型记为DABiLSTM-Attention-CRF。
Step 5无标签测试集数据通过模型预测打上相应的标签,结合提取策略进行三元组提取。
Step 6进行模型可靠性和有效性验证与评价。
需要注意的是,该方法中训练集指带有人工标注标签且用作模型训练的中医文本语料;测试集同理;无标签的训练集指只包含训练集中的文本数据,不包含对应的标签;无标签测试集同理。 该方法涉及的主要深度学习模型BiLSTM-Attention-CRF,其网络模型结构如图1 所示。
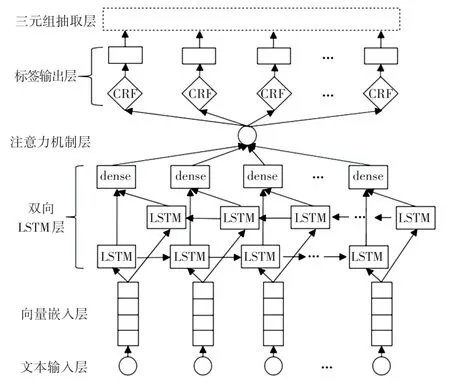
图1 BiLSTM-Attention-CRF 结构图Fig. 1 BiLSTM-Attention-CRF structure diagram
该模型结构主要包含3 个模块,分别为输入模块、神经网络模块和输出模块。 其中,输入模块由文本输入层和向量嵌入层组成;神经网络模块包括双向LSTM 层和注意力机制层;输出模块有CRF 层对中医文本的序列标注操作和结合提取策略进行三元组抽取处理。 下面对上述3 个模块所包含层级结构的作用和功能进行详细介绍。
(1)输入模块
①文本输入层:文本输入为中医文本序列及每个字符所对应的标签。
②向量嵌入层:对输入的文本序列进行向量表示。 向量所用语料来源于《中医证候鉴别诊断学》[16]、《中医150 证候辨证论治辑要(何晓晖)》[17]和《中医药学概论》[18]三本中医相关书籍。中医语料利用jieba 分词[19]工具,并加载自定义的中医领域自定义词典进行分词,自定义词典主要包含大量的证型、方剂等信息,通过Word2Vec[20]训练得到100 维词向量。 中医语料使用Word2Vec 训练得到100 维字向量,并以字为基本语义单元进行字词向量并联拼接,丰富语义特征信息[21]。
(2)神经网络模块
①双向LSTM 层:以字向量为基本语义单元与该字所在词的词向量进行并联拼接,得到200 维字向量作为BiLSTM 的输入,BiLSTM 由前向的LSTM与后向的LSTM 结合而成,得到一个前向t时刻的隐藏层输出和一个后向t时刻的隐藏层输出拼接而成[],更加充分地利用了上下文信息,进一步获取文本深层次特征表达。
②注意力机制层:注意力机制层的输入为上一层BiLSTM 的特征向量输出,通过计算概率权重,为不同字向量分配不同注意力权重,区分不同信息的重要程度,达到强化与当前信息有关联的上下文信息的目的。
(3)输出模块
①CRF 层:其作用是输出每个字符的最大概率标签,使用CRF 代替softmax函数,是因为CRF 层可以从训练数据中获得标签约束性规则,进而保证预测标签的准确性。
②三元组抽取层:CRF 层的序列标注输出作为该层的输入,根据预先定义的提取策略进行实体关系三元组抽取,其结果呈现类似于<杏苏散,方剂/中药,杏仁>。
1.1 标注模式及提取策略
本文实验语料来源于《中医证候鉴别诊断学》[16]、《中医150 证候辨证论治辑要(何晓晖)》[17]和《中医药学概论》[18]三本中医相关文献,累计2 968 个句子。 标注模式共涉及34 类标签,表1 展示了部分标签的内容及含义。 “BIES”表示字在词的位置;方剂/中药、证型/方剂、证型/症状、病因/证型和M 表示关系类别,M 表示该实体与多个实体组成关系不同的三元组;1、2 和M 表示关系角色,1和2 分别表示该实体在所属三元组中处于实体1 或实体2 的位置,M 表示该实体与多个实体组成三元组且处于不同位置。

表1 部分标签及含义Tab. 1 Part of the labels and meanings
通过标注模型标注文本得到标签后,将有相同关系类别(包括“M”类型)的2 个实体标签组合,再根据关系角色标签确定其在三元组中的位置。
需要强调的是,标签M 既可以扮演实体1,也可以扮演实体2。 标注实例和三元组抽取结果展示如图2 所示。

图2 标注实例Fig. 2 An example of labeling
1.2 自训练策略
当使用神经网络模型时,用于训练模型的数据是越多越好,而在有监督的任务中,所需训练数据必须根据目标任务进行打标,而想要构建这样的标注数据集依赖于大量的人力、物力和财力。 对于这个问题,半监督学习可以利用少量已标注数据进行模型训练,再使用已经训练好的模型对无标签数据进行预测,得到准确率较高的伪标签数据,不断迭代上述步骤将所有数据打标。 其中,自训练就是一个标准的半监督过程[22]。 自训练的算法流程主要步骤见如下:
Step 1将已标注的数据按比例划分训练集和测试集传送给模型,对模型进行训练。
Step 2使用训练好的模型预测无标签的数据,所得结果记作伪标签数据。
Step 3将伪标记数据与原训练数据组合,组合的“伪标记”和正确标记训练数据共同来重新训练模型。
Step 4使用经过训练的模型来预测已标注的测试集,根据所采用的评价指标评估模型性能。
1.3 数据增强
数据增强主要用于数据集较小的时候,用来防止模型过拟合,提升模型泛化能力。 对于深度学习模型来说,大的数据集是实验效果好的基本要求,而对于特定的领域任务,已标注的数据却是非常缺乏的。 数据增强是一种有效的扩充数据集的方法,在计算机视觉领域取得较好的效果,主要涉及的技术有随机旋转、随机裁剪、色彩抖动、高斯噪声、翻转等,通过增加图像的多样性扩充数据量。 然而在自然语言处理领域数据增强的方法相对较少,本文采用文献[23]提出的数据增强方法(下文简称EDA)对训练集进行数据增强处理。 EDA 采用4 种技术进行数据增强,分别是同义词替换、随机插入、随机交换、随机删除。
接下来将详细介绍这4 种技术,并以原文本“主治肝郁气滞证的方剂是黄芩散。”进行举例说明:
(1)同义词替换:从句子中随机选择非停用词,并用其同义词进行替换,则可以得到“主治肝郁气滞证的方药是黄芩散”。
(2)随机插入:找句子中一个随机词(非停用词)的同义词,插入到句子的随机位置,则可以得到“主治肝郁气滞证的方剂是黄芩散疏肝”。
(3)随机交换:随机选择句子中的2 个词,交换二者的位置,则可以得到“主治肝郁气滞证的方剂黄芩是散”。
(4)随机删除:随机删除句子中的词语,则可以得到“主治肝郁气滞的方剂是黄芩散”。
1.4 Attention 机制
Attention 机制[12]是一种模拟人脑注意力资源分配的机制,通过有限的注意力选择性地分配给更重要的信息,而弱化其他无用信息。 例如,给出中医文本:大承气汤由大黄、枳实各12 g,炙厚朴24 g,芒硝6 g。 根据文本回答问题“大承气汤由哪几味中药?”,那么答题人便只会专注去数大承气汤的中药组成个数;而当问题改为“大承气汤中枳实的用量是多少?”,那么答题人便只聚焦枳实的克数。 注意力机制就是随着任务的变化,变化注意力区域,找到对于任务要求最有价值的信息。 注意力机制的基本结构如图3 所示。

图3 注意力机制结构图Fig. 3 Structure diagram of attention mechanism
具体计算公式如下:
其中,ht表示t时刻上一层神经网络的输出向量;wt是第t时刻权重系数;bt是第t时刻偏置系数;ut表示第t时刻输入到全连接层获得其隐藏表示;uw表示随机初始化的注意力权重矩阵;at表示在t时刻通过归一化操作计算权重向量;st表示在t时刻最终编码后的句子向量。
2 实验分析
2.1 实验设置
本文实验环境是Windows 64 位操作系统,处理器是Inter(R)Celeron(R) CPU G530 @ 2.40 GHz,内存8 GB。 采用JetBrains PyCharm,Python 编程语言,搭建Tensorflow 框架,并运用Jieba 分词工具。评价指标选取精确率(Precision,P)、召回率(Recall,R)、F1值[24]。 模型涉及多个超参数,根据所得精确率、召回率和F1值进行参数调整,实验参数设置见表2。

表2 实验参数设置Tab. 2 Experimental parameter settings
2.2 模型对比实验
本节在使用相同字词向量并联拼接作为模型输入特征向量,相同标注模式和提取策略的情况下,对BiLSTM_CRF、BiLSTM-Attention-CRF_origin、DABiLSTM-Attention-CRF 进行对比实验,结果见表3。

表3 模型对比实验结果Tab. 3 Experimental results comparison of models%
由表3 可以得出结论如下:
(1)BiLSTM-Attention-CRF_origin 与BiLSTM_CRF 模型相比增加注意力机制结构,能够对BiLSTM输出的特征向量针对目标任务赋予不同的注意力权重,最大限度地强调上下文信息对目标词的重要性。研究中,2 个模型在相同数据集上做实验, BiLSTMAttention-CRF_origin 均有更好的效果。
(2)使用数据增强对训练集进行扩充,结合自训练策略对BiLSTM-Attention-CRF 模型进行多次训练学习,不仅没有降低模型性能,反而在领域标注语料不足的情况使模型性能得到一定的提升,F1分别较原模型提升0.52%。
2.3 DA 部分参数对比实验
为了确保新方法中数据增强部分参数α和navg的选取对于中医语料的可靠性,选取文献[23]推荐数据量为2 000 时采用的参数组合0.05、8 和本实验选取的参数组合0.05、4 分别进行对比,以实体及关系联合抽取实验的精确率、召回率和F1值作为评价指标,其结果见表4。
由表4 可以分析得出结论如下:
在DA-BiLSTM-Attention-CRF 模型上实验,利用EDA 方法进行数据扩充,当选取参数组合0.05、8时,实体识别和联合抽取综合评价指标F1 均有所下降,这是因为由模型BiLSTM-Attention-CRF_origin 预测所得伪标注数据存在一定概率的错误标签数;而参数组合0.05、4 的P、R、F1 值都高于未经数据增强处理的情况,与前者对比,这说明相对多倍数据增强后的伪标注语料存在的噪音数据对于原标注语料稀释作用较大,实验效果变差,而适当倍数的数据增强有助于提升模型性能。
2.4 模型成分消减实验
本文实验在数据处理部分采用了数据增强操作,模型输入采用字词向量并联拼接,核心算法结构使用双向LSTM、注意力机制和条件随机场。 为探究这些结构对于目标任务的影响,本节在相同标注模式和提取策略的前提下,分别对模型输入、数据增强、Attention、CRF 结构进行成分消减实验。 模型成分消减实验结果见表5。

表5 模型成分消减实验结果Tab. 5 Model component reduction experiment results %
由表5 可以得到如下结论:
(1)使用字词向量并联拼接作为模型输入,与采用单独字向量相比,在召回率和F1值有显著的提升,证明了字词向量并联拼接将字和词的信息有效地结合起来,更有利于提取有效特征。
(2)删减数据增强部分,即只有本文方法的第一阶段,实验的3 个评价指标均有所降低,证明了采用EDA 做数据扩充和自训练策略的有效性。
(3)注意力机制的作用是区分不同信息的重要程度,强化与当前信息有关联的上下文信息,而弱化其他无用信息。 增加Attention 层,显著提升了中医文本实体及关系联合抽取的精确率(提升接近2%),F1值增加1.07%。
(4)CRF 对于所有预测标签序列进行全局归一化操作,去掉CRF 层模型较原模型降低了联合抽取的F1值。
3 结束语
本文提出了一种融合数据增强和注意力机制的中医实体及关系联合抽取方法,选用EDA 对中医语料进行数据增强,使用自训练策略将原数据集和预测所得的伪标注数据共同学习,在中医语料上取得较优的效果。 将本文提出的方法与目前主流的序列标注模型进行对比,证明了本文方法的优越性;然后进行数据增强部分的参数组合对比实验,结果表明本实验选取参数取得更佳的实验效果;最后通过模型成分消减实验,验证了模型各个部分的必要性。
未来工作将寻求不同数据增强方法用于解决领域标注数据缺少的问题,对于本文采用的自训练方式进一步优化,提升模型性能,也可尝试探索预训练和自训练的融合策略对于实体及关系联合抽取任务的影响也是此后的研究工作。
