面向DCU非一致控制流的编译优化
2023-10-21杨小艺赵荣彩王洪生韩林徐坤坤
杨小艺,赵荣彩,王洪生,韩林,徐坤坤
面向DCU非一致控制流的编译优化
杨小艺1,2,赵荣彩1,2,王洪生2*,韩林1,2,徐坤坤1,2
(1.郑州大学 计算机与人工智能学院,郑州 450001; 2.国家超级计算郑州中心,郑州 450001)( ∗ 通信作者电子邮箱whs1814@foxmail.com)
国产DCU采用单指令多线程(SIMT)的并行执行模型,在程序执行时核函数内会产生非一致控制流,导致线程束中的线程部分只能串行执行,即线程束分化。针对核函数的性能因线程束分化受到严重制约的问题,提出一种减少线程束分化时间的编译优化方法——部分控制流合并(PCFM)。首先,通过散度分析找到同构且含有大量相同指令和相似指令的可融合发散区域;其次,统计合并后节省的指令周期百分比,从而评估可融合发散区域的融合盈利;最后,查找对齐序列,并合并有收益的可融合发散区域。在DCU上使用PCFM测试从图形处理器(GPU)基准测试套件Rodinia和经典的排序算法中选择的测试用例,实验结果表明,PCFM对测试用例能够取得1.146的平均加速比,与分支融合+尾合并方法相比,使用PCFM的加速比平均提高了5.72%。可见,所提方法减少线程束分化的效果更好。
DCU;单指令多线程;线程束分化;复杂控制流;编译优化
0 引言
国产DCU (Deep Computer Unit)[1]的单指令多线程(Single Instruction Multiple Thread, SIMT)并行执行模型采用锁步的机制,使一个线程束在某一时刻只能有一个活跃的程序计数器(Program Counter, PC)。但是,在很多通用的并行应用程序中存在频繁的分支指令和不规则的数据访问,导致非一致的控制流行为,此时线程束中的线程根据相应分支指令的执行结果选择不同的执行路径。由于线程束中的所有线程在某一周期内必须执行相同的指令,因此在遇到非一致控制流的情况下线程束中的线程只能串行执行,即线程束分化。
图1为非一致控制流的执行示例,图1(a)是分支转移的控制流结构,其中:每个方块代表一个基本块,基本块中每位数字表示一位掩码位,代表对应的单指令多数据流(Single Instruction Multiple Data, SIMD)通道:“1”表示该通道上有活跃线程执行,“0”表示该通道空闲。图1(b)展示了图1(a)中的线程在通道中的具体执行情况。从图1(b)中可以看出,当出现线程束分化时,SIMD通道不能满负载运行,并且线程束中的线程串行执行,导致计算资源的利用率低,严重制约了性能。如在极端情况下,若线程束中的64个线程均执行不同的分支路径,则理论上性能将降低为原来的1/64。因此,有必要研究减少线程束分化时间的优化技术。
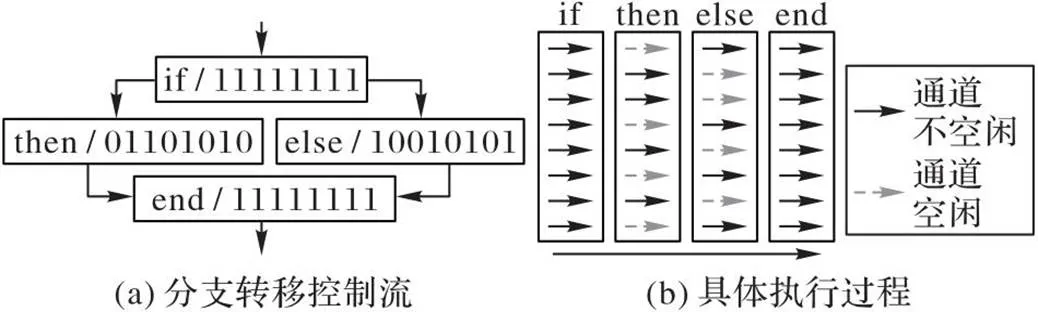
图1 非一致控制流执行示例
减少线程束分化时间,就是减少线程串行执行的时间,即压缩每个分支单独运行的时间。在传统的编译优化技术中,减少线程束分化时间的主要方法是分支融合[2]和尾合并[3]。
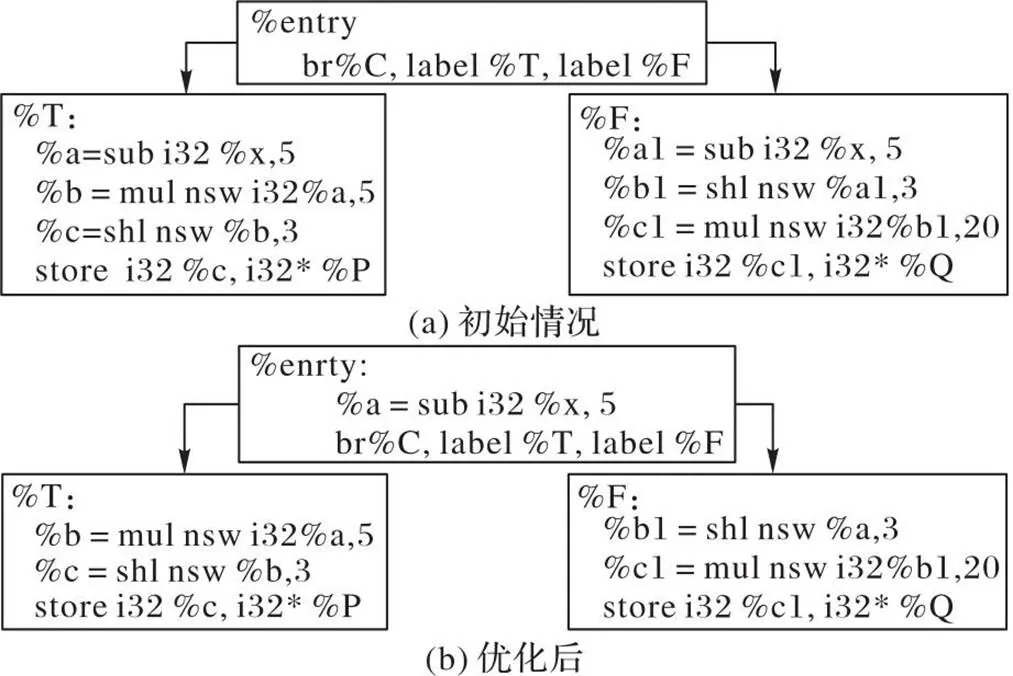
图2 分支融合示例
从图2~3可以看出,分支融合和尾合并的实现条件较严苛,只对简单的控制流有一定的优化作用;然而,较多通用的并行应用程序都有着非常复杂的控制流,传统的编译优化技术并不能较好地解决这些问题。
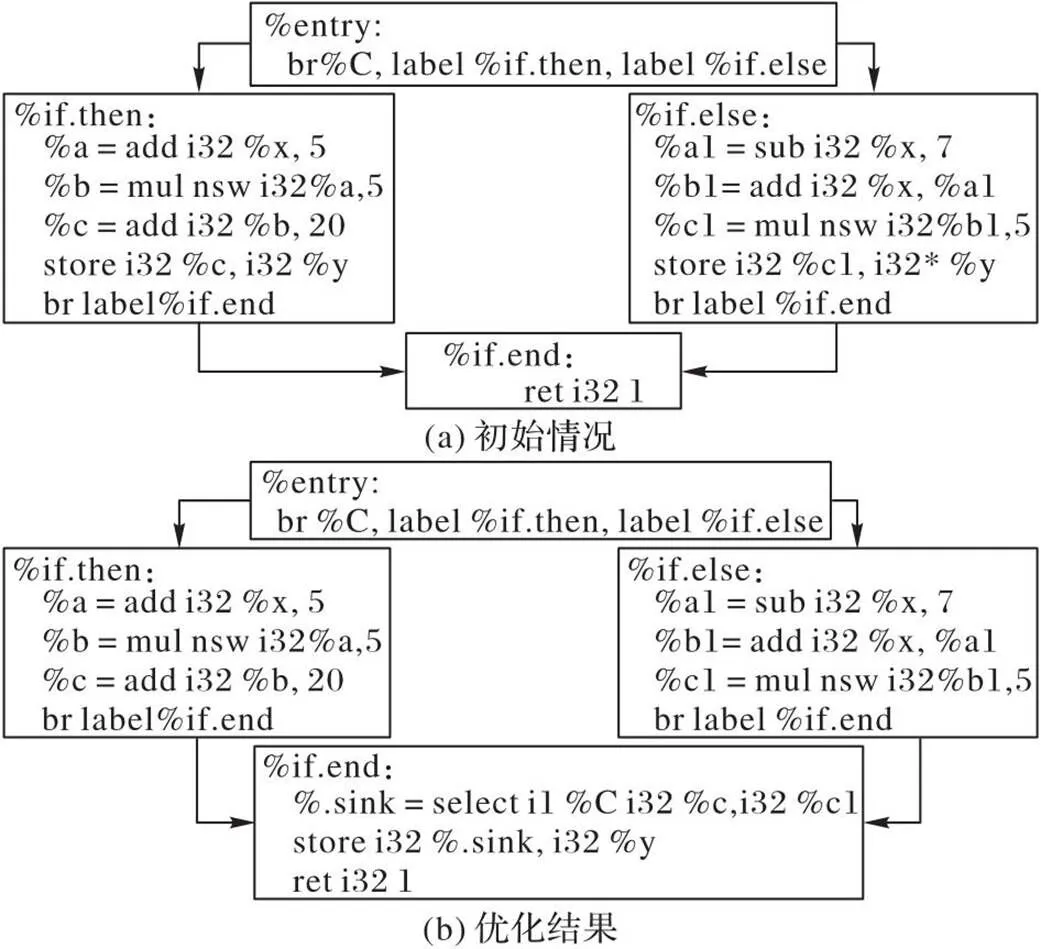
图3 尾合并示例
针对非一致控制流严重制约核函数性能的问题,本文提出一种减少线程束分化时间的编译优化方法——部分控制流合并(Partial-Control-Flow-Merging, PCFM)。该方法面向基本块和区域,合并发散控制流中拥有大量相同指令和相似指令的基本块‒基本块、区域‒区域。与分支融合和尾合并方法仅提升和下沉相同指令相比,PCFM的适用范围更广、融合区域更大,可以有效减少线程束分化的时间,提高活跃线程数。
本文的主要工作如下:
1)分析核函数中的复杂控制流,识别同构且含有大量相同指令和相似指令的可融合的发散区域。
2)统计合并后节省的指令周期百分比,计算融合盈利,评估可融合发散区域。
3)使用分层序列对比方法查找对齐序列,对有收益的可融合发散区域实现部分控制流的合并。
1 相关知识
异构系统架构(Heterogeneous System Architecture, HSA)在超级计算机系统中得到了广泛的使用,我国自主研发的新一代超级计算机“嵩山”超级计算机系统采用中央处理器(Central Processing Unit, CPU)+图形处理器(Graphics Processing Unit, GPU)异构体系结构[4]。
1.1 异构系统架构
异构系统架构(HSA)是将通用计算单元(Compute Unit, CU)和专用计算单元结合以加快处理速度的一种新兴架构。异构计算表示在异构系统上进行并行计算,异构计算根据计算任务的特点选择适合的架构,使架构的优势得到充分的发挥,更好地提升性能。在众核异构系统中,CPU+GPU异构系统的适用范围广且能效比较优,已经成为了主流架构,并在超级计算机系统中得到广泛的应用。
1.2 海光一号DCU加速器
我国自主研发的新一代超级计算机“嵩山”超级计算机系统采用海光一号CPU+海光一号DCU加速器的异构体系结构。“嵩山”超级计算机系统配备的海光一号DCU加速器是一种通用图形处理器(General Purpose Graphics Processing Unit, GPGPU),每个DCU有60个CU,每个CU有64个计算核心。与CPU相比,DCU部署了大面积的CU,精简了用于逻辑判断、分支跳转和中断处理等功能的控制单元,因此DCU设备在面向多数据并行计算的问题和具有高算术密集度类型的应用上有着更强的算力。
1.3 DCU中线程组织情况
DCU对线程的组织通常分为三级:线程束(Wavefront)级、线程块(Block)级和线程网格(Grid)级。线程束是CU中基本的执行单元,线程块由多个线程(Thread)构成,多个线程块构成了线程网格。在具体执行时,当一个线程块所在的网格被启动后,该网格中的线程块将分布在CU中,一旦线程块被调度到一个CU上,线程块中的线程会被进一步划分为线程束。DCU采用三级线程层次结构,从而在线程与线程处理的数据元素之间建立映射关系,图4展示了DCU的线程层次结构。
在DCU中,一个线程束由64个连续的线程组成,在一个线程束中,所有的线程按照SIMT方式执行,即所有线程都执行相同的指令,每个线程在私有数据上操作,线程与线程之间的通信通过共享存储器和同步操作完成。
1.4 LLVM
LLVM[5]的命名最早起源于底层虚拟机(Low Level Virtual Machine, LLVM)的首字母缩写,但是随着LLVM的发展,原有的内涵发生了巨大的转变,目前LLVM为模块化和可重用的编译器以及工具链的集合。
图5展示了传统的编译器架构和LLVM架构,可以看出,LLVM架构是基于传统的三段式架构(前端、优化、后端)设计的编译器。与传统的编译器架构相比,LLVM架构可以扩展新的前端和后端,支持更多的语言和设备(如C、Fortran、X86和Power PC等)。LLVM中不同的前端后端使用统一的中间代码(LLVM Intermediate Representation, LLVM IR);优化阶段是一个通用的阶段,因此针对统一的LLVM IR,可以高度复用优化阶段的工作。本文提出的PCFM就是针对LLVM IR进行修改和优化,PCFM通过识别且合并可融合的发散区域,减少分支串行执行的时间,从而提升性能。
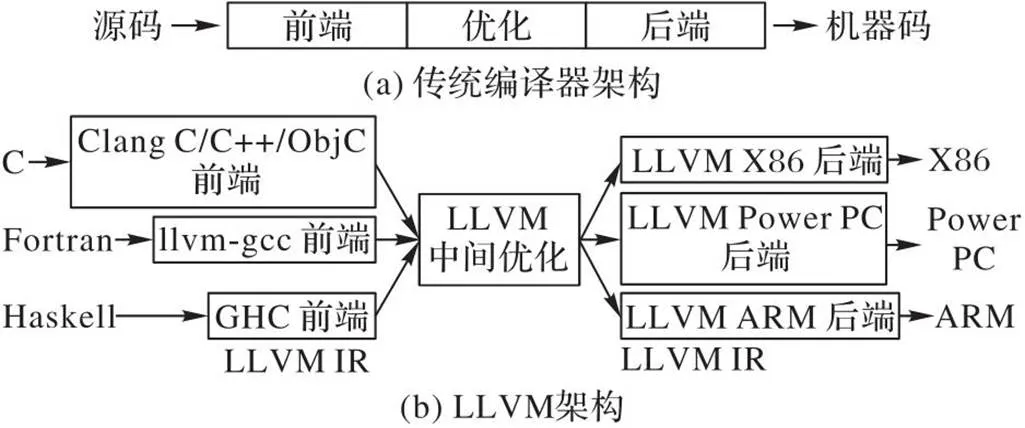
图5 传统编译器架构与LLVM架构
2 PCFM
2.1 部分控制流
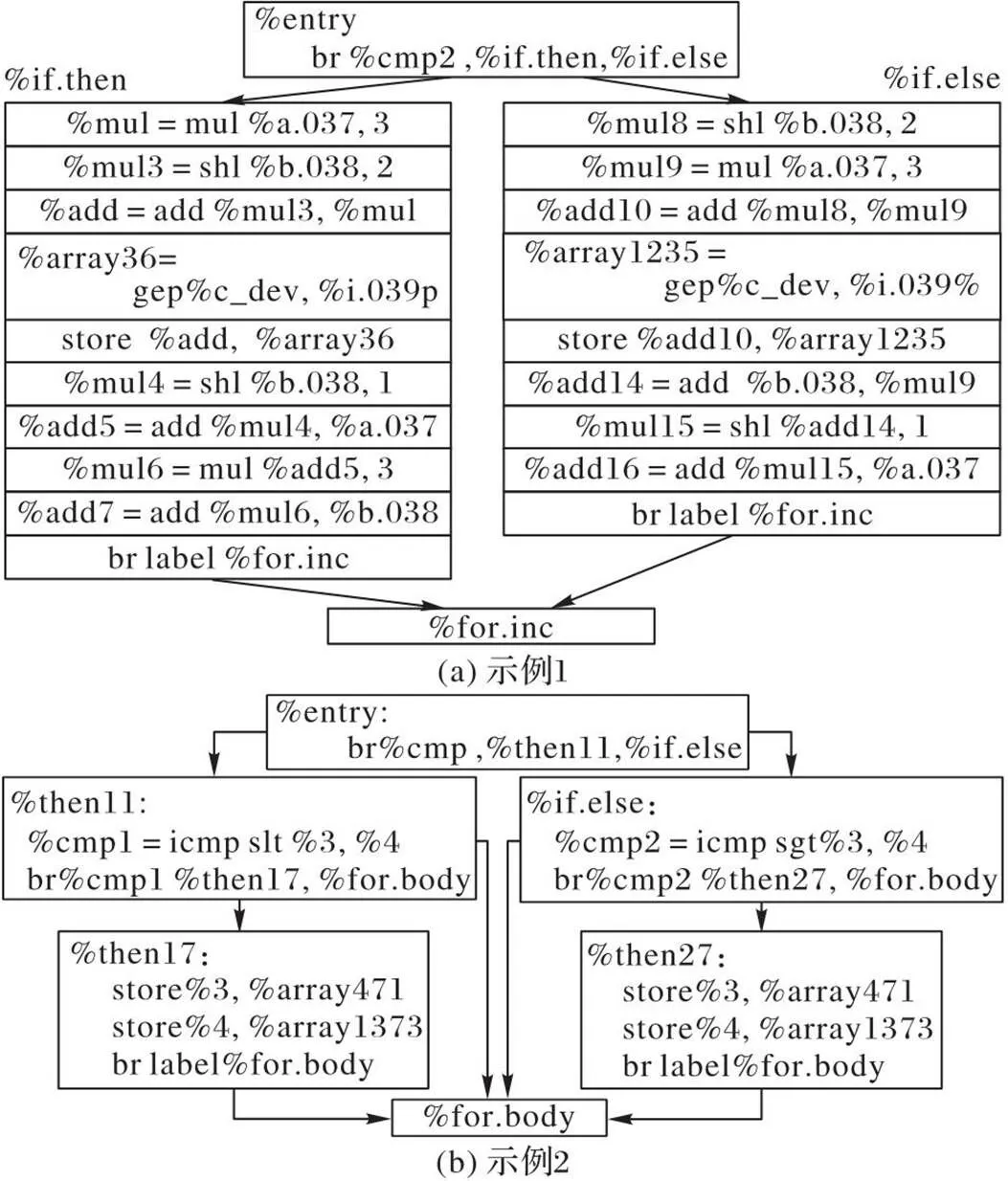
图6 复杂控制流示例
2.2 合并思想

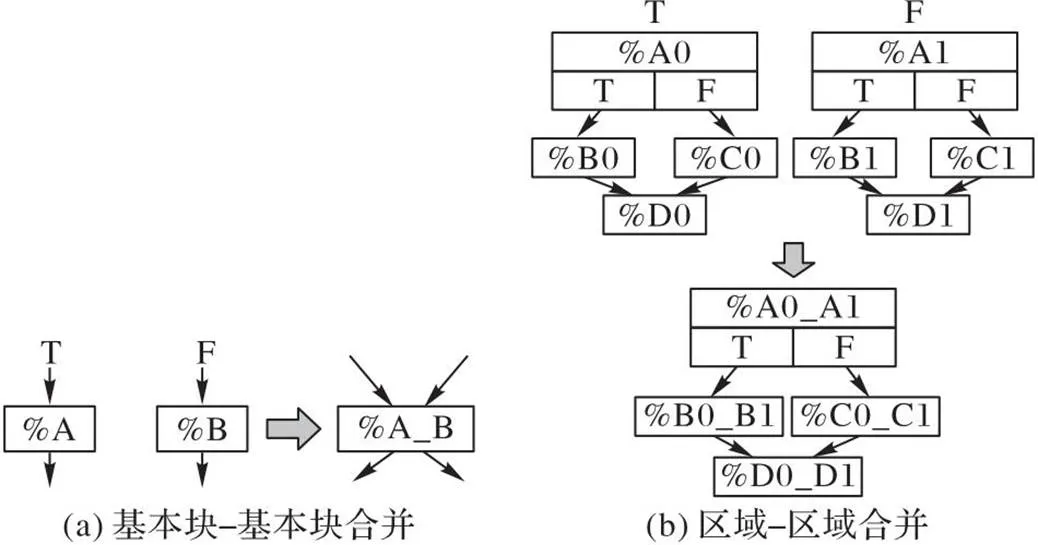
图7 合并示例
3 在编译器中的实现
PCFM主要包括4个步骤:1)识别编译器中间代码中的可融合发散区域;2)评估可融合发散区域;3)若有收益,则查找可融合发散区域的对齐序列;4)合并发散区域。
3.1 相关定义
定义2 简单区域。简单区域是CFG的子图。仅通过入口边和出口边连接剩余的CFG。
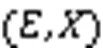
满足以上任一条件的两个单入口单出口子图均可以合并,且不会给控制流引入额外的分化。
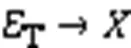
3.2 识别可融合发散区域
通过散度分析[6]识别程序中的发散区域。如图8所示,若线程束中不同线程分支条件的计算值不一致,则认为线程束在这个分支条件下是发散的,对该分支条件作一个发散标记。如果分支条件依赖于数据或发散变量,如线程ID[7],后续需要对它进行更加复杂的散度分析[8]。包含一个发散分支的最小CFG区域就是该分支对应的发散区域,在找到发散区域后根据定义5找到可融合发散区域。

图8 散度分析流程
3.3 评估可融合发散区域
找到可融合发散区域后,通过计算融合盈利值评估合并后的性能,根据评估的结果决定是否合并。
融合盈利计算分为基本块的融合盈利计算和区域的融合盈利计算。它们的核心思想都是考虑在最佳情况下(即不考虑指令的执行顺序),两个基本块或两个区域融合后节省的指令周期百分比。
3.4 查找对齐序列
为了保证合并后的正确性,PCFM在确保操作相对顺序不变的情况下融合具有相同操作码和兼容操作数类型的指令序列,其中操作码相同、操作数兼容的指令称为相似指令。查找对齐序列[9]是查找在操作相对顺序上保持一致的相似指令序列。若能在可融合发散区域中找到最大数量的对齐序列进行合并,则可以节省的指令周期百分比最大。
PCFM使用史密斯‒沃特曼算法[10]计算可融合发散区域中指令的最佳对齐方式。在史密斯算法中,相似指令被认为是可以对齐的指令,具有较高延迟的指令对齐优先于具有较低延迟的指令对齐。此外,该算法对未对齐的指令也使用了间歇惩罚以处理它产生的额外分支,并且可融合发散区域合并算法与指令对齐算法之间相互独立。
史密斯算法计算指令对齐序列分为两个步骤:首先建立一个盈利矩阵,计算每对指令的盈利值;其次反向遍历盈利矩阵,找到指令的最佳对齐方式。
盈利矩阵的计算公式如下:
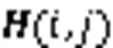

图9 指令对齐算法
3.5 合并可融合发散区域
得到融合盈利和指令对齐序列后,合并可融合发散区域[11]。指令对齐序列的合并分为指令对齐和指令非对齐这两种情况,针对不同的情况采取不同的合并措施。

图10 复杂控制流示例1对齐指令的合并

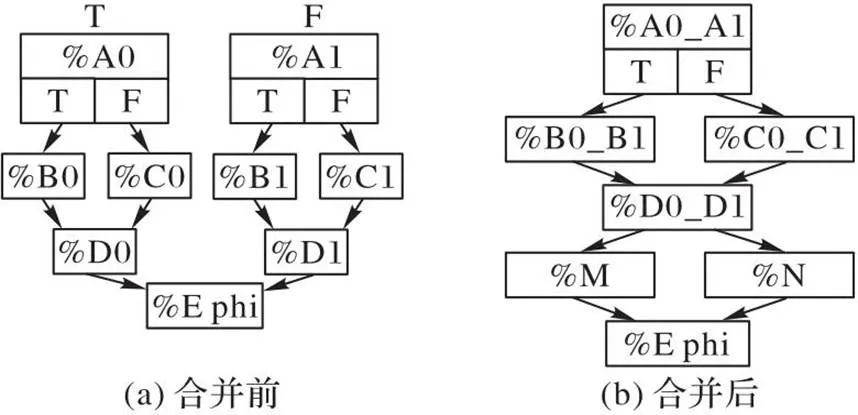
图12 退出块的合并
在基本块合并的过程中会引入具有相同后继节点的分支、冗余的phi指令,针对这些情况后续会对它们进行消除。
算法1 子图合并核心算法。
BuildNewBlock()
else{
RunPostOptimizations()
3.6 PCFM的核心算法
图13展示了复杂控制流示例1应用PCFM后每个阶段的转换情况。

图13 PCFM的核心算法的应用
算法2 PCFM核心算法。
do{
4 实验与结果分析
在LLVM 12.0.0版本编译器中实现针对非一致控制流的PCFM,并使用单节点、单DCU测试该方法的优化效果。
4.1 基准程序
采用的测试集取自GPU基准测试套件Rodinia[13]和经典的排序算法程序。选取了7个适用于PCFM的测试用例。
1)BITonic sort (BIT)[14]。排序网络中一种比较顺序和数据无关的算法,适合并行运算。
2)Speckle Reducing Anisotropic Diffusion (SRAD)[13]。取自基准测试套件Rodinia,是一种基于偏微分方程的扩散算法,用于在不牺牲图像重要特征的情况下去除图像中的散斑,广泛应用于超声波和雷达成像领域。
3)MergeSort (MS)。建立在归并操作上的一种有效的排序算法,通过并行的自下而上的合并排序实现,其中,合并的核函数包含依赖于数据的非一致性控制流。
4)N-QUeens (NQU)。使用回溯法找到将个Queens放置在×棋盘上并且不会相互攻击的所有方式,使用的核函数来自GPGPU-sim[15]基准套件,为15。
5)Partition and Concurrent Merge (PCM)[16]。一种基于奇偶合并排序的并行排序算法。PCM在数组的每个位置对已排序的元素执行奇偶合并,导致具有嵌套数据依赖分支的循环,给减少线程束分化算法提供了机会。
6)LU-Decomposition (LUD)[13]。取自基准测试套件Rodinia中,是矩阵分解的一种,主要应用于数值分析,复杂控制流减少线程束分化重点评估lud_perimeter内核。
7)DCT quantization (DCT)(https://docs.nvidia.com/cuda/cuda-samples)。离散余弦变换,把目标信号从复杂的时域信号分解为不同频率强度的频域信号,主要用于数据和图像的压缩中。
4.2 测试结果
选取的7个测试用例的内核中线程块的大小都可以调节。在某些情况下,线程块大小对线程束分化的影响较大,因此在测试过程中考虑了每个内核在不同块大小情况下使用PCFM的性能。表1展示了7个测试用例分别使用无控制流优化、分支融合[2]+尾合并[3]和PCFM的性能对比,并以无控制流优化的性能作为基准,且无控制流优化下所有测试用例的加速比均为1.000。
从表1可以发现,PCFM对选取的所有测试用例的平均加速比为1.146,分支融合+尾合并对选取的所有测试用例的加速比为1.084,因此PCFM的优化能力更强,加速比平均提高了5.72%。BIT和SRAD使用PCFM的加速效果最显著,这是因为在BIT和SRAD中存在大量的可融合发散区域,PCFM能够有效合并这些可融合发散区域,大幅提升性能。LUD的散度取决于块的大小,当LUD块的大小为16、32和64时会产生线程束分化,此时PCFM的优化效果明显优于分支融合+尾合并。
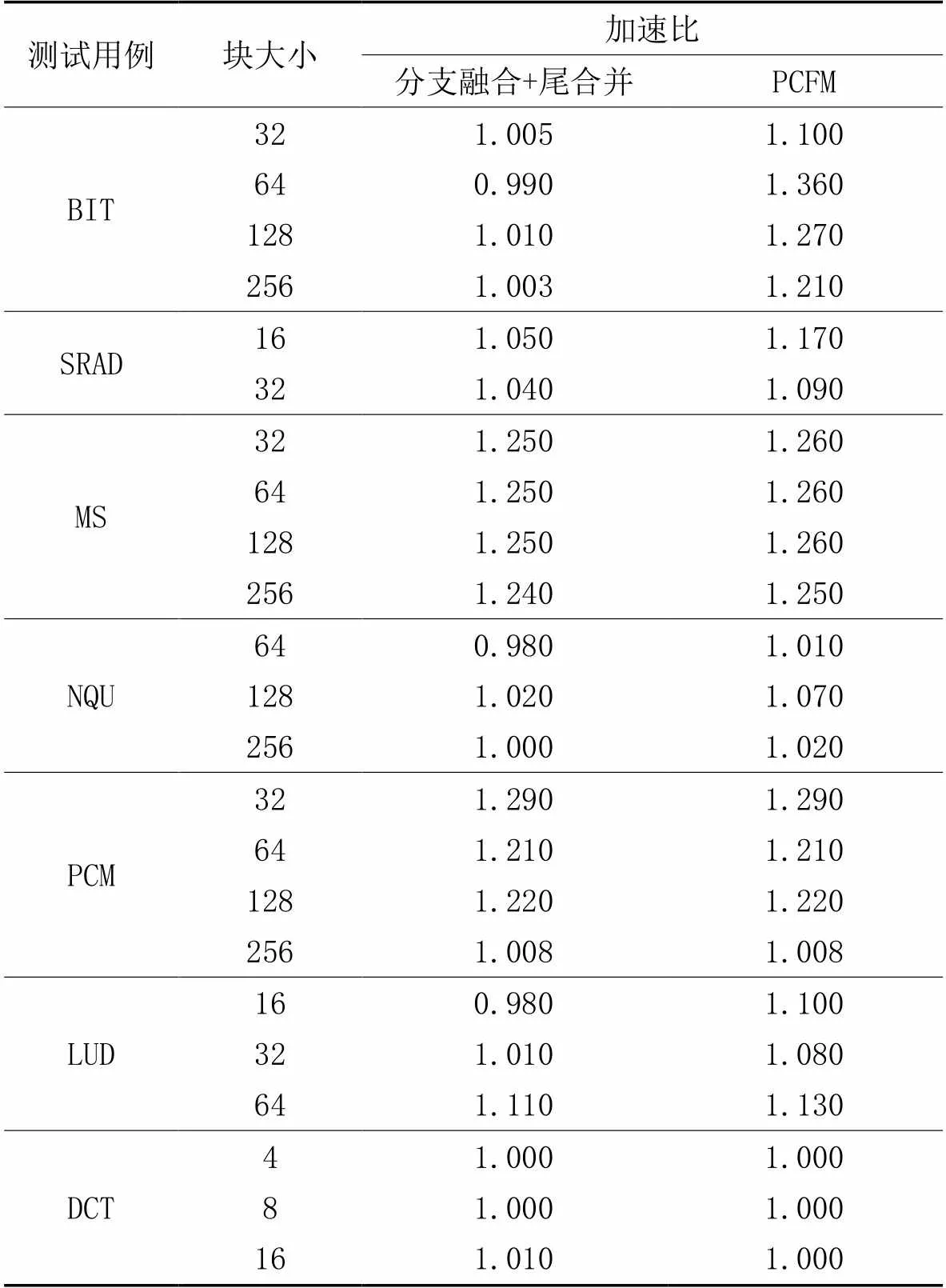
表1 不同算法的加速比性能对比
融合阈值决定了可融合发散区域合并的力度。表2为在实际的基准测试中融合阈值对性能的影响,7个测试用例选取的块大小均为最佳性能下的块大小。可以看出,并不是融合阈值越大性能越好,随着融合阈值的增大,会损失一部分的合并机会,但也不能将它完全置为0,因为这会导致不考虑融合盈利而将所有的可融合发散区域都进行合并。
4.3 性能分析
通过测试发现PCFM对性能的提升显著,本节使用性能分析工具分析性能提升的原因。
表3展示了7个测试用例的归一化共享内存指令数的情况。BIT和PCM的可融合发散区域中包含了大量的共享内存指令,PCFM合并这些共享内存指令,使性能得到了显著的提升。DCT没有使用共享内存,所以共享内存的指令个数为0。共享内存指令比大部分的ALU指令的延迟更高,因此合并共享内存指令对性能的提升更为明显。
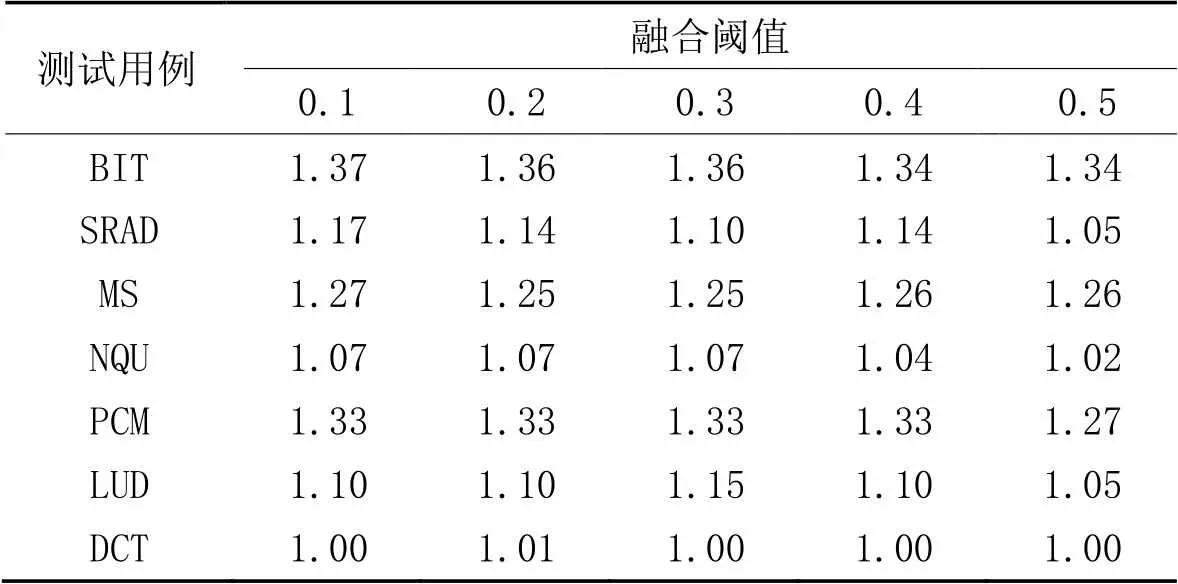
表2 不同融合阈值下的加速比

表3 不同算法的归一化共享内存指令数
5 结语
本文面向DCU平台分析了大量核函数中存在的复杂控制流,针对非一致控制流提出了优化方法PCFM,并在编译器中实现了该方法。PCFM通过检测、评估和合并不同路径中的同构区域提升性能,与传统减少线程束分化的优化方法分支融合+尾合并相比,PCFM的适用范围更广,减少线程束分化的效果更好。
目前PCFM的优化方法只针对同构区域进行合并,在分析核函数中的复杂控制流时,很多不具备同构性质的区域也存在合并的可能性,因此在未来的工作中准备从非同构区域入手,扩大方法的适用范围。
[1] 胡伟方. 面向DCU的多面体编译优化技术研究[D]. 郑州:郑州大学, 2021: 11-19.(HU W F. Research on DCU-oriented polyhedron compiler optimization technology[D]. Zhengzhou: Zhengzhou University, 2021:11-19.)
[2] HOLZINGER P, REICHENBACH M, FEY D. A new generic HLS approach for heterogeneous computing: on the feasibility of high-level synthesis in HSA-compatible systems[C]// Proceedings of the 18th International Conference on Embedded Computer Systems: Architectures, Modeling, and Simulation. New York: ACM, 2018: 18-27.
[3] CHEN W K, LI B G, GUPTA R. Code compaction of matching single-entry multiple-exit regions[C]// Proceedings of the 2003 International Static Analysis Symposium, LNCS 2694. Berlin: Springer, 2003: 401-417.
[4] COUTINHO B, SAMPAIO D, PEREIRA F M Q, et al. Divergence analysis and optimizations[C]// Proceedings of the 2011 International Conference on Parallel Architectures and Compilation Techniques. Piscataway: IEEE, 2011: 320-329.
[5] LATTNER C, ADVE V. LLVM: a compilation framework for lifelong program analysis & transformation[C]// Proceedings of the 2004 International Symposium on Code Generation and Optimization. Piscataway: IEEE, 2004: 75-86.
[6] HAN T D, ABDELRAHMAN T S. Reducing branch divergence in GPU programs[C]// Proceedings of the 4th Workshop on General Purpose Processing on Graphics Processing Units. New York: ACM, 2011: No.3.
[7] KARRENBERG R, HACK S. Improving performance of OpenCL on CPUs[C]// Proceedings of the 2012 International Conference on Compiler Construction, LNCS 7210. Berlin: Springer, 2012: 1-20.
[8] ROSEMANN J, MOLL S, HACK S. An abstract interpretation for SPMD divergence on reducible control flow graphs[J]. Proceedings of the ACM on Programming Languages and Systems, 2021, 5(POPL): No.31.
[9] ROCHA R C O, PETOUMENOS P, WANG Z, et al. Function merging by sequence alignment[C]// Proceedings of the 2019 IEEE/ACM International Symposium on Code Generation and Optimization. Piscataway: IEEE, 2019: 149-163.
[10] SMITH T F, WATERMAN M S. Identification of common molecular subsequences[J]. Journal of Molecular Biology, 1981, 147(1): 195-197.
[11] ROCHA R C O, PETOUMENOS P, WANG Z, et al. Effective function merging in the SSA form[C]// Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation. New York: ACM, 2020: 854-868.
[12] CYTRON R, FERRANTE J, ROSEN B K, et al. Efficiently computing static single assignment form and the control dependence graph[J]. ACM Transactions on Programming Languages and Systems, 1991, 13(4):451-490.
[13] CHE S, BOYER M, MENG J, et al. Rodinia: a benchmark suite for heterogeneous computing[C]// Proceedings of the 2009 IEEE International Symposium on Workload Characterization. Piscataway: IEEE, 2009: 44-54.
[14] BATCHER K E. Sorting networks and their applications[C]// Proceedings of the 1968 Spring Joint Computer Conference. New York: ACM, 1968: 307-314.
[15] BAKHODA A, YUAN G L, FUNG W W L, et al. Analyzing CUDA workloads using a detailed GPU simulator[C]// Proceedings of the 2009 IEEE International Symposium on Performance Analysis of Systems and Software. Piscataway: IEEE, 2009: 163-174.
[16] HERRUZO E, RUÍZ G, BENAVIDES J I, et al. A new parallel sorting algorithm based on odd-even mergesort[C]// Proceedings of the 15th EUROMICRO International Conference on Parallel, Distributed and Network-Based Processing. Piscataway: IEEE, 2007: 18-22.
Compilation optimizations for inconsistent control flow on deep computer unit
YANG Xiaoyi1,2, ZHAO Rongcai1,2, WANG Hongsheng2*, HAN Lin1,2, XU Kunkun1,2
(1,,450001,;2,450001,)
The domestic DCU (Deep Computer Unit) adopts the parallel execution model of Single Instruction Multiple Thread (SIMT). When the programs are executed, inconsistent control flow is generated in the kernel function, which causes the threads in the warp be executed serially. And that is warp divergence. Aiming at the problem that the performance of the kernel function is severely restricted by warp divergence, a compilation optimization method to reduce the warp divergence time — Partial-Control-Flow-Merging (PCFM) was proposed. Firstly, divergence analysis was performed to find the fusible divergent regions that are isomorphic and contained a large number of same instructions and similar instructions. Then, the fusion profit of the fusible divergent regions was evaluated by counting the percentage of instruction cycles saved after merging. Finally, the alignment sequence was searched, the profitable fusible divergent regions were merged. Some test cases from Graphics Processing Unit (GPU) benchmark suite Rodinia and the classic sorting algorithm were selected to test PCFM on DCU. Experimental results show that PCFM can achieve an average speedup ratio of 1.146 for the test cases. And the speedup of PCFM is increased by 5.72% compared to that of the branch fusion + tail merging method. It can be seen that the proposed method has a better effect on reducing warp divergence.
Deep Computer Unit (DCU); Single Instruction Multiple Thread (SIMT); warp divergence; complex control flow; compilation optimization
This work is partially supported by Major Science and Technology Special Project of Henan Province (221100210600).
YANG Xiaoyi, born in 1997, M. S. candidate. Her research interests include advanced compilation technology.
ZHAO Rongcai, born in 1957, Ph. D., professor. His research interests include advanced compilation technology, high-performance computing.
WANG Hongsheng,born in 1994, M. S. His research interests include advanced compilation technology, high-performance computing.
HAN Lin, born in 1978, Ph. D., associate professor. His research interests include advanced compilation technology, high-performance computing.
XU Kunkun, born in 1991, M. S. candidate. His research interests include advanced compilation technology.
1001-9081(2023)10-3170-08
10.11772/j.issn.1001-9081.2022091338
2022⁃09⁃12;
2022⁃12⁃21;
河南省重大科技专项(221100210600)。
杨小艺(1997—),女,河南南阳人,硕士研究生,主要研究方向:先进编译技术; 赵荣彩(1957—),男,河南洛阳人,教授,博士,CCF会员,主要研究方向:先进编译技术、高性能计算; 王洪生(1994—),山东滨州人,硕士,主要研究方向:先进编译技术、高性能计算; 韩林(1978—),男,山东临沂人,副教授,博士,CCF会员,主要研究方向:先进编译技术、高性能计算; 徐坤坤(1991—),男,河南信阳人,硕士研究生,主要研究方向:先进编译技术。
TP314
A
2022⁃12⁃25。
