基于YOLO的无约束场景中文车牌检测与识别
2023-10-21陈子昂李清都万里红
陈子昂,刘 娜,袁 野,李清都,万里红
(1.上海理工大学 健康科学与工程学院,上海 200093; 2.上海交通大学 电子信息与电气工程学院,上海 2000093;3.上海理工大学 光电信息与计算机工程学院,上海 200093; 4.中原动力智能机器人有限公司,河南 郑州 450018)
随着交通业与人工智能的迅速发展,越来越多的研究人员开始关注人工智能技术在交通运输业中的应用[1]。车牌识别是这一领域的研究热点之一,实现车牌识别主要分为车牌定位和车牌字符识别两大步骤。车牌定位分为车牌检测与车牌矫正两个步骤。传统的车牌检测方法主要分为基于边缘的车牌检测、基于颜色的车牌检测、基于纹理的车牌检测和基于字符的车牌检测[2]4类。
文献[3]提出基于Canny算子的边缘检测方法检测车牌,结合Hough变换来识别车牌的水平和垂直边界线。该算法速度较快,但对于模糊图像的检测效果不够理想。文献[4]利用HSV(Hue,Saturation,Value)空间颜色模型与直方图基于颜色来检测车牌,但该算法易受光照、车身颜色等因素影响。文献[5]提出利用Haar特征基于图像纹理的车牌检测方法。该算法对车牌的亮度、颜色大小的变换具有一定鲁棒性,但对场景要求严格,在无约束场景下精度欠佳。基于字符的车牌检测与上述方法类似,检测目标为特征更明显的字符,更易受亮度、颜色等因素的影响。
车牌矫正是检测出车牌候选区域后的后处理步骤。检测得到的车牌区域伴随一定程度的倾斜,影响后续识别步骤的精确度,所以需要对检测得到的车牌图像进行矫正。传统方法使用基于HSV颜色空间和Hough变换的边缘检测得到倾斜角度,结合仿射变换对车牌进行矫正,但该方法对图像质量要求较高,在无约束场景下效果不佳。
目前,基于卷积神经网络的深度学习方法在计算机视觉领域效果显著,尤其在目标检测领域,单阶段目标检测网络YOLO系列是该领域的代表。
本文提出了一种改进的YOLOv5算法用于车牌检测以及后续的车牌矫正,在无约束场景下仍具有高精度的检测效果。该方法通过在COCO数据集上训练的预训练模型减少了在无约束场景下由于图像背景复杂而产生的误检问题,并在检测出车牌候选区域的基础上多预测4个关键点用于车牌矫正。本文所提算法对于光照、倾斜、模糊等由环境诱发的影响因素具有较高的鲁棒性。
传统的车牌字符识别方法分为字符分割和单字符识别两个步骤,先通过支持向量机、投影和模板匹配等方法分割字符[6],再执行逐个字符的识别。这种基于字符分割的方法易受光照条件等环境因素影响且实时性较差。
目前国内大多数车牌识别方法仍是较为传统的基于字符分割的方法,这些方法的准确率约为86.4%,在复杂的环境里仍存在较大的局限性,检测性能也较低[7]。随着深度学习在计算机视觉领域的流行,基于字符无分割的方法逐渐成为主流。该方法通过神经网络模型端对端直接识别车牌图片并返回字符串。目前较常用的CRNN网络在理想条件下的准确率可达98.5%。但CRNN网络模型本身需要一定的计算量,边缘设备的部署也是一大难题。因此,若要在无约束环境进行车牌识别,使用轻量级网络模型并将其部署在边缘设备是必要条件。
本文提出了一种改进的CRNN模型,对车牌识别任务进行了优化,减少了网络的计算量,在不减少预测精度的前提下使其能够被部署在边缘设备中。同时,由于在开源数据集CCPD(Chinese City Parking Dataset)[8]中各省份车牌数据存在类别不平衡的现象,本文还设计了一种车牌数据的生成方法。
1 车牌检测
本文提出的车牌检测与矫正方法设计主要包括数据集的制作以及模型的设计两部分,整体流程如图1所示。
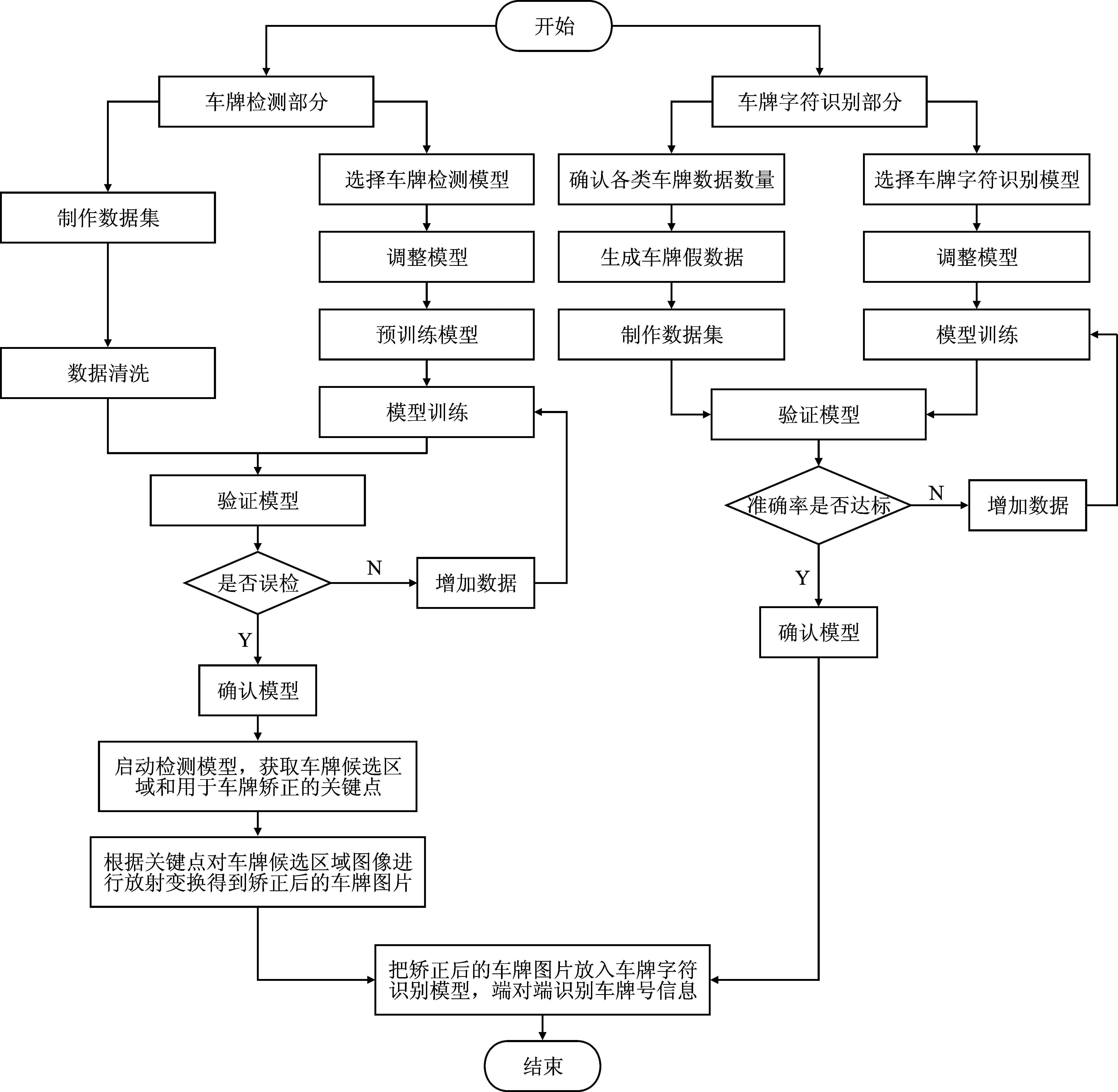
图1 设计流程Figure 1. Flow of the proposed design
1.1 数据集
本文采用CCPD数据集进行车牌检测部分的训练。CCPD数据集是开源的中文车牌数据集,在合肥街道采集完成。该数据集总体分为蓝牌普通车牌图片和绿牌新能源车牌图片两大类,包含在不同天气、位置以及角度拍摄到的车牌图片,共363 753张图片。
图2是各类数据在CCPD数据集下的占比。Base代表正常拍摄车牌,FN代表拍摄时距离摄像头相当远或者相当近,DB代表拍摄时光线暗或者比较亮,Rotate代表水平倾斜20°~25°、垂直倾斜-10°~10°拍摄,Tilt代表水平倾斜15°~45°、垂直倾斜15°~45°拍摄,Weather代表在雨天、雪天或者雾天拍摄,Blur代表在相机抖动时拍摄,Challenge代表其他具有挑战性的车牌,NP代表没有车牌的新车。
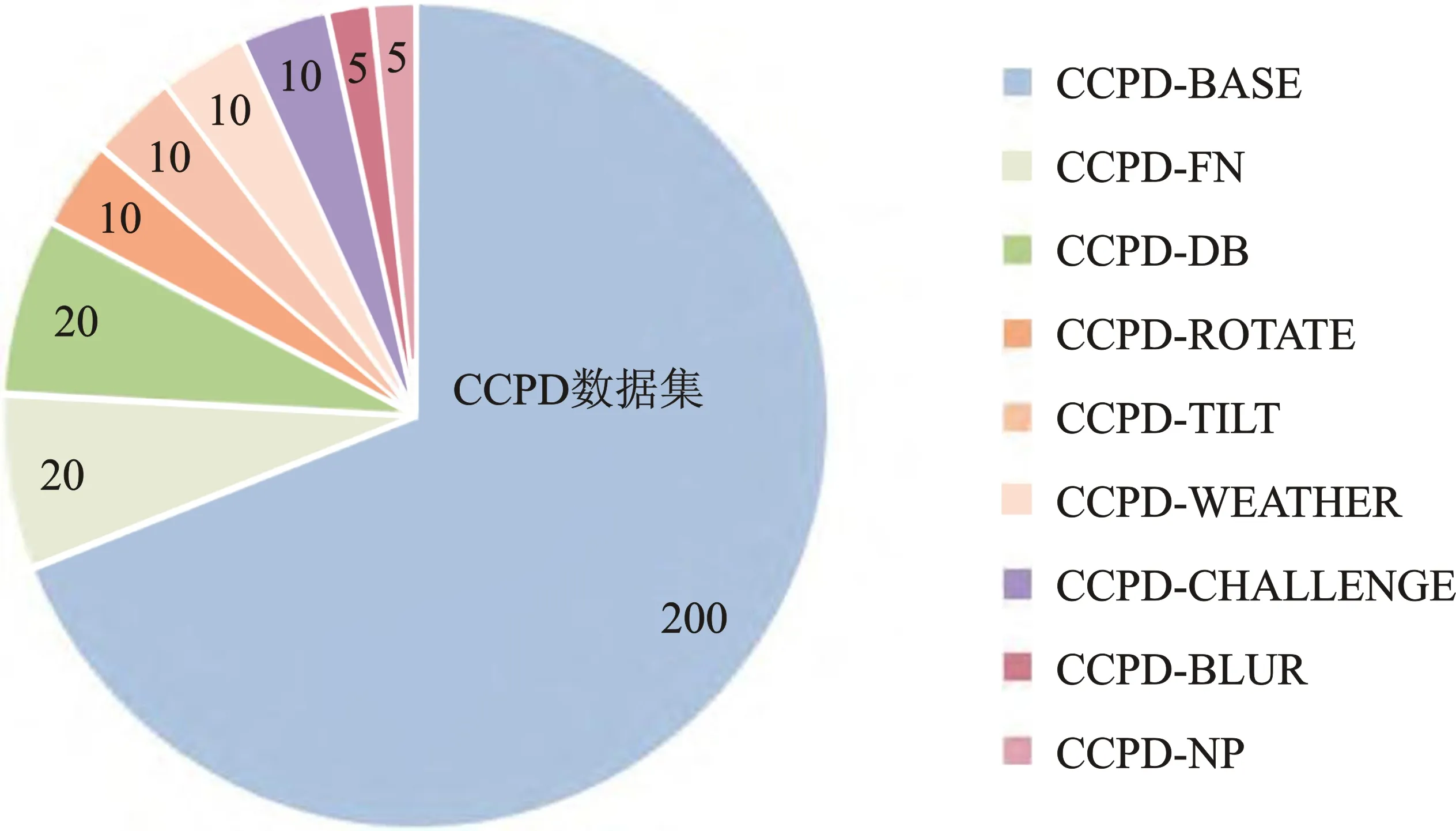
图2 各类数据在CCPD数据集下的占比Figure 2. The proportion of different types data in the CCPD data set
本文选取各类车牌图片共5 000张作为测试集,其余全部用于训练。在训练步骤,本文使用在COCO数据集训练的预训练模型进行训练,可以大幅减少在各种背景下的误检现象。
1.2 改进的YOLOv5模型设计
YOLO[9]将目标检测看作为一个回归问题进行求解,仅一次求解便可以得到图像中所有物体的位置、类别以及相应的置信概率[10]。结果表明,该算法不仅具有良好的检测性能,还具备高实时性。此外,YOLO具有良好的泛化能力,易进行训练,以便有效地检测不同的目标。YOLO算法已经升级了5个版本[11],其中YOLOv3通过引入FPN(Feature Pyramid Network)[12]、Darknet53以及使用二进制交叉熵损失取代Softmax分类损失,大幅提升了算法的性能和速度。相较于YOLOv3算法,YOLOv4在主干网络、损失函数和数据增强等方面均有所改进[13]。相较于早期版本,YOLOv5的模型尺寸显著减小,速度更快,性能与YOLOv4相似。
本文所使用的检测模型整体结构如图3所示。CBS(Conv+Bn+SiLU)模块是融合了批量归一化并使用SiLU激活函数的卷积层。Foucs模块将原始图像按照横纵坐标方向各做一次二倍间隔采样后,结合CBS模块进行特征提取,相比传统卷积层降低了计算量与参数量。SPP(Spatial Pyramid Pooling)模块使用各种步长的池化层获取多尺度特征并进行拼接,解决了网络输入图像尺寸不统一的问题。C3模块是结合了残差连接的多个CBS模块,可避免网络训练时梯度消失的问题。组件的详细结构如图4所示。
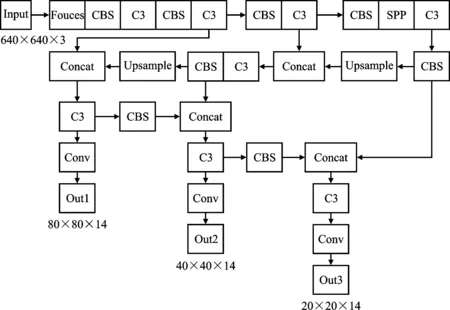
图3 YOLOv5网络主体结构Figure 3. The main structure of YOLOv5 network
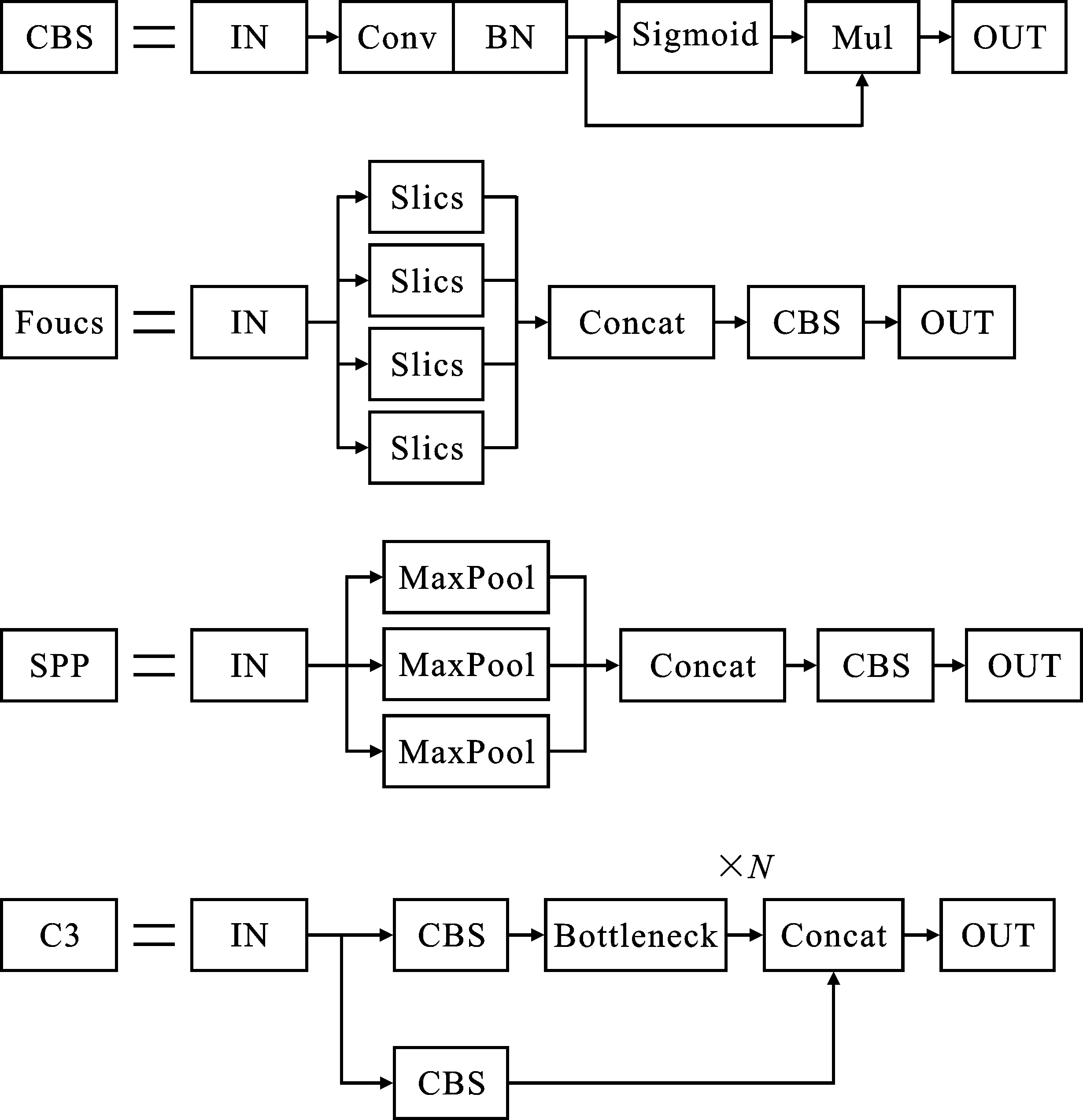
图4 YOLOv5各组件详细结构Figure 4. Structure of YOLOv5 components
本文基于YOLOv5模型做了以下改进:本文在YOLOv5的基础上加入了预测4组坐标点的逻辑回归,使其能够在预测车牌候选区域的同时预测4组landmark关键点坐标并将其用于车牌矫正。本文重组了模型的输出,新的结构如图5所示。

图5 模型输出Figure 5. Output of model
为了使网络学习到landmark关键点坐标的特征,本文在原YOLOv5的基础上加入了机翼损失(Wing loss)[14]用于拟合landmark、优化landmark预测的精度。机翼损失可表示为
(1)
其中,正数w将非线性部分的范围限制在[-w,w];e用于约束非线性区域的曲率;C=w-wln(1 +x/e),是一个常数,用于连接分段的线性和非线性部分。本文实验验证将w设置为10,将e设置为2时效果最佳。此时,设网络预测的landmark的集合为向量s= {si}。设landmark的真实值集合为s′= {si},当i为1,2,…,8时,landmark的损失函数如式(2)所示。
(2)
假设原YOLOv5的损失函数为lossO,用于学习bbox(检测框)、类别、置信度,则现在新的损失函数如式(3)所示。
loss=lossO+lossL
(3)
2 车牌识别
车牌识别方法分为基于字符分割和无需字符分割两种,其中基于字符分割的方法通常使用边缘检测、模板匹配等方法分割车牌图片中的单个字符,再使用卷积神经网络(Convolutional Neural Network,CNN)对该字符进行分类,但该方法受光照等外界条件影响较大。随着新能源车辆在我国的推广,6位数字的新能源车牌在我国越来越常见,模板匹配等字符分割方法受外界条件影响较大,易产生误差[15]。因此,本文采用OCR(Optical Character Recognition)神经网络端对端且无需字符分割的方法对车牌照进行识别。此外,本文还选择使用CRNN神经网络模型,并对其进行改进。
CRNN[16]主要用于端到端地对不定长的文本序列进行识别。与传统方法相比,CRNN不用先把图片切割为多个字符,而是将文本识别转化为时序依赖的序列学习问题,从而基于图像的序列进行识别。整个CRNN网络结构包含3部分,从上到下依次为:CNN部分、RNN(Recurrent Neural Networks)部分和LOSS部分。在CNN部分使用卷积神经网络,对输入图像提取特征,得到特征图。在RNN部分,使用循环神经网络对特征序列进行预测。在LOSS部分计算预测标签与真实标签的损失,进行网络学习。
本文在CRNN的基础上做了以下改进:
1)原CRNN中的CNN使用VGG-16(Visual Geometry Group 16)[17]网络模型提取特征,但此模型结构较为复杂,计算量大,精度不佳,故本文采用MobileNetV3[18]替代VGG-16网络模型提取图像特征。
2)本文采用双向长短时记忆神经网络(Bi-directional Long Short-Term Memory,Bi-LSTM)模型替代原CRNN中使用的LSTM模型。Bi-LSTM由前向LSTM和后向LSTM组合而成。相比LSTM,Bi-LSTM能更好地获取上下文信息,从而提高预测的精确度。
3)本文在LOSS部分采用CTC Loss,其是OCR任务的关键,能使网络有效地学习序列特征。
2.1 CNN部分
MobileNetV3模型是优秀的轻量级模型,被广泛用于各种基于边缘设备的任务,能有效加快模型的推理速度,其整体模型结构如图6所示。

图6 MobileNetV3网络主体结构Figure 6. The main structure of MobileNetV3 network
其中,Conv_BN_HSwish模块由卷积层、批量归一化和Hardswish激活函数组成。如图6所示,bneck是MobileNetV3的主体,也是一种可选模块,由深度可分离卷积层、SE(Squeeze Excitation)注意力模块[19]、批量归一化和Hardswish激活函数组成,有large和small两种版本。不同版本的区别为模块中卷积层的层数。本文实验均使用large版本,但在实际应用中,若需部署在极端的边缘设备,亦可使用small版本。
2.2 RNN部分
本文中CRNN模型中的RNN部分使用Bi-LSTM[20]。在中文车牌中,车牌号的生成存在命名规则的,因此车牌号之间存在某种关联,例如小型新能源汽车牌号第1位必须使用字母D、F,第2位可以使用字母或数字,后4位则必须使用数字。使用Bi-LSTM能够有效地获取这种关联特征。
2.3 Loss部分
本文CRNN模型中的LOSS部分使用CTC Loss函数。在实际场景中,由于每个样本的字符数量不同、字体样式不同、字体大小不同,导致每列输出并不一定能与每个字符一一对应。文献[21]提出一种不需要对齐的Loss计算方法,即CTC Loss。对于给定的输入即RNN部分的输出x,使用最佳路径解码算法进行解码,将其转换为对应最高概率的字符串,最佳路径π的概率定义为
(4)
式中,y表示第t帧时最佳路径为π的概率。在此基础上定义映射函数B,对于一个给定的标签,其输出概率可以用式(5)描述成所有可能路径概率之和的形式。
(5)
在式(4)和式(5)得到的损失函数的基础上引入L2范数正则项以减少过拟合现象的出现,计算式为
(6)
式中,α为L2范数正则项系数,在本文中经过实验将其设为0.8可有效减少过拟合现象的出现。
2.4 车牌数据生成
开源数据集CCPD(Chinese City Parking Dataset)是目前使用最多、数据量最大的开源车牌数据集。但其数据来自于安徽省合肥市,因此数据集中皖字车牌较多,其它省份的车牌偏少,各省份车牌数据存在类别不平衡的现象,在训练车牌识别网络时会导致其它省份中文字体识别精度不佳。为缓解该问题,本文提出一种车牌图片的生成方法,结合部分线下采集车牌数据以及其它网络平台收集车牌数据以构建各类数据相对平衡的数据集。
生成数据时主要使用按模板生成的方法:首先,准备各类车牌框图片、各类车牌号字体以及污渍图片;然后,随机按规则匹配模板和车牌号字体,组成车牌;随后,加入随机的小幅度透视变换以模拟真实场景,设置饱和度、亮度、色调以模拟光照条件;最后,随机插入污渍图片并加入高斯噪声以模拟真实车牌污渍,生成车牌效果如图7所示。

图7 生成车牌图片效果Figure 7. Effects of generated license plate pictures
车牌识别数据集整体分布情况如表1所示。本文车牌识别部分数据集整合CCPD真实车牌数据以及部分线下采集数据和生成数据,共计268 743张车牌图片,分为蓝牌普通车牌和绿牌新能源车牌,各省份车牌数据相对平衡,皖字开头车牌占比最高。其中,真实车牌数据与生成车牌数据比例约为1.25∶1.00。随机按比例选取其中1 000张真实车牌图片作为测试集,确保测试集存在全部省份车牌图片,其余均用于训练。
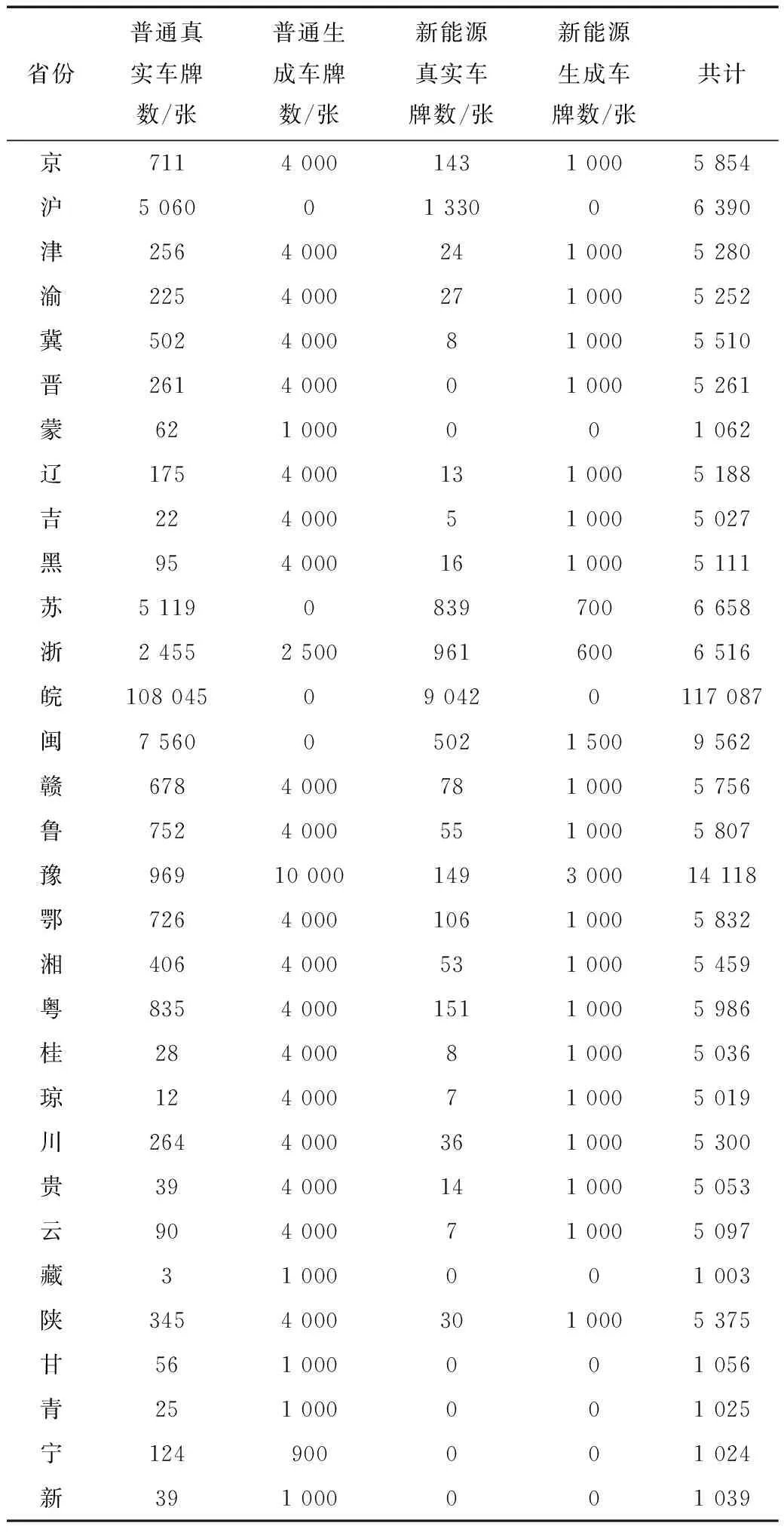
表1 车牌识别数据集整体分布Table 1. Distribution of license plate recognition data set
3 实验结果与分析
本文实验分为两组,分别对比车牌检测模型和车牌识别模型。将本文所提方法与该领域常用模型进行对比。本文网络模型的训练与实验平台为NVIDIA GeForce RTX 3090显卡平台,代码基于Python平台,模型基于Pytorch框架。
表2为车牌检测模型的对比实验结果。mAP(mean Average Precision)和召回率 (Recall)是目标检测算法中常用的评价指标。其中,mAP表示所有类别准确率-召回率曲线下面积的平均值,Recall表示检测器输出的结果中正确的个数除以正确个数与漏检个数的和,FPS表示实时帧率,1 FPS=1 frame·s-1。Retina-face[22]是经典的人脸检测模型,也是同时预测目标候选区域和关键点的常用模型之一。本文对Retina-face稍作修改,将其预测出的landmark关键点坐标从预测人脸的5组改为4组,从而使其适配于车牌检测,并以此作为对比模型与本文所提模型进行比较。本文设置初始学习率为0.01,batch size为8,迭代100次。随机选择CCPD数据集当中各类车牌图片共5 000张作为测试集。
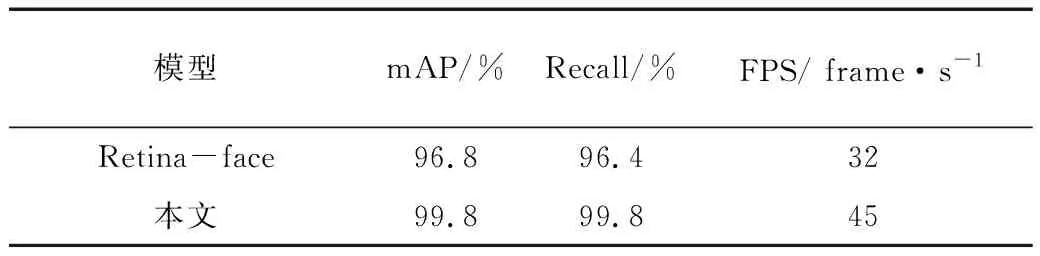
表2 本文方法与车牌检测常用模型对比Table 2. Comparison between the common license plate detection model and the proposed method
由表2可知,本文所提出的YOLOv5-plate车牌检测模型在精度方面全面优于Retina-face,其高帧率也证明了该模型适用于边缘设备。
表3为车牌识别模型的对比实验。其中,Acuracy表示准确率,即正确识别的车牌占所有车牌数量的比例,Parameter表示参数量,单位为MByte(MB)。将本文模型与未作改进的CRNN模型和LPR-Net(License Plate Recognition via Deep Neural Networks)[23]进行对比。LPR-Net专用于中文车牌识别的端对端文字识别神经网络,其轻量化的网络结构使其具备了高实时性。设置初始学习率为0.001,batch size为4,迭代100次。随机按比例选取车牌识别数据集中1 000张真实车牌图片作为测试集,确保测试集当中存在所有省份的车牌数据。

表3 本文方法与车牌识别常用模型对比 Table 3. Comparison between common license plate recognition models and the proposed method
由表3可知,本文模型比LPR-Net等模型在精确度方面有所提高,且参数量相对较少,能适应边缘设备的要求。
如图8所示,本文提出的基于无约束场景的中文车牌识别方法具有较高的鲁棒性与精确度,能够准确识别具有倾斜角度的车牌,能基本满足无约束场景下的要求。灵活的车牌识别方法也可用于安防机器人等需要在复杂环境下工作的项目。
4 结束语
传统车牌识别方法易受环境影响,在无约束场景下效果不佳,难以在边缘设备上部署。针对该问题,本文基于卷积神经网络的模型,并对其进行进一步的实验分析与改进,提出了一种新的基于无约束场景的中文车牌检测与识别方法。该方法兼具高精度和高鲁棒性,能方便地被部署在例如NVIDIA Jetson Xavier NX、NVIDIA Jetson AGX Xavier等边缘设备上,可助力于城市安防智能化、智能停车场以及智能安防机器人等工作。
