基于深度互学习的多标记零样本分类
2023-10-17袁志祥王雅卿黄俊
袁志祥,王雅卿,黄俊
(安徽工业大学 计算机科学与技术学院,安徽 马鞍山 243032)
0 概述
传统的图像分类问题主要属于单标记学习领域的问题,即一个对象只有一个类别标签。而在很多应用中目标对象并没有那么简单,一个对象可以属于好几个类别。例如,在图像分类中,一张图片里可能包含多个物体;在文本分类中,一篇新闻可能涵盖多个主题;在视频分类中,一个电影可能属于多个类型。
由于以往的单标记学习方法只能预测类别单一的样本,使用效果有待改善,因此人们将注意力转移到了多标记学习上。多标记学习的主要任务是通过训练数据,学习高效的分类模型,为输入样本预测可能的类别标记集合。随着数据集的扩大和深度学习方法越来越成熟,多标记学习问题得到解决,但在实际应用场景中,大部分数据集依然没有类别标记,这要求模型能够识别训练过程中从未见过的类别,于是多标记零样本学习应运而生。多标记零样本学习模拟了人类学习未知事物的过程,利用以往学习到的先验知识为目标样本推理预测多个未见过的新类别。然而目前的零样本问题几乎也都属于单标记学习领域,在多标记方向上的研究很少。
本文针对多标记零样本分类问题,提出一种基于深度互学习技术的解决方案。该方案包含3 个模块,其中一个子网络利用图像中每个区域与其他区域的关联信息来增强图像本身的特征,挖掘图像中存在的类别标签,包括已知和未知;另一个子网络将标签的语义信息与图像的每个区域特征相融合,在训练过程中引入标签语义使知识可以很好地从已知标签转移到未知标签;另一个是深度互学习模块,该模块能使两个子网络在训练过程中做深度互学习,即他们在训练自身分类性能的同时还能互相学习对方的训练经验,从而达到互相促进、共同进步的目的。
1 相关工作
1.1 多标记学习
随着数据集的扩大和深度学习方法的逐渐成熟,图像分类领域取得了显著的发展。多标记分类的任务是为输入图像预测多个标签,通过为每个标签学习一个二元分类器[1]完成,但它有两个缺点,一是在处理大量标签时增加了计算的复杂性,二是不包含标签之间的相关性。近年来大多数多标记学习方法均聚焦在挖掘标签之间的相关性上,比如文献[2]通过对标记空间进行属性聚类来挖掘标签的局部相关性;文献[3]利用余弦相似性来计算标签的全局和局部相关性;文献[4-5]采用图神经网络建立标签之间的依赖关系;文献[6]基于先验知识的词嵌入将标签转化为嵌入的标签向量后,再利用标签之间的相关性;文献[7-9]使用基于注意力机制的方法来解决多标记问题,通过编码图像的每个区域,使训练过程中的模型能注意到图像中的每个部分。
1.2 多标记零样本学习
虽然上述大多数方法在传统的多标记学习中都能取得很好的成绩,但不能直接应用到多标记零样本学习。由传统多标记学习方法训练得到的模型只能识别和预测它学习过程中见过的类别,见过的类别越多,即训练数据越多,该模型的分类性能就越好。尽管研究人员为了科研工作标记了大量数据集,但在现实生活中的数据依旧是未标记占绝大多数,导致以往的训练方法很难有效地解决实际问题,于是人们开始关注多标记零样本学习。
随着对零样本图像分类的广泛研究,模型在很大程度上克服了对未知类别数据进行分类的局限。零样本学习依赖于已知类别与未知类别之间相关联的语义信息,这通常是利用相关先验知识得到的,比如属性、词向量、文本描述等。零样本学习的解决方式主要分为两种,一种是将图像视觉特征和标签语义向量结合起来学习,如文献[10]提出的ALE(Attribute Label Embedding)模型,首先提取图像视觉特征及类别标签的语义向量,引入一个双线性评分函数,通过衡量视觉特征嵌入语义空间的兼容度来预测输入图像的类别。文献[11]提出LDF(Latent Discriminative Features)模型,能够发现图像中的判别性区域,并将图像的判别性区域特征与图像的全局特征进行联合学习,提升分类的准确率。另一种通过生成模型来生成未知标签的特征,再将其当做传统的监督学习进行训练,比如基于生成对抗网络(Generative Adversarial Network,GAN)[12]的方法和进一步对生成对抗网络进行优化的GMMN[13]方法等。
上述方法在零样本领域取得了巨大的成功,但这些解决方案并不能直接用到多标记零样本分类问题中。多标记零样本分类任务是为输入图像预测多个已知标签和未知标签。目前,对多标记零样本学习问题的研究较少,比较典型的有文献[14]中结合知识图谱的框架来描述多标签之间的关系,以此来建模已知类和未知类之间的相互依赖,但它需要访问已知和未知标签之间的先验知识图;相似地,还有文献[15]介绍的融合图卷积神经网络(Graph Convolutional Network,GCN)的多标记零样本学习框架,也是利用图来学习标签相互依赖的分类器;文献[16]提出一种基于生成模型的多标记零样本学习方法,它提出的CLF(Cross-Level feature Fusion)方法结合了ALF(Attribute-Level Fusion)标签依赖性和FLF(Feature-Level Fusion)特定类判别性的优点,并将其集成到常用生成模型框架中进行预测分类。还有一些基于注意机制的解决方案,例如文献[17]介绍了多模态注意,它可用于为每个标签产生特定的注意,并通过标签语义推广到未知标签,但是对数千个标签需要计算数千个注意,这会导致巨大的时间和内存消耗。文献[18]提出一种共享多注意框架,该框架为一幅图像学习所有类别共享的多个注意力模块,利用得到的多个注意力权重对图像的区域特征进行加权;而后文献[19]在其上进行优化,提出双层注意模块,通过融合图像的区域和全局信息来增强图像视觉特征。这两个模型的缺点在于在训练过程中只单独关注到图像特征,包括利用区域特征与区域特征之间的关联以及区域特征与全局特征之间的关联,并没有引入标签语义信息参与训练。
以上目前存在的多标记零样本学习方法在训练过程中除了利用一般图像分类任务所给定的基础信息(已标记的样本和类别先验知识)外,要么就只利用图像区域信息,要么就只利用标签语义信息。而本文提出的基于深度互学习技术的解决方案,在两个子网络互相学习的过程中,不仅可以起到互相促进、互相增强的效果,而且可以同时将图像区域信息和标签语义信息一起引入到训练过程中,这样得到的模型既能识别未知类,又能更全面地挖掘图像中存在的已知和未知标记。
1.3 深度互学习
文献[20]介绍了深度互学习,其灵感来源于模型蒸馏算法。模型蒸馏算法需要有教师网络和学生网络,教师网络向学生网络单方向传递它自身所学到的知识,即教师网络单方面教学生网络,并不能从学生网络上学到东西。而且在做蒸馏的时候,要有一个训练好的网络当教师,但深度互学习是将多个子网络同时进行训练,这些子网络不仅被真实标签值监督来训练自身的预测性能,而且能通过学习其他子网络的训练经验来进一步提高预测能力。在模型训练时,多个子网络之间都在不断分享训练经验,互相学习、互相增强,从而实现共同进步。
2 本文方案
2.1 问题定义
本文用CS表示已知类别集合,其中S表示已知类别个数;用CU表示未知类别集合,其中U表示未知类别个数。已知类别表示在训练过程中出现过的类别,而未知类别表示训练过程中没有出现过,只包含在测试数据集中的类别。CS+U≜CS∪CU表示包括已知和未知类别的集合。(I1,Y1),(I2,Y2),…,(IN,YN)表示N个训练样本,其中Ii表示第i个训练图像,Yi⊆CS表示第i个训练图像对应的标签集合。由于未知类没有对应的训练图像,本文假设给定标签描述的语义向量{Vc}c∈CS+U,给定的标签语义向量可以是属性或者词嵌入。传统多标记零样本分类的任务是为给定图像Ii预测其存在的多个未知标签Yi⊆CU;广义多标记零样本分类的任务是为给定图像Ii预测其存在的多个已知和未知标签Yi⊆CS+U。
2.2 多标记零样本学习模型
本文提出一种基于深度互学习技术的方案来解决多标记零样本图像分类问题,框架如图1 所示,该模型由两个子网络和一个深度互学习模块组成。具体过程为:给定图像Ii,经过卷积神经网络获得图像特征xi。在区域特征与区域特征相关联的子网络中将xi输入到多头自注意机制,得到图像中各区域特征之间的相关性权值rm,m为多头自注意机制的投影头,最终利用图像中各区域相关信息得到基于区域的特征Fi,将Fi映射到语义空间中,计算每个标签的置信度分数;在区域特征与标签语义相关联的子网络中,通过计算标签语义V={V1,V2,…,VS}与图像特征xi的相关性权重,对标签语义与图像特征进行融合,最终得到基于语义的特征Fg,将Fg映射到语义空间中,计算每个标签的置信度分数;最后加上深度互学习模块,引入一种损失函数对整个模型进行约束,使得两个子网络能够一边训练自身的分类性能,一边学习对方的训练经验。
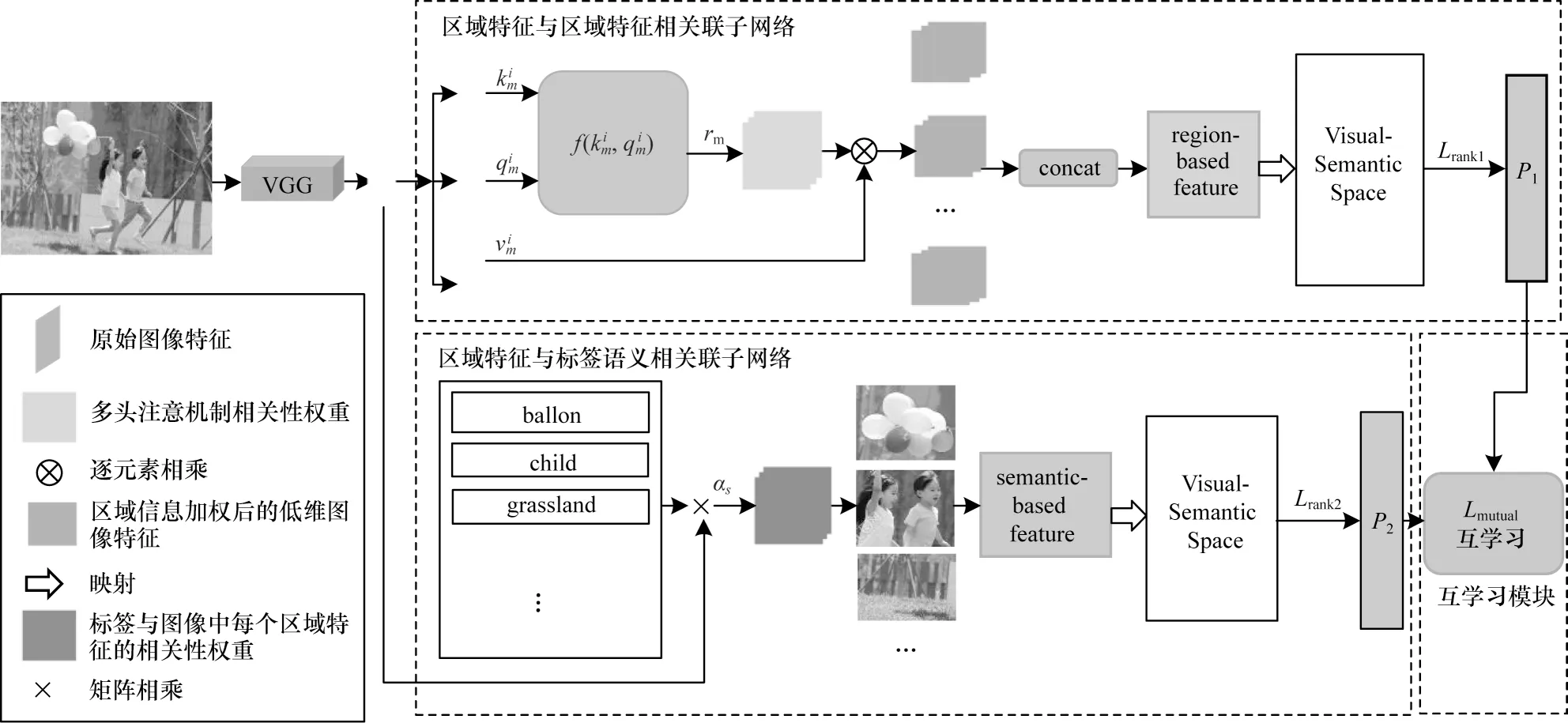
图1 基于深度互学习的多标记零样本学习模型Fig.1 Multi-label zero-shot learning model based on deep mutual learning
2.2.1 关联区域特征与区域特征的子网络
在该子网络中引入多头自注意力机制来关联图像各个区域,相当于利用各区域的相关信息增强图像自身的特征,得到基于区域的视觉特征表示。
首先从卷积神经网络中提取得到原始图像特征xi∈Rh×w×d,本文可以将其分成h×w个d维区域特征,即其中表示图像i的第r个区域。然后将原始图像特征xi∈Rh×w×d映射到低维空间(d'=d/M),使用M个投影头为图像的每个区域创建查询向量(query)、键向量(key)和值向量(value)。则原始特征经过3 种映射可得到:
计算每个区域的查询向量与图像中所有h×w个区域的键向量之间的相关性,可得到图像各个区域的相关权值:
其中:rm∈Rhw×hw;σ函数用来对权重值做归一化处理。利用得到的权值对值向量进行加权:
其中:αm∈Rh×w×d',表示从第m个投影头得到的h×w个d'维加权区域特征。在多头自注意机制中,图像原始特征的通道数将会从d维被切片成M个d'维,经过计算加权后再合并这些低维特征,得到最终基于区域的特征表示Fi:
其中:Wf∈Rd×d表示可学习的权重参数。
本文将加权后的特征表示Fi∈Rh×w×d也分成h×w个区域,即其中表示图像i中第r个区域的加权特征。
最后将得到的Fi映射到语义空间中,可以计算所有标签在图像i中的置信度分数,即图像i中存在这些标签的概率。计算如下:
其中:c表示第c个标签;θc∈R1×d为c的分类器参数;将图像的每个区域特征都与标签c的分类器参数做计算,取结果中最大值作为标签c的置信度分数Sci。
每个标签的分类器参数都取决于其对应的语义向量,可表示为:
如果图像中存在一个标签,那么该标签在图像上的置信度分数一定大于其他不存在的标签,据此引入损失函数作为一种约束,对该子网络进行优化:
其中:yi表示图像i中所存在标签的集合;表示标签c的置信度分数;表示标签c'的置信度分数。
2.2.2 关联区域特征与标签语义的子网络
首先将从卷积神经网络中提取到的原始图像特征和所有的标签语义向量输入该子网络,计算每个标签与给定图像中每个区域特征的相关性权重,利用相关性权重融合标签语义信息与图像视觉特征,获得基于语义的视觉特征表示。
其中:Wg∈Rda×d是可学习的权重参数;表示标签c对图像i中第r个区域的相关性权重。
其中:Fc∈R1×d表示图像i中所有区域经标签c加权后的特征,则Fg={F1,F2,…,FS}表示图像i经所有标签加权后的特征,即基于语义的视觉特征表示。
然后将Fg同样映射到语义空间中,可以计算所有标签在图像i中的置信度分数,表达式如式(13)所示:
其中:c表示第c个标签;θc∈R1×d由式(8)得到。
同样规定,如果图像中存在一个标签,那么该标签在图像上的置信度分数一定大于其他不存在的标签,据此引入损失函数作为约束,对该子网络进行优化:
其中:yi表示图像i中所存在标签的集合;表示标签c的置信度分数;表示标签c'的置信度分数。
2.2.3 两种子网络互相学习
为约束提出的两个子网络,使它们在整个训练过程中相互学习、相互促进,本文提出一种互学习损失函数。由于子网络学习到的训练经验可以通过最后输出的概率分布表现出来,所以本文将每个子网络得到的概率分布引入互学习损失,在互学习过程中让两个概率分布应尽可能接近,保持一致性。
在一般情况下,用KL 散度(Kullback-Leibler divergence)来计算概率分布之间的差别,概率分布越相似,散度值就越小,表达式如下:
KL 散度的缺点是P1与P2之间的散度值和P2与P1之间的散度值不相等。所以本文模型采用JS 散度(Jensen-Shannon divergence)作为互学习损失,JS散度为KL 散度的变体,表达式如下:
最后,本文定义模型总的损失函数如式(17)所示:
其中:λ是一个控制互学习损失的系数。
2.2.4 多标记零样本预测
利用得到的模型对多标记零样本图像分类任务进行预测:首先从CNN 网络中得到测试样本Ii的原始特征,再将原始特征分别输入到关联区域特征与区域特征的子网络和关联区域特征与标签语义的子网络,输出基于区域和基于语义的两种特征表示,将两种表示分别做映射,在语义空间中计算标签的置信度分数,得到和。最后,本文引入一组权重(α,1-α)融合这两个子网络输出的预测值,可得到测试样本Ii的最终标签预测,表达式如下:
其中:topk表示按照预测值大小排序的操作;arg topk表示取前k个预测值作为测试样本Ii的预测标签的操作;当c∈CU时,表示标签c属于只包含未知类别的集合,即是未知标签,此时该任务属于传统多标记零样本分类;当c∈CU+S时,表示标签c属于同时包含未知类别和已知类别的集合,即可能是未知标签也可能是已知标签,此时该任务属于广义多标签零样本分类。
3 实验结果与分析
3.1 数据集及实验细节
实验中采用多标记零样本分类常用的两个数据集NUS-WIDE[21]和MS COCO[22]。NUS-WIDE 数据集中有81 个人工标注的标签被用作未知类,925 个用户自动标记的标签被用作已知类;本文参考文献[23]对MS COCO 数据集中的标签进行划分,分成了48 个已知类和17 个未知类。数据集的具体信息见表1。

表1 数据集的具体信息Table 1 Specific information of the data set 单位:个
为评估本文方法的有效性,使用mAP 和每个图像的前K个预测的F1 得分作为评价标准。
本文的实验配置与文献[24]保持一致,所有实验均使用预训练的VGG-19 网络对图像进行特征提取。输入图片尺寸为224×224 像素,本文提取最后一个卷积层输出的特征,尺寸大小为14×14×512 像素,将其看作14×14 个区域的特征。使用基于维基文章训练得到的GloVe[25]模型来提取标签的语义向量,其中每个标签的向量维度等于300。
本文将多头注意机制的投影头个数M设置为8。当模型训练时,在NUS-WIDE 数据集上使用ADAM优化器,(β1,β2)设为(0.5,0.999),学习率设为0.006,批量大小设为256,训练20 轮;在MS COCO 数据集上使用SGD 优化器,动量值设为0.9,学习率设为0.001,批量大小设为32,训练20轮。
3.2 多标记零样本图像分类
3.2.1 NUS-WIDE 数据集上的实验结果
为评估本文方法的性能,本文在NUS-WIDE 数据集上做了传统多标记零样本(ZS)图像分类实验和广义多标记零样本(GZS)图像分类实验。将本文方法 与Fast0Tag[24]、CONSE[26]、LabelEM[27]、One Attention per Label[17]、One Attention per Cluster[18]和LESA[18]进行对比,这些对比方法在NUS-WIDE 数据集上的实验结果由本文直接引入文献[18]中的结果获得。文献[26]介绍的CONSE 是最基本的零样本学习模型,利用CNN 计算给定图像的预测标签,再将其输入Word2Vec 模型得到对应的类别向量,最后与真实的类别向量计算相似度。文献[27]介绍的LabelEM是基于嵌入的方式解决零样本学习模型,将类别标签嵌入到给定的属性向量空间中,再引入兼容函数,计算图像特征和嵌入标签的兼容度。文献[24]介绍的Fast0Tag 是最开始用于解决多标记零样本图像分类问题的模型,利用图像-标签的关联,提出对于给定图像,相关标签的词向量在词向量空间中沿着一个主方向排在不相关的标签前面,该方法通过估计图像的主方向来解决图像标记问题。表2 展示了在数据集NUS-WIDE 上两种分类实验的结果比较,表中加粗数字表示该组数据最大值。对于传统多标记零样本分类,LESA 方法提出一种共享多注意框架,为一幅图像学习所有K∈{3,5}类别共享的多个注意力模块,得到加权注意特征后,再将注意特征映射到语义空间进行预测分类。LESA 方法的分类性能在各方面都优于之前的方法。对比LESA 方法,本文方法在ZS 任务上的F1(K=3)分数、F1(K=5)分数、mAP 分别提高了1.4、1.1、1.9 个百分点。对于广义多标记零样本分类,与LESA 方法相比,本文方法的mAP、F1(K=3)分数、F1(K=5)分数分别提高了1.4、0.2、0.8 个百分点。实验结果表明,在NUS-WIDE 数据集上,本文方法在传统多标记零样本(ZS)图像分类实验和广义多标记零样本(GZS)图像分类实验中,性能都可以达到最佳。
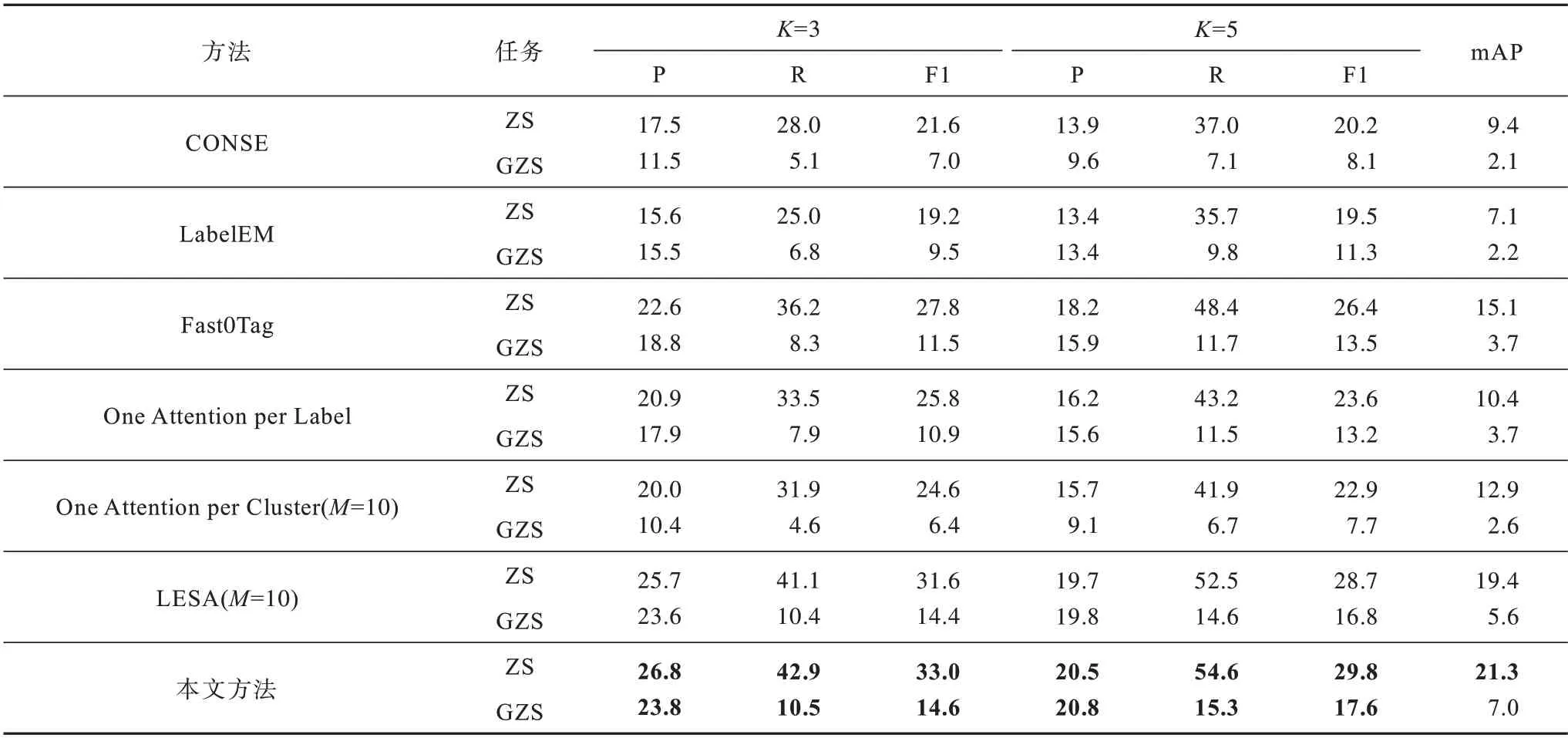
表2 在NUS-WIDE 数据集上的传统多标记零样本和广义多标记零样本分类性能比较Table 2 Comparison of classification performance between traditional multi-label zero-shot and generalized multi-label zero-shot on NUS-WIDE data set %
3.2.2 MS COCO 数据集上的实验结果
MS COCO 数据集曾被用于多标记零样本目标检测,近年来开始用在多标记零样本图像分类任务中。将本文方法与 Fast0Tag[24]、CONSE[26]、Deep0Tag[28]进行对比,这些对比方法 在MS COCO数据集上的实验结果将参考文献[23]中的结果。文献[28]介绍的Deep0Tag 是一种基于多示例框架来解决多标记零样本学习问题的模型,能够自动定位相关图像区域和建模图像标记(端到端),从多个尺度发现图像中场景信息,并兼顾全局和局部图像细节。表3 展示了在MS COCO 数据集上广义多标记零样本(GZS)图像分类的结果,主要将K=3 处的F1 分数及每个F1 分数的P 值和R 值进行比较。
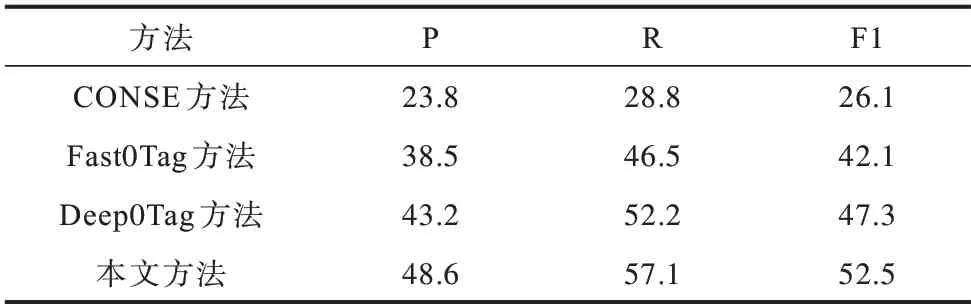
表3 MS COCO 数据集上的广义多标记零样本分类性能比较Table 3 Comparison of classification performance of generalized multi-label zero-shot on MS COCO data set %
在MS COCO 数据集中,参照文献[23]工作结果对已知类别和未知类别进行划分,本文模型在传统多标记零样本(ZS)图像分类任务中的性能不占优势,这是因为本文模型对一些复杂和抽象的类别如baseball bat、baseball glove、microwave、dining table、sink、fire hydrant 等难以预测。但在广义多标记零样本分类中,本文模型性能依然可以达到最好。
以往提出的多标记零样本分类方法中大多基于目标检测等模块,可以在MS COCO 数据集上达到较好的效果。通过对比本文方法和传统方法,发现本文方法即便不使用任何额外的检测模块,性能也可以达到最优,实验结果如表3 所示。对比Deep0Tag 方法,本文方法的P 值、R 值、F1 分数分别提高了5.4、4.9、5.2 个百分点。
3.3 消融实验
本文还在NUS-WIDE 数据集上进行了消融实验:仅使用关联区域特征与区域特征的子网络1 训练、仅使用关联区域特征与标签语义的子网络2 训练,仅使用本文方法训练,将其得到的实验结果进行对比。表4 展示了在传统多标记零样本(ZS)和广义多标记零样本(GZS)分类实验上三者的F1 分数和mAP 的对比,表中加粗数字表示该组数据最大值。对于传统多标记零样本分类,当仅使用子网络2时,相对于仅使用子网络1 的F1(K=3)分数、F1(K=5)分数、mAP 值分别提高了4.8、3.5、8.4 个百分点。而本文方法相对于仅使用子网络2 的F1(K=3)分数、F1(K=5)分数、mAP 值分别提高了2.7、1.8、1.5 个百分点。对于广义多标记零样本分类,当仅使用子网络1时,相对于仅使用子网络2 的F1(K=3)分数、F1(K=5)分数分别提高了1.1、1.0 个百分点。而本文方法相对于仅使用子网络1 的F1(K=3)分数、F1(K=5)分数分别提高了0.9、1.3 个百分点。

表4 在NUS-WIDE 数据集上3 种方法的分类性能对比Table 4 Comparison of classification performance of the three methods on NUS-WIDE data set %
上述结果说明了关联区域特征与标签语义的子网络2 在传统多标记零样本分类任务中表现更好,这是因为在传统多标记零样本分类任务中,测试数据集只包含未知标签,训练过程中只将每个标签的语义信息融入到图像区域,知识能很好地从已知标签转移到未知标签,所以在只识别未知标签的任务中表现较好;而关联区域特征与区域特征的子网络1在广义多标记零样本分类任务中表现更好,这是因为在广义多标记零样本分类任务中,测试数据集既包含已知标签又包含未知标签,将图像中各区域的特征信息相互关联之后,更容易挖掘图像中存在的标签,包括已知标签和未知标签。而本文方法在两种类型任务中的表现都能达到最好,证明了两种子网络在训练过程中进行深度互学习的有效性。
3.4 超参数分析
本文在NUS-WIDE 数据集上进行实验,分析互学习损失系数λ的影响,实验结果如图2 所示,其中F1_ZS_3 表示在ZS 分类实验中排名前三的预测结果的F1 分数。对比实验结果发现,当λ=0.01时,本文模型性能达到最佳。

图2 不同互学习损失系数λ 对模型性能的影响Fig.2 Effect of different mutual learning loss coefficients λ on model performance
本文还通过实验分析了2 个子网络权重系数组合(α,1-α) 对模型预测性能的影响。在数据集NUS-WIDE上,实验结果如图3 所示,对比结果发现α=0.3 即权重组合系数为(0.3,0.7)时,本文模型性能达到最佳;在数据集MS COCO上,实验结果如图4 所示,对比结果发现α=0.2 即权重组合系数为(0.2,0.8)时,本文模型性能达到最佳。

图3 NUS-WIDE 数据集上不同权重系数α对模型性能的影响Fig.3 Effect of different weight coefficients α on model performance on NUS-WIDE data set

图4 MS COCO 数据集上不同权重系数α对模型性能的影响Fig.4 Effect of different weight coefficients α on model performance on MS COCO data set
4 结束语
为了解决多标记零样本图像分类问题,本文提出基于深度互学习的方法,使图像区域信息和标签语义信息同时参与到模型训练中,增强图像本身的视觉特征。建立标签与图像特征之间的关系,且在训练过程中让2 个子网络互相学习对方的训练经验,互相促进。最后在对输入样本做预测时,使用一个组合权重系数融合两个子网络分别得到的预测值。本文还在两个数据集上进行传统多标记零样本分类和广义多标记零样本分类两种类型的实验,与以往研究方法的结果进行对比,证明所提方法的有效性。由于深度互学习并不局限于两个子网络进行互相学习,因此下一步也可以设计多个子网络,从不同的研究方向和技术切入,让各个子网络做不同的工作,互相弥补、促进,提高分类性能。
