基于RDMA 的高性能单向数据采集技术研究
2023-10-17梁嘉诚余江王洪波刘渊王晓锋
梁嘉诚,余江,王洪波,刘渊,王晓锋
(1.江南大学 人工智能与计算机学院,江苏 无锡 214122;2.拓尔思天行网安信息技术有限责任公司,北京 100000)
0 概述
随着大数据时代的兴起,众多企事业单位都建立了庞大的数据中心,有效地整合了各类数据资源,以供高效地采集数据[1],并通过搭建大数据分析平台,对数据资源进行实时分析和监控等操作[2]。然而,传统数据采集技术不能满足数据中心海量数据、类型多样化等需求,无法实现数据高效采集,并且内网数据中心、外网大数据平台等非对称安全等级网域之间在直接进行数据交互时,内网存在网络渗透、数据篡改等安全隐患。因此,如何保证数据采集的高效性、内网数据的安全性,成为亟待解决的问题[3-4]。
为解决当前数据采集存在的性能问题,国内外学者进行了广泛的研究。对数据中心海量、实时、异构的数据采集传输场景,传统的内网数据采集技术已经不满足当前需求,而消息中间件Kafka 具有高性能、低时延等特点[5-6],并且具备分布式集群部署能力,能够有效提高数据采集传输的效率。
针对内网数据中心与外网大数据分析平台直接交互时存在的数据安全问题,为提高网络环境的安全性,研究人员提出了一系列跨网域数据交换的安全措施,其中主要方法是单向数据传输[7-8]。单向数据传输通过构建不同安全等级的网域,避免内外网直接交互,从而有效防止内网攻击、数据篡改等安全问题[9-10]。
目前,单向传输技术一般都采用硬件光闸和软件协议相结合的形式,从物理和逻辑两个层面保证传输过程中内网数据安全[11]。文献[12]提出采用单向光网卡进行数据单向传输,通过小反馈技术进行数据的确认,两个方向都不能建立在线连接,可以有效防止网络攻击。单向光网卡两端采用私有协议进行数据传输,保证传输过程中内网数据的安全性。文献[13]设计一个以二维码为信息载体的移动端单向传输系统,完成涉密信息从低密级网络向高密级网络的单向传输,不依赖单向的物理传输设备,信息传输工作只在软件层面进行,降低了对专业设备的要求,从而保证低密级网络的安全性。文献[14]针对不同安全等级网络之间数据单向传输的需求,提出一种单向代理传输协议,该协议运行在计算机网络体系中的网络层,是一种非IP 协议,通过该协议实现了数据单向传输。
上述研究对于提升数据采集的安全性具有一定的参考价值,然而这些单向传输系统存在一些性能瓶颈,基于UDP 协议或相关私有传输协议实现的单向传输系统存在传输时延过高、CPU 开销过大等问题。因此,在对数据时延敏感的业务场景中,传统的单向传输系统不能满足真实需求。
本文将远程直接内存访问(Remote Direct Memory Access,RDMA)技术应用于单向数据采集场景,设计一种基于RDMA 的高性能单向数据采集(One-way Data Acquisition by RDMA,ODAR)架构。RDMA 技术[15]通过网络将数据直接写入远端主机的内存区域,绕过内核处理,避免用户态和内核态之间的频繁拷贝,降低系统的上下文切换的开销,实现高带宽和低时延的数据传输[16]。ODAR 架构采用RDMA 技术的不可靠连接(Unreliable Connect,UC)模式,以及RDMA 技术所提供的Write 单边原语进行数据传输,从软件层面保证数据传递的单向性与内网的安全性。此外,ODAR 架构为保证传输数据的完整性和正确性,设计基于可靠性的数据封装策略,保证数据能够正确传输到接收端对应的节点,并针对内存分配存在时延过高的问题,结合RDMA 技术设计动态内存优化策略,通过对内存的复用以及内存分配和数据封装,发送异步操作降低数据的时延。最后,提出基于优先级的数据传输调度算法,解决数据传输时存在网卡带宽实际利用率过低的问题,以提高网卡带宽的实际传输量。
1 基于RDMA 的高性能单向数据采集架构
针对当前数据采集技术中存在的数据安全和传输性能问题,本文设计基于RDMA 的高性能单向数据采集架构,该架构能保障数据传输时内网的安全性,提高网络传输性能。如图1 所示,ODAR 架构主要分为发送端和接收端,发送端包括初始化模块、数据封装模块、数据传输调度模块、数据发送模块,接收端包括数据初始化模块、数据处理模块、数据接收模块。
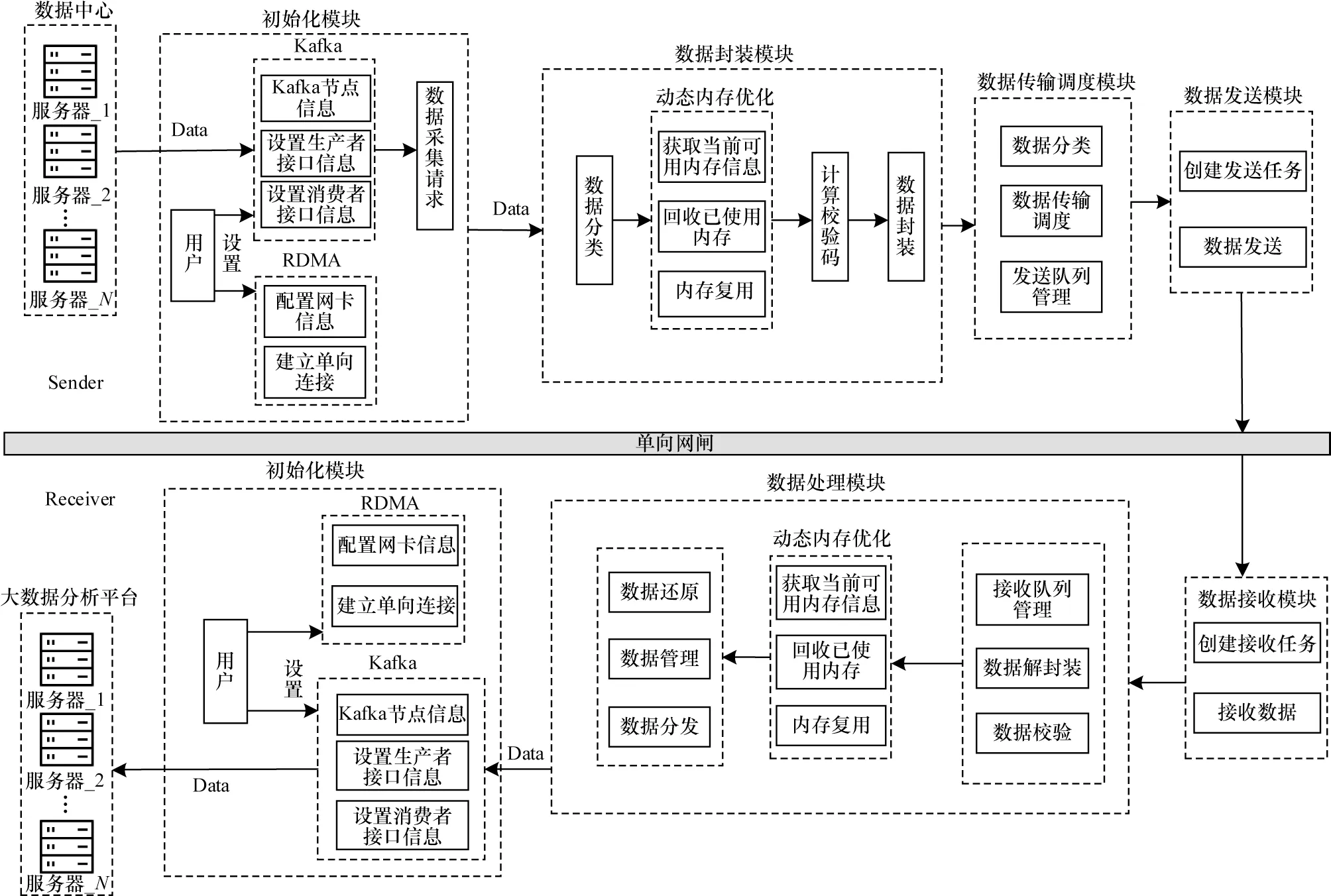
图1 ODAR 总体架构Fig.1 ODAR overall architecture
1.1 初始化模块
发送端初始化模块主要负责消息队列Kafka 和RDMA 网卡等信息初始化。如图2 所示,首先构建Kafka 集群,将Kafka 的生产者接口与数据中心服务器节点对接进行数据采集,并将消费者接口与发送主机对接,在该发送主机中监听多个Kafka 集群中的Broker[17],构成多对一模式。然后根据需求将采集到的数据交由数据封装模块进行处理。
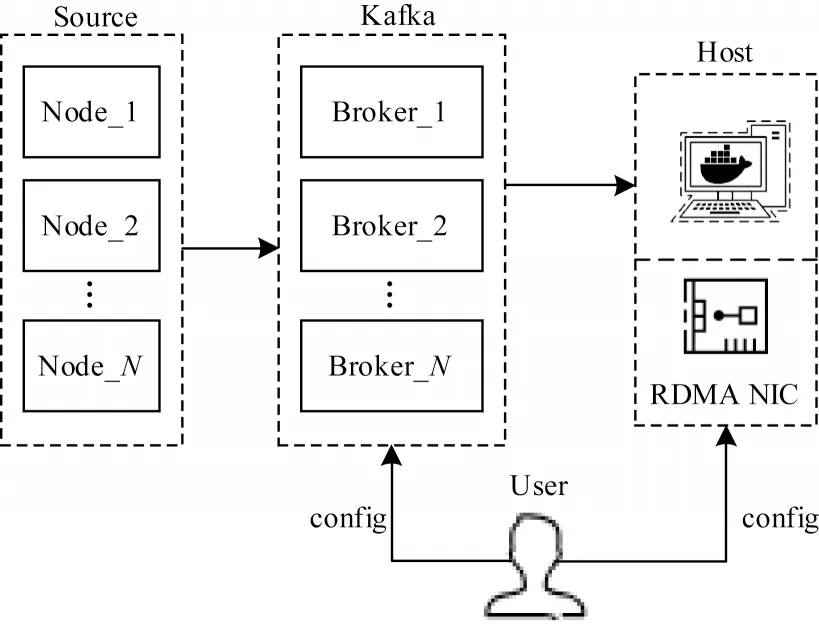
图2 初始化过程Fig.2 Initialization process
类似地,接收端的初始化模块也需要对接收端一侧的消息队列Kafka 和RDMA 网卡进行初始化操作,将接收主机作为生产者对接Kafka 集群,大数据分析平台作为消费者对接Kafka 集群。
1.2 数据封装模块
数据封装模块对应基于可靠性的数据封装和动态内存优化。首先进行数据分类,根据数据类型将数据区分为普通数据和实时数据,通过原始数据的长度以及封装信息分配内存,为数据包设置相对应的优先级,然后根据数据来源设置标志信息,计算校验码,最后将这些信息封装为一个完整的数据包,用于保证传输数据的安全性和准确性。
1.3 数据传输调度模块
数据传输调度模块对应基于优先级的数据传输调度,主要负责数据的分类处理,并根据当前的数据包长度进行传输调度,提高网卡带宽的实际利用率,在传输时将数据进行序列化处理,提高数据的传输效率。
1.4 数据发送模块
如图3 所示,在第1.1 节初始化模块中,用户初始化RDMA 网卡静态信息,将连接信息存入RDMA队列对(Queue Pair,QP)的队列对上下 文(QP Context,QPC)中,QP 由发送队列(Send Queue,SQ)和接收队列(Receive Queue,RQ)组成[18-19],ODAR 架构使用RDMA 的不可靠连接(UC)[20]模式,保证传输过程的单向性。在第1.2 节和第1.3 节对数据进行封装和调度之后,可以创建工作任务,按序存入SQ中,RDMA 网卡(RDMA NIC)根据SQ 中的工作任务信息获取内存中的数据,使用RDMA 单边原语Write[21]根据配置信息将数据直接写入接收端指定的内存区域,该数据传输过程绕过内核处理,从而降低了CPU的开销。

图3 数据发送流程Fig.3 Data sending procedure
1.5 数据接收模块
通过配置信息,数据接收模块与RDMA 发送方建立连接,当RDMA 发送端使用RDMA 原语Write将数据写入接收端内存之后,响应RQ 中的接收请求,产生工作完成(Work Completion,WC)信息告知上层[22-23],因此根据发送数据包携带的数据信息,接收端对指定接收内存区域进行轮询,获取写入的数据,然后将接收到的数据交由接收方的数据处理模块进行处理。
1.6 数据处理模块
接收端的数据处理模块对应发送端的数据封装模块,申请了与发送端相同大小的内存空间,首先将接收内存中的数据包解封装处理,对处理完成后的内存空间进行回收复用。其次将数据包排序,根据封装信息将数据包还原为原始数据,存入对应的Kafka 集群中。
2 基于可靠性的数据封装
ODAR 架构从物理和逻辑两个层面来保证数据传输的单向性,数据只能由内网发送到外网,没有数据回路,从而保证了内网的安全性。由于发送端监听了多个服务器节点进行数据采集,如果直接传输原始数据,接收端无法根据数据信息将接收到的数据准确分发到对应的节点。针对上述问题,本节设计了基于可靠性的数据封装策略,保证了传输数据的准确性,接收端能够根据封装的数据信息将数据分发到对应的节点。封装过程如图4 所示。

图4 基于可靠性的数据封装过程Fig.4 Reliability-based data encapsulation process
封装过程如下:
1)解析原始数据信息进行数据分类,采集到的数据可以划分为实时数据和普通数据。实时数据对时延敏感,而普通数据允许一定的时延,因此需要将它们分类处理。数据包封装时需要分配内存空间,本文结合RDMA 技术设计动态内存优化策略。
2)根据数据的来源对数据做标识,保证接收端能够根据封装信息将数据准确地分发到对应的节点中。
3)设定数据长度阈值,当数据长度超过阈值时,将数据分片压缩,如果数据过小未达到阈值,则无须分片,并根据数据的优先级选用不同的加密算法,保证数据的安全性。计算数据的校验码,附加在数据包的尾部,在接收端能够通过校验码来进行判别该数据是否完整。对于分片的数据增加片段编码,避免数据重新组装时出现问题。
增加数据的头部和尾部信息以及数据包编号等内容,组成一个完整的发送数据包,在数据发送前,对数据做序列化处理,提高传输效率。
3 动态内存优化
在ODAR 架构中,由于RDMA 具有Kernel Bypass 特性[24],因此需要在数据发送前锁定申请的发送内存,防止Swap 机制导致虚拟内存和物理内存之间的映射产生变化。由于在发送主机中开启了多个消费者线程监听Kafka 集群中的多个节点,在数据传输过程中,需要对采集到的原始数据进行封装,避免数据传输到接收端之后无法存放到对应节点。在高并发环境中,为了避免同时操作相同内存区域导致数据出错,因此多个线程之间需要保持互斥性,等待RDMA 发送内存中数据发送完成,再由其他线程继续写入数据,上述同步操作会导致数据产生过高的时延。针对该问题,提出动态内存优化策略,将RDMA 发送内存构建成一个环形缓冲区,使内存分配、数据封装和数据发送可以异步执行,从而降低数据时延。动态内存优化流程如图5 所示。

图5 动态内存优化流程Fig.5 Dynamic memory optimization procedure
动态内存优化流程如下:
1)初次申请内存:系统会对内存进行初始化操作,申请大块的连续RDMA 发送内存,用于内存再分配。
2)内存申请:后续所申请的空间都是由该内存再分配,并返回申请内存区域的地址信息。
3)回收内存:根据该区域的状态信息,启动一个线程不断回收可复用的内存空间,用于后续再分配过程。
4)数据封装:按照封装格式将数据写入申请的内存区域中。
5)请求发送:将内存中封装好的数据发送到接收端。在数据封装和数据发送过程中,其他线程可以继续申请内存,达到异步处理的效果。
由于采集的数据包长度不可预估,为保证能够充分利用内存空间,根据原始数据信息和数据封装信息在初始化的RDMA 发送内存上动态申请对应长度的空间,并保证申请过程中各个线程之间的互斥性。
首先将RDMA 发送内存的首尾地址、长度、使用状态等信息作为一个链表节点存入记录当前内存信息的链表List_Cur中。在申请内存时,需要遍历链表List_Cur,判断当前RDMA 内存剩余容量是否足够分配,如果内存充足,那么记录申请内存区域的首地址Node_Head、尾地址Node_Tail、长度和使用状态等信息,将申请的内存区域的信息作为一个链表节点,插入记录使用内存信息的链表List_Used 尾部,在申请的同时,需要更新链表List_Cur 中当前RDMA 发送内存的信息,将指向当前RDMA 发送内存头部的指针RDMA_Cur 向后移动,直到指向RDMA 发送内存的尾部指针RDMA_Tail。如果内存余量不充足,出现图6 所示中Situation 2 的情况,则可以利用RDMA 技术所具备的分散聚合特性,即RDMA 支持分散/聚合条目[25],读取多个内存区域中的数据作为一个流直接写入到远端内存中,即可以将数据拆分,存放在两个不连续的内存空间中,并在RDMA 发送任务中指定这两片内存的地址和长度信息,网卡根据指定的信息将数据发送。
在数据发送完毕后,更新链表List_Used 中内存节点的信息,将使用状态设置为可回收状态,由回收线程进行处理,从链表List_Used 头部开始遍历节点,判断链表List_Cur 的尾部节点的尾地址是否与回收的内存节点的头地址相等,如果相等则将回收的内存节点信息合并到链表List_Cur 的尾部节点中。由于在对RDMA 发送内存再分配时始终按照顺序将指针从头部向尾部移动,如果不相等,表示当前回收节点的首地址是RDMA 发送内存的首地址,链表List_Cur 中尾节点的尾地址是RDMA 发送内存的尾地址RDMA_Tail,因此将回收的节点作为一个新的节点插入到链表List_Cur 尾部。RDMA 发送内存的再分配与回收始终按照地址顺序操作,避免出现内存碎片。
4 基于优先级的数据传输调度
在数据采集时,由于数据包长度不可预估,针对频繁发送小型数据包存在网卡带宽利用率过低的问题,本文提出基于优先级的数据传输调度算法,对实时数据和普通数据两种类型数据采用不同处理方式。
根据采集的数据类型区分优先级,实时数据对于时延敏感,要求在传输过程中尽可能地降低时延,因此在传输过程中使用数据流式传输模式,指定数据存放内存地址交由网卡直接发送。而普通数据可以适当地接收一些数据延迟,为保证网卡带宽利用率,当普通数据长度小于发送数据包长度阈值Data_Len时,采用数据发送策略,将多个小型数据包累积成一个大型数据包,可以有效提高网卡带宽利用率,具体数据发送策略流程如图7 所示。
实时监控数据的发送速率在数据发送速率超过阈值时,接收方因为处理不及时,存在数据丢包问题,因此当数据发送速率过高时,需要对其限速。
具体传输调度算法伪代码如下:
算法1基于优先级的数据传输调度算法
1.Timer()
2.while there is new data to send
3.if Throughput >=Max_Throughput
4.Speed_limit()
5.if Data->pkt_priority==Realtime_Data
6.RDMA_Buffer←Data
7.RDMA_Post_Send(RDMA_Buffer)
8.continue
9.if Data->pkt_len>Data_Len
10.Send_Queue(Data)
11.else
12.SubTimer()
13.while Sub_Wait_Time<=
Max_Wait_time or Total_Len<=Max_DataSize do:
14.Data_Merge(data)
15.end while
16.Send_Queue(Data)
17.end if
18.if Wait_Time==MAX_Cal_Time
19.Recalculate_Throughput()
20.end while
算法1描述基于优先级的数据传输调度过程。输入待发送的数据,在数据传输时,启动一个定时器Timer(第1 行),用于实时计算吞吐量(第19 行),当吞吐量高于阈值时,调用Speed_limit 函数进行限速,避免传输速度过快、接收不及时产生丢包问题(第4 行)。
在数据封装过程中,根据采集数据的不同类型,规定了不同的优先级pkt_priority,因此在数据传输时根据数据的优先级来实施调度。判断该数据包是否是实时数据Realtime_Data,如果是实时数据,为尽可能降低时延,不考虑数据包长度都直接使用数据流传输模式,直接将数据写入缓存,将数据存入发送队列Send_Queue,保证了数据的时效性(第5~8 行)。
当传输普通数据时,为保证网卡带宽的利用率,针对小型数据包采取数据发送策略,将数据包尽可能地归并成一个大的数据包发送,提高实际发送的数据量。
普通数据发送策略主要将多个小型数据包归并为一个大型数据包,具体操作如下:
普通数据首先判断原始数据块的长度是否大于发送数据包长度阈值Data_Len,如果大于Data_Len,判断数据的标志,即判断数据来源,将数据存入相对应的发送队列(第9~10 行)。然后,当原始数据块长度小于Data_Len时,首先在第3 节内存分配时需要申请一个发送数据包大小的空间,然后开始归并数据,启动一个子定时器SubTimer 用于定时,计算归并数据包总长度Total_Len 以及归并等待时间Sub_Wait_Time,将多个来自同一个节点的小型原始数据块归并为一个大的数据块,不同节点的数据则分类归并,在多个小型原始数据块之间增加边界符,并在数据包头部信息中写入对应的长度和编号等信息,从而提高了网卡带宽的有效利用率,当接收端接收到数据之后,根据封装信息和编号重新排序还原为原始数据块。最后,如果数据包总长度Total_Len大于Data_Len,或者Sub_Wait_Time 大于最大等待时间Max_Wait_Time,则根据数据的标志将数据存入对应的发送队列中(第12~16 行)。
5 实验结果与分析
实验主要对比基于UDP 和基于RDMA 技术实现的单向数据采集性能,并验证基于可靠性的数据封装的有效性、动态内存优化的性能以及基于优先级的数据传输调度的有效性。
本文的实验环境为操作系统CentOS7,并且在发送端和接收端两台服务器上分别装载支持RDMA 技术运行的相关驱动MLNX_OFED(version 4.9-2.2.4.0)。RDMA 测试使用网卡InifinBand connectX-3,UDP 测试使用网卡NetXtreme BCM5720,两张网卡均为万兆网卡。
5.1 ODAR 架构性能验证测试
实验测试在相同环境中基于RDMA 与基于UDP 实现的单向数据采集技术的吞吐量、时延、CPU开销,验证RDMA 技术应用在单向环境中的性能。
实验性能测试的计算公式如式(1)所示:
其中:区间[i,j]表示数据包长度的区间范围;Mi表示在数据包长度为i使用RDMA 测试性能的数值;Ni表示数据包长度为i使用UDP 测试性能的数值;avg 代表在区间[i,j]内使用RDMA 技术相对于使用UDP的性能平均提升数值。
1)吞吐量测试
实验测试基于RDMA 技术与基于UDP 协议实现的单向数据采集的吞吐量,控制数据总量及数据包长度,保证数据流量充足,忽略数据处理过程的开销。实验结果如图8 所示。

图8 吞吐量测试结果Fig.8 Test result of throughput
实验结果表明,在数据包长度区间[8 Byte,4 096 Byte]时,使用RDMA 和使用UDP 的吞吐量均处于增长阶段,而使用RDMA 技术的吞吐量此时明显优于使用UDP,在数据包大于4 096 Byte后,当前两者吞吐量大小均接近阈值,并逐渐趋于稳定。
由于使用UDP 协议传输过程中需要操作系统封装和解析数据、验证数据完整性等工作,当数据包长度较小时,对于相同待传输数据量操作系统需要处理更多的数据包,这个过程中操作系统会在内核态和用户态频繁地切换,对CPU 资源的消耗急剧增加,因此CPU 的性能成为传输的瓶颈,所以UDP 在数据包长度较小的情况下吞吐量损失十分明显,而RDMA 技术具有零拷贝和内核旁路等特点,在数据传输过程中,CPU 无须参与,通过DMA 引擎直接与用户态进行交互,数据包的封装和解析工作交由RDMA 的硬件网卡来完成,从而避免过多地切换上下文,因此吞吐量、时延以及CPU 开销这3 个方面相对于UDP 协议,RDMA 都具有明显优势。
根据式(1)计算结果表明,基于RDMA 实现的单向数据采集技术的吞吐量,相对于UDP 协议平均提高了57.01%。
2)传输时延测试
实验测试基于RDMA 技术与基于UDP 协议实现的单向数据采集的时延,控制数据总量及数据包长度,保证数据流量充足,忽略数据处理过程的开销。实验结果如图9 所示。从图9 可以看出,在整个数据包长度区间内,使用RDMA 技术的时延明显小于使用UDP 协议。主要原因同样在于RDMA 技术是绕过内核,直接由网卡来进行封装解析,无须像UDP 协议那样需要层层封装,频繁地上下文切换会导致时延急剧增加。

图9 传输时延测试结果Fig.9 Test result of transmission delay
根据式(1)计算结果表明,基于RDMA 技术实现的单向数据采集相对于基于UDP 协议实现的单向数据采集的传输时延平均降低了61.27%。
3)CPU 开销测试
实验测试基于RDMA 技术与基于UDP 协议实现的单向数据采集的CPU 开销,控制数据总量及数据包长度,保证数据流量充足,忽略数据处理过程的开销。CPU 开销测试结果如图10 所示。从图10 可以看出,在整个数据包长度区间范围内,使用RDMA技术的CPU 开销明显小于使用UDP 协议。主要原因与吞吐量测试相同,使用UDP 协议在数据传输时频繁地上下文切换,导致CPU 消耗急剧增加,而RDMA 除了在程序初始化时注册内存等操作需要消耗CPU 资源,整个数据传输过程直接绕过内核处理,无须CPU 的参与。根据式(1)计算结果表明,基于RDMA 技术实现的单向数据采集相对于基于UDP协议实现的CPU 开销平均降低了68.01%。通过吞吐量、时延以及CPU 开销3 个方面验证了ODAR 架构的优势性能。
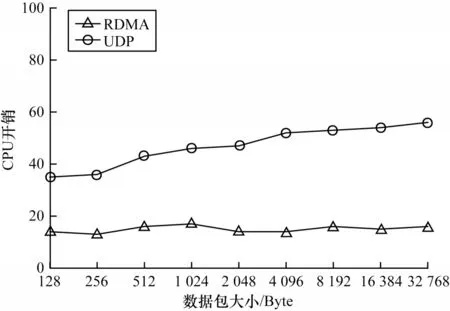
图10 CPU 开销测试结果Fig.10 Test result of CPU overhead
5.2 基于可靠性的数据封装测试
实验分别测试基于可靠性的数据封装和使用原始数据传输两种情况下接收端接收数据的正确率。实验测试结果如表1所示,当数据包长度为4 096 Byte左右时,吞吐量接近阈值,且此时的时延较低,因此设置发送的数据包长度为4 096 Byte,发送总量分别为10/20/30 GB,每个总量发送10 次求取其平均值。如果直接使用原始数据块发送,则数据再发送到接收端,由于未标识数据的来源以及应该存放对应位置的信息,导致数据不能正确被分发,只能由分发线程随机分发,导致大规模数据出错的现象,而基于可靠性的数据封装之后,接收方根据数据标识基本可以正确接收数据,平均提高了93.3%,但由于发送速率过快,存在部分丢包现象。
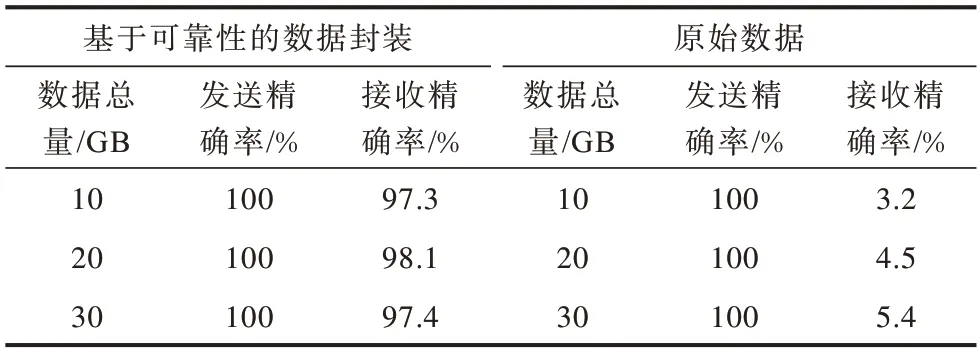
表1 基于可靠性的数据封装测试Table 1 Reliability-based data encapsulation test
5.3 动态内存优化测试
实验测试内存分配和数据封装、发送同步操作的情况,以及使用本文设计的动态内存优化情况下测试相同大小的数据从申请内存开始到数据发送的平均时延,对比两者在ODAR 架构中的差异。实验性能测试的计算公式见式(1),其中,区间[i,j]表示数据包长度的区间,Mi表示使用动态内存优化策略在数据包长度为i的测试的数值,Ni表示同步操作在数据包长度为i测试的数据值,avg 表示使用动态内存优化策略相对于同步操作在数据包长度区间[i,j]性能平均提升值。
时延测试结果如图11 所示,其中,RDMA-syn 曲线表示同步操作时的时延曲线,RDMA-asyn 表示使用本文设计的动态内存优化的时延曲线。控制数据发送总量,保证数据量充足,根据测试数据显示,在高并发环境中,整个数据包长度区间内ODAR 架构使用动态内存优化策略的时延明显较低,动态内存优化策略使时延平均降低了80.15%。

图11 动态内存优化-时延测试结果Fig.11 Test result of dynamic memory optimization-delay
实验结果证明了动态内存优化策略的优势性能。在数据封装和数据发送时,对接Kafka 集群的多个数据消费线程无法运行,必须等待数据封装、发送完成之后才能继续运行,从而导致处理时间开销增大,而使用动态内存优化操作时,将内存分配和数据封装,发送异步操作,使RDMA 发送内存构建为一个环形缓冲区,在数据封装与发送时,其他消费者线程仍然可以申请内存,因此时延随之降低。
5.4 基于优先级的数据传输调度测试
由于数据采集到的原始数据包存在长度不确定的情况,如果采集到海量小型原始数据块,并将其封装成一个数据包直接发送时,则封装信息长度在数据包长度中占比过高会导致网卡带宽的利用率严重下降,因此本文提出基于优先级的数据传输调度算法。
在实际传输时为保证实时数据的低时延,对于数据采用流式处理,而普通数据可以容忍一些数据时延。为提高当前网卡带宽的有效利用率,本文采用对应的数据发送策略。测试结果如图12 所示,其中,RDMA-Scheduling 表示基于优先级的数据传输调度,RDMA-Raw 表示未做任何调度。实验性能测试的计算公式见式(1),其中,区间[i,j]表示数据包长度的区间,Mi表示使用RDMA-Scheduling 在数据包长度为i测试的数值,Ni表示使用RDMA-Raw 在数据包长度为i测试的数据值,avg 表示使用基于优先级的传输调度算法相对于未做任何处理的性能平均提升值。

图12 基于优先级的数据传输调度测试结果Fig.12 Test result of priority-based data transmission scheduling
在实验测试时发送大批量的小型普通数据包,控制发送总量,保证数据流量充足。当数据包长度在[8 Byte,4 096 Byte]时,吞吐量未达到阈值,在4 096 Byte 之后,当前吞吐量趋于稳定,接近阈值,并且此时时延较低,数据包是由原始数据和封装信息组成。实验结果表明,基于优先级的数据传输调度能够提高普通数据在数据包长度区间[8 Byte,4 096 Byte]范围中的网卡带宽利用率,网卡真实利用率也随之增大,在不做任何处理的情况下,当原始数据包长度逐渐增大时,网卡带宽的实际利用率也在逐渐增大。主要是因为原始数据块的封装信息具有固定长度,当传输的原始数据包长度过小时,封装信息在发送数据包中所占比重较高,从而导致网卡的实际传输量低,而基于优先级的数据传输调度处理对于长度较小的普通数据归并为一个较大的数据包,设置边界符,避免粘包,减少封装信息在数据包长度的比重,从而可以提高网卡带宽的实际利用率。根据式(1)计算,在[8 Byte,4 096 Byte]区间内基于优先级的数据传输调度之后,网卡带宽利用率平均提高了33.03%。
6 结束语
针对单向数据采集场景,本文设计了结合消息中间件Kafka 和RDMA 技术的单向数据采集架构ODAR,并提出基于可靠性的数据封装解决传输时数据准确性的问题。为克服内存分配时存在的性能问题,设计动态内存优化策略,并给出基于优先级的数据传输调度算法解决数据传输时网卡带宽的利用率过低的问题。实验结果表明,ODAR 架构在单向场景中能够提高单向传输时的吞吐量,降低时延和CPU 开销,并验证了基于可靠性的数据封装和动态内存优化策略的有效性,且基于优先级的数据传输调度能够提高网卡实际传输量。但是,本文未对丢包问题做更加详细的处理,因此在数据可靠性方面还需要进一步研究。
