用于颈椎MRI 分割的多尺度特征融合注意力网络模型
2023-10-17周静钟原李平杨毅马立泰张涛
周静,钟原,李平,杨毅,马立泰,张涛
(1.西南石油大学 计算机科学学院,成都 610500;2.四川大学华西医院 骨科,成都 610041)
0 概述
对于颈椎病的诊断,有必要获取患者的骨关节和颈椎脊髓信息作为判断依据,这通常需要获得CT、X 射线、MRI 等医学成像信息。与CT 和X 射线相比,MRI 分辨率高、图像准确清晰,更能清楚地看到器官的内部组织形态和神经静脉。由于成像原理不同,因此MRI 还能获得相关部位的脊髓信息。然而,在当前的临床应用中,特别是在初级保健设置中,在MRI 上手动识别和分割颈椎结构是一个费力、耗时且容易出错的过程。基于人工智能的辅助分割可以大大减少劳动消耗,并有助于根据分割结果判断颈椎骨折、脊髓受压等问题。因此,人工智能技术可以对颈椎关节图像和脊髓信息进行精细的像素级别诊断,在颈椎MRI 图像诊断过程中进一步为疾病诊断提供更详细的依据。但由于相邻骨关节的相似性和相邻椎间盘的相似性,与传统的器官[1-2]或组织分割[3-4]相比,颈椎分割任务更具挑战。
近年来,许多研究者致力于基于深度学习进行医学图像的相关分析[5-6],然而由于缺乏颈椎MRI 图像数据集,专注于颈椎图像分析的研究较少[7]。公开的MRI 椎体分割数据集主要涉及胸椎和腰椎信息[8-9],其他的一些MRI 数据集侧重于脑部肿瘤[10-11]、心脏器官[12-13]等。对于脊椎分割,标准U-Net 和具有数据增强的U-Net 被用于进行CT 和MRI 数据集分割[14],一种混合方法[15]结合卷积神经网络(Convolutional Neural Network,CNN)和完全卷积网络(FCN),利用类冗余作为软约束,改进了分割脊椎的效果。Res50-UNet[16]将U-Net 应用于脊椎分割,大幅度提升了分割效果。DGMSNet[17]为脊椎分割预测生成分割路径,并为关键点生成热图预测生成检测路径。但是,基于颈椎的多实例分割依旧是匮乏的,且由于颈椎结构复杂,因此相关模型应用于颈椎分割时分割结构不完整,难以保证分割精度。
本文建立一种多尺度特征融合注意力(Multi-Scale Feature Fusion Attention,MSFFA)网络模型。基于ResNet[18]进行特征提取,利 用DeepLabv2[19]中空间金字塔池化(ASPP)结构构建特征注意力机制和多尺度信息融合实现更加精细的边缘信息提取,同时结合原始尺寸特征补充分割的细节信息。通过不同尺度的融合增强,有效提取颈椎部位的不同结构。
1 相关工作
随着人工智能的快速发展,构建基于深度学习的端到端图像分割网络在图像领域取得了不断的突破[20]。基于深度学习的主流医疗图像分割网络主要分为非对称的DeepLab 系列和对称的U 型结构系列[21-22]。
1.1 DeepLab 分割网络
FCN[23]将图像分类中的CNN 特征提取过程 引入端到端图像分割领域。为了解决FCN 缺乏空间一致性信息的问题,在VGG-16 网络[24]的基础上重写了DeepLabv1[25],通过调整VGG 网络结构,加 入Atrous 卷积,在不增加计算负荷的情况下扩大接收场,并利用条件随机场(CRF)提高分割边界的准确性。DeepLabv2 提出了Atrous ASPP,通过灵活地使用Atrous 卷积来捕获多尺度图像的上下文,使用底层细节来优化分割性能。DeepLabv3[26]级联了Atrous 卷积模块,该模块使用多个衰减率来捕捉不同尺度的背景。为了细化分割效果,DeepLabv3+[27]利用中间层的特征图对输出图像进行放大,并增加一个简单的解码模块对分割结果进行细化。
1.2 U 型分割网络
U 形结构的编解码网络也被广泛应用于医学图像分割。U-Net[28]网络通过连续下采样和连续上采样构成U 型网络结构,将编码器和解码器连接起来。由于其良好的结构设计和性能,在U 型结构的基础上产生了大量的网络变体。Res-UNet[29]将ResNet和U-Net 相结合,替换了传统U-Net 中有残留连接的子模块。H-DenseUNet[30]的灵感来自密集连接,使用密集连接替换子模块。UNet++[31]在U-Net 上增加了嵌套和密集的跳接卷积神经网络,解决了医学图像分割的准确性问题。Res-UNet++[32]在Res-UNet的基础上使用了CRF 和测试时间增强(TTA)。同时,注意力机制也被引入医学图像分割任务中。例如:UNet++[33]在U-Net 的基础上集成了Attention,在解码器部分使用了Attention Gates;TransUNet[34]在U-Net 的编码结构中引入了Transformer,增强了模型对细粒度特征的提取;UTNet[35]在编码器和解码器中应用了一个自注意力模块,以最小的开销捕获不同规模的远程依赖关系。此外,Swin-UNet[36]使用Transformer 替换U-Net 中的子模块,将标记化的图像补丁通过跳跃式连接发送到基于Transformer 的U型En-Decoder 架构进行局部和全局语义特征学习。
2 MSFFA 网络模型
MSFFA 网络模型整体结构如图1 所示。首先,基于ResNet 进行初步特征提取,通过多尺度注意力(Multi-Scale Attention,MSA)模块对特征信息进行不同感受野卷积,实现特征信息的注意力机制,增强对于关键信息的提取。其次,为缓解不同尺度特征融合带来的损失,提出一种具有差异化的跨尺度特征融合(Cross-scale Feature Fusion,CFF)模块,将高维特征信息进行切分处理,通过中心增强和边缘增强融合信息,将高维信息融入低维特征,丰富低维特征信息。最后,对特征进行分割输出时,引入原始样本进行简单的卷积操作,进行分割细节的补充。

图1 MSFFA 网络模型整体结构Fig.1 Overall structure of MSFFA network model
2.1 多尺度注意力
注意力机制的设计主要用于实现对特定特征信息的增强。在MSFFA 中的MSA 模块来源于对颈椎分割图像特征提取有效性的考虑,通过ResNet 进行特征提取后添加简易的Decoder 模块就能取得较好的分割性能[Dice 相似系数(Dice Similarity Coefficient,DSC)约为88%],但ResNet 通过连续卷积操作缺乏全局信息的提取。因此,MSFFA 将ASPP 的思想引入其中,增强对于全局信息的捕获。
ASPP 通过不同步长的卷积操作进行特征提取,然后通过在维度上的叠加获得全局信息,会对原始特征改变较大。出于对ResNet 原始特征的保护,对ASPP 中的特征信息的叠加过程进行了重新考虑,构建基于ASPP 结构的注意力设计:MSA 模块。MSA依赖于ASPP 的结构设计,被用于特征信息的增强,从ResNet 特征出发,通过不同步长的卷积操作将不同感受野的注意力信息引入ResNet 特征信息,对于重要的特征,通过在不同视野上不断增强其权重后,能够获得更好的整体结构信息。
MSA 主要包含特征权重计算和特征融合两个操作。特征权重计算采用金字塔结构的卷积设计获取特征在不同感受野中的权重大小,并对ResNet 生成的高维特征信息进行相乘,实现不同感受野的特征增强。特征融合将金字塔结构和高维权重信息统一后降低通道维数,通过融合模型特征权重来增强不同感受野感受到的特征,达到融合增强的效果。如图2 所示,对于单个步长为2 的卷积注意力,根据训练不同视图的特征信息本身构造不同视图的权重信息,并将生成的权值与特征对应相乘,构造并生成具有空间相关性的权值特征信息。
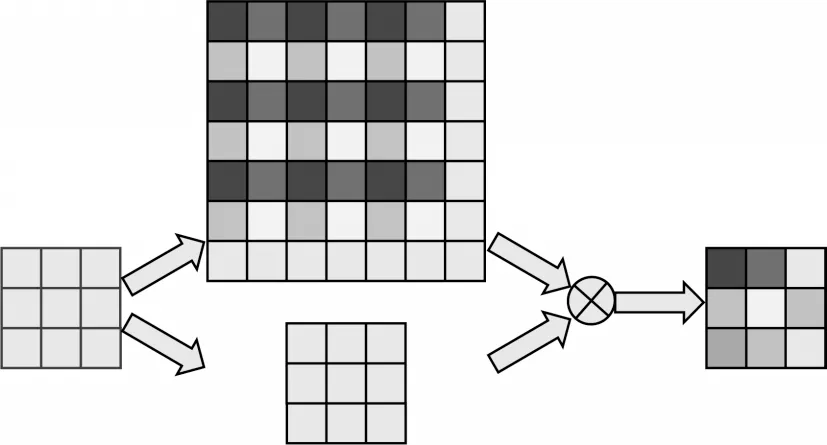
图2 多尺度注意力结构Fig.2 Structure of multi-scale attention
2.2 跨尺度特征融合
由于低维特征往往包含更详细的信息,高维特征更容易训练,在获得高维特征后,模型往往需要将高维特征与低维特征相结合,以增强图像分割效果。为了缓解高维特征和低维特征之间的通道差异以及上采样损失,提出跨尺度特征融合对得到的低维特征构建多个分支,将多个分支进行差异化对比,进一步融合到高维特征中。
CFF 主要实现相似域特征增强和边缘域特征增强,相似域特征增强在结构上保护了重要特征,通过相加的方式增强相似域信息。边缘域特征增强对边界信息进行判断,边缘性判断依据边缘位置差异,通过相减的方式增强边缘域信息。CFF 主要通过不同顺序的卷积运算和上采样运算,使得特征训练过程不同,产生差异的特征。先上采样后卷积的特征信息主要来源于高维空间的转换,先卷积后采样的特征信息主要来源于低维空间的转换,通过具有差异化的跨尺度特征融合实现不同尺度特征信息的融合。跨尺度特征融合结构如图3 所示。

图3 跨尺度特征融合结构Fig.3 Structure of cross-scale feature fusion
2.3 原始特征信息引入
在上述特征信息变化的基础上,获得了H/4×W/4(H和W分别为原始输入图像的长和宽)大小的特征信息,但在上采样过程中,H/4×W/4 大小的特征往往对特征信息的细节保护不够。在最终的分割前,引入原始样本特征,对分割结果进行细节增强。但如果简单地使用原始样本的特征信息,往往会引入大量的噪声,因此不能简单地用原始样本信息与高维特征进行相加完成分割,可以通过一些简单的卷积操作减少噪声的引入。简单的卷积运算包含1 个卷积核大小为3、输入通道为3、输出通道为16 的卷积,1 个BatchNorm模块,1 个ReLU 激活函数和1个卷积核大小为1、输入通道为16、输出通道为64 的卷积。
3 实验与结果分析
3.1 实验设置
对于颈椎分割数据集,采集300 例患者在T2 模态下600 张图像作为数据集,每张图像包括颈椎关节、椎间盘、脊髓、椎管、背景等16 个类别。数据切分按照患者切分,保证切分的独立性,其中,175 例患者的350 张图像用作训练,50 例患者的100 张图像用作验证,75 例患者的150 张图像用作测试。
在实验训练中,优化器统一使用RMSprop,损失函数为交叉熵损失和Dice 损失的均值。批处理大小B统一设置为6,训练迭代次数E 设置为200,初始学习率r设置为0.01,学习率依据验证数据集的Dice 进行自适应调整。测量指标选取Dice 相似系数和交并比(Intersection of Union,IoU)作为参考。通过IoU测量单个类别的实验结果进行比较,并统计模型的训练时间和内存消耗。为了验证实验方案的可靠性和稳定性,实验对比纯卷积运算U-Net、AttUNet、UNet++、DeepLabv3+(ResNet34)、纯Transformer 结构的Swin-UNet以及结 合CNN 和Transformer 的TransUNet 和UTNet 模型,在相同的条件下,每个实验进行5次,均值和方差作为衡量指标,其中,均值作为性能的主要参考指标,方差作为稳定性的判断依据。
3.2 性能比较实验
实验测试了多种常用的图像分割模型的性能指标,并验证了不同模型的分割效果。MSFFA 基于ResNet 作为基准特征提取器,通过调整结构和训练,分割结果在DSC 中达到90.55±0.19%,优于其他模型。单个类别的IoU 分割结果如表1 所示,类别均值结果如表2 所示,其中,最优指标值用加粗字体标示。不同模型在两个实例上的可视化结果如图4 所示(彩色效果见《计算机工程》官网HTML 版)。
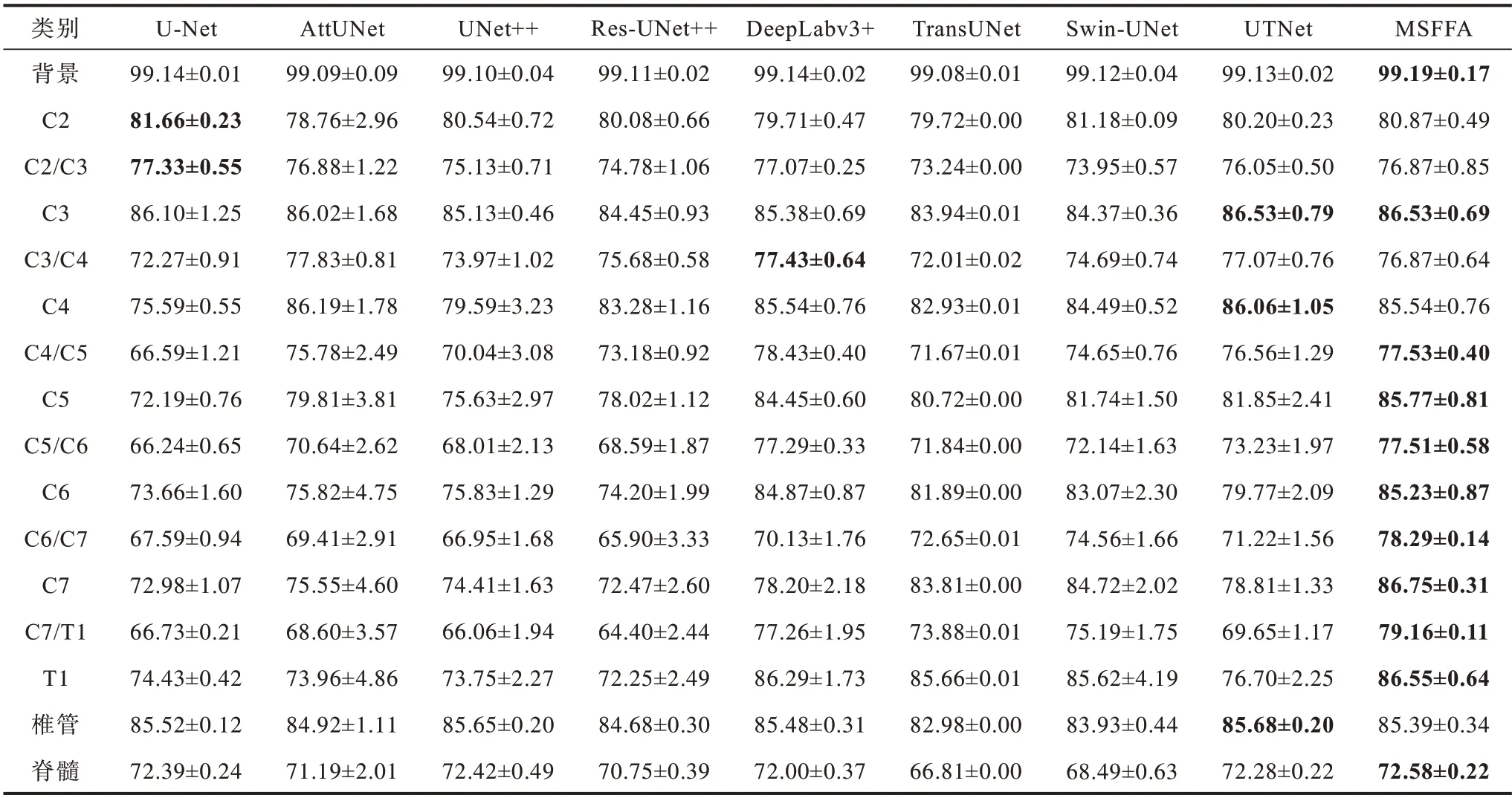
表1 不同模型和分割类别的IoU 比较Table 1 Comparison of the IoUs of different models and segmentation classes %

表2 不同模型的指标均值比较Table 2 Comparison of indicator mean values of different models %
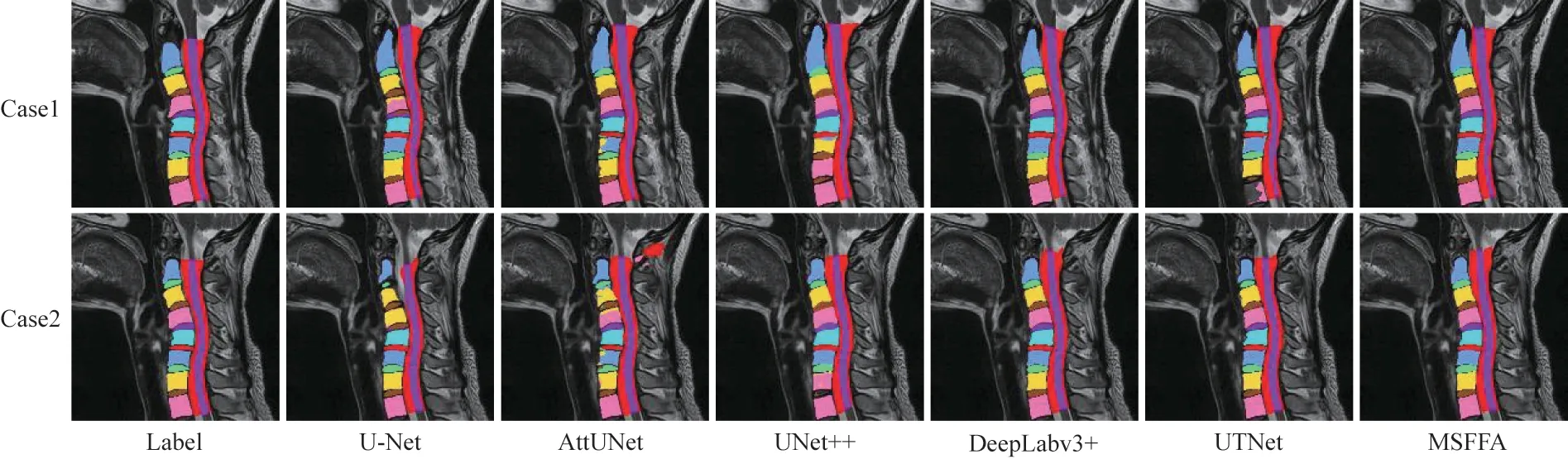
图4 不同模型在颈椎数据集上的分割结果Fig.4 Segmentation results of different models on cervical vertebra dataset
如表1 所示,与其他模型相比,MSFFA 在多个类别上更具优势,证明了该模型在当前数据集上的可用性。如表2 所示,MSFFA 在DSC 和IoU 指标上优于其他模型且方差更小,表明模型更稳定。为了验证每个模型的单独分割性能,选择了U-Net、AttUNet等模型在两个实例上的分割效果进行展示和比较。由图4 可以看出,MSFFA 比多数模型分割更加清晰,且与DeepLabv3+的分割结果相似,但比DeepLabv3+的边缘更平滑。
3.3 消融实验
根据MSFFA 设计,对连续叠加过程中各模块的影响进行多次实验,验证各模块对模型性能的改善效果。各模块叠加过程实验结果如图5 所示,其中,A1 代表多尺度注意力的调整,A2 代表基于A1 的多tap 特征融合的调整,A3 代表基于A2 增加的原始尺度特征进行分割。随着各模块的增加,模型性能不断提高,逐渐趋于稳定状态。
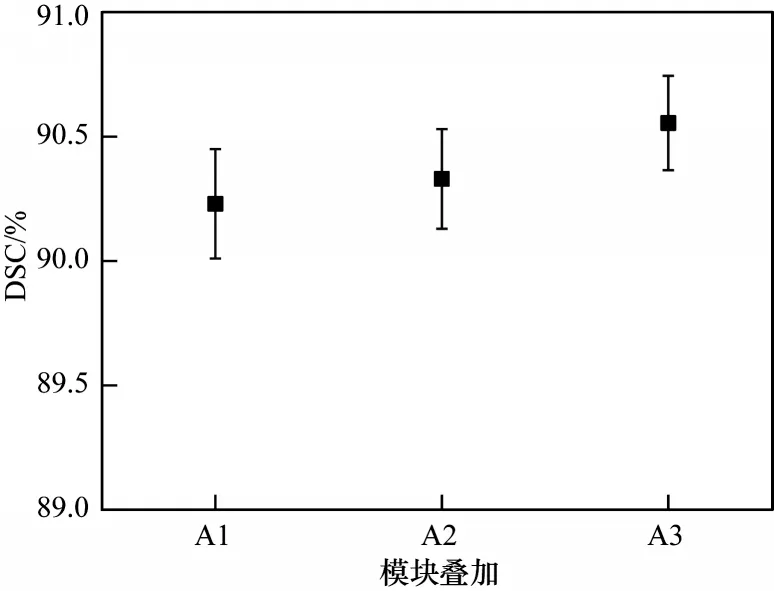
图5 模块叠加的性能变化Fig.5 Performance change of module overlays
为了验证加减法操作对模型训练的影响,设计了“+,+”和“-,-”操作构建多tap 特征融合,分别表示中心特征增强和边缘特征增强。由图6 可以看出,与“+,-”操作进行对比,“+,-”组合更稳定,分割精度略高于另外两种组合,验证了MSFFA 设计的正确性和有效性。
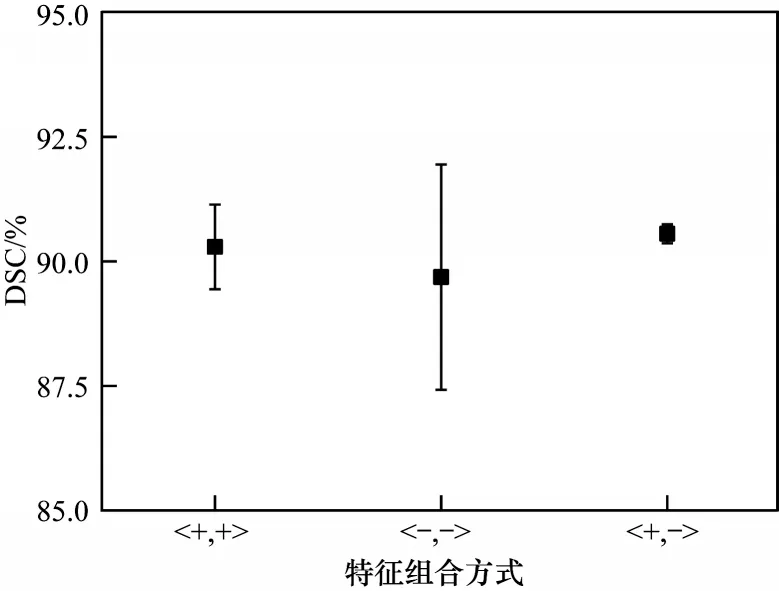
图6 不同特征组合的性能差异Fig.6 Performance difference of different feature combinations
为了验证原始尺寸的样本特征对当前数据集的性能优化效果,引入不同的Dropout,如表3 所示,最优指标值用加粗字体标示。由表3 可以看出,Dropout 的增加使得原始尺寸的样本信息的引入减少,导致性能持续下降,稳定性也有下降的趋势,这说明了完整地引入原始样本信息能有效地增强模型性能,提高模型准确性。

表3 不同Dropout 对原始特征的影响Table 3 Influence of different Dropouts on original features %
3.4 训练时间和内存消耗比较实验
如图7 所示,与所有U 结构网络模型相比,MSFFA 内存消耗更小,单次训练时间也相对更短。由于Swin-UNet 和TransUNet 是针对不同的图像尺寸设计,导致模型尺寸和其他尺寸有较大差异,因此无法直接与它们进行对比。由图7 可以看出,除了DeepLabv3+以外,其他模型具有较低的训练时间消耗和内存消耗,虽然引入了额外的模型结构,稍增加了模型内存消耗和训练时间,但总体变化不明显。

图7 不同模型的平均训练时间和内存消耗Fig.7 Average training time and memory consumption of different models
3.5 泛化性实验
为了验证模型的泛化性,在一个公开的矢状面腰椎分割MRI 数据集[37]上利用相同的实验设置进行实验,共包含514 张带有脊柱测量的图像和注释,图像大小为320×320 像素,图像标签共包含7 个类别的分割,包含1 个背景和6 个椎体信息。数据划分按照7∶1∶2 的比例构建训练集、验证集和测试集。在该数据集中,由于Transformer 对于图像像素信息有一定限制,因此只对CNN 结构的模型进行比较。如表4所示,最优指标值用加粗字体标示,在各模型上共进行5 次实验,对所有类别统计了5 次实验的IoU 和DSC 均值。

表4 腰椎分割性能比较Table 4 Comparison of lumbar vertebra segmentation performance %
由表4 可以看出,MSFFA 在与其他CNN 模型的对比中表现出较高的分割性能,这说明了MSFFA 在椎体分割的医学图像上具有一定的泛化能力,能够在多个类别上具有良好的分割效果,且CNN 的结构设计对图像像素尺寸限制更小,能够以准确的图像信息进行训练预测。
在图8 中选择两个实例进行可视化(彩色效果见《计算机工程》官网HTML 版),可以看出MSFFA在分割结果上更加明显,不存在错误分割脊椎块的问题,并且在细节上分割更平滑。
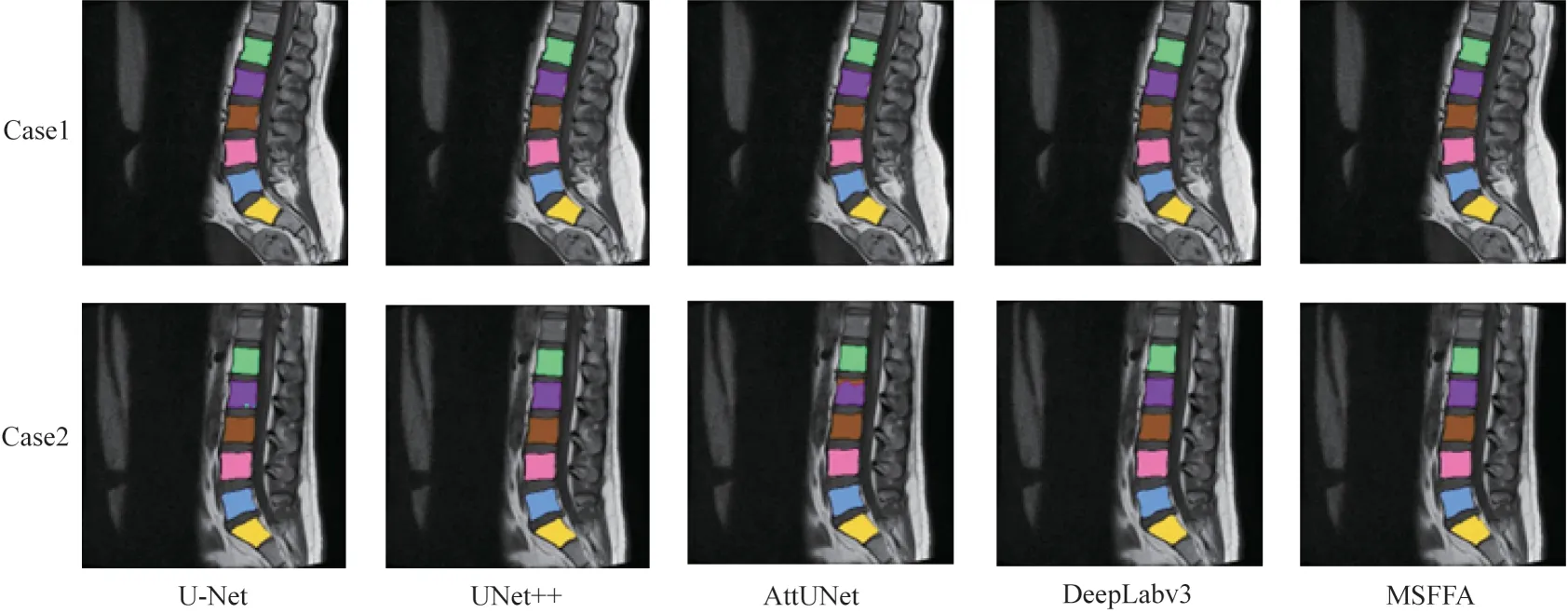
图8 不同模型在腰椎数据集上的分割结果Fig.8 Segmentation results of different models on lumbar vertebra dataset
4 结束语
为了解决颈椎MRI 图像分割模型缺乏、分割边缘提取效果差的问题,本文基于ResNet 提出MSFFA模型。利用多尺度注意力以及跨尺度特征融合对颈椎分割进行优化,增强对于分割边缘的特征提取,实现颈椎MRI 锥体、椎间盘与脊髓的精细分割。实验结果表明,与U-Net、UNet++、AttUNet、UTNet 等模型相比,MSFFA 分割得到的颈椎结构更加完整,边缘更加平滑,同时在腰椎分割中也能取得更精确的分割结果。下一步将针对不同医疗机构采集样本差异问题,采用自适应分割方法,结合颈椎病分类模型,实现全自动颈椎疾病诊断。
