魔方派:面向全同态加密的存算模运算加速器设计
2023-10-17刘怀骏张伟功
李 冰 刘怀骏 张伟功
①(首都师范大学交叉科学研究院 北京 100048)
②(首都师范大学信息工程学院 北京 100048)
1 引言
模算法是密码学中的核心计算,从传统密码[1]到后量子密码全同态加密(Fully Homomorphic Encryption , FHE)几乎都会用到模运算。基于理想格构建的全同态加密由于具有抗量子计算的安全性,自2009年Gentry[2]提出后备受关注,其完整过程如图1所示。经过十几年的发展,全同态密码逐渐从理论走向实际,以BFV[3]为代表的全同态密码机制在医疗诊断、云计算、生物医药、机器学习等领域得到应用[4]。比如,在云计算领域,用户端将数据进行加密,加密数据上传到云端服务器,不解密完成计算,计算结果下载到用户端完成解密,用户端得到计算结果。云端不需要解密完成隐私数据的计算,进一步提高隐私数据的安全。虽然全同态密码提高了隐私计算的安全性,但是全同态密码高昂的计算代价阻碍了其广泛应用。即使经过算法和软件设计优化,FHE全同态加密中一个整数明文的密文数据规模达到53 MByte[5],端侧生成的密钥最大都会达到11 k Byte[6]。密文以及密钥数据规模过大引起严重的计算和访存瓶颈,导致FHE密文上的计算相比未加密数据的计算慢10 000~100 000倍[7]。端侧计算设备的硬件资源有限,一般无法部署能耗高的GPU计算单元,传统的计算机架构[8]在面对全同态加密中数据规模几十MByte的密文以及密钥处理时就会遇到严重的内存墙问题,产生大量数据搬运造成能量消耗。

图1 全同态加密完整过程
存内计算(Processing In Memory, PIM)是不同于传统计算架构的新兴计算范式,具备在存储器内执行计算的能力,基于存内计算的计算设备往往有功耗低、面积小、计算速度高的特点,因而存内计算是为在端侧执行数据密集型应用提供有效的解决途径[9]。本文对端侧全同态加密计算的计算进行分析发现,在端侧的整体计算中,模计算延迟开销占比较大,而且即使是采用优化的计算算法,计算执行时间减少不明显,根本原因是模计算执行过程中,访存行为占用了大量时间。综上,结合存内计算以及全同态加密计算的特性,本文设计一个名为魔方派(Processing-In-Memory Modular , M2PI)的模运算加速器,用来优化全同态加密在端侧中的计算。本文的主要贡献:
(1) 本文分析了CPU 平台上,BFV加密、解密、密钥生成操作中各个关键算子的计算开销,发现模计算的计算开销占比达到了平均41%。进一步地,分析优化的巴雷特算法计算过程中计算和访存操作的延迟,发现访存延迟是造成模计算计算延迟过大的原因。
(2) 本文提出一种基于存内计算阵列的模计算电路。一方面,针对存内计算阵列的计算特性,对巴雷特模计算算法进行优化,减少了计算步骤;另一方面,提出一种基于存内计算阵列的减法电路,完成巴雷特模计算算法中的减法操作。减法操作的优势来自两方面:(a)基于10T-SRAM的存储单元,能够用更低延迟完成NOT,NOR等逻辑操作;(b)优化的加法电路。相比于以往存内计算的加法电路,本文所提的电路用更少的计算周期完成计算。
(3) 在实验中,对全同态BFV方案的各计算操作中,不同规模的被模数和模数的模计算进行评估,实验结果表明,本文所提加速器相比CPU中模计算有1.77倍的计算速度提升以及32.76倍能量的节省。
2 背景
2.1 全同态密码的模计算
模运算是许多加密应用必不可少的,并且密码方案的性能在很大程度上取决于模运算[10]的速度。为了优化模计算的执行,巴雷特模算法是通常采用的优化算法,将模计算中的除法用位运算以及减法来实现。巴雷特模计算的算法如算法1所示。
在全同态加密系统中,端侧主要完成密钥生成、加密和解密计算,在这几种计算中,模操作频繁出现。下面以BFV同态加密方案的密钥生成和加密计算为例说明全同态加密的模计算操作。
(1) 密文生成(Enc):在加密过程,明文多项式(m)与公钥对 (p0,p1) ,经过一定计算得到密文对c=(c0,c1), 密文对生成计算公式为c0=[∆·m+p0·u+e0]q,c1=[p1·u+e1]q,其中u, e0和e1是从高斯分布x采样得到的,e0和e1为误差,[]q是模q计算。

算法 1 巴雷特模算法
(2) 公钥对 (p0,p1)生成(Pk_gen):计算公式,p0=[-(a·s+e)]q,p1=a,其中a从多项式环Rq随机抽样的多项式,e是从高斯分布x随机抽样的误差,s是私钥,一个n次多项式,通过从多项式环R2随机抽样得到,[]q是模q计算。
(3) 重线性化钥生成(Rk_gen):全同态乘法计算会导致密文规模变大,所以需要重线性化钥来控制密文规模。重线性化钥是一组多项式,([-(ai·s+ei+Ti·s2)]q,ai),i∈{0,1,...,l}其中T=。ai从多项式环Rq随机抽样的多项式,ei是从高斯分布x随机抽样的误差。
其中计算中所涉及的多项式次数为n,n通常是2的幂且大于210、而密文模数q通常是2的幂,通常是215, 219, 227甚至更大[11]。因此,全同态加密方案中,模数和被模数规模过大,对模计算的执行造成了巨大压力。本文分析发现在BFV方案端侧的密钥生成、加密和解密操作计算过程中频繁的模计算,而且耗时占比最高。
2.2 存内计算交叉阵列
存内计算(PIM)作为一种非常有潜力的新兴技术,支持在存储单元内完成计算,减少了数据的移动过程,从而缓解数据密集算法在冯·诺依曼架构的数据瓶颈问题。在众多存内计算实现的存储设备中,与忆阻器(Resistive Random Access Memory,ReRAM)和动态随机存取存储器(Dynamic Random Access Memory, DRAM)这些存储设备相比,静态随机存取存储器(Static Random-Access Memory,SRAM)由于其成熟的CMOS制造工艺、低访问延迟和几乎无限的写耐久性备受关注。基于SRAM存内计算阵列可以实现矩阵乘、逻辑计算甚至高精度的浮点计算[12],基于SRAM 的存内计算已经被应用到全同态加密计算中,用于提高全同态加密计算的执行效率。例如文献 [13]利用6T-SRAM实现了格密码加密机制中用到的数论变换(Number Theoretic Transform, NTT)算法的加速;文献[6]也是为了加速格密码加密机制中用到的NTT;还有一些工作也用到了存内计算架构来加速加密过程,如文献[14]主要优化了全同态计算(全同态加、减和乘),他们在提出的设计结构中实现了大数乘法,以此提高整体加密计算的速度;文献[15]在内存中实现端到端的全同态加密(FHE)计算,并且全同态加密计算中开销最大的自举(Bootstrapping)操作进行了加速。这些工作都展示了存内计算阵列是有效缓解全同态加密中内存墙问题的解决方案,但是这些工作大多都是为了加速云侧的全同态计算,对于端侧的各个计算过程执行过程以及算子尚缺少深入的分析,而端侧的全同态加密在云计算场景中至关重要,所以本文提出了基于存内计算的加速端侧计算的瓶颈:模运算,以此使得端侧的计算执行过程速度得到提高。
3 基于存内计算阵列的模计算
3.1 研究动机
本文分析全同态加密中端侧执行的4个计算过程:公钥生成(Pk_gen)、重线性化钥生成(Rk_gen)、加密(Enc)以及解密(Dec),发现在每个计算步骤中,巴雷特模计算的执行时间超过多项式计算的执行时间,而巴雷特计算执行时间过长的问题是访存延迟造成的。在实验中,本文参考pyFHE[16]库在C++中实现了BFV方案,统计各个计算步骤中模计算以及多项式计算在Intel(R) Core(TM) i7-7700HQ CPU平台上的执行时间。考虑到模计算的数据规模由多项式系数n,密文模数q决定,在不同规模的密文模数q情况下,对端侧4个计算过程中模计算的执行时间分别进行了统计,并与它们各自的多项式计算延迟进行对比。端侧4个计算过程中模计算与多项式计算执行时间对比如图2所示。参考文献[17],将密文多项式的系数n设置为1 024,图2(a)—图2(c)中密文模数分别对应q=215, q=219以及 q=227。可以看出,在不同计算过程中,模运算比多项式计算的执行时间长,尤其是在重线性化密钥生成(Rk_gen)的计算中,模计算的执行时间是多项式乘法的1.6倍。本文进一步分析了巴雷特模计算的执行时间,结果如图3所示,可以看出巴雷特模的执行时间与普通模计算相比,计算执行时间并没有显著下降,甚至有的计算中,巴雷特模比模运算的执行时间还略高,比如重线性化密钥生成(Rk_gen)中模计算的计算执行时间反而比之前增大了19%。本文以q=227为例,分析端侧4个计算过程中巴雷特模中计算时间和访存时间比例,结果如图4所示,4个计算中,巴雷特模计算用于计算的时间最高仅仅占到了模计算总时间的3%,而访存时间最高却占到了97%的比例,访存明显成为模计算计算效率的瓶颈,而存内计算能够在存储器中完成计算,大大降低了巴雷特模中数据搬运导致的过高的计算延迟。
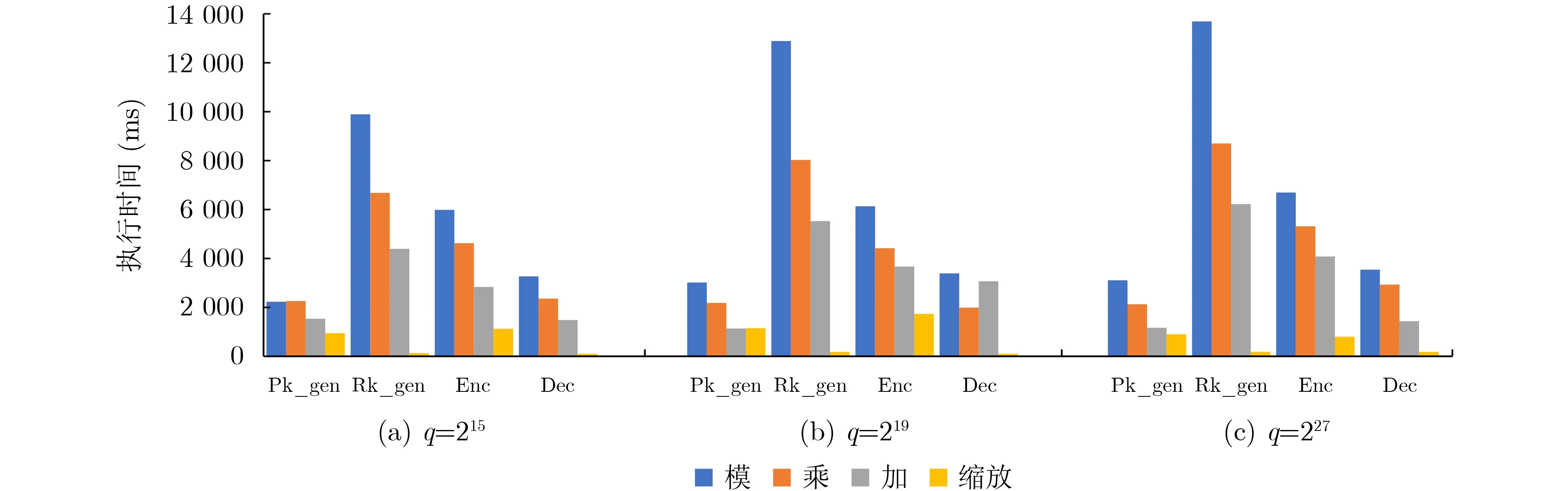
图2 不同参数规模下各阶段算子执行时间对比
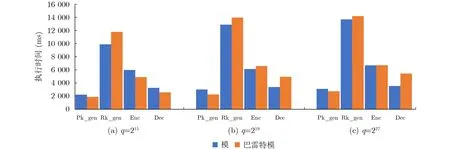
图3 优化前后模计算延迟对比
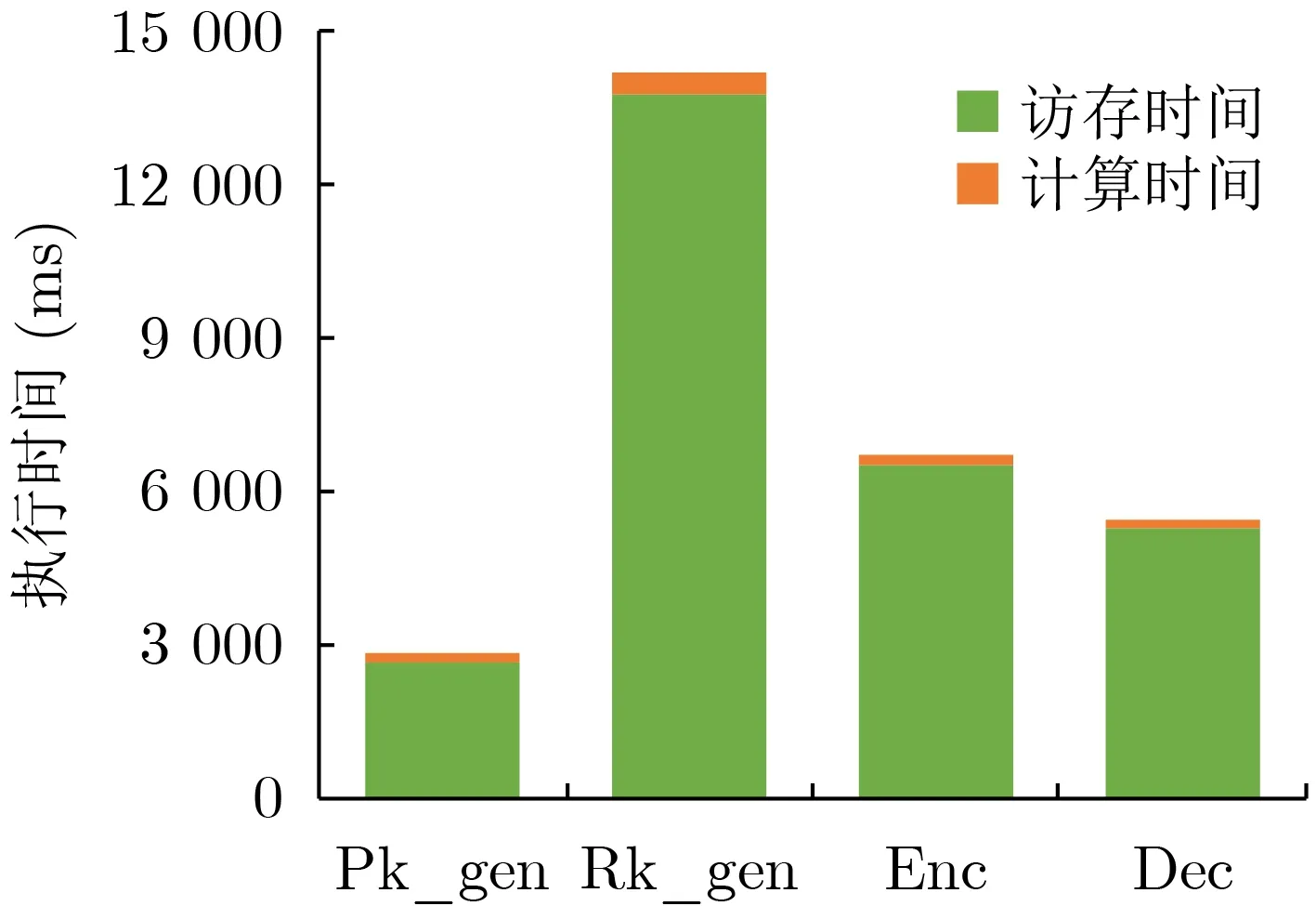
图4 巴雷特模运算中计算和访存时间对比
3.2 模计算阵列设计
针对模计算的访存瓶颈,本文提出一种基于PIM阵列的模计算执行单元,在被模数的存储位置进行计算,避免了数据搬运产生的开销。模计算存内阵列的总体设计如图5(a)所示。本文的模计算PIM阵列是128×512大小,阵列的基本存储单元是10TSRAM[18],支持读写并行,如图6(a)所示。在计算之前,被模数(即多项式系数)存储在SRAM的行中。特别地,巴雷特模计算中的除法和乘法操作由存内计算阵列的移位操作完成。如图5(b)所示阵列用来执行大数的移位和减法操作,其中每个存储单元完成按位逻辑运算。为了实现移位和减法操作,本文存内计算阵列包含以下功能模块:预充电器、控制器、行解码器、移位掩码器、读控制器、写控制器和比较器[19],用于支持读写的同时进行,以及逻辑计算操作,下面介绍各功能模块的不同作用:
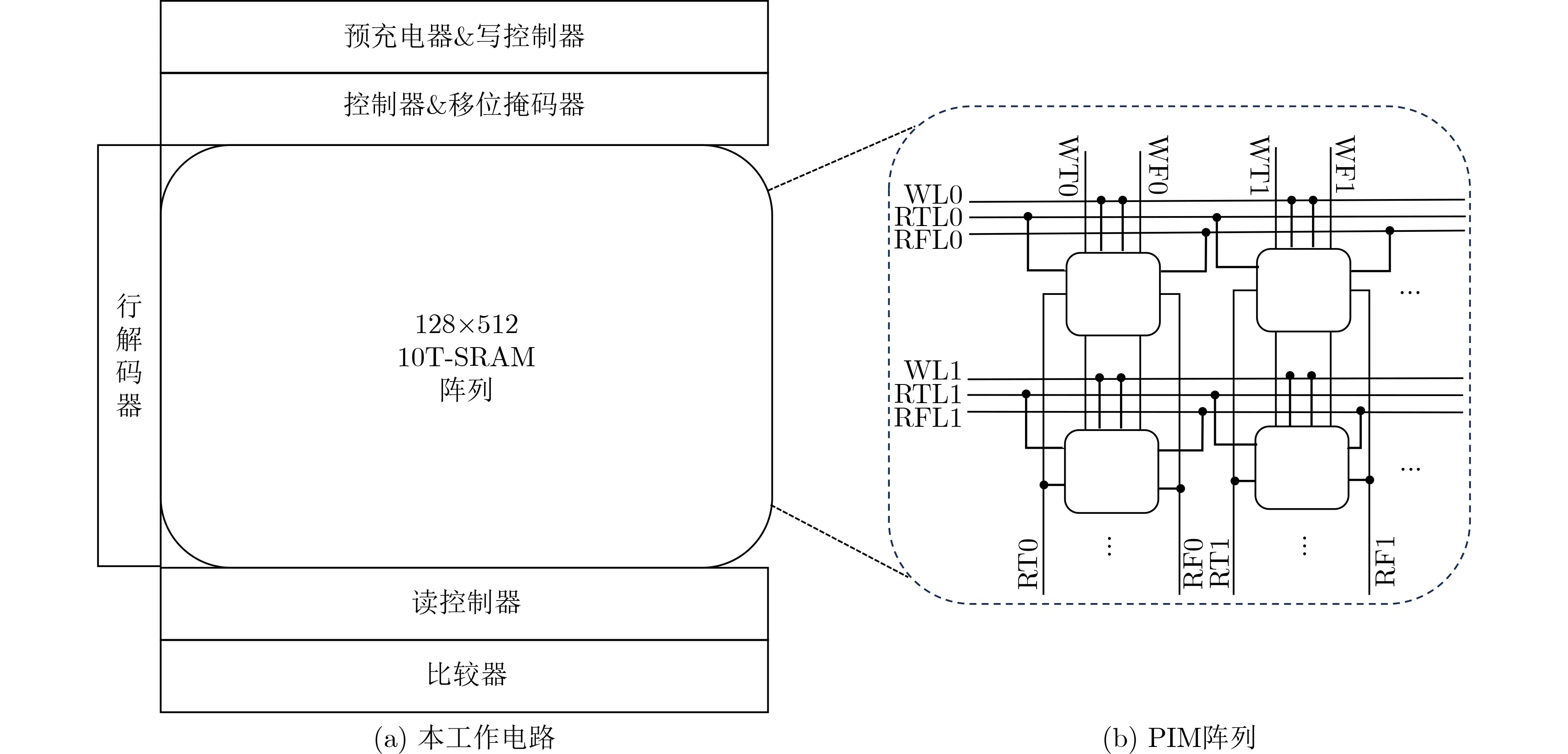
图5 用于模计算的 PIM 阵列
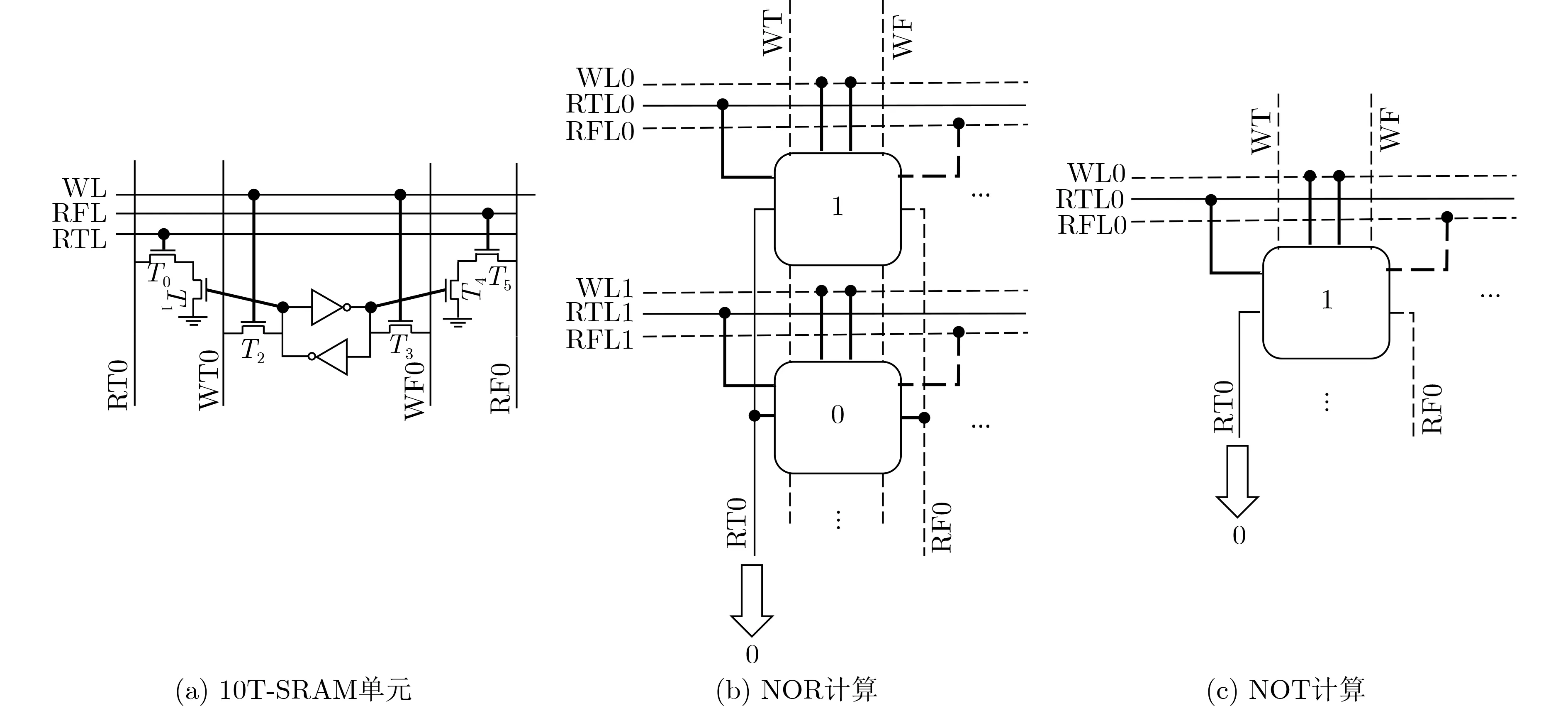
图6 按位逻辑计算
(1)控制器:控制电路操作的执行,产生读、写、具体的逻辑计算操作的控制信号。
(2)行解码器:激活需要写操作时的WL线,读操作和计算时RTL和RFL线。
(3)移位掩码器:接受模数的位数信息,用于产生移位操作的地址掩码以及移位操作的方向,其中掩码最高位是移位码,1表示左移,0表示右移。
(4)读控制器:根据RTL和RFL线的选通情况控制电路每列的RT和RF线进行读取操作,RT和RF线仅用来进行读操作,以及逻辑计算。
(5)写控制器:根据WL选通的待写入行,控制电路的各个WT和WF线对SRAM单元进行写操作,WT和WF线仅用来进行写。本文设计独立的读位线和写位线,支持读写并行性。
(6)比较器:用于对计算结果是否在需要的范围内进行判定,然后根据判断的不同情况决定下一步的操作。
3.2.1 逻辑计算存内计算单元
(1)按位逻辑计算。本文设计的阵列采用10TSRAM单元,其电路图如图6(a)所示,支持同时读写,每个存储单元完成按位逻辑计算。RT和RF位线用于逻辑运算的实现,当仅导通RTL线时晶体管T0会先被导通,将RT0预充电到VDD电位,如果存储单元中存储的数据是1也就是高电位,晶体管T1就会导通,经过两个晶体管T0和T1将RT0线的电位放电至低电位。反之如果存储的是0,晶体管T1就不会导通,这样一来RT0就保持了高电位。依据此逻辑,将一列中两个单元同时用RT线读取,读出的汇聚电压就是两单元的NOR逻辑运算结果。图6给出了本文利用10T-SRAM单元完成NOR计算和NOT计算电路示意图。图6(b)是完成两个数值的NOR,其中实线表示选通的线,虚线表示没有选通,同列中两个单元分别存储了1和0,同时导通RTL0和RTL1线,输出结果0从RT0读出,这样,通过读操作完成NOR的计算。如图6(c)所示,单个单元导通RTL0用RT0线读取,就实现了NOT逻辑,得到NOT结果0。
(2)N位逻辑计算。依据以上按位逻辑计算的存内单元,实现N位数据的逻辑计算,如图7所示。图7(a)中两个N bit数据的逻辑NOR运算,两个N bit数据分别存储第0行第0列到n–1列和第1行第0列到n–1列,执行计算时,RTL0和RTL1线同时导通,NOR运算的结果从RT0到RTn–1进行读取。同理,一个N bit数据的NOT计算,如图7(b)所示,通过导通RTL, NOT计算结果从RT0到RTn–1进行读取。

图7 多比特逻辑运算
3.2.2 基于存内计算阵列的巴雷特模
本文首先约简巴雷特模算法,消除其中的除法和乘法,简化为1次右移,1次左移以及1次减法;之后利用PIM按位并行计算的优势,在存内阵列实现高效的移位和减法操作,从而完成巴雷特模计算。
(1)巴雷特模优化。算法2是优化后的巴雷特模,这里省略算法1中第(1)步的除法过程,合并了第(2)(3)(4)和第(6)步中的右移和乘法,将它们转化为1次右移和1次左移运算,如算法2中(1),(2)步所示。
(2)优化后的存内巴雷特模计算。存内计算阵列中的移位和减法计算如图8(a)、图8(b)所示。
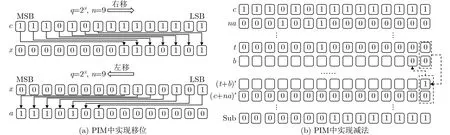
图8 PIM 中实现计算
(a) 右移:根据移位掩码器给出的掩码地址信息,在模计算结果行的MSB位地址单元开始依次写入n–1个0,同时,将被模数c的MSB位写入之后的位置,直到该行数据写满。这样,c中溢出部分自动截断,完成右移计算,移位结果x存储在阵列中。阵列同一行中存储的所有被模数都可以同时进行计算,所以只需使能1次移位计算就可以同时得出该行所有待计算数据的移位结果。
(b) 左移:根据移位掩码器给出的掩码地址信息和左移信号,在结果行的LSB位地址开始写入n–1个0,被模数x 从LSB位顺序写入余下地址,移位结果a存储在阵列中。

算法 2 PIM中执行巴雷特模算法
(c) 减法:最后执行c-a操作,这里通过补码加法实现。本文在内存阵列中首先实现了全加器逻辑[20],减法过程如算法3所示,其中形如(c+na)′的计算表示N OR(c,na), t和b为中间结果变量。NOR运算按照3.2.1节中多比特逻辑计算进行的。在阵列中开辟一行存储a的补码,再依据多比特逻辑计算完成第(1)步中的NOR计算。需要注意的是,第(2)步是加法逻辑中的进位计算过程,并不能按照多比特逻辑计算那样完成所有比特的计算结果,因为高比特需要等待低比特的进位结果再执行计算,由此只能逐比特进行计算(将b最低位初始化为0),如图8(b)所示的计算流程。最后再根据多比特逻辑计算完成第(3)步得到Sub这一行就是c与a的减法结果。

算法 3 PIM 中实现减法
4 实验结果及分析
4.1 实验设计
为了评估本设计的延迟和能耗,本文首先通过Virtuoso平台采用65 nm工艺,激励源时钟频率为100 MHz,供电电压为1.1 V,对10T-SRAM单元进行了验证仿真,得到其读写延迟为6.61 ns,读能量293.3 fJ,写能量316.3 fJ,如表1所示。器件的参数参考了Yang等人[21]的工作。然后本文修改Neurosim[11]模拟器中的阵列设计参数,采用同样的65 nm工艺,阵列的时钟频率为100 MHz,供电电压为1.1 V,阵列单元总数为65 536个,每个单元存储1 bit数据。对本文设计的模计算阵列进行了延迟和能量的仿真计算。存内计算阵列的总面积为0.069 mm2。

表1 实验参数设置[11,21]
为分析本设计对于加密算法中模运算效能的提升,本文根据实验设置1:q=215;实验设置2:q=219;实验设置3:q=227来进行优化效果验证。观测分析这3种实验参数下,本文设计的PIM阵列中执行模运算的效果。依据本文的实验设计对实验CPU中的延迟和能耗进行了统计,并将实验结果与在CPU中直接进行模计算结果(图10中CPU_Mod)以及在CPU中执行巴雷特模计算结果(图10中CPU_Barrett)进行了对比。
4.2 实验结果
本文方法相较于软件中执行巴雷特模计算算法(CPU_Barrett),在q=215, q=219, q=2273种参数设置下执行时间都有非常明显的提升,如图9所示。q=215时巴雷特模计算速度提升最高,其4个计算过程的模计算执行速度总和提升了3.27×104倍;而q=227时巴雷特模计算相对提升的速度较少,但4个计算过程的模计算执行速度总和也提升了1.74×104倍。而后本文又以在CPU中直接执行4个计算过程的总时间为基准,对比了3种参数设置下端侧4个计算过程总时间(模计算加多项式计算时间和)在本设计中执行速度的提升。结果如图10所示,3种参数设置下的执行时间均有明显提升,其中在q=227时整体计算执行速度提升了1.77倍。公钥生成(Pk_gen)阶段在q=227时提升速度最高达到1.74倍,3个参数设置的公钥生成速度平均提升了1.63倍;重线性化密钥生成阶段(Rk_gen)在q=219时提升速度最高达到1.94倍,3个参数设置的重线性化密钥生成速度平均提升了1.91倍;加密阶段(Enc)在q=215时提升速度最高达到1.7倍,3个参数设置的加密速度平均提升了1.66倍;解密阶段(Dec)在q=215时提升速度最高达到1.84倍,3个参数设置的解密速度平均提升了1.76倍。本文统计了端侧4个计算过程总体计算过程能量的消耗情况,如图11所示。本文以在CPU中直接计算4个计算过程的执行能量为基准,可以看出:在本文所提出的方案中进行计算能量消耗最低在q=215时相较于CPU 4个计算过程平均节省了32.76倍,在q=227时消耗能量最高4个计算过程也平均节省了7.99倍。
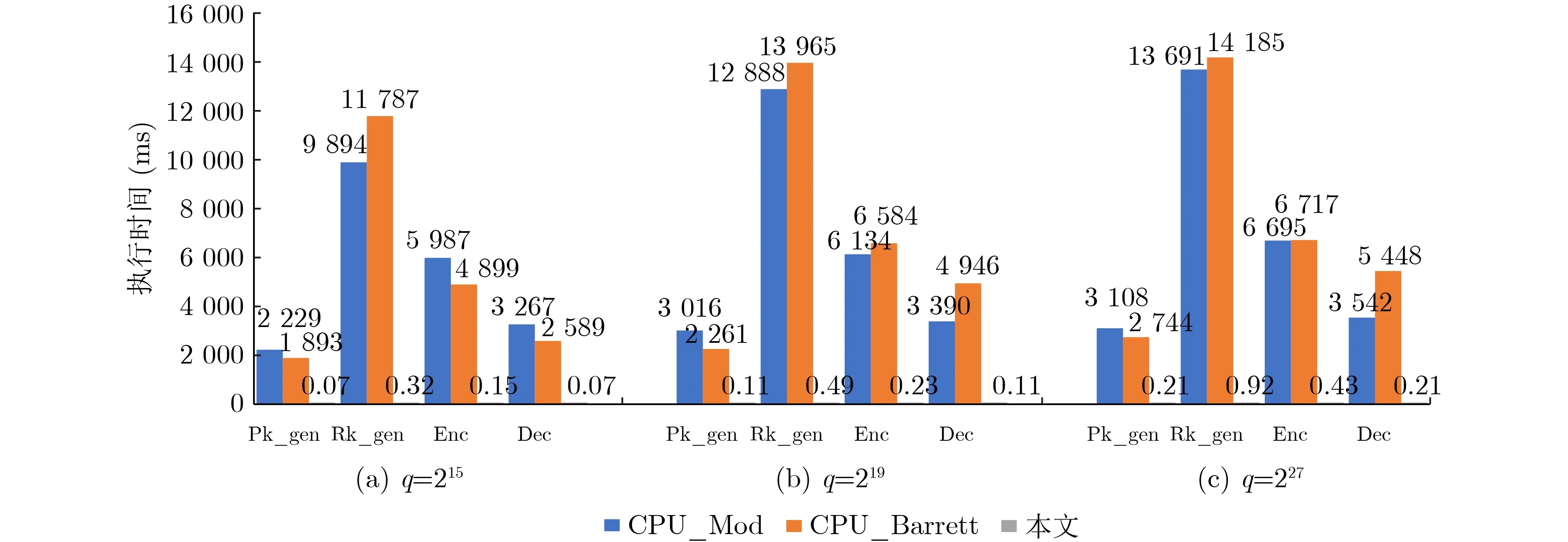
图9 PIM 中执行模运算与之前结果对比
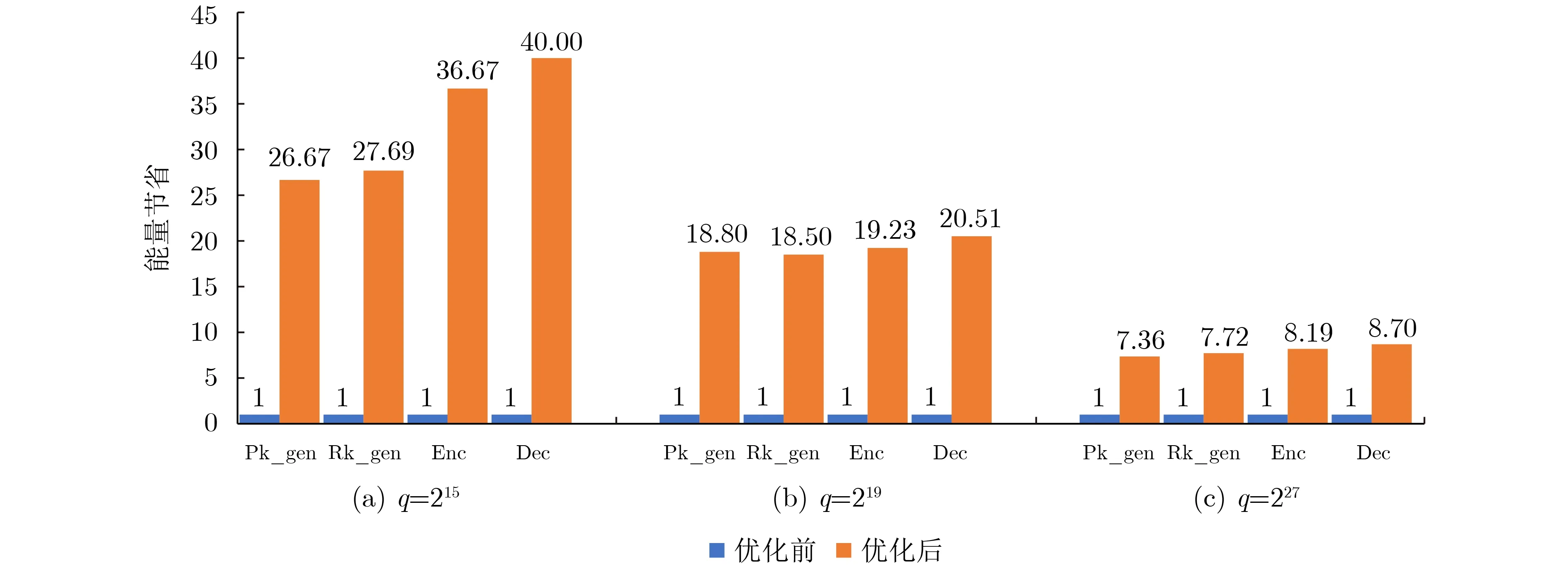
图11 优化前后 4 个计算过程执行能量节省
5 结论
本文提出一种基于存内计算阵列的模运算加速器,并针对不同参数设置下的模运算分别进行了实验比对。结果表明,本文加速器相比CPU有1.77倍的计算速度提升以及32.76倍能耗的节省。
