基于双塔隐语义与自注意力的跨域推荐模型
2023-10-16操凤萍张锐汀窦万峰
操凤萍, 张锐汀, 窦万峰
(1.东南大学成贤学院计算机系, 南京 210088; 2.江苏远程测控技术省重点实验室, 南京 210096;3.华泰证券股份有限公司, 南京 210019; 4.南京师范大学计算机科学与技术学院, 南京 210023)
跨域推荐能够利用信息量充足的源域对信息量不足的目标领域进行补充,缓解目标领域数据稀疏问题.跨域推荐一般需要满足如下条件:两个或多个领域间存在内容层级的相关性;或存在用户层级的相关性,有用户上的重叠关系;或存在项目层级的相关性,有项目上的重叠关系[1].目前跨域推荐方法大多属于如下三类[2].
第一类,基于协同过滤的跨域推荐.主要利用具有相似偏好的用户之间相关性,为目标用户推荐相关产品或项目[3-4].Berkovsky 等[5-6]将源域的共现矩阵Rs与目标域的共现矩阵Rt拼接成一个完整的共现矩阵R,并使用单域方法对用户进行项目推荐.Ajit等[7]利用联合矩阵分解进行协同过滤,构造加权损失函数并使之最小化,从而得到目标矩阵并依此对用户进行项目分配.这些方法通常计算速度快、时间复杂度低,但推荐效果往往不够理想.
第二类,基于语义关系的跨域推荐.该类方法常常需要利用图模型进行建模,在构建好的模型上基于图表示学习的方法进行数据处理得到特征表示,并依此进行跨域推荐.Jiang 等[8]通过构建图模型将不同领域数据串联起来,利用随机游走方法进行用户与项目间的匹配度预测.Zhu 等[9]首先基于图嵌入方法得到数据的特征表示,然后利用注意力机制将源域的数据信息迁移至目标域,最后利用经过知识迁移的目标域模型进行个性化推荐.图模型将多个领域串联起来,以解决不同领域数据的异构问题.然而对于大规模的互联网数据,图模型处理起来难度较大,计算速度较慢.
第三类,基于深度学习的跨域推荐.该类方法一般包括特征提取、特征映射、个性化推荐等几个步骤.Man 等[10]提出一个深度学习跨域推荐框架,利用隐语义模型获取用户和项目的隐语义特征,并利用线性映射或多层感知机的方法将源域特征映射至目标域中,最后利用特征映射后隐语义进行跨域的个性化推荐.Zhu 等[11]利用深度网络对特征进行跨域映射,并将源域目标域的数据稀疏度作为模型训练中的重要参数,从而提升数据的使用效率.Gao等[12]将注意力机制和隐语义模型进行结合,利用注意力机制来调整带有辅助信息的隐语义特征的相关系数,从而提升跨域推荐的效果.随着深度神经网络和图学习技术的发展,跨领域推荐引起越来越多人的研究和关注[1].
近几年,学者们从融合邻域辅助信息的角度,对深度学习跨域推荐方法进行了研究.但在跨域推荐中,或多或少仍存在辅助信息利用不足、源域特征迁移不充分、负迁移等问题[13-16].本文提出了基于双塔隐语义与自注意力的跨域推荐模型(DLDASA),框架如图1所示.其包括基于双塔隐语义模型的隐语义特征提取、引入域适应的隐语义特征迁移、借助自注意力机制缓解负迁移问题并跨域推荐这三个部分.本文主要贡献如下.
1) 在隐语义模型的基础上引入双塔结构,充分获取高质量隐语义以提升后续跨域推荐的效果.
2) 在传统的多层感知机迁移方法中引入域适应过程,有效对齐源域与目标域的特征分布,将源域信息更充分地迁移至目标域.
3) 利用自注意力机制缓解负迁移问题,迁移时对差异信息进行筛选与融合,补足目标域信息,提升跨域推荐效果.
4) 设计多组对比实验验证了DLDASA模型的有效性,验证了模块作用.
1 研究基础
1.1 隐语义模型
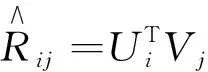
矩阵分解(matrix factorization)和神经矩阵分解(neural matrix factorization)作为跨域推荐算法中特征提取的主要方法,利用了用户与项目间的交互信息,但并未考虑用户与项目的额外信息.隐语义模型与 Item2Vec[18]神经方法相结合,能够将用户项目信息进行向量化处理,然后利用网络提取数据的嵌入表示,同时还可以引入双塔模型进行拓展.本文基于Item2Vec方法提出了双塔隐语义模型.
1.2 域适应
领域自适应 (domain adaptation),也称域适应,属于基于特征的迁移方法.它研究如何将从源域学习到的知识更好的迁移至目标域.特征自适应目的是学习一个域间不变的特征表达.

推荐的场景下,源域与目标域的数据均无标签属性,在“是否存在标签”这一条件上与传统迁移学习是不相符的.但在“缩小域间分布差异”这一问题上,推荐场景与经典的迁移学习场景是一致的,本文利用域适应方法缩小源域数据分布与目标域数据分布之间的差异.
1.3 自注意力机制
特征迁移可能使不合适的源域项目隐语义迁移至目标域的某一项目之上,存在着负迁移.单纯注意力机制无法聚焦于编码器端输入中值得被关注的部分,自注意力机制(self-attention mechanism)由 Ashish 等[19]提出,其结构如图1所示,其自下而上分为输入层、注意力全连接层、输出层.自注意力机制的核心是通过Q和K计算得到注意力权重;然后再作用于V得到整个权重和输出.输入的w1、w2、w3通过式(1)可以计算出查询键(query,Q) 、推导键(key,K)和输出值(value,V).

图1 自注意力机制结构Fig.1 Self-attention mechanism structure
k=Wkw;
q=Wqw;
v=Wvw,
(1)
得到各查询键Q={q1,q2,…,qn}、推导键K={k1,k2,…,kn} 和输出值V={v1,v2,…,vn}后,各个特征wi关于其余特征 {wj∣j=1,2,…,n}的相关性α可以通过式 (2) 得到:
(2)

(3)
综合式(1)、(2)、(3)即可得到自注意力公式(4):
(4)

(5)
MultiHead(w)=Conca(head1,head2,…,headh)Wh,
(6)
利用多头策略,将多个输出进行拼接得到最终输出.
本文由于利用自注意力机制对输入的源域特征信息进行筛选和汇聚,使目标域的项目按相关程度来获取源域信息,从而更好地进行特征迁移,以提高跨域推荐的性能.
2 DLDASA算法
2.1 DLDASA算法框架
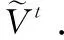

图2 DLDASA模型框架Fig.2 DLDASA model framework
模型具体包括如下三个过程.
1) 隐语义预训练:利用双塔隐语义模型获取各隐语义特征表示,经多层神经网络训练后,可得到输出.预训练后V,U=DLLFM(R,info),其中,DLLFM(·)为双塔隐语义模型,R为共现矩阵,info为用户类别偏好信息和项目类别信息等.
2) 特征迁移:将源域与目标域的项目隐语义,进行基于一阶统计量和二阶统计量对齐的领域自适应迁移方法,对源域特征进行特征迁移,如式(7)所示.
(7)

3) 跨域推荐:域适应方法特征迁移后,为减轻特征迁移时所产生的负迁移影响,使用自注意力机制进行调整,如式(8)所示.
(8)
(9)

(10)
(11)
2.2 双塔隐语义模型
双塔隐语义模型在特征提取过程中融入用户类别偏好信息和任务类别信息.它利用广义Item2Vec 方法将用户、用户类别偏好信息、项目、项目类别信息分别进行向量化处理和整合,输入项目塔与用户塔之中.双塔隐语义模型如图3所示.

图3 双塔隐语义模型Fig.3 Two-tower latent semantic model
1) 输入层(input layer):输入层包括四个部分,用户 ID(user ID)、用户类别偏好信息(user type)、项目ID(item ID)和项目类别信息(item type).首先对用户隐语义矩阵Wu∈m×k、 项目隐语义矩阵Wv∈n×k、类别隐语义矩阵Wt∈d×k进行随机初始化,然后利用式(12)计算出用户隐语义(user embedding)、用户类别偏好隐语义(user type)、项目隐语义(item embedding)、项目类别隐语义(item type)的嵌入表示.
ui=xu,iWu;uti=∑xut,iWt;vj=xv,jWv;vtj=∑xvt,jWt,
(12)
其中,xu,i、xut,i、xv,j、xvt,j为用户、用户类别偏好、项目、项目类别的One-hot编码,用户类别偏好与项目类别均经过归一化.通过One-hot编码,得到用户隐语义矩阵、项目隐语义矩阵、类别隐语义矩阵中存放着的用户隐语义ui、用户类别偏好隐语义uti、项目隐语义vj、项目类别隐语义vtj.
2)融合层(fusion layer):对于双塔模型,项目塔的融合层与用户塔融合层类似,在得到项目隐语义vj和项目类别隐语义vtj后,对两个特征进行融合,利用项目类别信息对项目隐语义进行信息补充,如式(13)、(14)所示.
(13)
(14)
其中,θu和bu为用户融合函数的参数,θv和bv为项目融合函数的参数,ui,uti,vj,vtj∈k.最终得到的中既包含用户与项目的交互信息,也包含用户自己的类别偏好信息和项目的类别信息.

(15)
而后通过最小化损失函数(均方误差)对模型进行训练,如式(16)所示.
(16)

2.3 基于域适应的知识迁移
域适应方法通过对齐一阶统计量(均值)和二阶统计量(方差)统计特征的方法,将数据的统计特征进行变换对齐,不需要利用标签属性,也避免将数据映射到高维空间.
设源域项目隐语义DS={x1,x2,…,xs},xi∈k,目标域项目隐语义Dt={y1,y2,…,yt},yj∈k.假设μs,μt是源域与目标域项目隐语义的均值(一阶统计量),CS,CT是源域与目标域项目隐语义的协方差矩阵(二阶统计量).将隐语义特征进行标准化,如式(17)、(18)所示,
(17)
(18)
(19)
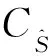

由Sun等[22]的工作知,设Σ+为矩阵Σ的广义逆矩阵,rCS,rCT为矩阵CS,CT的秩.那么,式(20)为目标函数式(19)的最优解,
(20)


算法1基于领域自适应的特征迁移方法
Input:源域特征,目标域特征
1:一阶统计量对齐:
2:二阶统计量对齐:
3:完成迁移:
2.4 自注意力机制
基于自注意力机制的跨域信息整合流程如图4所示.

图4 自注意力跨域信息整合示意图Fig.4 Self-attention cross-domain information integration
zij=Similarity(vt,Vs),
(21)
其中,Similarity(·,·) 表示相似度计算函数,用内积作为相似度的度量方式.之后对其归一化处理如式(22)所示,αij=softmax(zij),
(22)
其中,αij为注意力系数,表示目标域项目i与源域项目j的相关度.之后, 计算得到源域项目隐语义的加权平均结果αiVs,利用该结果计算得到融合系数
c=sigoid(Dense(αiUs),
(23)

(24)

3 实验
3.1 数据集
1) 一品威客(YPWK)和猪八戒网(ZBJW)
一品威客(YPWK)和猪八戒网(ZBJW)是国内知名众包领域平台,包含软件测试的15类项目和7个类别标签.稀疏度为44.53%的一品威客网数据视为源域,稀疏度为84.56%的猪八戒网数据视为目标域,数据集如表2所示.

表2 YPWK&ZBJW数据集
2) Movielens和Netflix
随机选取5 000个用户和2 500个电影的数据集,该数据集带有20个类别标签.稀疏度为97.90%的Movielens数据为源域,稀疏度为99.32%的Netflix数据为目标域.数据集如表3所示.

表3 Movielens&Netfl数据集
3.2 评价指标
实验评价指标:均方根误差(root mean squard error,RMSE)和平均绝对误差(mean absolute error,MAE),这两种方法均通过计算预测结果与实际值的误差大小来进行评价.
(26)
(27)
其中,m表示测试数据的数量,yi表示测试数据真实的评分,f(xi)表示模型计算后的预测评分.
3.3 基准模型
为了验证DLDASA模型的有效性,设置单域推荐和跨域推荐两类对比实验.单域推荐模型包括:
1) CF-user[3-4]:基于用户的协同过滤推荐.
2) CF-item[3-4]:基于项目的协同过滤推荐.
3) MF[5]:矩阵分解.将共现矩阵进行神经矩阵分解,得到用户特征矩阵与项目特征矩阵,并基于两个矩阵进行推荐.
跨域推荐模型包括:
1) Cross-domain CF/item[6]:将源域f的共现矩阵Rs和目标域的共现矩阵Rt合并为一个共现矩阵,并以单域推荐中的CF-item进行推荐.
2) CMF[7]:将源域矩阵分解损失函数与目标域矩阵分解损失函数按照一定的权重进行加和,得到新的损失函数,将其最小化可以得到该模型的特征矩阵,从而进行推荐.
3) EMCDR[10]:利用隐语义模型获得源域与目标域的隐语义特征,而后利用线性映射或多层感知机的特征映射方法进行特征迁移,并以此进行推荐.EMCDR/LM表示跨域推荐过程中使用线性映射(LM),EMCDR/MLP表示跨域推荐过程中使用多层感知机映射(MLP).
3.4 实验结果与分析
DLDASA模型首先利用双塔隐语义模型(DLLFM)获取隐语义特征,这部分实验选用参数如表4所示.其次利用基于统计特征对齐的领域自适应(DA/MLP)方法对源域项目隐语义进行特征迁移,这部分实验无额外参数.最后,基于自注意力机制的跨域推荐,所需其他参数如表5所示.
表4 DLLFM模块参数设置

表5 Self-Attention模块参数设置
采用Xavier[23]方法对用户隐语义矩阵、用户类别偏好隐语义矩阵、项目隐语义矩阵、项目类别隐语义矩阵及各项参数作随机初始化处理.模型中的偏置项均设置为0,参数的数值及含义如表4所示.用神经元节点随机缺失Dropout方法和L2正则化的方法防止过拟合.使用Adam优化器训练,设置β1=0.9,β2=0.99,多组实验调参后学习率定为0.05.
在Win10下进行实验,使用Tensorflow 1.14.0作为深度学习框架.CPU为Intel(R) Core(TM) i5-8300H CPU@2.30GHz,GPU为NVDIA GeForce GTX 1050Ti 4G,内存为 8G.
表6显示DLLFM-DA/SelfAtten(DLDASA模型)在2个数据集上,RMSE指标和MAE指标均优于对比模型,且均为最优结果.DLDASA模型在“YPWK-ZBJW”数据集上的RMSE值和MAE值分别为0.267 2和0.138 0,比效果最好的EMCDR/MLP模型分别提高了34.3%和55.4%.在“Movielens-Netflix”数据集上的RMSE值和MAE值分别为0.547 2和0.403 5,对比效果最好的EMCDR/MLP模型分别提高了42.9%和45.1%.

表6 跨域推荐模型推荐结果
3.5 模块有效性分析
1) 特征提取模块有效性分析
为验证双塔隐语义模型特征提取的有效性,设置了单领域推荐对比实验.如表7所示,在影视单域推荐场景下,基于用户的协同过滤(CF-user)与基于项目的协同过滤(CF-item)在数据稀疏的场景下,效果最差;矩阵分解(MF)此处为神经矩阵分解,能够通过历史的共现矩阵获取用户特征和项目特征,效果相较 CF-user 和 CF-item 有较大提升;双塔隐语义模型(DLLFM)相较于MF 方法来说,由于获取用户隐语义和项目隐语义,还利用了额外的用户类别偏好信息和项目类别信息,得到了更优的推荐效果.

表7 Movielens&Netflix单域推荐
如表8所示,基于项目的跨域协同过滤(cross-domain CF/item)与协同矩阵分解(CMF)的效果较差,EMCDR/LM 与 EMCDR/MLP 的效果相对较好,DLLFM/MLP效果最好.基于项目的跨域协同过滤(cross-domain CF/item),对原始共现矩阵的稀疏性问题更为敏感,跨域推荐的效果一般.协同矩阵分解(CMF)通过共享隐语义特征来进行矩阵分解以获取特征,受到源域与目标域数据差异的影响,在该场景下的跨域推荐效果也比较差.EMCDR 推荐效果较好,但其神经矩阵分解过程未充分利用各类额外的辅助信息.同时,EMCDR 跨域推荐过程中使用多层感知机映射(MLF),相比线性映射(LM)能够得到更优的迁移特征.

表8 Movielens&Netflix跨域推荐
2) 特征迁移模块有效性分析
表9显示了在两对数据集上DLLFM/MLP(双塔隐语义训练+多层感知)、DLLFM-DA/MLP(双塔隐语义训练+域适应+多层感知)、DLLFM-DA/SelfAtten(DLDASA模型)模型的平均RMSE

表9 基于自注意力机制的跨域推荐
和MAE,其中每个数据集的最优值以粗体突出显示.DLLFM-DA/SelfAtten在所有算法中推荐效果最优.相比DLLFM-DA/MLP模型,推荐效果进一步提升,说明自注意力机制能够有效降低特征迁移时的负迁移影响,显著提升推荐效果.
4 结束语
针对跨域推荐方法的特征提取、特征映射、个性化推荐等过程中的一系列问题,从高质量的特征提取、更充分的特征迁移、更全面的差异捕捉等角度出发对共享项目跨域推荐算法进行了研究,提出了基于双塔隐语义模型的跨域推荐模型.在隐语义模型的基础上引入双塔结构,充分利用用户的类别偏好信息和项目的类别信息,获取高质量隐语义以提升后续跨域推荐的质量;在传统的多层感知机迁移方法中引入域适应过程,通过拉近源域特征与目标域特征的一阶矩、二阶矩等特征分布,有效对齐源域与目标域的特征分布,将源域信息更充分地迁移至目标域;利用自注意力机制来捕捉两个域之间的差异性与相关性,使模型在知识迁移时能够对不同域的差异信息进行筛选与融合,从而对目标域的信息进行补足,以提升最终的跨域推荐效果.最后实验验证了该模型及其各个模块的有效性.
