基于KPCA-Kmeans++数据挖掘的二次风燃烧优化
2023-10-16孙宇航
孙宇航, 田 亮
(华北电力大学 控制与计算机工程学院,河北 保定 071003)
0 引 言
据《中国电力行业年度发展报告2021》数据显示,截至2020年底,全国全口径发电装机容量220 204万kW,比上年增长9.6%。其中火电124 624万kW,占比56.6%,比上年增长4.8%(煤电107 912万kW,比上年增长3.7%)。虽然我国处于能源结构转型的关键时期,但在可预见的时间里,国内发电主力形式仍然是燃煤机组火力发电[1]。因此,如何实现电站锅炉的高效率、低污染燃烧,对能源与环境的和谐发展具有重要意义。
燃烧调整实验通常在3个典型负荷660 MW、500 MW、330 MW下进行(以660 MW锅炉为例)。通过调整氧量、一次风风压、二次风门开度等,探究可调参数变化对锅炉燃烧效率及NOx等污染物排放产生的影响。但由于锅炉燃烧存在变煤质、变工况、深调峰等复杂情况,仅针对个别典型负荷进行燃烧优化调整实验会缺失大量燃烧过程中的关键信息,若对所有工况进行燃烧优化调整实验,燃烧优化成本则会大幅增加[2]。考虑到锅炉运行过程中积累了海量历史数据,蕴含着适合机组真实特性的参数“场景”及运行人员的调整经验,因此出现了对海量机组历史运行数据进行优化参数挖掘的方法。刘晓鹏[3]采用RBF神经网络基于滚动化形成实现了对历史数据的优化调制、优化分析与测算过程;郑伟[4]等采用约束模糊关联规则算法对数据进行模糊处理,再通过FCM算法划分模糊处理后的数据从而实现聚类过程;吴坡[5]等通过改进最小二乘法、极大似然法等方法通过算法从历史数据中辨识出锅炉的特征运行状态,选取特征状态参数指导燃烧优化;周小朋[6]采用粗糙集和属性简约算法找出了与锅炉NOx排放量高度相关且去除冗余信息的可调整优化参数,采用Apriori算法,并将CA算法引入到模糊关联规则中,挖掘出用于指导锅炉低NOx排放的规则;张尚志[7]等通过采用改进置信区间判别相结合的滑动判别算法确定不同工况下的稳态数据,并以稳态数据为指导控制二次风配风方式从而实现燃烧优化;李建强[8]利用粒子群优化Apriori算法,挖掘精简后的数据库中符合机组NOx减排要求的各个参数的最优参考工况作为燃烧优化的指导数据。目前火电机组燃烧优化研究方法大多着重于利用智能优化算法建立燃烧模型并求解复杂的非线性问题,但当机组负荷频繁波动时,基于进化算法的优化方法在稳定性和响应速度方面往往不能达到很好的效果,且算法中存在隐式规律,不能直观的展示。采用算法针对全工况进行数据分析得到的结果虽然具体,但由于数据量过大,导致工程实践过程中指导意义不强。
本文从工程应用角度出发,设计一种基于数据挖掘工况聚类的燃烧优化方法。在对锅炉海量历史运行数据进行工况划分并剔除离群点基础上,采用KPCA-K-means++数据挖掘方法对各工况稳态历史数据进行数据降维、聚类,聚类结果能够能精准、凝练、直观地反映锅炉燃烧在不同工况下锅炉燃烧控制规律,根据聚类结果将每种工况控制参数划分出:锅炉效率最优、NOx排放最优、锅炉效率和NOx排放均衡三种燃烧优化模式。针对GHJJ电厂海量历史数据进行KPCA-Kmeans++数据挖掘,得到典型工况下二次风门优化参数,能够满足燃烧优化在线指导的实际需要,实现多目标燃烧优化。
1 算法模型简介
1.1 核主成分分析法(KPCA)
PCA即主成分分析法,是一种统计分析、简化数据集的方法。采用该算法能尽可能保留原本数据结构分布,并在最小均方条件下进行最能代表原始数据的投影查找,从而在特征空间中实现数据降维。采用该算法能够对原始数据进行线性变换,根据方差变化依次建立新坐标系,将数据转换到新坐标系中。主成分分析法可以同时实现数据提取和去冗降维,使得数据结构更加简单[9]。
通过对PCA进行改进即可得到核主成分分析法(KPCA)算法。KPCA方法可以避免遇到特征向量线性不可分的问题,不仅适合解决线性问题,而且能提供比PCA更多的特征数目,可以最大限度地提取特征信息。KPCA算法采用非线性的方式对其主成分进行合理提取[10,11]。使用算法前需要对所有样本进行合理的非线性转换:
xk→φ(xk)
(1)
式中:xk表示第k个样本。
将所有样本转换至高维空间F中,数据样本协方差矩阵为
(2)
协方差矩阵C的特征向量V与特征值λ满足:
λV-CV=0
(3)
代入非线性函数φ(xk)可得
λφ(xk)V-Cφ(xk)V=0
(4)
将协方差矩阵特征向量由非线性函数表示为
(5)
引入核函数
Kij=K(xi,xj)=φ(xi)φ(xj)
(6)
将公式(3)、(5)代入公式(4)中得到
mλα-Kα=0
(7)
式中:α表示核函数矩阵K的特征向量。
对任意样本数据,在高维空间F中非线性函数φ(x)的投影表示:
(8)
进行核主成分分析时,保证累计贡献率的值大于85%可以确保损失的信息不至于太多,也能够达到减少变量、简化数据结构的目的,便于提取出反映工业系统整体过程的前k个主成分。选择累计贡献率大于85%的影响因素替代原有全部影响因素,即
(9)
式中:s表示满足该条件影响因素的数量[12,13]。
上述计算过程均在满足:
(10)
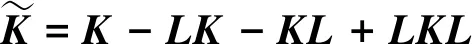
(11)
式中:L表示m×m阶系数为1/m的矩阵。
目前可选择的核函数类型较多,本次实验选取径向基核函数:
(12)
1.2 Kmeans++聚类
Kmeans是一种经典的基于划分的聚类算法,其目标是将对象集划分为若干个簇,使得簇内对象间的相似度较高,而簇间对象的相似度较。Kmeans++对Kmeans算法随机选取初始聚类中心进行了改进,该方法并不是随机地给出若干个初始聚类中心,而是先随机选取一个点作为第一个初始聚类中心,然后计算所有点到该聚类中心的距离,接着依据“聚类中心相互之间距离越远越好”的朴素原则[12],选取新的聚类中心,不断重复,直到选出k个聚类中心,最后将这些聚类中心作为初始聚类中心来运行Kmeans通过计算与距离占比相关的概率逐一选取新的初始聚类中心,直到最后选取k个初始聚类中心[13-18]。Kmeans++算法过程如下:
(1)随机选取一个样本作为初始聚类中心x1,即X=x1;
(2)计算出每个样本点的x到与其最近的聚类中心的距离D(x);
(3)每个样本点被选为新的聚类中心的概率P:
(13)
(4)重复计算2、3两步,直至选出K个初始聚类中心;
(5)采用计算出的K个初始聚类中心运行Kmeans聚类算法。
算法框架如图1所示。
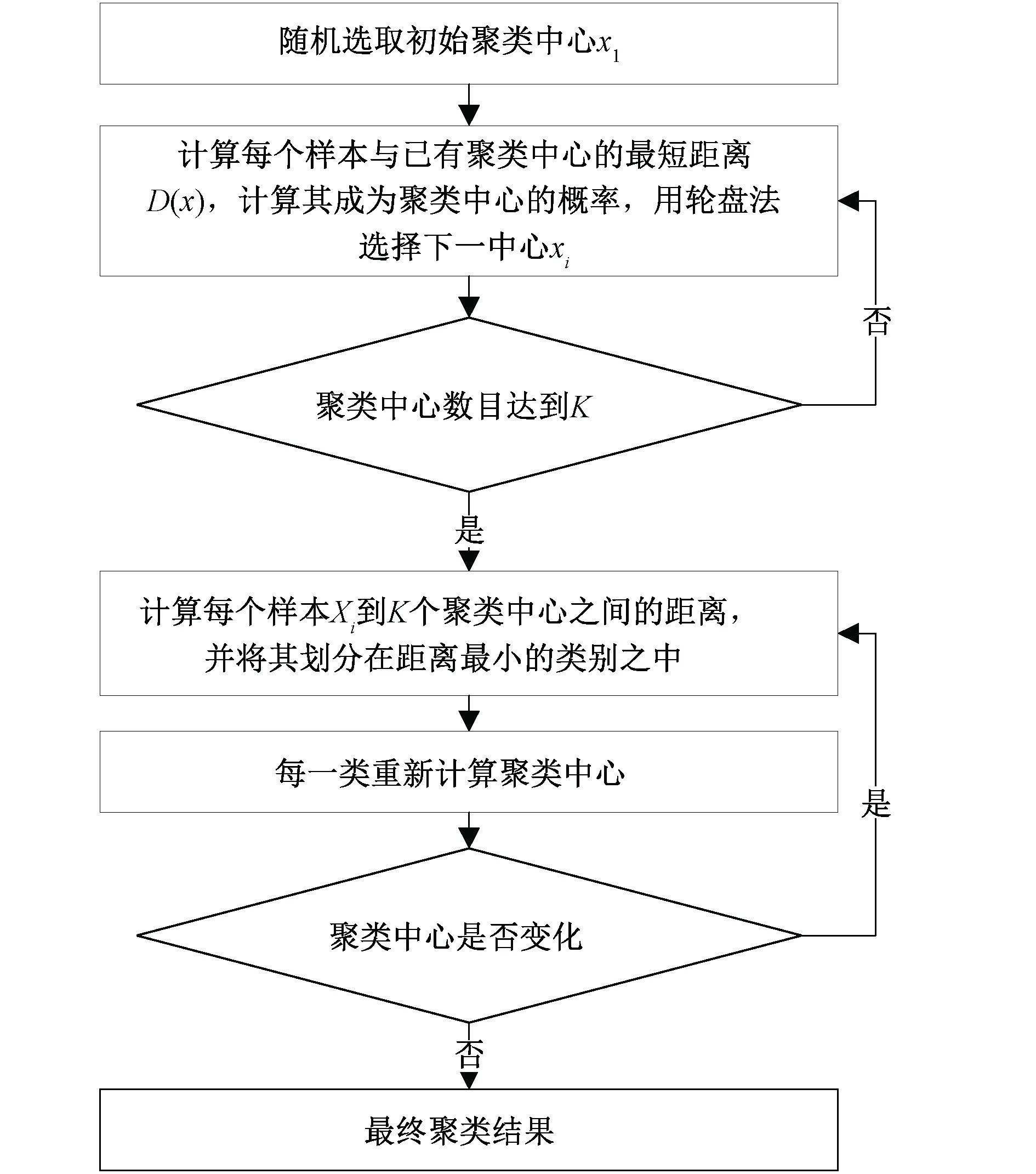
图1 Kmeans++算法框图
2 KPCA-Kmeans++数据挖掘实例
2.1 数据来源及降维聚类过程
本文以GHJJ电厂5号660 MW超超临界机组四角切圆燃烧锅炉为例,对预处理后的锅炉燃历史运行数据采用KPCA和Kmeans++进行降维处理及聚类分析,过程如图2所示。从电厂DCS系统中采集2个月的全工况历史运行数据进行预处理后,根据工况划分结果整理出194 467组运行数据,每组运行数据包含110种运行参数,部分数据见表1。
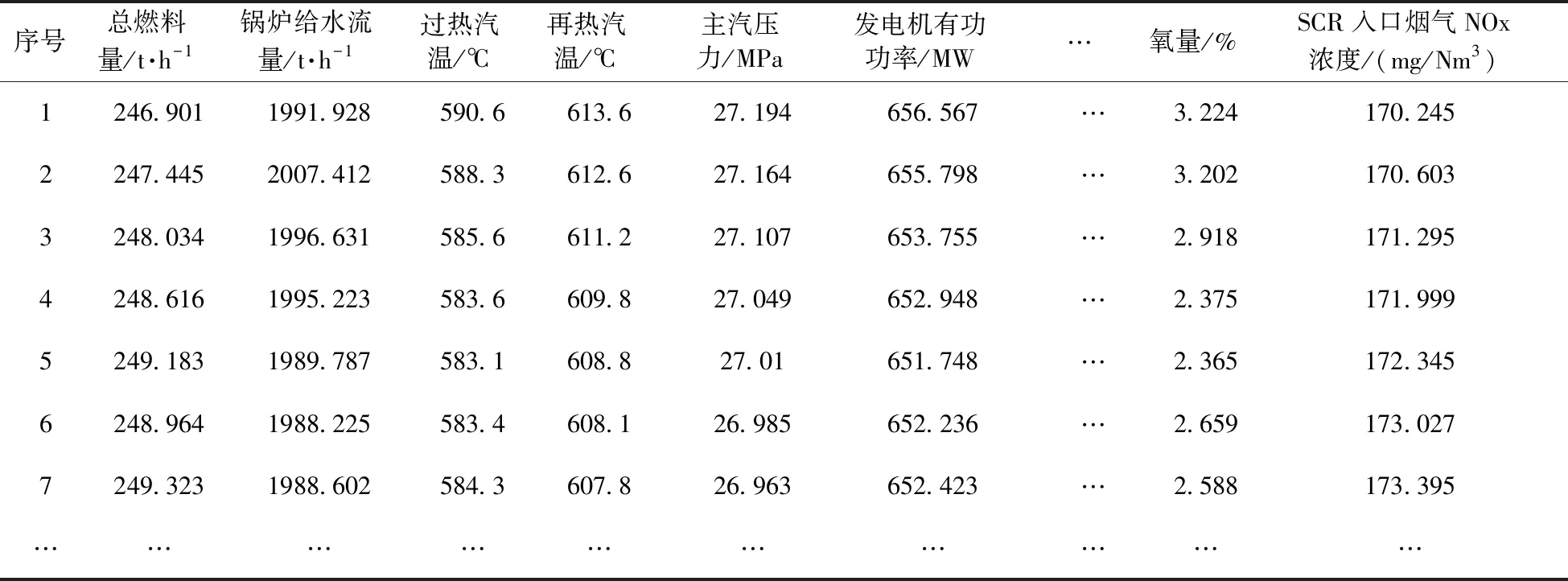
表1 部分ABCDEF工况数据

图2 PCA-Kmeans++数据挖掘系统流程图
2.2 工况划分
由于在不同的工况下锅炉燃烧过程会表现出不同的特性,因此需要选择一个参数作为工况划分的标准。本文以6台磨的起磨方式进行工况划分,会出现64种6台磨的排列组合结果。机组运行规程要求运行过程中保持至少三台磨运行且四角切圆燃烧方式不得出现燃烧器隔2层燃烧。按照上述要求剔除非法起磨方式后采用细分网格化的拼法,可以得到31种合法起磨方式,再根据起磨方式在燃烧过程中出现的时间及电厂的实际运行情况可划分为典型工况、常见工况、少数工况,如表2所示。
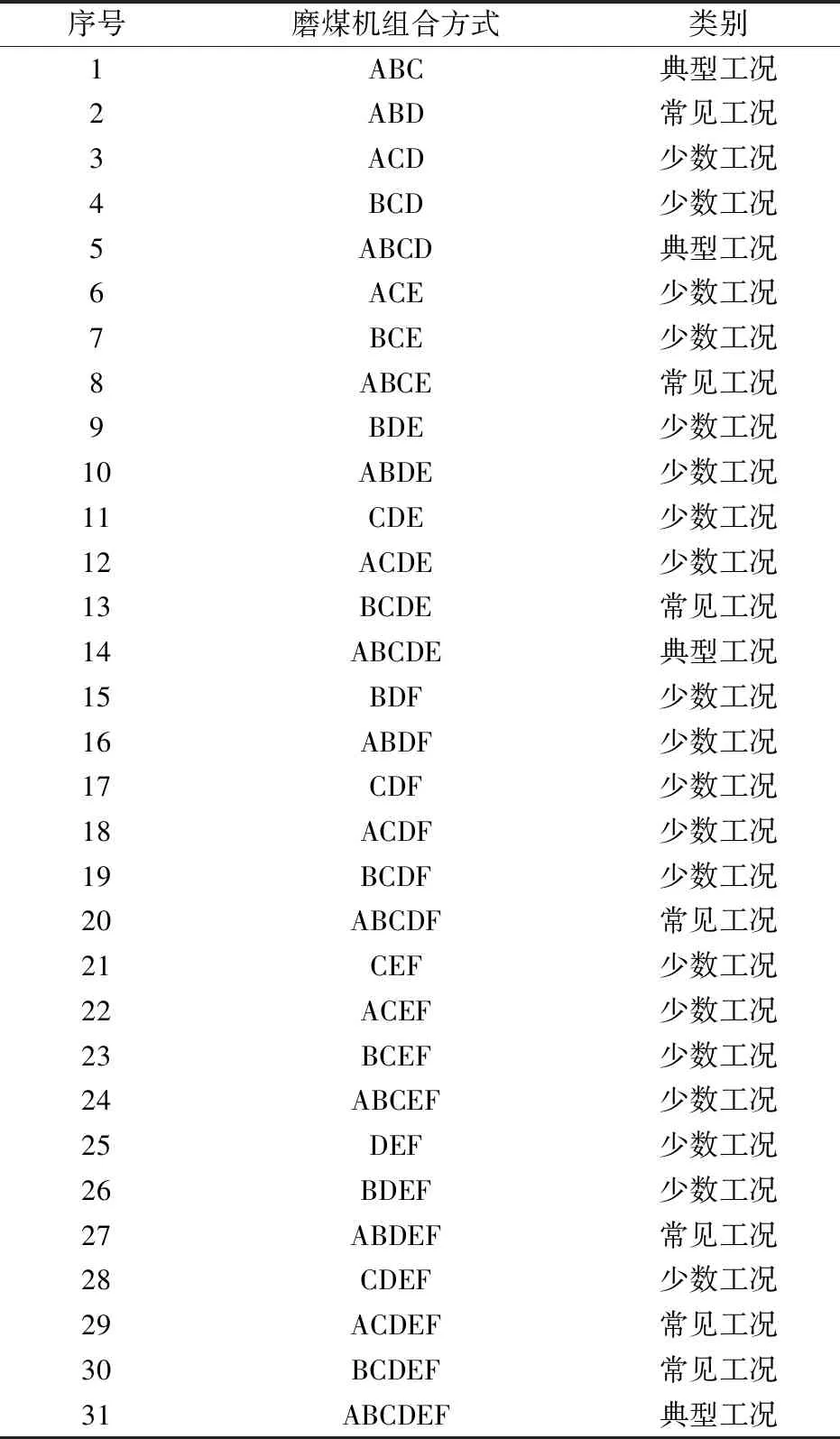
表2 合法工况及分类
由于分析的工况太多且每个工况下得到的控制规律不尽相同,所体现的数据规律性差,对燃烧系统的指导意义不能有效体现。考虑到火电机组对象特性并不具有非此即彼的性质,且不同工况之间往往存在一定的关联,若能将挖掘后的大量数据更准确、更精炼地呈现,使其有规律可循,那么挖掘后的数据对燃烧优化更具有指导意义[19-21]。相较于典型工况和常见工况,少数工况在锅炉运行过程中所出现的时间短,对锅炉燃烧优化的指导意义不强,为了找出尽可能精炼、准确的规律,在后续降维、聚类分析过程中不再对少数工况进行讨论,防止挖掘的数据规律复杂化。排除少数工况后可得到ABC、ABCD、ABCDE、ABCDEF、ABD、ABCE、ABDEF、ACDEF、BCDE、ABCDF、BCDEF,共11组对锅炉燃烧过程具有代表性的运行工况控制参数。
2.3 KPCA降维
过程参数的选取是实现燃烧优化的重要内容。过程参数选取过多,会导致控制规律复杂且不直观;过程参数选取过少则会导致优化过程不够精确。这里将过程参数分为三类:可调参数、不可调参数和优化参数。根据现场取得的实际运行数据,作如下分类,如表3所示。

表3 过程参数分类
上述过程参数在锅炉运行历史数据中共包含110种参数,显然数据种类过于复杂,不利于发现主要运行参数与性能指标之间的关联关系。因此采用KPCA对典型工况和常见工况稳态下110种参数进行降维处理,找出能包含所有过程参数85%以上信息的特征参数。
通过对表4的数据进行分析可以发现,前29个参数的累积贡献率已经超过85%,因此在接下来的研究中可以使用前29个特征参数作为下一步Kmeans++聚类的对象。另外,通过对原始数据进行分析可以发现在使用KPCA降维的过程中,可以最大程度的保留原始数据的基本信息,进而实现不同过程参数的降维处理,即将原有的110个过程参数减少至29个,使过程参数之间的冗余性降低,为后续聚类分析奠定基础。
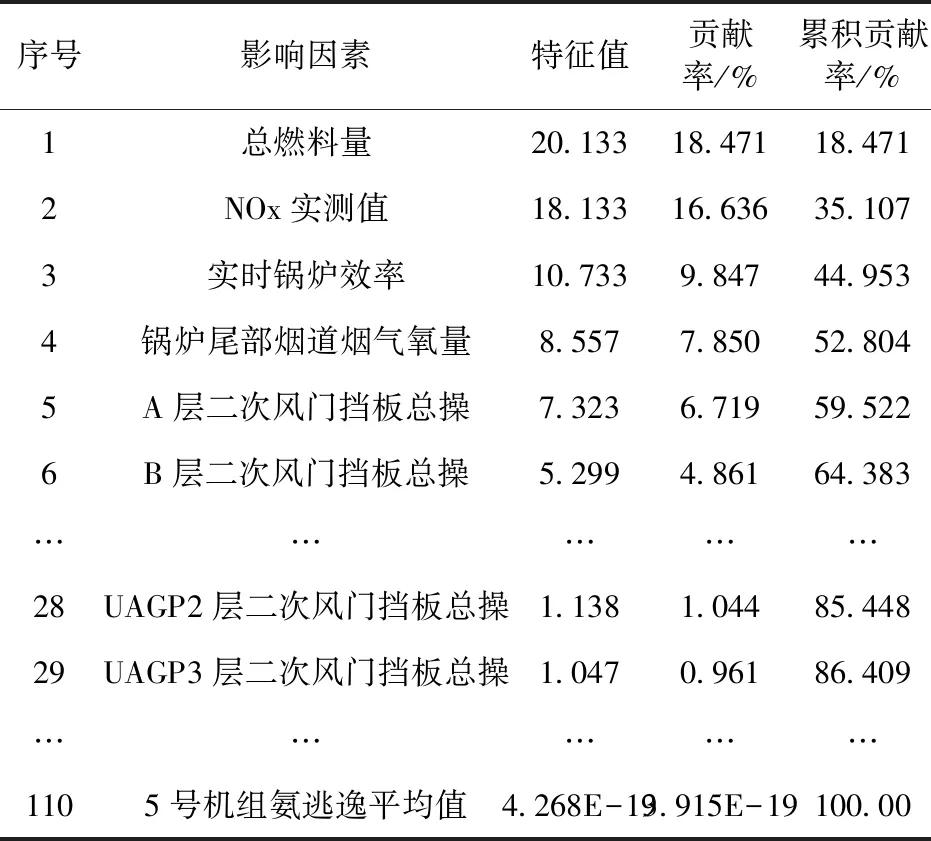
表4 过程参数特征值和累计贡献率
2.4 Kmeans++聚类分析
对KPCA降维处理后确定的过程参数分别按11种工况进行聚类分析,找出不同工况下隐含的控制规律。实验表明,聚类迭代次数为29次时可满足所有工况聚类结果收敛。为了评价与衡量聚类的结果的好坏,需要指定统一的评价指标,这里采用业界比较常用的DBI指标作为评价标准:
(14)
式中:i、j为任意两类别的类内距离平方和;ci、cj表示第i、j个聚类中心。DBI越小意味着类内距离越小,同时类间距离越大。所有聚类结果DBI指数经计算均小于0.7,已实现较好的聚类效果。
通过分析聚类结果可将每个工况分出三种模式,模式1:NOx排放最优;模式2:锅炉效率最优;模式3:锅炉效率和NOx排放均衡。按照每种工况下三种模式的划分方式可得到表5所示典型工况二次风挡板开度聚类结果参数表。

表5 部分典型工况二次风挡板开度聚类结果参数表
3 现场应用
在GHJJ电厂5号机组锅炉上进行KPCA-Kmeans++数据挖掘燃烧优化实验。该机组为660 MW参数变压运行螺旋管圈直流炉,炉型为一次再热四角切圆型锅炉,配置磨煤机6台。KPCA-Kmeans++分析数据取自机组2021年7月至8月的历史运行数据,共计26万7千组数据,经过聚类分析得到11种典型工况控制参数规律。
在磨组合为ABCDE工况下,考虑到现场应用需要,在表5聚类结果基础上对二次风挡板数据做近似处理,优化系统二次风挡板开度输入参数如表6所示。机组应用优化参数2小时后,得到NOx排放、锅炉效率运行数据,并与同工况条件下没有应用二次风挡板优化参数的运行数据进行比较(如图3所示)。

图3 锅炉燃烧优化前后对比
图3(a)中,在模式1即NOx排放最优模式下,采用优化后的二次风门挡板参数,NOx排放浓度平均值下降45.6 mg/m3;图3(b),在模式2即锅炉效率最优模式下,优化后的锅炉效率平均值提升0.18%;而在模式3即均衡模式下,图3(c)和(d)中NOx排放浓度平均值下降29.2 mg/m3,锅炉效率平均提升0.11%,实现了多目标燃烧优化。
4 结 论
(1)采用KPCA降维后,数据复杂度明显降低,由110维降至29维,保证保留数据85%以上信息的同时降低了模型训练的复杂程度,达到了减少计算资源,节省实时优化时间的目的。Kmeans++聚类将各工况下的大量数据根据其特征对数据进行有效划分,每种工况下划分出三种典型模式,能在保证燃烧系统正常运行同时,根据实际需要调整燃烧优化方式。KPCA与Kmeans++相结合的数据挖掘方法可以直观展现锅炉控制规律,保证优化效果的同时对锅炉燃烧优化进行精简、全面的指导,为机组经济、高效、清洁运行提供了有力支持。
(2)以GHJJ电厂5号660 MW超超临界机组锅炉运行历史数据为研究对象,对海量历史运行数据进行工况划分,得到典型工况、常见工况共11种有效工况。对11种工况进行KPCA-Kmeans++数据分析,进行KPCA降维后,采用Kmeans++聚类算法对降维后的数据进行聚类,按照每种工况特性进行模式划分,每种工况下找到NOx排放最优、锅炉效率最优、NOx排放-锅炉效率均衡3种模式,并运用于电厂燃烧优化。针对二次风挡板开度进行优化调整实验,在均衡模式下实现NOx排放浓度平均值下降29.2 mg/m3,锅炉效率平均提升0.11%。
