基于改进度量学习的煤矿井下行人重识别方法研究
2023-10-12张立亚王寓郝博南
张立亚, 王寓, 郝博南
(1. 煤炭科学技术研究院有限公司, 北京 100013;2. 煤矿应急避险技术装备工程研究中心, 北京 100013;3. 北京市煤矿安全工程技术研究中心, 北京 100013;4. 中国传媒大学 信息与通信工程学院, 北京 100024)
0 引言
2020年2月25日,国家八部委联合下发《关于加快煤矿智能化发展的指导意见》,加快了新一代信息化技术在煤矿行业的推广应用[1-2],其中矿井人员精确定位技术是煤矿智能化关键技术之一,可有效遏制煤矿井下超定员生产,避免或减少煤矿重特大事故发生[3]。行人重识别技术作为人员身份位置信息确认的重要手段,对人员安全监管有着重要意义。煤矿作为传统高危行业,矿井内部结构环境复杂,受井下低照度、高尘雾等影响,视觉图像采集困难,人员信息获取不到位[4],如何利用行人重识别技术高效准确区分井下工作人员身份位置信息是目前亟需解决的重要问题。
2006年N. Gheissari等[5]提出了2种行人重识别方法,分别使用兴趣算子和模型拟合来建立2个个体之间的空间对应关系,开启了行人重识别新的研究热潮。2007年,首个用于行人重识别算法研究的数据集VIPeR发布,包含了同一人的不同图像,并囊括了摄像机视点变化等干扰因素[6]。从2014年开始,深度学习框架开始逐步应用在行人重识别技术中,随着开源人员训练数据库数据量的增大[7],行人重识别技术得到了飞速发展。目前较为成熟的行人重识别方法主要包括基于元学习和基于度量学习2类,基于度量学习的方法相较基于元学习的方法,更侧重于利用特征相似性来进行学习训练,特征相似性可以捕捉到数据的本质特征,且可以减小噪声的影响,因此基于度量学习的方法识别精度较高、应用范围更广。文献[8]提出了分层跨模态度量学习方法,解决了人员图像距离过大的问题;文献[9]提出了倒排k近邻的度量学习方法,提高了特征之间的相关性;文献[10]提出了基于等距度量学习策略的行人重识别Equid-MLAPG算法,提高了模型的鲁棒性;文献[11]提出了一种基于距离度量学习的行人重识别方法,对每一个摄像机建立一个距离度量模型,提高了识别正确率。由于现有度量学习的损失函数未考虑正负样本之间的绝对距离,易造成梯度消失或梯度弥散现象,从而导致井下人员位置信息识别精度不高。
针对上述问题,本文提出了一种基于改进度量学习的煤矿井下行人重识别方法。首先,通过手工设计特征的方法对井下人员特征信息进行有效提取。然后,采用欧氏距离对人员高维特征进行相似性计算。最后,将提取到的特征输入到基于改进度量学习的煤矿井下行人重识别算法中,通过在三重损失函数中加入自适应权重,将正负样本的绝对距离考虑在内,为不同绝对距离的正负样本赋予不同权重,有效解决了传统井下行人重识别算法中梯度消失或梯度弥散的问题,提升了模型识别精度。
1 基于传统度量学习的行人重识别方法
煤矿井下基于传统度量学习的行人重识别方法流程如图1所示。首先进行特征提取,即通过神经网络中的卷积层和池化层对采集到的输入图像进行特征提取,其中,卷积层用来捕捉图像的局部特征,池化层用来降低特征的维度并提高模型的计算效率。然后进行相似性度量,使用相似性度量方法计算2个行人图像特征之间的距离或相似性得分,并选择适当的损失函数来优化行人重识别模型。最后进行卷积迭代训练,用训练好的模型对人员进行重识别,得到结果。

图1 煤矿井下人员重识别流程Fig. 1 Process for underground personnel re-recognition
2 基于改进度量学习的行人重识别方法
2.1 特征提取方法分析
传统煤矿井下人员特征提取方法主要针对人员身体关键部分进行提取,忽略了环境、纹理与色彩等细节,采集的人员特征信息单一,样本量少,不利于模型准确率的提升。因此,采用手工设计特征提取井下人员面部信息、所穿工作服等信息。通过对图像进行预处理,提取出图像的特征点,然后对这些特征点进行描述,最终得到一个特征向量,用于图像的识别和分类。筛选后的具体采集特征指标见表1。其中,手工设计特征主要包含颜色空间、纹理空间、局部特征、专用特征4种[12-13]。

表1 手工设计特征指标Table 1 Manual design feature indicators
2.2 相似性度量分析
煤矿井下结构复杂,采掘工作面、变电所、硐室、主辅运等场所图像环境差异较大。因此,煤矿井下行人重识别算法如何对不同视觉采集设备采集到的人员图像信息进行相似性判断是算法的核心部分。本文通过对提取的人员特征进行人员相似判断,将不同图像中具有相似特征的人判定为同一人[12],最终实现人员相似性判断。选择合适的特征相似性度测量方法是提高检测准确率的关键,相似性度测量方法分为无监督测量和有监督测量[14-16]。本文采用有监督测量中的欧氏距离计算方法对不同摄像机下行人图像特征向量进行相似性计算,欧氏距离的计算公式为
式中:xi,yi为当前像素点i的2个特征向量;Xi,Yi为特征向量中的所有特征点;n为图像中像素点个数。
2.3 损失函数分析
损失函数是度量学习中的重要部分,是模型优化的重要依据,损失函数主要分为基于样本对的损失函数、基于代理的损失函数和基于分类的损失函数3类。其中,基于样本对的损失函数中的三重损失函数可以更好地解决训练数据中的类内变化和类间差异问题,从而提高模型的准确率。三重损失函数的输入为3张图像,将这3张图像分别命名为原始图像特征A、正样本图像特征P、负样本图像特征N[17-18]。因此包括2对样本,1对正样本AP,1对负样本AN。
三重损失函数的目标是使相同图像样本在编码空间中距离更近,不同图像样本在编码空间中距离更远,即需要使图像中负样本对距离大于正样本对距离,或大于某一特定值[19]。三重损失函数的计算公式为
式中:da,p,da,n分别为正负样本对之间的欧氏距离,即正负样本对之间的相似度;m为根据实际需求设置的训练阈值参数,即设定的正负样本之间的距离间隔[20],m值越小,最后得出的损失值越接近0,越难以区分相似图像;m值越大,用置信度区分相似图像越容易,但损失值很难接近0,且易导致模拟的神经网络收敛性变差[21]。
当三重损失函数对模型优化成功时,会将编码空间中的正负样本对距离收敛在一个阈值范围内,但传统的三重损失函数只考虑了正负样本对之间的相对距离,并没有考虑正负样本对之间的绝对距离,当特殊情况下负样本和正样本间距离太远时,样本间的差异会变得非常明显,导致梯度变得非常小。在反向传播的过程中,这些小的梯度会逐渐传递到模型的早期层,易造成这些层的权重更新变得非常缓慢,甚至不再更新,导致模型训练缓慢或停滞不前,通常将此类特殊情况称为梯度消失或梯度弥散。三重损失函数的缺陷如图2所示。

图2 三重损失函数的缺陷Fig. 2 Deficiencies of triplet loss function
为解决上述问题,本文提出一种自适应的三重损失函数,在计算样本之间距离的过程中引入自适应变量。传统三重损失函数使用欧氏距离来衡量样本之间的相似性,然后将不同类别样本之间的距离进行比较,从而计算不同类别样本之间的差异。自适应的三重损失函数增加了适应性的权重来避免正负样本由于绝对距离影响导致的模型精准度下降问题。具体来说,每个样本的损失函数权重是动态调整的,根据欧氏距离计算结果,如果2个正样本之间的距离很大,那么它们之间的损失函数权重就会变得越大,从而使模型更加关注样本之间的区别。反之,如果1个负样本和所有正样本的距离都很大,那么它的损失函数权重就会变得很小,可以避免对模型训练造成不良影响,从而提高模型的性能。自适应的三重损失函数为
式中:α为正样本对相似性权重;β为负样本对相似性权重;s为补偿因子;x为目标样本点;Q为所有正样本集合;Z为所有负样本集合。
本文提出的自适应三重损失函数使用自适应的权重对损失函数进行动态调整,保证正负样本间距在合理范围内,使得模型更加关注难分类的样本和重要的样本,在模型训练过程中忽略无关信息,提升模型收敛速度,增加模型的拟合能力,从而提高模型的性能和训练效率,降低梯度消失或梯度弥散问题的影响。传统的三重损失函数与自适应三重损失函数的函数曲线如图3所示。

图3 传统与自适应的三重损失函数的函数曲线Fig. 3 Function curves of traditional and an adaptive trip loss function
由图3可看出,由于正负样本分布不均,有些正负样本间距过大,传统三重损失函数的值会在一段时间内停滞不前,甚至出现震荡或上升的情况,不能正常下降。自适应三重损失函数的曲线呈平滑的自然下降趋势,这是因为本文提出的方法可针对样本距离进行权重分配动态调整,避免了梯度消失或梯度弥散问题。
3 实验验证
3.1 数据集及预处理
为了验证本文提出的自适应三重损失函数对度量学习的改进效果,在内蒙古某煤矿现场获取实验数据,从中选取60张完整的人身图像作为测试集,对数据图像进行基于HSV色彩空间的转换,提升人员细节检测的精确度[22-24]。将每个人不同姿态和角度的60张图像作为训练集,利用图像分割将训练集与测试集分割成3个子块。 同时采用HSV颜色空间对图像数据进行处理,图像分割结果如图4所示。

图4 分割后子块Fig. 4 Sub block and color extraction after segmentation
3.2 实验结果评价分析
CMC(Cumulative Match Characteristic,累积匹配特征)曲线[23]将行人样本与训练生成的K个行人图像逐一进行对比,计算K个值中包含真实行人样本的概率,通常又称作击中概率(top-k),k为样本分别与K个值逐一比较的顺序号,CMC曲线斜率越大,说明算法性能越好。
选取基于传统度量学习的井下行人重识别方法与基于改进度量学习的井下行人重识别方法进行性能测试,得到CMC曲线,如图5所示。可看出传统度量学习的井下行人重识别方法在图像数位于两端(小于10或大于50)时,识别效率不高,在相似样本个数达到上限60时,样本匹配概率仅为83%左右。基于改进度量学习的井下行人重识别方法在相似样本个数为50左右时,样本匹配概率达100%,相比原有模型识别准确率提升明显。
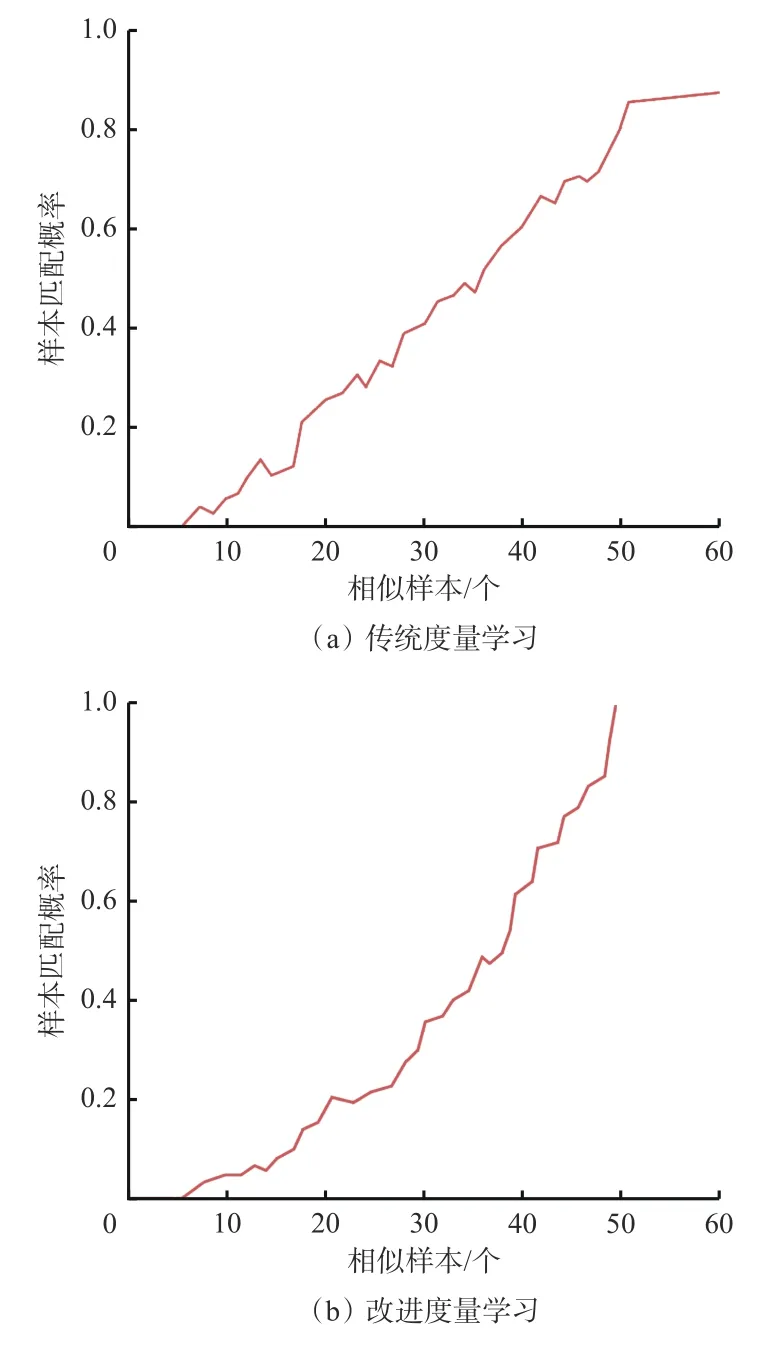
图5 基于传统度量学习与改进度量学习的行人重识别效率Fig. 5 Rerecognition efficiency under traditional heavy recognition and adaptive metric learning
使用传统度量学习的井下行人重识别方法和基于改进度量学习的井下行人重识别方法同时对分辨率分别为224×224与640×640的图像进行识别,对比2种方法的推理耗时,对比结果见表2。可看出基于改进度量学习的井下行人重识别方法对224×224与640×640图像的推理耗时比传统重识别方法分别减少了44,68 ms。

表2 传统与改进的度量学习的行人重识别推理耗时Table 2 The time cost between traditional rerecognition and adaptive metric learning
受到井下受低照度、高尘雾等环境影响及佩戴装备限制,井下人员头脚部分采集到的图像精度往往较差且相似性普遍较高,本文提出的基于改进度量学习的行人重识别方法可对图像中头脚部分进行剥离,减小模型在训练及识别过程中由于头脚相似性过高造成的噪声,并对图像进行三重分割,得到CMC对比结果,如图6所示。可看出基于改进度量学习的井下行人重识别方法在舍弃行人头脚部分图像后表现更好,当相似样本个数为42左右时,样本匹配概率达100%,图像识别准确率得到了进一步提高。

图6 舍弃头脚部信息后得出的自适应的三重损失下重识别效率Fig. 6 Heavy identification efficiency of adaptive metric learning after discarding head and feet information
4 结论
1) 基于传统度量学习的井下行人重识别方法在相似样本数位于两端(小于10或大于50)时,识别效率不高,在相似样本个数达到上限60时,样本匹配概率仅为83%左右。基于改进度量学习的井下行人重识别方法在相似样本个数为50左右时,样本匹配概率达100%,相比原有模型识别准确率提升明显。
2) 基于改进度量学习的井下行人重识别方法对224×224与640×640图像的推理耗时比传统重识别方法分别减少了44,68 ms。
3) 基于改进度量学习的井下行人重识别方法在舍弃行人头脚部分图像后表现更好,当相似样本个数为42左右时,样本匹配概率达100%,图像识别准确率得到了进一步提高。
