用于井下行人检测的可见光和红外图像融合算法
2023-10-12周李兵陈晓晶贾文琪卫健健叶柏松邹盛
周李兵, 陈晓晶, 贾文琪, 卫健健, 叶柏松, 邹盛
(1. 中煤科工集团常州研究院有限公司,江苏 常州 213015;2. 天地(常州)自动化股份有限公司,江苏 常州 213015;3. 南京航空航天大学 机电学院,江苏 南京 210016)
0 引言
目前,我国煤矿多采用人工驾驶运输车辆。鉴于井下巷道环境复杂,作业人员繁多,驾驶员在疲劳驾驶或者误操作的情况下,容易造成车辆碰撞和侧翻等运输事故,威胁井下作业人员生命安全,影响生产效率。现阶段,我国煤矿开采技术正处于由传统开采转向智能化开采的关键时期。矿用运输车辆无人化作为智慧矿山建设的重要一环,很大程度上决定了煤矿开采的智能化程度[1]。矿用无人驾驶车辆的工作环境光照条件复杂,导致行人检测易出现漏检和误检现象,降低了矿用无人驾驶车辆的可靠性。
由于井下光照条件复杂,难以利用可见光对环境中的行人轮廓成像,在逆光和弱光情况下,需要联合其他图像传感器对环境中的行人目标成像,获取更多行人特征信息。红外摄像头通过补充红外线对场景成像,可以在复杂光照或弱光条件下工作,采集的图像为灰度图像。可见光摄像头可以提供场景中的细节纹理,具有更高的分辨率,且可见光图像更加契合人类的视觉系统。因此,可以通过融合红外和可见光图像,将红外线反射信息和细节纹理信息融合于可见光图像中,解决单个传感器的不足,改善目标检测效果。
红外与可见光图像融合方法主要分为传统方法和基于深度学习的方法[2]。传统方法中,多尺度变换融合方法[3]是目前该领域研究最广泛、应用最多的方法。基于多尺度变换的图像融合方法主要通过一组变换和逆变换模型来融合图像,典型的方法包括金字塔变换、小波变换[4]、非下采样轮廓波变换(Non-Subsampled Contourlet Transform,NSCT)[5-9]和边缘保持滤波器等[10]。多尺度变换融合方法随着分解层数增多,会导致图像边缘和纹理模糊,同时融合时间也会增加。
深度学习方法具有强大的数据处理能力、抗干扰能力和自适应能力,因此近年来被广泛应用于图像融合领域。目前,基于深度学习的图像融合方法主要包括卷积神经网络方法[11-15]、生成对抗网络方法[16-18]和基于Transformer的方法[19-20]。Liu Yu等[14]通过卷积神经网络计算拉普拉斯变换中的高斯金字塔和拉普拉斯系数,然后重构出融合图像。Li Hui等[15]首先通过残差连接设计了一种由卷积层、融合层和Dense块组成的编码器,有助于从源图像中提取更多特征。王志社等[17]提出了一种基于可见光和红外图像的交互式注意力生成对抗融合算法,通过在融合层次上设计一种可学习的注意力机制来构建局部特征间的长距离关系。Li Jing等[20]提出了一种卷积导向变换框架,通过卷积特征提取模块提取局部特征,再利用Transformer 特征提取模块对图像的长距离依赖关系进行构建。深度学习方法可以实现多样性特征表达且泛化性强,但特征融合策略和特征提取模型的设计是难点,融合模型的性能在很大程度上受到二者的影响。多数深度学习方法难以平衡可见光和红外图像中的特征,导致融合图像中细节信息模糊。
针对上述问题,本文设计了一种基于多注意力机制的可见光和红外图像融合算法(Image Fusion Algorithm based on Multiple Attention Modules,IFAM)。首先采用卷积神经网络对可见光和红外图像提取图像特征;然后通过空间注意力和通道注意力模块对提取出来的特征进行交叉融合,同时利用特征中的梯度信息计算2个注意力模块输出特征的融合权值,根据权值融合2个注意力模块的输出特征;最后通过反卷积变换对图像特征进行还原,得到最终的融合图像。
1 井下行人数据集构建
井下行人数据集构建流程如图1所示。首先使用可见光和红外传感器采集井下视频,将视频分解为图像帧;然后采用弱光增强算法EnlightenGAN[21]对图像帧中的可见光图像进行弱光增强,使之能够恢复为高对比度图像;最后对图像中的行人目标进行标注,完成井下行人数据集构建[22]。

图1 井下行人数据集构建流程Fig. 1 Construction process of underground pedestrian dataset
1.1 数据采集
可见光图像传感器采用Intel d435i摄像头,采集图像为三通道(RGB),分辨率为640×640。为了保证图像融合时尺寸一致,红外传感器采用USB2.0红外夜视摄像头,采集图像为单通道,分辨率为640×640。摄像头采集图像时的位置如图2所示。为了使2个摄像头之间的相对位置固定,设计了传感器安装支架,支架左侧为可见光摄像头,右侧为红外摄像头,摄像头底部与支架之间采用螺栓固定。通过标定2个传感器外部参数,使采集的可见光和红外图像内容一致。摄像头采集的数据通过USB数据线传输至计算机。采集数据时,使用强磁力磁板将传感器支架固定在矿用智能车辆前车盖上。

图2 摄像头位置Fig. 2 Location of the cameras
井下采集的部分可见光和红外图像如图3所示。对比2组图片可以发现:可见光图像中细节丰富,包含了场景中行人的色彩信息和背景信息;红外图像不受背景光照影响,可以在弱光情况下对行人轮廓成像,但是缺乏背景和行人的色彩信息,成像距离近。

图3 可见光和红外图像Fig. 3 Visible images and infrared images
1.2 数据标注
为了测试特有工况下融合算法的可行性,需要对井下采集到的图像进行标注。选用标注软件LabelImg进行手工标注,标注时会对标注内容生成对应的XML格式标签文件。数据集标注信息包括目标类别(行人)、目标边界框的中心点坐标、高和宽。LabelImg标注界面如图4(a)所示,标注后生成的标签文件如图4(b)所示。井下行人数据集中共10 000张图像,其中可见光和红外图像各5 000张。将数据集分为训练集和测试集,分别包含8 000,2 000张图像。

图4 井下数据标注Fig. 4 Underground data annotation
2 可见光和红外图像融合算法
2.1 IFAM算法
2.1.1 算法框架
IFAM算法主要包含编码网络(Encoder Block)、特征融合模块(Information Preservation Weighted Channel and Spatial Attention,ICS)和解码网络(Decoder Block)3个部分,其中编码网络和解码网络构成了自编码-解码网络,如图5所示。首先,通过1个卷积层将源图像通道数从3增加到64,再送到1个级联了4个编码块的编码网络中分别提取特征;其次,在ICS中对提取的特征进行融合;然后,将融合特征馈送到包含6个解码块的解码网络中;最后,经过重构得到融合后的图像。
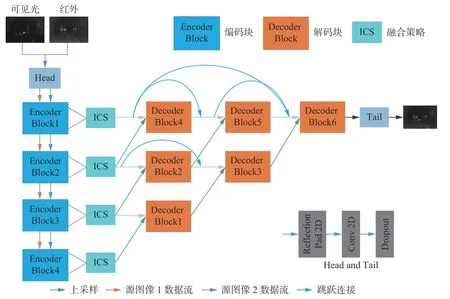
图5 IFAM算法框架Fig. 5 IFAM algorithm framework
本文中的图像融合属于特征级融合,因此特征融合策略很重要。设计了一种ICS融合策略,使用通道注意力模块和空间注意力模块对图像特征中的空间和纹理信息进行关注,使得融合图像中兼具可见光图像的背景信息和红外图像的纹理信息。此外,以往的研究中一般对特征平均融合,缺乏针对性,因此,本文计算特征中梯度信息的丰富度,并对2种图像特征的丰富度求加权均值,得到融合权值。以图像特征梯度信息为依据计算自适应的融合权值,可使融合图像更为合理。
2.1.2 自编码-解码网络
自编码-解码网络配置信息见表1,包含预处理层、编码网络、解码网络和后处理层4个部分。编码网络包含4个串行连接的编码块,每个编码块中有2个卷积层,如图6(a)所示。对输入特征进行镜像填充,经过一个卷积核大小为3×3的卷积,最后对卷积中的神经元随机失活,得到第1个卷积层模型。第2个卷积层中卷积核大小为1×1。解码网络中有6个解码块,如图6(b)所示。解码块的整体结构与编码块基本相同,不同的是将卷积层中的Dropout替换为ReLU激活函数。6个解码块分别属于3个层次,最下面一层接收的特征通道数最多。同一层的解码块之间从左至右侧边连接,上一层的解码块接收下一层的输出。
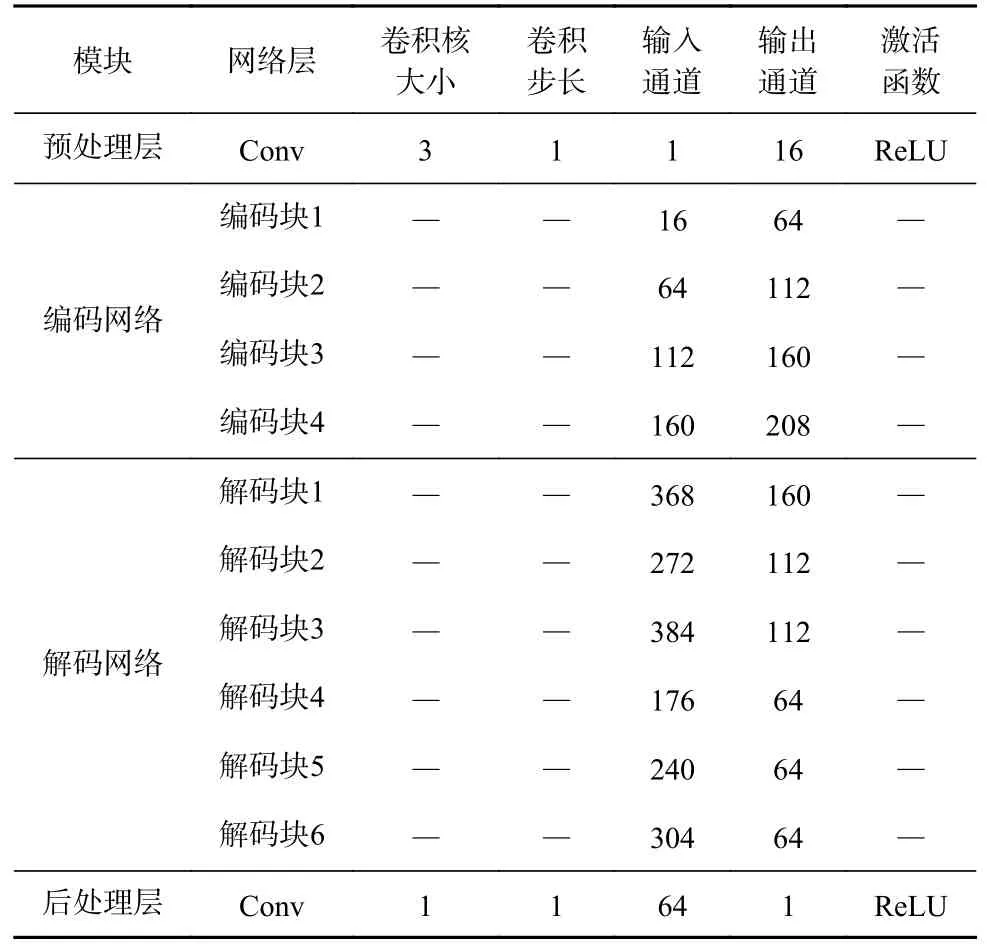
表1 自编码-解码网络配置信息Table 1 Configuration information of self-encoding and decoding network

图6 编码块和解码块结构Fig. 6 Structure of the encoding blocks and the decoding blocks
2.1.3 基于多注意力机制的特征融合策略
注意力机制是人类视觉系统的主要特性之一。视觉信号被分成多个通道送入人脑视觉中枢系统,注意力机制可以根据不同视觉任务帮助视觉系统从复杂的通道中过滤出关键信息。根据这一特性,S. Woo等[23]提出了一种简单有效的注意力模块,促使卷积神经网络从通道和空间2个方面对特征施加不同注意力权值,从而细化特征[24]。基于多注意力机制的特征融合策略如图7所示,其中包含通道注意力模块、空间注意力模块和信息保留度权值3个部分。
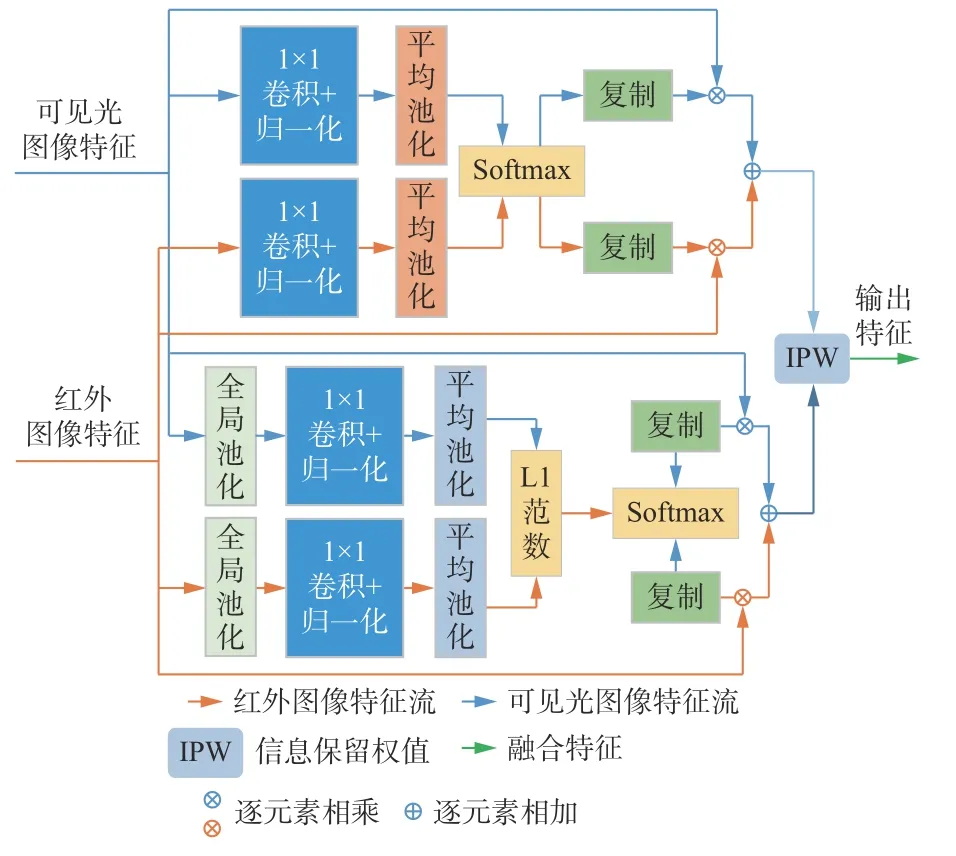
图7 基于多注意力机制的特征融合策略Fig. 7 Feature fusion strategy based on multi attention mechanism
1) 通道注意力模块。通过计算2个特征图中不同通道的权值,得到通道注意力权值矩阵,如图8所示[25]。
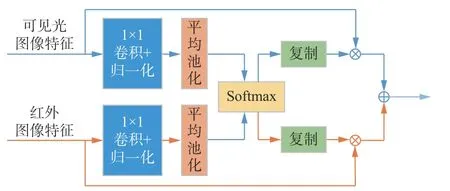
图8 通道注意力模块Fig. 8 Channel attention module
将输入特征通过一个卷积和归一化组合的卷积层,再进行全局池化,得到初始化全局权值向量:
式中:Ik为源图像,k∈{1,2},I1为红外光源图像,I2为可见光源图像;G(·)为逐通道平均全局池化函数;Φi为4个编码块从可见光和红外图像中提取出的特征图,i∈{1,2,3,4},Φi∈RCi×Wi×Hi,Ci,Wi,Hi分别为特征图Φi的通道数、宽度和高度。
初始全局权值向量经过Softmax函数计算得到2个输入特征对应的权值向量。为了与输入特征逐点相乘,将权值向量拓展到与输入特征大小一致。将输入特征与拓展后的权值逐通道相乘相加,得到通道注意力模块的融合输出特征:
式中ε为防止分母为0的常量,ε=0.0001。
2) 空间注意力模块。该模块利用特征的空间关系生成空间注意力权值矩阵,如图9所示。文献[26]研究表明沿着通道轴施加池化操作可以有效突出显示信息区域。针对三维特征图Φi,通道注意力模块关注的是特征的每一个向量中的关系,而空间注意力模块关注的是特征的每一个平面中的关系。
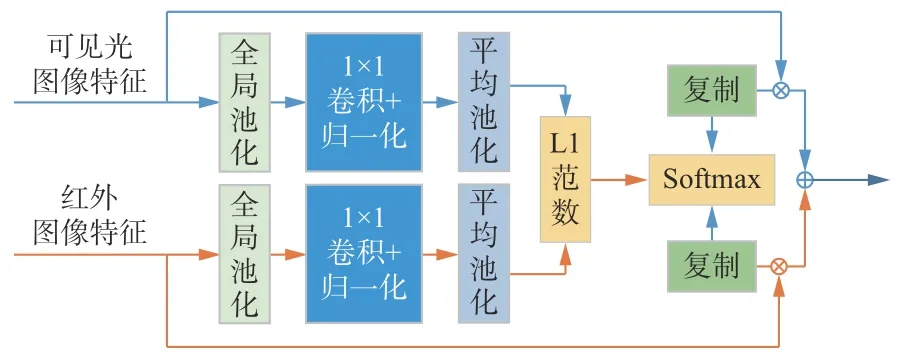
图9 空间注意力模块Fig. 9 Spatial attention module
对特征逐通道求和,得到初始化全局权值矩阵:
初始化全局权值矩阵经过L1范数和Softmax函数后取加权平均,得到最终的空间注意力权值矩阵;再将权值矩阵的维度通过复制方式扩展到Ci维;最后将拓展后的权值和输入特征分别相乘相加,得到空间注意力模块的输出特征[27]:
3) 信息保留度权值。源图像中的信息保留度越大,该源图像对最终融合图像的影响也越大,融合特征中应该多保留一些该源图像的特征。为了再次融合通道注意力模块和空间注意力模块的输出特征,本文提出根据梯度信息估算2个融合特征中的信息保有度,再根据信息保有度计算2个融合特征再次融合的权值。图像梯度是一种基于局部空间结构的度量[28],具有较小的感受野,易计算和存储[29]。信息保留度Rz的计算公式为
引入wIk表示自适应权值,则2个注意力模块输出特征的融合权值为
式中:f(·)为Softmax函数,其作用是将2个信息保留度限制在0~1之间;Rc,Rs分别为通道注意力模块和空间注意力模块的信息保留度。
2.1.4 损失函数设计
设计损失函数时主要考虑结构相似损失Lstructure和空间相似损失Lspectral。结构相似损失主要约束源图像中的纹理信息,空间相似损失主要约束源图像中的像素信息。总体损失函数为
式中α和β分别为Lspectral,Lstructure的系数。
结构相似性度量(Structural Similarity Index Measure,SSIM) 是衡量图像相似性的主要评价指标之一,被广泛应用于图像融合的损失函数中,本文使用SSIM约束红外图像、可见光图像与融合图像之间的相似性。
结构相似损失计算公式为
式中T为输入图像Ik与重构图像Uk的SSIM。
空间相似损失计算公式为
式中:Uk为重构图像;||·||F为F范数。
考虑到井下图像数据并不丰富,在训练编码-解码网络时先使用大型数据集COCO2014[30]中的图像进行预训练,获得初始网络权值,再加入井下图像对网络权值进行微调。训练时,损失函数中系数α和β分别取1和100。
2.2 多通道和单通道图像融合
可见光图像和红外图像的格式不同,前者为彩色图像,后者为灰度图像。2个源图像通道不同,不能直接融合。为了融合彩色可见光图像和灰色红外图像,本文设计了多通道可见光图像和单通道红外图像融合策略,融合流程如图10所示。
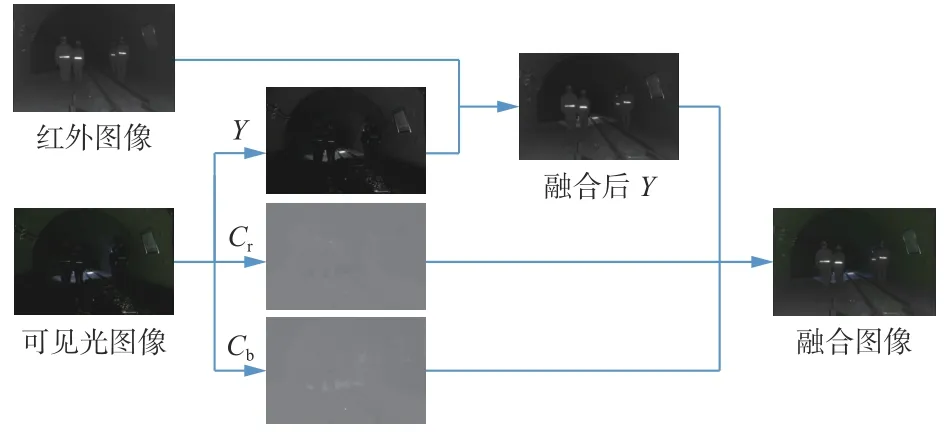
图10 多通道和单通道图像融合流程Fig. 10 Fusion flow of multi-channel and single-channel image
将可见光图像分解到YCbCr图像空间,该图像空间包含3个分量,分别是亮度分量Y(luminance)、蓝色色度分量Cb(blue hue)和红色色度分量Cr(red hue)。从图10可看出,结构细节主要在亮度分量中,并且亮度分量中包含的信息比另外2个色度分量包含的信息更丰富。因此,将YCbCr空间的亮度分量与红外图像进行融合,得到融合后的亮度分量。之后,通过逆变换函数将2个色度分量与融合后的亮度分量融合,并转换到RGB图像空间。
3 实验结果与分析
3.1 评价指标
采用5个指标来分析融合图像的质量,包括信息熵[31](Entropy,EN)、梯度融合度量指标[32](QAB/F)、融合视觉信息保真度[33](Visual Information Fidelity for Fusion,VIFF)、联合结构相似性度量(The union Structural Similarity Index Measure,SSIMu)和标准方差(Standard Deviation,SD)。
EN通过计算融合图像中的信息量来评价融合图像质量。EN和图像的质量成正比,即EN值越大,图像质量越高。EN为
式中:X为图像的灰度级数量;hl为图像的归一化直方图。
梯度融合度量指标QAB/F的作用是衡量源图像和融合图像之间边缘信息的保有量[34],具体表示图像A和B融合为图像F的给定融合过程的归一化加权性能度量,其计算公式为
式中:(n,m)为像素坐标;N,M分别为F的长和宽;QAF,QBF为边缘信息保存值, 0≤QAF≤1,0≤QBF≤1,0对应于边缘信息完全丢失,1对应于边缘信息保留完整;WA(n,m),WB(n,m)分别为QAF和QBF的权值系数;分别为融合后图像与源图像的相对边缘强度和边缘方向。
VIFF是基于视觉信息保真度提出的融合图像质量评估算法,其数值与图像的质量成正比。VIFF为
式中:pK为加权系数;VK(A,B,F)为第K个子带的融合评估值。
SSIMu是在结构相似度的基础上演变而来,用于评估融合图像和源图像的结构相似度。SSIMu为
SD的作用是衡量图像清晰度。SD与图像清晰度成正比,即SD越大,图像对比度越高,图像越清晰。SD为
式中gmean为图像F的灰度均值。
3.2 实验结果和指标分析
IFAM在RoadScene数据集[35]和TNO[36]数据集上的融合结果如图11所示。其中第1,3,4组为弱光图像,第2组为逆光图像。经过对比可以看出,融合后的图像中同时具备了可见光图像中的背景纹理和红外图像中的行人轮廓特征信息,经过图像融合后,图像中的行人信息更加明显,可以为行人检测网络提供更加充分的特征信息。

图11 可见光图像和红外图像融合结果Fig. 11 Fusion results of visible images and infrared images
IFAM在井下数据集上的融合结果如图12所示。经过对比可以看出,在弱光环境下,红外图像可以弥补可见光的缺点,并且不受环境中其他光源(如手电光)的影响。在弱光条件下融合后的图像中行人轮廓依旧明显。

图12 井下可见光和红外图像融合结果Fig. 12 Fusion results of underground visible images and infrared images
选用5种性能优异的图像融合算法进行对比分析,分别为LLF-IOI[37]、NDM[38]、PA-PCNN[39]、TA-cGAN[40]和U2fuse[29],结果见表2。可看出,本文提出的IFAM的SD和SSIMu分别为88.015 5和0.791 6,高于其他算法,EN,QAB/F,VIFF分别为4.901 3,0.169 3,1.413 5。从指标数据可知,通过通道和空间注意力机制融合图像特征可以避免可见光的纹理信息被红外图像的灰度信息淡化,使得融合图像中的结构信息更加明显;信息保留度权值能够平衡可见光和红外图像特征在融合特征中的占比,避免图像模糊。
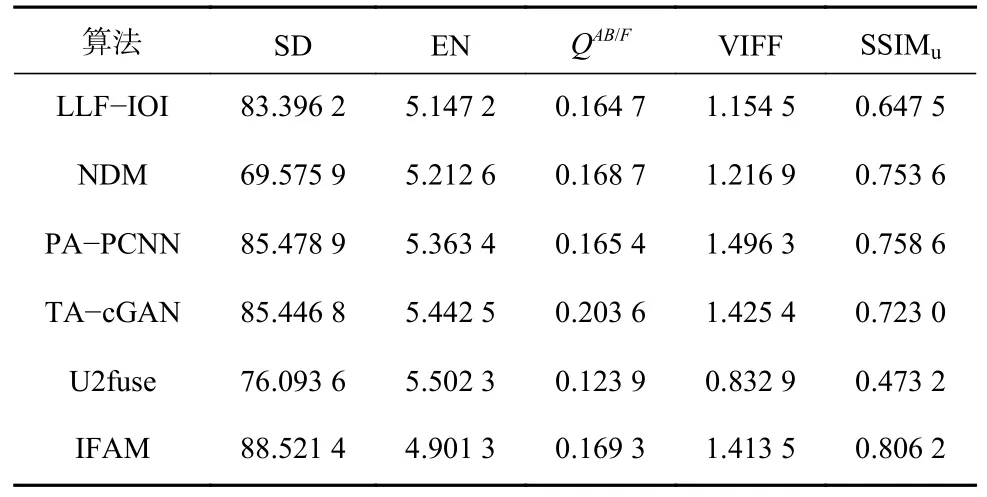
表2 图像融合算法在井下数据集上的指标数据Table 2 Index data of image fusion algorithm on underground dataset
3.3 消融实验分析
第1个消融实验目的是证明融合策略中3个模型之间组合的合理性,分析不同注意力模块组合对融合结果的影响。通道注意力模块可以保留更多结构信息,但降低了图像前景和背景之间的对比度。空间注意力模块可以获得良好的对比度,但模糊了纹理信息。通道和空间注意力改善了纹理的模糊效果,但忽略了对比度。本文提出的基于多注意力机制的特征融合策略不仅改善了纹理信息,还提高了前景和背景的对比度。针对通道注意力模块、空间注意力模块和信息保留度权值模块的消融实验结果见表3。可看出,基于多注意力机制的特征融合策略的EN,SD,VIFF,SSIMu优于其他组合。与单个注意力模块相比,具有信息保留权值的特征融合策略取得了更显著的效果。

表3 基于多注意力机制的特征融合策略中各模块消融实验结果Table 3 Experimental results of ablation of each module in feature fusion strategy based on multi attention mechanism
第2个消融实验目的是探究损失函数中2个超参数的最佳值组合,即α和β最佳组合。实验中,α设置为0.1,0.5,1,β设置为1,10,100,1 000。不同α和β组合下IFAM的实验结果见表4。可看出,当α<0.5且β<100时,在5个指标上综合表现较差;当α=1,β=1 000时,虽然融合图像的SD和QAB/F较大,但是其他3个指标较小,因为局部亮度的增加导致结构信息被覆盖,使得融合图像更加模糊。综合对比结果,α=1和β=100是最佳组合。
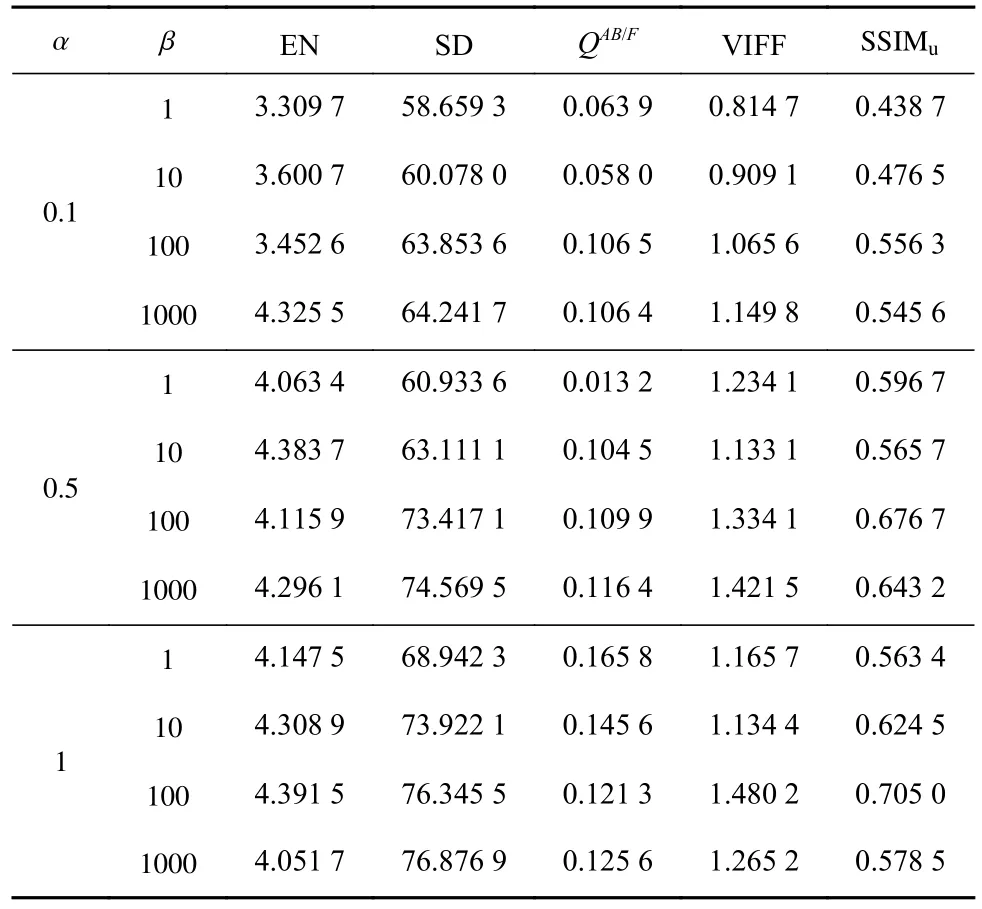
表4 不同α和β组合下IFAM的实验结果Table 4 Experimental results of IFAM under different combinations of α and β
4 结论
1) 提出了用于井下智能车辆行人检测的图像融合算法IFAM。首先采用自编码器对可见光和红外图像进行特征提取,其次采用空间注意力机制和通道注意力机制融合从可见光和红外图像中提取的特征,然后采用基于梯度信息方法计算空间注意力机制和通道注意力机制输出特征的融合权值,融合2个注意力机制处理后的特征,最后通过解码器还原出融合图像。
2) 在RoadScene数据集、TNO数据集及井下数据集上的融合结果表明,IFAM能够有效融合图像,经IFAM融合后的图像中同时具备可见光图像中的背景纹理和红外图像中的行人轮廓特征信息,在弱光条件下融合后的图像中行人轮廓依旧明显。
3) 对比分析结果表明,经IFAM融合后图像的EN,SD,QAB/F,VIFF,SSIMu分别为4.901 3,88.521 4,0.169 3,1.413 5,0.806 2,整体性能优于同类的LLF-IOI、NDM等算法。
4) 消融实验结果表明:与单个注意力模块相比,具有信息保留权值的多注意力特征融合策略取得了更显著的效果;损失函数中超参数α=1,β=100是最佳组合。
