基于正常样本学习的真伪卷烟小盒胶痕鉴别方法
2023-10-12梁洲源马慧宇李海燕王春琼张榆锋
李 郸,梁洲源,马慧宇,李海燕,王春琼,张 轲,张榆锋*
1. 云南省烟草质量监督检测站,昆明市高新技术开发区科医路41 号 650104
2. 云南大学信息学院,昆明市呈贡区大学城东外环南路 650500
鉴别检验卷烟真伪对于加强烟草专卖管理、防止假冒卷烟流入市场具有重要意义。鉴别卷烟真伪最常用的方法是感官检验法,主要依赖检测人员自身的经验知识,从包装、烟支、烟丝和吸味等多个方面对卷烟产品进行鉴定[1-2]。该方法对检测人员的专业技能要求较高,且存在主观性强等问题。因此,利用机器视觉技术和物化检验设备代替人类感官功能进行卷烟真伪鉴定成为当前研究热点。钟宇等[3]和肖楠等[4]基于卷烟外包装图像,分别通过传统机器学习和深度学习对真伪包装图像进行了鉴别。魏中华[5]基于烟支的总通风率、硬度和滤嘴通风率3个物理指标构建了SVM(Support Vector Machine)真伪预测模型。张灵帅等[6]采集真伪烟丝的近红外光谱数据,并通过主成分分析结合马氏距离方法建立了判别模型。田耀伟等[7]、聂磊等[8]和高莉等[9]分别利用电子嗅觉系统、顶空-气相色谱-质谱技术和顶空-离子分子反应质谱技术对卷烟的挥发性和半挥发性成分进行分析,以此区分真假卷烟。检验仪器的使用在很大程度上提高了卷烟真伪鉴别工作的客观性,但随着卷烟仿制技术水平的提升,真假烟的外观和内在结构差异极小,并且卷烟的包装样式繁多、理化特性复杂,从外包装和烟支、烟丝物化参数等方面进行卷烟真伪鉴别难度大且耗时费力,需要选择更加有效的鉴别方法。卷烟小盒(以下简称烟盒)内部的粘胶痕迹是反映卷烟包装机型的重要特征,由于制假者大多使用简单的包装设备和粗劣的包装工艺,因而真烟和假烟的胶痕形态存在显著差异[10]。目前,卷烟工业企业使用的主流包装机型有14种,对应14类真品胶痕,类别数量少,并且相较于不断推陈出新的包装样式和卷烟配方,卷烟包装工艺相对稳定,粘胶痕迹长期保持不变。因此,将胶痕作为检测对象可有效降低鉴别问题的复杂度,使鉴别方法具有更广泛、更长期的通用性。由于胶痕在自然光下人眼难以辨识,需要在特殊光照环境下采集图像再进行真伪鉴别处理。此外,考虑到假烟的辨别、收集、标定工作困难,并且制假者的生产工艺参差不齐,使得假样本具有数量少、特征不稳定等特点,因而引入异常检测技术,仅通过正常(真品)样本构建鉴别模型。异常检测作为机器学习领域的重要分支,主要解决机器学习模型在面对未知样本时的安全问题,对于保证机器学习系统的可靠性至关重要,被广泛应用于网络入侵检测[11]、欺诈行为检测[12]、农作物病害检测[13]和工业产品缺陷检测[14]等多个领域。深度学习通过深层神经网络自动获取数据的语义信息和潜在模式,无需人工设计特征,可提高异常检测的效率、准确率和鲁棒性[15]。为此,提出一种基于胶痕图像深度学习的卷烟真伪鉴别方法,通过构建适用于多种卷烟规格的卷烟真伪鉴别模型,以期利用机器视觉代替人眼视觉进行鉴别,提高卷烟真伪鉴别准确率。
1 材料与方法
1.1 材料
收集10 种常见包装机型生产的烟盒(硬盒卷烟包装机型5种,软盒卷烟包装机型5种);假冒硬盒和软盒卷烟来源于云南省烟草质量监督检测站。拆解所有烟盒并去除内衬纸后得到平整的烟盒样品,包装机型类别、卷烟规格和烟盒样品数量见表1。

表1 包装机型类别和烟盒样品数量Tab.1 Packer types and number of cigarette packet samples
1.2 方法
如图1 所示,基于胶痕图像深度学习的卷烟真伪鉴别方法包括烟盒胶痕图像采集、胶痕图像样本产生、基于深度学习异常检测的真伪鉴别3 个主要步骤。
1.2.1 烟盒胶痕图像采集
烟盒包装过程中主要使用热熔胶或白乳胶作为粘接剂,产生的粘胶痕迹呈无色透明状或白色半透明状,主要分布于硬烟盒内部的正面和反面以及软烟盒内部的侧边。由于烟盒包装纸内部多为白色,使得胶痕在自然光或普通荧光灯照射下人眼辨识度低,难以通过普通拍摄或扫描方式采集到清晰的胶痕图像。借鉴刑侦学中的分色摄影技术[16],利用特殊光谱成分的可见光对烟盒样品进行照射,以增强胶痕与内部包装纸的区分度,并以此设计了一种胶痕图像采集装置,见图2。该装置主体为密闭的遮光箱(长29.2 cm,宽25.5 cm,高32.3 cm),以避免外界环境光干扰。顶部的LED灯带可提供均匀的光照,灯带额定电压5 V,3 条灯带间隔2.5 cm。中间为白光灯带,波长400~760 nm;两侧为蓝光灯带,波长400~450 nm。装置下方的抽拉式铁质底板配备限位器和磁条,便于快速放置烟盒样品。拍摄手机型号为iPhone 11 Pro Max,拍摄软件为Lightroom,选择广角镜头,快门时间1/100 s,白平衡6 000 K,感光度250,画幅缩放200%。利用该装置采集烟盒胶痕图像,图像尺寸为2 000 px×1 500 px,图像存储格式为JPG。
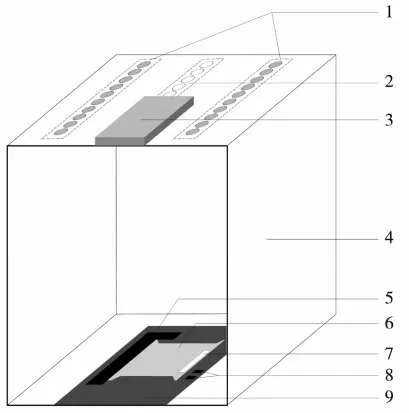
图2 胶痕图像采集装置结构示意图Fig.2 Structure of glue line image capturing device
1.2.2 胶痕图像样本产生
采集到的烟盒胶痕图像仍有大部分与检测无关的背景,需要通过图像处理技术剔除这些背景,以突出图像中的胶痕信息。如图3所示,硬烟盒与软烟盒的图像处理流程:①读取烟盒胶痕图像;②通过二值化生成黑白图像;③对黑白图像进行开操作,先通过腐蚀操作去除烟盒外部的噪点和狭长突起部分,再通过膨胀操作还原烟盒外轮廓;④基于处理后的黑白图像,得到胶痕分布区域的烟盒外轮廓点;⑤根据相邻轮廓点之间的位置关系筛选得到4 个关键点;⑥获取4 个关键点的最大外接矩形;⑦基于最大外接矩形,对原始图像进行裁剪得到胶痕图像样本。图4展示了各包装机型胶痕图像样本,经过图像处理后,图像中的胶痕特征更加显著。

图3 烟盒图像处理流程Fig.3 Process flow of cigarette packet images
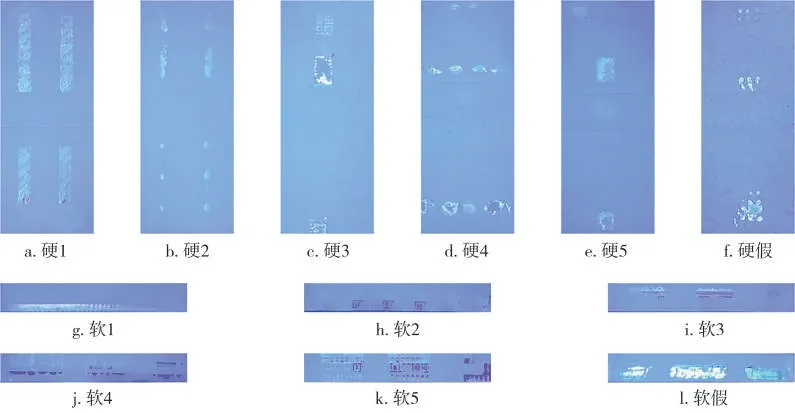
图4 不同包装机型的烟盒胶痕图像样本Fig.4 Glue line image samples from different packers
1.2.3 基于深度学习异常检测的真伪鉴别
机器学习模型在面对训练期间未见过的样本时难以做出准确判别,这将严重干扰机器学习系统在实际应用中的安全性和可靠性。异常检测可以有效解决此类问题,该方法通过正常样本构建检测模型,检测与正常模式存在差异的异常样本[17]。Hendrycks 等[18]的研究表明,由于正常样本与异常样本的分布不同,由正常样本训练得到的分类模型,通常会对同样来自正常分布的样本产生较大的最大预测概率值,而对来自异常分布的样本产生较小的最大预测概率值。为此,本研究中将数量多、胶痕特征稳定的真品胶痕样本视作正常样本,而将数量少、胶痕特征不稳定的假样本视作异常样本,基于深度学习异常检测方法对胶痕图像样本进行真伪鉴别。
1.2.3.1 模型训练数据集的建立和划分
使用包装机型表示胶痕类别,按类别整理胶痕图像样本后,得到胶痕图像数据集。从该数据集的10 个真品类别中,每类随机选取300 个样本组成模型训练数据集,样本总量为3 000 个,各类真品样本分别对应于0~9 的数值标签。然后按7∶2∶1 的比例将模型训练数据集随机划分为训练集、验证集和测试集。
1.2.3.2 模型分类训练
卷积神经网络(Convolutional Neural Networks,简称CNN)作为重要的深度学习网络架构,被广泛应用于图像分类任务[19]。通过模型训练数据集对CNN进行分类训练,训练目标是使模型能够准确识别真样本的胶痕类别。图5展示了CNN分类模型的一般架构,将图像样本调整为指定大小后输入模型,通过一系列操作自动提取图像的深层语义信息,并通过softmax层对网络输出层进行处理,产生多个预测概率值p1,p2,…,pc,softmax层的计算公式可表示为:
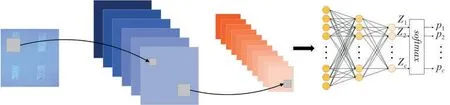
图5 卷积神经网络分类模型Fig.5 Convolutional neural network classification model
式中:zi表示输出层第i个节点的输出值;c表示节点个数,即类别数量;将最大预测概率值记为pmax,该值所对应的类别即为模型预测样本的类别。
选择AlexNet[20]、VGG11[21]、ResNet18[22]、DenseNet121[23]、InceptionV1[24]这5个经典的CNN作为分类模型,各模型通过不同结构改进方式提升自身性能,见表2。

表2 不同卷积神经网络模型的特点Tab.2 Characteristics of different convolutional neural network models
1.2.3.3 模型真伪鉴别
模型真伪鉴别流程见图6。首先,加载完成训练的分类模型,将测试集中所有样本调整为指定大小后输入模型,得到各样本的最大预测概率值。然后,基于最大预测概率值计算判别阈值R,选择两种阈值计算方式进行对比:①将所有最大预测概率值由大到小排列,选取第95个百分位点对应的最大预测概率值作为阈值[25-26],记为R_0.95;②计算所有最大预测概率值的平均值作为阈值[27],记为R_mean。最后,将待测样本调整为指定大小后输入分类模型,通过模型对待测样本产生的最大预测概率值pmax与阈值R进行比较,若pmax≥R,则将该待测样本判别为真,否则判别为假,以此实现模型真伪鉴别。
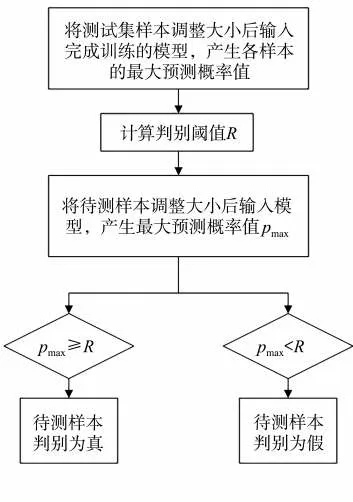
图6 真伪鉴别流程Fig.6 Authentication process flow
2 实验与结果分析
2.1 实验环境
硬件环境:Intel Core i7-10700 CPU @ 2.90 GHz,32 GB 内存,NVIDIA GeForce GTX 1650 图形处理器。软件环境:Windows 10 操作系统,Python 3.9.7 开发语言,图像处理操作基于OpenCV-Python 4.5.5.64实现,深度学习框架基于PyTorch 1.10.2实现。
2.2 参数设置
训练过程中超参数的设定值见表3。为避免模型训练过拟合,采用提前终止的训练策略,若模型的验证集损失值在连续5个训练周期内无下降,则终止训练。
表3 超参数设置Tab.3 Setting values of hyperparameters
2.3 模型分类性能
训练后模型的分类性能见表4。可见,AlexNet的测试集准确率约为94%,表明该模型能够较好地区分真品胶痕类型,其训练集和验证集准确率相差约3 百分点,说明模型存在轻微的过拟合。VGG11的测试集准确率在97%以上,其训练集和验证集准确率的差值在2百分点以内,表明模型具有良好的分类精度和泛化性。ResNet18、DenseNet121、InceptionV1的测试集准确率均能够达到99%,并且其训练集和验证集准确率的差值均在2百分点以内,表明这3 个模型的分类性能优异,精度高且泛化性好。
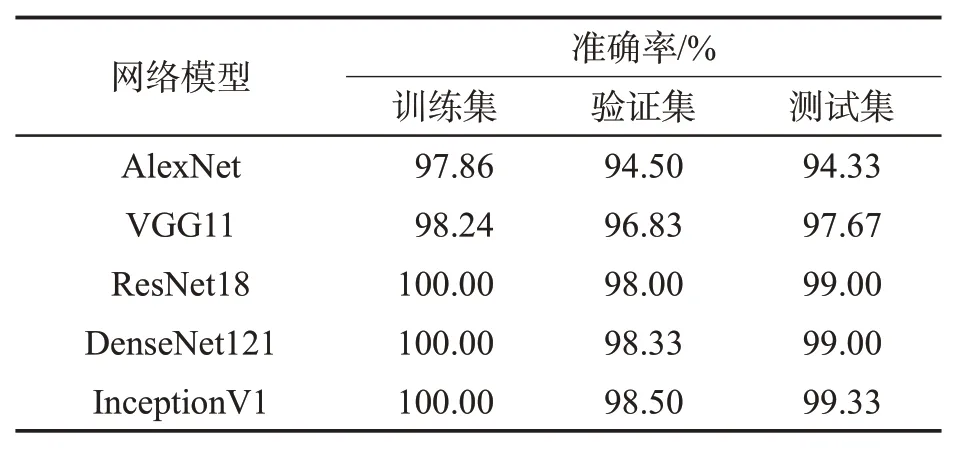
表4 不同卷积神经网络模型的分类性能Tab.4 Classification performance of different convolution neural network models
2.4 模型鉴别性能
将未参与模型训练的974 个真样本和320 个假样本作为待测样本进行真伪鉴别,结果见图7。基于混淆矩阵使用准确率、召回率和特异性[28]对模型的鉴别性能进行评估,结果见表5。可见,不同判别阈值对ResNet18、DenseNet121、InceptionV1 的鉴别性能影响较小,但会显著影响AlexNet 和VGG11 对假样本的判别能力。当阈值R=R_0.95 时,AlexNet 和VGG11 的特异性分别约为32%和52%,表明这两个模型对假样本的判别能力较差;当R=R_mean 时,AlexNet 和VGG11 的召回率分别约为82%和92%,特异性分别约为61%和68%,表明这两个模型能够准确判别大部分真样本,并且具有一定的假样本判别能力。因此,相较于R_0.95,选择R_mean 作为判别阈值能够保证所有模型对真伪样本均具备一定的鉴别能力。当阈值R=R_mean 时,ResNet18、DenseNet121、InceptionV1 的鉴别准确率约为94%,召回率和特异性分别约为93%~94%和93%~95%,表明这3个模型能够对绝大部分的真样本和假样本做出准确判别,表现出优异的鉴别性能。5 个模型的检测时间均在10 ms左右,鉴别速度快,检测效率高。
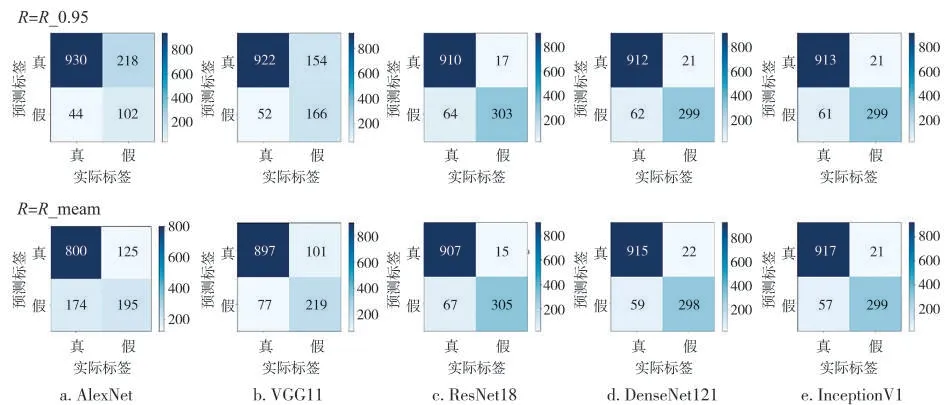
图7 不同卷积神经网络模型的混淆矩阵Fig.7 Confusion matrixes of different convolution neural network models
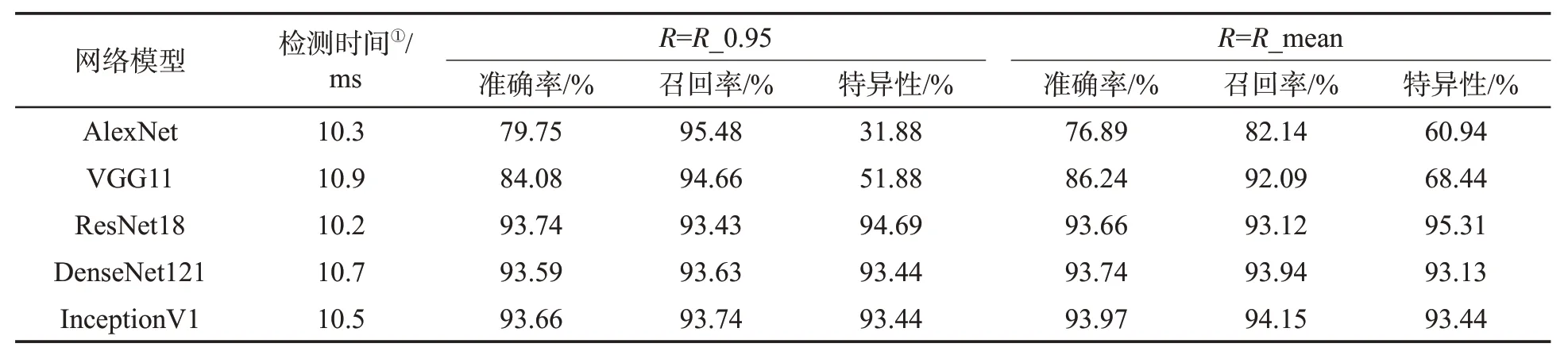
表5 不同卷积神经网络模型的鉴别性能Tab.5 Identification performance of different convolution neural network models
本研究中还引入受试者工作特性曲线(ReceiverOperating Characteristic Curve,简称ROC 曲线)和曲线下面积(Area Under Curve,简称AUC)[29]进一步评估模型的鉴别性能,结果见图8。可见,AlexNet 的AUC 约为0.82,表明模型的鉴别性能较好。VGG11的AUC 约为0.92,表明模型具有良好的鉴别能力。ResNet18、DenseNet121、InceptionV1 的AUC 约为0.98,表明这3 个模型的鉴别性能优异。结合2.3 节模型分类性能进行对比可以看出,模型在训练过程中获得的分类性能越好,其真伪鉴别性能越好。
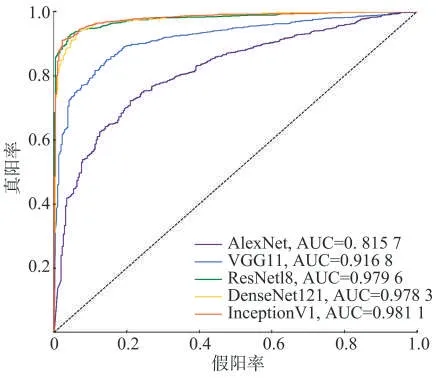
图8 不同卷积神经网络模型的ROC曲线Fig.8 ROC curves of different convolution neural network models
3 结论
提出了一种基于正常样本学习的真伪卷烟胶痕鉴别方法,将卷烟包装外观检测转换为包装痕迹检测,将真伪鉴别问题由一般分类任务转换为异常检测任务。使用1 294个真伪样本进行鉴别测试,结果表明:采用本方法构建的鉴别模型能够在完全不使用假样本训练的前提下对待测样本进行真伪判别,因而无需进行大量的假样本收集和标定工作,并且保证了模型在面对未知假样本时的判别能力。AlexNet、VGG11、ResNet18、DenseNet121、InceptionV1 这5 个CNN分类模型中,ResNet18、DenseNet121、InceptionV1的鉴别性能优异,考虑到InceptionV1 的参数量比其他两个模型更少,有利于将来在移动端设备进行应用部署,因而可以优先使用InceptionV1 构建判别模型。本方法简单、准确、高效,适用于多种常见规格的卷烟产品。未来工作重点是收集其他包装机型生产的足量烟盒样品,构建更加完备的胶痕图像数据集,在新的数据集上进一步验证方法的有效性,并对鉴别模型进行优化,为建立高效、可靠的卷烟真伪智能鉴别方法提供支撑。
