基于ERNIE-BiLSTM-CRF 模型的土壤肥力命名实体识别研究
2023-10-12周乐乐陈磊季丰任竹刘楠楠
周乐乐,陈磊,季丰,任竹,刘楠楠
(安徽省农业科学院农业经济与信息研究所,安徽合肥 230001)
近些年,数据呈现爆发式增长,计算机硬件性能不断增强,计算机算法理论也不断突破,尤其是大数据时代的到来,许多电子文档类的自然语言呈现在我们周围,在人类自然语言文本里提取出相关实体、属性、关系等这类高层次结构化的语义信息来处理每个行业中的一些问题正是现阶段的研究热点[1-2]。种植业与每个人息息相关,土壤情况是种植业的基本。掌握土壤肥力情况是因地种植的前提条件。而现有的土壤肥力数据比较分散,种植户们想快速直接地了解当地土壤肥力情况较为困难。多数情况下种植户们都还是根据经验施肥,这就导致了施肥不科学的情况。
为了将分散的土壤肥力数据利用起来,可以通过建立土壤肥力的知识图谱。土壤肥力知识图谱是将不同地区的土壤肥力信息按照土壤肥力属性关联组合而成的巨大信息网。通过构建土壤肥力知识图谱建立一套土壤肥力知识问答系统,使用者可以通过土壤肥力知识问答系统获取需要了解的地区的土壤肥力指标情况,能更加高效快捷地获得针对性土壤肥力的信息,并将其作为决策依据。
土壤肥力命名实体识别是构建土壤肥力知识图谱中至关重要的一个步骤。首先预定义需要识别对象的语义类别,命名实体识别就是指在文本数据集中利用算法自动识别出预定义过的需要识别的对象[3]。此外,在信息检索、问答系统、机器翻译等方向也常用到命名实体识别[4]。土壤肥力命名实体识别流程见图1。考虑土壤肥力文本的特点:(1)中文数据集文本字词比较随意[5];(2)土壤肥力的属性较多,存在别名和英文缩写;(3)为便于土壤肥力知识问答系统的建立,需要将土壤肥力知识信息在语言理解中进行整合。因此本文使用了一种基于ERNIE-BiLSTM-CRF 模型的土壤肥力命名实体识别技术。

图1 土壤肥力命名实体识别流程
ERNIE-BiLSTM-CRF 模型,采用ERNIE(enhanced language representation with informative entities)模型对土壤肥力信息预训练并进行向量表示,利用BiLSTM(bidirectional long short term memory)学习ERNIE 预训练语言模型输出的字向量特征,并对获得的所有可能的标签序列计分,计分后将所有标签序列输入CRF(condition random field),通过CRF 层解码生成最优序列结果输出。
该研究结合中国知网中文献提供的土壤肥力数据,构建了基于文献数据的土壤肥力领域语料集,并应用于安徽省土壤肥力知识问答系统中。试验结果表明本文构建的ERNIE-BiLSTM-CRF 模型在准确率P、召回率R、F1值方面均取得了较好的效果。
1 相关工作
命名实体识别方法大致可以分为以下3 类方法[6]。
1.1 基于规则的方法
这种方法的基础是依靠人为制定句法、语法、词汇模式和特定领域知识等各个方面的相关规则,在涉及字典不多的情况下可考虑使用这种方法。但特定领域规则、字典不完备导致召回率低。另外每个领域的准则一般都是不通用的,换一个领域就需要再次制定相关规则和字典,系统很难迁移使用。
1.2 基于统计的方法
将训练集中含有的语义信息统计分析,从中挖掘出各种词、上下文和语义等相关特征[7],这种方式对选取特征方面要求比较高,受语料库制约,大规模通用的语料库较少[8]。
1.3 基于深度学习方法
在这种学习方法中命名实体识别被当成序列标注处理,通过大量语料学习出标注模型,标注句子的每个位置[9]。
基于深度学习方法的优点有:命名实体识别时基于深度学习非线性的特性,由输入至输出形成非线性映射。深度学习模型能够基于大量的数据使用非线性激活函数学习,从而获取复杂度更高的精致的特征;深度学习不会涉及很高复杂度的特征工程[10],能够在输入的文本里自动发掘信息并且学习信息的表示,这样自动学习的效果相较于传统方法也是有优势的;深度命名实体识别模型是端到端的,避免流水线类模型中国年各模块间误差传播,能够承载复杂度更高的内部设计,得到更好的效果。
2 ERNIE-BiLSTM-CRF 模型
文中提出的ERNIE-BiLSTM-CRF 模型由3 部分组成,具体结构如图2。
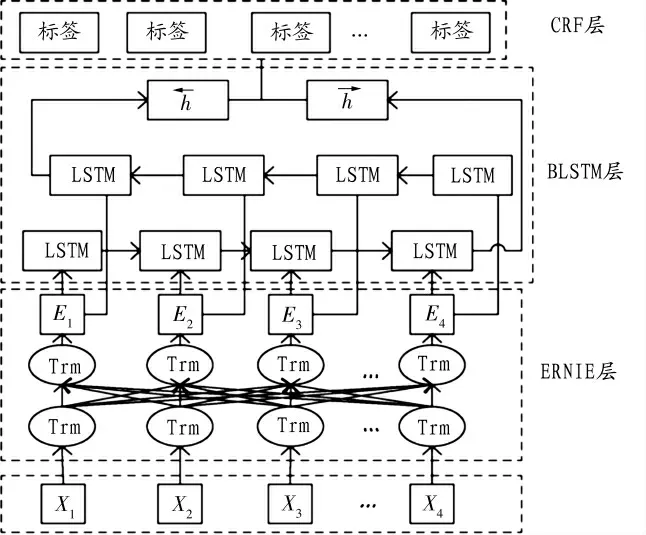
图2 ERNIE-BiLSTM-CRF 模型结构
(1)ERNIE 层:在ERNIE 层预训练处理过的土壤肥力数据集,将输入的文本向量化;(2)BiLSTM 层:在BiLSTM层训练ERNI 预训练模型输出的向量化标签,提取出文本特征,将一切可能的标签序列评分并输出;(3)CRF 层:在CRF 层解码BiLSTM 层输出的所有标签序列并获取其中分值最高的标签序列,此最优标签序列做为模型的最终输出,即为最终的实体标签序列。
2.1 ERNIE 预训练语言模型
最初很长一段时间内,在自然语言处理方面,都是利用Word2Vec 等词向量的方法处理文本编码需求。但这种这种处理后的文本上下文是没有关联的,这样在进行自然突然处理任务的时候就非常局限。另外,有些词会有多种表达意思,使用这种方法进行预训练,后期也无法解决表达具体意思的问题。为了解决一个词语会有多种表达意思的问题,ELMo 率先设计出一种可以表达文本上下文间关联的方法。再后来,诸如GPT、BERT 之类的预训练模型也陆续出现,自然语言处理进入动态预训练技术时代[11]。
近期,针对BERT 模型只学习与语言文本相关的信息,并没有把知识信息整合其中的问题,清华大学与华为的研究学者设计了ERNIE 模型,该模型利用知识图谱提升预训练效果[11]。在知识驱动型的任务中ERNIE 预训练语言模型的效果会比BERT 模型更好。因此,结合文中需要处理土壤肥力信息并用于安徽省土壤肥力知识问答系统,选择通过ERNIE 处理土壤肥力语料,能够将上下文与知识实体的信息同时聚合,构建知识化语言表征模型。
ERNIE 预训练语言模型的结构如图3。ERNIE 是基于多层双向transformer 编码器构建,使用的是全attention 机制[12]。attention 机制与人为分析句子的方式比较相似,主要按照关键信息点来分析理解整句话表达的意思,使用的原理是
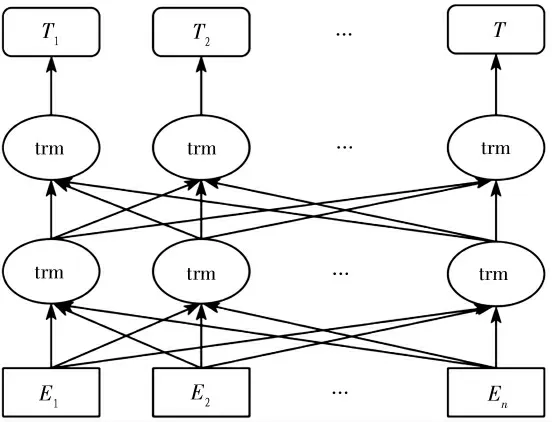
图3 ERNIE 模型结构
公式(1)里,Q,K,V 表示输入字向量矩阵;dk表示输入向量的维度。
计算时,transformer 编码器采用一个计算步骤把句子里任何两个词进行联系,再将所有的词表示通过加权求和,权重则通过softmax 层将此词表示和被编码的词表示进行点积获得[12],这样就能够很大程度地减小远距离依赖特征间距离,提升特征的有效使用率。
ERNIE 预训练语言模型经过3 个掩码阶段处理达到对实体概念知识的学习、强化句子里完整概念的语义表示的功能[13]。
(1)基本遮蔽掩码阶段。把每个句子当作基本的语言单位序列,以每个字为单位施行遮蔽[13]。此阶段只是在字的层面上施行的随机性遮蔽,对高层语义还无法完全建模。
(2)短语级遮蔽阶段。把每个句子中的短语当作基本的遮蔽单位,以短语为单位施行遮蔽。选取句子里的短语,把其含有的每个字使用[mask]标记和预测[14]。通过这种方式能够较好地保留短语信息。
(3)实体级遮蔽阶段。先分析每句话含有的命名实体,包含人员、地点、组织、产品等[14]。再通过随机选取的方式,选取句子里的实体,对实体里每个字使用[mask]标记和预测。
在通过上述3 个掩码遮蔽处理之后,获取的词表示形式含有丰富的语义信息,句子里成分间的关联性以及重要成分包含的语义信息都能够较好地保存下来。
2.2 BiLSTM 层
RNN(Recurrent Neural Network)结构由输入层、隐藏层和输出层3 个模块所组成[15]。相较于其他普通的神经网络结构,该结构特别之处是它的隐藏层之间是前后相连接的。这种相对特别的网络结构能够保存序列里前文信息,因此RNN 结构常被使用在命名实体识别工作中[16]。RNN 结构在处理序列数据时对数据长度并没有进行限制,但是过长的序列会导致梯度爆炸的情况[17]。为了防止这种情况的发生,Hochreiter 等在传统的RNN 结构的基础上设计了LSTM(Long Short-Term Memory)网络[18]。
LSTM 单元结构在传统RNN 基础上进行了优化,是由输入门、遗忘门及输出门3 个门单元模块组成[13],其具体的结构如图4 所示。

图4 LSTM 单元结构
LSTM 结构处理数据时把前一刻的输入做此刻的输出,再利用Sigmoid 激活函数来激活输入的数据,3 部分的公式分别如下:
公式(2)(3)(4)中,it、ft、ot依次表示LSTM 单元结构中输入门、遗忘门和输出门3 个门单元,σ 表示Sigmoid 激活函数,xt是输入的字符向量表示,ht-1表示LSTM 结构上个时刻隐藏层状态,Ct-1表示LSTM 结构上个时刻的细胞状态,b 则表示偏置向量。细胞状态的更新公式如下:
公式(5)中,·为逐元素乘法,tanh 函数即为双曲正切激活函数。LSTM 单元隐藏层状态的更新过程公式如下:
由上可知,一个LSTM 单元结构针对的都是上个时刻的状态,这样处理仅学习到文本里的历史信息,无法学习到未来信息。但是,在实体识别工作中,实体的标签不仅会有历史信息的影响,未来信息也会影响实体的标签。为了学习到文本里的历史信息和未来信息,该试验在这一阶段选用BiLSTM 模型,模型结构如图5 所示。

图5 BiLSTM 结构
该试验使用BiLSTM 模型将上一步骤中ERNIE 预训练的输出作为输入,对其进行正向LSTM 训练与反向LSTM 训练,分别获得和2 个向量,再将这两个向量拼接,这样得到BiLSTM 输出序列既能够学习到文本中的历史信息,又能够学习到文本中的未来信息,比单独的LSTM更加充分地提取文本特征。
2.3 CRF 层
如图6 所示,通过BiLSTM 层处理后,并不能获取标签出现顺序等限制关系并且输出的标签也不能组成完整的实体序列标签。所以还要在预测过程中引入各标签的限制关系。

图6 BiLSTM 输出标签
CRF 属于一种概率化无向图模型。利用CRF 可以在预测过程中引入标签之间的限制关系,以保证最后输出标签的合理性[16]。具体做法是,假设X={x1,x2,…,xn}、y={y1,y2,…,yn}分别是BiLSTM 层输入和对应输出的序列。计算标签序列得分的公式如下:
公式(7)中,W 是转移矩阵,yi是xi对应的输出,yi+1是xi+1对应的输出,Wyi,yi+1是表示标签从yi转移到yi+1的得分,Pi+1,yi+1表示输入序列第i+1 个字对应标签yi+1的得分。再对标签序列y 的概率进行计算,计算公式如下:
公式(8)中,YX是一切可能标签组成的集合。计算出概率最大的标签集合,将其做为最终的输出序列标签。
3 结果与分析
3.1 数据集
该试验涉及数据集为土壤肥力数据集。土壤肥力数据集是根据中国知网1980 年1 月至2021 年7 月间的学术期刊文献,通过过滤条件“SU=(土壤)×(肥力+测土配方+土壤养分+全氮+全磷+全钾+pH+有效磷+有效氮+有机质+黏粒+砂粒+粉粒)NOT TI=(订阅+订购+征文+征稿+稿约+声明+启事+通知+须知+通讯+论文索引)”筛选出包含土壤肥力十大指标数值的文献,并存为UTF-8纯文本格式。将其中地址、数值、关系进行标注。试验中,训练集使用720 条,验证集使用180 条,测试集使用90 条。
ERNIE-BiLSTM-CRF 模型在处理短文本命名实体识别上具有很大的优势,但是在处理长文本实体识别上效果就没有那么好。~因此在试验前需要将大量的土壤肥力长文本进行处理,提取出数据集长文本里对试验有用的语句,去除其中的无关语句。
假如有一段这样表述的长文本:“试验地区选在安徽省长丰县岗集镇周山村,时间为2020 年,该区原土壤养分如表2。xxxxxx,xxxxx。由图3 可知,试验处理后的土壤pH为5.01,处理之后pH 下降。”其中“xxxxxx,xxxxx”代表中间还有很多汉字。
通过这段长文本内容,找到“安徽省长丰县岗集镇周山村”这种地址字符串,一直循环下去,直到找到最近的句号,立即停止,这样就可以获得“试验地区选在安徽省长丰县岗集镇周山村,时间为2020 年,该区原土壤养分如表2。”这样含有地址的文本。之后再循环剩余的句子,找到类似“5.01”这种数值字符串,同样,在遇到句号立即停止循环,这样循环得到最终的“由图3 可知,试验处理后的土壤pH 为5.01,处理之后pH 下降。”这样含有数值的文本。再将获得的文本进行拼接,得到一段新的短文本“试验地区选在安徽省长丰县岗集镇周山村,时间为2020 年,该区原土壤养分如表2。由图3 可知,试验处理后的土壤pH 为5.01,处理之后pH 下降。”
通过上面的方法,可以将数据集中长文本处理为短文本,如表1 所示,与开始的长文本对比,去除了其中许多无用的文本,只提取其中与试验相关的短文本。再使用ERNIE-BiLSTM-CRF 模型进行土壤肥力命名实体识别,极大地降低了长文本的干扰,提高试验的有效性。

表1 长文本处理后得到的短文本
3.2 试验环境与参数
该试验环境见下表2。

表2 试验环境
ERNIE-BiLSTM-CRF 模型参数设置见表3。

表3 模型参数
3.3 评价指标
在该试验中,通过准确率P、召回率R、F1值这3 个通用指标评价土壤肥力命名实体识别的试验效果。3 种评价指标越高,代表模型的准确率、召回率和综合性能越好。各评价指标的计算公式为:
3.4 结果与分析
为了验证试验结果,通过长文本处理数据集后,再分别使用HMM 模型、CRF 模型、BiLSTM 模型、BiLSTM-CRF模型、ERNIE-BiLSTM-CRF 模型的土壤肥力命名实体识别实验,结果见表4。由试验结果数据可知,文中使用的ERNIE-BiLSTM-CRF 模型在正确率、召回率和F1值都高于其他几个模型,并且分别达到92.85%、92.00%、92.59%,取得了均高于92%的数值,文中使用的ERNIE-BiLSTM-CRF模型在处理土壤肥力命名实体识别中有很大的优势。

表4 不同模型的试验结果
4 结语
针对传统土壤肥力解析方法效率低、迁移能力差、长文本处理的问题,文中提出了ERNIE-BiLSTM-CRF 模型。为了达到更理想的土壤肥力命名实体识别,在使用模型前,将土壤肥力数据集中长文本处理为短文本。ERNIE-BiLSTM-CRF模型首先通过ERNIE 预训练模型生成基于上下文语义的字向量,提升了字向量的表征能力,再通过BiLSTM 层学习向量特征,最后通过CRF 层解码得到最优标签序列,提升土壤肥力命名实体识别的效果。文中模型处理了长文本命名实体识别问题,并且不需要人为制定相关规则、特征模板,实验结果取得了最高的F1值,为92.59%,能够有效识别出土壤肥力的各种实体信息。本研究还利用本文提出的模型构建土壤肥力知识图谱,把分散的土壤肥力数据利用起来。下一步工作计划,检验文中模型在实际使用效果,根据使用情况进一步改进算法。另外持续地搜集新的土壤肥力数据,更新数据集,提供更加准确的土壤肥力数据以及更加科学的施肥建议。
