基于迁移学习的智能合约漏洞检测方法
2023-10-11薛佳雷张佳乐孙小兵
薛佳雷, 李 斌, 张佳乐, 孙小兵, 蔡 杰
(扬州大学信息工程学院, 江苏 扬州 225127)
近年来, 区块链技术[1]快速发展,作为区块链核心部分的智能合约[2]为交易多方提供了可信的去中心化应用程序, 但其存在的漏洞常被用于恶意攻击用户账户,造成巨大的经济损失.现有的智能合约漏洞检测方法主要为传统检测工具和机器学习方法.传统漏洞检测工具包括SmartCheck[3]和Securify[4], 其中SmartCheck是根据合约语法规则生成源代码的可扩展标记语言(extensible markup language, XML)解析树作为中间表示, 通过查询匹配数据发现漏洞; Securify是通过将代码符号化来分析数据流和控制流信息, 根据预定义的安全属性规则进行漏洞检测.基于符号执行的传统漏洞检测方法需要探索所有的可执行路径或分析合约中的依赖关系, 耗时较长, 且依赖预先定义的专家规则.机器学习方法则是利用神经网络模型自动学习检测工具中无法定义的漏洞特征, 进而提高漏洞检测的准确率, 已被广泛应用于智能合约漏洞检测.Gao等[5]提出了一种基于词嵌入和向量空间的SmartEmbed漏洞检测方法, 代码为矩阵向量, 通过比较相似度阈值检测漏洞; Zhuang等[6]提出将合约代码的函数公式转换为合约图, 根据信息传递构造的神经网络作为漏洞检测模型; Wang等[7]提出ContractWard方法, 从智能合约的操作码中提取二元图特征, 利用机器学习算法进行漏洞检测.然而, 机器学习过程需要大量的标签数据集, 而以太坊平台上开源的智能合约源代码仅占1%[8], 漏洞数据集十分匮乏.针对以上问题, 本文拟引入迁移学习[9]的思想, 提出一种基于迁移学习的智能合约漏洞检测方法, 利用预训练模型对智能合约代码进行表征, 以期提高特征提取准确度, 在小数据集上获得更好的检测效果.
1 本文方法
1.1 总体框架
本文提出的基于迁移学习的智能合约漏洞检测模型总体框架如图1所示.预训练阶段, 获取CodeBERT[10]预训练模型中编码器的训练参数, 迁移到漏洞检测模型的编码器中. 微调阶段, 训练智能合约漏洞检测模型, 先对智能合约源代码漏洞数据集进行数据预处理, 去除中英文注释和空格, 转化为代码序列, 使用迁移参数后的编码器将智能合约代码序列转化为特征向量; 再使用长短期记忆(long short-term memory, LSTM)网络接收预训练模型的输出结果, 进一步获取智能合约代码的上下文特征; 最后在输出层使用全连接层和Softmax逻辑回归分类函数, 输出智能合约漏洞检测结果, 采用交叉熵作为损失函数.应用阶段, 输入未知漏洞的智能合约源代码, 进行漏洞检测并输出漏洞检测结果.
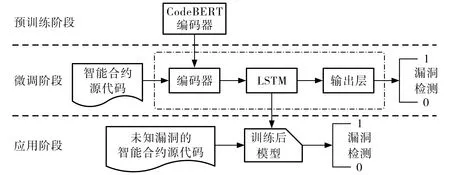
图1 模型总体框架Fig.1 Overall framework of the model
1.2 智能合约代码特征提取
智能合约特定的Solidity语言是一种面向对象的编程语言,与传统编程语言具有相似的编码规定和语法结构,因此可迁移从传统编程语言学习到的知识, 例如变量命名规定、代码标记顺序信息和语义表示等, 能够更好地利用现有资源.CodeBERT模型使用Java、Python、 JavaScript、 Ruby、 PHP和Go等6种传统编程语言代码进行训练, 具备良好的代码特征提取能力.本文通过访问CodeBERT预训练模型的编码器, 获取训练参数, 提取智能合约代码特征.
根据图2所示的Transformer编码器结构, 利用多头自注意力层捕捉输入信息的重要部分, 帮助漏洞检测模型重点关注智能合约代码的语义表示.8个注意力头部进行并行特征分析, 除训练权重和参数外, 其余结构完全一致.
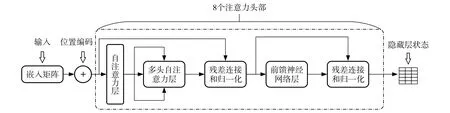
图2 Transformer中的编码器结构Fig.2 Structure of Transformer encoder
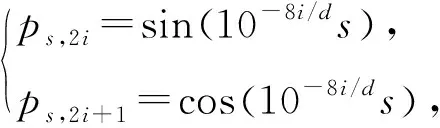
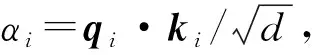
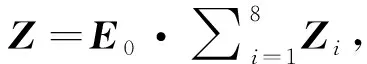
1.3 基于LSTM网络的特征向量处理
采用LSTM网络进行特征向量处理, 获取长距离依赖的序列特征表示.LSTM单元结构如图3所示, 包含遗忘门、输入门和输出门3种门结构, 利用tanh激活函数控制信息交互, 并维持和控制单元状态.
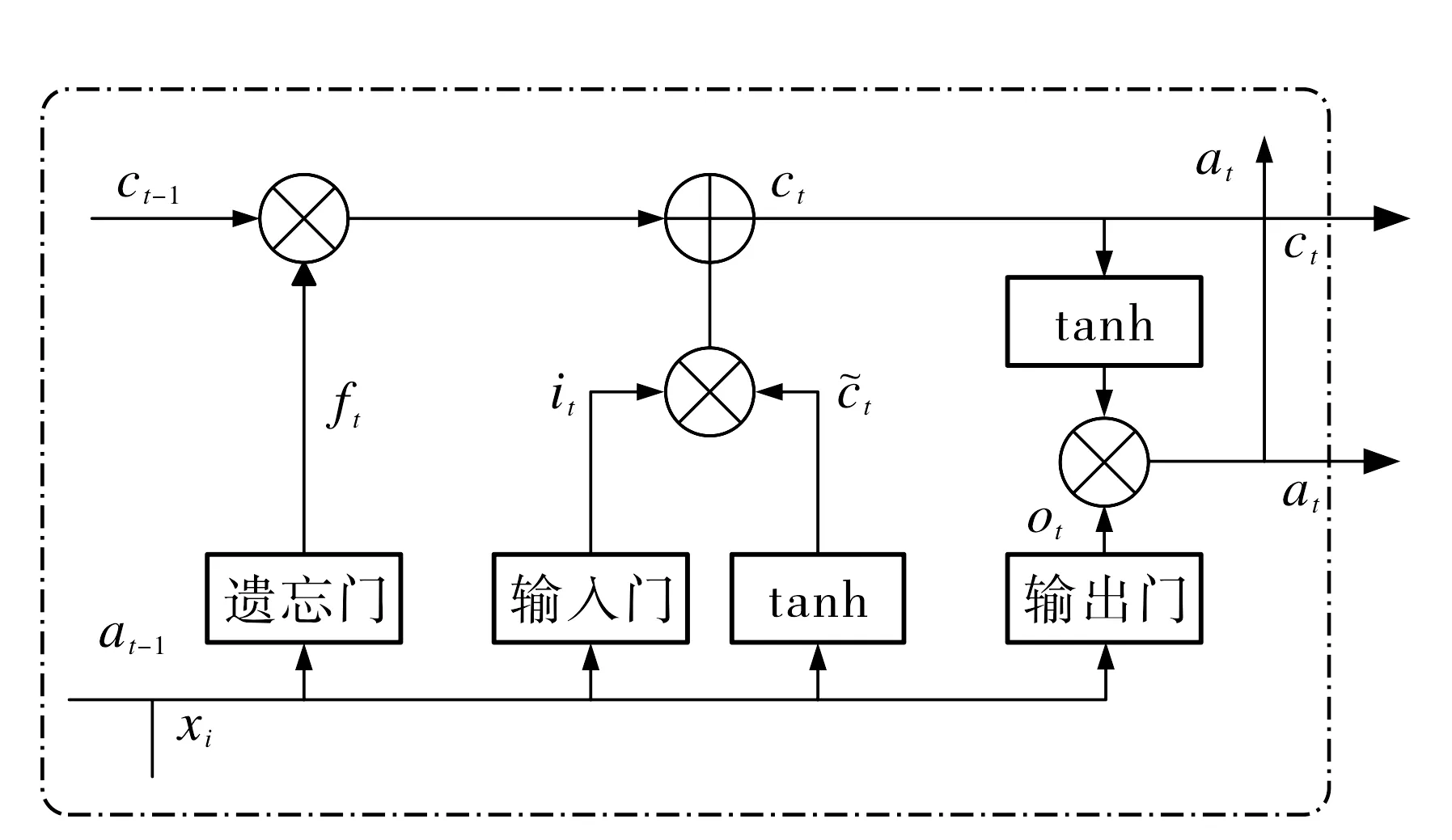
图3 LSTM单元结构Fig.3 LSTM cell structure
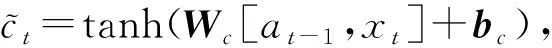
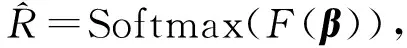
2 实验结果与分析
本文实验采用的操作系统为Windows 10, 处理器为Intel Core i5, 显卡为NVDIA RTX 3060, 显存为32 GB, CUDA版本为11.1, cuDNN版本为8.7.1, Python版本为3.7.10, Pytorch版本为1.14.编码器最大长度设置为512, 批量大小设置为8, 学习率设置为0.000 01, 训练轮次设置为15.
2.1 实验数据集
选取Smartbugs[11]和Smart-Contract-Dataset[6]两个公开数据集进行智能合约漏洞检测实验.数据集包括整数溢出、可重入性、执行顺序依赖、时间戳、拒绝服务和tx.origin漏洞6种solidity智能合约编程语言的常见漏洞.以Smartbugs数据集作为漏洞检测的基准数据集, 收集Smart-Contract-Dataset中包含6种漏洞类型的智能合约补充到基准数据集中, 每种漏洞类型对应的样本数量分别为整数溢出1 362个, 可重入性555个, 执行顺序依赖944个, 时间戳1 093个, 拒绝服务407个和tx.origin漏洞155个, 将数据集按7∶3划分为训练集和测试集.
2.2 评价指标
2.3 实验结果
图4为智能合约漏洞检测实验训练集和测试集的准确率和损失函数曲线图.由图4可知, 训练过程和测试过程的损失函数曲线在实验初期拟合良好, 随着训练轮数的增加, 拟合度降低, 产生一定范围内的波动; 6种漏洞检测的准确率均在80%以上, 其中tx.origin漏洞检测的准确率高达98.05%.由此得出, 本文提出的基于迁移学习的智能合约漏洞检测方法是有效的.
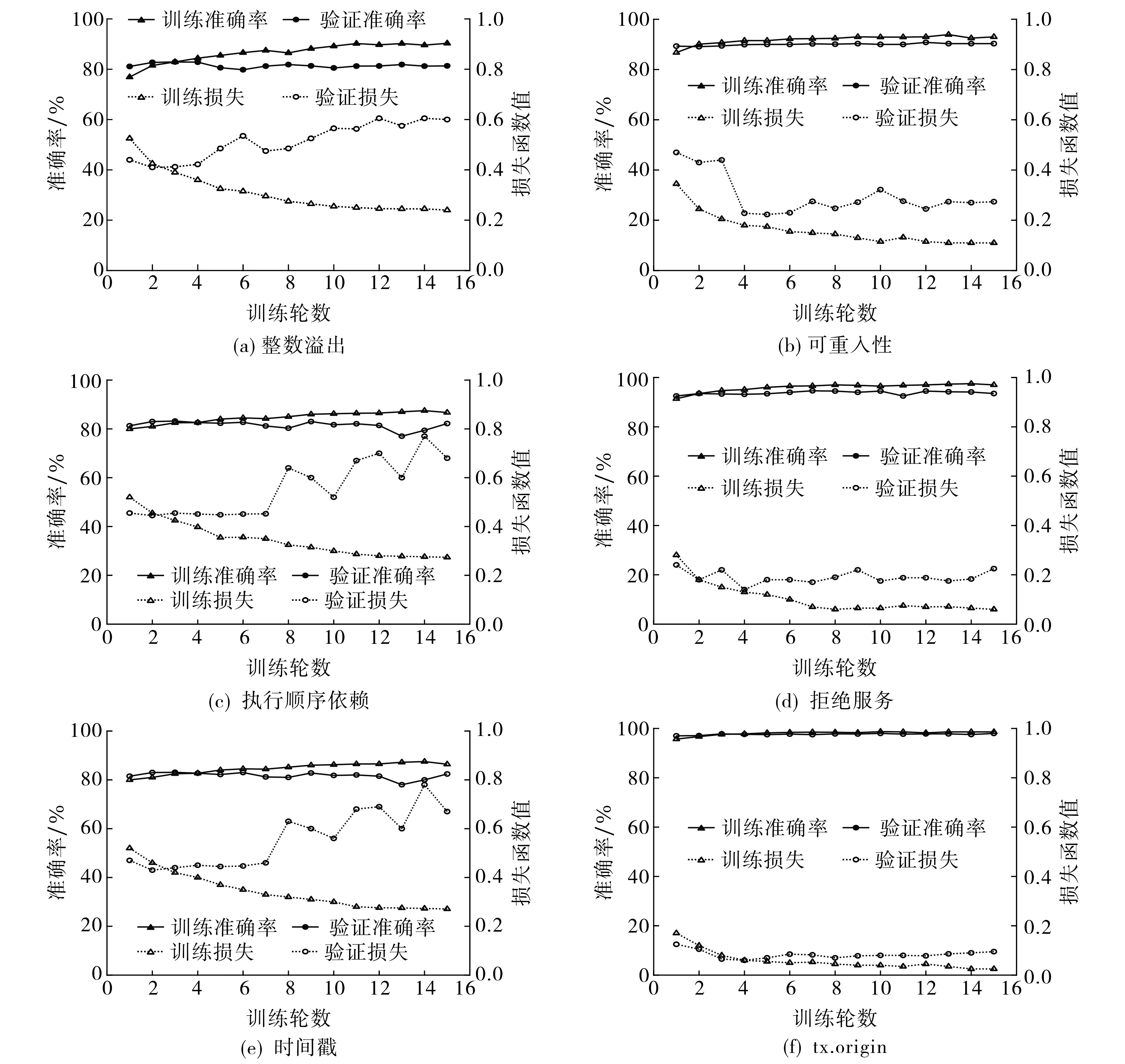
图4 6种漏洞的准确率和损失函数曲线Fig.4 Accuracy and loss function curves for six vulnerabilities
为了进一步验证本文模型的有效性, 选取主流的智能合约漏洞检测工具SmartCheck[3]、 Securify[4]和Mythri作为基线模型进行对比实验, 结果如表1所示.由表1可知, 与3种基线模型对各类漏洞检测的最佳结果相比, 本文模型检测整数溢出漏洞的精度、召回率和F1分数分别提升了16.59%, 22.28%和19.60%,可重入性漏洞的精度、召回率和F1分数分别提升了24.13%, 13.31%和18.45%, 执行顺序依赖漏洞的精度、召回率和F1分数分别提升了14.67%, 2.99%和6.53%,时间戳漏洞的精度、召回率和F1分数分别提升了20.43%, 27.43%和24.3%, 拒绝服务漏洞的精度、召回率和F1分数分别提升了17.91%, 25.81%和27.58%, tx.origin漏洞的精度、召回率和F1分数分别提升了21.26%,53.29%和26.2%.综上得出, 相较于基线模型, 本文提出的智能合同漏洞检测模型的检测效果显著提高.
此外, 选择循环神经网络[12](recurrent neural network, RNN)和门控循环单元(gated recurrent unit, GRU)两种具有代表性的机器学习方法进行对比实验, 结果如表2所示.由表2可知, GRU模型的漏洞检测性能优于RNN模型, 与GRU模型相比, 本文模型检测整数溢出漏洞的精度、召回率和F1分数分别提升了32.06%, 17.68%和23.81%, 可重入性漏洞的精度、召回率和F1分数分别提升了21.78%,1.66%和11.17%, 执行顺序依赖漏洞的精度、召回率和F1分数分别提升了17.13%, 2.37%和5.16%, 时间戳漏洞的精度、召回率和F1分数分别提升了20.13%, 9.97%和15.36%, 拒绝服务漏洞的精度、召回率和F1分数分别提升了5.11%,9.93%和6.82%, tx.origin漏洞的精度、召回率和F1分数分别提升了12.46%,2.07%和6.57%.综上得出, 本文模型的精度、召回率和F1分数3项指标均有所提高, 进一步证实了本文提出的基于迁移学习的漏洞检测模型能够有效地捕获带有漏洞的智能合约代码特征,从而提高漏洞检测的准确率.
