基于串行自编码器的无监督领域自适应特征学习方法
2023-10-11陈家合
陈家合, 朱 毅, 沈 辉, 王 志, 李 云
(扬州大学信息工程学院, 江苏 扬州 225127)
传统的机器学习方法通常假设训练数据与测试数据独立同分布, 而现实场景中却难以满足该情形[1].为了解决不同领域中数据分布不匹配的问题, 领域自适应方法被提出且成为数据挖掘和人工智能领域的研究热点[2].近年来, 深度学习方法因其强大的特征学习能力而被广泛用于学习领域间不变的特征表示[3].主流的深度学习模型, 如自编码器(autoencoder, AE)[4]、卷积神经网络[5]、递归神经网络[6]和生成对抗网络[7]等, 均能够学习跨领域的高层特征表示, 并且可以通过对齐领域间的全局特征表示实现知识迁移,从而完成跨领域的学习任务.例如, Wang等[8]提出一种基于标签自矫正的无监督领域自适应方法,使用概率标签直接端到端地学习并矫正目标领域样本的伪标签.在众多深度学习模型中, 基于自编码器的无监督领域自适应方法因无需标签进行训练和快速收敛等优势而备受关注.Wei等[9]提出一种改进的边缘化堆叠去噪自编码器的特征学习方法, 在堆叠自编码器的损失函数中引入核化非线性编码, 通过最大均值差异度量的最小化域散度提取具有较小分布差异的深度特征; Zhu等[10]提出一种基于堆叠卷积稀疏自编码器的无监督领域自适应方法, 通过在原始数据进行层投影获得更高级的特征表示; Li等[11]提出一种联合对抗变分自编码器方法, 利用Wasserstein距离调整边际和条件分布以缩小领域之间的差异, 从而消除类别先验偏见的影响.然而, 现有的基于自编码器的方法倾向于通过对单个自编码器的堆叠逐层学习领域之间的多种特征表达来降低局部差异[12], 而忽略了不同特性的自编码器所学习到的特征表达间的差异性; 因此, 本文拟提出一种基于串行自编码器(serial autoencoder unsupervised domain adaptation, SAUDA)的特征表示学习方法, 通过串行方法连接堆叠自编码器和稀疏自编码器, 进一步发掘领域之间的全局特征.
1 串行自编码器
1.1 问题形式化
1.2 自编码器
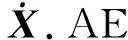
若AE的输入X∈R(ns+nt)×d, 其中d为特征空间的维数.假设W1,b1为编码层的权值矩阵和偏置向量,W2,b2为解码层的权值矩阵和偏置向量,σ1,σ2分别为编码阶段与解码阶段的节点激活函数.AE首先通过线性映射和非线性激活函数完成对输入样本的编码, 得到编码特征输出
H=σ1(W1X+b1);
(1)
然后解码器通过对编码特征进行解码得到输入样本的重构
(2)
AE的训练目标是使得损失函数J达最小值, 即求minW1,W2,b1,b2J(W1,W2,b1,b2).本文选择平方损失误差函数
(3)
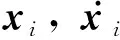
采用梯度下降算法, 通过反向传播误差调整网络参数使得重构误差函数达最小值.假设学习速率为η, 更新AE的权值矩阵W1,W2和偏置向量b1,b2:
(4)
(5)
为了提取更具代表性的特征, 本文采取多个AE级联方式构建SAE, 采用逐层贪婪训练方法将上一级AE的隐含层输出作为下一级AE的输入来提取层次化特征.
1.3 稀疏自编码器
当隐含层节点多于输入节点时, AE会失去自主学习样本特征的能力, 此时需要对隐含层添加一定的约束.SSAE则是在AE中添加稀疏性限制, 旨在得到更具代表性的特征表示, 并发现样本中的特定结构.在SSAE中, 稀疏性限制迫使隐含层节点大部分时间处于抑制状态, 即当激活函数选择Sigmoid时隐含层节点输出接近于0, 从而使得网络仅依赖少量处于激活状态的隐含层节点进行编码和解码, 提取更具稀疏性的特征.
本文采用L1范数正则化项对损失函数的激活项加以惩罚, 迫使神经元输出的平均激活值与一个给定的稀疏值接近.给定隐层节点k对输入xj的激活值ak(xj), 通过L1正则化系数μ来控制惩罚程度, 则SSAE的损失函数
(6)
SSAE能有效学习重要特征和抑制次要特征, 从而得到领域间更好的全局特征表示.
2 基于串行自编码器的无监督领域自适应
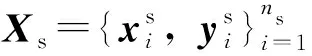

图1 SAUDA框架示意图Fig.1 The framework of SAUDA
3 实验结果与分析
硬件环境为NVIDIA Geforce RTX 3090 Founders Edition GPU,Intel(R)Core(TM)i9-10980XE CPU, 内存为128 GB.编程软件为Python 3.9.16, 机器学习包PyTorch-CUDA 11.7.
3.1 数据集
实验数据集是由淘宝和京东网站的电商评论收集并整合而成的中文情感分析数据集(https://github.com/zhuyiYZU/Chinese-e-commerce-review-dataset), 包含6种领域类别,共60 000条评论数据,其中正负例样本各30 000个.现选取“计算机”“书籍”“水果”和“洗发水”等4种领域类别,每个领域选取正负例样本各1 000个, 并设置“计算机→水果”“计算机→洗发水”“书籍→水果”和“书籍→洗发水”等4种不同的跨领域任务.
3.2 特征学习准确率
利用本文提出的SAUDA方法进行无监督领域自适应特征学习, 并与标准AE[4]、卷积神经网络(convolutional neural network, CNN)[5]、堆叠自编码器串行连接(SAE+SAE)以及稀疏自编码器与堆叠自编码器串行连接(SSAE+SAE)等领域自适应方法进行对比分析.
每个任务选取2 000条源域数据样本和2 000条目标域数据样本.在基于CNN和标准AE方法的实验中, 设置训练轮次为5轮, 批量大小为32个, 学习率为0.001.在本文方法、SAE+SAE和SSAE+SAE自编码器实验中, 设置训练轮次为10轮, 批量大小为64个,学习率为0.001,稀疏参数为0.3.选择分类精度作为评估指标, 其中y(x)为实例x的真实标签,f(x)为分类模型预测的x的标签.表1给出了上述5种方法在中文电商评论集的4个跨领域任务上的实验结果.由表1可知: 本文SAUDA方法是有效的, 且在不同任务上的特征学习准确率优于其他4种方法.其可能原因是: 1) 基于串联自编码器的领域自适应方法能够进行二次特征学习, 从而挖掘更丰富的全局特征表示; 2) 特征学习的不同阶段引入不同种类的自编码器后学习得到的特征表示差异很大, SAUDA方法因在各阶段引入合适种类的自编码器进行适应性的特征学习, 故具有更高的特征学习准确率.

表1 5种方法在不同任务上的特征学习准确率
(7)
3.3 参数敏感性
为了验证学习率rl、训练轮次和批量大小等参数对本文方法的影响, 现对其参数敏感性进行实证分析.
设置训练轮次为10, 批量大小为64 ,当rl分别为0.000 1, 0.000 5, 0.001, 0.003时跨领域分类任务的准确率如图2(a)所示.由图2(a)可见: SAUDA对于学习率的变化较敏感, 当rl=0.001时, 模型学习的准确率最优, 但当rl过高或过低时模型的学习效率较低.这是因为当学习率过高时, 大幅度的参数更新会导致模型错过在自适应中所需的最佳特征表示, 从而在目标领域上产生较差的泛化性能; 当学习率过低时, 参数的微小更新可能无法有效调整模型能用于领域自适应的特征表示.故本文优化选择学习率为0.001.
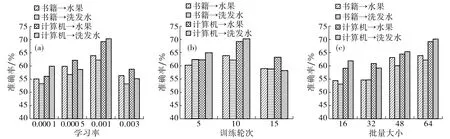
图2 SAUDA在不同参数影响下的准确率Fig.2 The accuracy of SAUDA under the influence of different parameters
设置rl为0.001, 批量大小为64,当训练轮次分别为5,10,15时跨领域分类任务的准确率如图2(b)所示.由图2(b)可见: 在不同任务下训练轮次对分类准确率的最优解不同, 当训练轮次取10时,模型整体能够获得最优解.这是因为此时模型有足够的时间有效地从目标领域学习特征和适应源领域的特征;训练轮次过低, 模型无法充分捕捉目标领域的特征,导致分类性能下降; 训练轮次过多,模型则会因过度关注目标领域而丧失对源领域的泛化能力.故本文优化选择训练轮次数为10.
设置rl为0.001, 训练轮次为10, 当批量大小分别为16,32,48,64时跨领域分类任务的准确率如图2(c)所示.由图2(c)可见: 随批量大小增加, 各任务的整体分类准确率都呈上升趋势, 当批量大小取64时, 跨领域分类任务的准确率最高.由于更大的批量大小可能引发模型训练的不稳定性, 同时需要更多的计算资源, 并且易导致模型对训练数据中的噪声过于敏感, 故权衡模型训练的稳定性与泛化性能, 本文优化选择批量大小为64.
4 结语
本文考虑不同类型的自编码器可学习不同的特征表示, 提出了一种基于串行自编码器的无监督领域自适应特征学习方法.通过串行连接两种不同类型的自编码器,学习到更强大、更具有鲁棒性的全局特征表示,以用于不同的无监督领域自适应任务.实验结果表明, 本文方法的分类准确率最优,可为串行连接自编码器的领域适应方法研究提供一种可行的思路.今后将进一步考虑自编码器个数以及堆叠层数对模型分类性能的影响,组合不同类型的自编码器应用于不同的无监督领域自适应任务.
