基于PCA-PSO-RBF模型的水产品冷链物流需求预测
2023-10-11庄伟卿王浩燃
庄伟卿,王浩燃
(1. 福建理工大学 互联网经贸学院,福建 福州 350014;2. 福建理工大学 交通运输学院,福建 福州 350118)
具有易腐和温度敏感特性的水产品在运输与储存时,对供应链冷链物流各环节有效协调和供需信息匹配要求较高,准确的冷链需求预测会降低供应链中断的风险[1~2]。现阶段对冷链水产品需求预测研究侧重于方法。如鲁泉[3]建立灰色预测模型对中国渔业产量预测;Ren[4]考虑了影响需求的因素,提出了反映信息优先级的多变量灰色预测模型FGM(1,N);He[5]引入了灰色与BP神经网络相组合模型;韩慧健[6]采用模糊认知图构建预测模型;夏伟怀[7]利用随机森林预测模型对铁路冷藏运输需求量进行预测;刘艳利[8]采用主成分因子分析降维,用BP预测模型对水产品冷链物流需求预测;Ma H J等[9]在改进的神经网络算法中加入逻辑回归算法; Keizer[10]采用人工鱼群算法(AFSA)优化SVM构建组合模型对物流需求进行预测;李敏杰等[11]运用RBF预测模型对水产品冷链物流需求模拟仿真,显示了较好的非线性处理能力。但单一RBF预测模型针对于多因素特征小样本的数据容易产生过拟合现象,而实际应用中,水产品冷链物流需求受到多因素的影响。
本文利用灰色关联分析法筛选出与冷链水产品需求相关性较强的影响因素,结合PCA进行数据降维,通过改进PSO算法优化后的RBF神经网络构建PCA-PSO-RBF模型,得到水产品冷链物流预测结果,可提升预测精度,为此类研究与政府决策提供帮助。
1 研究方法
1.1 灰色关联分析(GRA)
(1)把水产品冷链物流需求量作为原始数据进行规范化预处理, 18种水产品冷链物流因子作为影响因素,需求量作为目标因素。组成以需求量为第一列的22行19列的原始数据矩阵,创建一个所有元素值均为各列数组均值的重复数组22行19列矩阵,以原始数据矩阵除以重复数组矩阵对应值,即可得出预处理后数据,将处理后数据第一列设为x0并作为参考数列,n的取值范围为1~22,如式(1)。
x0(k)=[x0(1),x0(2),x0(3),…,x0(n)]
(1)
(2)将其他对水产品冷链物流需求量影响的18种因素设为xi(k),i作为比较数列,取值范围为1~18,如式(2)。
xi(k)=[xi(1),xi(2),xi(3),…,xi(n)]
(2)
(3)计算灰色关联系数ξ(k),如式(3),ξ(k)表示在k处各类水产品影响因素对目标因素的关联系数;ρ为范围[0,1]的分辨系数,取值0.5。
ξ(k)=
(3)
(4)计算影响因素与目标因素间灰色关联度γi,如式(4)。
(4)
式中,灰色关联度值越大,代表影响因素对于目标因素越重要;反之,则越不重要。
1.2 主成分分析(PCA)
利用SPSS软件中主成分分析对输入进行降低维度处理,即在操作界面的分析栏中选择降维因子,将影响冷链物流需求量18列数据作为输入,在“提取”界面选择“主成分”并设置提取特征值大于1的成分,得到各影响因素累计贡献率与特征值,根据累计贡献率高于80%原则,对需求参数进行成分划分,最终划分为两个主成分,并在后续基于主成分分析的预测模型中替代18种影响因素作为其输入数据,减少了相关性低的参量影响,提升模型运行效率,提高模型预测精度,最大程度保留原有数据集的信息并简化计算。
1.3 RBF神经网络及算法
RBF是前馈型神经网络,具有3层网络结构且性能优异,其寻优逼近能力与速度皆比传统BP神经网络好,可逼近任意非线性函数,原理是将输入数据映射到隐含层,把径向基函数作为隐单元的基,构成隐含层空间,在空间中将数据转换,把非线性变成线性可分,文中将主成分分析后的训练集2000~2020年的影响因素数据作为输入,水产品冷链物流需求量作为输出,通过算法训练学习确定权重,使用训练好的网络再对测试集2003年至2021年的水产品冷链物流需求量进行预测,图1为RBF神经网络结构图,设输入层有m个节点,隐含层有n个节点,并由权值w连接。

图1 RBF神经网络结构图Fig.1 PBF network structure diagram
在现实仿真实验中,通常选择正定的高斯基函数为RBF隐藏层函数,如式(5)。
(5)
式中,x为神经网络输入样本,个;Pj为隐含层的节点向量,个;cj为隐藏层节点的中心矢量,与输入样本维度相同;δj为隐藏层节点的宽度。
RBF的线性输出表达式为:
(6)
式中,y为神经网络的计算输出数值,万t;n为隐含层神经元节点数;wj代表隐含层与输出层间权重。虽然RBE算法有较好的处理非线性能力,但其神经网络参数的确定与模型的输出密切关联,因此用合适的算法来优化模型以避免陷入局部最优尤为重要。
1.4 改进的PSO优化模型
利用粒子群算法思想来寻求最优解,在每一次迭代中,粒子根据追踪个体与全局极值进行更新自我,速度与位置的寻优分别如式(7)(8)。
vi,j(t+1)=wvi,j(t)+c1r1[pi,j-xi,j(t)]+c2r2[pg,j-xi,j(t)]
(7)
xi,j(t+1)=xi,j(t)+vi,j(t+1)
(8)
式中:c1、c2都为学习因子;w为惯性因子;r1和r2为在[0,1]间的随机数;xi,j(t+1)为粒子进行第t+1次迭代时所在位置;vi,j(t+1)为粒子进行第t+1次迭代时速度;pi,j为粒子以往迭代过程中最佳位置;pg,j为整个群落在第j维最佳位置。在文献[12]中考虑学习因子c1取值过大会让全局寻优能力不足,过小则过早收敛,提出分段式的非线性递减的方法,算法性能得到改善。但未考虑在PSO算法中粒子是通过pi,j和pg,j两个参数实现自我进化。本文设计加入一种避免粒子后期陷入局部最优,并提升其他粒子的全局新区域寻优能力的方法,如式(9)(10)。
pi,j=pi,j×(μ1×randn(1,1)+1)
(9)
pg,j=pg,j×(μ1×randn(1,1)+1)
(10)
式中:μ1、μ2分别为权重调节系数,经多次实验确定μ1=0.1,μ2=0.7时,模型效果最好。randn(1,1)为正态分布随机数,可在模型后期重新计算调整pi,j、pg,j。算法模型流程如图2。
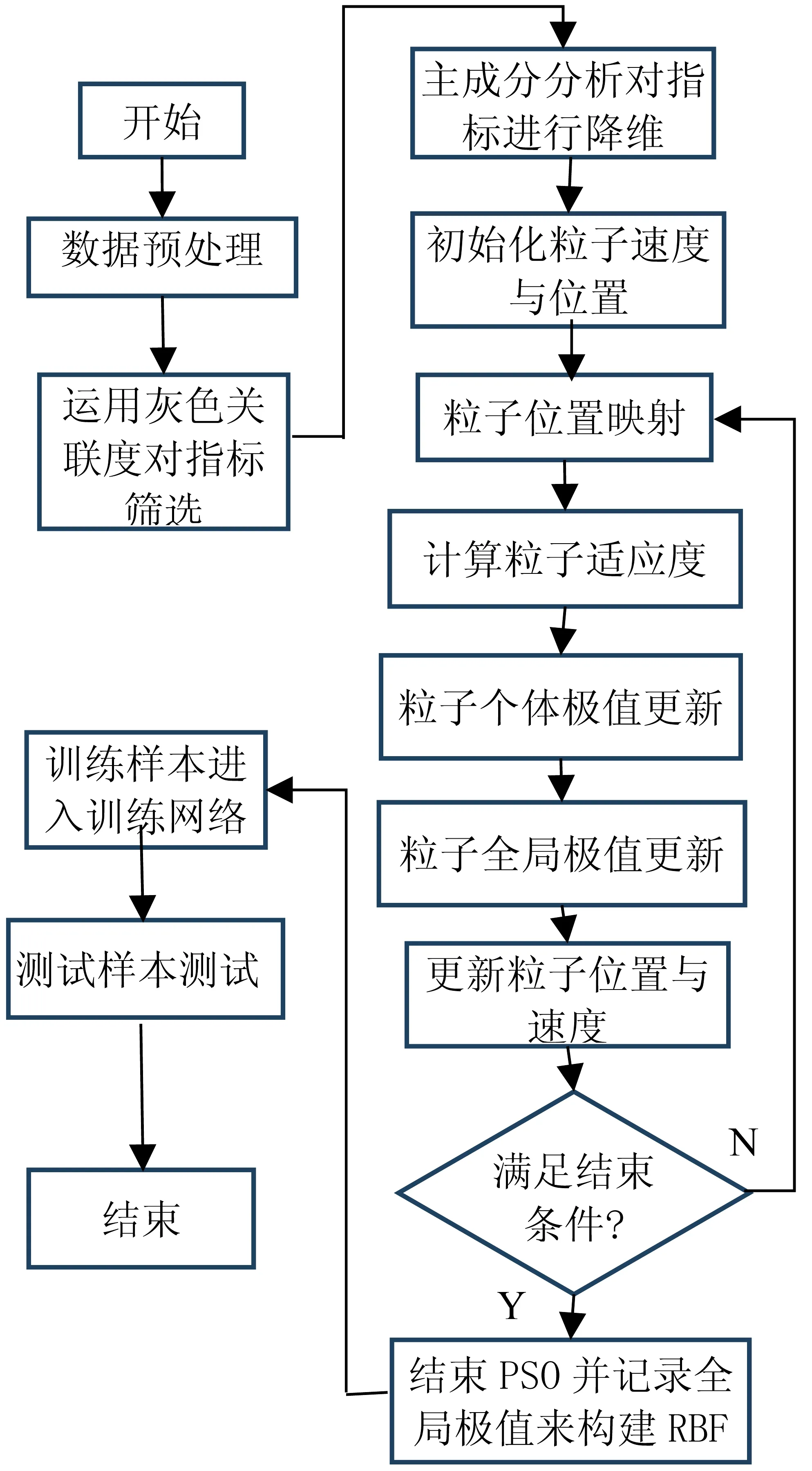
图2 算法模型流程图Fig.2 Algorithm model flowchart
2 实证分析
2.1 数据来源
在预测前对2000~2021年间水产相关数据进行收集整理,直接引用与间接计算数据来自《中国渔业统计年鉴》《中国统计年鉴》《福建统计年鉴》等,查阅已有文献并在实际生产中选取水产品冷链物流需求影响因素。本文将居民对水产品的人均消费量乘以年末人口数作为水产品冷链物流需求量,构建预测模型进行分析研究。
2.2 影响因素选择
2.2.1 经济因素
随着地区经济发展与居民消费升级,水产品冷链品质有了更高要求,使地区水产品冷链物流需求增加,刺激了该地区经济发展与居民收入。且与第一产业经济增长紧密相关。水产冷链物流产业隶属于第三产业,第三产业发展占比及物流时效性与服务水平相互促进、融合。故选取的经济因素指标有福建省人均地区GDP、第一产业增加值、第三产业结构总值比例、城镇与农村人均可支配收入。
2.2.2 人文因素
地区人口越多意味着潜在水产品消费群体越多,与之对应的水产品需求量就越高,水产品冷链物流包含交通运输、存储、物流信息传输等方面,其发展离不开第三产业从业人员。货运量和货运周转量是衡量水产品周转效率的重要指标。故选取指标有货运量、常住人口数量、货运周转量、第三产业从业人员。
2.2.3 冷链因素
冷库数量是反映冷链基础设施建设水平重要指标,选取指标有冷库数量、制冰能力、冻结能力、冷藏能力、水产品加工能力和水产品冷链物流流通率。
水产品冷链物流流通率=
100%
2.2.4 供给因素
水产品的产量供给影响着水产品需求量,同时影响着相应的配套运输服务,其中港口货物运输是水产品由海到内陆不可或缺的环节,同时消费者需求与购买力都随水产品类消费价格指数下降而上升;反之下降。作为水产品消费主体的居民,其消费支出与冷链物流密不可分。故选取指标有港口货物吞吐量、水产品产量、水产品类居民消费价格指数。
3 预测模型构建
3.1 数据预处理
由于指标间数量级不同,在网络学习中易产生误差,为消除量纲影响,进行归一化处理,xi为原始数据x标准化处理至[0,1]间的值,转换公式为:
(11)
3.2 灰色关联度分析
基于预处理数据,将所选取的18个指标标记并进行灰色关联分析,人均地区GDP为X1、城镇居民人均可支配收入为X2、农村居民人均可支配收入为X3、第一产业增加值为X4、第三产业结构总值比例为X5、福建省常住总人口为X6、货运量为X7、货运周转量为X8、水产品总产量为X9、沿海港口货物吞吐量为X10、冷库数量为X11、冻结能力为X12、冷藏能力为X13、制冰能力为X14、水产品加工能力为X15、水产品类居民消费价格指数为X16、水产品冷链物流流通率为X17、第三产业从业人员为X18。分析结果如表1所示,本文所选18个因素中17个指标与水产品冷链物流需求量之间存在强相关性,另一指标冻结能力与水产品冷链物流需求量存在较强相关性,对影响因素指标进行排序:X18>X16>X9>X14>X17>X11>X4>X6>X5>X10>X13>X7>X2>X3>X15>X1>X8>X12。

表1 灰色关联度分析Tab.1 Gray correlation analysis
3.3 主成分分析(PCA)
由表2可知,18个指标皆适用于水产品冷链物流需求预测,但为使研究的指标重要特征突显,降低数据空间维数,以捕获内在模式与结构,拟采用PCA对构建的影响因素指标数据进行分析,在此之前,进行KMO检验和巴特利特球形度检验,经检验其 df自由度为153,巴特利特球形度检验的显著性为0,小于0.05,说明适用于做主成分分析。再通过主成分因子分析,提取两个特征根大于1公因子,其特征根分别为16.479和1.003。累计方差分别达到91.552%和97.123%,大于指标80%,证明该主成分分析成立,可进行成分矩阵分析。将第一、第二主成分作为基础成分替代原有数据,经过主成分分析后得到各主成分得分系数,将第一与第二主成分值作为PCA-PSO-RBF、PCA-PSO-BP、PCA-RBF、PCA-BP预测模型输入量。

表2 不同预测模型的统计误差Tab.2 Statistical errors of different forecasting models
3.4 PCA-PSO-RBF预测模型
在MATLAB环境下,构建PCA-PSO-RBF模型进行水产品冷链物流需求预测研究。其中,PSO优化RBF神经网络原理是把参数映射为PSO的粒子目标,根据 PSO寻优能力找最优解,寻找到最优解后再回到RBF神经网络实现网络模型的构建,在寻优过程中,将均方误差最小作为模型的适应度函数,其算法调用公式为式(12)(13):
rbf spread = Best_pos
(12)
net = newrbe(p_train, t_train, rbf_spread)
(13)
式中,rbf spread为径向基函数扩展速度; net是创建好的RBF神经网;newrbe为径向基函数;p train是网络输入变量;t train是网络输出变量。文中以2000年至2020年水产品冷链物流需求量作为训练样本输入到PSO-RBF神经网络进行模拟仿真,再将已经训练好的神经网络模型对2003年至2021年的水产品冷链物流需求进行仿真预测,分别构建出SVM、BP、PCA-BP、PCA-RBF、PCA-PSO-BP、PCA-PSO-RBF神经网络算法模型,并依次绘制预测曲线图(图3),其编号分别为(a)(b)(c)(d)(e)(f),其中SVM、BP模型输入为具有18个特征的数据集,其不同神经网络模型预测结果如图3。

图3 不同神经网络模型预测图Fig.3 Predictive plots of different neural network models
3.5 PCA-PSO-BP预测模型
BP神经网络是多层前馈神经网络,基于误差反向传播进行训练,获取输出值后可反向传播,来不断调整权值,直到达到设定值后停止迭代,输出最终结果。在 MATLAB环境下,用PSO算法进行优化的PCA-PSO-BP预测模型与PCA-BP、传统BP预测模型对比实验,当其迭代次数为100次,学习效率为0.01,误差阈值为10-6,其预测误差最小。
3.6 支持向量机(SVM)预测模型
支持向量机预测模型在结构风险最小前提下,对未来样本预测有比较好的推广性,目的是将各个水产品冷链物流影响因素输入量映射到高维特征空间,把非线性模型转化为特征空间线性回归模型,经实验,惩罚因子取100,径向基函数参数取0.04时,误差最小。
3.7 实验结果分析
依据6种预测模型的预测结果,绘制出真实曲线与预测曲线的对比图3,在对比图中, PCA-PSO-RBF模型预测曲线与真实曲线基本重合,效果最好,在2014年存在少量偏差;PCA-PSO-BP模型的预测效果较好,在2009年、2010年存在较大偏差;PCA-RBF模型预测中在2021年存在较大偏差;在PCA-BP模型预测中2007年至2009年、2013年、2018年处在较大偏差;SVM模型预测中2013年预测偏差大,其余年份拟合效果较好;BP神经网络模型2003年至2008年、2019年预测偏差较大,2013年预测偏差大,其他年份偏差较小。为更直观对比各预测模型对水产品冷链物流需求预测精度,绘制出残差值柱状图4。

图4 残差值柱状图Fig.4 Histogram of residual values
预测模型的精度,常用残差平均值(MAE)、均方根误差(RMSE)、相对误差平均值(MAPE)3类重要指标。
(14)
(15)
(16)

由表2可知,相比于其他预测模型,传统的单一BP模型在衡量精度指标MAE 、RMSE、MAPE中表现最差,预测精度最低;而 PCA -BP预测模型相较BP模型,其MAE 、RMSE、MAPE分别降低了31.27%、43.23%、37.9%;SVM虽为单一模型,但较适用于解决小样本情况下的机器学习问题和高维问题,拟合效果较好,较PCA -BP预测模型MAE 、RMSE、MAPE分别降低了38.67%、0.97%、36.31%;具有较强非线性拟合能力的PCA-RBF预测模型,可较好避免针对高纬度小样本的过拟合问题,相比于SVM模型的RMSE降低了34.5%,其他指标稍高于SVM模型;在加入粒子群算法参数寻优中,通过对比 PCA-PSO-BP、PCA-PSO-RBF与其他模型得出,PCA-PSO-BP预测模型相比于 PCA-BP、PCA-RBF、 SVM 、BP神经网络模型的MAE 、RMSE、MAPE皆有降低,而PCA-PSO-RBF预测模型相比于PCA-PSO-BP预测模型的MAE 、RMSE、MAPE依次降低了27.23%、33.1%、32.77%,说明改进后的PCA-PSO-RBF预测模型预测精度有较高提升,进一步验证了其模型的可行性。
4 结论
1) 福建省水产品冷链物流需求的影响因素前5名包括:第三产业从业人员数量、水产品类居民消费价格指数、水产品总产量、制冰能力以及水产品冷链物流流通率,关联度依次为0.944 1、0.931 4、0.896 3、0.870 7、0.864 7。表明福建省第三产业从业人员数量、水产品类居民消费价格指数对水产品冷链物流需求影响很大,继续增加水产品总生产量和提升冷库制冰能力是拉动居民水产品冷链物流内需的重要方法,水产品冷链物流的流通率仍为制约水产品冷链物流需求的关键指标。
2)在实验过程中,PSO-RBF不仅发挥出处理非线性系统问题能力强的优点,在考虑尽可能多的关键因素下可防止信息重叠并提取主要影响成分,且增强了全局搜索和跳出局部最优的能力,可为相关决策者提供更具价值的信息,为具有多特征小样本特点数据样本的研究提供了普适性更强的方法。
3)仿真结果表明,PCA-PSO-RBF预测模型的MAE 、RMSE、MAPE皆为最小,具有最好的预测精准度。SVM虽为单一模型,但其预测精度与PCA-RBF预测模型同样都高于PCA-BP 与BP预测模型。
