基于Transformer的多标签工业故障诊断方法研究
2023-10-10火久元李超杰于春潇
火久元, 李超杰, 于春潇
(1. 兰州交通大学 电子与信息工程学院,兰州 730070; 2. 国家冰川冻土沙漠科学数据中心,兰州 730000;3. 兰州瑞智元信息技术有限责任公司,兰州 730070)
随着现代化工业的发展,工业设备能否安全可靠的以最佳状态运行,对于保证产品质量、保障生产安全、提高企业生产力都具有十分重要的意义。机械设备是现代化工业生产的物质基础,设备管理是企业管理中的重要领域,如何有效的提高设备运行的可靠性,及时发现和预测出故障是加强设备管理的重要环节。传统的基于“时间”的计划维修、基于“事件”(故障)的事后维修等方式已无法满足现代化工业的需求。故障诊断是一种基于“状态”(数据)的预防性维修方式,通过信号处理、统计分析、趋势分析等方法确定设备发生的故障类型,有效解决了僵化的计划维修以及被动的事后维修所存在的“过度维修”和“维修不足”等问题,在工业生产设备管理中占有重要地位[1]。
国内外学者针对不同的研究对象(如航空发动机、风电机组、直升飞机、高速铁路等重大装备及其关键部件如轴承、齿轮箱、电机等)在故障诊断问题上做了大量的工作。故障诊断的主要方法包括:物理模型方法和数据驱动方法[2]。传统的物理模型方法主要基于失效机理、退化模式等研究故障状态下动力学参数与故障模式的内在联系,该方法一般适应于单个组件或单个故障模式下的设备[3]。针对复杂设备,由于它们的失效机理复杂、故障模式多样,构建其物理模型进行故障诊断往往比较困难,所以通常采用数据驱动方法。
数据驱动方法通过监测信号或历史数据直接训练模型进行故障诊断,该方法无需大量的领域专家知识和知识的表达推理机制。数据驱动方法主要包括统计方法、机器学习方法、深度学习方法等。针对海量、高维、复杂的工业数据,统计方法无法挖掘出隐藏的内部特征。逻辑回归(logistic regression,LR)、梯度提升树、随机森林(random forest,RF)等传统的机器学习方法[4]学习能力弱、特征提取与模型建立孤立进行,无法挖掘出特征与标签之间复杂的映射关系。近几年来,由于大数据和人工智能的迅速发展,深度学习凭借其强大的建模与数据处理能力在工业设备故障诊断上得到了工业和学术界广泛的关注。其中,以卷积神经网络(convolutional neural network,CNN)[5]、循环神经网络[6-7]以及卷积神经网络和循环神经网络的组合模型[8]在故障诊断上应用的最多,但上述模型无法挖掘出标签与标签之间复杂的映射关系。
此外,工业故障数据通常具有极端的类不均衡性,应对这一问题的主要方法包括:数据级方法和算法级方法。数据级方法通过采样策略改变不均衡数据中不同类别故障样本的数量和分布,如欠采样和过采样方法可以平衡多数类和少数类之间的数量和分布[9];随机欠采样和随机过采样是两种常见的方法[10],但随机欠采样会丢失过多的信息,而随机过采样会产生过多的冗余信息;合成少数类过采样方法(synthetic minority oversamping technique,SMOTE)采用K近邻方法在少数类样本附近生成新样本,但生成的新样本可能更接近多数类样本[11]。算法级方法通过调整分类器以适应故障类不均衡的数据,成本敏感方法可以修改分类器训练的成本,从而使分类器更关注少数类[12],但会改变训练损失的范围影响训练的稳定性,因此本文仅对数据级方法进行研究。
工业故障数据的多维性、类不均衡性和并发性为工业故障诊断带来了三大挑战[13]。现有研究大多集中在单标签识别问题,在多标签识别问题中不同故障标签之间愈发表现为耦合性、不确定性、并发性,且故障样本和故障标签之间也表现为更加复杂的映射关系。因此,为了应对这些挑战,本文提出了一种基于多重自注意力机制改进的Transformer多标签故障诊断方法,通过自适应合成采样(adaptive synthetic sampling,ADASYN)和Borderline-SMOTE1组合过采样方法改善多维工业故障数据严重的类不均衡现象,充分利用编码器-解码器结构以及注意力机制的优势,深入挖掘多维传感器数据与多个故障标签之间的复杂映射关系。
1 理论基础
1.1 数据采样
1.1.1 ADASYN
ADASYN方法根据样本分布情况为不同的少数类样本生成不同数量的新样本[14]。ADASYN生成少数类样本的步骤如下:
步骤1根据少数类样本和多数类样本之间的差值计算少数类样本需要合成的数量G。
步骤2根据K近邻算法计算样本权重(K近邻中多数类占比),并根据样本权重计算每个少数类样本需要生成的新样本数量gi。
步骤3根据SMOTE算法依次生成gi个新的少数类样本。
1.1.2 Borderline-SMOTE1
Borderline-SMOTE1是基于SMOTE改进的过采样方法,该方法仅使用边界上的少数类样本生成新样本[15]。Borderline-SMOTE1生成少数类样本的步骤如下:
步骤1根据每个少数类样本的K近邻中属于少数类的样本数量将少数类样本划分为安全样本、噪声样本和危险样本。
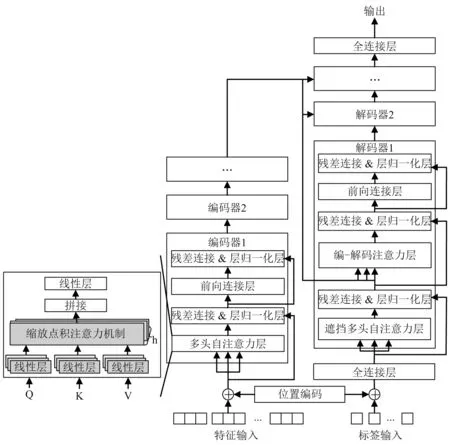
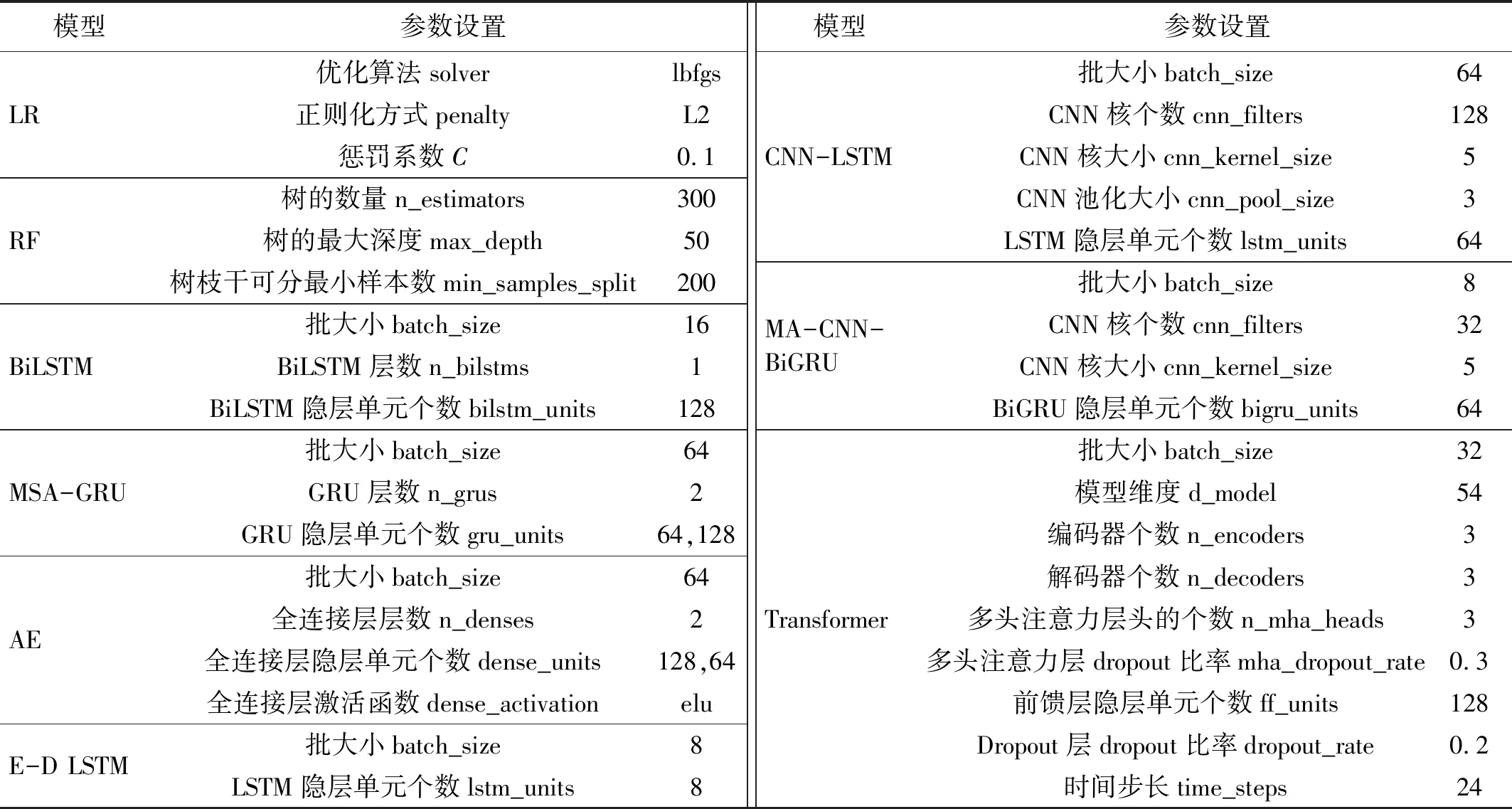
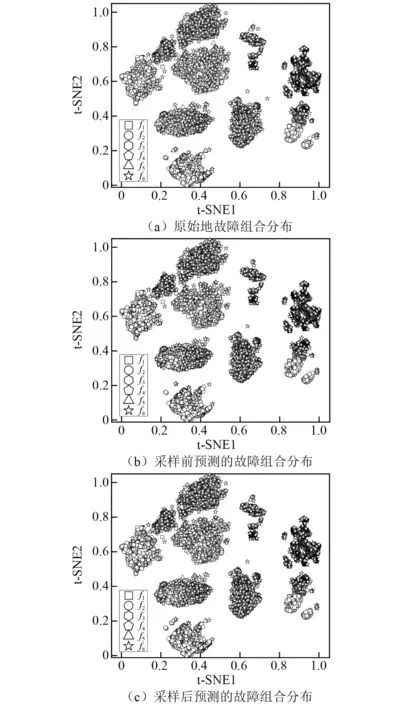
步骤2根据每个危险样本(危险样本是指超过一半的K近邻样本属于多数类)从K近邻中随机选取的s(0 Transformer是一种基于注意力机制的编码器-解码器结构的网络模型[16]。如图1所示,Transformer网络模型主要由多个编码器和解码器堆叠而成,其中,编码器主要用于将输入特征序列编码为中间向量;解码器主要用于将编码器编码的中间向量解码为输出标签序列。 图1 Transformer网络架构Fig.1 Transformer network architecture 1.2.1 编码器 编码器由位置编码层、多头自注意力层、前馈神经网络层和残差&层归一化层组成。编码器的核心是多头自注意力机制,主要用于为输入特征序列分配注意力(即权重),使模型更加关注输入特征序列中的重要信息;前馈神经网络层主要用于将多头自注意力层的输出转换到非线性空间;此外,在多头自注意力层和前馈神经网络层后加入残差&层归一化层,解决网络深度过深导致的梯度消失等问题,并加快网络收敛速度,提升网络泛化能力。编码器的主要组件介绍如下。 (1) 位置编码 Transformer网络的核心是注意力机制,但注意力机制无法学习序列位置信息,所以通过位置编码加入序列位置信息。位置编码通过sin和cos函数对输入特征样本的偶数维度和奇数维度交替进行编码,如式(1)、式(2)所示 (1) (2) 式中:pos为输入特征样本的位置;i为输入特征的维度; 2i和2i+1为偶数和奇数维度;dmodel为位置编码的维数,即输入特征的维数。 (2) 多头自注意力机制 自注意力机制是注意力机制的变体,减少了对外部信息的依赖,更擅长捕获输入特征序列内部的相关性,通过计算输入特征序列间的相似性分配权重,以表征信息的重要程度。本文使用的是缩放点积自注意力机制,首先输入特征序列X乘以3个不同的权重矩阵得到查询矩阵Q、键矩阵K、值矩阵V,然后使用查询矩阵Q对键矩阵K进行点积与Softmax归一化计算注意力权重,最后根据注意力权重对值矩阵V加权求和得到输出特征序列,如式(3)~式(6)所示 Q=XWq (3) K=XWk (4) V=XWv (5) (6) 式中,Wq,Wk,Wv分别为Q,K,V对应的权重矩阵。 相较于单一的自注意力机制,多头自注意力机制提供了多个“表示子空间”,扩展了模型关注不同位置的能力。多头自注意力机制是多个自注意力机制的拼接和线性变化,如式(7)~式(8)所示 Multi-Head(Q,K,V)=Concat(H1,H2,…,Hn)W (7) Hi=Self-Attention(XWQi,XWKi,XWVi) (8) 式中:Hi(i∈{1,2,…,n})为第i个自注意力头;n为自注意力头的个数; Concat函数为拼接多个自注意力头的输出;W为多头自注意力权重矩阵;WQi,WKi,WVi为第i个自注意力头的Q,K,V权重矩阵。 1.2.2 解码器 解码器由位置编码层、遮挡多头自注意力层、编-解码器多头注意力层、前馈神经网络层、和残差&层归一化层组成。解码器的核心是遮挡多头自注意力机制和编-解码器多头注意力机制,遮挡多头自注意力机制用于为输入标签序列分配注意力(即权重),使模型更加关注输入标签序列中的重要信息;然后通过编-解码器多头注意力机制学习编码器输出的中间向量和输入标签序列的依赖关系。解码器的主要组件介绍如下。 (1) 遮挡多头自注意力机制 相较于多头自注意力机制,遮挡多头自注意力机制在多头自注意力机制中加入了遮挡操作,为了防止每个时间步学习到未来的标签序列信息。遮挡操作是指在计算缩放点积自注意力时引入一个下三角单位矩阵M(主对角线上方元素全为0,主对角线及主对角线下方元素全为1)和QKT相乘,使得未来的标签序列信息清零,如式(9)所示 (9) (2) 编-解码器多头注意力机制 相较于多头自注意力机制,编-解码器多头注意力机制的查询矩阵Q来自遮挡多头自注意力层,表示标签序列信息,记为QD;键矩阵K和值矩阵V来自编码器输出的中间向量,表示特征序列信息,分别记为KE和VE,式(10)所示 (10) 本文提出了一种基于多重自注意力机制改进的Transformer多标签故障诊断模型,并在PHM2015 Plant数据集上进行了训练、验证、测试。如图2所示,多标签故障诊断流程主要由5个步骤组成: ①特征工程,将多维传感器数据按采样时间对齐后,再根据采样时间合并组件的传感器数据,并加入季节、月份、周、天、小时以及分钟数等周期变量;②数据采样,根据故障样本的不均衡率采用ADASYN和Borderline-SMOTE1组合策略进行数据过采样;③故障检测,基于Transformer-N网络模型进行故障检测,若未发生故障则直接结束,否则执行步骤④,其中,Transformer-N包括1个Transformer网络模型,用于检测是否发生了故障;④故障诊断,若发生了故障,则基于Transformer-Fn(n∈{1,2,3,4,5,6})网络模型进行故障诊断,其中,Transformer-Fn包括6个Transformer网络模型,用于分别诊断是否发生了故障f1~f6,然后根据时间生成多标签故障序列(如,故障序列[0,1,1,0,0,1]表示同时发生了故障f2,f3,f6);⑤结果与评估,最后根据Precision,Recall,F1-score,Jaccard index以及Hamming loss评价指标对Transformer-Fn模型的整体预测性能进行评估。 图2 基于Transformer的多标签故障诊断流程Fig.2 Multi-label fault diagnosis process based on Transformer ADASYN算法易受离群点的影响,若某个少数类样本的K近邻都是多数类样本,则易在其周围产生过多单一的少数类样本。而Borderline-SMOTE1算法在产生少数类样本时,从每个危险样本的K近邻中随机选择要生成的少数类样本数量,无法对边界上要产生的少数类样本数量进行合理评估。所以本文对ADASYN和Borderline-SMOTE1算法进行融合,提出了一种ADASYN和Borderline-SMOTE1组合过采样策略,自适应地在分类边界上合成新的少数类样本,如图3所示。流程如下。 图3 ADASYN和Borderline-SMOTE1组合过采样Fig.3 Combined oversampling of ADASYN and Borderline-SMOTE1 (1) 计算少数类要生成的样本数量G,如式(11)所示。 G=(Nmaj-Nmin)×β (11) 式中:Nmaj和Nmin为多数类和少数类样本数量;β∈(0,1]为采样后的多数类与少数类比例。 ri=Δi/K (12) (13) 式中, Δi为K近邻中多数类样本数。 (4) 计算每个危险样本x′>i需要生成的新样本个数gi,如式(14)所示。 (14) (5) 根据SMOTE算法从危险样本x′>i的K个近邻中随机选取少数类样本依次生成gi个少数类样本,如式(15)所示。 si=x′i+(x′iK-x′i)×λ (15) 式中:si为合成的少数类样本;x′>iK为从危险样本x′>i的K个近邻中随机选取的少数类样本;λ∈[0,1]为一个随机数。 Transformer模型在自然语言处理等领域取得了巨大的成功,但其独特的结构限制了在故障诊断领域的应用,因此针对多标签故障诊断问题对其核心的自注意力机制和结构进行改进。本文提出了一种基于多重自注意力机制改进的Transformer模型,充分利用编码器-解码器结构以及自注意力机制的优势,深入挖掘多维传感器数据与多个故障标签之间的复杂映射关系。 传统的Transformer模型仅关注输入序列中不同时间步长的注意力(即权重),但忽略了输入序列中不同传感器的重要性。所以本文提出了一种多重自注意力机制改进的Transformer模型,在Transformer模型的编码器中加入多重自注意力机制,以提取输入特征序列中不同时间步长和不同传感器中的重要特征。 多重自注意力机制如图4所示,首先输入时间步长特征序列,经过多头的时间步长自注意力得到加权的时间步长特征序列;然后对加权的时间步长特征序列进行转置得到传感器特征序列;最后经过多头的传感器自注意力得到加权的传感器特征序列。所以多重自注意力机制不仅可以提取不同时间步长中的重要特征,还可以提取不同传感器中的重要特征,如式(16)~式(18)所示。 图4 多重自注意力机制Fig.4 Multiple self-attention mechanism (16) (WtVt)T=Qs=Ks=Vs (17) (18) 式中:Qt,Kt,Vt,Wt为时间步长特征的查询、键、值、权重矩阵;Qs,Ks,Vs,Ws为传感器特征的查询、键、值、权重矩阵。 在解码器中,由于多标签故障诊断的输入特征序列和输入标签序列维度不一致导致编-解码器多头注意力层无法计算,所以在解码器输入端加入一个全连接层提升输入标签序列的维度和输入特征序列保持一致;同理,在解码器输出端加入一个全连接层降低输出标签序列的维度和原始的输入标签序列保持一致。 本文使用PHM Society在PHM 2015数据挑战赛中提供的Plant数据集对所提出的模型进行训练、验证和测试。该数据集是脱敏后的真实工厂数据,包括6种故障事件以及正常事件,大约33个plant的数据,数据采集的时间跨度约为3~4 a,采样间隔约为15 min。每个plant包括3个文件:①每个组件的传感器数据和控制参考信号数据;②工厂内每个区域的累计能耗和瞬时功率;③每个故障的开始时间和结束时间。其中,每个plant包含多个区域,每个区域包含多个组件,且每个plant的区域数量和组件数量都不相同。该数据挑战赛的目标是预测故障f1~f5(f6为其他故障)以及它们的起止时间,本文仅预测故障f1~f6而不考虑它们的起止时间,这可以表述为一个类不均衡的多标签分类问题。 本文将特征序列X和标签序列E以6∶4的比例划分为训练集和测试集,然后再将训练集以9∶1的比例划分为训练集和验证集。如图5(a)所示,在工厂plant_1中正常样本和故障样本的数量分别为78 710和34 466,占样本总量的69.55%和30.45%。各类故障样本数量对比,如图5(b)所示。plant_1中各类故障的样本数量及所占比例,如表1所示。由图5(b)和表1可知:在故障样本中故障f1~f6存在严重的类不均衡现象,其中,故障f6的样本数量为21 463,占故障样本总量的62.27%,样本数量远超过其他类型的故障;而故障f4和f5的样本数量分别为597和784,仅占故障样本总量的1.73%和2.27%,样本数量远低于其他类型的故障。 表1 plant_1中各类故障的样本数量及所占比例 图5 plant_1中正常样本和各类故障样本数量对比Fig.5 Number comparison of normal samples and various fault samples in plant_1 此外,在所有的故障样本中,多个类型的故障同时发生的样本数量为3 876,占故障样本总量的11.25%。其中,多个类型的故障同时发生的组合高达28种,每个组合中可能同时发生2~4种故障。如图6所示,以样本数量最多的前10种故障组合为例进行分析,同时发生2种故障的组合及其样本数量最多,故障f2,f3经常和其他故障一起发生,且故障f2和f6一起发生的样本数量最多。 图6 plant_1中故障样本数量最多的前10种故障组合Fig.6 Top 10 fault combinations with largest number of fault samples in plant_1 本文主要使用plant_1的①文件和③文件,即plant_1a.csv和plant_1c.csv,如表2所示。其中,plant_1包括6个组件,每个组件包括4个传感器、4个控制参考信号以及6种故障标签。 表2 plant_1中①文件和③文件介绍Tab.2 Introduction of ① and ③ files in plant_1 3.2.1 特征工程 plant_1a.csv即原始数据Xraw是由多个传感器采集的带时间戳的多维时间序列,由于传感器日志记录延迟导致采样间隔在15 min左右浮动,所以首先在Xraw中以15 min的采样间隔对齐所有样本的时间戳ti;然后删除在相同时间戳ti上重复的组件记录,若某个组件记录缺失则按时间戳ti先前向插补再后向插补缺失的组件记录;然后在时间戳ti上根据组件编号cid合并6个组件的传感器数据s1~s4以及控制参考信号r1~r4添加到特征序列X;然后由于故障事件存在周期性,所以从时间戳ti中提取季节、月份、周、天、小时以及分钟数(当年1月1日0时0分到当前的分钟数)特征添加到X;最后,根据plant_1c.csv即Eraw中每个故障标签对应的开始时间st和结束时间et生成X对应的one-hot故障标签序列。 3.2.2 数据过采样 在划分数据集后训练集中故障f1~f6的类不均衡现象更加严重,如表3所示。其中,故障f4和f5的样本数量仅为243和53,仅占训练集样本总量的1.31%和0.28%,样本数量远低于其他类型的故障。 表3 plant_1训练集中各类故障的样本数量及所占比例 故障样本的极端类不均衡性严重限制故障诊断分类器的性能,若不考虑故障样本的类不均衡性,则故障诊断分类器的预测结果更倾向于多数类故障而忽略了少数类故障,但在故障诊断时往往更关注少数类故障,所以本文提出了ADASYN和Borderline-SMOTE1组合过采样策略。为了防止数据泄露,本文仅对训练集进行采样,训练集中故障样本不均衡率(多数类和少数类故障样本数量的比率,本文是指采样前在训练集中其他类和当前类故障样本数量的比率)大于20且小于100时过采样率(少数类和多数类故障样本数量的比率,本文是指采样后在训练集中当前类和其他类故障样本数量的比率)设置为0.25,如故障f4;故障样本不均衡率大于100时过采样率设置为0.2,如故障f5。 4.1.1 试验环境 本文的试验环境:CPU是Intel Core i5 9300H,CPU核心数为4,逻辑处理器为8;GPU为NVIDIA GeForce GTX 1650with Max-Q Design(4096MB)。开发环境:Python3.8、scikit-learn1.0.2以及Tensorflow2.8.0等。训练参数:训练的最大迭代次数为500,当验证集损失连续20次不再下降时停止训练,实际训练的迭代次数在25~131,且主要集中在50左右;损失函数为BinaryCrossentropy;优化器为Adam,初始学习率设置为0.001,当验证集损失连续5次不再下降时学习率减少到一半,最小学习率为0.000 1,实际训练的学习率几乎都降到了0.000 1;分类层激活函数为sigmoid。 4.1.2 评价指标 针对多标签故障诊断问题,由于故障样本存在严重的类不均衡现象,所以使用微平均和宏平均Precision,Recall和F1-score分别从故障样本上和故障类别上评估多标签故障诊断模型的性能。micro和macro Precision,Recall和F1-score如式(19)~式(24)所示。 (19) (20) (21) (22) (23) (24) 式中:n∈{1,2,3,4,5,6}为故障类型;q=6为故障类型的个数;tpn为第n类故障被正确预测的样本个数;fpn为其他类型故障被错误预测为第n类故障的样本个数;fnn为第n类故障被错误预测为其他类型故障的样本个数。 Jaccard index主要用于计算真实标签序列集合和预测标签序列集合之间的相似程度[17],Jaccard index越高,真实标签序列集合和预测标签序列集合之间的相似程度越高。micro和macro Jaccard index如式(25)~式(26)所示。 (25) (26) Hamming loss主要用于计算真实标签序列集合和预测标签序列集合之间的不一致程度[18],Hamming Loss越低,真实标签序列集合和预测标签序列集合之间的不一致程度越低。Hamming Loss如式(27)所示。 (27) 为了验证本文提出方法的效果,本文将与以下8个模型在工厂plant_1数据集上进行比较,它们的超参数设置如表4所示。表4中的所有模型均经过Hyperband[19]超参数搜索算法得到最佳参数设置,该算法限定了资源(如时间、计算资源等)总量,通过连续减半[20]算法和早停策略分配资源,该算法不仅能够尽可能多的搜索到所有超参数组合,而且能够更快的找到最佳的超参数设置。Hyperband算法在搜索的过程中通过连续减半算法筛选出评价排名前一半的超参数组合进入下一轮筛选,每轮通过早停策略停止搜索评价不好的超参数组合,动态分配资源总量,直至搜索到最佳的超参数组合。此外,本文所提方法和以下8个模型使用相同的输入特征、采样策略、标准化方式以及训练参数等,且均训练1个*-N模型用于故障检测,以及6个*-Fn(n∈{1,2,3,4,5,6})模型用于故障诊断,最后按照时间生成多标签故障序列进行评估。 表4 Transformer及其他对比模型的超参数设置Tab.4 Hyperparameter setting of Transformer and other comparison models (1) LR模型:该模型输入特征数量较大时,该模型容易出现过拟合,严重影响分类性能,使用带L2惩罚的逻辑回归模型,以避免过拟合并提高预测性能。 (2) RF模型:该模型基于bagging和随机特征选择技术,每次构建决策树时随机选择部分特征,最后平均所有决策树的预测结果。 (3) 双向的长短期记忆网络(long short-term memory,LSTM),简称BiLSTM,该模型主要由前向LSTM和后向LSTM组成。其中,后向LSTM通过复制前向LSTM的结构以及输入序列的反向副本,以更好的捕获双向的时间序列依赖关系。 (4) 基于多头自注意力机制的门控循环单元网络(gated recurrent unit,GRU),简称MSA-GRU,该模型主要由2个GRU层组成。其中,在GRU层之前加入多头自注意力机制以提供多个表示子空间,使GRU模型在不同位置上关注到来自不同表示子空间的特征信息。 (5) CNN-LSTM:该模型主要由1D卷积层、1D池化层和LSTM层组成。其中,1D卷积层用于空间特征提取,1D池化层用于特征降维,LSTM层用于学习时间特征,通过编码空间、时间特征,以更好地应对时间序列分类问题。 (6) MA-CNN-BiGRU[21]:该模型是基于多重注意力机制的CNN-BiGRU模型。该模型主要由CNN和BiGRU组成。其中,在CNN层后加入通道注意力和空间注意力机制,在BiGRU层后加入序列注意力机制,加强关键信息提取能力,以解决BiGRU对于过长序列数据处理困难、无法保留全部关键信息的问题。 (7) 自动编码机(autoencoder,AE):该模型是一个编码器-解码器结构的网络,编码器和解码器中分别包含2个全连接层。其中,编码器将输入序列编码为低维的内部表示,解码器将低维的内部表示恢复为输入序列,该模型通过正常样本训练模型,使用重构误差均方误差(mean square error,MSE)作为阈值检测故障。本文尝试通过某个类别的故障数据训练模型,使用重构误差MSE检测是否发生该故障,从而进行故障诊断。 (8) Encoder-Decoder LSTM,简称E-D LSTM,该模型是一个编码器-解码器结构的LSTM网络,编码器和解码器中分别包含1个LSTM层,其中,编码器对输入特征序列编码得到一个内部隐藏状态,解码器以该内部隐藏状态为初始状态对输入标签序列解码得到最终的输出标签序列(注:输出标签序列是由输入标签序列向右偏移一个时间步得到的)。 4.3.1 故障检测试验 故障诊断之前最重要的环节是故障检测,故障检测是指检测指定时刻是否发生故障,精准的故障检测可以尽可能的减少甚至避免正常样本进入故障诊断环节导致故障诊断模型将正常样本误分类为某个类型的故障样本。本文将提出的Transformer-N模型与其他8个*-N模型在工厂plant_1数据集上进行比较,评价指标包括micro和macro Precision,Recall,F1-score,故障检测模型*-N的评价指标及其对比曲线如表5和图7所示。 表5 不同故障检测模型*-N的评价指标 图7 不同故障检测模型*-N的评价指标对比Fig.7 Comparison of evaluation metrics of different fault detection models *-N 由表5和图7可知,LR-N模型的故障检测效果最差,micro Precision,Recall,F1-score均不超过68.56%,macro Precision,Recall,F1-score均不超过57.25%。Transformer-N模型的故障检测效果最好,micro Precision,Recall,F1-score均超过96.17%,macro Precision,Recall,F1-score均超过95.15%;与最差的LR-N模型相比,micro Precision,Recall,F1-score提升均超过27.61%,macro Precision,Recall,F1-score提升均超过37.9%;与次之的E-D LSTM-N模型相比,micro Precision,Recall,F1-score提升均超过5.94%,macro Precision,Recall,F1-score提升均超过7.01%。此外,其他模型的micro Precision,Recall,F1-score均在72.47%~75.21%,macro Precision,Recall,F1-score大多不超过62.65%,远低于本文提出的Transformer-N故障检测模型。 4.3.2 多标签故障诊断试验 多标签故障诊断是指确定指定时刻发生的一个或多个故障,及时、有效的故障诊断可以减少维护人员的工作量,降低维护成本,防止重大工业事故。本文将提出的Transformer-Fn模型与其他8个*-Fn模型在工厂plant_1数据集上进行比较,评价指标包括micro和macro Precision,Recall,F1-score,Jaccard index以及Hamming loss,采样前和采样后故障诊断结果的评价指标如表6所示。由表6可知,本文提出的Transformer-Fn多标签故障诊断模型在采样前、采样后的micro和macro Precision,Recall,F1-score,Jaccard index以及Hamming loss均优于其他8个*-Fn对比模型。在采样前: 表6 不同多标签故障诊断模型*-Fn的评价指标Tab.6 Evaluation metrics of different multi-label fault diagnosis models *-Fn 单位:% (1) 与经典的机器学习方法LR-Fn、RF-Fn相比,BiLSTM-Fn循环神经网络的各种评价指标并没有提升;而Transformer-Fn的Hamming loss降低了9.49%,其他评价指标最高提高了37.65%,这说明在类不均衡的多标签故障诊断任务中Transformer-Fn的性能远优于经典的机器学习方法和简单的循环神经网络方法。此外,在经典的机器学习方法中,集成分类器RF-Fn比线性分类器LR-Fn的Hamming loss提高了2.48%,其他评价指标最低降低了10.34%。 (2) 与循环神经网络BiLSTM-Fn相比,MSA-GRU-Fn组合神经网络的效果并不好;但CNN-LSTM-Fn组合神经网络的Hamming loss降低了0.19%,其他评价指标最高提高了9.54%,这说明通过CNN提取特征、降低维度后模型能够更好地学习故障序列间的依赖关系;而MA-CNN-BiGRU-Fn组合神经网络的Hamming loss降低了0.87%,其他评价指标最高提高了15.33%,这说明多重注意力机制能够使模型聚焦于更为重要的故障信息上。此外,从上述结论也可以看出,在类不均衡的多标签故障诊断任务中,单重自注意力机制对循环神经网络的提升没有CNN及多重自注意力机制提升的效果好。 (3) 与组合神经网络MSA-GRU-Fn、CNN-LSTM-Fn和MA-CNN-BiGRU-Fn相比,编码器-解码器结构的AE-Fn效果特别差,这说明AE-Fn通过重构误差不能从多个故障类型的样本中检测出某个类型的故障;编码器-解码器结构的E-D LSTM-Fn与效果最好的MA-CNN-BiGRU-Fn组合神经网络相比,Hamming loss降低了8.45%,micro评价指标最低提高了22.69%,macro评价指标最低提高了11.43%,这说明在类不均衡的多标签故障诊断任务中,E-D LSTM-Fn不仅能够很好的学习故障特征序列之间的依赖关系,而且能够很好的学习故障标签序列之间的依赖关系。而编码器-解码器结构的Transformer-Fn与效果最好的MA-CNN-BiGRU-Fn组合神经网络相比,Hamming loss降低了9.77%,micro评价指标最低提高了26.35%,macro评价指标最低提高了16.44%,这说明在类不均衡的多标签故障诊断任务中,Transformer-Fn的性能比组合神经网络和编码器-解码器结构的循环神经网络要好。 (4) 与编码器-解码器结构的神经网络AE-Fn和E-D LSTM-Fn相比,Transformer-Fn的Hamming loss仅为2.74%,比次之的E-D LSTM-Fn降低了1.32%;Transformer-Fn的micro Precision,Recall,F1-score均超过了90.16%,比次之的E-D LSTM-Fn最低提高了3.58%;Transformer-Fn的macro Precision,Recall,F1-score均超过了74.71%,比次之的E-D LSTM-Fn最低提高了2.65%,最高提高了5.01%;Transformer-Fn的micro和macro Jaccard index均超过了70.16%,比次之的E-D LSTM-Fn最低提高了6.06%。这说明在类不均衡的多标签故障诊断任务中,Transformer-Fn凭借其独特的编码器-解码器结构以及改进后的多重自注意力机制,能够深入的挖掘故障特征序列与故障特征序列、故障标签序列与故障标签序列以及故障特征序列与故障标签序列之间复杂的映射关系。但Transformer-Fn的micro和macro Precision,Recall,F1-score,Jaccard index最高相差17.85%,这也说明故障类别之间的数据不均衡现象对Transformer-Fn模型的性能有很大的影响。 如图8所示,柱状图表示不同的多标签故障诊断模型*-Fn在采样前的评价指标(浅灰色区域表示采样后没有提高,深灰色区域表示采样后有所提高),柱状图上方的长横线表示不同的多标签故障诊断模型*-Fn在采样后的评价指标。由图8可知:在ADASYN和Borderline-SMOTE1组合过采样后,Transformer-Fn与其他7个*-Fn对比模型(除AE-Fn外)在micro和macro Recall,F1-score,Jaccard index上均有一定的提高,且macro比micro Recall,F1-score,Jaccard index提高的更多,但可能损失部分micro和macro Precision;此外,Hamming loss降低的很少甚至有轻微的上升。这说明在类不均衡的多标签故障诊断任务中,本文提出的ADASYN和Borderline-SMOTE1组合过采样方法虽然会生成一些噪声样本从而损失部分精度,但能够很好的改善故障数据的类不均衡现象,提高模型在样本上和类别上的整体预测性能。其中,故障诊断性能最差的MSA-GRU-Fn神经网络在采样后,macro评价指标平均提高了7.54%,且其他评价指标均有一定改善。故障诊断性能最好的Transformer-Fn神经网络在采样后,micro Precision,Recall,F1-score均超过91.04%,其中micro Precision高达94.77%;macro Precision,Recall,F1-score均接近甚至超过80.64%,其中macro Precision高达88.09%,平均提高了6.87%;micro和macro Jaccard index均超过74.6%,其中micro Jaccard index高达 86.68%;Hamming loss低至2.63%。而故障诊断性能次之的E-D LSTM-Fn神经网络在采样后,macro评价指标平均提高了4.14 %,且其他评价指标均有一定改善。 图8 不同多标签故障诊断模型*-Fn在采样前和采样后的评价指标对比Fig.8 Comparison of evaluation metrics of different multi-label fault diagnosis models *-Fn before and after sampling 为了进一步验证本文提出的ADASYN和Borderline-SMOTE1组合过采样方法,多重自注意力机制改进的Transformer-Fn模型的有效性,本文采用t-SNE算法[22]对测试集数据进行降维可视化分析,降至2维后的特征用t-SNE1和t-SNE2表示。图9中,簇表示可能同时发生的单个或多个故障组合,图9(a)、图9(b)、图9(c)用于比较Transformer-Fn模型在采样前和采样后的预测效果。如图9(a)所示,从测试集中原始的故障分布中我们可以看出,故障f1~f6存在严重的类不均衡现象,且可能同时发生1~4种故障,如故障f6经常单独发生,而故障f1和f5、f1和f6、f2和f3,以及f1,f5和f6等故障经常同时发生;如图9(b)所示,从采样前Transformer-Fn模型在测试集上的预测结果可以看出,本文提出的Transformer-Fn模型可以很好的预测出几乎所有的故障及其组合,但几乎预测不出故障f5且预测出的故障f4很少,这主要是因为训练集中故障f4和f5的样本数量太少,仅占训练集的1.31%和0.28%,导致模型学习不充分;如图9(c)所示,从采样后Transformer-Fn模型在测试集上的预测结果可以看出,经过本文提出的组合过采样方法采样后Transformer-Fn模型可以预测出接近一半的故障f5且可以预测出更多的故障f4,这主要是因为训练集中故障f5的样本数量太少,仅有53个,无法充分的表征故障f5,即使通过采样方法增加样本数量模型也无法充分学习出故障f5的特征模式,但我们提出的组合过采样方法可以在一定程度上缓解类不均衡现象,提高模型的预测性能。 图9 测试集中故障组合分布的可视化效果Fig.9 Visualization of fault combination distribution in test set 本文提出了一种基于多重自注意力机制改进的Transformer多标签故障诊断方法,结合ADASYN和Borderline-SMOTE1组合过采样策略,以解决极端类不均衡的多标签工业故障诊断问题。在PHM2015 Plant数据集上进行了训练、验证和测试,结果表明: (1) 本文提出的ADASYN和Borderline-SMOTE1组合过采样方法,能够改善工业故障数据的极端类不均衡现象,可能会损失部分精度,但是能够很好的提高样本上和类别上的整体预测性能。 (2) 本文提出的Transformer-N网络模型能够准确的识别出指定时刻是否发生了故障,尽可能的减少了正常样本进入故障诊断环节导致故障诊断模型将正常样本误分类为某个类型的故障样本。 (3) 本文提出的Transformer-Fn网络模型能够更好的挖掘出输入特征与输入特征、输入标签与输入标签、输入特征与多故障标签之间的复杂映射关系,可以较好地诊断出工厂生产过程中同时发生的多个故障。 在未来研究中,针对多维工业数据的严重类不均衡问题,可以考虑设计多标签的数据采样方法,以同时提高样本上和类别上的整体预测性能;针对多标签故障诊断问题,可以考虑设计单个多标签分类模型,降低训练模型的复杂性,挖掘故障之间更复杂的关系。1.2 Transformer模型
2 基于Transformer的多标签工业故障诊断

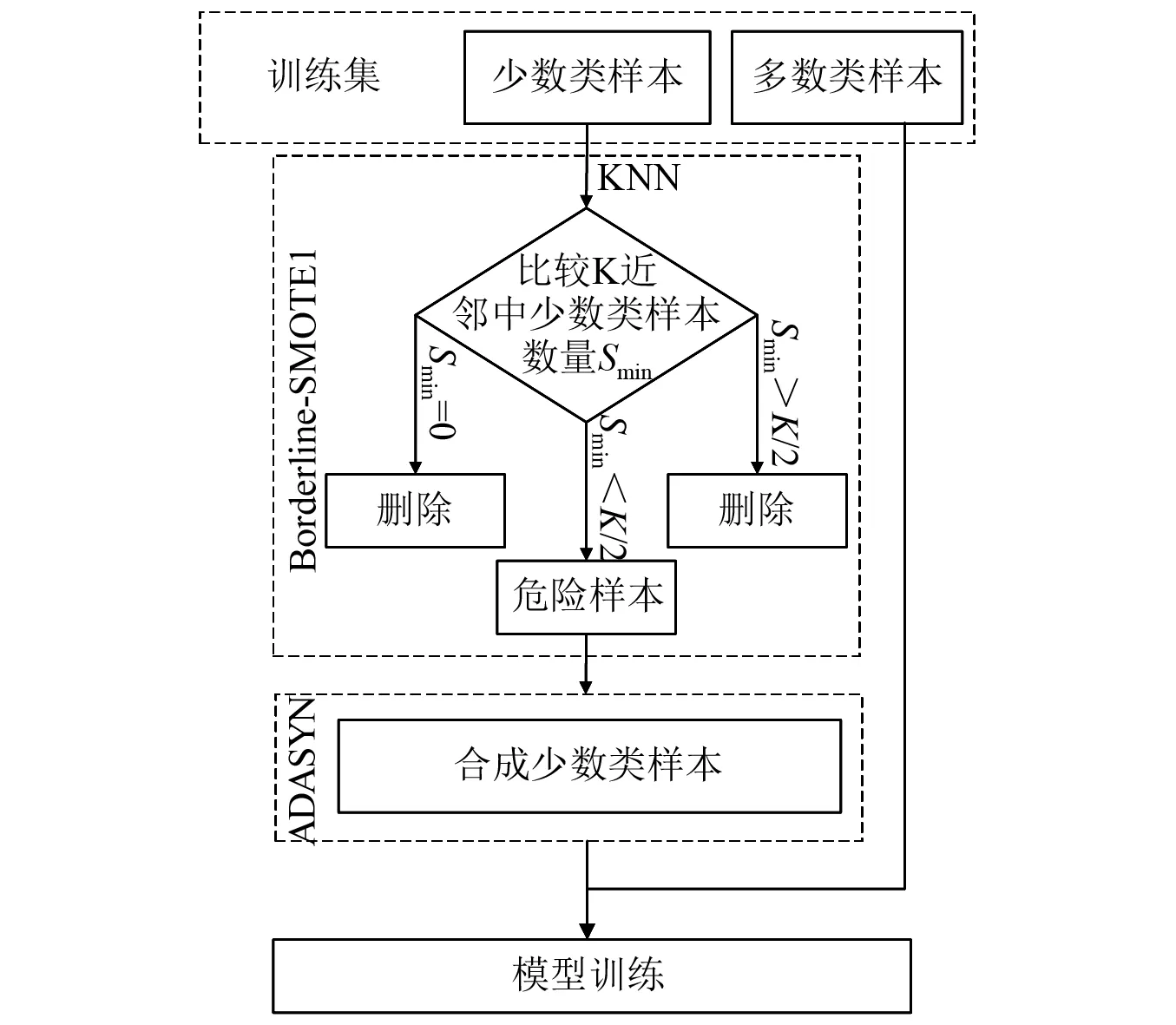
2.1 ADASYN和Borderline-SMOTE1组合过采样


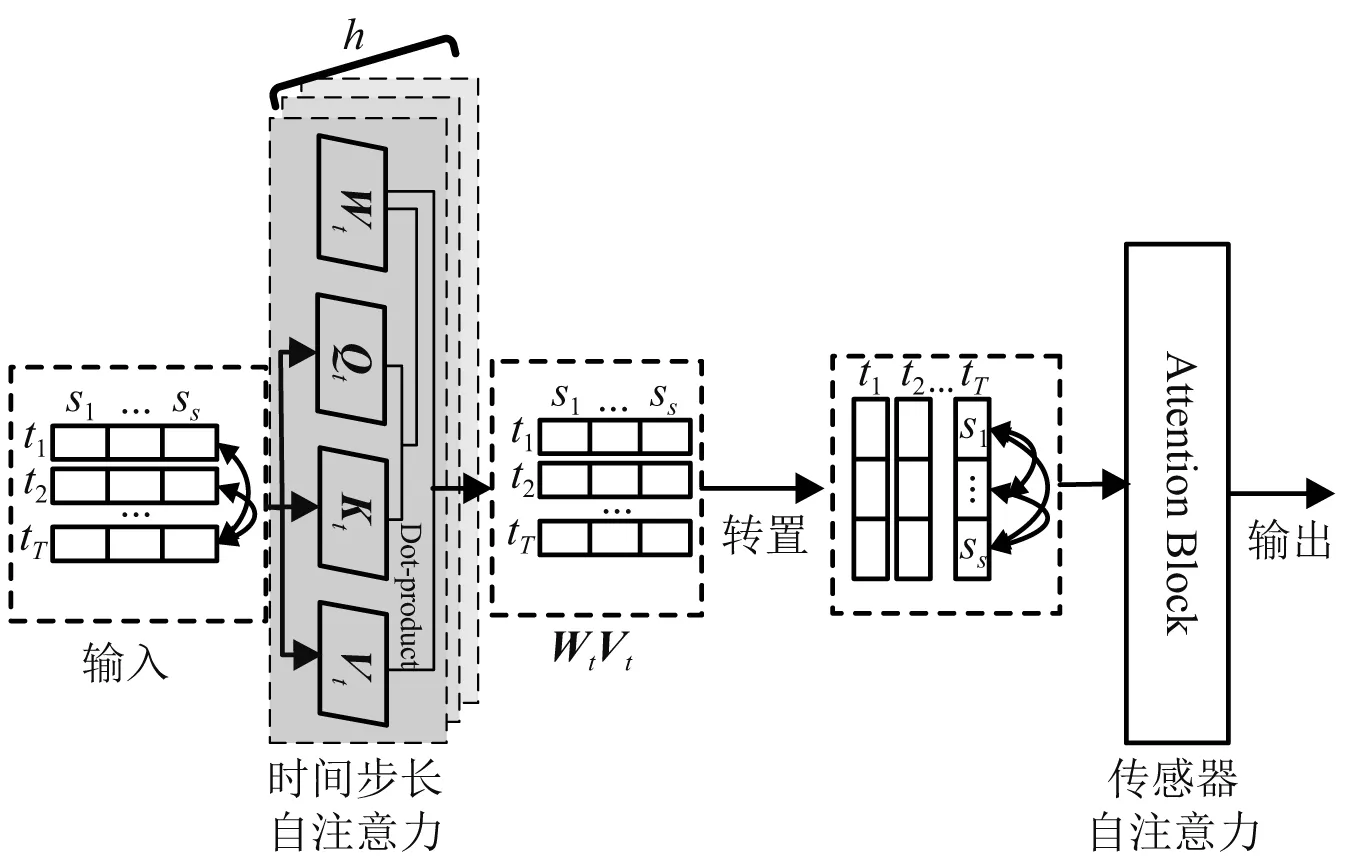
2.2 多重自注意力机制改进的Transformer模型
3 数据集描述与预处理
3.1 数据集描述

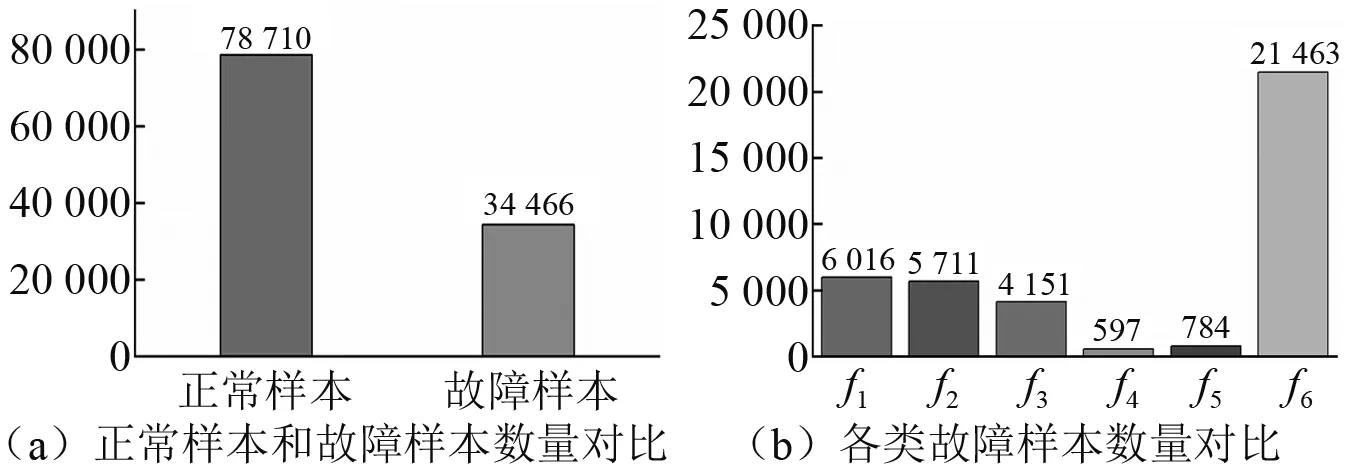

3.2 数据预处理


4 试验结果与分析
4.1 试验环境与评价指标
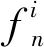

4.2 相关算法与参数设置
4.3 试验结果分析与对比




5 结 论
