面向YHFT-M7002平台图像中值滤波算法的优化实现
2023-10-09王梦园柴晓楠商建东
王梦园 柴晓楠 陈 云 商建东
(郑州大学电子与信息工程学院 河南 郑州 450000)
(河南省超级计算中心 河南 郑州 450000)
0 引 言
随着大规模集成电路和信息技术的发展,图形图像处理技术应运而生并得到了广泛的应用,OpenCV(Open Source Computer Vision Library)就是随之产生的图形图像处理库之一。由于OpenCV中包含很多有关图像处理方面的通用算法且为不同的平台提供了丰富的底层支持,已经成为计算机视觉领域最强大的开源工具之一。其中的中值滤波(Median Filter)作为一种通用的非线性信号处理算法,能够在保护图像边缘的基础上抑制消除一些孤立的噪声点,并且在滤除叠加白噪声等方面的运算速度较快性能极好,在图像去噪领域应用非常广泛。
在图形图像处理领域,如何尽量提升处理的实时性一直是一个重要的问题,由于DSP的高性能、低功耗等特点可以满足图像处理实时性以及密集型计算的需求,目前的应用愈加广泛。虽然国产DSP研究起步较晚但近年来随着国产化需求愈发强烈,国产的高性能处理器发展也迈入了新的阶段,其中比较有代表性的是国防科技大学研制的高性能处理器FT-M7002,其内核针对运算密集型算法进行了高度优化[1-2],在信号处理等需要进行大量数据运算的场合下能很好地发挥优势。
目前国内外针对在硬件平台上的中值滤波优化研究较少,大部分研究成果集中在对中值滤波自身算法的优化层面[3-17]。例如文献[6]提出了一种快速中值滤波算法,对传统算法重复的数据访存重新进行了设计,但没有结合硬件进行进一步优化。文献[8]提出了一种改进的中值滤波器针对降噪和改进细节进行了改进,提升了算法复杂度,但没有改进算法的计算量。
本文面向FT-M7002平台,在完成OpenCV2.4.9移植的基础上,提出针对该平台特性的中值滤波算法向量化优化实现。首先分析FT-M7002体系结构特点与中值滤波算法实现方式,并通过对opencv中中值滤波程序进行热点测试来分析程序的性能瓶颈并进行针对性优化。主要实现步骤有:(1) 将需要处理的数据排布成适合向量化操作的顺序;(2) 针对算法中密集型数据访存,使用手工向量化、循环展开等优化手段以充分利用数据级与指令级并行性;(3) 针对DMA传输产生的数据传输开销,采用乒乓缓存是数据传输与数据计算同时进行;(4) 针对实时性与高效性设计对比实验,对改进之后的算法性能进行详细的测试。
1 YHFT-M7002体系结构
1.1 FT-M7002总体结构
YHFT-Matrix是国内自主研发的面向图像处理、无线通信和视频的高性能DSP。其总体结构如图1所示,板卡包含2个FT-MT2 DSP核、1个RISC CPU核、2个IO节点、全局Cache、核间同步、1个MCU及PCIE、SRIO、GMAC等IO设备。内核和核外设备连接为环形[2]。

图1 FT-M7002总体结构
1.2 FT-MT2内核结构
FT-MT2内核为VLIW(超长指令字)结构,包括一个五流出标量处理单元和一个六流出向量处理单元。标量处理单元SPU包括指令流控部件、SPE、SM。SPE主要用来接收标量运算类的指令,将指令译码后在对应的功能单元执行操作。SM主要实现标量数据的访存。向量处理单元VPU由16个同构的VPE以及混洗/归约部件组成,负责对数据密集以及运算量大的任务进行并行处理。VPE支持归约操作以及混洗操作。图2为向量存储体结构,由16个Bank组成,统一编址交叉存放可以进行数据共享,且与向量处理单元的VPE0-VPE15对应,可以为VPE提供带宽为512位的向量数据读写访问[18-19]。
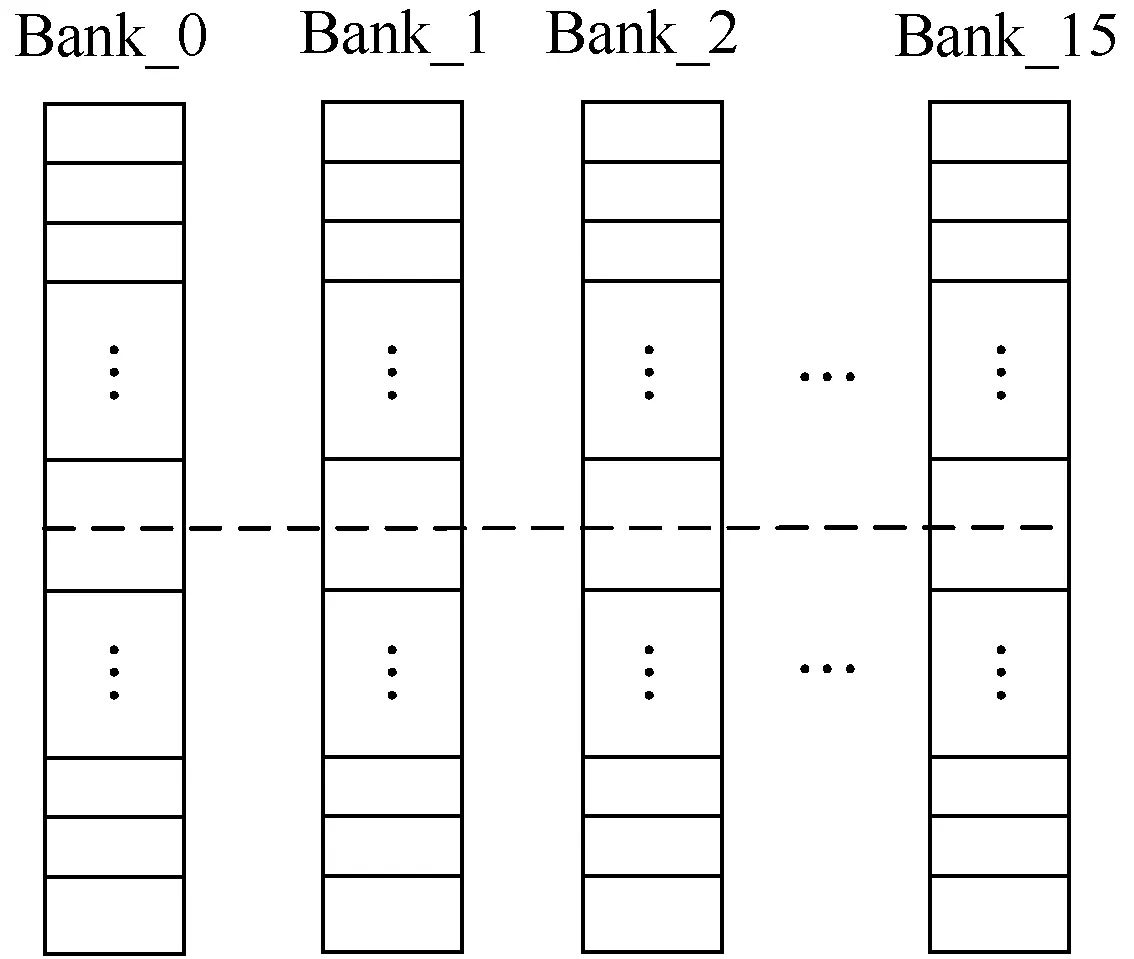
图2 向量存储体结构
2 中值滤波算法原理及实现方法分析
2.1 中值滤波算法原理
中值滤波的计算方式类似于卷积计算,中值滤波原理:对一维数字序列Xk,定义滤波窗口的长度为L,L=2N+1,N为正整数。为了保证使输出信号长度不变,在滤波前需要对滤波数据进行边界填充,在输入信号边界分别填充N个信号,具体的填充方式视情况而定[20],然后在信号序列XK-N,XK-N+1,…,XK,…,XK+N中滑动窗口,之后对窗口中的这些值进行排序操作之后,位于K处的序列样本值即为中值滤波的输出,用公式表示为:
YK=med{XK-N,XK-N+1,…,XK-1,XK+1,…XK+N}
(1)
式中:{XK,YK|1≤K≤L};med(·)表示取XK序列的中值。
对于对二维图像信号Xij,其中值滤波算法流程和一维序列类似,二维中值滤波输出值为:
Yij=medXij=med{Xi+r,j+s:r,s∈A}
(2)
式中:A为截取图像数据的二维窗口。图3为滤波窗口为正方形大小为3×3时的中值滤波过程以及结果。

(a) 滤波过程 (b) 滤波结果
2.2 中值滤波具体实现方法分析
Opencv的中值滤波算法实现为了达到不同滤波核大小的情况下最好的性能,根据滤波核的大小选用了不同的实现方法,当中值滤波采用的滤波核大小比较小(Ksize≤5)时,由于每次迭代需要比较计算的数据量比较小,所以可以直接采用传统的直接排序方法计算中值,以3×3的滤波核为例进行说明,其基本思路是先对数据进行排序(算法中的行向有序),然后再在三组有序的数据中找到数据合并后的中位数,首先需要取出有序序列中最小值中的最大值、最大值中的最小值、中间列向的中值,三个数进行比较之后的中值就是输出结果。
图4为滤波核大小为3×3时快速算法流程,其中p0-p8为3×3滤波核的9个数据,数字代表比较操作的执行顺序,3×3的数据中经过比较操作之后p4位置的数据就是输出值。
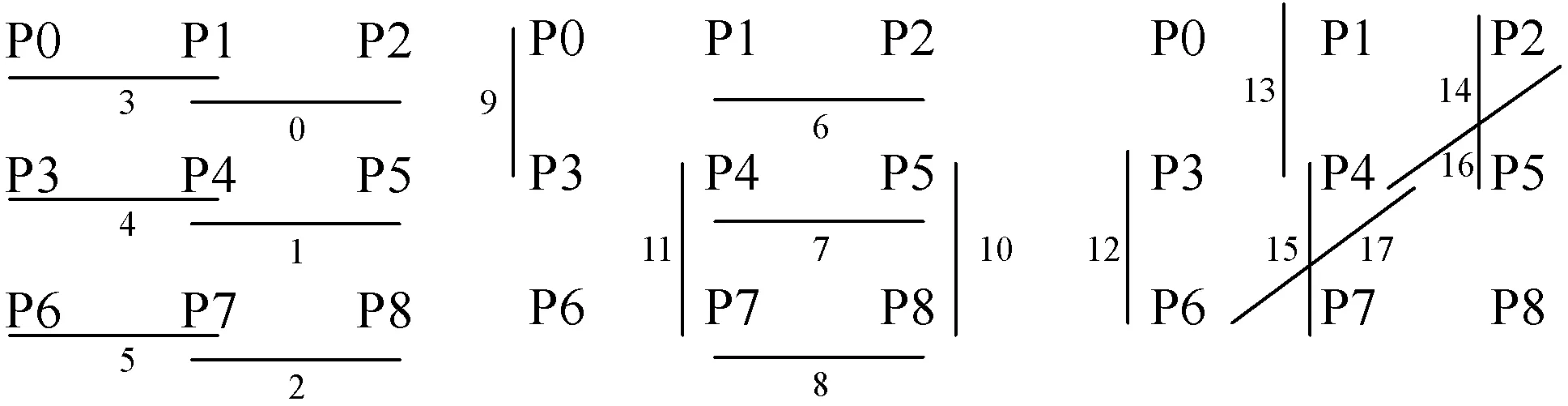
图4 滤波核为3×3时快速滤波算法流程
ksize>5时,opencv使用的算法是利用直方图的快速算法,在中值滤波的窗口n×m移动一列时,其实质是减去了左边一列m个像素值并增加了最右边的一列m个像素值,其中间的mn-2n个像素值保持不动,如图5所示,所以只需要考虑变化的两列像素值对窗口中值的影响(将mn个像素的灰度直方图存储在窗口中,并在窗口移动时对其进行更新)这样可以避免对大量没有变动的像素值进行比较,从而解决传统滤波算法重复计算的问题。
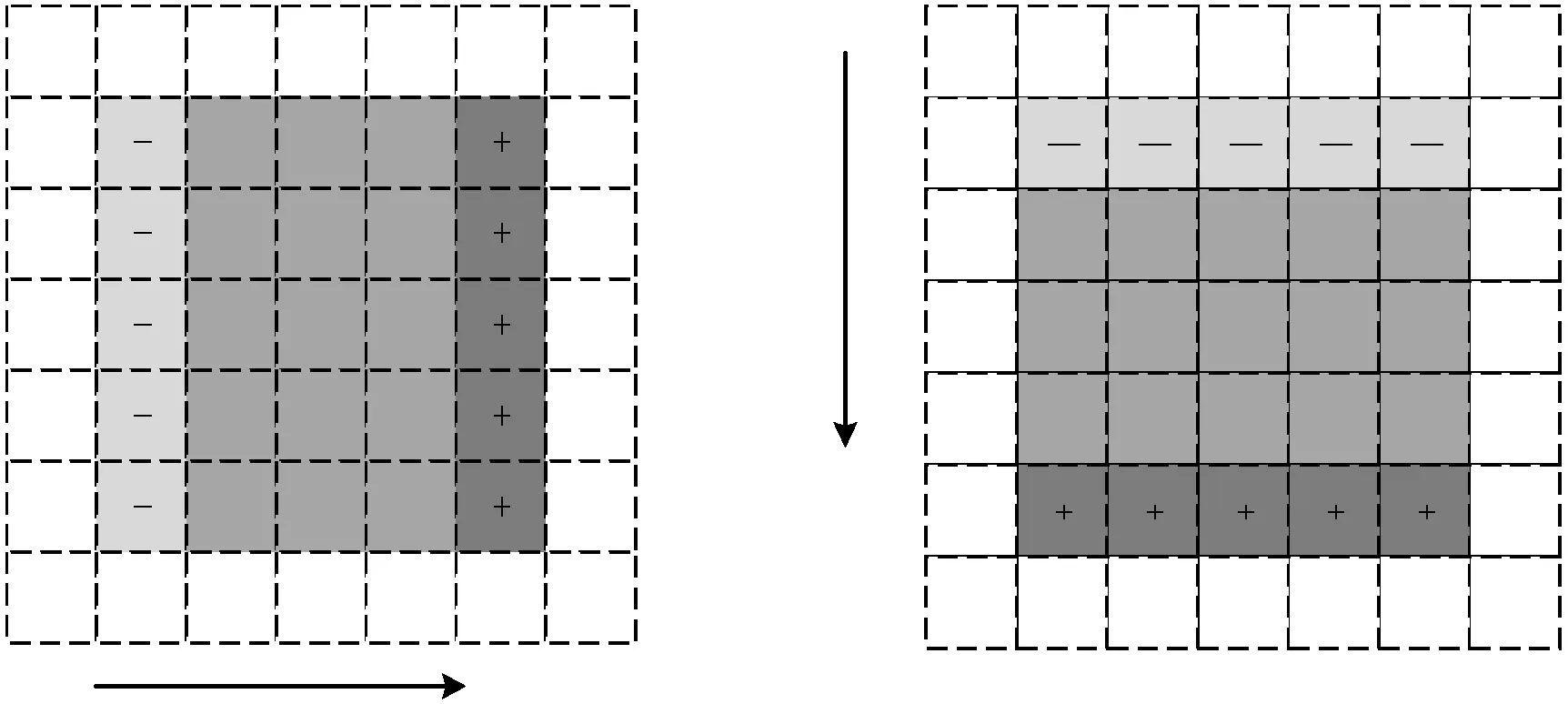
(a) 滤波核向右滑动时 变化的像素 (b) 滤波核向下滑动时 变化的像素
3 面向FT-M7002平台的中值滤波算法优化实现
在对FT-M7002的体系结构以及向量部件特点等进行分析之后,针对中值滤波算法设计FT平台上的一般实现方法,并对此算法的数据密集运算部分进行了数据级和指令级层面的优化,进一步提升了此算法的性能。
3.1 向量化优化
SIMD(Single Instruction Multiple Data)单指令多数据运算可以帮助CPU实现数据并行,提高运算效率。FT-M7002板卡中的AM向量模块由16个向量存储体组成,每个存储体都包含16个VPE,并且VPE对应的VLIW执行包中的向量指令可以同时调用16个VPE中的数据进行操作。所以在读取完图片数据之后,可以利用DMA传输模块将数据传输到AM空间,使得一次操作运算可以对16个VPE中的数据同时进行,可以达到提升运行效率的效果[2]。
3.1.1总体实现流程
以图6为例说明基于向量处理器的中值滤波的实现方法.设滤波核大小为3×3,首先使用DMA将已经转化成的矩阵数据从DDR中传输到AM空间;向量寄存器从AM空间中加载矩阵中第一行和第二行的数据调用已经写好的向量接口进行比较,将结果存放在对应的位置;继续加载相应的数据进行上述操作,直至完成所有的比较操作之后,将结果传输回标量空间。标量算法的核心在于核内9个像素值的比较排序,一共需要19次比较排序,若在FT平台使用向量寄存器完成比较操作则可以同时进行16次对像素的比较,理论上可以产生16倍左右的加速效果。

图6 FT平台上中值滤波算法示意图
3.1.2数据搬移
由于FT-M7002在使用向量指令进行数据的向量操作的时候,需要从AM空间进行数据的访存,但是AM的存储空间比较小,数据量比较大时AM空间不能完全存放,所以为了提升性能并且满足向量操作的需要,在中值滤波的计算过程之前利用DMA将存储在DDR的数据搬移到AM地址中进行计算,向量计算完成之后再使用DMA将数据重新传送回标量空间的地址中进行后续操作。
直接存储器访问(Direct Memory Access,DMA)是一种在系统内部转移数据的独特外设,可以独立于CPU进行数据的传输交换[21]。在实际应用过程中由于核内存储器的空间大小的限制,需要将数据存储在DDR中,再使用DMA根据访问地址向AM或者SM空间发起读写操作,每次启动DMA可完成一个二维数据块的传输。通过使用DMA传输可以将输入图片矩阵连续地存放在AM存储空间中,从而可以直接利用7002向量指令存取数据,保证了数据的局部性,减少不必要的访存操作。
3.1.3FT-M7002向量指令集改写
中值滤波算法向量化优化的重点在于标量比较指令的向量化改写,以float类型为例,因为FT-M7002的vec_lt(小于)、vec_fcmpg(大于)比较指令返回的值是int型的0或1,不能直接得到比较后对应的数据,所以还需要利用类型转换指令vec_fxts和乘法指令vec_muli进行组合来取到比较大小之后的数值,以小于指令为例,要取a、b中较小的值首先需要使用vec_lt指令分别比较(ab)、(ba),两个返回的结果值利用vec_fxts进行转换之后分别与a、b相乘,再使用vec_eq判断两个值是否相等,返回的值与b相乘之后把得到的三个值进行加法操作,就可以得到较小的值。大于指令也是类似的原理,为减少代码的冗余将上述指令集合封装成两个比较大小的通用函数接口,进行向量化改写时可以直接调用这两个向量接口来完成比较指令的替换。部分代码示例如下:
vector float(vec_minf)(vector float a,vector float b)
{
vector signed int t=vec_lt(a,b);
vectoe float t1=vec_fxts(t);
vecroe float r2=vec_muli(t1,a);
vector signed int t3=vec_lt(b,a);
vectoe float t4=vec_fxts(t3);
vector float t5=vec_muli(t4,b);
vector signed int t6=vec_eq(b,a);
vector float t7=vec_fxts(t6);
vector float t8=vec_muli(t7,b);
vector float dst=vec_add(t2,t5);
dst=vec_add(t8,dst);
return dst;
}
3.2 DMA传输优化
由于处理器的时钟频率和计算性能增长速度远远大于主存DRAM访问的增长速度,即便是cache和数据预取可以减少访存时间但解决不了根本问题,并且FT-M7002的特殊结构导致在进行向量运算时需要利用DMA将数据搬移到AM空间中,导致数据传输需要的时间占比过多影响程序的性能。对于这些问题可以利用双Buffer机制来解决[22]。也就是在DMA开始传输循环检测之前将其和计算程序运行并行起来,同时进行数据传输和运算,相当于隐藏一部分运算时间,从而达到性能优化的目的。
图7为双Buffer机制的示意图,首先数据的初始化配置按顺序依次向Buffer0、Buffer1传输数据。进入循环后首先检测Buffer0的数据输入是否完成,若已经完成传输则对其进行向量计算操作,同时DMA开始向Buffer1中传输数据,若Buffer1中的数据传输完成且向DDR写回后,就开始新的计算同时对Buffer0中的数据进行更新。双Buffer循环次数根据运算的数据量而定,循环结束后需要对循环中最后一次传入Buffer0和Buffer1中的数据进行计算然后再将数据传出到DDR中完成全部计算。
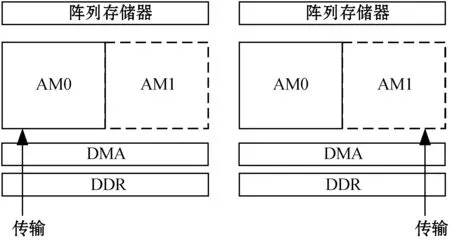
图7 双Buffer机制示意图
使用双Buffer优化时,具体AM空间的划分如图8所示,将AM空间划分成Buffer0和Buffer1两个部分,分别属于AM中地址0X3XXXX60000的两侧,两部分都包括输入数据空间和保留空间。
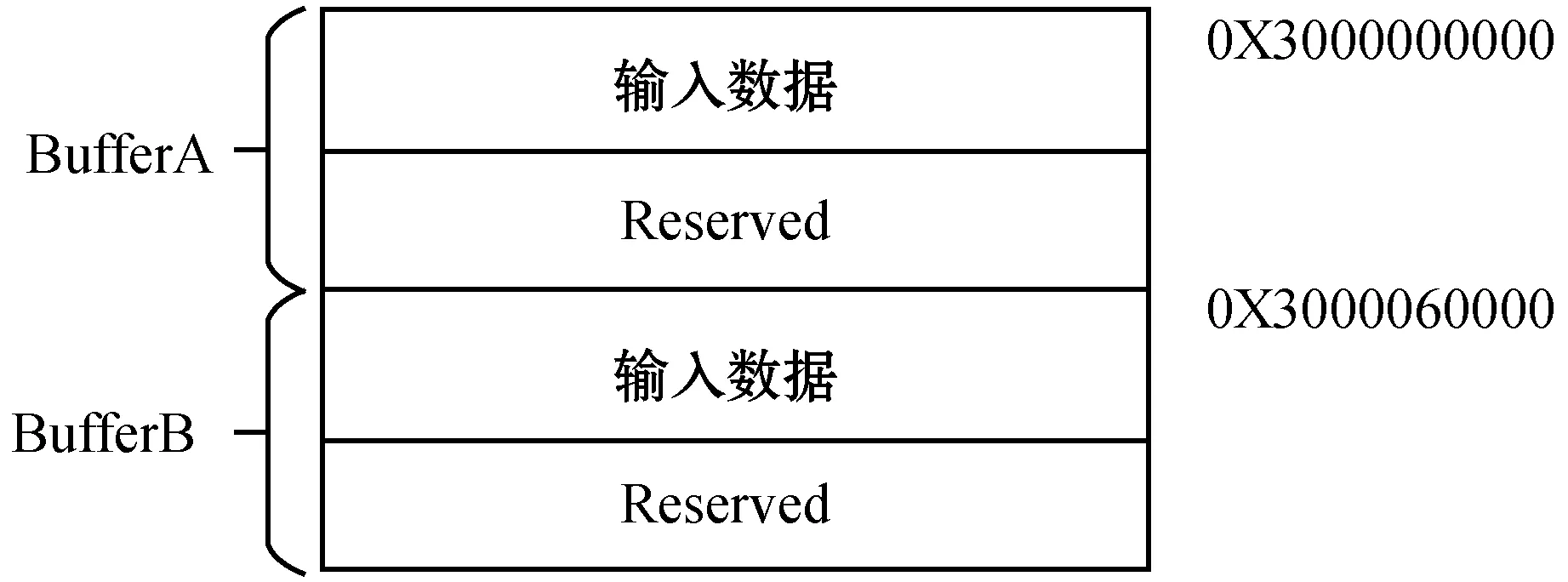
图8 AM数据布局
3.3 其他优化
为进一步提升优化效果,在进行以上优化方法的基础上尝试进行了核心代码段部分最内层循环的展开优化,通过增加每次迭代计算的元素的数量来减少循环的迭代的次数以提供更多的软件流水并行,减小循环开销的影响。但循环展开会大大增加生成的目标代码的体积,因此在使用循环展开时要同时考虑选择多大的展开度以及这个展开度对空间开销比例的影响,在尽量不会使目标代码空间消耗激增的前提下获得最高的时间收益。
实际进行循环展开优化时,通过多次实验确定最优的循环展开因子为2,实验结果均为在循环展开因子为2时的测试结果,充分挖掘了程序的指令级并行性以获得最好的加速效果。
4 实验与结果分析
4.1 实验环境
在FT-M7002上对不同情况下中值滤波算法的性能进行测试,由于在FT平台上不同的数据类型对应使用的向量指令不同,所以实验结果对使用较多的三种数据类型(unsigned char、unsigned int、float)进行分开测试,并与未进行优化之前的Opencv滤波算法运行周期进行对比。
实验平台中,FT-M7002的主频为1 GHz(双精度峰值性96GFLOPS),单核L1D大小为32 KB,AM向量空间大小为512 KB。
4.2 算法正确性及性能测试
4.2.1unsignedchar类型测试结果
unsigned char是图像处理库应用较多的数据类型,但由于FT平台的向量寄存器较长还没有直接针对此类型的向量化指令,针对这个问题借助平台的混洗以及逻辑操作等指令提出一种通用的unsigned char和unsigned int进行数据类型转换的接口,通过调用接口将数据类型转换成为unsigned int类型进行操作,计算完成之后的结果再使用接口转换回unsigned char类型。
表1为滤波核为3×3时,unsigned char类型在不同的图片像素大小时的加速效果,可以看出在结果正确的前提下经过优化后的程序加速效果平均在13倍左右,加速比随着图片数据量的增大呈线性增长的趋势。原因在于随着数据量的增大其核心计算部分的耗时在程序整体运行时间占比增大,并且DMA传输耗时占比变小,所以加速效果呈现线性增大的趋势。

表1 unsigned char类型滤波核3×3时测试结果
表2整理了滤波核大小为5×5时程序的加速比。实验结果显示,经过优化后的程序加速效果为7倍左右,其加速效果不如3×3的主要原因在于当滤波核大小为5时,其一次内层循环计算量是滤波核为3时的6倍多,需要用到大量的向量寄存器,产生了较多的时间折损导致加速比较低。在不同数据量大小的情况下数据量较大时的数据级和指令级的并行更多,加速效果也比数据量较小时更好。
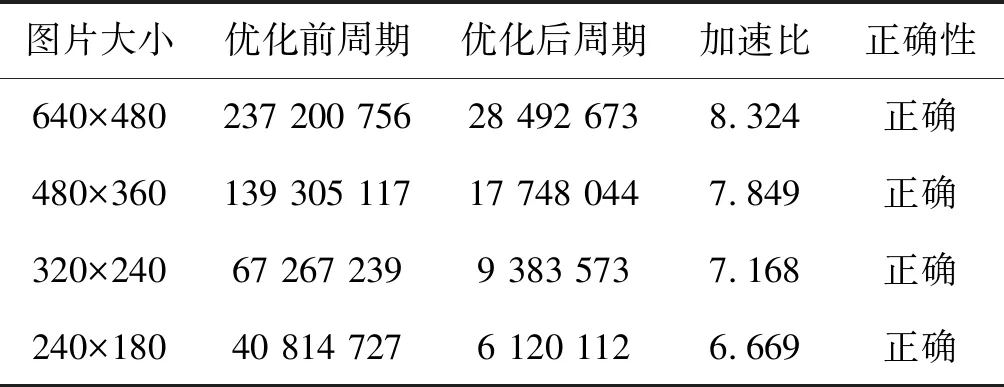
表2 unsigned char类型滤波核5×5时测试结果
4.2.2unsignedshort类型测试结果
当输入图片的数据类型为unsigned short时,由于向量部件计算16位数据时需要将两个16位数据组合放在一个寄存器中进行计算,就导致读取数据不支持产生奇数位偏移。为解决这个问题提出一种通用的unsigned short与unsigned int数据类型互相转换的接口,实际计算时可以调用接口把数据转换成unsigned int类型进行计算,但是使用接口转换数据就不可避免地会产生额外的数据传输成本。如表3所示,滤波核3×3时unsigned short类型加速效果为12倍左右,并且随着数据量的增大呈增加趋势。
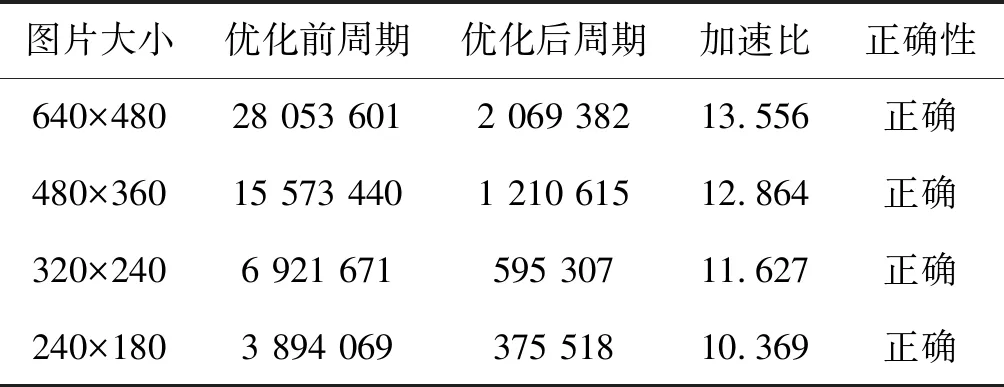
表3 unsigned short类型滤波核3×3时测试结果
表4为滤波核大小为5×5数据类型为unsigned short类型时的测试结果,可以看出优化后的算法加速比大概为5倍左右,原因是数据类型转换耗费时间较多,并且滤波核增加计算量呈指数型增长,所以滤波核为5时的加速比较低。
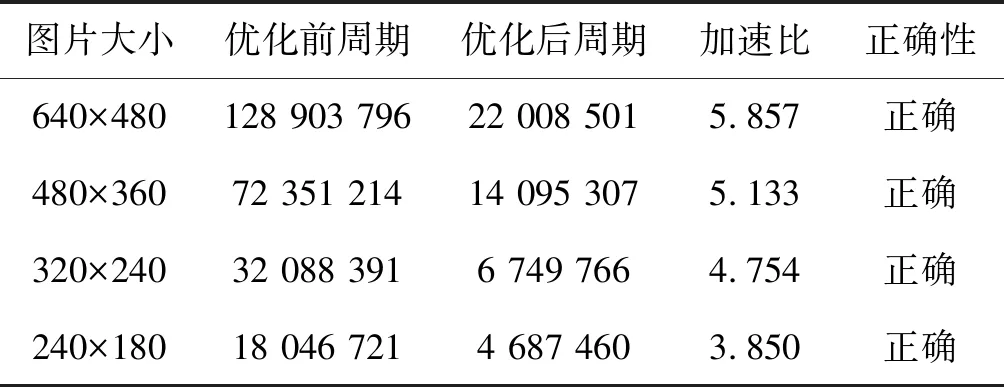
表4 unsigned short类型滤波核5×5时测试结果
4.2.3float类型测试结果
表5统计了滤波核大小为3×3时,32位浮点类型在不同数据量的情况下最高可以达到16.6倍左右的加速效果。由于float类型的中值滤波在进行向量化改写时可以直接使用对应的向量指令,无须进行类型转换,节省了较多运行时间,之后又结合了上文多种优化方法进行了优化加速,所以其效果得到了明显提升。
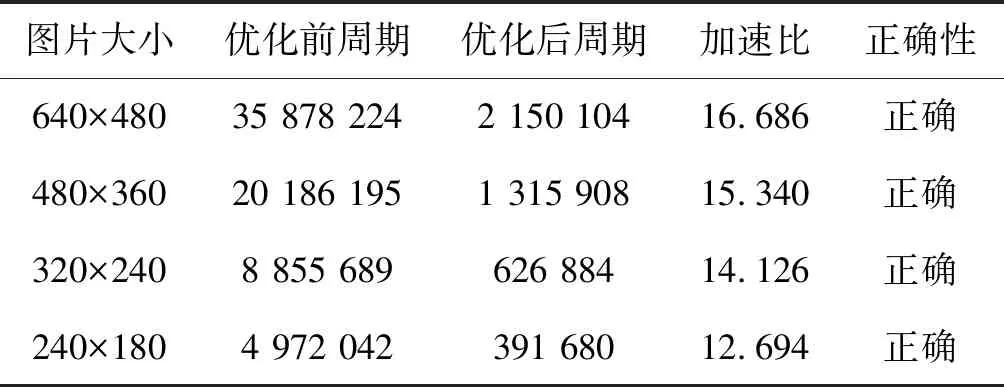
表5 float类型滤波核3×3时算法测试结果
当滤波核大小为5×5时,由于这种情况下计算量较大,并且32位浮点本身在计算过程中需要将部分数据由整型转换为浮点,在计算量大的情况下时间折损占比更多,加速比效果不如3×3,表6为不同数据量情况下的测试数据,加速比大概为5倍左右。
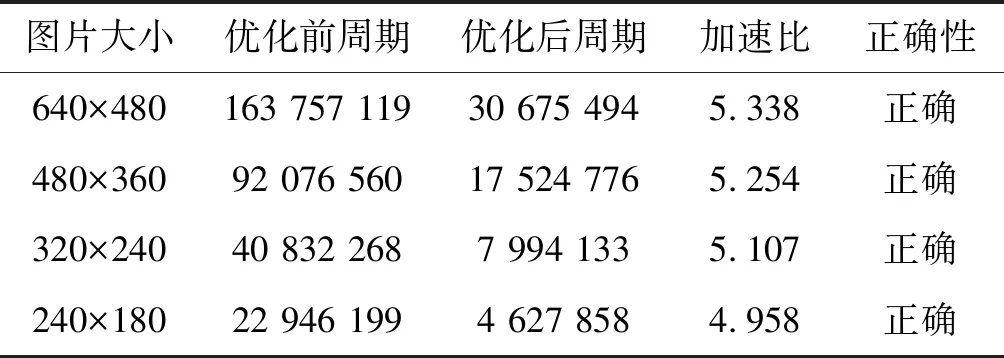
表6 float类型滤波核5×5时算法测试结果
5 结 语
本文面向国产FT-M7002平台提出一种中值滤波的实现方法,并结合平台的硬件特性使用手工向量化改写、数据传输优化、循环展开等优化方式,充分挖掘算法数据级以及指令级的并行性,实现程序性能提升的目的。本文在多种滤波核大小及不同数据类型输入图片的情况下进行性能测试,结果表明:相对于没有进行优化的串行实现,该优化使程序获得了5~16不等的加速比,验证了本文所提出优化的有效性以及FT DSP核的计算性能优势。下一步将继续完善其他常用图像处理算法在FT DSP平台的优化实现。
