基于对抗学习邻域注意网络的链路预测
2023-10-09代秀珍
代 秀 珍
(包头铁道职业技术学院 内蒙古 包头 014060)
0 引 言
网络对于现代社会是不可缺少的一部分,对网络中不可观测的链路进行预测对维护网络的稳定运行、提升网络运行效率等具有重要的意义[1]。例如,它可以省去盲目检查蛋白质网络中的交互作用,改进社交网络和电子商务网络的推荐服务,帮助完成信息确认[2-3]。
近年来,链路预测研究越来越重视邻域信息,它代表了网络节点的局部结构,通常被认为是链路预测的重要线索之一。许多方法侧重于人工设计相似性指标和邻域特征,最具代表性的是基于邻域的启发式算法,如公共邻域算法(Common Neighborhood,CN)、ADAMIAC adar(AA)和Simrank(SR)[4-6]。虽然方法简单,但这些启发式算法一个主要的限制是,由于它们的线性增强性,往往不能广泛应用于多个网络。并且在为不同类型的网络选择启发式和特征时,先验知识或昂贵的试验和错误是不可避免的。因此,寻找一种能够自动学习具有表达性的邻域特征并具有广泛的链路预测适用性的方法是非常重要的。
因此近年来发展了一些基于神经网络的链路预测模型,这些模型利用神经层来探索非线性的深层结构特征。文献[7]使用图标记算法将两个节点的联合邻域作为矩阵,并使用卷积神经层来预测链路编码。文献[8]在对抗生成网络(Generative Adversarial Networks,GAN)中引入一个鉴别器与之进行对抗博弈,鉴别器尝试将生成的样本从地面真实样本中分离出来。近年来,针对网络嵌入模型提出了一些基于对抗学习的正则化方法,以提高网络嵌入模型的鲁棒性。但是上述方法均没有充分挖掘邻域特征信息,无法实现端到端的方式预测链路,且模型的泛化能力不强。
针对上述问题,提出了一种基于对抗学习邻域注意网络的链路预测模型。在各种网络类型的12个基准数据集上评估所提出方法的性能,实验结果证明了提出方法的优越性。
1 基础理论
1.1 基础定义
网络可以表示为图G(V,E),其中V={v1,v2,…,vN}是节点的集合,E⊆V×V是链路的集合,并且总数为节点为N。图的结构信息通常表示为邻接矩阵A,其中,如果存在从节点vi到vj的链接,则Ai,j=1,否则Ai,j=0。如果链接是无向的,则A是对称的。使用Nh(vi)表示节点vi的第h阶邻域,即到vi的距离不大于h阶的节点集。vi为中心节点,vj∈Nh(vi)为h阶内vi的邻域。
在链路预测场景中,给定目标节点对(vi,vj),本文将vi的相邻节点,即vk∈Nh(vi)定义为vj的自邻域节点和vj的跨邻域节点。同样,vj的相邻节点,即v1∈Nh(vj),被定义为vj的自邻域节点和vi的交叉相邻节点。
链路预测问题可分为时间链路预测和临时性链路预测,前者可预测不断发展的网络中潜在的新链路,后者可推断静态网络中的缺失链路。重点介绍结构链接预测。给定部分观察到的网络结构,其目标是预测未观察到的链路。形式上,给定部分观测的网络G=(V,E),本文将未知链路状态的节点对集合表示为EΣ=V×V-E,则结构链接预测的目标是推断EΣ中节点对的链接状态。
提出了一种用于多空间邻域注意机制(Multi Spatial Neighborhood Attention,MSNA)以及用于链路预测的两个邻域注意网络(Neighborhood Attention Network,NAN)即自邻域注意网络(Self Neighborhood Attention Network,SNAN)和跨邻域注意网络(Cross Neighborhood Attention Network,CNAN)。给定一对节点(vi,vj)及其邻域信息,提出的注意神经网络旨在将其链接得分推断为:si,j=NAN(vi,Nh(vi),vj,Nh(vj))。
1.2 多空间邻域注意机制
在链接预测问题中,通常将邻域视为关键上下文信息。提出的多空间邻域注意机制原因是邻域对于中心节点具有不同的结构重要性,并且如果从不同方面来看,重要性也有所不同。例如,在社交网络中,某些邻居在考虑共同的朋友时更重要,而其他一些邻居在考虑中心性时则更为重要。该机制在多个潜在空间中学习重要的注意关系,这些潜在空间代表了潜在的不同方面。通过在不同空间中集中关注重点,该机制能够构建全面的邻域特征。
形式上,给定中心节点vi、其h阶邻域Nh(vi),以及这些节点的特征x∈Rdx,该算法利用注意分量构造中心节点的潜在邻域特征ci=fattn(xi,{xj∈Nh(vi)}),其中fattn()是基于注意力的编码函数。
在每个潜在空间s中,定义中心节点vi对它的相邻节点vj∈Nh(vi)的关注,它表示相邻节点vj在Nh(vi)中的重要性,如下所示:
(1)

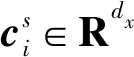
(2)
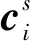
(3)
式中:[;]表示串联运算ci∈RSdx。另外,使用fattn(xi,{xj})表示在中心节点vi和上下文节点{vj}之间发送上述基于注意力的编码过程。
1.3 自邻域注意网络
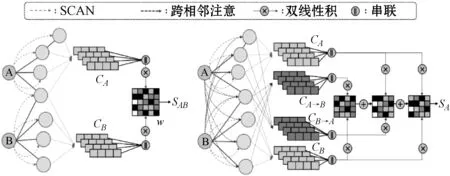
基于MSNA机制,本文首先提出SNAN。如图1(a)所示,SNAN由用于自邻域编码的注意层和用于链路分数预测的节点对匹配层组成。
(a) SNAN (b) CNAN
SNAN的输入是一对节点(vi,vj)。由于本文没有考虑节点的其他信息,因此节点的输入表示是节点IDs的一元向量o∈RN。本文通过线性映射x=Wxo将一元向量作为潜在节点特征进行传输,其中Wx∈Rdx×N将通过模型学习。
给定输入节点及其邻近节点的节点嵌入,SNAN的关注层使用所提出的关注机制对两个输入节点的各自邻域信息进行编码:
ci=fattn(xi,{xk|vk∈Nh(vi)})
(4)
cj=fattn(xj,{xl|vl∈Nh(vj)})
(5)
给定已编码的自相邻信息ci和cj,节点对匹配层将如下预测链路得分:
(6)
这里采用由矩阵W∈RSdx×Sdx参数化的双线性评分函数。此功能通过匹配两个输入节点的邻域上下文嵌入来测量链接分数。该函数适用于有向图和无向图,当图是无向的时,本文将W设为一个单位矩阵,以使分数对一对节点是对称的。
1.4 跨邻域注意网络
SNAN仅通过具有编码的自邻域特征的匹配层隐式捕获两个节点之间的结构交互。为了以更明确的方式捕获交互,提出了一个扩展模型,即CNAN。如图1(b)所示,还设计了一个跨邻域注意,使CNAN能够探索注意层的结构相互作用。通过计算一个输入节点与另一输入节点的邻域之间的注意力来生成跨上下文嵌入。如果两个节点链接在一起,则对于相同的邻域上下文,它们应该具有相似的上下文表示。
跨上下文嵌入是使用提出的注意力机制构造的,不同之处在于上下文节点是交叉相邻节点,而不是自邻域节点。令ci→j表示从输入节点vi到vj的相邻节点Nh(vj)的跨上下文嵌入,反之亦然,则ci→j和cj→i的计算定义为:
ci→j=fattn(xi,{xl|vl∈Nh(vj)})
(7)
cj→i=fattn(xj,{xk|vk∈Nh(vk)})
(8)
此外,CNAN以与SNAN相同的方式构造自上下文嵌入ci和cj。给定已编码的自身和跨邻域信息,本文定义链接评分功能如下:
(9)
在这里使用三个双线性乘积来测量链接得分。该评分功能不仅匹配两个自上下文嵌入,还匹配交叉邻域嵌入和相应的自邻域嵌入。另外该函数还针对有向图和无向图进行了概括:如果图形是有向的,则W1,W2,W3∈RSdx×Sdx是三个不同的参数矩阵;如果图是无向的,则令W1为单位矩阵,W2=W3。
2 对抗制模式学习
2.1 学习目标
链接预测问题的目的是推断节点对是否链接。由于网络的稀疏性,链接对和非链接对之间经常存在极度不平衡的现象。为了更好地处理不平衡问题,本文采用了模型学习的排序思想,其目的是对链接节点对进行评分,使其得分高于非链接对。
sij>skl∀(vi,vj)∈E和∀(vk,vt)∈E-
(10)
式中:E-是真正的非链接对的集合。将学习目标定义如下:
(11)
式中:Dθ代表NAN模型,θ是模型参数集,因此Si,j=Dθ(vi,vj)。对于正样本(vi,vj)∈E,考虑每一个边界负样本(vi,vk),该样本将vi视为锚节点,并将其链接节点vj替换为未链接的一个vk。如果网络是无向的,则将vi或vj视为锚点。本文采用基于边界的排名损失,这迫使正样本的得分高于具有边界γ的负样本的得分(γ=1)。
实际上,训练数据中没有真正的非链接集E-。常规策略是使用vi随机采样具有未观察到的链路状态的节点vk并将(vi,vk)假定为负样本。但是,由于完全随机性,随机采样策略的性能并不总是稳定的。例如,在训练过程达到一定水平之后,随机采样器有较高的可能性提取学习良好的样本,这满足了裕度约束,并不可避免地带来损失。这些无用的负样本使模型几乎没有改善,因此卡在了一些不太理想的点上。在其他任务中也发现了类似的随机负采样问题,例如知识图嵌入和图像检索。
本文提出了一种对抗学习框架,可为所提出的模型提供更有效和鲁棒的优化解决方案。具体来说,引入了一个生成模型G∅(由∅参数化)来生成负样本,而不是随机样本。G∅和链接预测模型Dθ(判别器)在此框架中进行极小极大博弈。G∅连续提供高质量的信息性负样本,Dθ观察到的真实链接与生成的负样本之间有明显的区别。正式地,将极小极大博弈定义为:
(12)
(13)
链接预测模型Dθ的目标是一个类似于式(11)的最小化问题。唯一的区别是负样本由G∅给出,其中Evk~G∅(vk|vi)表示对生成器中负样本分布的期望G∅。另一方面,生成器G∅的目的是最大化问题。这些负样本将被直接测量为链接得分Dθ(vi,vk),分数越高,样本越丰富。分别通过最大化和最小化两个目标函数可以迭代地学习Dθ和G∅的最优参数。
2.2 负样本生成器
由于考虑到每个边缘的负样本,因此生成器的输入是正样本(vi,vj)中的选定锚节点。对于定向网络,选择源节点vi作为锚点节点。对于无向网络,vi或vj以相等的概率随机选择。
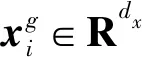
(14)
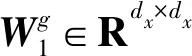
(15)

2.3 优 化
1) 优化鉴别器Dθ:可以通过随机梯度下降法直接解决鉴别器Dθ的最小化问题。给定从生成器G∅生成的正样本(vi,vj)和负样本(vi,vk),Dθ的参数将使用以下梯度更新。
2) 优化生成器G∅:生成器G∅的目标是最大化问题,但是,由于发生器的输出是离散的,即节点IDvk,因此无法通过梯度上升方法直接优化该问题。为了解决这个问题,采用了广泛使用的基于策略梯度的强化学习(RL)算法。在RL的意义上,生成器G∅充当“代理”,而鉴别符Dθ被视为“环境”。代理G∅通过基于当前“状态”执行“操作”来与环境Dθ进行交互,并通过最大化响应于其操作而从环境返回的“奖励”来改善自身。在该场景中,状态由输入锚节点vi表示,动作生成负样本(vi,vk),奖励定义为生成的样本Dθ(vi,vk)的链接得分。返回的奖励直接用于强化学习中的梯度计算。对于正样本(vi,vj)和生成的负样本Dθ(vi,vk)的奖励,得出式(13)的梯度如下:
(16)
在最后一步中,对K个生成的样本使用近似值。另外,通常使用奖励的基线值来减小强化学习的方差。本文将基线rb定义为一个训练时期的平均奖励。使用该奖励基准,将式(17)中的奖励Dθ(vi,vk)替换为Dθ(vi,vk)-rb。
3) 整体学习算法:如前所述,本文可以通过迭代优化两个目标来得出最佳参数。算法1中提供了该对抗性学习框架的详细信息。通过小批量训练来更新参数。对于每个小批量的正样本,首先让Gφ生成相同数量的具有批次大小的负样本。给定一批正样本和负样本,该算法会迭代更新鉴别器和生成器的参数。学习率分别为η1和η2。在这里,介绍了一种传统梯度算法(Vanilla Gradient Method,VGM),但是可以用任何基于梯度的优化方法代替。在每个训练时期之后,该算法都会计算新的奖励基准。
算法1NANs的对抗性学习
输入:训练网络G=(V,E)。
输出:链接预测模型Dθ(SNAN或CNAN)。
1 初始化Dθ的参数θ和生成器Gφ的参数φ。
2 循环
3 当 每个小批量Ebat∈E时 执行
4 当 (vi,vj)∈Ebat执行
5 用电流生成器Gφ(vk|vi)产生一个负对(vi,vk);
6 当固定Gφ时更新Dθ:
8 当固定Dθ时更新Gφ:
10rs←rs+ΣDθ(vi,vk);

12 收敛。
3 实验与分析
3.1 数据集
本文在包括多种网络类型的12个基准数据集上评估所提出方法的性能。EML是电子邮件通信网络。该网络中的节点是电子邮件地址,每个边缘代表至少已发送一封电子邮件。CEG是隐杆线虫的生物神经网络。神经元是节点,神经元之间的连接突触是边界。PLB是美国2004年选举后的政治博客网络,博客代表节点,博客之间的超链接是边缘。KHN是一个引用网络Kohonen网络。节点是科学论文,主题为“自组织图”,引用关系代表边界。HTC是一个科学合作网络。关于“高能物理”主题的预印本作者代表节点,每个边缘代表两个作者至少共同创作了一次。
UPG是美国电网的物理基础设施网络,其中节点是发电站,链路是发电站之间的传输线。UAL是美国航空公司的交通网络。节点是美国的机场,边缘是机场之间的现有航线。F2F是展览中的面对面行为网络。节点是展览的参与者,边缘代表一定时间内的F2F通信。SMG是另一个引文网络,其中节点是对经典文章的引用。YST是一种蛋白质-蛋白质相互作用网络。节点是不同的蛋白质,每个边界表示观察到两种蛋白质之间的相互作用。CORA和CITESEER是两个流行的引文网络,在图神经网络和链接预测的最新研究中被广泛用作基准数据集。数据的详细统计数据在表1中示出。较低的平均程度表示网络的稀疏性较高,这可能会给链接预测带来困难。

表1 详细统计数据
3.2 对比方法
为了充分证明所提出模型的有效性,本文将以下三种方法作为对比方法:
1) 基于邻域的启发式方法[9-11]:本文以六种传统启发式方法为基准,包括三种一阶启发式方法,即CN、Jaccard索引(JC)和优先连接(PA);两种二阶启发式算法,即Adamic Adar(AA)和资源分配(RA);和一个代表性的高阶邻域启发式SR。
2) 潜在节点嵌入模型[12-14]:学习网络节点的潜在嵌入是链路预测问题的另一个至关重要的方式。
矩阵分解(MF):基于矩阵分解的链接预测方法是最经典的潜在特征学习模型之一,它旨在基于节点潜在特征来重建用户对的二进制分数。
LINE:LINE是一种流行的通用网络表示学习方法,它分别学习一阶接近嵌入和二阶接近嵌入,并将它们串联为最终嵌入。
N2V:Node2vec是另一个代表性的节点嵌入模型。它通过随机行走对结构信息进行采样,并通过保留行走附近节点的相似性来学习嵌入。
PNRL:PNRL是最新的链路预测专用嵌入模型。该模型通过共同保存观察到的结构信息并预测假定的隐藏链接来学习嵌入。
3) 基于神经网络的模型[15-16]:随着神经网络在各种任务上的成功,提出了几种基于神经网络的链接预测模型。
图自动编码器(Graph Automatic Encoder,GAE)和变异图自动编码器(Variants Graph Automatic Encoder,VGAE):GAE和VGAE使用图卷积网络(Graph Convolution Network,GCN)将图邻接矩阵编码为潜在表示并重建观察到的链接或使用内部产品解码器预测未观察到的链接。
Weisfeiler-Lehman神经机器(Weisfeiler Lehman Neural Machine,WLNM):WLNM是用于链路预测的最先进的神经网络。它使用图标记算法将包围的子图转换为有意义的矩阵,该子图是节点对在结构上的组合邻域。然后,使用卷积神经网络(CNN)对标记的矩阵进行编码,并通过分类层预测链接分数。
SEAL:SEAL是另一个基于图神经网络的最新链接预测框架。它从局部封闭的子图学习一般的图结构特征。SEAL弥补了WLNM的一些缺点,深度图卷积神经网络(Depth Graph Convolution Neural Network,DGCNN)被用来代替WLNM中的CNN,从而实现了更好的图特征学习能力。
3.3 实验设置
为了更加有效地评估提出的模型,本文使用五重交叉验证设置进行比较实验。对于每个交叉验证,随机抽样原始网络的10%边缘进行测试,另外随机抽取10%进行验证,还分别对相同数量的非关联对进行了采样,它们分别与测试和对等阴性实例相符。本文删除采样的边缘,并将其余80%的边缘视为训练网络。链路预测性能是通过接收器工作特性曲线(Area Under Curve,AUC)下的面积测量的,该曲线是广泛使用的标准度量。
比较方法的详细参数设置如下。对于SR,本文遵循文献[12]中的设置,其中衰减率为0.6。所有潜在嵌入模型的嵌入大小均设置为64。对于LINE,负对比估计的采样数设置为5。对于N2V,窗口大小为10,步长为80,每个节点的步长为10。对于LINE和N2V,边缘特征为节点的Hadamard乘积嵌入。
对于预测性网络表示学习(Predictive Network Representation Learning,PNLR),噪声对比估计(Noise Contrast Estimation,NCE)的数量为5,使用秩损失以实现更好的性能,正则化权重为0.01,隐藏链接采样比为0.2。比较的神经网络模型的嵌入大小和隐藏大小也设置为64。对于VGAE,潜变量的维度大小为64,并使用默认的高斯先验。对于WLNM,文献[12]中的原始设置用于模型训练,其中,负样本是正链接的两倍,并且对不同的封闭子图大小10和20都进行了评估,分别表示为WLAN10和WLAN20。对于SEAL,使用推荐的设置。批大小为50,排序池的k为0.6,模型自动选择包围子图的跃点。用于检查验证集性能的早期停止策略用于训练所有嵌入和神经网络模型。
提出模型的详细参数设置如下:对于NAN模型,嵌入大小为64,潜在空间的数量为8,每个空间的尺寸大小为8,因此,总隐藏大小也为64,即8×8。对于负样本生成器,嵌入大小和隐藏大小均为64。对于鉴别器和生成器,将非线性激活函数σ(·)选择为指数线性单位。本文采用参数学习率为0.001的Adam更新规则。为防止过度拟合,对隐含单元和注意力应用了主动丢失技术,其权重为0.000 5的保持概率为0.8且L2正则化,还使用了相同的提前停止策略。
3.4 评估结果
实验结果如表2所示,为了验证改进的重要性,本文对提出模型与比较方法中最佳竞争对手之间的五倍交叉结果进行了配对t检验。
从实验结果,总结出以下发现:提出的模型实现了最优的预测性能。本文发现提出的NAN模型在十个数据集上显著优于所有比较方法,并且与其余两个数据集上的最佳方法相比仍具有很大的竞争力。这有力地证明了所提出的模型对于各种类型的网络上的链路预测普遍有效。
神经网络的广泛应用:与传统的启发式方法和节点嵌入方法相比,基于神经网络的模型在不同网络之间稳定地展示了良好的性能。这表明神经网络的引入能够有效提升预测性能。
NAN对邻域编码更有效:GAE、VGAE、WLNM和SEAL使用不同的方法进行邻域编码。与这些方法相比,NAN的性能始终更好。这归因于引入的注意力机制,该机制全面捕获了结构重要性并提取了邻域的普遍潜在特征。
跨邻域关注对预测性能提升有利:可以发现CNAN在大多数数据集上始终优于SNAN。与SNAN相比,CNAN通过交叉注意力直接捕获结构交互,从而在注意力层探索了更明确的链接线索。V-E4部分中的可视化示例也验证了交叉注意力的良好区分能力。
3.5 NAN的分析
多空间邻域的有效性注意:为了证明所提出的MSNA的有效性,本文针对以下邻域编码方法进行了对比实验。
AVG:此编码方法仅通过取邻居所有嵌入的平均值来构造邻域嵌入。
单空间注意(Single Space Attention,SSA):这是一种通用的SSA机制,在对节点特征进行线性映射后,在单个潜在空间中计算注意力,其中维是MSNA中多个空格的总维。
图形注意力(Graph Attention,GA):GA是一种针对图形的最新注意力机制,输入是节点特征的线性映射。
由于上述竞争方法不能直接用于链接预测,因此将它们全部放入提出的框架SNAN中进行性能评估。根据表3中的结果,可以发现集中注意力收集邻域的信息是有利的,这可以通过所有基于注意力的方法在大多数情况下胜过AVG方法来证明。相邻节点在邻域关系中具有不同的重要性,注意机制可以从结构信息中捕获这种重要性,从而提取出更好的邻域特征。在MSNA中,注意力集中在多个潜在空间中,这将从不同潜在方面构建更全面的上下文特征。此外,角色专用连接层的设计使MSNA能够深入探索邻域的非线性结构关系和特征。提出的MSNA胜过其他的注意机制。

表3 性能评估对比表
参数敏感性:提出的注意力机制能够对不同阶数的邻域进行编码,因此,首先证明邻域范围的影响。如图2所示,比较了从一阶到五阶的五个范围大小,可以发现一阶邻域信息对于大多数数据集的链接预测而言更为重要,然而HTC、CORA、CITESEER和UPG的四个稀疏数据集是例外。考虑使用高阶数邻域有助于减轻稀疏性,并在这四个数据集上获得较大的改进。同时,即使引入了更多无关的邻域信息,所提出的模型也可以获得相对鲁棒的性能。这归因于注意力机制,可以选择性地编码更重要的邻域。

(a) 在邻域范围内的表现
进一步研究了潜在空间的数量和维数大小如何影响模型。以三个数据集为例,而其他数据集具有相似的结果。如图3(a)所示,更多的潜在空间可以提高模型的预测能力。但是,当数量达到一定水平时,改进效果会变弱。尺寸大小具有相似的特征。如图3(b)所示,当维数变大时,模型的性能会更好,但当维数超过一定比例时,模型性能的改善效果会越来越弱。增大潜在空间的数量或尺寸大小不可避免地会增加计算复杂性。因此,在实践中应该综合考虑性能和效率的关系。
(a) 稀疏网络CITESEER
性能稀疏度:进一步分析所提出模型的性能稀疏性。以最稀疏的网络之一CITESEER和最密集的网络PLB之一为例。如图3所示,当剩余边缘减少时,即稀疏度增加,两个模型的AUC分数在两个网络上都会降低。由于PLB的稀疏性较低,即使删除了50%的边缘,PLB的性能也相对稳定。另外,CNAN的性能始终优于SNAN,而当网络变得稀疏时,改进的幅度更加明显。这可以归因于CNAN的交叉关注,每个节点在稀疏网络中只有很少的邻域,因此,SNAN仅从自邻域捕获非常有限的链接线索,而CNAN可以利用来自邻域的更多信息,从而缓解这种情况。
注意力可视化:如图4所示,将KHN中的学习注意力示例可视化,在该示例中,将潜在空间的数量设置为4。第一幅图像显示了节点240的自邻关注。第二个绘制正样本的交叉注意力,即节点1 504对节点240的邻域关注,其中节点1 504与节点240链接。第三幅图是负样本的交叉注意力,即节点1 390未与节点240链接,颜色越深,表示关注度越高。
可以发现,在多个潜在空间中,对邻域的学习注意力有所不同。进一步说明提出的注意力机制从不同的潜在方面抓住了结构的重要性,而每个潜在方面都有不同的重点。另外,交叉注意力具有很好的区分性。如果这对节点是链接的,则学习的注意力和自我注意就很好地匹配,如图4(a)和图4(b)所示,但是如果节点没有链接,则交叉注意和自我注意之间会有很大差异。如图4(a)和图4(c)所示,具有交叉注意力的交互可以进一步提高预测能力。
3.6 对抗学习分析
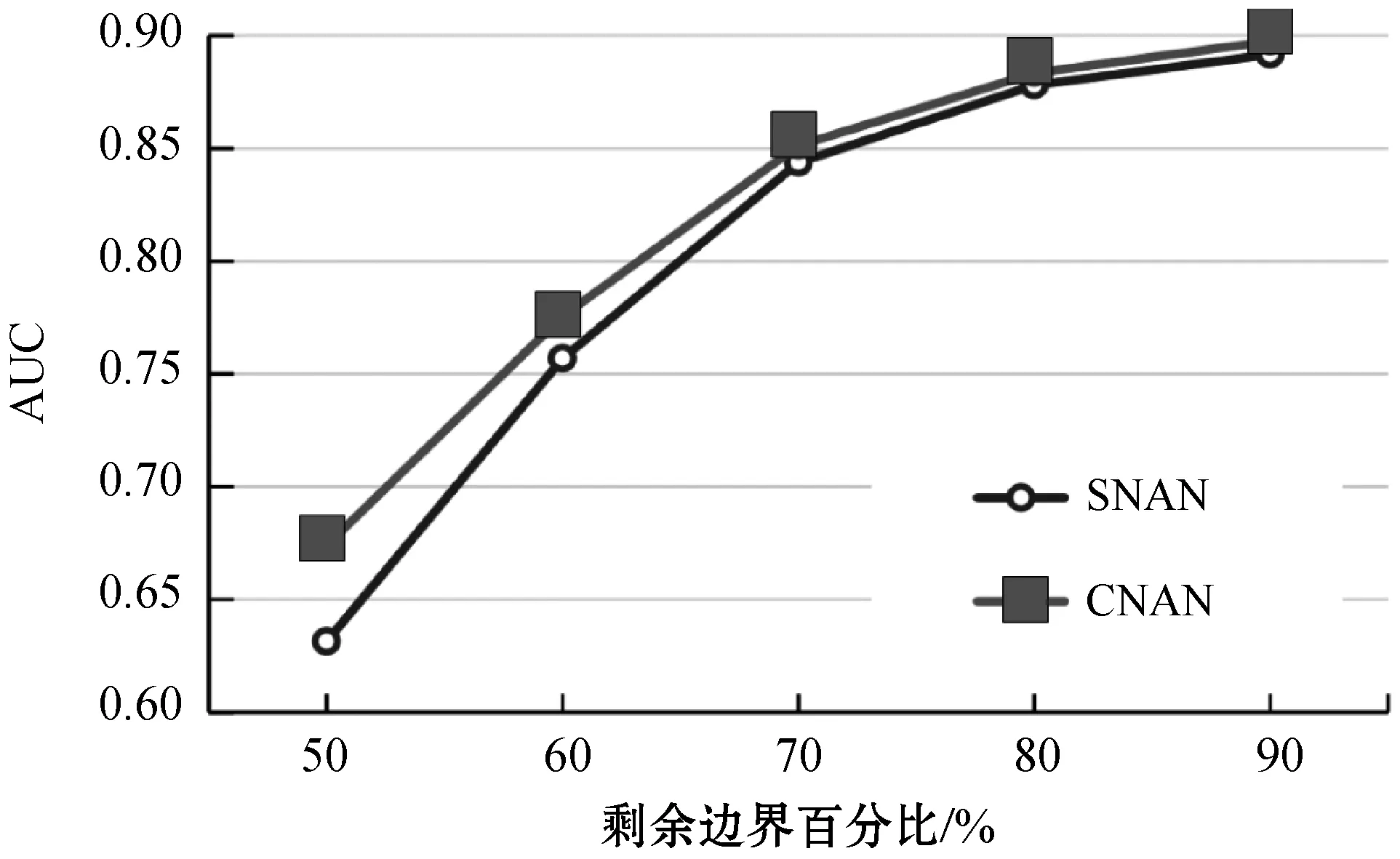
为了验证对抗学习的有效性和鲁棒性,在提出的对抗学习和随机否定采样策略之间进行了比较实验。由于空间有限,在该消融研究中选择了两个最困难的网络,即CEG和UPG。实验进行了十次,每一次都通过五重交叉验证设置进行评估。为了更清楚地可视化性能变化,在x轴的中间绘制了最佳结果,而在两侧则绘制了较差的结果。如图5所示,在两个数据集上,对抗学习的平均性能始终优于随机抽样。另外,对抗学习的方差比两个数据集上的随机抽样都要低约50%。尽管随机采样有机会获得良好的性能,但它不是很稳定。对抗学习通过在学习过程中不断生成高质量的否定样本来显著提高NAN模型的有效性和鲁棒性。
(a) CEG数据集
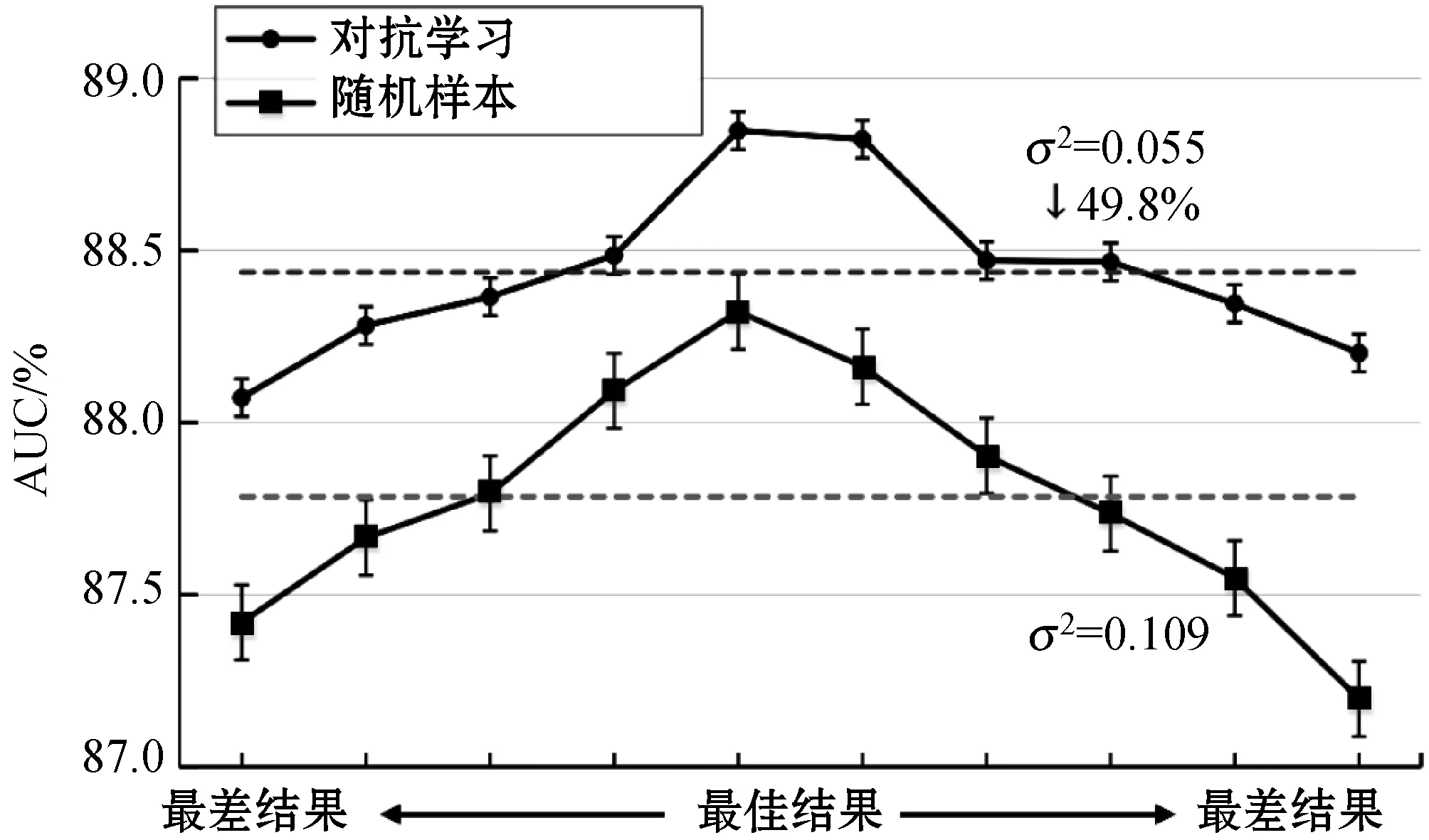
此外,研究了对抗学习和随机抽样之间的学习曲线差异。以CEG数据集为例。如图6所示,随机采样在50个周期后实现了相对较低的损耗,但是在此之后性能几乎没有提高。正如上文所提到的,经过一定时间的训练后,大多数负面样本都是学得很好的,随机样本可能总是提取没有信息或较少信息的样本,因此,性能可能会停滞不前。与随机抽样相比,在50个周期后对抗学习的损失明显更高,这意味着对抗学习会产生更多的信息性负面样本。因此,停滞的可能性较小,并且进一步提高了性能。
(a) 损耗曲线
4 结 语
针对传统链路预测模型无法充分挖掘邻域特征信息,且模型的泛化能力不强等缺点,提出了一种基于对抗学习邻域注意网络的链路预测。通过在12个基准数据集上评估所提出方法的性能可以得出如下结论:
(1) 提出的模型对于各种类型的网络上的链路预测普遍有效,且能够保证较好的预测性能。
(2) 引入的注意力机制,该机制全面捕获了结构重要性并提取了邻域的普遍潜在特征,对邻域编码更有效。
(3) 通过交叉注意力直接捕获结构交互,从而在注意力层探索了更明确的链接线索,能够有效地提升链路预测性能。
(4) 更多的潜在空间可以提高模型的预测能力。但是,当数量达到一定水平时,改进效果会变弱;当维数变大时,模型的性能会更好,但当维数超过一定比例时,模型性能的改善效果会越来越弱。
