面向领域自适应的部分最优传输高光谱图像分类
2023-10-02王碧琳王生生
王碧琳,王生生*,张 哲
(1.吉林大学 计算机科学与技术学院,吉林 长春 130012;2.中国科学院 苏州生物医学工程技术研究所,江苏 苏州 215163)
1 引言
随着航天技术和电子信息科学的发展,遥感器分辨率及信息处理能力不断提高,遥感技术已被广泛应用于气象观测、精准农业和土地利用规划等多个领域[1-3]。高光谱图像由多空间平台的成像光谱仪采集,结合光谱仪和光学相机的优点,实现目标区域的大范围细粒度成像,采集图像数据中包含丰富光谱-空间结构信息。基于像素空间关系及多波段光谱信息,高光谱图像分类技术致力于实现图像中地物精准分类,逐像素分配语义标签,对后续多种复杂地球信息的分析研究具有重要意义。
由于时空环境变化和图像采集设备不同,高光谱图像通常处于不同数学概率分布,数据特征偏移明显。在已有标注的源域数据集上训练的模型难以直接有效迁移到新捕获的无标注目标域数据。数据标注工作依赖专业设备和领域内专家,耗时费力,难以收集足够的标注数据。标注数据的缺乏对构建高精度高光谱图像分类模型带来了巨大挑战。
为解决域偏移导致的模型迁移困难问题,领域自适应技术通过缩减源域数据与目标域数据间的分布差异实现模型适配。当前领域自适应技术通常采用基于深度学习的方法,构建神经网络模型提取样本高维特征,衡量特征分布差异,利用神经网络迭代反馈促使域对齐[4]。Liu 等[5]提出建立特征提取器与多个域鉴别器对抗学习模型结构,引入基于概率分布的最大均值差异方法,有效提升模型特征比较能力。Miao 等[6]提出联合分布对齐框架,采用变分自编码器学习在共享空间中学习域不变表示,实现细粒度跨域比对。Fang 等[7]提出将领域自适应与自信学习相结合,选取高置信度的目标域样本作为训练数据,并逐步增加高置信度样本的比例,从而提升分类准确性。Liang 等[8]提出多源few-shot 学习方法,从源域融合同质和异质数据内提取特征,提升分类模型的泛化能力。Makkar 等[9]基于对抗学习提取一致特征,采用半监督方法扩展可用标签,模型在多类别大尺度遥感图像上取得了优异效果。
为进一步减小源域和目标域的分布差异,缓解域偏移,结合高光谱遥感图像性质,本文提出一种基于部分最优传输的域适应方法,引入类感知批量样本采样技术和质量分数因子自适应调整策略,促进同类别像素样本间建立传输映射,缓解类别错误对齐。在建立传输方案时考虑目标域样本伪标签置信度,通过计算熵可靠性自适应调整传输质量分数,促进构建全局最优映射,优化传输方案,减小分布差异,提升分类模型精度。
2 基本原理
2.1 无监督领域自适应
神经网络模型训练依赖于大规模有标注样本。然而,由于数据分布不同,在已有标注的源域训练集上学习的模型通常难以在新出现的无标注目标域数据上取得同样优异的表现。为了充分利用已有的数据信息,提高模型在多源分布数据上的鲁棒性,无监督领域自适应(Unsupervised Domain Adaptation,UDA)方法通过基于对抗或基于散度的方法对域间差异进行准确度量,挖掘域不变信息或减小域间分布差异,从而使源域模型同样适用于目标域数据。基于以上构想,Ben-David 等提出了无监督领域自适应的优化泛化误差界[10]。具体公式如下:
其中:h∈H为假设函数空间中分类函数。函数h在目标域数据上的分类误差εT(h)由源域分类误差εS(h)、源域与目标域间分布差异dHΔH以及常数项λ约束。因此,无监督领域自适应算法的关键是在保证分类函数h适配于源域样本的同时最小化源域与目标域间的分布差异。进一步,对源域与目标域分布间差异的准确度量至关重要。
2.2 最优传输
最优传输(Optimal Transport,OT)理论在18 世纪由Gaspard Monge 提出,旨在通过优化寻找概率测度间变换。Kantorovich 将求解多个数学分布之间的变换问题松弛化为求解满足条件的联合概率分布,从而有效衡量不同分布间的差异[11-12]。假设存在两组处于不同分布的样本点X:=和Y:=组成的两个离散概率分布μn:=和νn:=,则分布μn与νn间的最优传输优化问题定义如下:
其中:C是分布间的传输成本矩阵,π为分布间的概率耦合。在域适应问题中,为最小化域间分布差异,建立全局最优传输方案准确度量域间距离,在样本间建立传输,通过反向传播更新高维特征,实现样本级别分布对齐。
3 部分最优传输域适应图像分类算法
3.1 问题定义
假设存在两组由成像光谱仪采集的处于不同分布的高光谱遥感图像数据,两组数据中包含相同的地物类别。图像数据中任意像素位置均包含多个光谱多段信息,在模型构建及训练中,将图像中像素逐一作为数据样本。源域HS为有标注样本集XS=,包含M个像素样本,对应像素位置的标签为YS=。目标域HT为无标注样本集XT=,包含N个像素样本。源域与目标域像素地物类别空间YS(T)∈{1,2,…,C}相同,均包含C个类别。源域分布与目标域分布分别表示为和。
3.2 算法原理
根据基于散度的领域自适应方法框架,利用度量函数衡量域间差异,通过不断缩减源域与目标域间距离学习域不变特征,实现模型迁移。域适应模型构建中需要解决的关键问题在于如何准确衡量复杂分布间差异,以及如何通过调整特征提取器参数实现源域与目标域特征在高维空间中对齐。
针对以上问题,本文提出基于部分最优传输的领域自适应模型,算法框架如图1 所示。对于传入的源域与目标域数据,采用共享多层卷积神经网络Gθ作为特征提取器,将数据映射到潜在高维特征空间。对于提取到的数据特征,采用基于部分最优传输的度量函数,通过类感知样本采样以及质量分数因子自适应调整策略,构建样本间最优传输方案,准确衡量域间差异。进一步,利用两个不同的由全连接网络构造的分类器Fφ和Fφ之间的对抗学习,挖掘难以辨别的样本特征从而实现特征对齐。通过分类器Fφ计算源域样本分类损失,保证模型在域不变特征上具备分类能力。
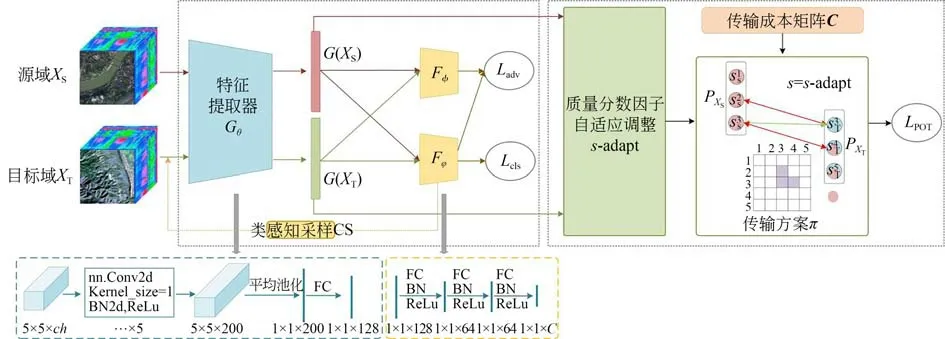
图1 基于部分最优传输的领域自适应模型整体框架Fig.1 Framework of proposed domain adaptive model base on partial optimal transport
3.2.1 部分最优传输
对于离散样本集,最优传输算法通过建立样本间的全局映射,根据样本间传输成本矩阵,计算最优全局传输方案,从而准确度量离散分布间差异。然而,高光谱图像数据通常包含数以万计离散样本点,直接建立全局映射面临严重运算存储问题和难以接受的计算复杂度。因此,在实际计算中,通常采用批量样本采样方法,在每次迭代中仅使用原始数据集中的小部分样本参与训练,从而提升模型迭代效率。在此情况下,每次映射仅有部分像素样本参与,无法保证域间最优样本匹配同时采样在当前批量,导致计算得到的最优映射存在偏差,域间样本次优对齐,影响模型到目标域数据的适配效果。
针对以上问题,部分最优传输(Partial Optimal Transport,POT)算法[13]通过在传输过程中设置质量分数因子控制样本质量映射,避免局部次优传输导致的负迁移。依照定义,离散概率测度μn与νn间的部分最优传输优化问题如下:
3.2.2 类感知样本采样
基于部分最优传输理论构建域间差异损失,为进一步促进最优传输的建立,预先避免由于域间样本类别不一致导致的传输干扰,提出类感知样本采样方法(Class-aware Sampling,CS),通过显式采样控制每次迭代中批量样本的类别,期望存在相同类别的域间样本,为类级别特征对齐以及建立最优匹配传输奠定基础。首先,在训练过程中利用源域数据训练的分类器Fφ计算目标域样本类别的伪标签:
3.2.3 质量分数因子自适应调整
已有基于部分最优传输的方法通常在不同域适应任务中采用显式设置质量分数因子的方式,在模型开始训练前固定因子数值,通过多次训练观测不同质量分数因子下的模型分类效果,确定最优数值[13]。然而,由于数据集规模不同、分布差异不同,难以预先准确估计质量分数因子的具体选取区间,并且批量采样的训练方式进一步加剧了固定因子数值难以适配到全部最优传输建立的情况,导致分布差异度量准确性严重受到质量分数因子的限制。
为解决以上问题,这里提出一种基于目标域样本分类预测熵可靠性的方法,自适应调整质量分数因子s的取值(s-adapt)。假设最优传输映射存在比例受当前批量样本类别匹配度的影响,考虑目标域样本预测伪标签的可信度,将目标域样本分类输出向量的熵正则化结果融入质量分数因子的计算中,每次迭代前更新质量分数因子s,实现自适应调整,计算公式如下:
3.3 优化目标函数
基于深度学习卷积神经网络构建分类模型,期望在反向传播时更新特征提取器和分类器参数,特征在潜在高维空间实现对齐,在建立损失函数中综合考虑模型分类能力、域特征间分布差异检测能力,对模型训练中建立的各项损失函数进行介绍。
对于特征提取器Gθ得到的特征,根据无监督领域自适应泛化误差[10],需要确保分类器可以对模型挖掘到的域不变特征准确分类。因此,基于交叉熵损失函数lce计算源域样本分类损失:
进一步,采用基于边际差异MDD 的域差异测度[14],设置两个分类函数Fφ,Fφ,计算分类器间对抗损失,利用分类结果一致性损失度量域间差异,disp(,)函数表示分类器结果差异,计算公式如下:
结合以上目标函数,模型整体优化问题由三部分组成,分别是源域样本分类损失Lcls、域间分布差异损失LPOT以及源分类器间对抗损失Ladv。整体优化目标函数如下:
其中:α,β为平衡因子,平衡各个损失项在模型训练中所占的比例。
4 实验与结果
4.1 数据集
为验证本文模型的有效性,在两组公开高光谱遥感图像数据集上进行实验,包括Pavia 数据集和Houston 数据集。
4.1.1 Pavia 数据集
Pavia 数据集[15]由反射光学光谱传感器ROSIS 于2003 年在意大利北部上空采集,其中包含Pavia University(UP)和 Pavia Center(PC)两组数据,波长为0.43~0.86 μm,空间分辨率为1.3 m/pixel,均为城市场地图像。UP 数据实验过程中,将UP 与PC 分别作为源域与目标域数据,并移除UP 中最后一个光谱波段,使UP 与PC拥有相同的光谱波段数量,均为102,同时选取共有的7 种地物类别用于构建分类模型。伪彩色图像及对应的地物类别标签如图2 所示。表1 显示了Pavia 数据集中包含的地物类别及对应的样本数量。

表1 Pavia 数据集中的地物类别及样本数Tab.1 Land cover classes and numbers of samples in Pavia dataset

图2 Pavia 数据集的伪彩色图和地物标签Fig.2 Pseudocolor images and corresponding ground truths with color indexes of Pavia dataset
4.1.2 Houston 数据集
Houston 数据集[16]包 括Houston2013(H13)与Houston2018(H18)两组数据,由不同传感器于不同年份在美国休斯敦上空采集,空间分辨率分别为2.5 m/pixel 与1 m/pixel,包含波段数量分别为144 个和48 个,波长均为380~1 050 nm。实验过程中,将Houston2013 与Houston2018 分别作为源域与目标域数据,选取Houston2013 数据中与Houston2018 数据相对应的48 个光谱波段和共有的7 个类别。伪彩色图像及对应的地物类别标签如图3 所示。表2 显示了Houston 数据集中包含的地物类别及对应的样本数量。

表2 Houston 数据集中的地物类别及样本数Tab.2 Land cover classes and numbers of samples in Houston dataset
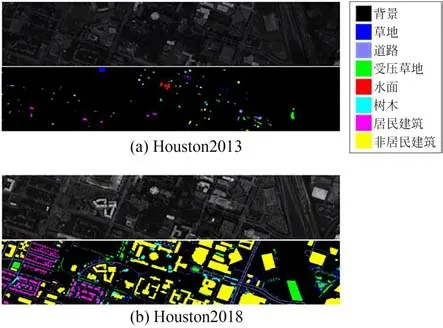
图3 Houston 数据集的伪彩色图和地物标签Fig.3 Pseudocolor images and corresponding ground truths with color indexes of Houston dataset
4.2 实验分析
4.2.1 评价指标
为检验本文提出方法的有效性,采用总体精度(Overall Accuracy,OA)、平均精度(Average Accuracy,AA)和Kappa 系数3 种指标评价模型的分类性能。其中,OA 计算正确分类样本个数占所有样本数量的比例,评估模型对数据的整体分类能力;AA 则分别在每个类别上计算精度,反映模型对数据中各个类别的分类能力;Kappa 系数则是基于混淆矩阵计算,用于一致性检验,当模型出现强偏向性时,计算出的Kappa 数值降低,反映模型出现了类别预测偏向性。
4.2.2 实现细节
本文研究基于Pytorch 框架,利用Nvidia 2080Ti GPU 实现。在训练集和测试集构建过程中,为有效利用空间关系信息提高网络特征的提取能力,在构建样本时,将每个像素本身及其周围两个像素看作一个样本,即每个样本尺寸均为5×5,通道数为波段数量,样本标签为中心像素所属类别。模型训练时,为了避免由于样本类别不平衡导致的分类器偏移,参考Fang 等[7]提出模型中的实验设置,对于有类别标注的源域样本,在每个类别中随机采样180 个样本用于模型训练,而目标域中包含的全部样本均参与随机采样,训练过程中不使用类别标签。特征提取器Gθ由多层卷积神经网络构成,将样本特征映射到200 维,并利用平均池化及全连接映射将每个样本表示为128 维向量,用于后续训练分类网络。分类网络Fφ,Fφ均为两层全连接层网络,进行128→64→C过程映射,最终输出地物类别数量长度的向量作为分类结果。采用随机梯度下降法训练模型,动量因子为0.9,权重衰减系数为0.000 5,学习率设置为0.01,批量采样大小为64,迭代轮次为100。在平衡因子α,β的选取上,利用网格搜索法调整参数,在固定其中一个参数α(β)时,对另一个参数β(α)在{0.05,0.1,0.5,1,5}内进行调整,选取模型OA 最高时的参数值。具体地,对于Pavia 数据集和Houston 数据集,参数(α,β)分别设置为(1,0.5)和(1,0.1)时,模型OA 最优。
4.2.3 分类结果
在UP→PC,Houston2013→Houston2018 两组域适应迁移任务上进行实验。为验证本文提出模型的效果,将分类结果与当前已有方法进行对比,比较方法包括TSVM[17],DAN[18],DANN[19],ED-DMM-UDA[20],CDA[5]以 及CLDA[7]。以上方法的实现细节及结果参照方法CLDA[7]文中结果。
两组迁移任务的量化像素级地物分类结果如表3 所示。可以看出,基于深度学习的方法优于传统方法TSVM,证明了神经网络结构能够有效挖掘样本特征,基于对抗和散度的方法在高维空间上对齐源域与目标域,提高了模型适配能力。对于迁移任务UP→PC,本文方法相较于TSVM 方法提升17.64%,相较于采用聚类的方法ED-DMM-UDA、利用伪标签的方法CDA、采用自信学习进一步筛选伪标签的方法CLDA 在OA 上分别提升11.7%、3.89%和0.87%,相应的AA 及分类一致性Kappa 结果同样得到了提升,证明了本文提出的类感知采样方法和随后的质量分数因子自适应调整方法充分利用了伪标签信息,指导域不变特征挖掘,实现了更加精确的类级别特征对齐,提升了模型的分类精度。对于迁移任务H13→H18,虽然本文方法相较于已有方法存在小幅度提升,但在分类精度上仍低于80%,推测原因是当前源域与目标域的分布差异更为明显,因此从初始训练时取得的目标域样本的伪标签准确度不高,导致其指导的类感知采样及后续质量分数因子调整均受到较多错误标签的影响,建立的传输难以达到最优。从一致性检验系数Kappa 值可以看出,模型对于分类类别具有较强的倾向性,后续考虑在模型构建中进一步针对各个地物类别特点优化特征提取器和最优传输算法。

表3 目标域上不同方法在OA、AA 和Kappa 上的分类结果Tab.3 Classification performance on OA,AA(%)and Kappa of different target domains
图4 展示了部分已有方法及本文提出方法的像素级地物分类效果。可以看出,本文方法的分类效果更加精细。较为明显的是,对于处于地物不同类别间边缘的像素,本文方法获得了更为清晰的地物轮廓边缘。由于处于边缘的像素通常存在更复杂的空间上下文关系,提取到的特征往往区别于地物中心位置的像素,因此,需要与源域建立更为准确的映射关系。本文提出的基于部分最优传输的域适应方法实现了类级别的样本传输,有助于缓解样本负迁移,提升了分类模型的稳定性。
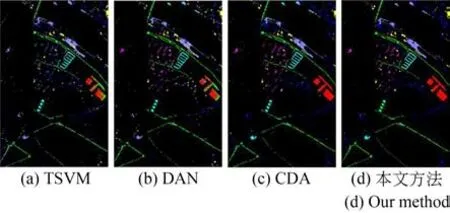
图4 不同方法在PC 数据上的分类效果Fig.4 Classification maps of PC dataset produced by different methods
4.2.4 消融实验
为了验证本文提出的基于部分最优传输的无监督领域自适应高光谱图像分类模型中各个模块的有效性,分别讨论部分最优传输算法POT、类感知样本采样CS 以及质量分数因子自适应调整算法s-adapt 对模型分类的影响。在两组域适应迁移任务UP→PC,H13→H18 上进行实验,实验结果如表4 所示。基线方法采用模型中的源域分类损失和双分类器一致性损失进行训练,即式(9)中的Lcls+Ladv。可以看出,相比于基线方法,在模型中加入原始最优传输方法OT作为度量函数计算域间差异损失,在两组迁移任务上分别提升0.5%和0.74%。在此基础上,添加类感知采样法CS 对分类结果进一步提升了0.89%和1.03%,证明了类感知采样方法通过建立特定类别间的传输可以更好地对齐特征。相比于传统OT 算法,采用部分最优传输POT,即使在固定质量分数因子s=0.5 的情况下,模型分类精度仍有提升,证明POT 能够避免由于原始强制传输导致的样本错误迁移,建立更加适宜的传输方案,提升了模型的适配能力。当运用质量分数因子自适应调整策略s-adapt 后,质量分数因子随当前批量传输样本的熵可靠性自适应变化,相比于固定s=0.5,分类模型精度分别提升了0.62%和0.82%,反映出质量分数因子s的取值对POT 传输方案具有重要作用。
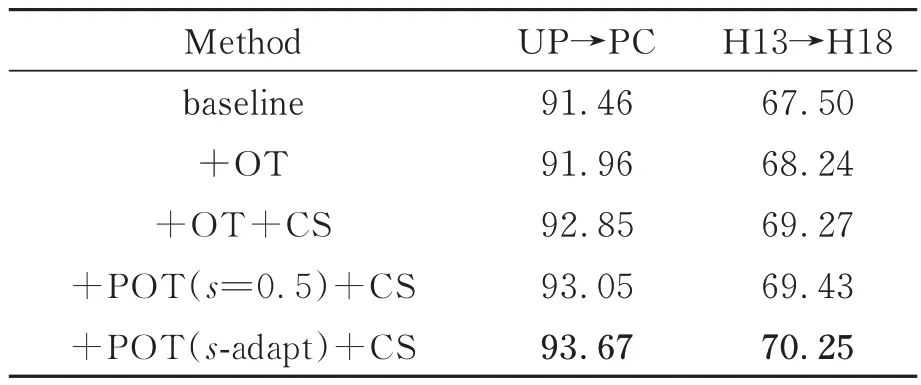
表4 不同迁移任务消融实验分类结果OATab.4 Ablation study classification results of OA with different transfer tasks (%)
5 结论
本文提出基于部分最优传输的无监督领域自适应方法用于高光谱图像分类,以缓解由于标注数据不足导致的模型训练困难的问题。研究部分最优传输算法在批量采样神经网络训练中的作用、类感知采样方法以及质量分数因子自适应调整算法对建立传输方案的影响,并在两组公开的高光谱遥感数据上进行实验。实验结果表明,相比于基线方法,本文方法建立的分类模型在两组迁移任务上的地物分类结果分别提升2.21% 和2.75%,验证了算法各个模块的有效性。
