面向高光谱医学图像分类的空-谱自注意力Transformer
2023-09-27李远时旭杨正春谭崎娟黄鸿
李远, 时旭, 杨正春, 谭崎娟, 黄鸿*
(1.重庆大学 光电技术与系统教育部重点实验室,重庆 400044;2.重庆市妇幼保健院 超声科,重庆 401147;3.重庆大学附属肿瘤医院 影像科,重庆 400030)
1 引 言
高光谱成像(Hyperspectral Imaging, HSI)技术是一种先进的图像空间信息与光谱信息提取技术,能同时获取拍摄对象的二维空间信息和一维光谱信息,覆盖可见光、红外和紫外等光谱范围,其已成功应用于遥感监测、艺术保护以及食品安全等[1]。在生物医学领域,高光谱成像作为一种非侵入性的辅助诊断手段,因其可提供有关组织生理、形态和生化成分的诊断信息,为生物组织学研究提供精细的光谱特征,正逐渐受到广泛关注[2-5],并已成功应用于非侵入性疾病的诊断和监测[6-7]、图像引导的微创手术[8]和药物剂量评估[9]等。近年来,随着精准医学理论的高速发展,如何针对高光谱医学图像高维度、高冗余度以及“图谱合一”的特点,设计高效与精确的诊断算法已成为高光谱医学图像分析领域的研究热点。
传统的高光谱医学图像分类方法通常在提取手工特征之后,使用分类器对其分类。Duan[10]等提出一种旋转不变的局部二值化模式作为纹理特征,同时结合形状特征和光谱特征,采用支持向量机(Support Vector Machine,SVM)对白细胞进行分类。Ruiz[11]等使用SVM和随机森林(Random Forest, RF)对活体大脑高光谱图像进行分类,验证了传统分类方法的潜力。Baltussen[12]等对腹腔镜获取的结肠癌高光谱图像进行特征提取后,采用SVM对三种组织类型进行区分。然而传统的高光谱图像分类方法无法提取深层特征,其性能受到很大限制。
近年来,深度学习作为一种端到端的方法,已开始应用于高光谱医学图像处理领域。其中,卷积神经网络(Convolutional Neural Network,CNN)成为主流,其使用局部感受野,并且随着网络层数的加深,逐渐提取深层特征,在诊断任务中表现优异。Huang等[13]提出了一种将调制Gabor小波与深度卷积神经网络核相结合的血细胞分类框架(Modulated Gabor CNN,MGCNN),将调制Gabor滤波与卷积神经网络相结合,对血细胞进行分类。Wei[14]等设计了一种双通道CNN提取局部特征与全局特征,取得了比传统卷积神经网络更好的分类结果。Zhang[15]等提出了一种基于卷积组合单元的三维卷积神经网络(3DPulCNN),对肺癌三种亚型进行分类。Hu[16]等提出一种空-谱联合卷积神经网络,对胃部病理组织进行识别。然而,高光谱图像波段数量丰富,传统的卷积神经网络无法在长距离波段之间挖掘有效的关系信息,并扭曲其原有的光谱序列关系。这限制了卷积神经网络方法在高光谱医学图像上的性能。
Vision Transformer(ViT)以其强大的全局建模能力而受到广泛关注[17]。ViT中的自注意力机制,可以捕获长距离光谱波段间的关系,更好地对光谱序列建模,已在高光谱医学图像领域取得一定成效。Zhou等[18]提出一种 Swin-spectral Transformer用来获得有效的光谱和空间特征表示。Li[19]等提出一种光谱纹理Transformer,用来感知光谱上下文信息。Li[20]等提出一种多层协同生成对抗Transformer,用于缓解高光谱医学标记样本数量的不足,加深而受限的问题。然而高光谱医学图像在获取过程中,由于采集设备、操作手段,以及预处理方式(光谱矫正、降噪以及解混等)的不同,其光谱分辨率、空间分辨率也往往不同,所拍摄生物组织的光谱曲线差异较大。因此,每个具体的诊断任务往往需要设计不同的算法。当上述算法应用于不同的诊断任务时,其性能难以满足更进一步的精度需求。
最近,研究人员开始结合Transformer模型和空-谱注意力机制,以提升高光谱图像分类的精度。空-谱注意力机制可以更好地捕捉关键的空间和光谱信息,并根据不同类型的高光谱图像的特点挖掘关键的空-谱信息。Peng[21]等设计了一种双分支结构的交叉空-谱注意力,其中空间分支用来获取细粒度的空间信息,光谱分支用来建立光谱序列之间的关系。Ouyang[22]等提出一种空-谱注意力机制,用于依次捕获空间信息和光谱信息,使模型更加关注差异化的空间和光谱位置。Liu等[23]提出一种双流深度空-谱注意力机制,分别用于关注空间维度和光谱维度的特征。然而,这些空-谱注意力机制只是简单地将输入特征分别处理成光谱序列或空间序列,再依次或并行使用自注意力机制对这两种序列进行长距离关系捕获,并未对自注意力机制本身进行改进,使其具备空-谱特征提取能力。此外,这些高光谱图像分类算法中,往往只进行单一地输出预测,未能结合多个视野的信息对图像类别进行综合预测,这给模型的性能带来了瓶颈。
基于此,本文提出了一种空-谱自注意力Transformer (Spatial-spectral Self-attention Transformer, S3AT)。首先,为了适应不同仪器设备所采集的高光谱医学图像的空-谱信息密度不同,该模型在原有自注意力机制基础上,将空间注意力和光谱注意力融入自注意力机制中,寻找空间特征和光谱特征之间的内在关联,得到空-谱自注意力。其次,将不同空-谱Transformer编码器中的卷积核大小设计为不同尺寸,以获得不同视野下的空-谱自注意力,并对其进行融合。在最后分类过程中,网络在不同视野下分别进行预测,并将预测结果使用可学习的预测权重进行融合,形成最终分类结果。在In-vivo Human Brain 和 BloodCell HSI数据集上进行的实验表明,该方法充分挖掘了空-谱特征,有效地融合不同视野下获取的信息,在不同仪器所获得的高光谱医学图像上均具有明显的精度优势。
2 空-谱自注意力Transformer(S3AT)
本文所提出的S3AT算法如图1所示。首先以高光谱图像的一个像素点为中心取出一个图像块作为样本,沿光谱维将图像块展开后输入S3AT网络。网络由三阶段空-谱Transformer编码器组成,其内部卷积核的空间感受野(kernel size)依次由大到小。在每个阶段的编码器中,所获得的空-谱自注意力会与之前更大视野下所获得空-谱自注意力进行融合。最后,通过可训练系数对这些不同视野下预测进行加权融合,形成最终的输出结果。下面对空-谱Transformer编码器和预测加权融合分别进行介绍。

图1 空-谱自注意力Transformer流程图Fig.1 Flowchart of spatial-spectral self-attention transformer
2.1 空-谱Transformer编码器
在不同仪器、不同获取条件获得高光谱医学图像中,信息在空间像素间、光谱波段间的分布往往存在较大差异,这需要模型精细地描绘像素与像素间、波段与波段之间的关系,自适应地挖掘空间信息与光谱信息之间的内蕴关联。因此,本文设计了一种空-谱Transformer编码器,其如图2(a)所示。首先,通过层归一化、线性层和Reshape(sequence to patch)操作,将输入特征映射为三个矩阵Q∈Rb×w×w,K∈Rb×w×w和V∈Rb×w×w,其中w为特征的空间尺度,b为特征所含波段数。随后,这三个矩阵输入空-谱自注意力(Spatial-spectral Self-attention,S3A)机制模块,以获取空-谱特征。在空-谱自注意力模块中,将Q输入空间注意力模块,以精确地挖掘高光谱医学图像中不同像素间的关系,赋予特征图不同空间位置的以不同的重要性,提取更加具有鉴别性的空间特征,其具体结构如图2(b)所示。首先通过全局最大池化和全局平均池化对Q的通道域特征进行压缩,并将所得的两个特征沿通道维进行拼接。接着,通过一个卷积层将这个二通道特征转换为单通道特征,再以一个Sigmoid函数对其激活得到空间注意力。此过程可表示为:
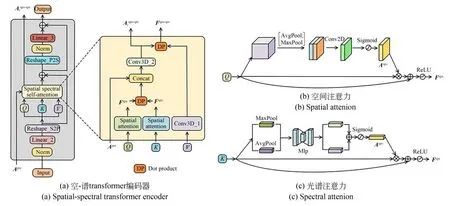
图2 空-谱Transformer编码器结构图Fig.2 Structure of spatial-spectral transformer encoder
其中,AvgPool(·)表示平均池化操作,
[·]表示特征图拼接,MaxPool(·)表示最大池化操作,Sigmoid(·)为Sigmoid激活函数操作,fn×n(·)表示卷积层,其中n表示感受野大小。将Q与空间注意力进行点乘并残差连接,再以ReLU函数激活,可得空间特征:
获取空间特征之后,为了精确地描绘波段与波段之间的关系,更好地赋予不同波段以不同权重,提取对诊断有帮助的波段,将K输入光谱注意力模块,其结构如图2(c)所示。首先,使用最大池化和均值池化,把K的每个波段内的空间特征信息进行压缩。然后采用MLP对压缩特征进行映射,以提高压缩信息的迁移能力。最后,在每个波段上对两种压缩方式得到的压缩信息相加融合并以Sigmoid函数激活,得到光谱注意力。这个过程可表示为:
其中,MLP(·)为多层感知机。随后可得光谱特征:
为了获得空间特征和光谱特征的内蕴关联,详细地刻画高光谱医学图像空-谱信息分布,将Fspa和Fspe进行点积,可得本层编码器下空-谱自注意力。为了更好地利用不同视野下所获得的空-谱自注意力,对不同视野下所获的关键空-谱信息进行整合,本文设计的空-谱自注意力中,将之前更大视野下获得空-谱自注意力Apre与本层所得空-谱自注意力进行拼接融合,并接一个卷积层对拼接后的维度进行降维。记本层编码器的序号为i,i∈{1,2,3},则多视野融合后的空-谱自注意力可表示为:
随后,Aspa-spei会分成两条支路:一路会直接输入下一个编码器进行不同视野关键信息融合,另一路会和fn×n×n(V)进行点乘,得空-谱特征为:
其中:fn×n×n(·)表3D卷积层,n表示本层编码器感受野大小。最后,经过Reshape (patch to sequence),LayerNorm以及Linear层后,空-谱特征从本层编码器输出。
2.2 多视野预测融合
如图1所示,文本设计了一种多视野预测融合(Multi-View Predictions Fusion,MVPF)策略,将不同感受野下的编码器对样本分别进行预测,并对所有预测结果进行有机融合,弥补网络模型单一预测的不足。具体而言,将三个不同视野下的Transformer编码器所得空-谱特征分别接以一个分类器,输出三个类别预测,再对这三个预测进行加权融合。将大视野到小视野所得的三个预测分别表示为p1,p2和p3,则最终融合预测pfusion满足:其中,αi,i∈{1,2,3}为第i个视野下的可训练预测权重。这些权重的训练使用标准的反向传播算法来进行。由(7)式可得:
设损失函数为L(pfusion),则对于可训练参数α1和α2的梯度可以通过链式法则计算得到,其表达式如下:
2.3 网络模型参数
为了详细说明S3AT的结构,受篇幅所限,其重要可训练网络参数如表1所示。

表1 S3AT的模型参数Tab.1 Model parameter of S3AT
3 实验结果与分析
3.1 实验数据
为了验证S3AT在面向不同仪器、不同成像以及不同预处理方式下所获得高光谱医学数据,均具有出色的分类性能,本文采用In-vivo Human Brain HSI Dataset 和 BloodCell HSI Dataset来进行对比实验。下面分别对其进行介绍:
(1) In-vivo Human Brain HSI Dataset( Brain HSI Dataset):该数据集由英国南安普顿大学医院(UHS)和西班牙拉斯帕尔马斯大学内格林医院(UHDRN)共同采集。采集系统由Hyperspec®VNIR A-Series相机组成。相机基于推扫技术,使用硅CCD探测器阵列,最低帧率为90帧/秒,光谱范围为400~1 000 nm,光谱分辨率为2~3 nm,可捕获826个光谱波段,每行1 004个空间像素。采集对象为进行开颅切除脑肿瘤手术过程中的16名成年患者,最终获得26张高光谱图像,其共包含背景、正常、肿瘤以及血管四个类别。在本文实验中,选取包含全部四种类别的高光谱图像进行实验,共包含6个病人、9张图像。
(2) BloodCell HSI Dataset:该数据集是通过将显微镜和硅电荷耦合装置与VariSpec®液晶可调谐滤波器(Liquid Crystal Tunable Filter,LCTFs)结合起来收集。该数据集包含两张血细胞图像,其分别命名为Bloodcell1-3和Bloodcell2-2。Bloodcell1-3的大小为973×799 pixel,Bloodcell2-2的大小为462×451 pixel,它们都含33个波段。每张高光谱图像含有红细胞、白细胞和背景3个类别。
由于成像方式不同,采集设备不同,以上两个数据集中的高光谱图像的空间分辨率和光谱分辨率存在较大差异,进而空间信息和光谱信息分布有所不同。为了展示这个特性,在两个数据集中各自随机选取一个样本点,以其为中心裁剪出一个patch,分别做出光谱曲线以及某个随机波段的二维图像,最终可视化结果如图3所示。

图3 Brain和BloodCell HSI数据集上的空间和光谱信息可视化Fig.3 Visualization of spatial and spectral information on Brain and BloodCell HSI Dataset
由图3可知,本文采用的两个数据集中图像的波段数、光谱曲线以及空间分辨率存在较大差异,因此可以验证所提出算法在不同类型高光谱医学图像上的有效性。
3.2 实验设置
为验证本文算法的有效性,选取卷积神经网络方法HybridSN[24],SSRN(Spectral-Spatial Residual Network)[25]和DBDA(Double-Branch Dual-Attention )[26],Transformer深度学习方法Spectral-wise ViT[27],SSFTT[28]和CTMixer[29]作为对比算法。每种算法重复进行10次实验,以均值±标准差(Standard Deviation,STD)的形式表征总体分类精度(Overall Accuracy,OA)、平均分类精度(Average Accuracy,AA)以及Kappa系数(Kappa Coefficient,KC),以便综合比较并判断各算法的分类性能。在实验中,按波段对高光谱血细胞数据进行归一化处理,而学习率以及样本Patch大小,均由实验确定。在两个数据上的实验设置如表2所示。

表2 Brain和BloodCell HSI数据集上的实验设置Tab.2 Experimental setup on Brain and BloodCell HSI datasets
3.3 参数实验分析
为了对所提出的S3AT进行全面的研究,本文分析了样本patch大小和学习率对分类精度的影响。对于输入样本patch大小,不仅影响空间信息量,而且影响模型的复杂性。至于学习率,学习率过大会导致模型过快收敛到次优解,而学习率过小则会导致导致收敛过程停滞。因此,这些参数需要进行实验以获得更好的分类精度。对于学习率,选取范围为{1×10-5,1×10-4,1×10-3,1×10-2}。对于样本patch大小,选取范围为{3,5,7,9,11}。实验中,采用网格搜索确定最佳参数,数据集划分与表1相同,结果如图4所示。

图4 Brain和BloodCell HSI数据集上的参数分析Fig.4 Parameter analysis on Brain and BloodCell HSI datasets
由图4(a)和图4(b)可知,增加样本patch大小可以明显提高分类精度。这是因为更大的patch包含了更多的空间信息,提高了样本的鉴别性。考虑到运算效率,在两个数据集上,patch大小均设为9。同时,过小的学习率会使得模型更难获得高级特征,而学习率过大会使模型发散和梯度爆炸,因此在本文两个数据集中,学习率均设置为1×10-3。
3.4 消融实验分析
在文本所提出的S3AT模型中,空-谱自注意力机制和多视野预测融合策略占据关键地位。为了验证它们的有效性,以单视野下的原始Transformer网络为Baseline,在Brain HSI数据集上进行关于视野个数(Number of Views, NV)以及空-谱自注意力机制的消融实验。结果如表3所示。
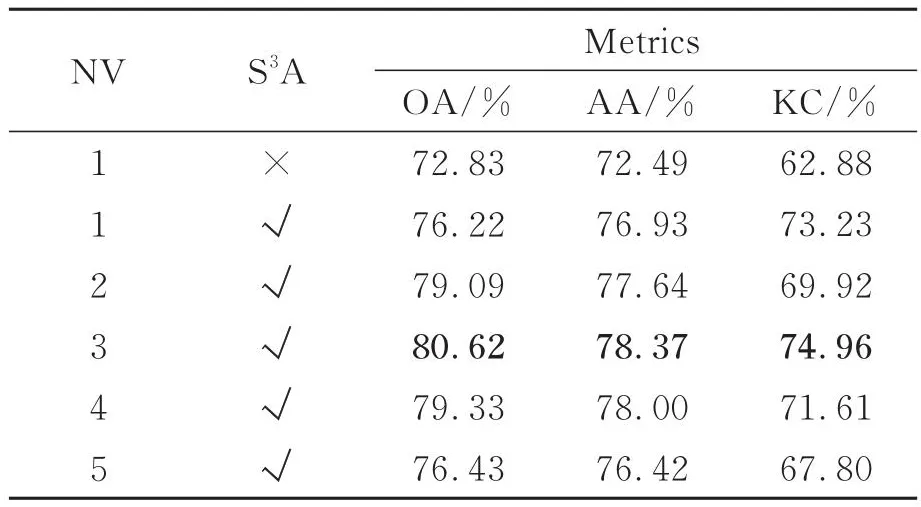
表3 S3AT关于不同模块的消融实验分析Tab.3 Ablation analysis of the proposed S3AT with a combination of different components
由表3可知,将S3A单独添加到单视野网络后,OA,AA和KC分别提升了3.39%,4.44%和10.35%。这说明S3A模块成功关注到了关键的空-谱特征区域,提取出了更具鉴别性空-谱特征。在添加S3A的状态下,随着视野数的增多,模型的预测能力得到进一步的提升。这是因为多视野预测融合策略成功融合不同视野下的决策。当视野个数为3时,模型分类表现达到最优。其OA,AA和KC分别提升了7.79%,5.88%和12.08%。当视野个数进一步增大时,模型预测性能下降,这是因为过多的视野使得模型过于复杂,引入过多可训练参数,陷入过拟合状态。
3.5 多视野预测融合分析
在本文所提出的S3AT模型中,多视野预测融合策略占据了重要地位。为了展示不同视野下的预测效果,在Brain HSI数据集上,分别使用三个视野下对应的分类器单独对整张测试图像进行预测,同时使用预测融合后的预测图作为对照,实验结果如图5所示。

图5 多视野预测融合分析Fig.5 Analysis of multi-view predictions fusion
图5可以看出,在原有各个视野下的预测的基础上,多视野预测融合策略取得了更好的分类效果。这是由于不同视野下的空-谱Transformer编码器获得了不同的关键信息,所设计的多视野融合策略有效地对这些信息赋予不同的权重,有效地对其进行整合,从而更好地利用不同视野下所获的信息,取得更高的分类精度。值得注意的是,从大视野至小视野,模型所获的预测权重分别为0.41,0.36和0.23。这是因为模型在大视野下获得了更多的整体信息,而在小视野下,模型获得更多的细节信息作为补充。
3.6 对比实验结果
3.6.1 Brain HSI数据集结果
在Brain HSI数据集上,实验结果由表4所示。由表4可知,ViT取得了最差的分类精度。这是由于ViT偏重于光谱特征提取,未能充分提取到充足的空间特征。其余对比方法均取得了稍好的分类结果,这是因为它们均包含空-谱特征提取模块,提升了模型的鉴别能力。在对比方法中,SSRN取得了更好的分类结果,这是因为SSRN中的空间注意力和光谱注意力模块关注到了重点空间区域和重要光谱波段,消除了特征冗余。然而,其单一的预测使得模型精度受限。在所有方法中,本文提出的方法取得了更好的分类结果。这是因为S3AT中的空-谱自注意力机制赋予空-谱特征以不同权重,并且其将不同视野下的诊断预测按不同的权重进行融合,提升了模型的预测能力。
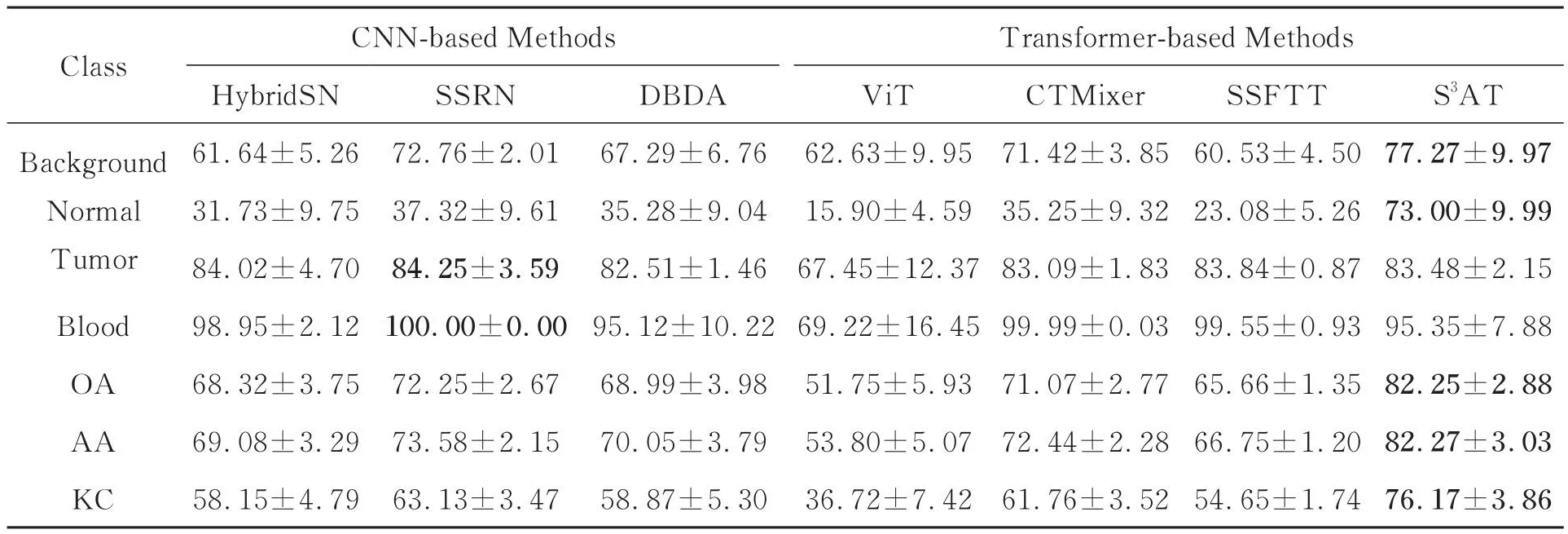
表4 Brain HSI数据集上不同算法的分类结果Tab.4 Classification results of different algorithms on Brain HSI Dataset(%)
为了直观对比不同方法的预测,在上述实验中,取其中一次实验中一张预测图作为展示,结果如图6所示。可以看出,本文算法相比其他方法,分类图错分点较少,更为平滑。这是因为S3AT在面向基于反射光成像的高光谱图像时,可以自适应地获取空-谱自注意力,详细地描绘出图像的空-谱信息分布,挖掘更具鉴别性的空-谱特征,并将多视野所得到的空-谱自注意力融合。此外,在预测阶段,多视野预测的有机融合,使得模型的预测更加精确。
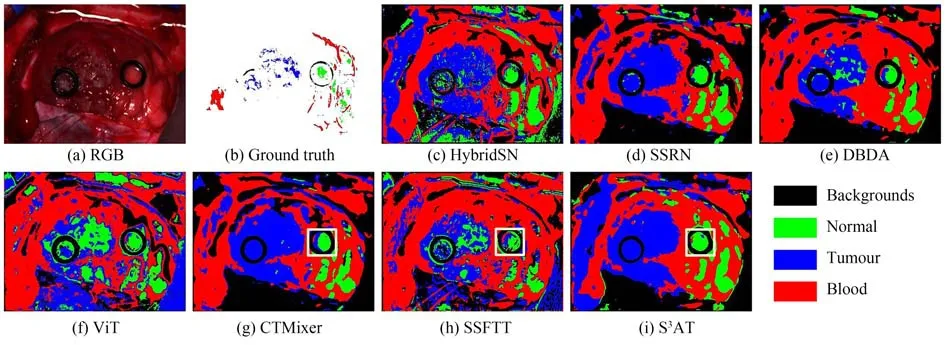
图6 各算法在 Brain HSI数据集上的分类结果图Fig.6 Classification maps of different methods on Brain HSI Dataset
3.6.2 BloodCell HSI数据集结果
在BloodCell HSI数据集上,实验结果如表5所示。由表5可知,S3AT在大多数指标上,依旧取得更好的分类结果。这是因为在面向基于显微镜透射光成像的高光谱图像时,S3AT的空-谱自注意力模块仍然能够捕获关键的空-谱信息,提高模型的分类能力,并且融合了不同视野下的诊断信息。这说明S3AT可以适用于不同仪器、不同成像方式所获取的高光谱医学图像,具有较好的泛化性,节约了模型开发成本。为了直观对比不同方法的预测,在上述实验中,取其中一次实验的预测图作为展示,结果如图7所示。由图7可知,S3AT所得分类图更为光滑,误分点较少。这说明基于空-谱自注意力机制和多视野预测融合的S3AT算法的分类性能有明显提升,具有强的鲁棒性,更适合实际应用场景。

表5 BloodCell HSI数据集上不同算法的分类结果Tab.5 Classification results of different algorithms on BloodCell HSI Dataset(%)
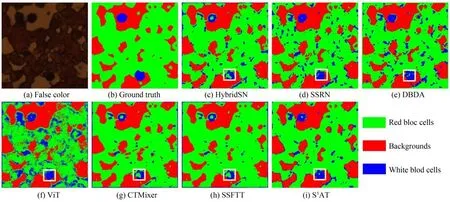
图7 各算法在BloodCell HSI数据集上的分类结果图Fig.7 Classification maps of different methods on BloodCell HSI Dataset
3.7 模型时空代价分析
所有算法在执行时都需要消耗时间和空间资源,因此,对算法的时空代价进行分析非常必要。在神经网络中,参数数量可用于表示网络的空间复杂度和大小,也对应计算机内存资源的消耗。该指标越小,则表示网络的空间复杂度越小。浮点运算次(Floating Point Operations,FLOPs)表示每秒完成预测所需的计算量,用来衡量网络的运算速度。该指标越小,则表示网络的时间复杂度越小。而推理时间则直接反映了一个算法在某一个设备上运算效率。使用Brain HSI Dataset上对32个测试样本在对本文使用的所有算法进行时空代价分析,实验平台如表1所示,实验结果如表6所示。
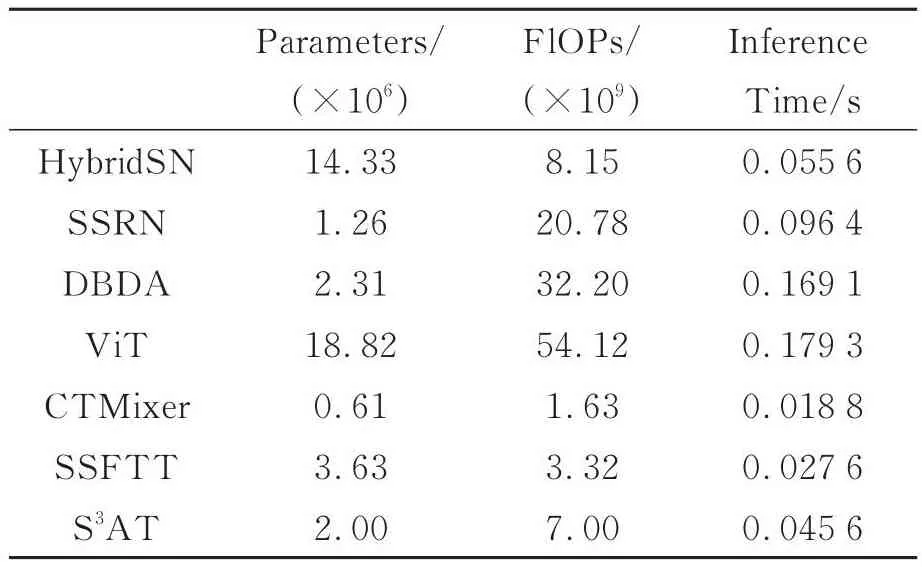
表6 不同算法的参数量、FLOPs以及推理时间比较Tab.6 Parameters, FLOPs and inference time comparison of different algorithms
如表6可知,S3AT相比HybridSN,SSRN,DBDA,ViT取得了更少的运算次数、更少的推理时间以及更少的模型参数(DBDA除外)。虽然SSFTT和CTMixer在时间复杂度上取得更低的结果,但S3AT分类性能比上述两个算法有显著性提升。这说明本文所提出算法具有较高的性能和效率,在高光谱医学图像分类任务中得到更好的表现,进而可以在计算资源受限的场景下得到更好地应用,具有较高的实用价值和推广前景。
4 结 论
在高光谱医学图像分类任务中,为了克服Transformer网络难以适应不同类型的高光谱图像而导致的性能表现差异较大,以及未能使用多个感受野的空-谱信息的问题,本文基于空-谱自注意力机制以及多视野预测融合策略,提出一种空-谱自注意力Transformer (S3AT)。该方法能根据高光谱医学图像中的空-谱信息分布,自适应挖掘重点空-谱信息,并将不同感受野下所获得空-谱自注意力进行融合,且将不同感受野下的预测进行加权融合。在Brain和Bloodcell HSI高光谱数据集上,OA,AA和KC分别获得了82.25%,82.27%和76.17%以及91.74%,88.97%和81.86%。实验结果表明,S3AT对不同类型的高光谱医学图像,均具有高精度的分类效果。然而,S3AT中的各个感受野大小为手工设定,未能根据图像自适应进行尺寸调整。因此下一步研究工作将关注如何设计一种自适应动态感受野,从而使模型更加有效地获取不同视野下的空-谱信息。
