联合自注意力和分支采样的无人机图像目标检测
2023-09-27张云佐武存宇刘亚猛张天郑宇鑫
张云佐, 武存宇, 刘亚猛, 张天, 郑宇鑫
(1.石家庄铁道大学 信息科学与技术学院,河北 石家庄 050043;2.河北省电磁环境效应与信息处理重点实验室,河北 石家庄 050043)
1 引 言
作为信息化时代的新型技术产物,无人机在遥感测绘、城市管理、灾害预警等领域都展现出了巨大的价值和应用前景[1]。但无人机高空巡航、飞行高度不定等作业方式,使其所捕获的图像通常存在背景复杂、包含大量密集微小目标、目标尺度变化剧烈等特点[2-3],因此无人机图像目标检测仍然是一项具有挑战性的任务。
传统目标检测方法通常可分为三步:首先通过区域选择器以遍历的方式选出候选区域;然后利用HOG(Histograms of Oriented Gradients)[4],Haar[5]等特征提取器进行特征提取;最后使用AdaBoost[6]、支持向量机[7]等分类器对提取到的特征进行分类。但该类方法通过穷举候选框来得到感兴趣区域,不仅时间复杂度高,而且会产生大量窗口冗余[8]。此外手工设计的特征提取器泛化能力不足以应对航拍图像中的复杂场景和多类检测任务[9]。
得益于硬件和算力的发展,基于深度学习的无人机图像目标检测算法逐渐代替传统方法成为了主流。与传统方法相比,基于深度学习的方法因其出色的特征表达和学习能力促进了无人机航拍图像目标检测的发展。Yang等[10]提出了一种集群检测网络ClusDet,将聚类和检测过程统一到了端到端框架中,同时通过隐式地建模先验上下文信息提高尺度估计的准确性。Yu等[11]对于无人机数据集中类别分布不均衡的问题进行了研究,并采用双路径方式分别处理头部类和尾部类,这种处理方式有效提高了尾部类的检测效果。Liu等[12]设计了一种针对高分辨率图像的检测模型HRDNet。该方法利用深层主干网络和浅层主干网络分别对低分辨率特征图和高分辨率特征图进行处理,解决了检测高分辨率特征图时计算开销过大的问题。Wu等[13]从提高无人机目标检测鲁棒性的角度展开研究,通过对抗学习方式区分有效的目标特征和干扰因素,提高了单类目标检测的鲁棒性。Youssef等[14]将多层级联RCNN与特征金字塔进行融合,在个别类别上提升了精度,但整体效果下降。Li等[15]提出了一种感知生成对抗网络模型,用于实现小目标的超分辨率表示,使小目标具有与大目标相似的表达,从而缩减尺度差异。Tang等[16]设计了一种无锚框的检测器,并将原始高分辨率图像分割为多个子图像进行检测,这使得算法在精度上得到提高,但这也带来了更多的计算负荷。Mekhalfi等[17]通过胶囊网络对目标之间的关系进行建模,提高了网络对于拥挤、遮挡情况下目标的解析能力。Chen等[18]提出了场景上下文特征金字塔,强化了目标与场景之间的关系,抑制了尺度变化带来的影响,此外在ResNeXt结构的基础上,引入了膨胀卷积增大感受野。这些方法从不同角度入手对密集微小目标检测任务进行优化,但此类方法没有考虑到复杂背景对航拍图像目标检测任务的影响,以及微小目标信息随网络层数增加而丢失的问题。
为了实现对无人机视角中微小目标的精准检测,本文提出了一种联合自注意力和分支采样的无人机图像目标检测方法。首先,通过嵌套残差结构将自注意力机制集成到主干网络中,实现对于全局信息和局部信息的有效结合,提升网络对全局信息和上下文信息的捕获能力。其次,针对现存特征融合模块的缺陷,设计了一种基于分支采样的特征融合模块,通过分支并行策略分别实现上、下采样操作,而后对不同分支的采样结果进行融合,有效强化模型的空间位置信息和特征表达能力,并缓解了小目标信息丢失问题。此外,将包含细粒度特征的浅层特征图引入到特征融合序列中,改善小目标检测效果。最后,构建了一种基于反残差结构的特征增强模块以提取具有鉴别性的小目标特征。
2 算法设计
目前主流目标检测算法可以分为两大类:以R-CNN系列[19-20]为代表的双阶段算法和以Yolo系列[21-22]为代表的单阶段算法,其中双阶段算法的精度更高,但检测速度较慢,而单阶段算法凭借简洁快速的优点得到了更广泛的应用。
本文选择Yolov5算法作为基线模型,改进后的网络结构图如图1所示,其中,主干部分由CSPDarkNet53和本文提出卷积和自注意力相结合的嵌套残差模块(Nested Residual combining Convolution and Self-attention, NRCS)构成,CSPDarkNet53用于提取局部特征,NRCS模块获取特征之间的全相关性,实现局部特征和全局特征的结合。Neck部分通过本文所提出的双分支采样的特征融合模块(Double-Branch Sampling Feature Fusion model, DBS-FU)实现特征融合。该结构通过多分支并行策略生成更精细的特征以提高特征融合效果。Head中引入浅层特征,构建新的检测头(Head 1)。每个检测头通过编码目标信息生成具有S2×B×(4+1+C)维度的张量。S2为特征图中包含的网格数;B为每个网格上预设的预测框数量,在本文中被设置为3;S2×B×(4+1+C)中的数字4表示预测框的坐标信息(x,y,h,w),数字1表示置信度;C表示待检测目标的类别数量。同时使用本文提出的反残差结构的特征增强模块(Feature Enhancement module of In-Residual,FE-IR)对新增的检测头进行特征增强。
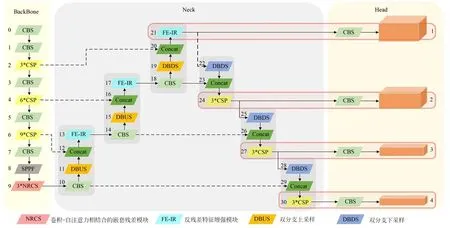
图1 本文所提算法整体结构图Fig.1 Overall structure of the algorithm proposed in this paper
2.1 集成自注意力的特征提取网络
无人机所捕获的高分辨率航拍图像背景复杂,在通常情况下背景信息远超目标信息。如果不予以处理,主干网络在特征提取过程中就会提取到大量的无效背景信息。因此,需要让模型聚焦在有效的目标信息上。
自注意力机制最初被广泛应用在自然语言处理领域中。Dosovitskiy等[23]首次将自注意力机制引入到了计算机视觉领域,并取得了一定成效。随着对自注意力机制研究的不断深入,自注意力机制的作用已经在计算机视觉领域得到了广泛认可。
在基于卷积神经网络的主干网络中,通过共享的卷积核进行特征提取,减少冗余参数的同时也带来了两种归纳偏好,即平移不变性和局部相关性,这使得卷积神经网络在提取底层特征和视觉结构方面具有很大优势,但这也导致卷积神经网络受限于局部感受野,无法捕获全局依赖关系。而自注意力机制则通过全局相似度计算像素之间的联系,为不同像素点赋予不同权重,从而获得全局相关性。自注意力相似度计算公式如下:
其中:X表示输入序列,Wq,Wk,Wv分别表示三个随机初始化矩阵,并且它们可以通过注意力进行动态调整,X与它们相乘得到Q,K,V。
其中:Q点乘KT,计算每个输入序列和其他序列之间的相似程度。除以用于防止内积过大导致梯度消失。其中dk为隐藏层维度。通过Softmax进行归一化计算得到权重系数后再与V相乘即可得到通过自注意力机制调整后的输入序列。
卷积神经网络擅长于对局部信息进行提取,而自注意力机制更擅长于对全局信息进行建模。综上,基于卷积神经网络和自注意力机制互补的思想,设计了卷积和自注意力相结合的嵌套残差模块NRCS,其结构如图2所示。该结构是一种嵌套残差结构,外层残差边对局部信息进行恒等映射,内层残差结构中使用多头自注意力模块(Multi Head Self Attention module,MHSA)计算全局相关性。与卷积结构相比,所提出的NRCS模块通过结合局部信息和全局信息提高模型对上下文信息的捕获能力。

图2 NRCS结构图Fig.2 Structure diagram of NRCS
此外,无人机图像分辨率远超普通图像,Sun等[24]研究发现,对分辨率较高的特征图进行全局相关性计算会带来过多的计算量和显存开销,并导致训练过程难以收敛。实验中发现目标检测任务中浅层的高分辨率特征图更依赖卷积的局部特征提取能力。而对经过多次下采样的深层低分辨率特征图进行全局相关性建模不仅可以保证主干网络对局部信息和全局信息进行有效提取,而且所需的内存开销和计算量也更符合应用需求。因此,本文方法仅在主干网络末端使用NRCS结构,其余部分仍然使用卷积神经网络。这样做既保留了卷积神经网络强大的局部特征提取能力,也通过自注意力获取了全局信息。同时在深层低分辨率特征图中使用NRCS模块可以有效减少模型的参数量。
2.2 分支采样特征融合
在特征融合阶段,原始网络结构中通过构建双向特征金字塔实现信息交互,其中第一个特征金字塔通过线性插值进行上采样,将浅层特征图中的空间位置信息传递到深层特征图。第二个特征金字塔则通过卷积进行下采样,将融合后的信息逐步传递回浅层特征图,保证每层特征层都有足够的信息进行预测,但这种设计有两个明显的缺陷。首先,在深层特征图向浅层特征图传递信息的时候使用的采样方法单一,导致深层语义信息并未有效传递。其次,在浅层特征图向深层特征图适配的过程中会出现严重的信息衰减的问题。而小目标携带的信息量本就远小于常规目标,因此信息衰减问题对小目标检测来说更加致命。针对这些缺陷,设计了一种基于双分支采样的特征融合模块DBS-FU。具体来讲,DBSFU包含DBUS和DBDS两个主要模块。其结构如图3所示。

图3 DBS-FU结构图Fig.3 Structure diagram of DBS-FU
如图3(a)所示,DBUS模块通过构建Bilinear和Nearest两条并行分支分别实现上采样,其中Bilinear分支和Nearest中的采样倍数(Scale_factor)均设为2。得到上采样结果后使用归一化(Batch Normalization, BN)分别对不同的上采样结果进行处理,防止梯度消失。最后将各分支采样结果进行逐元素加和,并使用SiLU激活函数引入更多非线性因素,得到最终的采样结果。相较于单一的采样方式,该结构通过生成高质量的上采样结果强化浅层特征图中的语义信息,从而提高模型对混淆目标的分类能力。该过程定义如下:
其中:Branch_Bi和Branch_Ne对应不同分支的上采样结果,BN表示批处理归一化层,⊕表示逐元素加和。
如图3(b)所示,DBDS通过构建Conv和Maxpool两条并行分支分别实现下采样,其中,Conv分支中卷积核大小为3,填充量为1,步长为2;Maxpool分支中池化核大小为2,填充量为0,步长为2。Conv分支提取局部感受野内的整体特征,Maxpool分支则专注于池化核内最突出的信息。这两种特性对小目标来说同样重要,任意一种单一采样方式都会导致某种信息的丢失。而分支并行策略可以有效缓解这一问题。每条分支都代表了原始特征图中一部分特征。将下采样结果融合后,可以对深层特征图中的空间位置信息进行进一步强化,提高对小目标的定位能力,并保留更多的上下文信息。其公式如下:
其中:Branch_Conv和Branch_Max对应不同分支的下采样结果,BN表示批处理归一化层,⊕表示逐元素加和。
2.3 针对微小目标的改进检测头
在基于卷积的深度学习网络对图像进行处理的过程中,特征图的分辨率会随着层数加深而逐渐变小。深层特征图包含丰富的语义信息,但空间位置信息逐渐丧失。相比而言,浅层特征图保留着较多的细粒度信息,更适合预测无人机图像中大量的密集小目标。因此,本文选择将较浅层的特征图集成到特征图融合序列中。所提算法将最终用于预测的特征图分为S×S个单元格,每个单元格仅预测一个中心点落入该单元格内的目标。当多个目标的中心点落入同一个单元格时会导致大量目标漏检。而浅层高分辨率特征图将包含更密集的S,这降低了多个目标落入同一网格区域的概率,有效提高密集小目标的检测精度。同时,我们通过将高分辨率特征图的通道数由128提升至256,以提高特征融合过程中的浅层特征图权重,该方法可有效提高模型对微小目标的敏感性。
此外,在输出最终的检测结果前,需要先对特征进行降维,但对无人机图像中大量存在的小目标来说,低维特征不足以保留足够的有用信息。并且特征通道数不足可能会阻碍梯度回传,不利于模型训练。因此本文设计了一个基于反残差的特征增强模块FE-IR。该结构先对特征进行升维,并利用深度卷积(Depthwise Convolution, DWConv)对高维特征进行特征提取以保证代表性。同时,我们将跳连路径建立在升维后的特征上,将增强后的特征映射至下一层。激活函数ReLU会将分布小于0的特征截断,导致信息损失。因此本文选择在深层模型上效果更好的Swish作为激活函数,以提高FE-IR模块性能。本文将该模块嵌入到检测层之前,用于对小目标特征进行增强。其结构图如图4所示。

图4 FE-IR 模块结构图Fig.4 Structure diagram of FE-IR
2.4 损失函数
损失函数用于度量网络的预测结果与真实标签之间的距离,通过使损失函数最小化,不断修正网络参数,实现精准预测。所提算法使用的损失函数由三部分组成:置信度损失表示检测框内是否存在目标;回归损失用于衡量预测框与真实框的误差;分类损失表示预测类别和真实标签的差异。总体损失函数定义如下:
其中:LossObj,LossRect,LossCls分别表示置信度损失、回归损失和分类损失。A,B,C表示不同损失所占权重。
本文在计算回归损失时考虑到预测值与真实值中心点坐标、重叠面积和宽高比之间的相关性,通过CIoU处理回归损失。定义如下:
其中:ρ为预测框和真实框的中心点距离,c为两者的最小包围矩形的对角线长度,v为两者的宽高比相似度,λ为v的影响因子。
本文置信度损失使用二值交叉熵(Binary cross entropy, BCE)。置信度损失定义如下:
其中:oi表示预测框i内是否存在目标,ci表示预测值。
BCE损失不仅适用于二分类任务,也可以通过多个二元分类叠加实现多标签分类,故本文分类损失同样采用BCE损失,分类损失定义如下:
其中:Oij表示预测框i内的目标是否为当前类别,Cij表示预测值。
3 实验与分析
3.1 实验环境
本文实验的运行环境为:操作系统CentOS7,显卡型号NVIDIA Tesla V100S-PCIE-32GB,处理器Intel(R) Xeon(R) Gold 6226R CPU @ 2.90 GHz。采用Pytorch深度学习框架。实验过程中,所有模型训练均采用随机梯度下降算法,初始学习率为0.001,动量因子为0.9,Batchsize为2。
3.2 实验数据集
VisDrone2019数据集[25]由AISKYEKY团队制作,其中包含288个视频片段,共包括261 908帧和10 209个静态图像,官方提供的数据集中选取了6 471张图像作为训练集,548张图像作为验证集。数据集中包含了11个类别,分别是行人、汽车、人、公交车、自行车、卡车、面包车、带棚三轮车、三轮车、摩托车以及others,其中others是非有效目标区域,本次实验中予以忽略。训练过程中,输入图像分辨率为1 536×1 536。
UAVDT数据集[26]由Du等在2018年欧洲计算机视觉会议提出。数据集中包含50个视频片段。本文按照通用标准,将前30个视频片段中的22 919张图像用于训练,后20个视频片段中的17 457张图像用于测试。该数据集共包含汽车、货车、公交车3类检测目标,涉及十字路口、高速公路、街区等常见场景。训练过程中,输入图像分辨率为800×800。
3.3 评估指标
为了精准量化所提模型在无人机航拍图像上的检测性能,本文采用多类目标检测任务中公认度最高的评估指标:平均精度均值(mean Average Precision, mAP)。其中mAP是通过按0.05为步长在0.5~0.95中取10个IoU阈值再取平均精度的过程,mAP50和mAP75则是分别以0.5和0.75的作为IoU阈值计算得到的平均精度,mAP计算过程如下:
其中:TP(True Positives)表示真正例,FP(False Positive)表示假正例,FN(Flase Negatives)表示假反例,n表示类别数量,J(Precision,Recall)k表示平均精度函数。
3.4 对比实验
为了适应不同的需求,本文通过调整网络的深度和宽度获得了两种不同规模的模型:m和s。其中m模型精度更高,但检测速度相对较低。s模型检测速度优于m模型,但精度相较于m模型有所下降。我们将两种模型在VisDrone2019数据集上的表现和其他目标检测算法进行比较,并在UAVDT数据集上验证所提方法的泛化能力。
3.4.1 VisDrone数据集实验结果
为了直观地展示本文所提算法相较于基线模型的性能提升,我们在表1中显示了两种基线模型和本文所提算法对VisDrone2019数据集中各类目标的检测性能。实验结果表明,本文所提算法的两种模型在全部类别上均实现提升,其中,行人、人、摩托车等小目标提升效果明显。

表1 基线模型和本文算法在VisDrone2019上的性能对比Tab.1 Comparison of the results of the baseline and the algorithm in this paper on VisDrone2019(%)
为了客观地展示本文所提方法的性能优势,我们将两种型号的模型与其他最先进的目标检测方法在VisDrone2019数据集上的性能表现进行了比较和分析。结果如表2所示,其中所提方法的m模型的mAP50,mAP和mAP75分别达到62.1%,38.9%和39.5%,在所有对比算法中达到最优。此外,所提算法的s模型的mAP50,mAP和mAP75分别达到59.3%,37.1%和38.3%,其中mAP和mAP75达到次优。mAP50仅次于所提算法的m模型和HRDNet。值得注意的是,HRDNet算法的输入图像分辨率远超本文所提方法,尽管这会提高精度,但这会严重影响检测速度。本文所提方法的两种模型在输入图像分辨率远低于HRDNet的情况下,整体性能仍然取得了最优和次优的结果。因此,本文所提方法更适合处理无人机图像目标检测。

表2 不同算法模型在VisDrone2019上的结果对比Tab.2 Comparison of results of different algorithm models on VisDrone2019(%)
3.4.2 UAVDT数据集实验结果
为了探究本文所提算法的泛化能力,我们测试了两种型号的基线模型和本文所提算法在UAVDT数据集中的检测性能。结果如表3所示,相较于基线模型,本文所提算法在全部类别上的检测精度均实现提升。

表3 基线模型和本文方法在UAVDT上的性能对比Tab.3 Comparison of the results of the baseline and the algorithm in this paper on UAVDT(%)
表4列举了本文所提方法和其他对比算法在UAVDT数据集上的性能表现。实验结果表明,本文所提方法的m模型在UAVDT数据集上的mAP50,mAP和mAP75分别达到44.7%,25.3%和28.1%,相较于其他对比方法,m模型的三项指标均达到最优,而s模型的mAP50和mAP也达到次优。综上,本文所提方法具有较高的检测精度和泛化能力。

表4 不同算法在UAVDT数据集上的结果对比Tab.4 Comparison of results of different algorithm models on UAVDT(%)
3.5 消融实验
本文提出的DBS-FU模块通过并行分支分别进行采样,以获取高质量的特征融合结果。为了验证单一采样和并行采样方式的性能差异,我们在VisDrone2019数据集上进行了相关测试,结果如表5所示。当使用基线模型默认的Nearest上采样和Conv下采样时,mAP50和mAP分别为53.7%和31.7%。相较于Nearest,Bilinear利用相邻像素分别在两个方向上进行插值。在替换Bilinear后,模型性能有所提升。而本文所提出的DBUS模块通过不同分支分别进行上采样,并在批处理归一化后对不同的上采样结果进行逐元素加,再由激活函数SiLU引入更多非线性因素。相较于单一方式的采样结果,DBUS所得到的特征图中携带更多的信息量,在特征融合过程中可以向浅层特征图传递更丰富的语义信息,从而提高模型对目标的分类性能。因此,当使用DBUS时,模型精度优于任意一种单一采样方法。在下采样时,使用卷积或池化任意一种下采样方式都会导致另一部分信息缺失,而本文所提出的DBDS模块同时使用两条采样分支捕获不同信息,有效减少信息损耗。

表5 不同采样方式性能对比Tab.5 Performance comparison of different sampling methods(%)

表6 消融实验结果Tab.6 Ablation experiment result
为了验证本文所提出的各个模块对模型整体性能的影响,本文选取6.0版本的Yolov5-s作为基线模型,通过消融实验对所提出的各个模块的有效性进行验证。结果如表5所示。对于消融实验结果的具体分析如下:
在未添加任何改进模块时,基线模型的mAP50和mAP分别为53.7%和31.7%。在此基础上,引入浅层高分辨率特征图构建新的检测头,mAP50和mAP增长至54.8%和32.4%,但参数量有所上升。当提高特征融合序列中浅层特征图权重占比,并通过加大深层特征图中卷积步距来平衡参数时,mAP50和mAP进一步增长至56.1%和34.3%,并且参数量下降。NRCS模块通过结合局部信息和全局信息,降低复杂背景对模型的影响。数据表明在加入NRCS模块后,mAP50和mAP增长至56.9%和35.1%,参数量明显下降。考虑到现有特征融合方法无法高效融合多尺度信息,信息衰减严重,构建DBS-FU特征融合模块,该模块通过并行分支生成高质量特征图,提高信息传递效率。数据表明分别加入DBUS模块和DBDS模块后,mAP50和mAP均出现上升,证明采用分支并行策略生成的采样结果在特征融合过程中效果更优。为了对小目标特征进行增强,设计了FE-IR模块,数据表明加入3组FE-IR模块后,mAP50和mAP增长至59.7%和37.1%,但检测速度有所下降。鉴于FE-IR模块即插即用,使用者可以根据需求灵活增加或减少FE-IR模块的数量。综上所述,消融实验表明本文所提的四个改进点都可以提高无人机图像目标检测的精度。
3.6 算法有效性展示
为客观表现本文所提算法相较于其他算法的优势,本文在VisDrone2019和UAVDT数据集中选取了不同场景下的图片作为测试对象,不同检测结果中差异较大的区域被黄色线框标注(彩图见期刊电子版)。
如图5所示,我们在VisDrone2019数据集中选取了四种常见的无人机图像,分别为高空视角、低空视角、密集小目标场景和夜间场景。图5(a)展示无人机在城市高空捕获的鸟瞰图像,该类图像分辨率较高,但背景信息复杂,容易对待测目标造成干扰。如图5(a)结果所示,其他检测算法不仅将图像右上角中的形似物体(民房、小屋等)误判为目标,而且部分待测目标并未被检测,而本文所提算法可以通过引入全局信息对复杂背景进行有效抑制。图5(b)中展示了无人机在低空作业环境下捕获的图像,该类图像中目标尺寸差异明显。观察结果可发现,此类图像中漏检情况较为频繁,而所提方法在检测不同尺寸的目标时更具有优势。图5(c)展示了密集小目标场景中模型的检测性能,其他算法中将特征图分为若干网格单元,每个网格单元预测一个目标。当目标尺寸较小且排列密集时,多个目标落入同一网格单元的概率将大大增加,导致大量目标未被检测。而所提方法通过改进后的检测头引入浅层特征层增加了网格单元的数量,减少了多个小尺寸目标落入同一网格的概率。图5(d)中展示了夜间场景的检测结果。目标检测模型极易受到光线不足带来的影响。该类图像中,可用特征较少,目标难以与背景分离。其他算法的检测结果中大量受到遮挡或处于暗处的目标未能被检测。而本文所提算法可以提取到精细和具有鉴别性的特征,从而提高在此类场景中的检测能力。
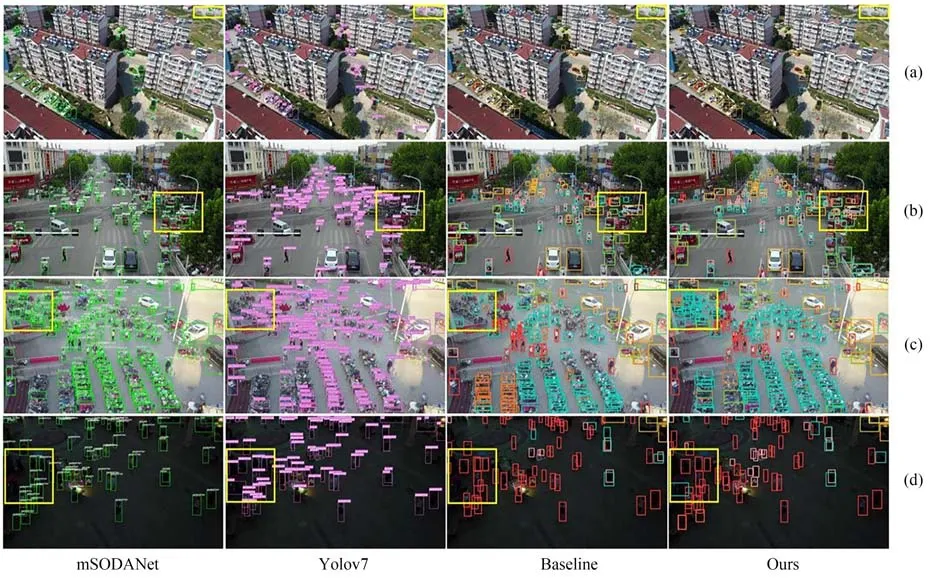
图5 不同算法在VisDrone2019数据集上的检测结果对比Fig.5 Comparison of detection results of different algorithms on VisDrone2019
图6中展示了不同算法在UAVDT数据集上的检测结果。结果表明,本文所提方法街道、路口、夜晚多种复杂场景中取得了显著的检测结果。

图6 不同算法在UAVDT数据集上的检测结果对比Fig.6 Comparison of detection results of different algorithms on UAVDT
不同数据集上的验证结果表明,本文所提方法具有抗干扰性强、检测精度高、泛化能力强等优势,更适合于无人机图像目标检测任务。
4 结 论
无人机图像中存在背景复杂、尺度变化剧烈、包含大量密集微小目标等问题,这对无人机图像目标检测任务带来了一定挑战性。针对上述问题,本文提出了一种联合自注意力和分支采样的无人机图像目标检测方法。首先,该方法在现有的目标检测算法基础上,构建卷积和自注意力相结合的嵌套残差模块NRCS,通过结合局部信息和全局信息提高模型对上下文信息的捕获能力,缓解复杂背景带来的干扰问题。其次,针对现有特征融合模块的缺陷,通过分支并行策略构建DBS-FU特征融合模块,提高特征融合质量。最后,将经过权重调整后的浅层细粒度特征图引入到特征融合序列中,设置对应的检测头以适应尺度变化的影响,并利用提出的特征增强模块FE-IR捕获更具有鉴别能力的小目标特征。实验结果表明,本文所提方法在不同场景中均表现出了良好的检测性能。
