基于语境辅助转换器的图像标题生成算法
2023-09-27李海昌胡晓惠
连 政 王 瑞 李海昌 姚 辉 胡晓惠
图像标题生成(Image captioning)是一项跨越计算机视觉与自然语言处理领域的多模态生成式任务[1-5],其主要目标是自动为图像生成准确的描述性语句.这要求计算机不仅要充分理解图像中的对象以及它们之间的关系,还要通过流畅的自然语言表达出图像的内容.图像标题生成技术具有广泛的应用价值.在学术研究当中,它可以推动图文检索、视觉问答等多模态领域技术的发展.在实际生活当中,这项技术在幼儿的早期教育和视障人群辅助设备的设计方面发挥着重要作用.
受神经机器翻译领域研究的启发,早期的基于深度神经网络的图像标题生成算法[6]采用了经典的编码器-解码器 (Encoder-decoder)框架,它将卷积神经网络(Convolutional neural network,CNN)作为编码器,提取图像的全局特征,再使用循环神经网络(Recurrent neural network,RNN)作为解码器对图像特征进行解码,生成图像标题.尽管经典的编码器-解码器框架在图像标题生成领域取得了巨大的成功,但是两个固有的缺陷严重限制了该框架的序列解码能力: 1)图像的全局信息在初始时刻被一次性地输入到解码器当中,而解码器缺少特征筛选的关键模块,难以捕捉预测单词时所需的相关视觉特征;2)在整个序列预测的过程中,作为解码器的循环神经网络会不断丢失一些重要的视觉信息,从而导致语言模型在预测后期逐渐缺少了视觉信息的指导,产生明显的误差累积,降低图像标题的生成质量.
为了解决上述问题,注意力机制(Attention mechanism)被引入到图像标题生成算法当中.注意力机制拓展了经典的编码器-解码器框架,它允许解码器在图像标题生成的不同时刻关注到与当前语义查询最为相关的图像信息.具体来讲,基于注意力机制的图像标题生成算法不再只是使用图像的全局特征,而是首先通过CNN 提取图像的局部区域特征,再使用基于长短期记忆(Long short-term memory,LSTM)网络的解码器对图像特征进行解码.在每一个解码时刻,注意力模块会将LSTM 提供的隐藏状态作为语义查询,为图像的各个区域分配不同的注意力权重,再通过对各部分图像特征进行加权求和,得到当前时刻的注意力语境特征,进而指导语言模型生成图像标题.近年来,转换器(Transformer)[7]在自然语言处理领域得到了广泛的应用,它通过多头注意力 (Multi-head attention)机制在多个语义空间中建模查询与键值对之间的关系.在图像标题生成领域,Transformer 首先依靠自注意力(Self-attention)机制实现图像局部信息的融合,然后通过解码器中的交叉注意力模块向语言模型中引入融合后的视觉特征,实现不同模态的特征交互.
在当前主流的图像标题生成算法中,交叉注意力机制在建模语义查询与图像区域之间的关系方面,发挥着关键性的作用.然而,大多数现有的基于注意力机制的算法都忽视了视觉连贯性的潜在影响.事实上,我们人类往往会不由自主地回顾先前关注过的信息,以便在当前时刻做出更加合理的注意力决策.遗憾的是,传统的交叉注意力机制无法实现这个意图.为了弥补这项缺陷,本文提出了一种新颖的语境辅助的交叉注意力(Context-assisted cross attention,CACA)机制.具体来讲,在每一个解码时刻,CACA 模块会首先根据当前输入的语义查询,利用交叉注意力模块从图像特征中提取出与当前查询最为相关的临时语境特征,并将其保存在历史语境记忆(Historical context memory,HCM)中,然后将HCM 中全部的历史语境特征与图像的局部特征相拼接,作为键值对,再次输入交叉注意力模块,获取当前时刻最终的注意力语境特征.同时,为了限制每个CACA 模块分配给历史语境的权重总和,本文提出了一种名为“自适应权重约束(Adaptive weight constraint,AWC)”的正则化方法,从优化注意力权重分布的角度提升模型的泛化性能.本文将CACA 模块与AWC 方法同时集成在转换器(Transformer)模型上,构建了语境辅助的转换器(Context-assisted transformer,CAT)模型.尽管Transformer 模型可以通过自注意力层在一定程度上建模历史语义信息,然而,从信息论的角度来讲,根据数据处理不等式[8]可知,输入模型的特征向量在神经网络逐层的特征处理与消息传递过程中,势必会丢失一部分关键信息,这将导致交叉注意力模块在某一时刻建模的语义信息无法完整地传递到后续解码过程中并得到充分利用.为此,CAT 模型采用语境辅助的交叉注意力机制,通过历史语境记忆保存了历史时刻中完整的交叉注意力语义特征,充分利用序列预测过程中视觉信息的连贯性,为解码过程提供更加丰富可靠的语境信息.本文在流行的MS COCO (Microsoft common objects in context)数据集[9]上,以多个基于Transformer 的图像标题生成算法作为基线模型,通过向解码器中引入CACA 模块与AWC 方法,对所提算法进行了评价.实验结果表明,与众多先进的基线模型相比,本文提出的方法在它们的基础上均实现了稳定的提升.
本文的后续内容安排如下: 第1 节主要介绍图像标题生成领域的相关工作;第2 节详细介绍本文提出的方法;第3 节通过大量的对比实验从众多角度对本文方法进行分析;第4 节总结本文的研究成果,并提出下一步的工作设想.
1 图像标题生成算法综述
迄今绝大多数的图像标题生成模型都采用了经典的编码器-解码器框架.该框架最早被提出并应用于神经机器翻译领域,取得了显著的成就.编码器-解码器框架的成功应用极大地促进了序列到序列(Sequence-to-sequence)任务的发展.在早期的图像标题生成模型[6]中,该框架首先利用CNN提取图像的视觉表征,再使用RNN 解码图像特征生成图像标题.在编码器-解码器框架下,图像标题生成领域涌现出一大批出色的解决方案[10-12],这些方法主要从编码器和解码器的组成结构上对图像标题生成模型进行了探索和改进,然而,由于在解码器中缺少特征选择的关键模块,经典的编码器-解码器框架在序列预测能力上受到了很大的限制.
注意力机制是编码器-解码器框架的重要拓展,它允许解码器在序列生成的每个时刻选择性地关注与当前查询最为相关的特征.受到人类直觉与神经机器翻译领域研究的启发,Xu 等[13]首次尝试将视觉注意力机制引入图像标题生成模型中,以便在生成描述时动态关注图像的显著区域.随后,You 等[14]通过一种语义注意力模型,选择性地关注编码器提出的语义概念,并将它们与循环神经网络的隐藏状态相结合.该模型中的选择与融合形成了一个反馈,连接了自顶而下和自底而上两种不同的计算方式.Lu 等[15]提出了一种带有视觉哨兵的自适应注意力模型,该模型可以决定是否关注视觉特征.Anderson 等[16]介绍了一种组合的自底向上和自顶向下的注意力机制,其中,自底向上的注意力利用Faster R-CNN 提取对象级别的图像特征,而自顶向下的注意力负责预测视觉特征上的权重分布.Chen 等[17]在文献中提出了一种增强的注意力机制,它将基于刺激的注意力与自顶而下的注意力相结合,为图像的显著区域提供可靠的先验知识.Huang 等[18]设计了一种“注意力上的注意力”模块,来确定注意力结果和查询之间的相关性.Pan 等[19]提出了一种X-线性注意力模块,来模拟多模态输入的二阶相互作用.最近,Yang 等[20]提出了一种因果注意力机制,来处理视觉-语言任务.因果注意力从前门调整策略出发,提出了样本内注意力机制和交叉样本注意力机制.其中,样本内注意力机制采用了经典的注意力网络,来捕获语义查询与当前样本中图像特征的关系,而交叉样本注意力机制负责在整个数据集的图像样本聚类后,捕获语义查询与各个质心特征之间的关系.王鑫等[21]设计了一种显著性特征提取机制,为语言模型提供最有价值的视觉特征,指导单词的预测.
近年来,Transformer[7]在图像标题生成领域得到了广泛的应用.Transformer 由堆叠的编码器层和解码器层组成,每一个编码器层包括一个自注意力模块和一个前馈模块,每一个解码器层包括一个掩码自注意力模块、一个交叉注意力模块和一个前馈模块.Herdade 等[22]在标准Transformer 模型的基础上,对识别出的对象设计了一种几何注意力机制,使得模型能够在编码图像的过程中考虑到对象在空间上的相对信息.Li 等[23]沿用了Transformer架构,在编码阶段使用了两个独立的Transformer编码器分别编码视觉信息和语义信息,在解码器部分设计了一种纠缠注意力机制,来弥补传统注意力在两类模态特征之间缺乏的互补性.此外,Yu 等[24]对Transformer 进行了拓展,提出了一种多模态Transformer 模型,该模型利用一种统一的注意力块同时捕获模态内与模态间的特征交互.之后,Cornia 等[25]提出了一种完全基于注意力机制的图像标题生成模型,该模型首先通过记忆增强的编码器学习图像区域之间关系的多级表示,整合从图像数据中学到的先验知识,保存在记忆向量当中,然后在解码阶段采用网状解码器同时利用底层和高层的视觉特征生成高质量的图像标题.Zhang 等[26]提出了网格增强模块与适应性注意力模块,并将二者嵌入到Transformer 中构成RSTNet.其中,网格增强模块通过融合图像网格间的相对几何特征增强模型的视觉表征能力,适应性注意力模块在解码器做出单词预测的决策之前自适应地度量视觉和语言线索的贡献.Luo 等[27]提出了一种双层协同Transformer 网络,充分利用了图像区域特征与网格特征之间的互补性.最近,Zeng 等[28]提出了空间与尺度感知的Transformer,它首先采用一个空间感知伪监督模块,利用特征聚类帮助模型保存网格特征的空间信息,然后通过一个简单的加权残差连接,同时探索具有丰富语义的低级和高级编码特征.Wu等[29]在Transformer 解码框架的基础上提出了一种双信息流网络,它将全景分割特征作为网格特征之外的另一个视觉信息源,来增强视觉信息对标题序列预测的贡献.
尽管交叉注意力机制在建模语义查询与图像区域之间的关系方面发挥了重要的作用,极大地提升了编码器-解码器框架在图像标题生成任务上的性能,但是,其视觉连贯性对注意力语境生成的潜在影响尚未得到深入研究.当前大多数基于注意力的图像标题生成算法都忽略了历史语境对产生当前注意力分布的影响.截至目前,只有少数研究在注意力机制的视觉连贯性方面进行了探索.Qin 等[10]提出了回顾算法,将上一时刻的注意力语境引入当前时刻的语义查询,以适应人类的视觉连贯性.Lian等[30]使用注意力LSTM 扩展了传统的时序注意力机制,以捕获之前时间步中产生的注意力权重分布特征.尽管上述两种解决方案充分考虑了注意力语境的历史信息,有效地提升了图像标题生成模型的性能,然而,它们仅考虑了基于LSTM 的解码框架,尚未在流行的Transformer 模型上实现进一步的探索.本文在交叉注意力模块的设计上聚焦于Transformer 解码框架,充分考虑了Transformer 在训练阶段的并行解码优势,在不向注意力网络中添加额外的可训练参数的条件下,引入视觉连贯性,显著提升了基线模型的性能.值得一提的是,本文提出的CACA 模块不仅可以扩展Transformer 模型,还同样适用于基于LSTM 的解码框架.
2 基于语境辅助转换器的图像标题生成模型
为了更加清晰地阐述模型的细节,本节首先回顾了经典的多头注意力机制,其次基于Transformer解码器结构介绍了语境辅助的交叉注意力机制,以及其轻量级的网络结构设计,然后介绍了基于语境辅助转换器的图像标题生成模型的整体框架,最后提出了结合自适应权重约束的模型优化方法.
2.1 多头注意力机制
多头注意力机制fmhatt(Q,K,V)集成了多个并行的缩放点积注意力(Scaled dot-product attention)层,以捕获不同特征子空间中与当前查询相关的语义信息.具体而言,它首先利用h组不同的线性转换层对输入的查询Q,键K和值V进行投影,再利用缩放点积注意力网络fdpatt(Q,K,V)对每一组投影后的特征进行建模,提取第i个子空间中的相关语义特征headi,最后,将这h组从特征子空间中提取到的语境向量拼接在一起,通过另一个可学习的线性转换层进行投影,得到最终的多头注意力语境特征.在此,本文假设Q,K,V的特征维度分别为dq,dk,dv.如图1 所示,多头注意力机制可由如下公式表达:

图1 多头注意力机制的结构Fig.1 The structure of multi-head attention mechanism
2.2 语境辅助的交叉注意力机制
在图像标题生成领域,交叉注意力模块的查询向量依赖于输入的文本特征,而键值对往往采用固定不变的图像区域特征.因此,传统的交叉注意力机制无法捕获先前时刻被关注过的语境特征,缺乏视觉信息的连贯性.针对这一问题,本文面向Transformer 解码框架提出了一种语境辅助的交叉注意力CACA 机制.如图2(a)所示,CACA 拓展了传统的交叉注意力机制,通过历史语境记忆HCM 为每一个解码时刻提供丰富的历史语境特征.具体而言,在第t时刻,CACA以当前的语义查询与键值对K,作为输入,利用交叉注意力模块与残差连接得到当前时刻的临时语境向量.需要说明的是,Transformer解码器中的交叉注意力模块采用的是多头注意力机制.
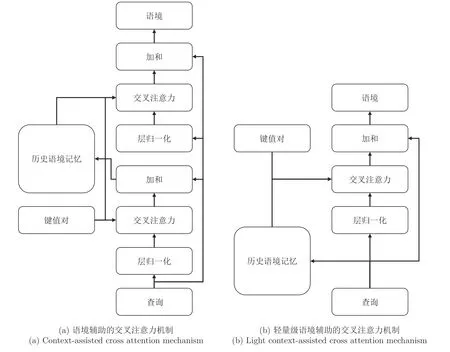
图2 语境辅助的交叉注意力机制与其轻量级的模型结构Fig.2 Context-assisted cross attention mechanism and its light model structure
值得一提的是,CACA 中两次使用的层归一化和多头交叉注意力机制分别共享相同的模型参数.综上所述,相较于Transformer 解码器中传统的交叉注意力模块,CACA 在不添加任何参数的条件下,引入了视觉信息的连贯性,建模了每一时刻语义查询qt与键值对K,V之间的关系,得到了该时刻的最终语境特征ct:
其中,fcaca表示语境辅助的交叉注意力机制.
2.3 轻量级语境辅助的交叉注意力机制
语境辅助的交叉注意力机制通过历史语境记忆模块为每一个解码时刻提供了完整的历史语境特征,向注意力模块中引入了视觉信息的连贯性.然而,两次使用交叉注意力机制大幅提高了模型推理的时间成本,降低了模型的解码效率.因此,本文提出了一种轻量级的语境辅助的交叉注意力(Light context-assisted cross attention,LightCACA)模型,在保证视觉连贯性的前提下,以牺牲部分历史语境信息为代价,换取与传统的交叉注意力机制接近的解码效率.
如图2(b)所示,LightCACA 首先将当前时刻的查询向量qt加入到历史语境记忆当中,构建当前完整的历史语境特征:
随后,键值对K,V和完整历史语境特征在空间维度上拼接,供交叉注意力模块提取当前时刻的语境特征:
轻量级语境辅助的交叉注意力机制与其标准模型的主要区别在于历史语境信息的不同.在Transformer 解码器的层级结构下,CACA 的历史语境信息由当前层的交叉注意力模块产生,HCM 存储的是当前层在每一时刻产生的临时语境特征,而Light-CACA 的历史语境信息直接来源于当前层掩码自注意力模块的输出,间接来源于上一层LightCACA产生的语境特征.值得注意的是,最底层Light-CACA 模块中HCM 存储的历史语境信息来自解码器输入的文本序列特征.
2.4 语境辅助的转换器
图3 展示了基于语境辅助转换器(Context-assisted transformer,CAT)的图像标题生成算法框架.该框架主要包括三个部分: 提取图像对象级特征的Faster R-CNN,优化图像特征的Transformer 编码器,以及基于语境辅助的交叉注意力机制的Transformer 解码器.

图3 基于语境辅助转换器的图像标题生成模型Fig.3 Context-assisted transformer for image captioning
给定一幅图像I,CAT 首先使用预训练好的Faster R-CNN 从图像中提取出一组对象级别的视觉特征V={v1,v2,···,vm},其中,vi∈Rdv,m为从图像中提取到对象的数量.需要说明的是,在整个模型训练的过程中,Faster R-CNN 的参数固定.
其中,fenc表示Faster R-CNN 特征提取模块.
随后,视觉特征V将被输入Transformer 编码器进行优化,建立不同对象特征之间的语义关系.值得一提的是,本文认为不同对象之间不存在明显的位置顺序,所以并未给视觉特征添加位置编码信息.除此之外,本文方法与传统Transformer 编码器的算法流程一致.第n层Transformer 编码器的操作可总结如下:
其中,第一层Transformer 编码器的输入向量V1=V.在此,假设Transformer 编码器共N层,则其优化后的视觉特征可由如下操作得到:
本文假设CAT 解码器的层数与编码器层数相同,在第t时刻,解码器生成单词wt的过程可由如下公式表示:
轻量级语境辅助的转换器(Light context-assisted transformer,LightCAT)在模型设计的思路上与CAT 完全相同,区别仅在于使用LightCACA替换了CAT 中的CACA 模块.
2.5 模型优化
其中,βn,h是一个可学习的参数,ϵ用于防止训练过程中的梯度爆炸.本文设置ϵ为1×10-8.
其中,γ是两项损失的平衡因子,H是多头注意力模块的头部数量,本文依据经验将其设置为0.5,N为(Light)CAT 解码器的层数.
随后,本文在强化学习阶段采用自我批判序列训练(Self-critical sequence training,SCST)算法[31]直接优化了不可微分的评价指标:
其中,w1:l是生成的图像标题,本文中的奖励r(·)采用了流行的CIDEr-D[32]分数.
3 实验与分析
3.1 数据集与评价标准
本文在MS COCO (Microsoft common objects in context)数据集[9]上评估了(Light)CAT 的性能.该数据集共包含123287 幅图像,每幅图像由不同的AMT (Amazon mechanical turk)工作人员用至少5 条标题进行标注.为了与其他先进的基线方法进行公平的比较,本文采用了“Karpathy”分割[33]进行离线评估,其中,113287 幅图像用于训练,5000 幅用于验证,另外5000 幅用于测试.本文使用的评价方法包括BLEU[34],METEOR[35],ROUGE-L[36],CIDEr-D[32],以及SPICE[37].
3.2 实现细节
本文采用在视觉基因组(Visual genome)数据集[38]上预训练好的Faster R-CNN 作为图像特征提取器,该编码器为每一幅图像检测出10~100 个不同区域,每个区域特征向量的维数为2048,随后将它们投影到512 维后输入到Transformer 编码器当中进行特征优化.对于Transformer 编码器与(Light)CAT 解码器而言,本文参照了之前的研究工作[25],将二者的层数设定为3,多头注意力机制的头数为8,每个模块输出的向量维度为512,每一个注意力网络和前向网络都采用了Dropout 方法,丢失率为0.1.在训练过程中,本文首先采用联合优化交叉熵损失和自适应权重约束损失的方式训练模型,其中包括了10000 次热身(Warm-up)训练.之后,在优化CIDEr-D 分数时,本文采用了固定的学习率5×10-6,当CIDEr-D 分数在连续五轮训练中均未出现提升时,终止训练过程.在两个训练阶段,本文都将批量大小设置为50,集束搜索的大小设置为5.
3.3 语境辅助交叉注意力机制的性能分析
为了验证语境辅助的交叉注意力机制在Transformer 解码框架中的有效性和通用性,本文采用Transformer,M2Transformer[25],DLCT[27],S2Transformer[28],DIFNet[29]作为基线模型,在MS COCO 数据集上设计了5 组对比实验.每一组实验均使用CACA 模块与LightCACA 模块替换了基线模型中的传统的交叉注意力机制,除(Light)CACA模块外,改进模型与原模型在结构上完全一致.同时,改进模型在训练过程中加入了自适应权重约束,来寻求一个更具泛化性的交叉注意力权重分布.如表1 所示,采用(Light)CACA 模块改进后的模型在绝大多数评价指标中都超越了基线模型的性能.值得一提的是,在与当前最先进的S2Transformer和DIFNet 模型的比较中,采用标准CACA 模块的改进模型实现了对基线方法的全面超越,在BLEU与CIDEr-D 分数上均取得了明显的提升.同时,标准CACA 模块给模型带来的性能提升比Light-CACA 模块更加明显.举例而言,以Transformer为基线模型,LightCAT 模型在BLEU-4 和CIDEr-D 分数上较Transformer 分别提升了1.1%和1.0%,而CAT 模型带来的提升为2.4%和2.5%.该结果从定量分析的角度有力地证明了当前层交叉注意力语境特征对解码过程的实用价值.

表1 基于Transformer 的图像标题生成模型结合(轻量级)语境辅助的交叉注意力机制在MS COCO 数据集上的性能表现 (%)Table 1 Performance of Transformer-based image captioning models combined with(Light)CACA on MS COCO dataset (%)
正如上文所提到的,本文设计的CACA 模块与自适应权重约束同样适用于基于LSTM 的解码框架.在此,本文以Att2in[31],BUTD[16],LB[10]作为基线模型,在MS COCO 数据集上设计了3 组对比实验.由于这些基线模型的解码器中只存在一个交叉注意力模块,所以自适应权重约束中的参数N=1.表2 是上述三种基于LSTM 的图像标题生成模型结合CACA 模块后在MS COCO 数据集上的性能表现.实验结果表明,本文提出的CACA 模块不仅适用于Transformer 解码框架,还可以大幅提升LSTM 解码模型的性能.

表2 基于LSTM 的图像标题生成模型结合语境辅助的交叉注意力机制在MS COCO 数据集上的性能表现 (%)Table 2 Performance of LSTM-based image captioning models combined with CACA on MS COCO dataset (%)
为了分析语境辅助的交叉注意力机制对模型推理效率的影响,本文从MS COCO 测试集中随机选出了1000 幅图像,分别使用Transformer,CAT和LightCAT 模型生成图像标题.具体而言,每一轮解码过程的输入为50 幅图像,集束搜索算法的束大小为5.本组实验在单块NVIDIA TITAN XP GPU 环境下进行,CUDA 版本为10.1.表3 记录了3 种模型对每一轮输入图像的平均解码时间.尽管语境辅助的交叉注意力机制大幅提高了图像标题的质量,但由于两次使用交叉注意力模块,不可避免地导致了解码效率的下降,在贪心和集束搜索算法下,使模型的解码时间分别上升29.8%和35.5%.对于轻量级的语境辅助的交叉注意力机制而言,其模型结构与传统的交叉注意力模块相似,仅通过扩充数据信息的方式引入视觉连贯性,所以,Light-CACA 可以在保证解码效率的同时提升模型的性能.虽然CACA 模块的结构较为复杂,需要更长的解码时间,但总体来讲,它为模型带来的性能提升更加明显,且解码效率仍在可接受的范围之内,所以,本文中的大部分实验均以CACA 模块为代表,体现本文算法的优势.

表3 语境辅助的交叉注意力机制对Transformer 推理效率的影响(ms)Table 3 The effect of context-assisted cross attention mechanism on Transformer's reasoning efficiency (ms)
3.4 语境辅助转换器与先进基线方法的比较
本文将基于不同基线模型的语境辅助转换器与当前先进的基线方法在MS COCO 数据集上进行了比较.这些基线方法包括: 1)Att2in 与Att2all[31],使用视觉注意力机制,并采用不可微分的评价指标对模型进行优化;2)BUTD[16],使用Faster RCNN 提取图像特征,再采用自顶向下的解码器对视觉特征进行解码;3)AoANet[18],使用注意力门从被关注的语境特征中筛选与语义查询切实相关的知识;4)M2Transformer[25],通过网状连接的编解码框架充分利用低层与高层的视觉特征;5)X-LAN与X-Transformer[19],使用空间与管道双线性注意力机制来建模不同模态间的二阶相互作用;6)DLCT[27],通过图像区域特征与网格特征的协作互补,增强视觉信息的表达能力;7)RSTNet[26],建立了一个基于BERT 的语言模型来捕获文本上下文信息,并通过自适应注意力模块来衡量视觉与文本线索的贡献;8)CATT[20],使用前门调整策略来消除视觉-语言模型中难以捕捉的混淆效应;9)S2Transformer[28],采用空间和尺度感知的Transformer 将图像网格特征高效地融入图像标题生成模型;10)DIFNet[29],将图像的全景分割特征作为网格特征之外的另一个视觉信息源,以增强视觉信息对图像标题生成的贡献;11)CIIC[39],通过后门调整策略缓解由无法观测的混淆因素引起的虚假相关性.与当前先进方法的对比结果如表4 所示.本文的DIFNet+CACA 模型在全部评价指标上都取得了当前最优的效果,其中,在BLEU-4 和CIDEr-D 上分别达到了40.5 与136.8.

表4 本文模型与先进方法在MS COCO 数据集上的性能对比(%)Table 4 Performance comparison between our models and the state-of-the-art (%)
3.5 语境辅助交叉注意力机制的消融实验
为了更加清晰地说明语境辅助的交叉注意力机制的设计思路,分析它为基线模型带来的性能提升,本文以经典的Transformer 解码框架为基础,使用三种不同的语境辅助策略增强解码器中传统的交叉注意力(Traditional cross attention,TCA)模块,在MS COCO 数据集上进行了对比实验.具体而言,不同语境辅助策略的主要区别在于历史语境特征的引入形式不同.如图4 所示,左侧的CACA 模块在引入历史语境特征时,并未与视觉特征相结合,而是仅将历史语境记忆中的特征向量作为键值对(Only historical contexts,OHC),通过二次使用交叉注意力模块,提取当前时刻的语境特征;中间的CACA 模块将之前时刻的历史语境特征与视觉特征相拼接,构建交叉注意力模块的键值对输入,此处的历史语境特征不包括当前时刻首次使用交叉注意力模块时产生的临时语境特征(Incomplete historical contexts,IHC);右侧的CACA 模块则是本文在第2.2 节中提到的方法,它为交叉注意力模块同时提供了完整的历史语境特征(Complete historical contexts,CHC)与视觉信息.为公平起见,本组对比实验中均未加入自适应权重约束.

图4 传统交叉注意力机制的三种语境辅助策略Fig.4 Three context-assisted strategies of traditional cross attention
表5 列出了在Transformer 解码框架下,传统交叉注意力机制在结合三种不同语境辅助策略时的性能表现.从实验结果中可以看出,TCA+OHC与传统方法相比,在多数评价指标中分数均有所下降,导致此结果的原因是,交叉注意力模块在生成最终语境特征时缺少了原始视觉特征的参与和指导,同时,每一时刻历史语境记忆能够为注意力模块提供的特征向量十分有限,严重限制了注意力模块的选择能力.TCA+IHC 相较于传统方法,在大多数评价指标上均有所提升,说明历史语境特征的加入丰富了交叉注意力模块的选择空间,为当前语境特征的生成提供了更加丰富且有效的信息,也从侧面反映出视觉连贯性在序列预测任务当中的重要性.TCA+CHC 是本文提出的CACA 模型,与传统交叉注意力机制相比,该方法在所有的评价指标上均取得了明显的提升.同时,从TCA+CHC 与TCA+IHC 的性能对比中可以得出结论,临时语境特征的加入有助于每一个CACA 模块产生更高质量的最终语境特征,进而指导语言模型生成更加合理的图像标题.

表5 传统交叉注意力机制结合不同语境辅助策略在MS COCO 数据集上的表现(%)Table 5 Performance of the traditional cross attention mechanism combined with different context-assisted strategies on MS COCO dataset (%)
本文在CACA 模块上的设计理念是,在不添加任何额外的可训练模型参数的条件下,通过CACA模块引入视觉信息的连贯性,提升基线模型的性能.具体来讲,在CACA 中两次使用的交叉注意力模块共享(Shared)相同的参数.为了分析在不共享(Not shared)模型参数的条件下CACA 模块的性能表现,本文在MS COCO 数据集上以不同解码器层数的CAT 模型为基础进行了对比实验.在本组实验中,不同CAT 模型的编码器层数固定为3 层,且在训练过程中同样未加入自适应权重约束.
表6 展示了三组不同解码器层数的CAT 模型在共享与不共享交叉注意力模块参数时的性能表现.当解码器层数为2 层时,从实验结果中可以看出,无论是否共享交叉注意力模块的参数,使用CACA模块的CAT 模型的性能在所有评价指标上都超越了使用TCA 模块的模型的性能.进一步对CACA模块进行分析,与共享参数的CACA 模型相比,不共享参数的模型拥有更多的可训练参数,且模型性能明显优于共享参数的模型.3 层解码器的模型实验反映出了相似的实验结论,不同的是,相较于共享参数的CACA 模型,不共享参数的模型性能提升较小.同时,在4 层解码器的模型实验中,TCA模型的性能较3 层解码器的TCA 模型有所降低,且CACA 模块对基线模型的性能产生了负面影响.综合表6 中的实验结果及上述分析,本文得出了以下两点结论: 1)当基于TCA 的模型尚未出现过拟合现象时,共享参数的CACA 模块能够有效提升基线模型的性能,而不共享参数的CACA 模块在提升模型性能的同时,由于加入了更多的参数,模型可能出现过拟合问题;2)当基于TCA 的模型已经出现过拟合现象时,CACA 模块将扩大过拟合产生的负面影响,尤其是不共享参数的CACA 模块,将大幅降低图像标题的质量.
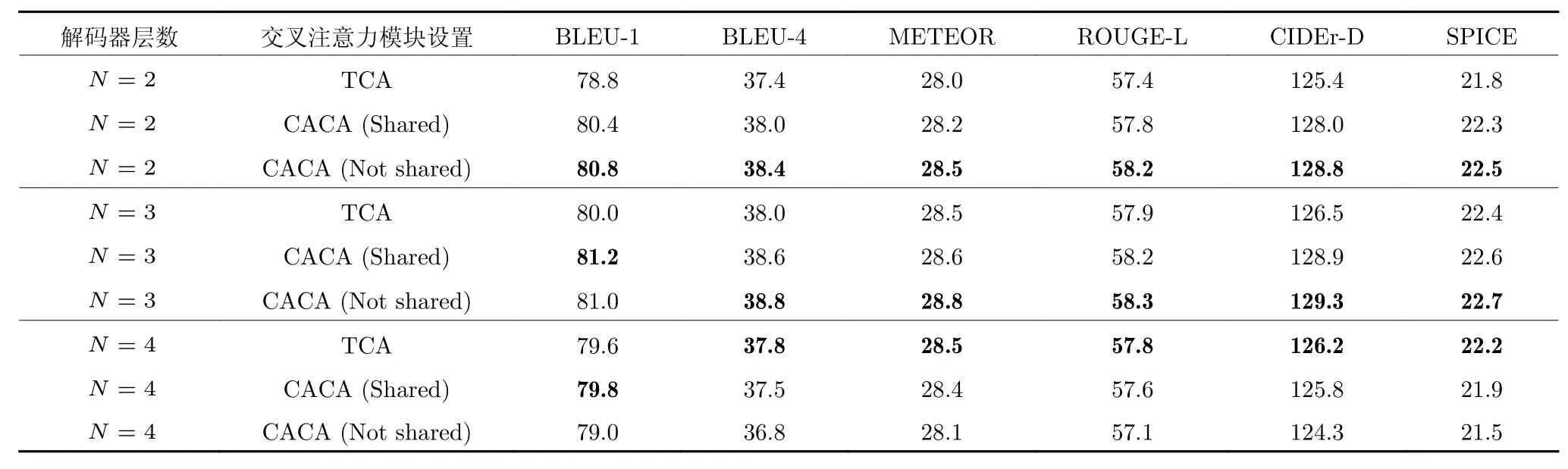
表6 不同解码器层数的CAT 模型在共享与不共享交叉注意力模块参数时的性能表现(%)Table 6 Performance of CAT models with different decoder layers when sharing or not sharing parameters of the cross attention module (%)
3.6 自适应权重约束的消融实验
本文在MS COCO 数据集上设计了一组消融实验来解释自适应权重约束给CAT 模型带来的性能提升.通过观察AWC 损失与CE 损失的数量级,本文依据经验将损失权衡系数γ设置为0.5.在本组实验中,CAT 解码器的层数为3 层.从表7 列出的实验结果中可以看出,当CAT 模型采用固定值作为CACA 模块的权重约束时,其性能表现随β值的增大,先缓慢提升,在β=0.5 附近达到最优,随后迅速下降.结合表5 中的信息,本文发现,当固定权重约束β=0.1 时,即在少量引入历史语境特征的条件下,CAT 模型的性能就可在仅使用TCA 的基础上实现大幅提升,模型的CIDEr-D 分数由126.5提升至127.8.同时,当固定权重约束β=0.9 时,即几乎将全部的权重都分配给历史语境特征时,CAT模型的性能将偏向表5 中TCA+OHC 的实验结果,过度关注历史语境信息而忽略原始的视觉信息,导致图像标题的质量严重下降.当固定权重约束β=0.5时,模型在视觉特征与历史语境特征上的权重分配相对平衡,一定程度上提升了CAT 模型的性能.与固定权重约束相比,自适应权重约束更加灵活,它能够依据数据和模型的需要,学习到一组更具泛化性的参数.从实验结果上看,自适应权重约束为CAT 模型带来的提升要明显优于固定权重约束,同时,与无权重约束的模型相比,采用AWC的CAT 模型在所有评价指标中均超越了基线模型.

表7 采用自适应权重约束的CAT 模型在MS COCO 数据集上的表现(%)Table 7 Performance of the CAT model with adaptive weight constraint on MS COCO dataset (%)
3.7 注意力图的可视化分析
为了深入阐释历史语境记忆的重要作用以及自适应权重约束的有效性,本文基于一组完整的图像标题生成示例,对视觉特征和历史语境记忆上的注意力分布进行了可视化分析.考虑到顶层解码器的输出特征与图像标题的生成结果直接相关,本文以Transformer 模型顶层解码器中的CACA 模块为例展开讨论.
如图5 所示,中间部分展示了原始图像,以及采用AWC 优化的CACA 模块在每个解码时刻分配给图像特征的注意力权重分布图.图5 顶部的折线图展示了CACA 模块在对应时刻为历史语境记忆分配的注意力权重总和.其中,橙黄色实线与金黄色虚线分别代表了“采用”与“未采用”AWC 优化的CACA 模块给历史语境记忆的权重分配结果.在此,本文首先通过橙黄色的实验数据深入分析历史语境记忆存在的重要意义.在第一个解码时刻,采用AWC 优化的CACA 模块将大部分注意力给予了图像特征,仅为历史语境记忆分配了0.0732 的注意力权重.直观分析,在序列生成的初始时刻,解码器亟待充分理解图像中的显著特征,同时,历史语境记忆能够为解码过程提供的语义信息十分有限,因此,CACA 模块主要依靠图像特征完成第一个时间步的单词预测.在后续的时刻中,随着历史语境记忆中的特征向量逐渐丰富,CACA 模块为其分配的注意力权重也迅速增加,并最终稳定在0.2左右.在图像标题的生成过程中,解码器不断寻求历史语境记忆的指导,说明历史语境记忆蕴含了大量有价值的信息,进一步证实了该模块存在的必要性.

图5 由语境辅助的交叉注意力模块分配给图像特征与历史语境记忆的注意力分布可视化Fig.5 Visualization of attention distribution assigned to both image features and historical context memory by our CACA module
与此同时,通过比较两条折线中数据点的大小,本文发现,未采用AWC 优化的CACA 模型对历史语境记忆的利用率远不及采用AWC 优化的CACA模型.结合前文的结论,若不采用AWC 对模型进行优化,CACA 模块则难以充分利用历史语境记忆中的有效信息为解码过程提供丰富的语义特征.综上所述,自适应权重能够提升CACA 模块对历史语境记忆的利用率,为解码器提供更多有价值的信息,从而提高图像标题的生成质量.
在图5 的底部,本文对注意力权重在历史语境记忆中的具体分配情况进行了可视化分析.为了清晰起见,本文挑选了三个具有代表性的时间步进行讨论.具体而言,当历史语境记忆中的一条特征向量获得大于0.05 的注意力权重时,则通过一条连线指向当前时刻生成的单词.此处展示的图像标题为采用AWC 优化的模型生成的结果.值得一提的是,连线的颜色越深,表示特征被分配的权重越大.如图5 所示,当模型预测单词“man (男人)”和“holding (拿着)”时,CACA 对当前时刻新加入历史语境记忆的特征向量格外关注,表明视觉特征在此刻发挥着重要作用;而当模型预测单词“on (在···之上)”时,由于图像中缺少明显的视觉线索表达这一概念,因此,CACA 重点关注了历史语境记忆中可以辅助推断当前词的语义特征.上述事实说明,历史语境记忆可以发挥视觉哨兵[16]的作用,为CACA 模块提供一个回退选项,在必要时舍弃部分低价值的视觉特征,利用之前时刻的历史语境特征,协助解码器完成单词的预测.
3.8 图像标题生成示例
为了进一步证明本文方法在传统的交叉注意力机制上的改进,本文在图6 中展示了八组图像标题生成的案例.其中,每组案例包括了一幅图像,Transformer 基线模型生成的标题,CAT 模型生成的标题,以及图像对应的真实(Ground truth,GT)标题.举例来讲,在第一个案例中,Transformer 与CAT 模型都关注到了图像中的主要目标“dog”与“frisbee”,这得益于它们拥有相同的编码器结构Faster R-CNN 与Transformer 编码器,Faster RCNN 能够提取到图像中的显著目标,Transformer编码器则可以隐性地建模不同目标之间的关系.然而,由于缺少动作信息捕捉的相关模块,这便要求解码器承担相应的职责.从模型结构来看,Transformer 解码器通过传统的交叉注意力机制与图像特征进行交互,认为图像中狗是叼着飞盘在沙滩上“奔跑(running)”,然而实际上,图像中的狗是通过“跳跃(jumping)”来接住空中的飞盘.本文提出的CAT 模型利用语境辅助的交叉注意力机制,在解码过程中,不仅能够关注到与当前语义查询最为相关的图像信息,还能够从历史语境特征中受到启发.在这一案例中,CAT 模型通过CACA 模块,进一步捕获到历史时刻与狗相关的语境特征,从而生成了更加符合图像事实的描述“狗跳起接住(jumping to catch)飞盘”.另外,本文在图6 中展示了一个失败的案例.如案例八所示,图中有一块砧板,上面放着一块被刀切开的奶酪.从两个模型生成的标题来看,它们都错误地将奶酪(cheese)描述成“橘子(orange)”.导致这一结果的原因主要有两点: 1)形如图中的奶酪在整个数据集中出现的次数较少,深度模型难以捕捉其内在的判别特征;2)奶酪的颜色与生活中常见的橘子相似,外加明亮的白光环境,使得编码器提取到的特征难以将二者进行区分.本文提出的CACA 模块主要作用于模型的解码器部分,对编码器的特征提取能力影响较小,难以解决上述问题.针对此类现象,可以通过平衡数据分布、增强编码器、采用小样本学习[37]等方式提升模型性能.

图6 Transformer 与CAT 生成的图像标题展示Fig.6 Image captions generated by the Transformer and the CAT
3.9 人工评价
在人工评价环节,本文从MS COCO 的测试集中随机选择了500 幅图像,使用Transformer 模型与CAT 模型为其生成图像标题.为了提高评价的可信度,本文将每组标题随机打乱,并提供给5 名评测人员,由他们对标题的“相关性”和“一致性”分别进行比较和评价.其中,相关性的评价标准是图像与标题之间的相关程度,而一致性代表了标题的流畅程度与语义一致性.对于每一幅图像,评测人员必须在上述两种评价指标上选出质量更高的一条标题,当2 名以上评测人员对某一条标题的相关性或一致性表示更加认可时,本文则认定该条标题在对应指标上表现更好.从表8 中可以看出,在图像与标题的相关性方面,Transformer 与CAT 具备相近的生成能力.然而,本文提出的CAT 模型生成的标题具有更强的一致性,评价结果明显优于Transformer 模型,这得益于CACA 模块可以回顾历史语境特征的能力,使语言模型在标题生成的过程中,不断参考过去关注过的信息,体现了视觉连贯性的优势.

表8 Transformer 与CAT 模型的人工评价(%)Table 8 Human evaluation of Transformer and CAT (%)
4 结束语
本文面向图像标题生成任务,针对传统的交叉注意力机制缺乏视觉连贯性的问题,提出了一种语境辅助的交叉注意力(CACA)机制,通过历史语境记忆为注意力模块提供先前关注过的语义信息,为语言模型提供更加丰富的语境特征,从而提升图像标题的生成质量.为了限制每一个CACA 模块分配给历史语境特征的权重总和,本文设计了一种自适应权重约束(AWC),来提升模型的泛化能力.本文将CACA 模块与AWC 方法集成到Transformer解码框架中,构建了一种语境辅助的转换器(CAT)模型.基于MS COCO 数据集的实验结果表明,与现有的多个基线模型相比,本文提出的方法均取得了稳定的提升.本文未来的研究工作将围绕历史语境特征在Transformer 中的跨层交互展开探索.
