基于多尺度特征提取与融合的图像复制-粘贴伪造检测
2023-09-27陈俊韬朱子奇
陈俊韬,朱子奇
(武汉科技大学 计算机科学与技术学院,武汉 430081)
0 引言
随着数字时代的发展,大量含有篡改图像的虚假新闻在网络上传播。在案件分析、法庭取证等重要领域,数字图像常常作为重要的物证,而图像伪造技术会混淆事实,给社会带来巨大危害。
复制-粘贴伪造是一种常见的图像伪造技术[1]。在复制-粘贴伪造中,图像的一部分区域(源区域)被复制粘贴到同一张图像的其他区域(目标区域),以隐藏部分内容或增加部分内容,这改变了图像原本的语义信息[2]。为了让伪造图像更逼真,通常会对被篡改的图像内容执行一些几何学变换(如旋转、缩放、变形等)和后处理操作(如图像模糊、噪声添加、JPEG 压缩等)。复制-粘贴伪造检测(Copy-Move Forgery Detection,CMFD)就是分析一张图像是否经过复制粘贴伪造,输出二进制掩码,其中,黑色部分表示背景(未篡改区域);白色部分表示源-目标区域。
早期的CMFD 研究可以追溯到20 世纪初,主要集中在传统的机器学习方法[3]。传统的CMFD 方法[4]主要分为两类:基于块的方法和基于关键点的方法。基于块的技术将输入图像分割为固定大小的重叠/不重叠的块,再进行特征提取,最后匹配块特征,目前已有许多提取块特征的方法,如离散余弦变换[5]、主成分分析[6]、奇异值分解[7]、梯度直方图[8]、局部二进制模式[9]、zernike 矩[10]等;但这些方法计算代价高昂。基于关键点的技术提取具有鲁棒性的关键点特征,并通过相似性匹配来定位被篡改的区域,尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)[11]和加速稳健特征(Speeded Up Robust Features,SURF)[12-13]是其中最流行的CMFD 方法;但是当源-目标区域光滑时(如天空),这些方法经常检测失败。Meena 等[14]提出了结合基于块和关键点的方法,利用两者互补的特点,取得了良好的效果。传统方法基于先验知识手工提取的特征通常只在特定数据集上表现良好,泛化能力却不足。
近十年,深度学习在计算机视觉领域取得了大量成果,因此,一些研究者试图用深度学习处理CMFD[15]。与传统方法相比,深度学习方法使用神经网络自动提取图像特征,替代了手工提取特征,模型的表现效果往往更好,而且具有良好的泛化能力。由于CMFD 领域公开的数据集只有几百到几千张图像,而深度学习方法常常需要大量的数据驱动,Ouyang 等[16]使用迁移学习,把AlexNet 在ImageNet 数据集上的预训练模型放到少量的CMFD 数据集上作微调,最后输出二分类结果(真/伪),该方法在简单的复制-粘贴伪造图像上表现良好,但是无法像素级地定位篡改区域。Wu 等[17]最先提出了像素级的端到端深度神经网络(Deep Neural Network,DNN)。由于区分伪造图像中的源-目标区域也十分重要,随后他又开创性地提出了BusterNet[18],该网络并行组合两个子网络:Simi-Det 用于检测相似区域;Mani-Det 用于检测篡改区域。BusterNet 最先做到了区分源-目标区域,但是需要两个分支的输出结果都正确才能保证最终的结果可靠;而且,BusterNet 的相似性检测网络在特征提取时只使用了单一尺度的特征,无法有效检测出经过缩放的篡改区域,因此性能有限。Chen 等[19]改进了BusterNet,提出串行组合两个子网络的方法,将前一个网络的输出作为后一个网络的输入,子网络CMSDNet(Copy-Move Similarity Detection Network)负责检测图像中的相似区域,STRDNet(Source Target Region Distinguishment Network)负责对CMSDNet 输出的相似区域中的源-目标区域进行区分。CMSDNet 中使用空洞卷积提取多尺度特征,并使用双重自相关匹配以有效利用多层次的特征,使CMFD 性能得到了明显提升。
在CMFD 中,图像中的篡改区域通常比未篡改区域小很多,以上深度学习方法在训练过程中使用交叉熵损失函数,该损失函数逐像素地计算篡改区域与背景,模型在训练过程中会学到更多的背景特征,导致输出的预测结果偏向于把篡改区域标记为背景,进而拉低了评估指标。同时,这些模型采用沙漏结构,在编码过程下采样丢失的空间信息在解码过程的上采样后无法恢复,这些模型没有利用编码特征以在解码过程中弥补丢失的信息,导致图像中被篡改的小目标的空间信息丢失,从而对小目标的边界识别不精确,影响了输出结果的可视化效果。
本文针对相似性检测问题,进一步改进了检测模型的性能。首先,在特征提取模块的第4 个卷积块中,并行设置3 个不同空洞率的空洞卷积层,进行多尺度的特征提取,再分别进行自相关特征匹配,最后融合这些分支的特征,这样可以有效地检测到不同大小的篡改目标;其次,在特征提取模块与解码模块之间添加跳跃连接,弥补编码特征与解码特征之间的差异;最后,使用Log-Cosh Dice Loss 函数替代交叉熵损失函数,解决CMFD 中存在的类别不平衡问题。
1 相关工作
在CMFD 中,基于深度学习的方法通常可以分为3 个组成部分:特征提取、自相关匹配以及掩码解码。BusterNet 中的相似性检测子网络Simi-Det 的特征提取模块由VGG16[20]的前4 个卷积块组成。自相关匹配模块使用前面提取的特征矩阵与自身的转置做乘法,逐像素计算相似性。在掩码解码过程中使用Inception[21]与上采样层逐渐恢复图像的尺寸,最后使用Sigmoid 激活函数输出二进制掩码。
CMSDNet[19]用于检测图像中的相似区域,定位出复制粘贴伪造图像中的源-目标区域。该网络的特征提取模块的前3 个卷积块与VGG16 对应的部分相同,第4 个卷积块使用3个串行的空洞卷积以增加过滤器的感受野[22],并去掉了池化层以提高分辨率。自相关匹配模块使用特征提取模块中第3 个和第4 个卷积块的输出特征,分别先经过通道注意力增强重要特征,再进行特征自匹配来识别相似的特征,最后把两个分支的特征图融合,这种双重自相关操作可以匹配到多层次的特征。在掩码解码模块,先用空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)获取多尺度的特征,再通过带有空间注意力的卷积层和上采样层逐渐恢复特征图的分辨率,最后使用Softmax 激活函数输出二进制掩码。
CMFD 也可以看作是图像分割任务,目标是逐像素地分类图像中的篡改部分与非篡改部分。U-Net[23]在医学图像分割领域应用广泛,它巧妙地使用跳跃连接,将编码器下采样前的特征与对应的解码器特征融合,消除编码器中下采样操作导致的编码特征与解码特征之间的差异,从而更精准地分割医学图像中的病灶。
基于以上研究,本文在特征提取模块中把第4 个卷积块中的空洞卷积层并行组合,使用了多尺度特征提取、多重自匹配,用特征融合的方法检测图像中不同尺寸的篡改目标。利用跳跃连接把不同分辨率的编码特征传递给解码器,帮助解码器更精准地定位篡改区域。
2 本文方法
由于现有方法存在引言中所描述的不足,本文继续对网络结构进行优化,提出的相似性检测网络结构如图1 所示,记为SimiNet。

图1 SimiNet结构Fig.1 Structure of SimiNet
2.1 网络结构
本文提出的SimiNet 可以分为3 个模块:特征提取模块、自相关模块以及解码模块。
在特征提取模块中,编码器使用VGG16 的前3 个卷积块。由于复制粘贴伪造图像时常常会对篡改区域进行缩放操作,利用多尺度特征可以有效识别出CMFD 中被缩放的篡改区域。因此,在编码器后面加入空洞卷积,并把这3 个空洞卷积并行组合,扩大过滤器的感受野,获取更多不同尺度的信息,还可以让后续的自相关模块同时进行三重自匹配。
在自相关模块中,SimiNet 很自然地直接使用特征提取模块中3 个并行组合的空洞卷积的输出特征进行三重自相关匹配,因此可以匹配到更多尺度上的特征并共享信息。在自相关操作前,特征图先经过通道注意力(Channel Attention,CA)处理,以关注通道上的重要信息。具体地,特征提取模块输出的3 个特征图大小为32×32×512,可以看作32×32 个块特征,每个块特征 512 维,即F={F[i,j]|i,j∈{ 0,1,…,31} }。自相关匹配会计算特征图中每个块之间的相似性,使用皮尔逊相关系数ρ来量化特征之间的相似性,计算公式如下:
最后,自相关模块输出形状为32×32×1 024 的张量S;接着把得到的张量S中各维度的相似性分数按从高到低排序;再通过百分比池化操作过滤掉其中不相关的信息,该操作同时也降低了特征的维度。执行百分比池化操作前,特征的总维度是1 024,百分比池化操作后保留其中的128 个维度的特征。最后把三重自相关匹配的输出结果进行融合操作。
在解码模块中,由于复制-粘贴的区域可能经过缩放,先使用空洞空间金字塔池化(ASPP)提取多尺度特征。接着使用多个Inception 变体进行多尺度的特征提取和融合,每个Inception 后接一个上采样操作以逐渐恢复图像的尺寸。由于特征提取模块中的下采样操作以及解码模块中的上采样操作,使编码特征与解码特征之间存在差异。网络浅层的低级别特征中包含更多的伪造痕迹,而深层的高级别特征中包含更多的语义信息,在CMFD 中含有鉴别伪造痕迹的特征往往比语义特征更重要。为了弥补这些差异,本文把特征提取模块中第2、3 个卷积块的输出特征经过跳跃连接操作后与对应的解码特征融合,帮助解码器更精准地定位篡改区域:
其中:concat 是融合操作;conv3×3是核大小为3×3 的卷积操作,conv1×1是核大小为1×1 的卷积操作;Fe、Fd分别表示编码特征与解码特征。在初步实验中发现,在特征提取模块的第1 个卷积块后添加跳跃连接会损害复制粘贴伪造检测的精度,因此,在第1 个卷积块后不添加跳跃连接。最后通过一个标准卷积层与Softmax 激活函数,输出二进制掩码。
2.2 损失函数
在CMFD 中,篡改区域通常比背景面积小很多,这种现象被称为类别不平衡。当前CMFD 方法中常用的交叉熵损失函数逐像素计算篡改区域与背景,模型在训练过程中会学到更多的背景特征,导致输出的预测结果偏向于把篡改区域标记为背景。因此,交叉熵损失函数不是一种良好的应对类别不平衡问题的方法,而一个合适的损失函数对于深度学习至关重要,此处要求选择的损失函数在监督模型训练时忽略大量的背景像素,重点关注篡改区域。
CMFD 任务中常用的评估指标为F1 分数,它在计算中忽略了大量的背景像素,因此,适用于类别不平衡问题。Dice系数的计算方式等价于F1 分数。因此,理论上来说使用由Dice 系数生成的Dice Loss 作为损失函数,训练得到的模型表现更好。但是Dice Loss 是非凸函数,它会给训练过程带来不稳定性与不确定性,从而导致训练损失无法收敛或者得到的只是局部最优解,而不是全局最优解。本文使用Log-Cosh Dice Loss[24]作为损失函数,Log-Cosh 方法被广泛应用于基于回归问题的曲线平滑,可以表示为:
其中,L′(x)为L(x)的导数。由于tanhx的值域为[-1,1],L(x)的一阶导数连续且有界,因此,Log-Cosh 方法可以修复Dice Loss 的非凸特性。假设模型输出的二进制掩码为p,真实的掩码为y,损失函数计算公式如式(6)~(7)所示,SimiNet 的目标是最小化损失Llc-dce。
3 实验与结果分析
3.1 数据集
CMFD 领域公开的数据集通常只有几百到几千张图像。Wu 等[18]创建了一个包含105张图像的合成数据集USCISI,以8∶1∶1 的方式划分为训练集、验证集和测试集。将本文的SimiNet 在USCISI 训练集上进行训练,在验证集上挑选超参数,最后在测试集上验证效果。同时,为了测试SimiNet 的泛化能力,在两个公开数据集CASIA v2.0[25]与CoMoFoD[26]上验证模型的表现。这3 个数据集的详细信息如表1 所示。CASIA 数据集是Wu 等[18]从CASIA v2.0 中手动挑选的1 313张复制粘贴伪造图像,并生成了对应的真实掩码,没有使用该数据集全部的复制粘贴伪造图像。

表1 数据集信息Tab.1 Information of datasets
3.2 评估指标
本文使用像素级的F1 分数作为评估CMFD 表现的指标。评价方法与BusterNet[18]中的方案B 相同,即先计算每张图像的F1 分数,然后在整个测试集上取平均值。对于一张测试图像,在像素级上计算TP(True Positive)、FP(False Positive)、FN(False Negative)。其中,TP表示正确识别出的被篡改的像素;FP表示错误标记为被篡改的像素(误报);FN表示错误标记为未篡改的像素(漏报)。分别按如下公式计算准确率P和召回率R:
用式(9)计算像素级的F1 分数;F1 分数越大,检测效果越好。
3.3 实验细节
SimiNet 的全部代码都是使用keras 框架实现。训练时使用Nadam 优化器,初始学习率设置为0.001,批大小为16。当验证损失连续10 轮不下降,将学习率调整为10-4并继续训练,当验证损失再次经历10 轮不下降就停止训练,选择其中表现最好的一组权重。本文不对模型输出的二进制掩码执行任何的后处理操作。
3.4 实验结果
3.4.1 消融实验
本文通过消融实验验证SimiNet 是否有益于CMFD,实验结果如表2 所示,其中:base 表示基础模型(特征提取模块中串行排列3 个空洞卷积,并且不使用跳跃连接);skip 表示添加了跳跃连接;multi-channel 表示使用并行的空洞卷积并进行多重自相关匹配。可以看出,相较于模型1,添加跳跃连接后的模型2 的F1 分数提升了4.19 个百分点,验证了跳跃连接的有效性,它弥补了编码特征与解码特征之间的差异,因此能更精确地定位篡改区域的边界。把base 中串行排列的空洞卷积改为并行,并且进行多重自相关匹配后,模型3的性能大幅提高,F1 分数相较于模型1 提升了9.54 个百分点,验证了多尺度特征提取与融合对CMFD 的重要性,这是因为复制粘贴伪造图像中的篡改区域通常都经过缩放,利用多尺度的特征可以有效识别出这些篡改痕迹。在此基础上继续添加跳跃连接,相较于模型3,模型4 的F1 分数又提升了1.16 个百分点。综上,与基础模型相比,模型4(即SimiNet)的F1 提高了10.7 个百分点,后续的实验都使用表现最好的这一组模型。以上结果验证了多尺度特征提取与融合以及跳跃连接的有效性。

表2 SimiNet在USCISI数据集上的消融实验结果Tab.2 Ablation experimental results of SimiNet on USCISI dataset
3.4.2 Log-Cosh Dice Loss与交叉熵损失对比
交叉熵损失逐像素计算篡改区域与背景,在CMFD 中类别不平衡的情况下,使用交叉熵损失会偏向于把伪造区域识别为背景,导致F1 分数偏低。Dice 损失在图像分割中十分常用,对于轻微的数据不平衡问题有一定的帮助[24]。本文使用Log-Cosh Dice Loss 替代交叉熵损失,对BusterNet 的相似性检测子网络(简写为BusterNet-simi)、CMSDNet 以及本文的SimiNet 这3 个模型进行对比实验,并对比了分别使用Log-Cosh Dice Loss 与交叉熵损失进行训练的表现差异,结果见表3。可以看出,使用Log-Cosh Dice Loss 作为损失函数的实验组都表现得比使用交叉熵的对照组好,F1 分数分别提高了3.56、2.08 和2.14 个百分点。而且,同样使用Log-Cosh Dice Loss 作为损失函数,SimiNet 的F1 比CMSDNet 提高了1.31 个百分点,再次验证了本文方法的有效性。

表3 在USCISI数据集上3个模型使用不同损失函数的F1 单位:%Tab.3 F1 scores of three models with different loss functions on USCISI dataset unit:%
3.4.3 在USCISI数据集上的实验对比
为了验证本文SimiNet 的有效性,将两种传统方法与两种基于深度学习(deep learning)的方法作为对比基线。传统方法中,本文选择了文献[27]中的基于块(block-based)的方法与文献[28]中的基于关键点(key point-based)的方法;两种深度学习方法分别是BusterNet-simi[18]与CMSDNet[19],实验结果如表4 所示。可以看出,深度学习方法比传统方法表现更好。SimiNet 表现最佳,F1 分数达到了72.54%,比次优的CMSDNet 方法提高了3.39 个百分点,因为SimiNet 使用了多尺度特征提取和融合,进行了三重自相关匹配,还引入了跳跃连接以及Log-Cosh Dice Loss。同时,SimiNet 的参数量比CMSDNet 更小,说明了SimiNet 的性能提升不是因为模型更复杂引起的,而是由于模型的结构更适用于CMFD。在时间复杂度方面,SimiNet 的运算量也比CMSDNet 更少,表明SimiNet 的运行效率更高。综上,SimiNet 的性能从整体上超越了CMSDNet 方法。
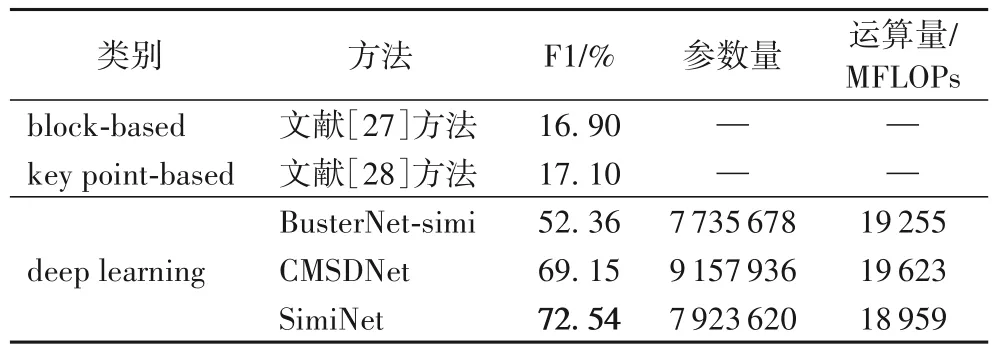
表4 不同类别方法在USCISI数据集上的检测表现对比Tab.4 Comparison of detection performance of different types of methods on USCISI dataset
3.4.4 在CASIA与CoMoFoD数据集上的实验对比
为了测试模型的泛化能力,本文在两个公开数据集(CASIA 与CoMoFoD)上进行实验。CASIA 数据集中包含的部分图像把目标区域复制粘贴到具有相似背景的其他位置,导致图像的伪造检测难度更大。观察表5 可以看出,SimiNet在两个数据集上都取得了最好的结果,虽然与次优的CMSDNet 方法表现接近,但是SimiNet 的参数量与运算量都比CMSDNet 小,模型更轻量化。与CMSDNet 相比,SimiNet 的优势在于能更精确地定位被篡改的小目标的边界。从表5中还可以发现,深度学习方法整体上比传统方法表现更好,这两个传统方法在CASIA 数据集上表现不理想,但是在CoMoFoD 数据集上的检测结果与深度学习方法差距不大。
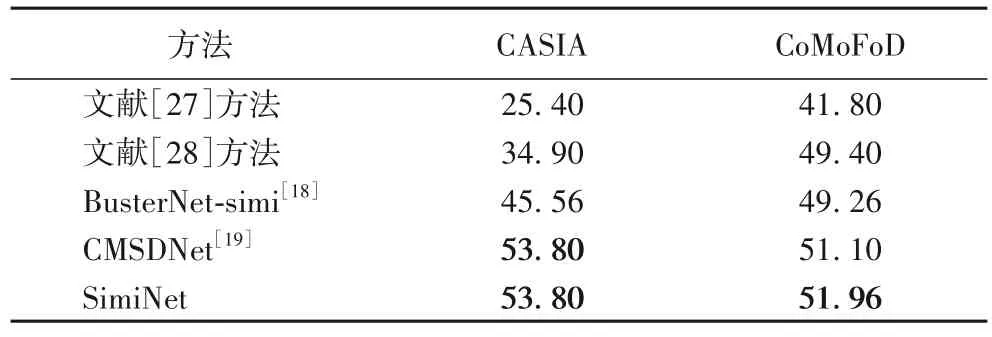
表5 在CASIA与CoMoFoD数据集上的F1对比 单位:%Tab.5 Comparison of F1 on CASIA and CoMoFoD datasets unit:%
CoMoFoD 数据集中应用亮度改变、对比度调整、颜色降低、图像模糊、JPEG 压缩与高斯噪声添加等后处理操作,可以用来测试模型对抗攻击的能力。实验结果如图2 所示,可以看出,SimiNet 总体表现良好,具有一定的抗攻击性,但是对JPEG 压缩比较敏感,特别是当压缩因子为20 或30 时,压缩程度太高,模型表现不佳。这可能是由于训练集中的图像被压缩的程度较低,模型没有学习到抗JPEG 压缩的特性。

图2 在CoMoFoD(带攻击)数据集上的F1分数Fig.2 F1 scores on CoMoFoD dataset under attacks
本文在图3 中可视化展示了一些检测结果的对比图像,并标出了对应的F1 分数。从图3 可以看出,SimiNet 比其他方法定位的伪造区域更精确,对图像篡改区域的边界的识别效果更好,这主要是由于引入的跳跃连接弥补了编码特征与解码特征之间的差异。观察图3(b)中图像5 可以发现,SimiNet 可以精确检测到图中小人的两条腿,预测的结果与真实的掩码很相似,而其他两个方法的输出无法区分人的两条腿。类似的结果还有图3(a)中图像3 中的天鹅与图像4中的小狗,这验证了本文方法的有效性。同时,F1 分数高的预测结果在视觉上确实表现更佳,证明了该评估指标的有效性。

图3 相似性检测的可视化比较与对应的F1分数Fig.3 Visual comparison of similarity detection and corresponding F1 scores
4 结语
本文提出了一种基于多尺度特征提取与融合的方法SimiNet 用于图像复制粘贴伪造检测。使用多尺度特征提取与融合方式,可以有效检测出复制粘贴伪造图像中经过缩放的篡改目标;添加跳跃连接可以帮助解码器利用编码器中高分辨率特征图中的伪造痕迹来更精确定位篡改区域;Log-Cosh Dice Loss 可以有效应对CMFD 中存在的类别不平衡问题。在3 个公开数据集上的实验结果验证了SimiNet 比其他对比的CMFD 方法表现更好。
在CMFD 任务中,相似性检测通常是区分源-目标区域的先决条件,它的效果直接决定了后续区分源-目标区域工作的可靠性。下一步计划研究区分源-目标区域的方法,这对于CMFD 也十分有意义。
