用于语音检索的三联体深度哈希方法
2023-09-27张秋余温永旺
张秋余,温永旺
(兰州理工大学 计算机与通信学院,兰州 730050)
0 引言
随着互联网多媒体数据检索等实际应用的爆炸式增长,迫切需要海量大数据的快速检索方法[1]。在现有的深度神经网络技术中,哈希方法因快速的查询速度和较低的内存成本,已成为最流行和有效的技术之一[2]。
目前,深度哈希方法被广泛应用于图像检索[3-4]、语音检索[5-6]、语音识别[7-8]等领域。图像领域采用三联体标签(锚图像、正图像、负图像)[4]的深度哈希方法能生成兼具语义信息和类别信息的哈希码,三联体标签提供了数据之间相对相似的概念,确保在学习的哈希码空间中,最大化锚图像和负图像之间的距离,同时最小化锚图像和正图像之间的距离,使生成的哈希码具有最大鉴别力。因此,要想更准确、快速地从海量语音数据中检索到所需的语音数据,如何生成更高效紧凑的哈希码是亟须解决的问题。
传统语音检索采用的语音特征有梅尔频率倒谱系数(Mel Frequency Cepstral Coefficient,MFCC)[9]、功率归一化倒谱系数(Power-Normalized Cepstral Coefficient,PNCC)[10]、线性预测倒谱系数(Linear Predictive Cepstral Coefficient,LPCC)[11]等。与一维特征参数不同,语谱图[12]以二维模式携带时域频域信息,是语音特征很好的表现形式。将语音转换成语谱图图像的形式,从语谱图图像的角度研究基于深度学习的语音检索方法,可将图像领域中的三联体深度哈希方法的优势在语音检索领域发挥出来,对于海量语音数据检索具有重要的研究意义和应用价值。
综上所述,为提高语音检索效率和精度,确保生成的二值哈希码更加高效紧凑,且具有最大鉴别力,本文引入注意力机制-残差网络(Attentional mechanism-Residual Network,ARN)模型,给出了一种用于语音检索的三联体深度哈希方法。本文的主要工作如下:
1)提出空间注意力力机制和三联体交叉熵损失对深度网络进行端到端训练,同时利用三联体标签进行语音特征和深度哈希码的学习,使模型在提取高级语义特征时充分利用数据集内的相似关系,学习具有最大鉴别力的深度哈希码。
2)为了利用数据之间的相对相似性关系,采用二次特征提取方法,提取语音数据的低级语谱图图像特征,并从同一类中随机选取相同语义的两幅语谱图图像特征作为锚语谱图图像特征和一幅正语谱图图像特征,从不同类中随机选取一幅负语谱图图像特征生成一组三联体作为网络的输入。
3)为了充分提取高级语义特征,利用ARN 模型,自主聚集整个语谱图能量显著区域信息,提高显著区域表示。引入一种新的三联体交叉熵损失函数,通过同时惩罚语义相似性和分类损失来保留深度哈希码中的分类信息。
1 相关工作
近年来,监督信息以三联体标签标记数据的深度哈希方法已广泛应用于图像检索、人脸识别等领域。Cao 等[3]通过构建具有度量学习目标函数的三重网络来充分提取图像的代表性特征并构建哈希码,可有效地检索同一类图像;Li等[4]提出了结合三态似然损失和线性分类损失的三重深度哈希方法,可使生成的哈希码具有更高的查询精度;Li 等[13]提出利用三重排序信息和铰链损失函数来度量框架下的相似度信息和分类信息;Long 等[14]提出了一种结合注意力模型的深度哈希检索算法,可充分提取有用信息,减少无用信息,并引入一种新的三联体交叉熵损失提高模型的表达能力,生成高质量的哈希码。Liao 等[15]提出基于三重深度相似度学习的人脸识别卷积神经网络(Convolutional Neural Network,CNN),使学习到的哈希码同一类之间的距离尽可能小,而不同类之间的距离尽可能增大。
现有基于内容的语音检索方法有基于感知哈希、基于生物哈希、基于深度哈希等方法。如Zhao 等[16]提出一种利用语音信号的分形特征和分段聚合逼近技术生成感知哈希序列的检索算法;He 等[17]提出一种基于音节感知哈希的语音检索方法;Huang 等[18]提出一种基于谱图的多格式语音生物哈希算法;Zhang 等[6]提出一种基于CNN 和深度哈希的语音检索方法。现有基于内容的语音检索算法采用的深度哈希方法存在一定的局限性,都是通过单标签标记数据来学习哈希码,并只考虑一种监督损失,导致监督信息利用不足,不能生成紧凑和区别化的哈希码,影响语音检索的效率及精度。
随着深度学习技术的发展,用语谱图图像特征来表示语音信号的方法被广泛应用于语音识别。语谱图生成原理采用快速傅里叶变换(Fast Fourier Transform,FFT)[8]、离散傅里叶变换(Discrete Fourier Transform,DFT)[12]、短时傅里叶变换(Short-Time Fourier Transform,STFT)[19]等方法。Fan 等[8]提出以语谱图作为网络输入,充分利用CNN 对图像识别的优势提取语谱图特征,提高说话人识别性能。基于仿生学的思想,Jia 等[12]提出一种基于语谱图图像特征和自适应聚类自组织特征映射(Self-Organizing feature Map,SOM)的快速说话人识别方法。Wang 等[19]提出两种新颖的深度CNN——稀疏编码卷积神经网络和多卷积通道网络,以语谱图作为输入,分层进行特征学习。
2 本文方法
2.1 三联体深度哈希系统模型
图1 为利用ARN 模型设计的三联体深度哈希的系统模型。主要由三个部分组成:1)语谱图图像特征深度语义学习;2)哈希码学习;3)交叉熵损失函数。该模型旨在从具有给定的三联体标签的原始语谱图图像特征中学习紧凑的哈希码。哈希码应该满足以下要求:1)锚语谱图图像特征应该在哈希空间中靠近正语谱图图像特征,远离负语谱图图像特征;2)基于空间注意力力机制和交叉熵损失函数,对ARN模型进行端到端训练,可同时利用三联体标签进行语谱图图像特征学习和哈希码学习。

图1 三联体深度哈希系统模型Fig.1 Model of triplet deep hashing system
本文提出的三联体深度哈希方法,实质上是将语音数据处理成语谱图图像特征,以语谱图图像特征作为训练数据和测试数据;然后利用图像领域发展成熟的三联体深度哈希方法训练网络,提取语谱图图像特征的深度语义特征;并通过哈希构造将高维向量转换成低维的二进制哈希码,减少检索的计算时间,提升检索效率,并在残差网络(Residual Network,ResNet)的基础上嵌入空间注意力模块,充分提取语谱图图像特征的能量显著区域。因此,本文提出的三联体深度哈希方法完全适用于训练语音数据。
本文的网络体系结构主要分为三个模块和三个全连接(Fully Connected,FC)层,包括:1 个net1 模块、1 个空间注意力模块、1 个net2 模块和3 个FC 层。net1 模块包含1 个残差块和1 个最大池化层,后面是1 个空间注意力(Spatial Attention,SA)模块(SA 模块用于生成1 个与输入特征图相乘的注意力图)。net2 模块包含1 个残差块和1 个平均池化层,之后连接1 个FC 层,用于将提取的特征扁平;FC 层之后是哈希层,哈希层的节点数即目标哈希码的长度,目的是生成语音数据的哈希码;在哈希层之后设置一个节点数为语音数据片段类别数的输出层,可在模型训练时调节哈希层的神经元活动,帮助哈希层生成包含类别语义信息和语义内容信息的哈希码。模型参数的具体设置如表1 所示。
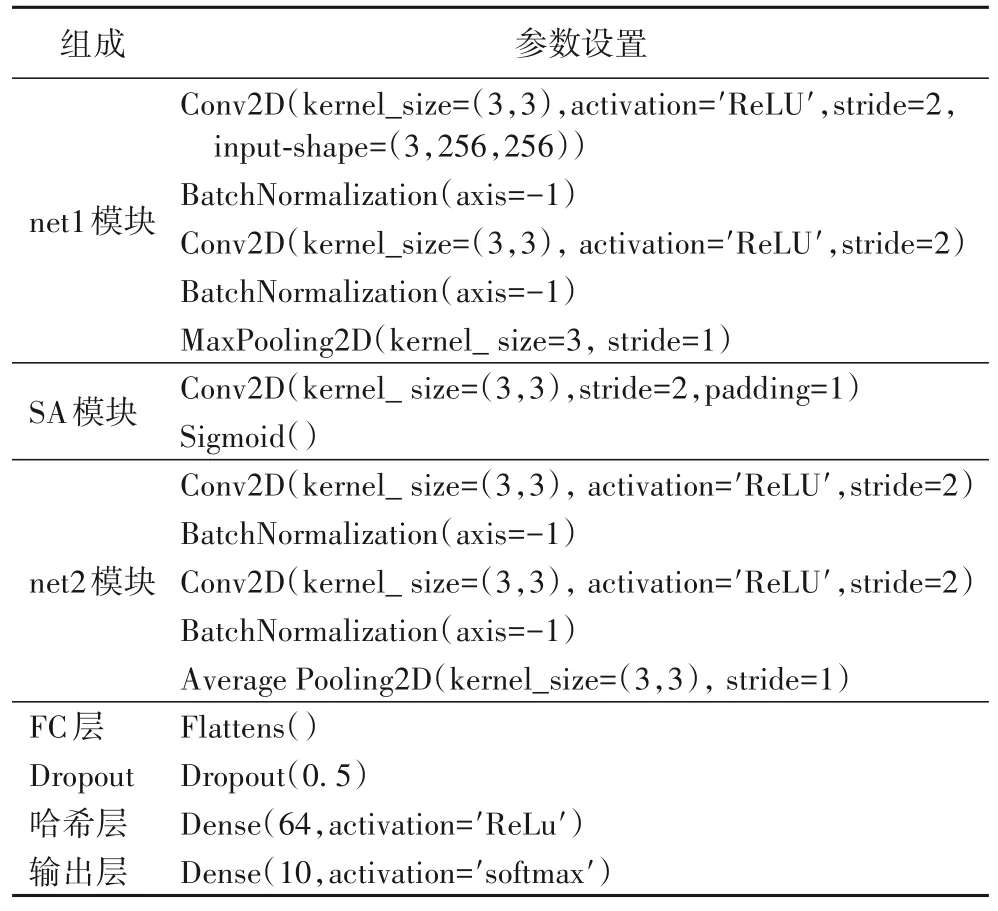
表1 深度哈希编码模型的参数设置Tab.1 Parameter setting of deep hash encoding model
所有的卷积和池化层使用3×3 的过滤器,卷积层、池化层步幅分别设置为2 和1。除输出层与空间注意力模块分别采用softmax 与Sigmoid 激化函数外,所有卷积层和FC 层都配备了修正线性函数(Rectified Linear Unit,ReLU)激活功能。
2.2 网络体系结构设计
ResNet 是He 等[20]提出的残差模块结构,如图2 所示。即增加一个恒等映射,将原始的函数H(X)转换为F(X)+X,两种表达的效果相同,但是F(X)的优化要比H(X)简单得多,可以加快模型的训练、提高训练效率,并且当模型层数增加时,可非常有效地解决网络退化问题。

图2 残差模块结构Fig.2 Residual module structure
另外,本文方法使用的空间注意力模块是对卷积块注意力模块(Convolutional Block Attention Module,CBAM)[21]改进后的变体,即在没有通道注意力模块的情况下,生成一个有效的特征描述符,以增强语谱图图像特征能量显著区域的特征,如图3 所示。

图3 空间注意力模块Fig.3 Spatial attention module
设X∈RC×H×W是从卷积层提取的特征映射,其中H、W、C分别表示每个特征映射的高度、宽度以及该层中特征映射(或通道)的数量。空间注意力模块利用最大池化Max(X)和平均池化Avg(X)操作沿通道轴线联合聚合特征映射X的空间信息。两种操作分别取特征映射X的局部最大值和平均值,然后使用Max(X)和Avg(X)按元素相乘,进一步加权局部突出区域,最后通过一个卷积层减少特征映射的数量。加权运算的输出是Sigmoid 函数,然后乘以特征映射X。改进后的空间注意力模块定义为式(1):
其中:Max(X)和Avg(X)为H×W×1 维;∂表示Sigmoid 函数。
2.3 深度哈希码构造
深度哈希码构造的实质是通过训练图1 的ARN 学习一个哈希函数H(⋅),将模型提取的高维向量βi压缩映射成一段二进制哈希码,hi,k=H(βi),hi,k∈{0,1}k,k代表哈希序列的长度。哈希函数H(⋅)必须满足原相似或不相似的高维特征在哈希映射之后的相似性不变。深度二进制哈希码构造的实现原理如下:
步骤1 提取初级语谱图图像特征。提取训练集中原始语音文件S={s1,s2,…,sn}的语谱图图像特征I,即I={I1,I2,…,In}。设置FFT 点数为512,采用频率为44 100,帧叠点数为384,窗函数采用汉明窗,具体提取流程如下:
1)分帧加窗。对重采样格式转换后的语音数据进行分帧加窗,并根据式(2)进行加窗处理:
其中:w(n)表示窗函数;si(n)表示加窗处理后的第i帧语音信号为幅值归一化处理后的语音信号;T表示移动帧长;N是时间长度。
2)FFT。对分帧加窗后的语音信号进行FFT,根据式(3)实现时-频域的转换:
其中:X(g)表示FFT 后得到的频域信号;g表示点序号。
3)取功率谱。根据式(4)可将语音信号的频谱取模的平方,得到语音信号的功率谱。
其中:X(g)是输入的频域信号;S(g)是得到的功率谱。
4)取对数。对功率谱进行对数运算,得到语谱图图像特征。
步骤2 生成三联体语谱图图像对。随机将训练数据I分成一些组,然后为每一对锚-正语谱图图像特征随机选择一个负语谱图图像特征,根据式(5)选取三联体。
其中:W,b分别表示哈希层的权重矩阵与偏置向量;μARN表示残差网络模型中的卷积层、池化层、空间注意力机制的参数向量,f(Ii,μARN)表示输入数据Ii在经过卷积、池化、空间注意力机制后所提取的特征向量;βi表示所提取到的深度语义特征向量。Wa、Wp、Wn分别表示从哈希层中提取的三联体深度语义特征向量Wi=(w1,k,w2,k,…,wm,k) (i∈{a,p,n})。其中,k代表哈希层的节点数。
步骤4 构造深度哈希序列。将提取的深度语义特征Wa、Wp、Wn进行哈希构造,生成哈希序列Hi=h1,k,h2,k,…,hm,k(i∈{ a,p,n})。
深度二进制哈希码具体构造过程如下:
为了创建二进制哈希码,首先通过式(7)线性缩放的方法将三联体深度语义特向量βi映射到[0,1]区间,即:
其中,umin和umax代表每个语谱图图像特征的深度语义特征向量值(u)中的最小值和最大值。然后利用哈希函数H(⋅)进行哈希映射,并根据式(8)将[0,1]区间的深度语义特征向量T映射成为k比特的二进制哈希码。
再通过式(9)进行深度哈希序列构造:
其中,Smeadian表示[0,1]区间每个语谱图图像特征深度语义特征向量值中的中值。
2.4 交叉熵损失函数
ARN 模型学习从输入三联体语谱图图像特征到三元哈希码的映射Hi=h1,k,h2,k,…,hm,k(i∈{a,p,n}),Ha到HP的距离应小于Ha到Hn的距离。为了使生成的哈希码具有最大类的可分性和最大哈希码可鉴别性,在模型训练过程中采用三联体交叉熵损失来训练网络,目的是在模型训练过程中,同时保留相似度和分类信息。
在模型的训练过程中,ARN 模型使用三联体标签和标注标签进行训练,以同时执行哈希码学习和分类似然学习。三联体标签T对应的标注标签可以表示为Y=并且表示训练标签)。为了惩罚三联体标签的相似性损失,将输入映射到目标空间,使用欧氏距离比较目标空间中的相似性,并确保锚语谱图图像特征与正语谱图图像特征的哈希码尽量接近,锚语谱图图像特征与负语谱图图像特征的哈希码应尽量远离。基于这一目标设计了铰链排序损失形式,使相似语谱图图像特征对之间的距离最小,不相似语谱图图像特征对之间的距离最大。三元组标签的损失定义如下:
其中:Dis(t,)为度量哈希码输出之间距离的L2 范数;k为哈希码的长度;r∈[0,1]为控制不同语谱图图像特征区分度惩罚强度的权重参数,r=0.5。为了惩罚标注标签下的分类损失,通过联合考虑输入的三联体语谱图图像特征来定义交叉熵损失,如式(11)所示:
其中:CE(,)为常见的交叉熵损失形式为预测类。对于相似损失ξ(T)和分类损失ξ(T,Y),通过反向传播两者的和来更新模型的权值。理论上,交叉熵损失有利于保留哈希码中的分类信息,三重态损失函数也可以通过鼓励哈希码最小化类内相似度、最大化类间相似度来提高分类性能。
3 实验与结果分析
3.1 实验环境及主要参数设置
为评估三联体深度哈希方法的性能,本文从理论和实验两方面进行分析。采用CSLT 发布的汉语语音数据库THCHS-30[22]作为数据集,总时长约30 h,采样频率为16 kHz,采样精度为16 B 单通道wav 格式语音段,每个语音片段的时长大约为10 s。实验中随机选取了内容不同的10类语音,并进行MP3 压缩、重采样(8-16 Kb/s)、重量化1(16-8-16 Kb/s)、重量化2(16-32-16 Kb/s)等4 种内容保持操作(Content Preserving Operation,CPO)后,得到共计3 060 条语音片段。在实验分析阶段,随机选取1 000 条THCHS-30 语音库中的语音片段进行评估。
在硬件平台为Intel Core i5-2450M CPU 2.50 GHz,内存16 GB;软件环境为Windows 10,PyCharm 2021.1.1、PyTorch-CPU 2.1.x+Python3.6 的环境下进行实验对比。
3.2 深度哈希编码模型性能分析
在语音检索系统中,语音数据的深度语义特征提取和高质量哈希码的生成对语音检索的精度至关重要,其中哈希层的维度实际上为哈希码的长度。当哈希层的维度不同时,模型的准确率会呈现一定的变化。因此,本文采用语谱图图像特征[8,12,19]与Log-Mel 谱图图像特征[23]作为网络模型的输入,来评估不同哈希码长度下模型的准确率。图4 为使用本文方法的语谱图图像特征和Log-Mel 谱图图像特征模型在不同哈希编码长度下的测试准确率曲线。

图4 不同哈希码长度k的测试准确率曲线Fig.4 Test accuracy curves of different hash code lengths k
从图4 可以看出,在不同哈希码长度k下,本文模型在输入语谱图图像特征/Log-Mel 谱图图像特征时,模型的测试准确率曲线几乎都快逼近1,性能表现卓越。哈希码长度为64时,两种特征下的模型测试准确率曲线都已达到最高,这是因为本文方法借鉴了图像领域发展成熟的三联体深度哈希方法,在生成哈希码的过程中,提供了数据相对相似的关系,以及网络模型中嵌入的注意力机制能够自主聚集整个语谱图图像特征/Log-Mel 谱图图像特征的能量显著区域,提高了显著区域表示,充分提取了深度语义信息。另外,当本文模型输入语谱图图像特征/Log-Mel 谱图图像特征时,在不同哈希层节点下,在训练批次15 或10 时,测试准确率曲线已基本趋于稳定,并取得了很好的效果,不再有任何变化,这说明模型没有过拟合和欠拟合现象,对输入数据的拟合程度表现良好。两种特征下,模型的收敛程度不同是由于语谱图图像特征频率范围跨度大,语义信息量更丰富,计算量更大。当哈希码长度为64 时,模型的测试准确率最高,这说明哈希码节点数为64 时可以满足检索系统的基本要求,而过长的哈希码会导致语音检索系统的检索效率下降,过短的哈希码会对语音数据的语义信息表达不全面,造成哈希码之间区分性的降低。因此,本文三联体深度哈希方法的哈希码长度为64时的模型架构表现最好,可用来生成更紧凑的哈希码。
3.3 精度分析
为了评价本文方法的性能,使用平均精度均值(mean Average Precision,mAP)进一步衡量在不同哈希码长度下网络模型的性能表现。同时,为了测试语谱图图像特征和Log-Mel 谱图图像特征在作为模型的输入时,模型所生成的哈希码的鲁棒性,在实验之前,先对语音数据进行MP3 压缩、重采样(8-16 Kb/s)、重量化1(16-8-16 Kb/s)、重量化2(16-32-16 Kb/s)等4 种CPO,共得到4 000 条语音数据。
本拓扑中网端提供单相交流高压电,输入级采用多个不控整流模块串联级联的方式,同时为保证网端能接近单位功率因数运行,需要在整流环节加装有源功率因数校正单元。
采用CPO 后的语音数据生成的哈希码进行测试,先采用三联体标签/单标签的方法,利用ARN 模型对各种CPO 后的语音数据所生成的语谱图图像特征/Log-Mel 谱图图像特征计算它们的平均精度(Average Precision,AP),然后再根据AP 值计算mAP。同理,利用深度平衡离散哈希(Deep Balanced Discrete Hashing,DBDH)[24]、改进的深度哈希(Improved Deep Hashing Method,IDHM)[25]对CPO 后的语谱图图像特征/Log-Mel 谱图图像特征计算mAP,并与文献[6,26]中的方法进行对比。给定一个锚语谱图图像特征xq,使用式(12)计算它的平均精度:
其中:Rk为相关语音片段数目;p(k)为返回列表中截止点k处的精度;Δr(k)为指示函数,如果第k个位置上的返回语音片段与xq相关,则该指示函数等于1;否则Δr(k)为0。给定Q次查询,mAP 为已排序的所有查询结果的AP。mAP 计算如式(13)所示:
表2 为不同哈希码长度下,利用本文三联体标签/单标签的方式将语谱图图像特征和Log-Mel 谱图图像特征分别送入ARN 模型的mAP 对比结果。
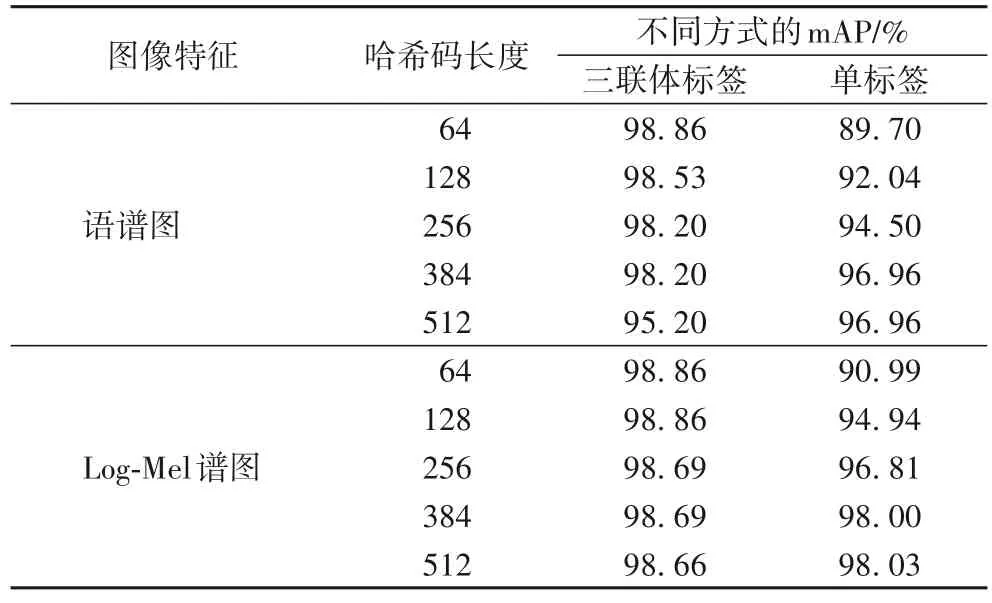
表2 不同哈希码长度下同一编码模型的mAPTab.2 mAP values of same encoding model under different hash code lengths
由表2 可知,同在ARN 编码模型下,将语谱图图像特征/Log-Mel 谱图图像特征以三联体标签的方式送入编码模型,它的编码模型的mAP 值与哈希码长度成反比,这是因为三联体标签信息会编码数据集内的相似关系,以及ARN 编码模型利用三联体交叉熵损失函数并实现了最大的类可分性和最大的哈希码可分性,当哈希码长度为64 时,mAP 就已达到最高。而利用单标签方法将语谱图图像特征/Log-Mel 谱图图像特征送入编码模型,它的编码模型的mAP 值与哈希码长度成正比,这是因为单标签对监督信息利用不足以及ARN 编码模型只考虑了一种损失,所以越长的哈希码对语音数据的语义信息表达越全面。由表2 可知,同在ARN 编码模型下,采用三联体标签的方法和单标签方法,设置哈希层不同的节点数,编码模型的mAP 基本都保持在90%以上,说明ARN 编码模型具有很好的鲁棒性。
表3 为不同哈希码长度下不同编码模型的mAP 的对比结果。其中,文献[24-25]中的实验数据是对语谱图图像特征/Log-Mel 谱图图像特征的运行结果。本文利用语谱图图像特征/Log-Mel 谱图图像特征,采用三联体标签的方法,将数据送入ARN 编码模型进行训练,生成哈希码。由表3 可知,相较于文献[6,24-26],当哈希码长度k为64、128、256、384 时,ARN 模型的mAP 最高,这说明ARN 模型的鲁棒性最优。当哈希码长度k为512 且模型输入特征为语谱图图像特征时,文献[6,26]方法的mAP 值略高于本文方法。主要有两个原因:1)本文方法采用的三联体标签本身比成对标签、单标签包含更丰富的语义信息,因为每个三联体标签可以自然地分解为两个成对的标签,明显地提供了数据之间相对相似的概念;2)本文方法同时利用注意力机制和三元交叉熵损失函数训练网络,充分提取语义信息并将类别信息嵌入到所学习的哈希码中,所以ARN 模型在哈希码长度为64 时,mAP值已最高,过长的哈希码太过冗余,反而影响mAP 值。文献[24-25]方法是成对标签,包含的语义信息和类别信息欠缺,且所采用的深度卷积神经网络模型需要150 次以上的迭代mAP 才能达到高精度,当迭代次数与本文方法一样,同为50 次的时候,模型的mAP 值精度不高,这是因为文献[24]方法采用的是平衡离散哈希方法,通过离散梯度传播和直通估计器优化哈希码,虽避免了传统连续松弛法带来的量化误差,但是增加了复杂度;文献[25]中引入了基于标准化语义标签的两两量化相似度计算方法以及采用量化损失来控制哈希码的质量,增加了算法复杂度;文献[6,26]中采用单标签方法且只考虑一种损失,造成监督信息利用不足,所以只有当哈希码长度为512 时,编码模型的mAP 值才能达到高精度。因此,本文方法采用的哈希编码模型具有良好的性能。
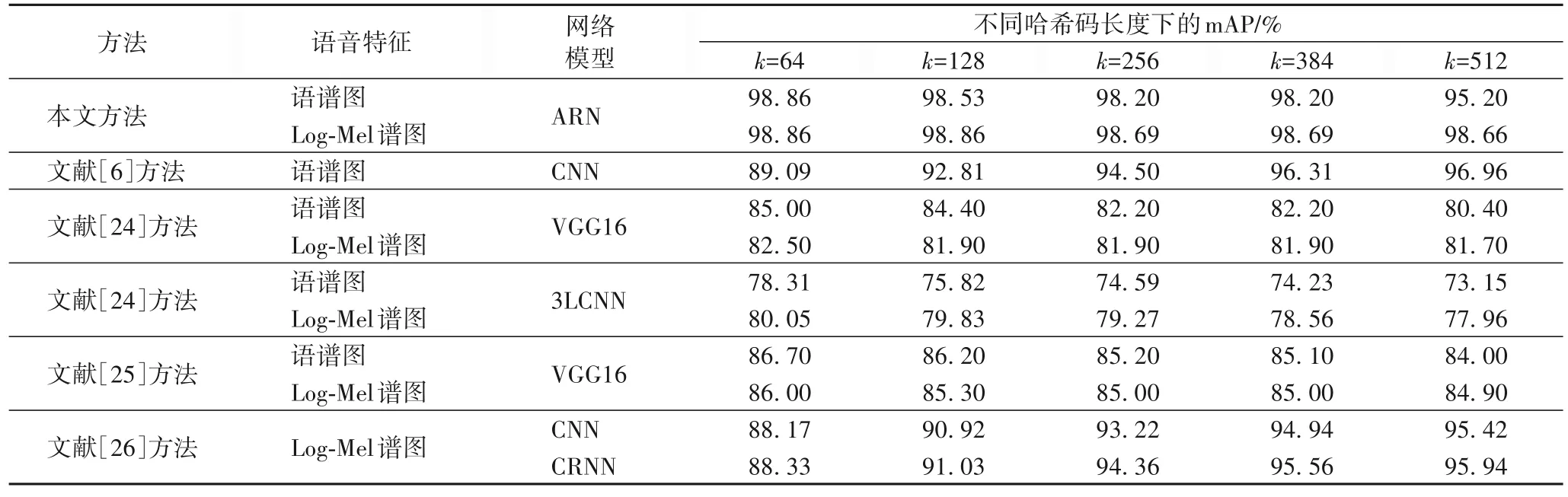
表3 不同哈希码长度下不同编码模型的mAP值Tab.3 mAP values of different encoding models under different hash code lengths
由表3 可知,通过对两种特征的mAP 值的权衡考虑,后续实验评估采用哈希码长度为64 的ARN 编码模型。
3.4 检索性能评估
查全率R又称作召回率,表示检索返回的列表中,查询出来的语音片段与查询相关的语音片段所占的比例。计算公式如(14)所示:
其中:TP、FN分别表示检索到的与查询相关的语音片段的数目,以及未检索到与查询相关的语音片段数目;TP和FN的和为语音数据库中与查询相关的语音片段的总数。
查准率P为检索精度,表示返回的列表中,查询为真的语音片段所占的比例,计算公式如(15)所示:
其中:FP表示检索到与查询无关的语音片段的总量,TP和FP的和为返回的语音片段的总量。
因为查全率和查准率是反依赖的关系,所以用F1 分数作为测试指标。F1 分数越大,说明检索性能越好。计算公式如(16)所示:
图5 为不同标签方法下不同特征的P-R曲线。实验分别利用三联体标签/单标签方式将语谱图图像特征和Log-Mel谱图图像特征送入ARN 模型中,来测试两种标签方式下两种特征的查全率和查准率。

图5 不同标签方法下不同特征的P-R曲线Fig.5 P-R curves of different features under different labeling manners
从图5 可知,在哈希码长度均为64 的时候,本文方法三联体标签比单标签方式下的查全率、查准率更高,说明在同等哈希码长度下,三联体标签方式能生成更高效紧凑的哈希码,这是因为三联体深度哈希编码模型在生成哈希码的过程中,会充分利用三联体之间的相似关系、三联体交叉熵损失函数,而单标签方式相比三联体标签方式,监督信息不足。
为评估本文方法的检索性能,采用哈希编码长度为64的ARN 模型来测试查全率、查准率和F1 分数,与现有方法[19,26-28]的检索性能进行了对比,对比结果如表4 所示。
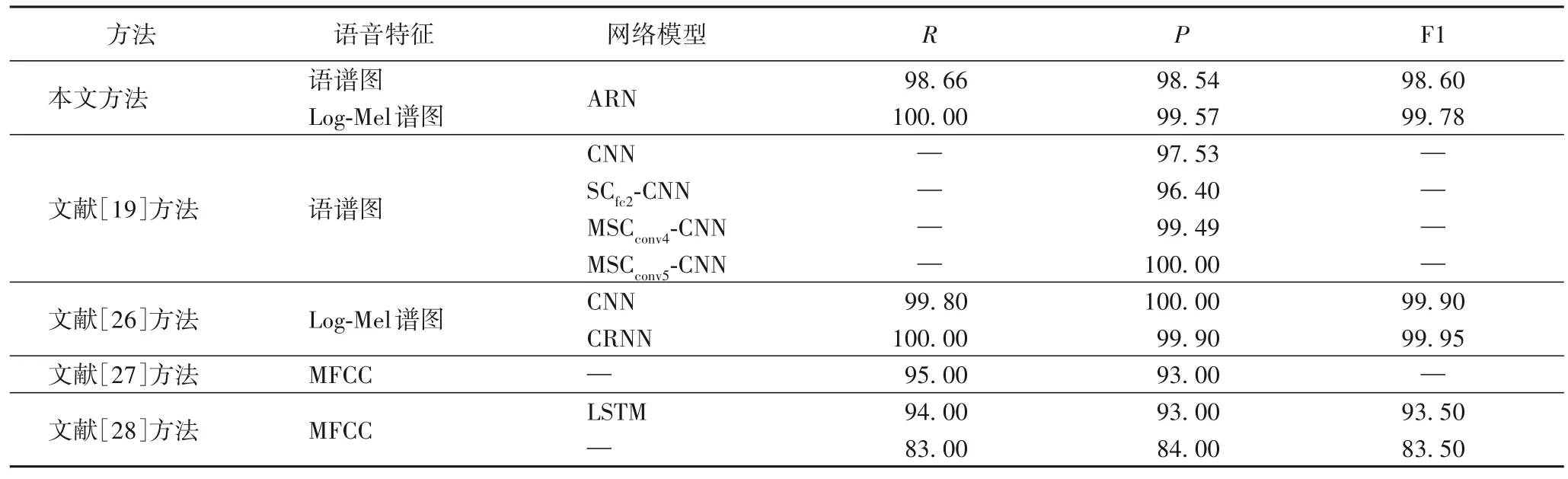
表4 不同方法的检索性能对比 单位:%Tab.4 Retrieval performance comparison of different methods unit:%
从表4 可知,相较于文献[19,27-28]中的方法,本文方法基本取得了最优结果,唯独查准率P略低于文献[19]中的MSCconv5-CNN(Multichannel Sparse Coding Convolutional Neural Network)模型,说明本文方法的检索性能较好。文献[26]中的方法的检索性能略高于本文方法,是因为文献[26]中的方法在检索过程中,采用了两级分类检索策略,先根据类别哈希码筛选出与查询语音同一类的候选集合,再在候选集合中检索匹配,且检索过程中采用了384 长度的哈希码。
为了评估ARN 模型的分类性能,对语谱图图像特征和Log-Mel 谱图图像特征的受试者工作特征(Receiver Operating Characteristic,ROC)曲线和曲线下面积的(Area Under Curve,AUC)进行了对比。ROC 曲线与x-y轴围成的区域面积被定义为AUC 值。y=x这条直线为判断模型分类性能好坏的一个阈值,它的值为0.5,若0.5 图6 不同特征的ROC曲线和AUC值Fig.6 ROC curves and AUC values for different features 从图6 可以看出,本文方法在两种不同特征的ROC 曲线中取得的AUC 值分别为0.85 和0.96。AUC 值的区间范围均在0.5 另外,为了测试本文方法生成的哈希码的鲁棒性,将CPO 后的语音数据生成的语谱图图像特征/Log-Mel 谱图图像特征作为ARN 模型的输入,并利用模型生成的哈希码进行评估分析,查全率和查准率如表5 所示。其中,文献[26]方法1 和文献[26]方法2 分别代表骨干网络为CNN 和CRNN 的方法。 表5 不同内容保持操作下的查全率和查准率对比结果 单位:%Tab.5 Comparison results of recall and precision under different content preserving operations unit:% 从表5 可看出,本文方法以四种CPO 后的语音数据所生成的语谱图图像特征和Log-Mel 谱图图像特征作为模型的输入时,本文方法所生成的哈希码仍然具有较高的查全率和查准率。相较于文献[26,29]方法,语音数据在MP3 压缩和重量化2(Requantization 2,R2)操作后,本文方法在两种特征下查全率和查准率均达到了100%。这是因为MP3 压缩的特点是使低频信号不失真,高频信号减弱;R2 操作的特点是使音频波形精度增高,而不影响音频的质量。相比之下,语音数据在重采样(Resampling,R)操作后,本文方法在采用语谱图图像特征下的查全率和查准率略低于文献[26,29]方法。R操作是将采样频率先降低到8 kHz,然后增加到16 kHz,虽提高了音频质量,但也无形中增加了音频体积,增大了计算量,致使语谱图图像特征损耗更大,部分信息丢失。相比其他语音内容保持操作,语音数据在重量化1(Requantization 1,R1)操作后,本文方法在两种特征下的查全率和查准率都低于文献[29]方法,这是因为语音信号在16-8 Kb/s 量化操作时,语音波形幅度精度降低,所以R1 操作影响了音频质量;而R1 操作下文献[29]方法的查全率和查准率更高,因为哈希码长度498 大于本文方法的哈希码长度64,所以在音频质量破坏的情况下,哈希码长度越长,所包含的语义信息更全面。 为了验证本文方法对语音检索的准确度,实验随机选取了1 000 条测试语音中的第756 条查询语音进行了匹配检索,分别利用语谱图图像特征和Log-Mel 谱图图像特征作为模型的输入所生成的深度哈希码与深度哈希索引表中的哈希码(数据库中每个语音数据所对应的哈希码)进行匹配检索,匹配检索结果如图7 所示。 图7 不同语音特征的匹配检索结果Fig.7 Matching retrieval results for different speech features 从图7 可知,只有查询语音的比特误码率(Bit Error Ratio,BER)小于设置的阈值0.20,其余999 条语音的BER 均大于0.20,匹配失败。因此,本文方法具有较好的检索效果。 检索效率是验证算法好坏的一种重要方法。实验随机选取THCHS-30 语音库中的10 000 条语音片段,并对它们经过MP3 压缩内容保持操作后作为查询语音进行评估。计算本文方法的平均检索时间,并与文献[26,29]方法进行对比分析,结果如表6 所示。 表6 本文方法与现有方法的检索效率对比结果Tab.6 Comparison results of retrieval efficiency of proposed method and existing methods 从表6 可知,使用Log-Mel 谱图作为特征的本文方法的平均运行时间相较于文献[26,29]方法缩短了19.0%~55.5%,说明本文方法检索效率良好。本文方法采用的三联体标签可以明显地提供数据之间相对相似的概念,同时利用注意力机制和三元交叉熵损失函数训练网络,生成更高效紧凑的哈希码,缩短了匹配长度,节省了检索时间。文献[26,29]中分别采用了384、498 长度的哈希码进行了匹配检索,相比本文方法采用的64 长度的哈希码,增加了匹配长度,影响了检索效率;文献[29]方法的检索平均运行时间低于文献[26]方法,是因为在生成哈希码的过程中,文献[29]中采用了降维速度更快的主成分分析算法。因此,本文方法非常适合语音检索任务。 本文利用注意力机制-残差网络(ARN)模型,提出了一种用于语音检索的三联体深度哈希方法。与现有的语音检索方法中采用的基于单标签的深度哈希方法相比,可利用三联体标签信息编码数据集内的相似关系生成高效紧凑的哈希码。另外,结合残差网络和注意力机制来提取语谱图图像特征的深度语义特征,并引入三联体交叉熵损失,不仅可以使模型充分提取语谱图图像特征的语义信息,而且还可将语谱图图像特征的所属类别信息嵌入到所学习的哈希码中,从而提高语音检索的检索精度和效率。实验结果表明,与现有语音检索方案相比,本文方法能够生成高效紧凑的哈希码,确保了语音检索系统具有良好的识别率、鲁棒性、查全率和查准率,对较长的语音具有良好的检索效率和准确性。 不足之处是本文方法不能构造更紧凑的深度哈希二值码来完成语音高效的检索。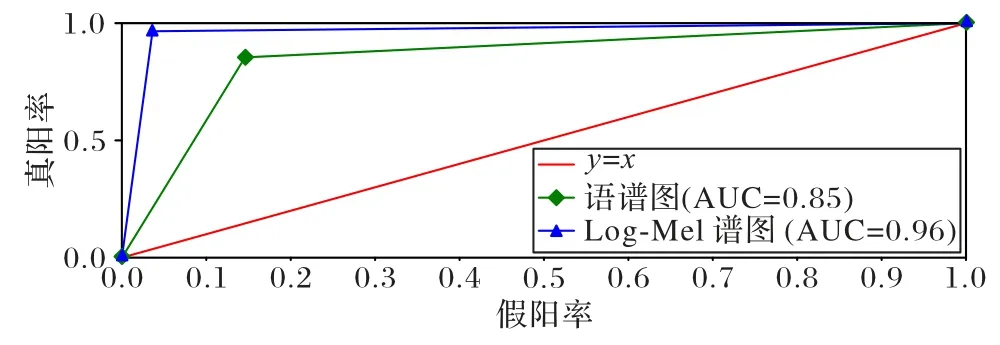


3.5 检索效率分析
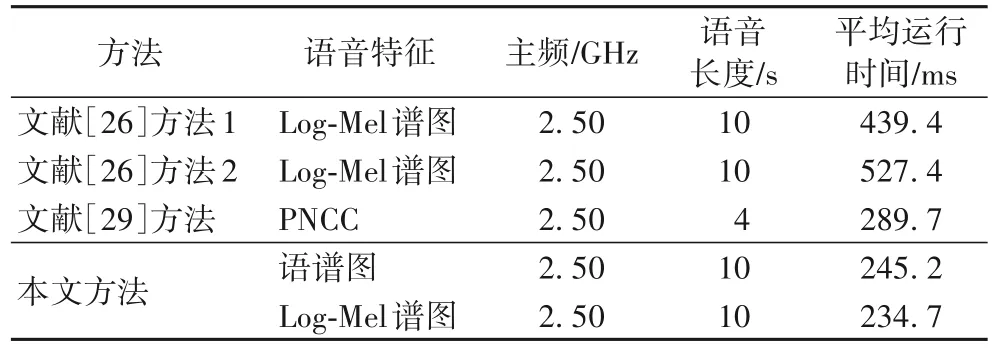
4 结语
