上市公司财务风险预警
——基于机器学习方法
2023-09-26张彩妮任爱珍林子达
张彩妮,任爱珍,林子达
(内蒙古农业大学,呼和浩特 010018)
1 引言
目前,我国整体经济受到国际经济形势影响,面临下行压力,众多公司融资困难,陷入财务困境。在此背景下,构建有效的财务危机预警模型以识别潜在财务风险,对于企业自身规避风险、投资者制定投资计划和经济社会健康发展具有重大意义。
当前,学者基于机器学习中的各种分类算法来构建预警模型:陈志君[1]以我国通信行业上市公司为研究对象,通过筛选财务指标,采用逻辑回归建立财务危机预警模型,该模型的正确率达到79%。李长山[2]的研究表明,由逻辑回归构建的预警模型能够有效识别我国制造业公司的财务风险。连晓丽[3]以A 股上市的正常公司和ST 公司为研究样本,发现基于随机森林的财务危机预警模型在不同的市场行情下均有较高的准确率。孟杰[4]通过对比随机森林与支持向量机、逻辑回归、分类决策树和神经网络在我国上市公司财务失败预警时的表现,得出随机森林模型预测精度更高、更稳健的结论。游甜[5]选取财务指标和非财务指标,对比分析优化后的支持向量机、BP_Adaboost 和kNN 在企业财务危机预测时的表现,发现支持向量机模型具有更高的判别正确率。周廷炜[6]利用优劣解距离法和网格寻优算法优化支持向量机预测模型,提高了该模型识别上市公司退市风险的能力。薛慧[7]构建了基于LightGBM 的财务风险预警模型,并与随机森林等常用模型进行对比分析,结果表明,参数优化后的LightGBM 模型对电力行业上市公司财务风险预测的效果更好。
在现有的研究中,加权K 近邻法被应用于机械故障诊断[8,9]、楼宇室内定位[10,11]和图像识别[12,13]等工业领域,取得了有效的成果。而目前加权K 近邻法并未涉及对企业财务危机进行预警分析,因此,文章基于大数据分析方法,利用加权K 近邻算法来构建上市公司财务预警模型,并与随机森林和支持向量机进行对比研究,分析不同模型的性能,帮助企业及时辨识财务风险,实现企业健康发展的良性循环。
2 指标选取与数据处理
有效的危机预测机制应发挥早期预警作用,提前对危机事件发出警示。相较于公司破产和企业违约等事件,公司被列入风险警示板的时点往往更早,更适用于刻画企业的财务危机。因此,文章以2022 年为基期,对陷入财务困境的公司定义为基期被列入风险警示板的公司,利用2019-2021 年的财务和非财务数据来预测基期公司是否陷入财务困境。在剔除披露信息不完全的公司后,文章获取540 个有效的危机样本,并对个别缺失的数据利用平均值进行补充。由于陷入财务困境的公司数量远远小于正常公司的数量,考虑到样本的平衡性,文章随机抽取了资产规模相似、数量相同的非ST 公司与ST 公司一一匹配。相关数据均来源于CSMAR 数据库。
根据国内外已有的关于上市公司财务危机预警的相关研究成果,结合定性分析和定量分析,文章筛选出使用频率较高且能够较好地解释企业财务风险的指标,从企业的偿债能力、盈利能力、营运能力、发展能力以及治理能力这5 方面选取了19 个财务指标和非财务指标作为模型的输入变量。表1 列示了财务指标和非财务指标的类型和定义。文章采用Z-Score 法对原始数据进行标准化处理,经过该种方法处理后的样本数据的取值范围为[0,1]。

表1 财务指标和非财务指标
3 模型设定
3.1 加权K 近邻
K 近邻是一种经典的监督学习算法。其基本思路为:在特征空间中,如果有K 个样本与待测类别的样本最相似(距离最近),且这K 个样本大多数属于某一个类别,那么待测样本也属于这个类别。在K近邻算法中,所选择的邻居都是已经正确分类的对象。该算法需确定的参数为K,即选择多少个与待测样本距离最近的样本进行预测。
采用K 近邻算法预测时,默认K 个近邻(K 个观测)对待测样本的影响力度是相同的。而事实上,距待测样本近的观测样本对预测结果的贡献应当大于距离较远的观测样本。为解决这个问题,Hechenbichler 和Schliep[14]提出了加权K 近邻法,其核心思想为:将相似性定义为各观测样本与需要预测的新观测样本距离的某种非线性函数,且距离越近,相似性越强,权重越高,预测时的贡献越大。
3.2 随机森林
随机森林算法依赖袋装算法,即从原始数据集中进行有放回抽样来产生新样本集。每个新产生的样本集都可生长出一棵决策树。假设总共有M 个输入变量,每棵树在生长时,会从全体输入变量中随机选取m 个(m<M)输入变量,根据不纯度最小的准则选取最优变量进行决策树节点的分割,使每棵树都充分生成。将所有决策树汇总到一起形成随机森林,随机森林的预测分类结果是由每棵树的预测分类结果进行少数服从多数的投票确定。
3.3 支持向量机
支持向量机是以统计学习理论为基础的一种监督学习方法。该方法在处理二分类问题时,是通过在高维特征空间找到一个超平面来将两类样本有效分开。根据样本是否线性可分,支持向量机的分类问题分为两种情况:对于线性可分的样本,可通过求解凸二次型规划问题来直接确定分类超平面,进而对不同类别的样本进行分类;对于非线性可分的样本,需要先将原低维空间中的样本映射到高维空间中,这一映射过程可通过选取适当的核函数来实现,然后在高维空间中寻找分类超平面,实现对观测样本的分类。
3.4 模型性能评估
为清晰有效地对比不同分类模型的泛化能力,文章基于混淆矩阵,选用ROC 曲线和AUC 值来评估模型的整体分类能力。ROC 曲线是二维平面空间中的一条曲线,AUC 则为曲线下方面积,是具体的数值。ROC 曲线的横轴为假正例率即FPR(“正例”指ST 样本),纵轴为真正例率即TPR,二者分别表示为:
式中,TP为分类模型正确预测了ST 样本的个数;FP 为将非ST 样本预测为ST 样本的个数;TN 为正确预测了非ST样本的个数;FN 为将ST 样本预测为非ST 样本的个数。在二分类问题中,ROC 曲线越偏离45°对角线,即AUC 值越接近1,表示模型的分类性能越好。
此外,文章选用在分类任务中常用的指标来评估模型性能,这些评价指标分别为准确率、F1得分、召回率和精确度,其计算公式如下:
4 实证结果与分析
文章针对上市公司的财务预警问题,从财务指标和非财务指标中充分挖掘相关特征,分别利用加权K 近邻算法、随机森林算法和支持向量机算法来构建预测模型,并利用R 软件进行实证分析。文章共选取135 家ST 公司,将2019-2021年的810 个观测值作为模型的训练样本,再将2022 年的270个观测值作为模型的测试集,用于验证不同模型的预测性能。
表2 为加权K 近邻模型在测试集上的混淆矩阵。从表2可以看出,加权K 近邻模型识别测试集中样本的整体正确率为87.04%,可分别将82.96%的ST 公司和91.11%的非ST 公司正确识别。因此,若提前3 年对被预测为ST 的企业预警,这些企业通过采取调整企业经营战略、优化企业债务结构和规划合理的现金流量等应对措施,那么其中将有82.96%的企业可以避免被证监会列入风险警示板。

表2 加权K 近邻模型混淆矩阵
表3 和表4 分别为随机森林和支持向量机模型在测试集上的混淆矩阵。从表3 可以看出,随机森林预警模型在测试集上的正确率为86.67%,识别ST 公司和非ST 公司的命中率分别为87.41%和85.93%。支持向量机预警模型在测试集上的正确率可由表4 得出,为86.30%。其识别ST 公司的命中率为89.63%,识别非ST 公司的命中率为82.96%。根据实验结果,若利用随机森林和支持向量机预测模型提前3 年对被预测为ST 的企业预警,及时采取正确应对措施的企业中将分别有87.41%和89.63%可避免被证监会列入风险警示板。

表3 随机森林模型混淆矩阵

表4 支持向量机模型混淆矩阵
图1~图3 展示了加权K 近邻模型、随机森林模型和支持向量机模型的ROC 曲线,从图中可以看到,3 种模型的ROC 曲线均较对角线有着明显的偏离,说明这3 个模型均有较好的性能;随机森林模型的ROC 曲线较对角线的偏离程度最大,AUC 值为0.942 2,这表明随机森林模型具有更好的整体分类效力,对ST 公司和非ST 公司的识别均较为准确。

图3 基于支持向量机模型的ROC 曲线
此外,表5 列示了评估预测模型性能的各项指标值。可以看到,3 种模型均具有较高的准确率,均在86%以上,其中加权K 近邻模型准确率最高。不同模型的精确度和召回率有较大差异,支持向量机模型的召回率最高,为89.63%,而精确度最低,为84.03%,这说明该模型更侧重于将测试集中所有的ST 公司识别出来,甚至牺牲了一些对非ST 公司判别的准确率。加权K 近邻模型的召回率最低,为82.96%,但其精确度高达90.32%,这表明该模型注重在每次识别时能够更准确地识别ST 公司,即在判定该公司是否会被ST 处理时趋于保守。就F1得分和AUC 值而言,随机森林模型的表现更为出色,这说明该模型兼顾了ST 和非ST公司识别的准确率。
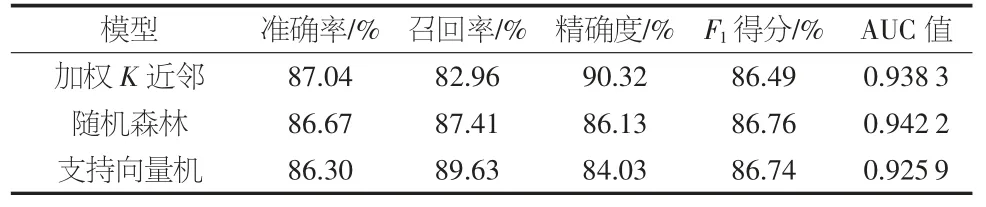
表5 各模型预测性能评价指标
5 结论
在复杂多变的宏观经济背景下,企业不可避免地面临着财务风险。财务预警模型通过对企业当前和历史的财务信息进行挖掘分析,能够有效预测企业未来经营状况,是财务危机管理的事前预防手段,在理论研究和实际应用中具有重要意义。文章选取2019-2022 年我国A 股上市公司的数据共计1 080 个样本作为实证研究对象,运用加权K 近邻、随机森林和支持向量机算法构建了预测模型,选取资产负债率、投入资本回报率、总资产周转率等财务指标和管理层持股比例、股权集中度等非财务指标作为模型输入变量,对上市公司进行财务预警研究。通过对实证结果的分析,发现3 种模型均能有效地识别企业财务风险,且各有所长。
文章在3 个方面仍待完善:首先,对于模型输入变量的选取以前人的研究结果与经验为基础,可能存在遗漏对企业财务危机有影响的变量的情况;其次,仅选择加权K 近邻、随机森林和支持向量机3 种方法来构建预警模型,在未来的研究中应选择更多、更前沿的算法来进行对比分析;最后,文章的数据均源自现有的数据库,可能存在企业财务信息未充分披露、数据失真等情况。
