基于高光谱的水稻稻曲病早期监测研究
2023-09-23谢亚平仝晓刚王晓慧
谢亚平 仝晓刚 王晓慧
(太原工业学院电子工程系,太原 030008)
0 引言
近年来,稻曲病的发生范围和危害有逐年上升趋势,已成为水稻主要病害。病害不仅直接导致水稻产量减少,而且使水稻的品质严重降低,甚至会引发食品安全事故[1-2]。防治病害的传统方法是喷洒农药,但是这种方法既费时又费力,且不可能实时大面积地监测水稻发病区域和严重程度。
高光谱成像作为一种融合图像处理和光谱学的信息获取技术,能同时获取目标的图像信息和光谱信息,从而更直观表达目标的特征[3]。目前,已经有很多学者将高光谱技术应用在农作物病害检测方面并做了大量研究[4-12],这些农作物主要包括水稻[13-14]、小麦[15]、黄瓜[16-18]等。曹益飞等[19]利用高光谱成像装置选取450~900 nm的水稻叶片作为样本,提出将光谱分形维数作为定量描述水稻白叶枯病害的监测光谱指数,实现对白叶枯病害的监测。梁栋等[20]利用高光谱成像技术区分冬小麦白粉病与条锈病,得到识别白粉病的敏感波长为 519、643、696、764、795、813 nm,条锈病的敏感波长为 494、630、637、698、755、805 nm。雷雨等[21]提出了一种基于高光谱成像技术的小麦条锈病病害程度分级方法,正确率达98.15%。秦立峰等[22]通过温室黄瓜早期霜霉病高光谱图像数据,选取特征波长,建立了黄瓜霜霉病早期检测模型,对染病2 d到发病12 d的黄瓜均能取得100%的检测识别率;对染病1 d的黄瓜检测识别率达到95.83%。刘莉等[23]利用近红外梨叶片的高光谱数据能够有效识别炭疽病与黑斑病。
高光谱成像技术是一种能够获得目标对象三维信息的成像方法,包括二维图像信息和一维光谱信息,图像信息能够反映目标物质大小、形状和缺陷等外部特征,光谱信息能够反映目标物质的内部物理、化学成分,从而实现物质的识别[24]。植物叶片的光学特征参数是在各种生物和非生物胁迫下监测植物生长状况的重要参数,不同植物的生理组分不同,这可以直接表征在光谱维上,体现出很明显的光谱差异性,植物受到病害侵袭后,会改变其内部的结构和生物化学特性,在外形上会表现出一定程度的叶片发黄、枯萎、凋零等现象,同时其光谱特征也会随着变化,而且这种变化间接反映了植物在病害胁迫下的生理特性,因此可以根据光谱的差异来监测植物的生长状况[25]。本文使用 450~998 nm 原始反射光谱,通过对光谱特征数据分析和主成分分析,选出特征波长,建立两种识别水稻稻曲病的模型,分别为支持向量机(SVM)识别模型和主成分分析(PCA)加人工神经网络(ANN)识别模型,并检验两种识别模型的准确性,为水稻稻曲病的早期监测提供理论依据与技术基础。
1 数据采集与处理
1.1 实验地点
本研究的实验地点为浙江省杭州市水稻田,该地区夏季闷热,冬季凉爽,降水充沛,为稻曲病感染创造了有利条件,水稻自然发病。
1.2 数据采集
Cubert UHD185 是一种全画幅、非扫描式、实时成像光谱仪,采用全画幅快照式高光谱成像技术,集高速相机的易用性和高光谱精度为一体,其搭载在无人机(起飞质量18 kg,静载荷不小于8 kg,单组续航达30 min)上时,可在1/1 000 s内得到波长450~1 000 nm范围内137个波段的高光谱影像。UHD185全画幅式高光谱仪如图1所示。

图1 UHD185全画幅式高光谱仪
由于各波长下光强度分布的不均匀性及高光谱相机的非线性和暗电流的存在,需要对原图像进行校正。校正公式为
(1)
式中Rn——校正后的图像反射率
Rs——原始图像反射率
Rd——关上光源,拧上镜头盖后采集的全暗参考图像反射率
Rw——扫描反射率为99%的标准白板全白参考图像反射率
黑白标定后进行数据采集,采集时镜头与被测目标平行,距离被测目标20~30 cm。在水稻的生长期,选择光线明亮、无云、无风的天气,利用机载UHD185全画幅式高光谱仪采集带有发病区域的多组水稻冠层高光谱图像数据,选取健康水稻和发病水稻中对比显著的冠层图像,共计198幅,该数据用于稻曲病识别。选用450~998 nm之间的548个光谱带,采样间隔为4 nm。采集的每幅图像由137个波段组成,最终得到尺寸为1 000像素×1 000像素的高光谱图像数据。采集的水稻稻曲病高光谱图像不但拥有二维的平面图像信息而且整个图像上每个像素都存在着连续光谱信息。
如图2所示,使用ENVI 5.1软件,在健康稻穗和患病稻穗区域分别选取一个50像素×30像素的长方形作为感兴趣区域(Region of interest,ROI),计算整个ROI的平均光谱,作为代表该感兴趣区域中心点像素的反射光谱。
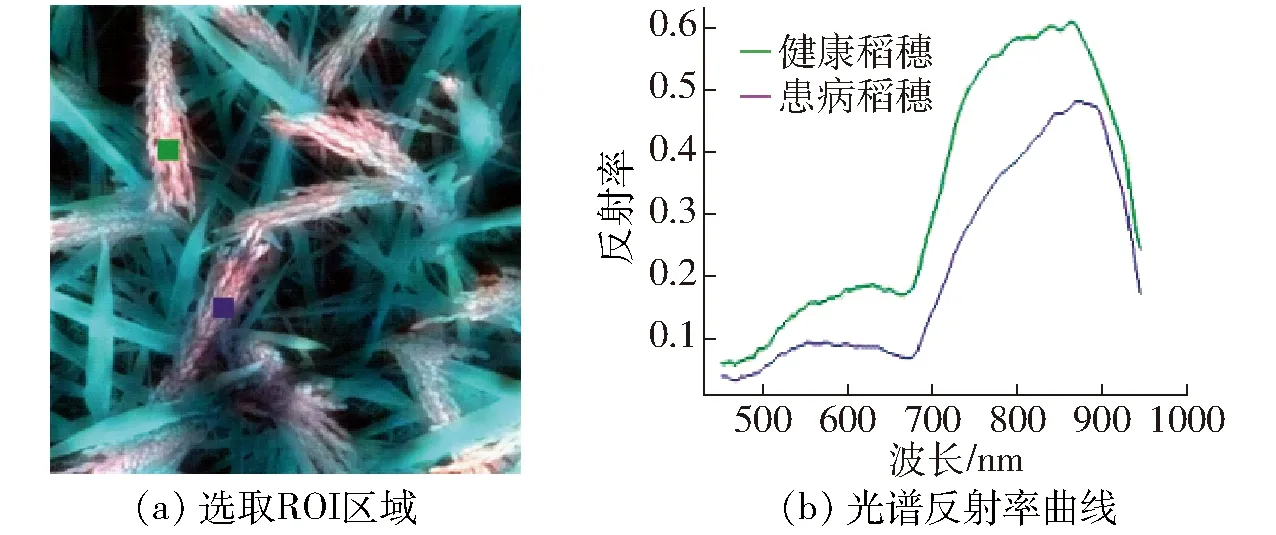
图2 健康和患病水稻光谱曲线
由图2可见,在450~720 nm可见光谱段范围内和780~900 nm的近红外光谱段内患病稻穗光谱反射率明显下降。在可见光波段450~780 nm,色素主导光谱特性,其中叶绿素起着关键作用,因此该波段的光谱反射率相比其他波段较低。其中,叶绿素在蓝波段(450 nm)和红波段(670 nm)具有较强的吸收能力,在这两处会形成吸收谷,在黄绿波段(550~600 nm)会出现一个反射峰,因此健康的稻穗会呈现黄绿色。受到稻曲病菌侵染后,细胞中色素被破坏,可见光波段反射率下降,同时对红蓝波段的吸收能力下降,因此稻穗呈现黄色、黑色等异常颜色[26]。近红外 780~1 000 nm 波段的光谱特性由植物体内细胞结构决定。稻曲病菌破坏了稻穗细胞结构,大量细胞坏死,细胞内部间隔增大,对光的多重散射减少,患病稻穗光谱反射率出现明显下降。
1.3 数据预处理
高光谱仪采集光谱图像时易受到外界条件影响,包括天气、仪器电流噪声、外界噪声和光照等,造成光谱谱线重叠等问题,因此需要进行噪声消除、敏感波段选择等预处理,去除冗余数据,提高模型准确度和稳定性。
平滑算法能够有效去除光谱内部随机误差,经常用于噪声消除。平滑算法需要估算最佳平衡点,基于平衡点将前后若干个点相关联,取平均值,从而达到消除噪声的目的,因此经过平滑算法处理的每个高光谱波段是原始数据和相邻多个波段的加权和[27]。平滑算法包括 Norris Derivative 平滑、移动窗口平均法和最小二乘拟合法[28]等,本文采用移动窗口平均法。该方法通过平滑窗口在光谱上移动,对平滑窗口内的光谱求平均。移动窗口平均法的算法步骤如下:①确定窗口大小,根据窗口大小对光谱首尾进行补零处理。②对处于移动窗口内的光谱进行平滑。③移动平滑窗口,不断重复步骤②直至结束。
2 分析模型
光谱曲线反映了水稻对光线的吸收和反射特征,因水稻的内部结构不同,水稻的吸收和反射特征不同,同一水稻在不同生长时期也呈现出一定规律的变化,提取能够体现水稻病害变化规律的敏感波段并建立对应的识别模型,具有良好的建模效果。使用 ENVI 5.1 影像处理软件分析预处理过的高光谱数据,通过选择 ROI 区域找出健康稻穗与发病稻穗光谱曲线之间的关系或者通过降维处理,得到发病稻穗的特征波段组合,建立不同的识别模型,并通过验证样本来检验识别模型的准确性。图3为稻曲病识别技术路线图。
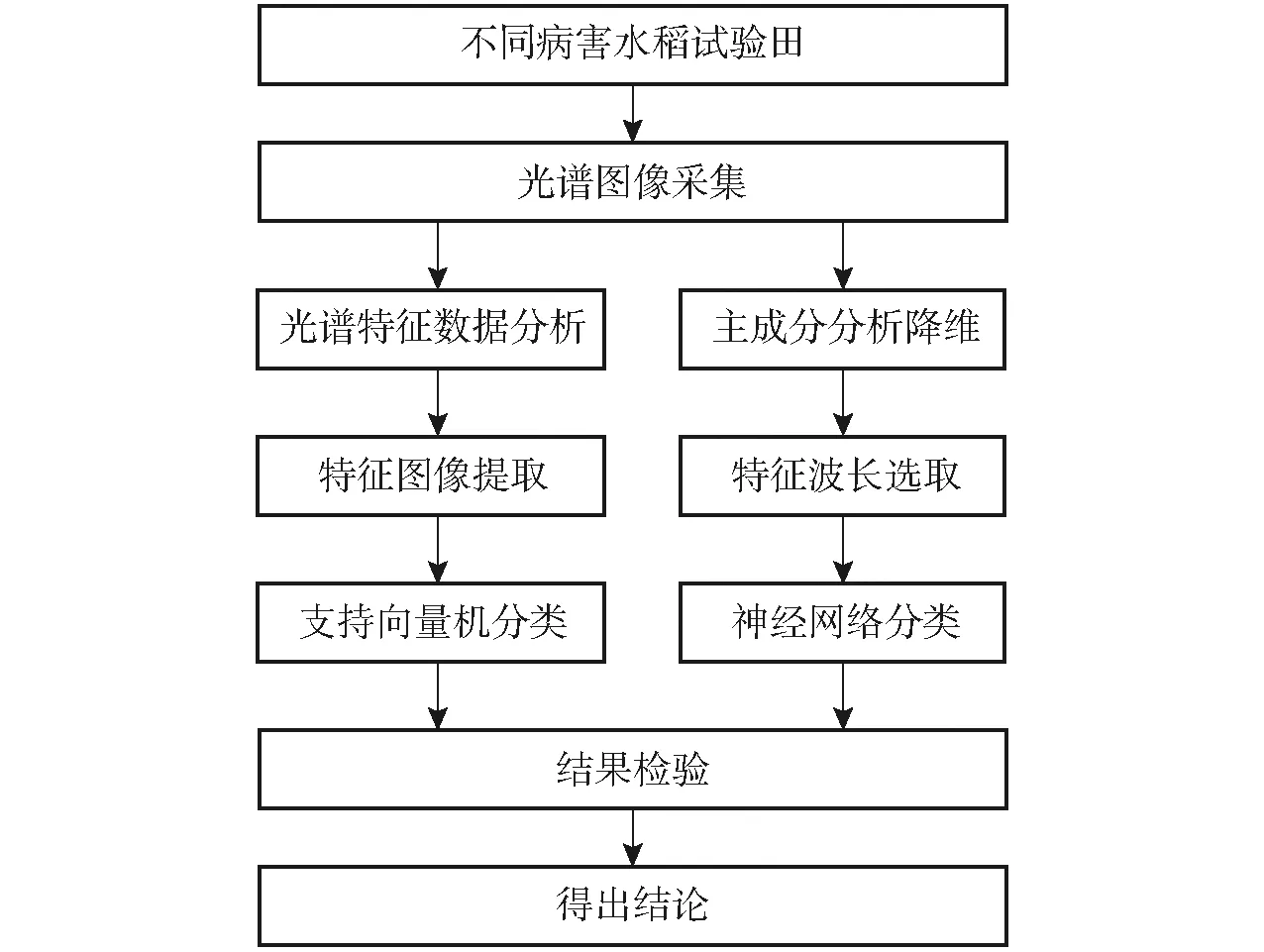
图3 稻曲病识别技术路线图
2.1 支持向量机(SVM)识别模型
支持向量机(SVM)是目前应用比较广泛的分类方法,其兼顾训练误差和泛化能力,在解决小样本、非线性、高维数、局部极小值等模式识别问题中表现出许多特有的优势。通过核函数将非线性问题转化为高维空间中的线性问题,从而完成分类识别。采用线性、多项式、径向基、S型4种核函数的 SVM 建模算法对发病稻穗进行识别;对影像分类后的结果进行精度验证,验证方法包括混淆矩阵、Kappa 统计等。
2.1.1样本及参数选择
选取ROI区域来获取训练和验证样本,获取与4种核函数分别对应的训练样本,4组训练样本相同且每组训练样本中样本的个数均为40;验证样本个数为45。在支持向量机分类中,Gamma、Penalty Parameter、Pyramid Levels等参数值一致。
2.1.2特征图像提取
通过ENVI 5.1软件反复尝试实验组1,由光谱反射率图像发现,在可见光谱段波长为654 nm处出现一个反射峰,该处波长下的水稻稻曲病图像是特征波长下的图像,近红外光谱段波长为838 nm和898 nm处的病斑部分与正常部分的光谱值差别较大,所以选取654、838、898 nm特征波长组合成 TZH1,TZH1 为红色波长为654 nm、绿色波长为838 nm、蓝色波长为898 nm的假彩色图像,如图4a所示。同样的方法应用于实验组2得出特征图像 TZH2,表示红色波长为630 nm、绿色波长为762 nm、蓝色波长为806 nm的假彩色图像,如图4b所示。

图4 两组特征波长下的图像
本实验采用2组数据进行分析。实验组1:选择Auto063.cue作为数据源,特征图像TZH1波段组合为654、838、898 nm;实验组2:选择Auto067.cue作为数据源,TZH2的波段组合为630、762、806 nm。假彩色图像是为了使稻曲病的特征更加明显,有助于进行解释和分析。
2.1.3支持向量机分类
分别对2组图像数据使用支持向量机分类,分类结果如图5所示。从2组实验数据的分类结果来看,除了实验组1有小部分空隙区域分为患病稻穗区域外,2组实验数据基本达到了准确识别患病稻穗区域的目的。支持向量机识别模型对水稻稻曲病诊断结果如表1所示。

表1 水稻稻曲病诊断结果
由表1可知,支持向量机分类方法诊断正确率比较高。其中,线性核函数、多项式核函数、径向基核函数、S型核函数的诊断性能依次升高。S型核函数总体分类精度最高达到 95.64%,Kappa系数最高达0.94,所以在这4种核函数中,S型核函数的 SVM 分类方法最适合受稻曲病胁迫的水稻病害识别。
2.2 主成分分析加人工神经网络识别模型
主成分分析(PCA)是高光谱图像处理的一项重要技术,它通过多个波段的线性变换,使原始数据映射到一个新的坐标系统,以使数据的差异性达到最大,其分析的目的在于寻找在最小均方差意义下最能代表原始数据的投影方法。主成分分析可以在保证数据信息损失最少的原则下,对高维变量空间数据进行降维处理。在不丢失主要光谱信息的前提下,选择数目较少的新变量替代原来较多的变量,解决了高光谱波段过多、谱带重叠的分析难题。
图6是PCA简易投影图,小方块代表原始二维数据,通过转换矩阵投影到以L为基准的低维空间,一方面保存了原始数据信息,另一方面降维到了一维。在实际问题中,往往会选择前k个主成分,使累计贡献率达到95%以上,这样获取的k个特征能较好地保存原始信息,同时减少噪声干扰,实现数据降维。
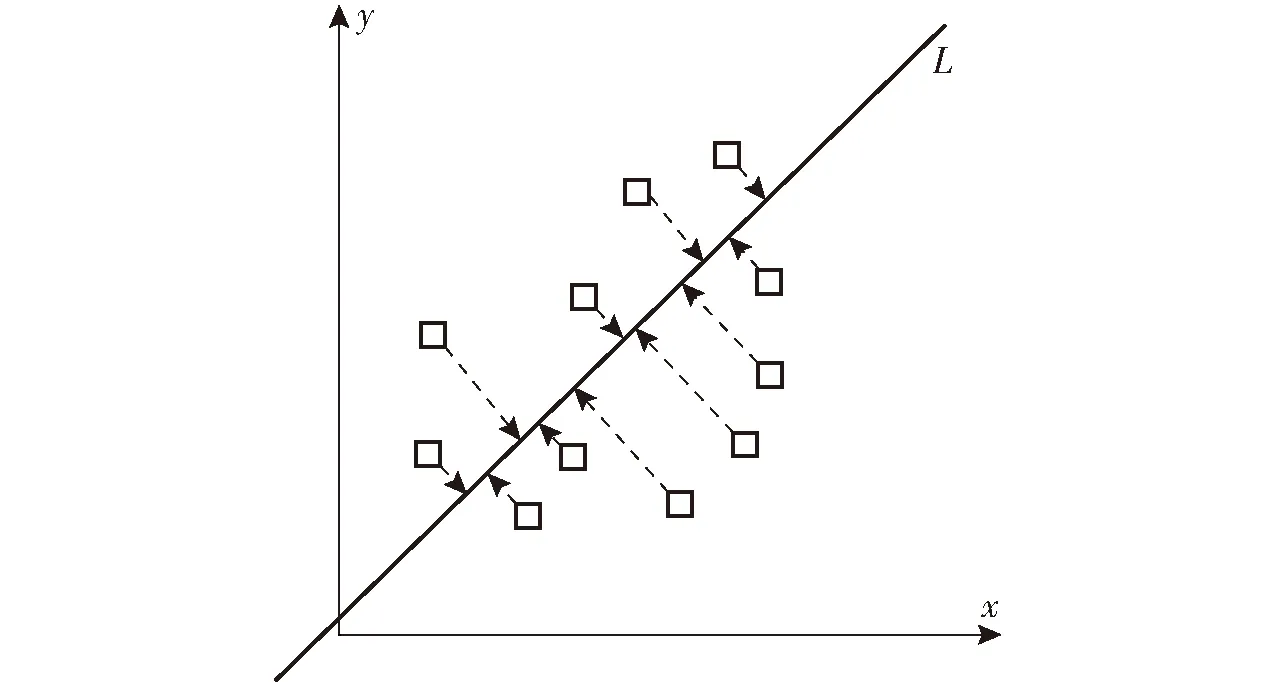
图6 PCA投影示意图
2.2.1样本选择
这里的感兴趣区域选取方式与支持向量机中样本的选取方式一致,选取ROI区域来获取训练样本和验证样本,获取一组训练样本,其对应的训练样本个数为40,验证样本个数为 45。
2.2.2特征波长选取
运用ENVI 5.1 软件对患病水稻高光谱数据主成分分析后,得到的累计贡献率见表2,其中“—”表示忽略不计。

表2 主成分分析中特征值贡献率统计
选择前6个主成分来代表原始高光谱图像,以对图像进行压缩处理,获得有全波段线性组合的6个主成分分析后的各个成分得分图,如图7所示。
从主成分得分图中可以看到第1主成分图像水稻轮廓清晰,信息量大,但是我们所关心的患病区域在大量信息中没有得到体现;在第2主成分图像和第3主成分图像中,在去除第1主成分中的特征波长后,虽然图像中特征波长特征值贡献率仅为 4.04%,图像中水稻轮廓没有第1个主成分效果好,但是健康稻穗区域和患病稻穗区域清晰可辨;而第4主成分、第5主成分和第6主成分的特征值贡献率不足1.5%,对分析作用不大。
2.2.3人工神经网络分类
选取前3个主成分所组成的假彩色图像代表患病水稻的特征波长下的图像,贡献率分别为93.67%、2.80%、1.24%。使用主成分分析得到特征波长组合后,通过选取感兴趣区域(ROI)来获得训练样本和验证样本,然后建立人工神经网络识别模型,得到线性分类和非线性分类的整体分类结果如图8所示。
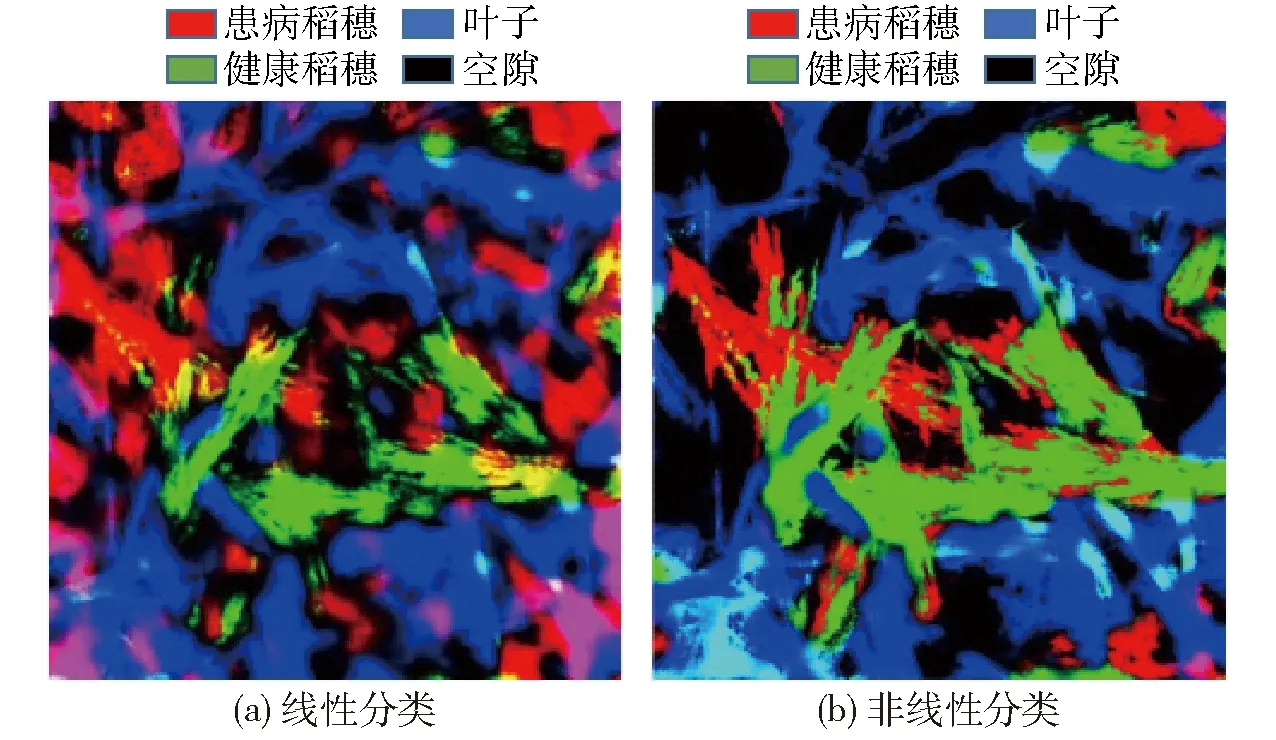
图8 人工神经网络分类结果
由图8可知,人工神经网络模型的非线性分类轮廓清晰,识别效果较好。
3 结果与讨论
3.1 支持向量机识别模型结果与检验
3.1.1分类结果
表3、4是2组数据分类后不同样本的诊断结果。
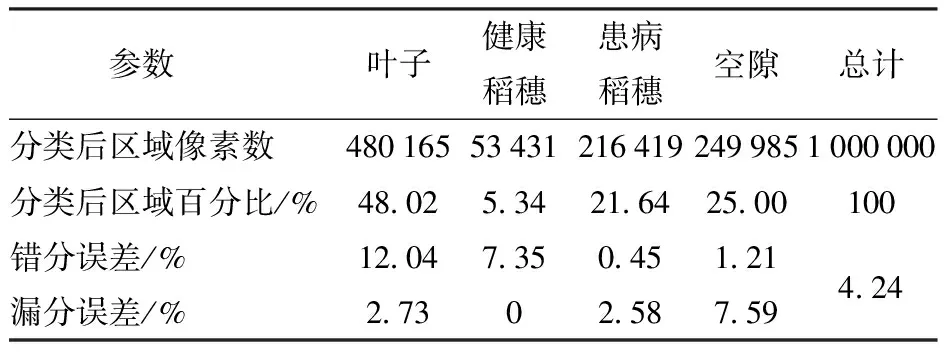
表3 第1组数据样本分类结果
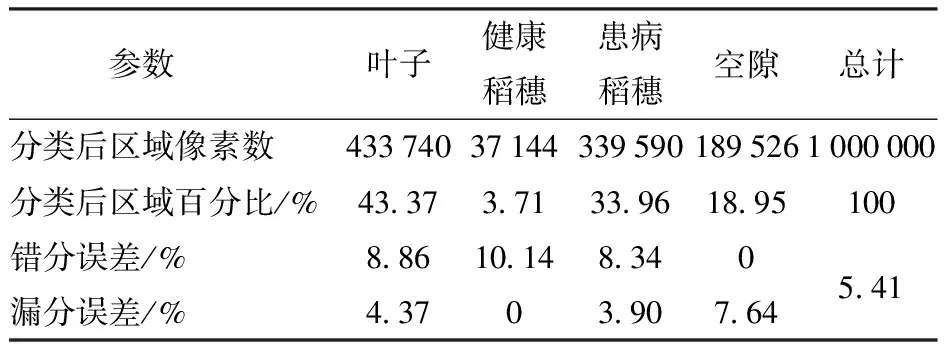
表4 第2组数据样本分类结果
从整体分类结果来看,2组数据的错分误差、漏分误差总体分别达到 4.24%和 5.41%。第1组的分类结果较好,且叶子和健康稻穗错分误差较高,患病稻穗和空隙错分误差较低,叶子、健康稻穗、患病稻穗的漏分误差较低,空隙的漏分误差较高;第2组分类结果中,除了空隙的错分误差为0和健康稻穗的漏分误差为0外,其余误差都比较大。造成2组数据不同的原因是不同的波段组合形成的假彩色图像信息识别度不同,即使2组数据选取训练样本和验证样本的方式一致,但仍然有差异,导致分类结果不同。从总体分类结果来看,2组数据均基本实现了识别水稻稻曲病的目的。
3.1.2模型检验
为了确定分类的精度及可靠性,需对分类结果进行检验,主要的检验方法为混淆矩阵。使用之前选择好的验证样本评价分类后的结果,将分类后的结果作为混淆矩阵的输入进行验证分析,从而实现分类结果准确性评估。文中使用第1组实验数据的S型核函数的支持向量机结果进行模型检验,混淆矩阵的总体分类精度(OA)如表5所示。混淆矩阵的错分误差、漏分误差、制图精度和用户精度如表6所示。从表5中可知,健康稻穗、叶子、患病稻穗、空隙分类结果所占百分比依次增加,其中,患病稻穗所占百分比达31.24%,说明水稻患病程度严重。总体分类精度为95.64%。Kappa系数为0.94。从表6 中可知,本实验中,总共划分为患病稻穗的ROI有2 879个像素,其中正确分类2 866个像素,其余13个像素是将叶子错分为患病稻穗,其错分误差为0.45%。同时患病稻穗有真实参考像素2 942个,其中正确分类2 866个像素,其余76个被错分为其余类,其漏分误差为2.58%。分析可知患病稻穗的漏分误差较大,这是由于部分患病稻穗与叶子的信息相似,导致错分的概率增大。
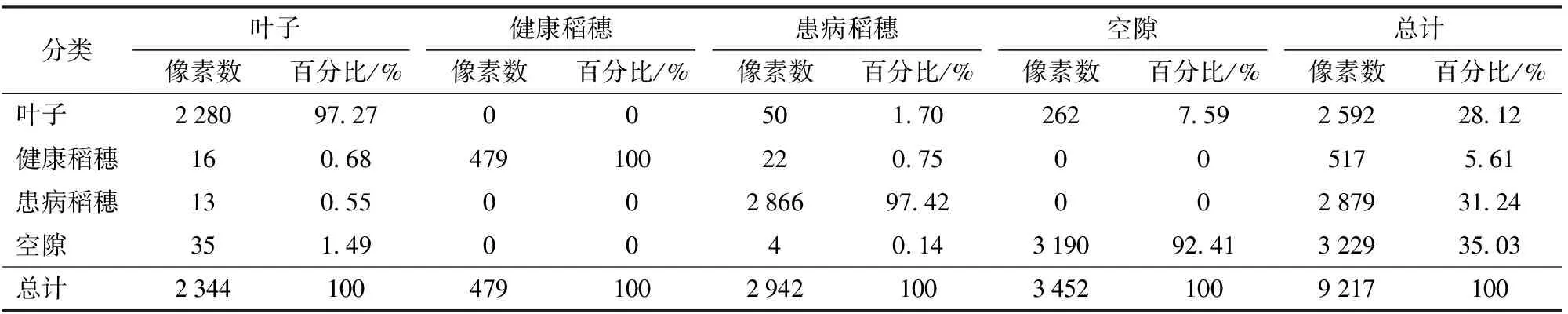
表5 混淆矩阵第1组指标

表6 混淆矩阵第2组指标
3.2 主成分分析加人工神经网络识别模型结果与检验
3.2.1分类结果
表7、8是两种分类方式分类后不同样本的诊断结果。
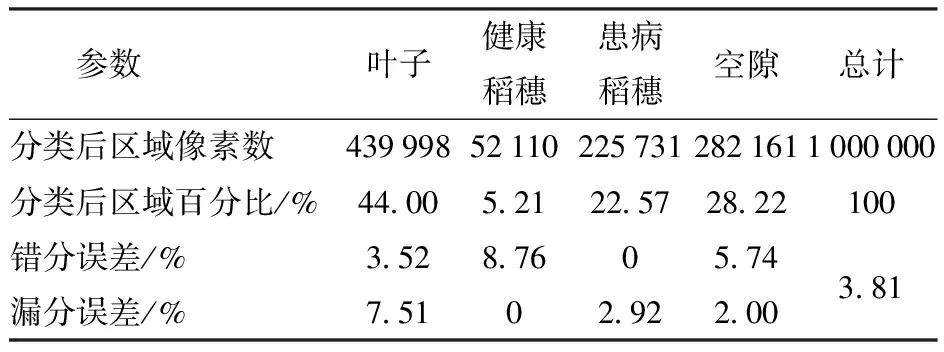
表8 非线性分类后不同样本的诊断结果
从整体分类结果来看,线性分类和非线性分类的错分误差、漏分误差总体分别达到9.57%、3.81%,非线性分类达到较好的效果。线性分类结果中,叶子、患病稻穗、空隙、健康稻穗的错分误差依次升高,其中健康稻穗的错分误差高达30.13%,叶子和患病稻穗的漏分误差较高,健康稻穗和空隙的漏分误差较低;非线性分类结果中,健康稻穗、空隙、叶子、患病稻穗的错分误差依次降低,其中患病稻穗的错分误差最低且为0,叶子、患病稻穗、空隙、健康稻穗的漏分误差依次降低,其中健康稻穗的漏分误差最低且为0。从2种分类结果来看,非线性分类可用于水稻稻曲病的早期监测。
3.2.2模型检验
为了确定分类的精度及可靠性,需对分类结果进行检验,检验方法为混淆矩阵。表9是线性分类和非线性分类验证结果统计。

表9 线性分类和非线性分类的验证结果统计
由表9可知,通过训练样本的人工神经网络模型分类结果与验证样本的检测结果一致,非线性分类明显比线性分类的精度高,总体分类精度达到 96.41%,Kappa 系数为0.95。这是在验证样本较多的情况下得出的结果,而实际验证样本可能没这么多,得到的识别精度会更高。所以非线性人工神经网络识别模型适合基于受稻曲病胁迫的水稻病害识别。
4 结论
(1)本研究建立了支持向量机识别模型和主成分分析加人工神经网络识别模型。通过选取感兴趣区域来进行训练样本及验证样本的选择,在支持向量机识别模型中,获取与4种核函数分别对应的训练样本,4组训练样本相同且每组训练样本中样本的个数均为40,验证样本个数为 45。找出健康稻穗与发病稻穗光谱曲线之间的关系,得到发病稻穗的特征波段组合。在主成分加人工神经网络识别模型中,通过对138个波段进行数据降维处理,得到前3个主成分代表的特征波段组合。这2种识别模型训练样本和验证样本的选取方式和个数均一致。
(2)结果表明,支持向量机识别模型中,S型核函数诊断性能最好且稳定,总体分类精度最高达到95.64%,Kappa系数为0.94;线性核函数的SVM诊断效果较差。通过2个实验组数据的支持向量机诊断结果对比可知,使用支持向量机识别模型分类精度整体平稳,4种核函数的诊断效果没有比较明显的差异。主成分加人工神经网络识别模型中,非线性分类比线性分类的结果准确性好,总体分类精度达到了96.41%,Kappa 系数为0.95。就总体分类精度而言,主成分分析加人工神经网络识别模型中的非线性分类比支持向量机识别模型中S型核函数分类高0.77个百分点。因此主成分分析加人工神经网络模型的非线性分类可以作为水稻稻曲病的早期监测手段。
