基于机器学习的小麦收获机掉头轨迹识别
2023-09-23杨丽丽王新鑫李元博常孟帅翟卫欣吴才聪
杨丽丽 王新鑫 李元博 常孟帅 翟卫欣 吴才聪
(1.中国农业大学信息与电气工程学院,北京 100083;2.农业农村部农机作业监测与大数据应用重点实验室,北京 100083)
0 引言
GNSS全球导航卫星系统是获取车辆轨迹数据、实现农业机械智能化管理的重要定位设备[1-3]。在农业机械上搭载定位设备可获得农机实时定位轨迹点,精确获取并识别农机运动轨迹,对农业机械自动化管理具有重要意义。农机轨迹数据反映农机的行为特征和田路分布等深层次信息,是农机作业调度管理[4]、农机作业行为分析[5]、农机手驾驶评价[6]、农田与机耕道轨迹识别[7]等研究的重要数据来源。
掉头识别是提升农机工作效率、合理规划路径的重要手段之一。设计合适的农机行驶路线和掉头方式与农机的工作效率息息相关,农机作业路径规划的主要目标是高效地实现农田全覆盖作业[8],掉头识别是路径优化的关键点之一[3]。相关研究表明,掉头时间可占农机在田内作业总时间的40%左右[9],且U形掉头效率较高[10],通过农机定位轨迹信息识别出农机掉头方式,进而计算出不同掉头方式下的农机作业效率,便于机手合理规划路径,提升农机作业效率。另外,掉头方式与田块形状关系密切[8,11],某地区的农田中不同掉头占比可作为判断该区域农田形状是否合理的依据之一,为农田区域的合理规划提供参考。农田面积的计算也是基于农机运动轨迹的相关研究之一,距离算法是计算农田面积的常用算法[12-13],对农机掉头轨迹识别后可以去除农机掉头行为导致的交错轨迹,防止面积计算过程中出现同一块区域面积的重复累加,从而提升距离算法计算农田面积的精度[14-16]。
小麦是全球粮食主产物之一[17-18],在我国是仅次于水稻、玉米的主要粮食作物,研究小麦收获轨迹对精准农业的发展至关重要。小麦收获轨迹包含典型的X形掉头与U形掉头轨迹。本文对小麦收获机田内的X形掉头、作业异常、U形掉头与作业轨迹进行识别。对收获机田内轨迹进行细致的划分,以期为农机作业效率计算、农田面积计算和农机路径规划等研究提供参考。
1 数据与方法
1.1 数据预处理
数据来自北斗农机作业大数据系统[12],获取的数据为2022年6月小麦收获季在河北、河南、山东等小麦主产区通过装载全球导航卫星系统(Global navigation satellite system,GNSS)的收获机,采集的产品为幅宽为2.75 m、车身长度为6.8 m的4LZ-8E2型和4LZ-7E5型自走式谷物联合收获机小麦收获轨迹,并通过人工标注获取田内农机轨迹。每条GNSS记录包含4个参数:时间(记为t,格式为YYYY-MM-DD hh:mm:ss)、经度(World geodetic system,WGS84世界大地坐标系)、纬度(WGS84)和速度(记为v,单位:m/s)。选取时间间隔5 s占比均在85%以上的5块已人工标注的农田,田内轨迹共1 969条,作为数据集A,用于训练后续试验中的SVM模型。选取时间间隔1~5 s占比均在85%以上的数据,每种时间间隔选取10块农田内的农机轨迹数据共50块,106 058条数据作为数据集B,用来测试算法效果。数据集见表1。
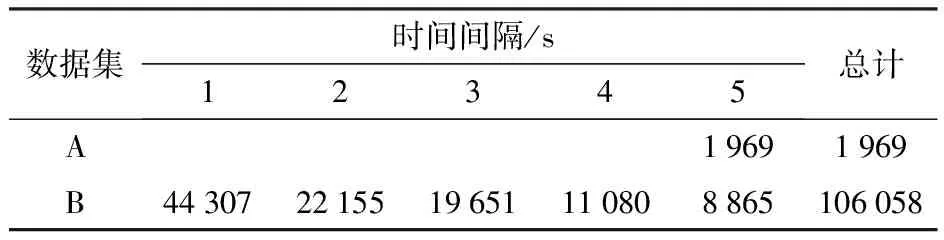
表1 数据集
数据预处理包含数据格式转换、去除停歇点和去除重复点。格式转换:将原始WGS84坐标系下的经纬度转换为平面坐标系下的x、y,转换后轨迹点pi属性为(ti,xi,yi,vi),时间ti格式为YYYYMMDDhhmmss。去除停歇点:将速度小于0.5 m/s的连续轨迹点视为一组停歇点[5],一组停歇点只保留一个轨迹点,其t为这组停歇点中第1个轨迹点的t,x、y为这组停歇点x、y的均值,v设为0。去除重复点:当存在连续轨迹点的x、y相同时,保留第1个轨迹点,将其他轨迹点删除。
1.2 数据定义
小麦收获机作业中的典型路线如图1所示,收获作业从农田外沿开始,绕圈向内进行收获,其形状如“回”字,定义为回形轨迹。
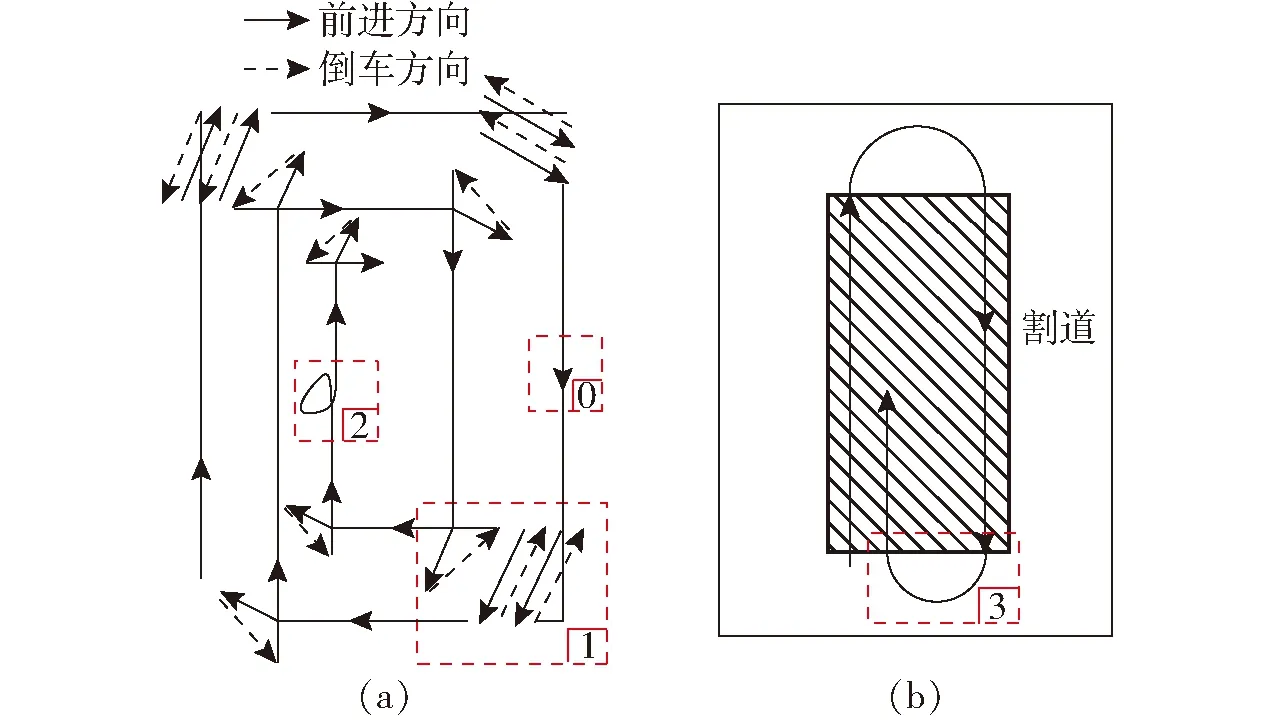
图1 回形收割路径示意图
图1a为收获机开始收获路线。收获机开入农田后沿麦田外围走直线收获至拐角处,为完成转向同时收获边角小麦需进行多次前进与倒车行为[19],当农田四周割出5 m左右的割道后进入内圈收获[20],内圈收获路线如图1b所示,空白部分为已收获完的割道,阴影部分为尚未收获的作物区域,此时收获机将以U形掉头方式进行转向,以提高掉头效率[10]。
为区分不同轨迹类型,轨迹点中增加label属性。如图1所示,回形小麦收获轨迹中常采用X形与U形掉头方式[19]。X形掉头是指农机在田内作业过程中为转变行进方向而做出的“前进-倒车-前进”的多次进退行为,该类轨迹点对应label属性记为1,如图1a的虚线框1处;作业异常轨迹是指农机行驶时脱离原轨迹方向,发生绕行或其他行为,之后又回到原轨迹方向,该类轨迹点对应label属性记为2,如图1a的虚线框2处;U形掉头是指无需倒车直接转向的行为,该类轨迹点对应label属性记为3,如图1b的虚线框3处;除掉头轨迹与作业异常轨迹外,其他轨迹为作业轨迹,该类轨迹点对应label属性记为0,如图1a虚线框0处。本文针对上述4种轨迹对其进行识别。
为描述农机行驶方向变化,记时间序列上相邻的3个轨迹点为Pi-1、Pi与Pi+1,记Pi-1到Pi的向量为lPi-1Pi。定义轨迹点Pi的角度属性αi的计算式为
αi=arccos(lPi-1PilPiPi+1/|lPi-1Pi||lPiPi+1|)
(1)
通过聚类得到的α较大点称之为拐点,按时间序列计算每个轨迹点到其最近的拐点的欧氏距离,记为轨迹点Pi的D_Ti属性。
将每个轨迹点与其时间序列上的前一个轨迹点的欧氏距离记为轨迹点Pi的D_Pi属性。
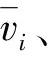
Δti=ti+1-ti-1
(2)
(3)
(4)
(5)
(6)
αmaxi=max(αi-1,αi,αi+1)
(7)
Rαi=max(αi-1,αi,αi+1)-min(αi-1,αi,αi+1)
(8)
(9)
1.3 技术路线
本文技术路线如图2所示,先对农机GNSS数据进行预处理,再分别用X形掉头识别算法与U形掉头识别算法识别出4种轨迹。最后用数据集B中的50块农田轨迹数据进行算法验证,并用距离算法比较原始轨迹数据与去除掉头和异常轨迹后数据的面积计算其精度。
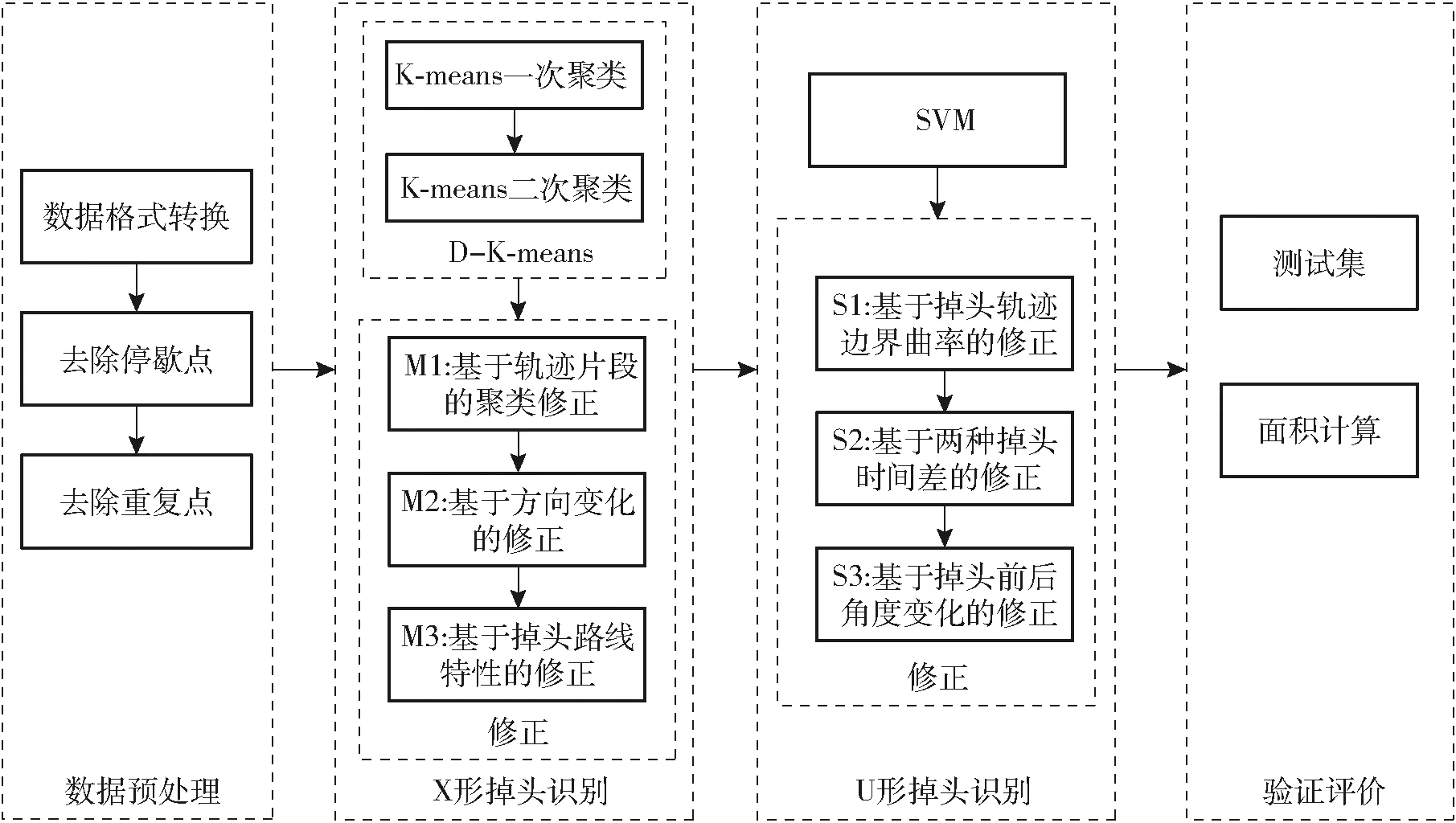
图2 技术路线
2 掉头轨迹识别
2.1 X形掉头轨迹识别
X形掉头轨迹识别算法包含2个模块:聚类模块与修正模块。
聚类模块执行2次K-means聚类,第1次聚类的输入特征为每个轨迹点的角度属性α,设定类别数k为2,初步将轨迹分为拐点与其他轨迹点。基于第1步聚类结果,输入每个轨迹点到最近拐点的距离特征D_T进行第2步聚类,聚类后初步得到作业轨迹与X形掉头轨迹。
基于轨迹片段的聚类修正M1:定义属于同一轨迹类别且在时间序列上相邻的轨迹点为一个轨迹片段,计算每个片段中轨迹点α属性的标准差、平均值与最大值作为轨迹片段的特征,对相同轨迹类别的轨迹片段的特征取平均值作为该类别的簇类中心。以轨迹片段为基本单位,计算每个轨迹片段到2个簇类中心的欧氏距离、契比雪夫距离与曼哈顿距离,以投票决策的方式判定该轨迹片段属于哪一类,并将轨迹片段内所有轨迹点的label属性赋予该类别标签。通过此过程,被误识别的轨迹片段得到修正。
基于方向变化的修正M2:如图1所示,X形掉头前后农机的行进方向不同,而作业异常轨迹往往是作业中途因避障而出现的绕行行为,故异常轨迹出现前后行进方向相同,根据GNSS的定位误差和小麦收获机行驶速度,定掉头前后行驶方向变化小于10°为方向未发生变化[21-22]。根据上述特点,对误识别为X形掉头轨迹的作业异常轨迹进行修正。
基于掉头路线特性的修正M3:X形掉头轨迹与作业轨迹相邻,为有效识别X形掉头轨迹,需对X形掉头轨迹起止位置进行界定:收获机在进行X形掉头时,为转变行进方向同时不遗漏作业,机身越过已收地至少半个机身位后转向[20],本文收获机车身长度为6.8 m,因此将每个X形掉头轨迹片段的起始拐点和终止拐点前后各3.4 m的轨迹点归为X形掉头轨迹点,依此完成对X形掉头轨迹边界的界定。
2.2 U形掉头轨迹识别
2.2.1SVM初步识别
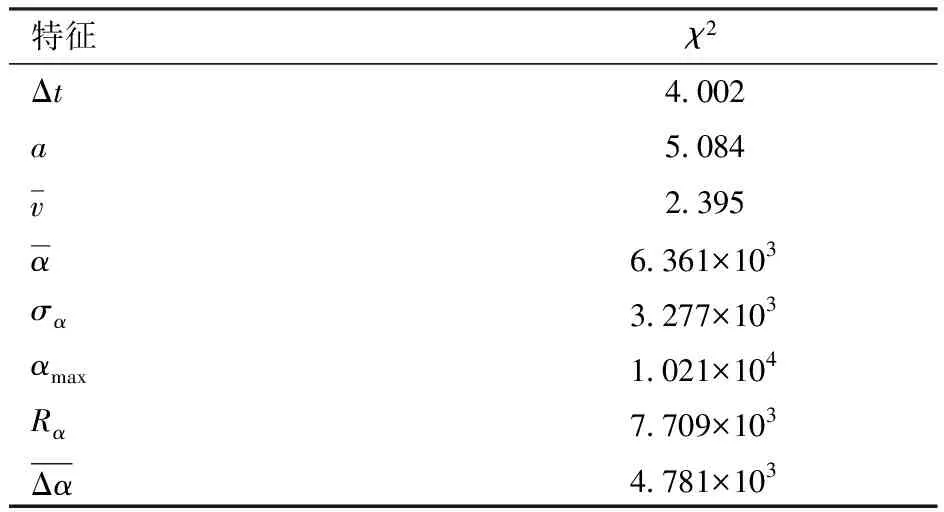
表2 卡方检验结果
构建基于SVM的U形掉头轨迹识别模型,以493条数据的5个与U形掉头强相关的特征属性和label属性作为模型输入,将其中80%的数据作为训练集。使用通过人工调优和网格搜索法,确定核函数为高斯核函数,确定惩罚参数C为0.21,该模型在测试集上的分类准确率为97%,召回率为97%,F1值为97%,可实现作业轨迹和U形掉头轨迹的初步识别,识别结果如图3所示。
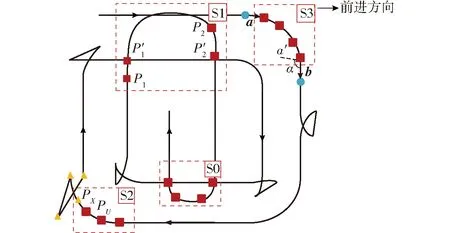
图3 SVM初步识别结果示意图
图3中红色方形为U形掉头轨迹点,黄色三角形为X形掉头轨迹点,蓝色圆形为作业轨迹点。虚框S0处为正确识别的U形掉头轨迹,虚框S1、S2与S3为3种误识别情况。
2.2.2基于掉头轨迹曲率的边界修正S1
在SVM初步识别的U形掉头轨迹中,存在U形掉头轨迹边界过长或过短问题,如图3的虚框S1。
虚框S1中的P1、P2为U形掉头初步识别结果的两个轨迹边界点。U形掉头轨迹是一个从直线变曲再变直的过程,为每个轨迹点构造曲率特征可以更精确地描述这种变化。
(1)特征构建:定义连续3个轨迹点Pi-1、Pi与Pi+1的外接圆曲率为轨迹点Pi的曲率。Pi点坐标为(xi,yi),根据3个轨迹点坐标值计算外接圆面积S,计算式为
(10)
3个轨迹点构成的三角形边长为a、b、c,与三角形面积S计算外接圆半径R
(11)
Pi曲率计算式为
(12)
(2)设定U形掉头边界点的曲率阈值K:取数据集A中标注的U形掉头轨迹的开始点与结束点的曲率,取最小值作为阈值K。由数据集A计算得K值为0.019 0 m-1。
(3)修正:识别出U形掉头轨迹边界点的曲率值大于(或小于)K时,延长(或缩短)U形掉头轨迹至其边界点曲率值刚好小于K。修正后图3虚框S1中边界点由P1、P2变为P′1、P′2。
2.2.3基于掉头时间差修正S2
(1)计算最小时间差:对每段U形掉头轨迹片段寻找与其在时间序列上最近的一段X形掉头轨迹片段,计算两段轨迹片段边界点PU与PX的最小时间差ΔtUX,计算式为
ΔtUX=min(|tU-tX|)
(13)
式中tU——U形掉头轨迹边界点PU的时间属性
tX——X形掉头轨迹边界点PX的时间属性
(2)设定时间阈值T:取数据集A中标注的U形掉头轨迹ΔtUX的最小值,作为时间阈值T。由数据集A计算得T为30 s。
(3)修正:当ΔtUX大于等于阈值T时,保留此段U形轨迹,否则将此段轨迹点类别值label由3恢复至X形掉头识别后的类别值。修正后图3的虚框S2中U形掉头轨迹点修正为作业轨迹点。
2.2.4基于掉头前后角度变化修正S3
农机在麦田边角的收获中也会出现作业轨迹被误识别为U形掉头轨迹的情况,如图3中虚框S3处。因此,通过掉头轨迹前后角度的变化来判断是否为误识别并修正,步骤为:
(1)计算U形掉头前后向量:U形掉头轨迹的开始点与前一个轨迹点构成向量a,U形掉头轨迹的结束点与后一个轨迹点构成的向量b,计算两个向量的夹角(计算方式同式(1)),如图3所示。
(2)设定角度阈值D:理想状态下U形掉头轨迹前后方向发生180°转变[23],即α为180°。但因实际农田形状不规则,人工操控农业机械以及GNSS定位精度等因素,U形掉头轨迹前后方向变化角度不定。取数据集A中的U形掉头轨迹前后向量夹角α的最小值作为角度阈值D。由数据集A计算得D为92.213 3°。
(3)修正:对通过S1与S2修正后的SVM结果中,计算所有U形掉头轨迹前后的向量夹角α。当α小于阈值D时,此U形掉头轨迹为误识别,将其label值由3恢复至X形掉头识别算法的结果,当α不小于阈值D时,保留此段U形掉头轨迹。如图3的虚框S3中U形掉头轨迹点修正为作业轨迹点。
3 结果与分析
3.1 轨迹识别结果
选取一块1.72 hm2的农田,对其进行掉头识别与修正,结果如图4所示。图4a中5个虚线框部分为误识别轨迹,对应修正过程见图4b~4f。
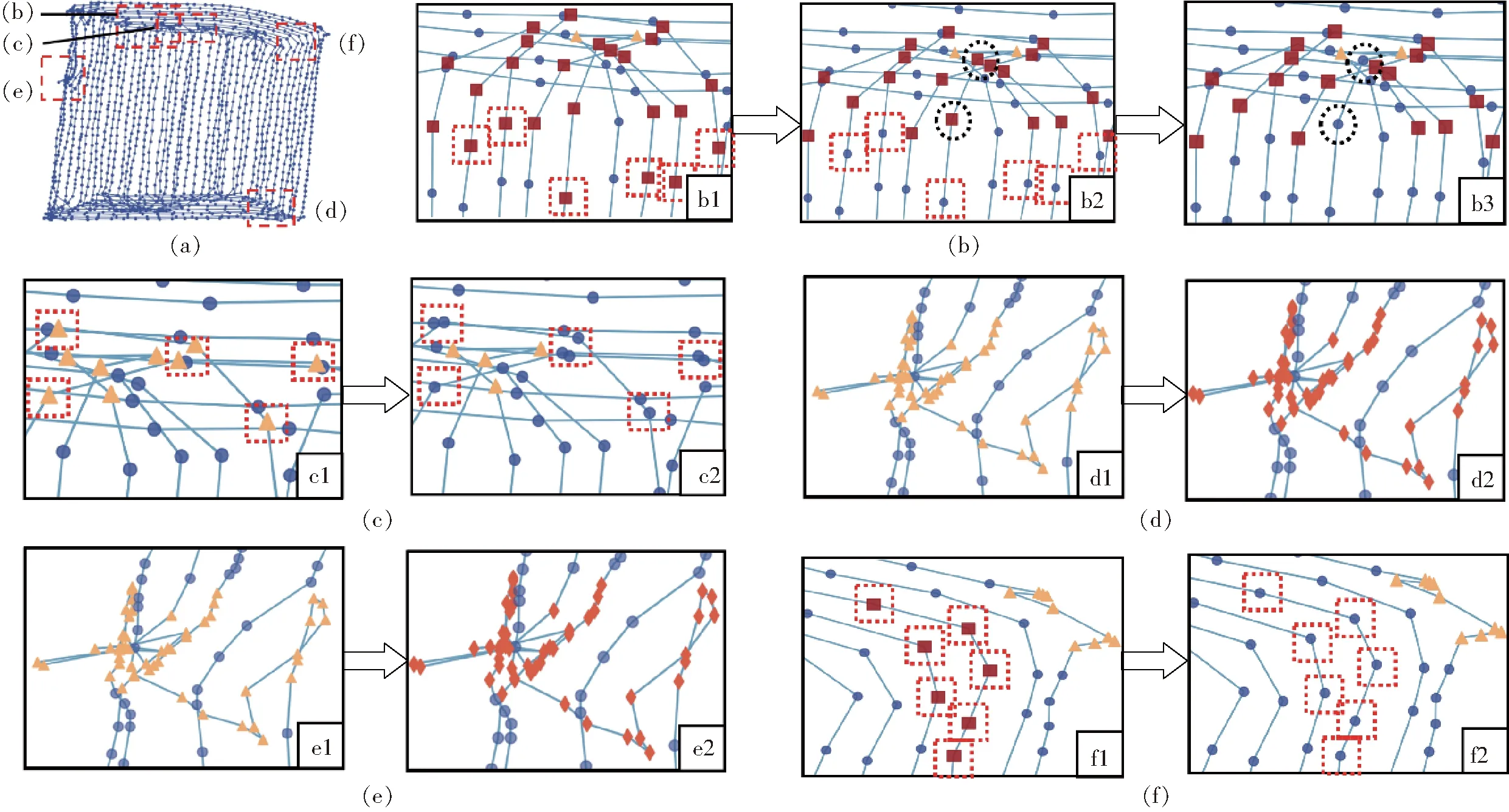
图4 掉头轨迹识别算法分步结果
图4中红色方形为U形掉头轨迹点,蓝色圆形为作业轨迹点,黄色三角形为X形掉头轨迹点,橘黄色菱形为作业异常轨迹点。
图4c~4e为X形掉头识别与修正:通过D-K-means聚类方法后得到作业轨迹与掉头轨迹,图4c中c1存在作业轨迹误识别为掉头轨迹的情况,经过基于轨迹片段的聚类修正方法M1修正后见图4c的c2;图4d中d1存在作业异常轨迹被识别为掉头轨迹的情况,经过基于方向变化的修正方法M2后见图4d的d2;图4e中e1存在边界不统一的情况,经过基于收获机作业特性的修正M3后见图4e的e2。
图4b、4f为U形掉头识别与修正:通过SVM识别后初步得到U形掉头轨迹,图4b中b1存在边界长度不统一的情况,经基于掉头轨迹曲率的边界修正为图4b的b2;图4b中b2存在X形掉头轨迹相邻的轨迹点被误识别为U形掉头轨迹(黑色虚线圆框处),经基于掉头时间差的修正方法S2修正为图4b的b3;图4f中f1存在作业轨迹被误识别为U形掉头轨迹,经基于掉头前后角度变化S3修正为图4f的f2。
3.2 轨迹识别算法评价
为客观评价收获机田内轨迹识别算法的效果,选取准确率P、召回率R和F1值3种评价指标进行评价。表3为数据集B的轨迹识别算法结果。
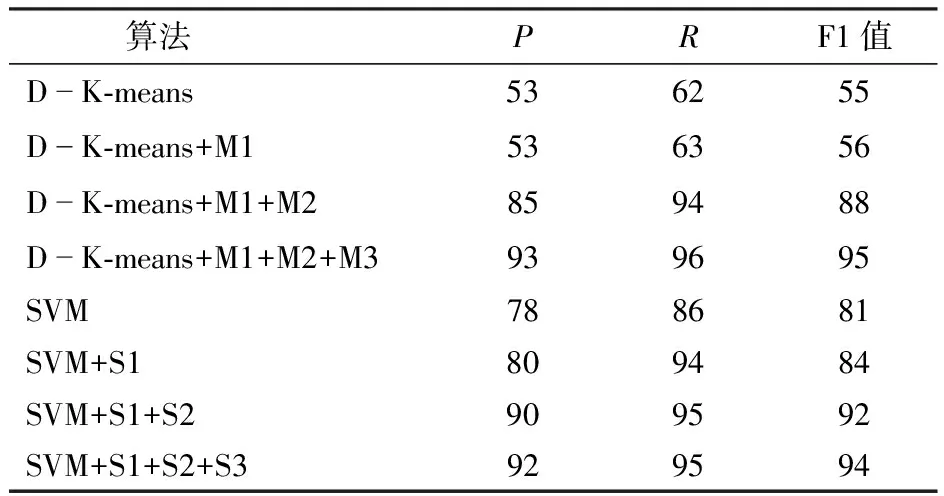
表3 轨迹识别算法结果
X形掉头初步识别与三步修正后F1值由55%提高到95%,表明基于聚类的X形掉头识别算法3种修正方法可以有效地对收获机田内作业的X形掉头轨迹、异常轨迹与作业轨迹进行识别。在U形掉头轨迹识别中对数据集B的50幅田内轨迹进行识别,4种轨迹SVM识别结果为81%,对SVM初步识别结果进行3步修正,修正前后F1值由81%提高到94%,表明X形掉头轨迹识别算法与U形掉头轨迹识别算法结合可以对收获机田内作业的4种轨迹进行识别。
实际应用中GNSS设备采集频率不同,选取时间间隔1~5 s的50幅轨迹,每种时间间隔10幅,及时间间隔为10、15 s的两幅农田内轨迹数据,表4为轨迹识别结果。
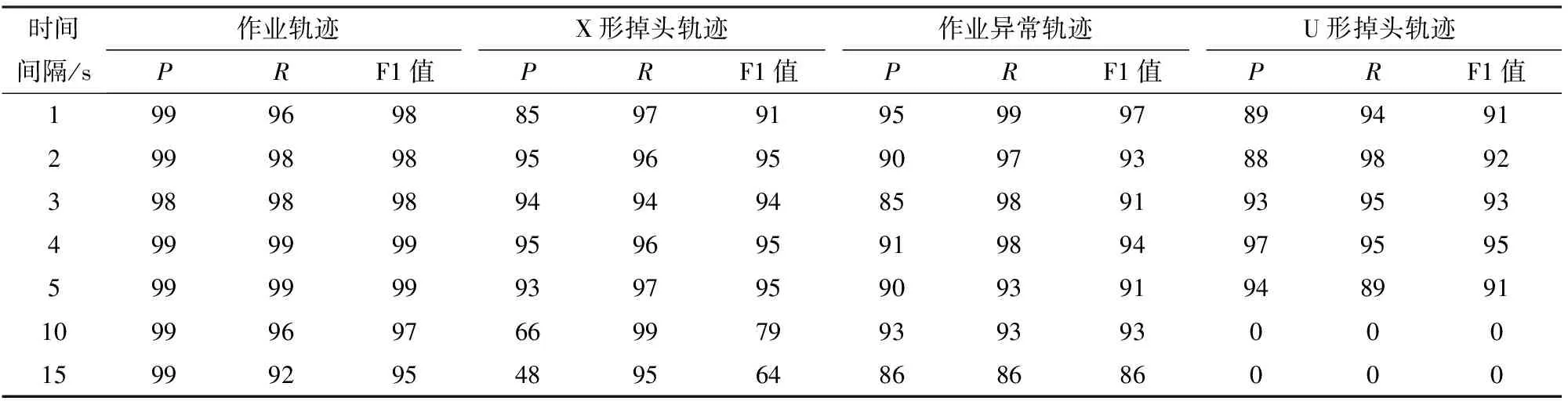
表4 不同频率轨迹数据识别结果
由表4可见,1~5 s内轨迹识别结果的3种评价指标均在85%以上,表示算法在1~5 s时间间隔的轨迹数据中均有良好表现。时间间隔10、15 s数据的X形掉头识别结果明显较差,主要原因在于当数据变得稀疏时,轨迹点的连线将从平滑变得尖锐,当原作业轨迹点与U形掉头轨迹点的α属性变大时,会被误识别为X形掉头轨迹点。被误识别为X形掉头的U形掉头轨迹点会在SVM初步识别时被去除,导致输入SVM模型的数据中无U形掉头轨迹片段,因此U形掉头轨迹识别结果为0。综上,当轨迹点时间间隔为1~5 s时本算法效果较好。
为进一步验证算法的有效性,从数据集B中选取一块标注面积为1.72 hm2的农田,其轨迹时间间隔为4 s,分别通过距离算法计算轨迹识别前后的农田面积并进行对比。
图5a为原始轨迹,包含1 479个轨迹点,距离算法计算面积为2.33 hm2,算法运行时间为369.67 ms;图5b为X形掉头识别结果,包含X形掉头轨迹点157个,作业异常轨迹点16个,如图中黄色三角形和橘黄色菱形轨迹点,去除X形掉头与异常轨迹点后计算面积为2.17 hm2,算法运行时间为369.08 ms,误差相比原始轨迹点面积计算误差降低9.51%;图5c为运行U形掉头识别结果,识别出U形掉头轨迹点47个,如图中红色方形轨迹点。将两种掉头轨迹及作业异常轨迹点均去除后得到图5d,剩余轨迹点个数1 258个,计算面积为2.11 hm2,算法运行时间为364.10 ms,面积计算误差相比标注面积仍有22.43%,但相比原始轨迹的计算面积误差降低12.76%,比只去除X形掉头轨迹和异常轨迹误差降低3.26%。
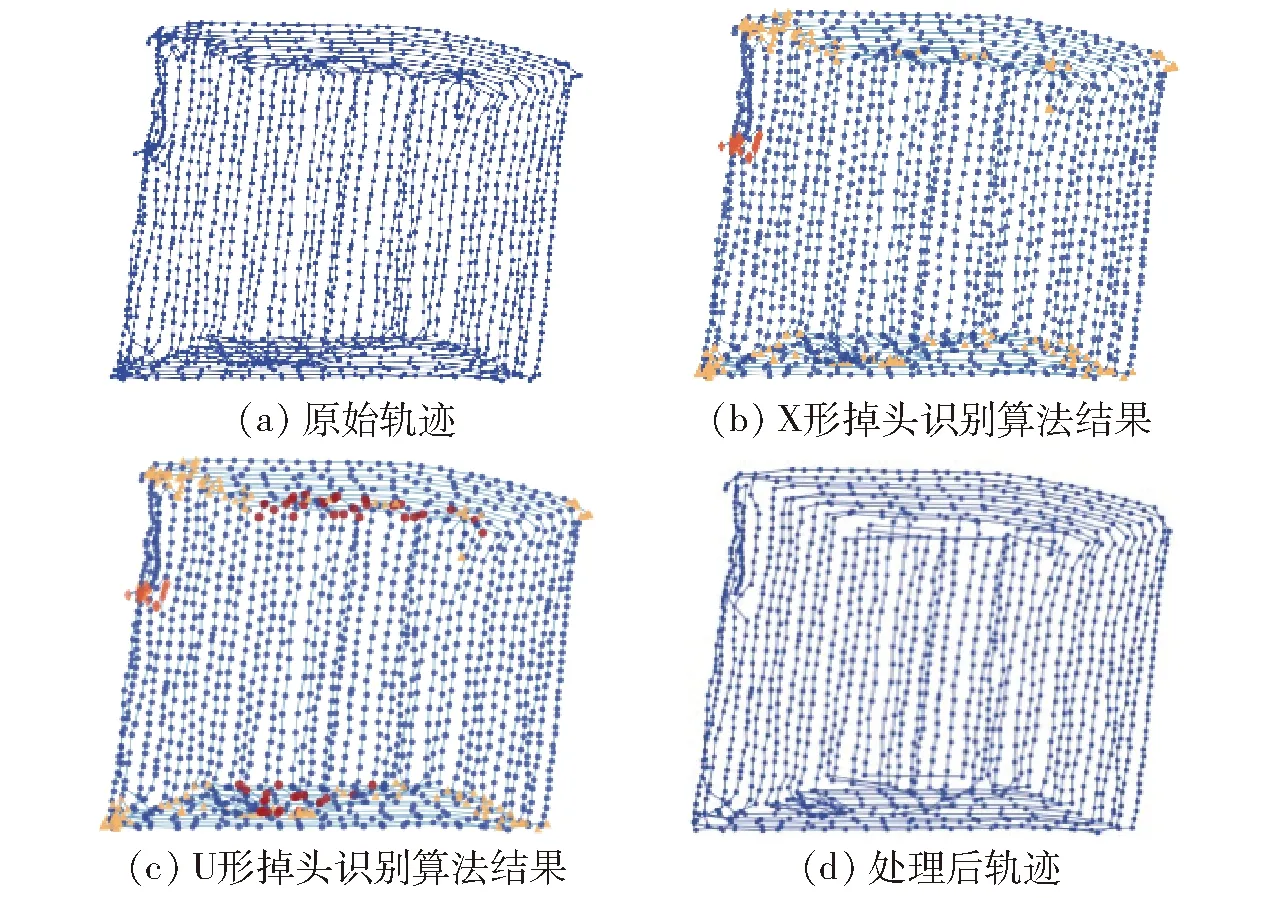
图5 收获机田内轨迹处理过程
4 结论
(1)通过X形掉头识别算法识别出X形掉头、作业异常和作业轨迹点,再通过U形掉头识别算法将作业轨迹点进一步识别出U形掉头轨迹点。本研究所用的50块农田轨迹数据的综合识别结果F1值为94%,时间间隔1~5 s数据的4种轨迹识别结果F1值均在90%以上。随着时间间隔增加,间隔为10 s与15 s的数据识别效果变差,实际应用时可参考1~5 s的时间间隔。
(2)对一块1.72 hm2的农田作业轨迹进行识别,去除掉头轨迹与异常轨迹后通过距离算法计算农田面积,相比使用原始轨迹,其面积计算误差降低12.76%。
