基于Transformer的透明物体图像语义分割
2023-09-23朱松豪孙冬轩
朱松豪,孙冬轩,宋 杰
(南京邮电大学 自动化学院、人工智能学院,江苏 南京 210023)
语义分割作为计算机视觉研究的重要内容之一,结合了目标检测、图像分类和图像分割。 通过某种方法将图像中的每个像素进行分类,最终得到一幅具有语义标注的分割图像,这种像素级分割也被称为密集预测。
随着全卷积神经网络的出现[1],深度学习逐渐用于解决图像语义分割问题。 由于图像分类和语义分割间存在着密切的联系,因此许多先进的语义分割框架都是基于ImageNet 的图像分类体系的变体,如AlexNet[2]、VGGNet[3]和GoogleNet[4]。 全卷积神经网络通过将以上这些分类网络的全连接层调整为卷积层,再经过端到端、像素到像素的训练,语义分割性能超越传统机器学习方法。
从模式识别的角度,语义分割问题可视为一个结构化预测问题,其难点在于如何设计能够有效捕获上下文信息的模块。 这方面的一个典型例子是空洞卷积[5],它通过在卷积核中“膨胀”孔洞增加感受野。 随着自然语言处理的巨大成功[6],Transformer横空出世,创造性地实现了对序列化数据的并行处理,极大提高了计算效率,因此Transformer 被引入视觉任务。 Dosovitskiy 等[7]提出视觉Transformer,首次将Transformer 引入计算机视觉领域。 按照自然语言处理的思路,Dosovitskiy 等将图像分割成多个线性嵌入的图像块,并将这些图像块输入带有位置嵌入的标准Transformer,作为向量进行多头注意力操作,实现图像全局上下文信息的捕获,从而在ImageNet 上获得了令人印象深刻的性能。
作为Trans10K-V2 数据集的创作者,Xie 等[8]提出用于解决透明物体语义分割的方法,该方法通过将卷积神经网络提取的初始特征和位置信息输入到Transformer,用以提取注意力特征,最后通过一个小的卷积头获得最终的语义分割结果。 由于透明物体具有透视、反射等特殊性质,因此需要借助丰富的上下文信息才能推断某个像素到底属于哪个类别。 受该方法启示,本文在编码器的注意力模块中增加了一个卷积模块,如图1 所示,其中图1(a)为文献[7]中编码器部分的结构,图1(b)为改进后的混合结构。 其多头注意力模块用于捕获图像的全局信息,卷积模块用于捕获图像的局部信息,这对于改善复杂场景下的语义分割性能至关重要。
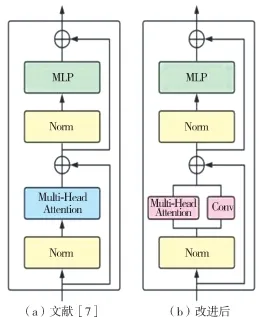
图1 Transformer 编码器结构示意图
文献[9]利用空洞空间卷积池化金字塔获取多尺度信息,用以获取更精确的分割结果。 文献[10]利用空洞空间卷积池化金字塔挖掘多尺度卷积特征,并对图像全局特征进行编码。 受该方法启示,本文在最后的特征融合模块引入了改进的金字塔模块,将主干网络提取的特征映射与注意力特征映射相结合,进一步提升透明物体语义分割效果。
本文所提方法主要贡献描述如下:
(1) 为更好地捕获图像上下文信息,提出将多头自注意力与卷积相结合的注意力机制模块引入Transformer 编码器,以期获得更为精确的特征映射;
(2) 为 更 好 地 融 合 多 尺 度 特 征 映 射, 在Transformer 解码器得到注意力特征映射后,引入了包含空洞空间卷积池化金字塔结构的特征融合模块,以期更好地融合主干网络特征映射和注意力特征映射,用以提升透明物体语义分割效果;
(3) 本文所提方法模型在Trans10K-v2 数据集上展现了良好的性能。
1 相关工作
1.1 语义分割
作为深度学习开山之作的全卷积神经网络,其将传统的分割方法转换为端到端的全卷积分类网络。 之后,研究人员从不同角度致力于改善全卷积神经网络。 继承全卷积神经网络的思想,文献[11]提出基于编解码结构和跳跃连接的分割方法。 文献[12]将边界信息引入条件随机场,用于改进分割结果。 文献[5,13]均通过引入空洞卷积扩大感受野,提高语义分割效果。 文献[14]利用金字塔解析模块获取不同区域上下文信息,用于解决语义分割问题。 同时,基于注意力机制的网络模型也广泛用于捕获上下文信息。 文献[15]利用点式空间注意模块,动态捕捉上下文信息,研究结果表明,全局上下文信息有利于提高场景分割精度。 文献[16]的网络模型中同时嵌入了空间注意力机制和通道注意力机制。 上述这些方法的主干网络依然基于全连接网络,其中的编码和特征提取部分大多都基于文献[3]提出的VGG 和文献[17]提出的ResNet 等经典卷积网络。
1.2 视觉任务中的Transformer
文献[6]中Transformer 和自注意力模型的出现,突破性地改变了自然语言处理的研究现状。 文献[7]首次将自然语言处理中的纯Transformer 引入视觉任务,构成视觉Transformer,并在图像分类方面取得令人满意的结果,为在语义分割模型中开发基于纯Transformer 编码器的设计提供了直接启发。在目标检测领域,文献[18]利用Transformer 对目标位置信息和全局图像上下文关系进行推理,且不使用非极大值抑制,而直接输出最终检测结果。 文献[19]首次在Transformer 中引入金字塔结构,展现了在视觉任务中纯Transformer 模型与卷积神经网络模 型 相 似 的 潜 力。 文 献[20] 采 用 视 觉Transformer 作为编码器,卷积神经网络作为解码器,获得了不错的性能。
1.3 特征融合
文献[11]中的U-Net 方法在下采样时提取分辨率较小的特征,在上采样时又将分辨率逐层回复到原来大小,在此过程中采用串联方式将两种尺度特征相结合,得到预测结果。 这种思想也常常出现在Transformer 结构中,但最后的融合特征尺寸过大,训练时间和预测时间较长。 文献[21]中的特征金字塔网络模型既可用于目标检测,也可用于语义分割,与U-Net 网络模型类似,特征金字塔网络模型也是基于编码-解码过程提取全局特征,区别在于特征金字塔网络模型采用叠加方式,并基于多个特征映射进行预测分类。 文献[9]提出基于空洞卷积特征金字塔的特征融合方式,对于主干网络提取的不同尺度的特征映射,分别使用不同空洞率的卷积得到新的特征映射,再进行融合,获得最终的特征。 文献[22]利用跨步卷积和空洞卷积进行特征融合,进一步提高了语义分割结果。
1.4 Trans10K-V2 数据集
文献[23]中的Trans10K 数据集是第一个大规模现实世界透明物体语义分割数据集,但其只有两个类别。 Trans10K-V2 数据集在其基础上,进一步使用更细粒度的类别对图像进行注释。 Trans10KV2 数据集共有10 428 张图像,分为2 个大类以及11 小类,具体信息如下:(1) 透明物品。 茶杯、玻璃瓶、玻璃罐、玻璃碗和眼镜。 (2) 透明材质。 窗户、透明隔板、透明盒子、冰柜盖板、玻璃墙和玻璃门。这些物体常出现在人们的生活中,更适合现实世界的应用。 图2 给出来自Trans10K-V2 数据集的例图。

图2 Trans10K-V2 数据集示意图
2 本文所提方法
图3 给出本文所提出的基于视觉转换器的透明物体语义分割网络模型结构图。 首先,利用卷积神经网络提取输入图像的初始特征映射,并将其展开平铺成一维特征序列;然后,将得到的一维特征序列输入至带有位置嵌入的视觉转换器的编码器,用以获取带有注意力的编码特征映射;其次,将编码特征映射与一组可学习的类别嵌入传至视觉转换器的解码器,用以获取注意力特征映射,其中N为类别数,M为多注意力的头数;最后,利用不同采样率的空洞卷积,实现来自卷积神经网络的初始特征映射与来自视觉转换器的注意力特征映射的融合,得到最终的透明物体语义分割结果。
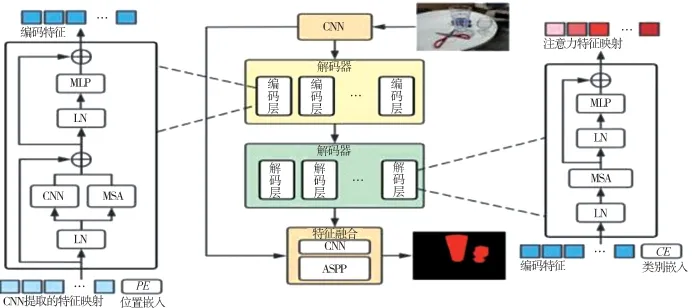
图3 本文所提网络模型的结构示意图
2.1 主干网络模块
对于图像语义分割算法而言,绝大多数主干网络均为来自文献[17]的残差网络,该网络的核心思想是引入一个恒等捷径连接结构,直接跳过一个或多个中间层。 通过残差学习,残差网络能够有效解决随着网络深度不断加深,网络性能不断退化的问题。 特征提取过程中,通常选取残差网络第一层至第五层的特征映射,这是因为相较于输入图像原始尺寸,第一层至第五层的特征映射分别缩减至1/2~1/25。
如图3 所示,将一幅尺寸为H×W×3 的原始图像,输入至残差网络-101 网络,通过下采样进行提取特征,文中提取网络第四层的特征映射。 由于视觉转换器的输入为一维数据序列,因此将二维图像特征进行分割并拉伸为C×(H/16,W/16)的图像块序列(C表示特征通道数),以便传入编码器中进行编码。
2.2 视觉转换编码器模块
视觉转换编码器模块由多层编码器模块堆叠而成,其中每层编码器模块由一个注意力模块、一个多层线性感知器以及一个归一化层组成,需要注意的是,这里的注意力模块包含一个多头自注意力模块和一个卷积模块,多层线性感知器包含一个ReLU激活函数和两个全连接层。 图4 给出视觉转换编码器模块的结构示意图。
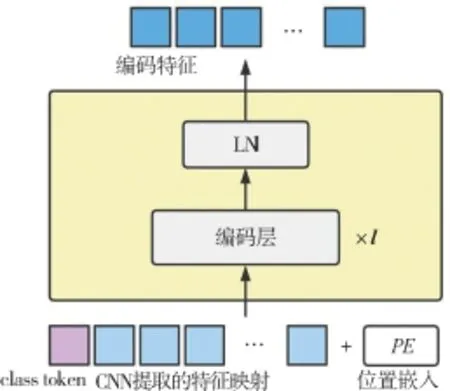
图4 视觉转换编码器模块的结构示意图
视觉转换编码器模块的流程描述如下:首先,利用残差网络提取特征映射,并将其与位置嵌入信息作为视觉转换编码器的输入;然后,依次利用层标准化和多头自注意力提取特征映射;接下来,依次利用层标准化和多层线性感知器提取特征映射,并进行多层以上的处理过程;最后,再次利用层标准化获得最终的编码特征映射。
由于视觉转换编码器的输入特征须是一维序列,因此为弥补空间维度上的缺失,本文引入文献[24]中的一组位置嵌入补充至一维特征序列,用以提供这些图像块在整幅图像中的绝对位置信息和相对位置信息,此时的位置嵌入与展开的特征映射具有相同的维度C×(H/16,W/16)。 除了采用位置嵌入策略外,本文还引入了文献[7]中的类别标记,其输出特征加上一个线性分类器即可实现分类。 网络模型训练过程中,随机初始化类别标记,并将其与位置嵌入进行相加。
在注意力机制方面,本文将原始视觉转换器中的多头注意力模块改变成多头自注意力与卷积层的混合结构,采用线性多头自注意力捕获全局上下文信息,采用卷积层捕获局部上下文信息。 最后,对全局上下文和局部上下文进行一个与操作,提取全局-局部上下文信息。
对于能够捕获全局上下文信息多头自注意力而言,其输出形式表示为
其中,Q、K、V分别表示查询、键、特征信息,分别通过3 个不同的权值矩阵WQ、WK、WV乘以输入一维特征序列获得,且采用softmax 函数计算注意力特征,表达式为
多头自注意力的特征提取过程描述如下:首先,通过n个不同的线性变换对Q、K、V进行投影;然后,将不同的线性投影结果进行拼接,具体操作为
经过编码器后,特征映射的维度依然为C×(H/16,W/16)。
卷积层部分采用卷积核分别为1、3、5 的3 个并行卷积,再分别进行批归一化操作来提取局部上下文信息,生成的全局和局部上下文进一步进行深度卷积、批归一化操作和1×1 卷积,以增强泛化能力。图3 中编码器模块中的注意力机制混合结构细节如图5 所示。
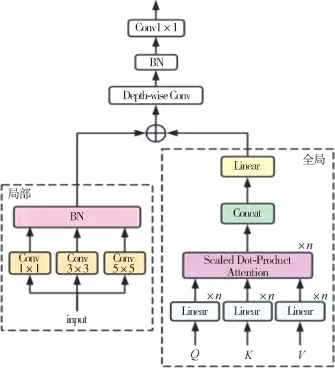
图5 注意力机制混合结构示意图
整个编码流程可用式(4)表示。
其中,x表示特征映射,PE表示位置嵌入信息,l表示编码器层数。
2.3 视觉转换解码器模块
解码器模块由多层解码器模块堆叠而成,其中每层解码器模块包含一个多头自注意力模块、一个标准化层以及一个多层线性感知器。 图6 给出视觉转换解码器模块的结构示意图。
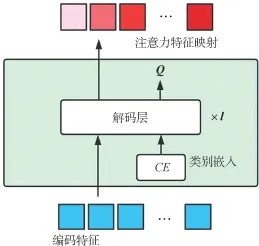
图6 视觉转换解码器模块的结构示意图
视觉转换解码器模块的流程描述如下:首先,将编码器得到的特征映射与一组可学习的类别嵌入输入到解码器;然后,利用多头自注意力机制获得一个注意力特征映射以及一个新的目标区域特征映射;接下来,分别将编码特征映射、注意力特征映射、目标区域特征映射依次通过层归一化、多层线性感知器提取特征映射;最后,进行多层处理,获得不同类别的注意力特征映射。
本文在解码器的输入端初始化一组可学习的类别嵌入Ecls作为查询Q,由多层视觉转换解码器模块通过多头自注意力进行迭代学习,且每次迭代后的类别嵌入Ecls可表示为
其中,n表示解码器层数。 每次迭代更新一次,就会生成一个新的类别嵌入供下一层查询。 经过多层解码后,最后获得的注意力特征映射的维度为N ×M ×(H/16,W/16)。
整个解码流程可用式(6)表示。
其中,CE表示类别嵌入,F表示编码特征映射,A表示注意力特征映射,l表示解码器层数。
2.4 特征融合模块
经过视觉转换器编码-解码后,将得到的注意力特征映射与主干网络提取的初始特征映射合并,然后进行每类别上的像素分类。 由于视觉转换器关注图像的全局上下文信息,因而得到的注意力特征映射往往忽略一些细节特征,需要融合不同尺度的特征才能达到更好的分割效果。
与文献[25]采用的特征融合方法不同,这里将最大池化层替换为包括深度卷积和点卷积的深度可分离卷积,其中的深度卷积是指首先对输入特征的每个通道分别进行卷积,然后再进行1×1 的全卷积,这样可大幅减少参数量并大幅降低计算量。
特征融合模块的流程描述如下:首先,对主干网络提取的第三层特征进行自适应平均池化,且利用空洞率分别为6、12 及18 的3 组卷积核进行卷积操作;然后,将解码器获得的注意力特征映射上采样至N×M×(H/4,W/4)维度,并与卷积神经网络提取的特征映射融合至N×(M+C)×(H/4,W/4)维度,再经过卷积等操作降至N×(H/4,W/4)维度;最后,利用平均最大池化函数获得分割结果。
对于优化器的选择,很多深度学习任务都会使用基于随机梯度下降的优化算法,实现模型收敛,但随机梯度下降算法存在以下问题:(1) 很难选择合适的初始学习率;(2) 各个参数只能使用同一种学习率;(3) 学习率调整策略受限。 为此,这里选择适应性矩估计优化器完成模型收敛。 这是因为适应性矩估计优化器结合了自适应学习梯度下降算法和动量梯度下降算法的优点,因而使得适应性矩估计优化器既能适应梯度稀疏问题,又能缓解梯度振荡问题。
3 实验结果
3.1 实验设置
(1) 利用残差网络-101 的预训练模型初始化网络参数。
(2) 对于优化损失,设置学习率为1×10-8,权重衰减设置为1×10-4,动量设置为0.9 的适应性矩估计优化器。
(3) 多头自注意力的头部数设置为8,编码层和解码层的层数均设置为16,多层线性感知器的比率设置为3,训练次数设置为50 个周期,初始学习率设置为1×10-4。
3.2 实验结果
由表1 所示的实验结果可以看出,本文所提方法的准确率和平均交并比分别达到最高的94.85%和73.86%。 相较于性能最好的文献[8]中语义分割方法Trans2Seg,本文所提方法的准确率和平均交并比分别提高了0.86%和1.71%。
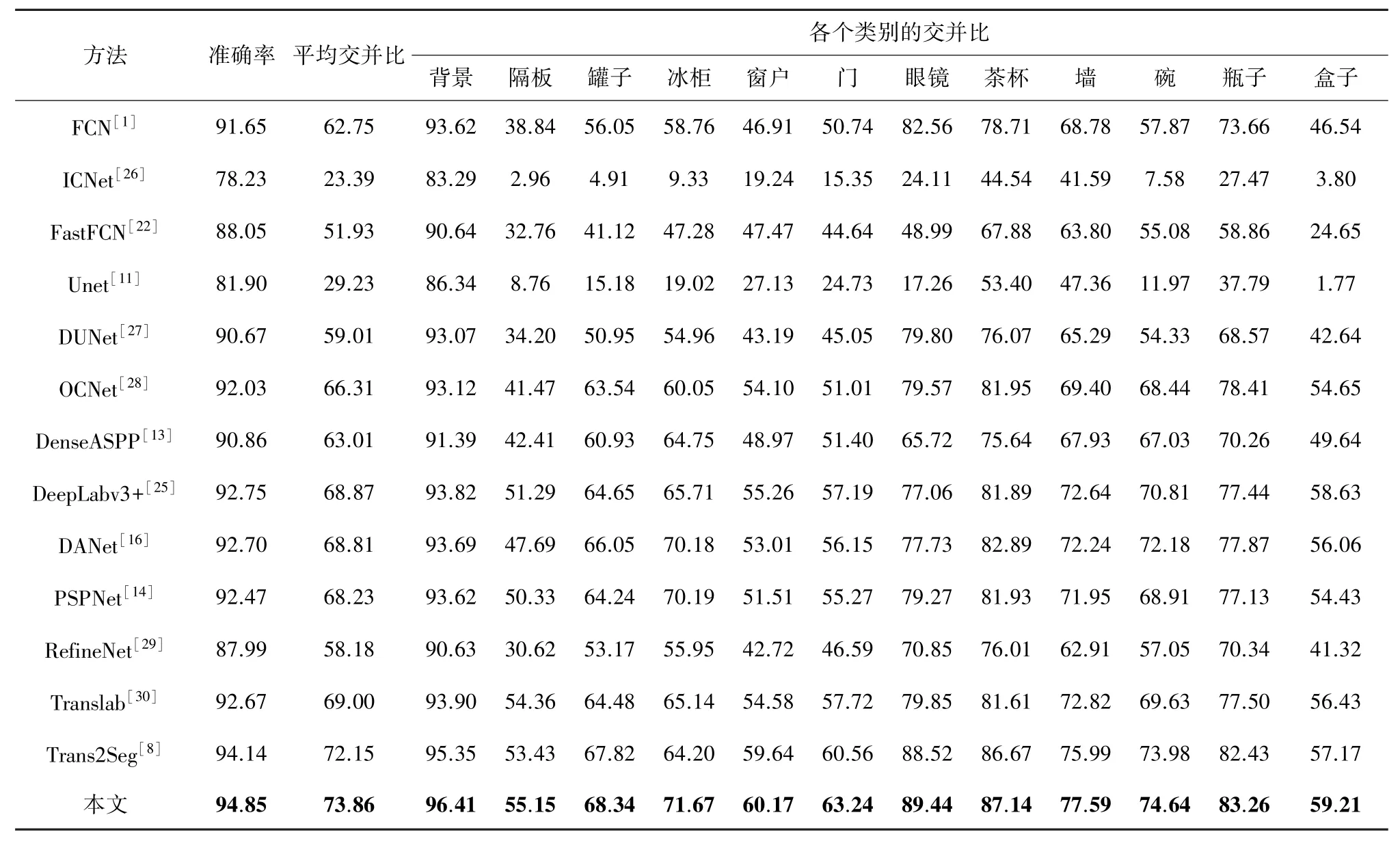
表1 Trans10K-V2 数据集实验结果 %
此外,由表1 的实验结果还可以看出,在所有类别的透明物体上,本文方法的分割性能总体上都得到了提高,特别是在大面积和整体透明物体方面。 例如,与目前整体性能先进的Trans2Seg 方法相比,本文提出的方法在“冰柜”、“玻璃门”和“玻璃盒子”3 个类别的平均交并比分别提高了7.47%、2.68%和2.04%。
3.3 消融实验
本文以文献[8]中的方法作为基线方法,首先通过卷积神经网络提取输入图像的初始特征,然后将其与位置信息输入到Transformer 的编码器和解码器中提取注意力特征,最后通过一个卷积头得到最终的分割结果。 由于Transformer 和卷积神经网络都具有特征提取的功能,Transformer 中强大的注意力机制侧重于提取图像的全局特征,而卷积神经网络则侧重于提取图像的局部特征。 对此,本文进行了全部的消融实验,具体包括以下3 个方面:(1)标准的多头注意力机制与卷积层辅助的注意力-卷积机制的对比实验;(2) 是否有特征融合模块的对比实验;(3) 多头自注意力中不同头数的对比实验。
第一组实验研究了Transformer 编码器中卷积层对注意力机制的辅助对实验结果的影响。 作为对比,使用图1(a)所示的标准Transformer 编码器结构。 从表2 所示的对比实验结果可以看出,使用卷积层辅助的注意力-卷积结构可以有效提高分割精度。

表2 注意力机制中卷积层的对比实验结果 %
第二组实验研究了特征融合模块对实验结果的影响。 作为对比,本文没有采用Transformer 解码器输出注意力特征映射后的空洞空间卷积金字塔结构,而是对注意力特征映射进行上采样后,直接与从卷积主干网络中提取的初始特征映射进行连接操作,最终得到分割结果。 从表3 所示的对比实验结果可以看出,通过使用空洞卷积对主干网络特征映射进行多尺度处理后,再与注意力映射融合,可以获得更好的实验结果。
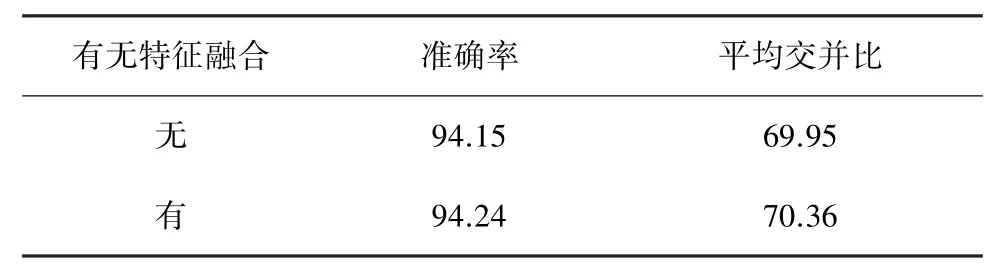
表3 特征融合模块的对比实验结果 %
第三组实验研究了多头自注意力中头部的数量对实验结果的影响。 头部数是影响注意力机制性能的一个重要超参数。 文献[31]中的研究表明,类似于卷积神经网络同时使用多个滤波器,多头的自注意力有助于网络利用各种特征。 本文设置了3 种多头自注意力,分别为4 头、8 头和16 头,进行对比实验。 从表4 所示的对比实验的结果可以看出,随着头数的增加,平均交并比值先增大后减小,并不是头数越多,分割性能的提高就越大,所以选择设置头数为8 进行实验。

表4 多头自注意机制中不同头数的对比实验结果 %
3.4 可视化实验结果
为了更直观地评价本文网络模型的性能,本文将日常生活中的实拍物品、一些复杂场景下的物体、提升最为明显的3 类物体以及本文方法与其他语义分割方法的对比进行分割结果的可视化展示。
图7 为对日常生活中的透明物体的实拍图像进行分割的结果。 从分割图像中可以看出,本文的网络模型对于生活中的实拍物体也具有较高的准确度,对瓶子、杯子、眼镜等常见物品识别得比较精细,也进一步说明本方法具有一定的实际意义。

图7 日常物品实拍分割结果
图8 为一些在复杂场景下的透明物体的分割结果。 例如,有树木和楼房等其他干扰物体作为背景的窗户和玻璃墙、商场中陈列商品的玻璃橱窗、多个交叉放置的玻璃杯、装有其他物体的杯子和罐子以及容易与玻璃墙和窗户混淆的玻璃门等。 从分割结果可以看出,在较为复杂的环境状态下,本文方法也能够轻松识别出透明物体的所在位置,并能分割出相对清晰的物体轮廓。

图8 复杂场景下的分割结果
图9 列出了“冰柜”、“玻璃门”和“玻璃盒子”3 种物体的原始图像、语义标注信息以及本文方法与Trans2Seg 方法的分割结果对比。 可以看出,本文对这3 类对象的分割精度有了明显的提高。 由于冰柜内部有许多陈列物品的干扰,Trans2Seg 很容易将冰柜误识别为窗户或隔板。由于玻璃墙与门的特征极其相似,在识别过程中很难把握门的特征而混淆。 Trans10K-V2 数据集还将一些如透明尺子和透明牌子的物体归类到盒子类别中,这进一步增加了分割的难度。 本文方法可以有效地克服这些问题,获得相对精确的分割结果。

图9 3 种物体分割结果对比
图10 为不同方法的分割结果示意图。 可以看出,与其他传统的卷积神经网络方法相比,本文方法最终预测到的结果更加准确,特别是在较为复杂的场景下。 在物体边缘的地方识别得更加精细,而且一些玻璃物体上的细节也可以高质量地预测出来,例如商场里的玻璃门、玻璃墙和透明橱窗。

图10 与其他方法的分割结果对比
通过上述可视化结果可以发现,本文方法中强大的注意力机制结构和特征融合方法能有效地捕捉到透明物体与周围环境之间的关系,并能在多种干扰因素存在下,较为准确地判断出该部位属于透明物体的一部分还是周围其他物体。
4 结束语
本文针对一种新的透明物体数据集的语义分割方法进行了相关研究。 以Trans2Seg 方法作为基线,提出了一种基于Transformer 的分割网络,并在此基础上优化了编码-解码过程的结构,设计了Transformer 编码器的多头自注意力与卷积的混合结构。 一方面,利用传统的卷积方法捕捉图像的局部特征;另一方面,利用多头自注意力提取图像全局特征,更好地理解图像上下文信息。 此外,为了提高分割效果,还引入了包含空洞空间卷积金字塔结构的特征融合模块。 实验结果表明,该网络模型能有效提高透明目标分割的性能。
