基于小样本学习的中文文本关系抽取方法
2023-09-23季一木刘尚东邱晨阳朱金森
季一木,张 旺,刘 强,2,刘尚东,洪 程,邱晨阳,朱金森,惠 岩,肖 婉
(1.南京邮电大学 计算机学院,江苏 南京 210023 2.南京邮电大学高性能计算与大数据处理研究所,江苏南京 210023 3.国家高性能计算中心南京分中心,江苏 南京 210023 4.南京邮电大学高性能计算与智能处理工程研究中心,江苏 南京 210023 5.南京邮电大学 教育科学与技术学院,江苏 南京 210023)
随着互联网的快速发展,数据越来越多样化,文本作为信息传播的主要形式之一,不断地更新[1]。实体关系抽取作为文本挖掘和信息抽取的核心任务,是知识图谱构建过程中的关键一环。 其主要目的是对句子中实体与实体之间的关系进行识别,抽取句子中的三元组信息,即实体1-实体2-关系三元组,得到的三元组信息可以提供给知识图谱的构建、问答、机器阅读等下游自然语言处理(Natural Language Processing, NLP)[2]任务。 由于近年来自然语言处理的发展与应用,关系抽取也吸引了许多研究者。 有监督的关系抽取方法如CNN、RNN、LSTM 等[2]在该任务上已取得非常好的效果。 但是,有监督的关系抽取的准确率往往过于依赖高质量的数据集,而人工标准数据集往往需要耗费大量精力。 为了快速构造有标签的大规模数据集, Mintz等[3]提出了远程监督的思想,用来生成带标签的大规模数据集。 该思想基于这样一个假设:如果一个句子中含有一个关系涉及的实体对,那这个句子就是描述的这个关系。 因此,远程监督的数据里存在大量噪声。 为了缓解噪声数据问题,Zeng 等[4]使用分段卷积神经网络(PCNN)提取特征,基于该模型的扩 展 有PCNN +MIL[4]、PCNN +ATT[5]、PCNN +BAG[6]等。 虽然这些模型在公共关系上取得了令人满意的结果,但当某些关系的训练实例很少时,它们的分类性能仍然会急剧下降[7]。 且现有的远程监督模型忽略了长尾关系的问题,这使得这些模型难以从纯文本中提取全面的信息。
在小样本学习(Few-shot Learning)方法中,仅仅需要几个样本实例就能使模型学会区分不同关系类型的能力[8],从而缓解大量无标签数据带来的标注压力。 小样本学习的概念最早从计算机视觉(Computer Vision)领域兴起,近几年受到广泛关注,在图像分类任务中已有很多性能优异的算法模型,但是在自然语言处理领域发展得较为缓慢,主要原因是与图像相比,文本更加多样化和嘈杂[9]。 最近,随着元学习方法[10-11](Mate-Learning)、图卷积神经网络[12](Graph Convolutional Network, GCN)等概念的提出,使得模型能快速地从少量的样本中进行学习。 Han 等[13]构建了一个用于小样本关系抽取的数据集FewRel,并基于不同的少样本模型对其进行了评估。 在这些模型中, 基于原型网络(Prototypical Network)[14]和 匹 配 网 络(Matching Network)[15]的方法能快速有效地对小样本进行学习并取得比较好的效果。 但是FewRel 是针对英文文本构建的关系抽取数据集,而相对于英文来说,中文更为复杂,具体表现在:(1) 在中文里,最小的语义单位是字,而字与字之间又能组成不同语义的词,所以在处理中文分词时容易遇到歧义问题;(2) 随着互联网的发展,会对一些词赋予新的含义,同时组合不同的字也会产生一些新的词汇,给模型的训练带来了不小的难度;(3) 中文还有一个特点是重意合而不重形式,句子结构比较松散,不易于提取特征。
为了解决上述问题,本文以FinRE[16]为基础,重新构建了中文关系抽取数据集,使用语义关系的网络HowNet[17]对抽取实体进行语义细分,同时基于改进后的Clues-BERT[18-19]对输入的文本进行编码,使用少样本学习中的原型网络对数据进行关系抽取。 同时,为了减少噪声数据对结果准确率的影响,考虑到每一次训练中,不同的实例对结果的影响不同,这里使用了基于实例级别的注意力机制对模型进行优化。
综上所述,本文的主要贡献如下:
(1) 基于FinRE 重新构建了适合少样本学习的中文数据集。
(2) 在对句子级的注意力机制的基础上,使用HowNet[17]对实体进行语义拆分,引入了实体级别编码层面的注意力机制,使模型关注质量更高的特征,提高实例编码质量。
(3) 为了评测该方法的有效性,人工地在训练集里加入了一定比例的噪声数据进行训练。 结果显示,基于注意力机制的原型网络要优于原始原型网络,关系抽取的准确率提升在1%~2%之间。
1 相关工作
关系抽取是非常重要的一项任务,许多研究者提出了各种不同的解决方法。 处理关系抽取任务的第一步就是需要将文本字符编码成计算机可以理解的数值常量,以便于提取特征。 Mikolov 等[20]开源了一款用于词向量计算的工具——Word2Vec,用于计算非常大数据集中单词的连续矢量表示。 但是由于计算出来的词和向量是一对一的关系,所以一次多义的问题无法解决。 这种缺点在中文上表现得比较明显,因为中文里单独的字的含义就非常丰富,组合成词的语义就更为繁多复杂。 Google 发布的BERT[18]模型在处理输入的中文序列时,将每个字视为最小的语义单位,使用双向Transforme 进行编码, 使得每个词都要和该句子中的所有词进行注意力计算,从而学习句子内部的词依赖关系,捕获句子的内部结构。 目前,BERT 在NLP 的多个研究领域中都取得良好效果。 但是,原始的BERT 模型参数众多,导致模型训练速度慢,且对中文词向量的表示效果远不如英文。 本文使用Xu 等[19]提供的基于BERT 的预训练模型CLUE-BERT,该模型使用100 GB的原始语料库,包含350 亿个汉字。 与Google 发布的原生模型BERT-Base 相比较,在保证准确率不受影响的情况下,训练和预测速度均有提高。
在将句子编码为向量后,如何优化关系抽取模型也是研究的热点。 最近,元学习的思想被应用到少样本关系抽取中,目的是让模型获得一种学习能力,这种学习能力可以让模型在新的领域自动学习到一些元知识。 在常规小样本关系抽取算法中,基于度量和优化的元学习方法最为常见。 Ye 等[21]提出基于卷积神经网络的多级别匹配聚合网络,Xu等[22]提 出 的 基 于 图 网 络 的 Frog-GNN 以 及Mueller[23]提出的标签语义感知预训练等方案提升了少样本关系抽取的准确率。 但这些复杂的方法往往对训练时间要求更长以及机器的性能要求更高,同时在小样本关系分类任务上的表现相较于基于简单度量和优化的方法并没有特别大的提升。 原型网络的思想和实现方法都十分简单明晰,效果与之前的工作相比得到了一定的提升。 Snell 等[14]基于简单度量的元学习方法提出了原型网络(Prototypical Network),认为每个类别在向量空间中都存在一个原型(Prototype),通过将不同类别的样例数据映射成向量并提取它们的“均值”表示一个类别的原型,通过比较向量之间的欧式距离进行相似度的判断。然而简单地提取样例数据映射向量的均值并不能很好地反映类别的特征,因为不同的样例对原型向量的影响不同[24]。 由于样本量少,分类边界存在误差,当数据存在噪声时,容易对结果造成干扰。 在少样本学习图像任务中,注意力机制已被用于减少噪声的影响[25]。 Gao 等[26]提出了基于混合注意力的原型网络,针对实例级别和特征级别分别设计了不同的关注方案,以分别突出关键实例和特征,在英文数据集FewRel2.0[27]取得了比较好的效果。 但是在中文语境里,一个实体往往有更为丰富的含义。 因此,如何在中文语境里准确地关注每个实体在上下文中对应的语义,以及如何减少噪声实例对模型准确率的影响是本文的关注点。 在本文工作中,使用双重注意力机制给每个类别的不同样例以及每个实体不同的含义赋予不同的权重参数,在一定程度上减少了噪声对结果的影响,提升了模型对抗噪声的能力。 同时,在少样本关系抽取中,无需构造数据,数据不会存在长尾关系,仅需要少量的样本就能训练出优质的模型。
2 基于HowNet 的双重注意力机制小样本关系抽取算法
本节详细介绍基于小样本学习的中文文本关系抽取方法。 整体框架图如图1 所示,S表示支持集,Q表示查询集,Framework 为总体框架图,Proto-Vector 部分为原型网络计算出来的原型向量,Attention 部分为注意力机制计算结构图。

图1 模型的体系结构
2.1 符号和定义
在小样本关系抽取问题中,将训练数据集划分为已分类的支持集合S和待分类的查询集合Q, 该任务被定义为预测查询集中的实体对(h,t) 在对应的支持集中属于关系r。 对于给定关系集合R, 支持集S以及查询集Q,有如下定义
2.2 基于HowNet 的实例编码
HowNet 是一个大规模高质量的跨语言(中英)常识知识库,蕴含着丰富的语义信息。 其中将词义概念用更小的语义单位描述,这种语义单位被称为“义原”(Sememe),是最基本的、不易于再分割的意义的最小单位。 在实际关系抽取任务中,一个实体通常在不同的上下文环境中具有不同的含义,如“乔布斯创造了苹果”和“牛顿因为苹果发现了万有引力”中的“苹果”,在前者中是“特定品牌”的意思,而在后者中是“水果”的意思。 为了减少歧义对抽取结果的影响,使用HowNet 可以获取每个实体的最小的义原,例如“苹果”一词经过HowNet 拆分后可以得到的义原为“tree |树, SpeBrand |特定牌子,tool|用具, computer|电脑等”,如图2 所示。 然后经过BERT 编码后进行权重分配,计算出最符合上下文语义的向量,这一部分将在后面详细描述。
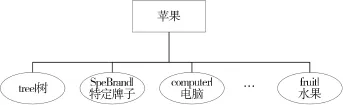
图2 “苹果”义原分解图
对于给定的实例x ={w1,w2,…,wn},假设其中的头实体为h,尾实体为t, 使用HowNet 获取每个实体的义原,即h→{h1,h2,…,hi},t→{t1,t2,…,tj}。 将 序 列{x,h,t} 使 用 预 训 练 模 型CLUEBERT,将句子编码为低维度向量以表示该实例的语义信息。 例如,对于给定的实例x,经过编码后句子中的每一单词wi将会与一个向量对应。
其中,BERT(·) 表示将输入的单词进行低维度嵌入,得到的向量ωi用来表示该单词的语义信息和语法信息。 最后将该实例中的所有词向量经过一个特征提取层,从而生成一个固定大小的句子嵌入向量X。
其中,Pool(·)用于提取每个单词特征,并输出一个固定大小的维度向量dw表示整个实例的语义和语法信息,编码流程如图3 所示。

图3 基于HowNet 的实例编码
2.3 原型网络
原型网络(Prototypical Networks)的主要思想是每个类别的关系类型在高维向量空间中都存在一个原型(Prototype),也称作类别中心点。 原型网络使用神经网络将不同的句子映射成一个向量,对于同属于一个关系类别的样本,求这一类样本向量的平均值作为该关系类型的原型,计算原型向量的一般方法是对支持集中所有的向量化样例数据取均值得到。其中,ci为原型网络为每个类别ri计算出的一个原型,为支持集S中的一个关系类型ri的嵌入式向量表示,K表示一次N way K Shot 分类中每个关系类型实例的数量。
在原型网络的计算中,所有实例都被同等地对待,但是在现实中并不是每个实例对结果都具有一样的相关性。 因此,在训练中应该关注那些更能代表该关系类型的实例。 在这里使用的方法中,简单的平均机制被实例级注意所取代,以突出支持集中那些更相关的实例,将在下一部分中讨论。 在分类时,原形网络使用Softmax(·)计算查询集Q与向量ci的距离,用来表示查询集总实例x在关系集合R中的概率。
其中,- d(·,·) 为计算两个向量距离的函数,fø(·) 表示 对 输入 的 查 询 集 实 例x进 行 编 码,pø(y = ri |x) 表示查询实例x是关系类型ri的概率。 距离函数有多种选择,根据Snell 等[14]的研究,欧几里德距离优于其他距离函数,因此在该网络中,选择使用欧几里德距离计算两个向量之间的距离。
2.4 双重注意力机制
每个实例中的实体经过HowNet 分解得到不同的义原,然而在现实中每个实体根据上下文的不同而具有不同的意义。 为了更为准确地表示实体在上下文中的意义,对其所有义原根据其相关性进行权重分配,从而减少噪声对训练结果的影响。 义原在经过CLUE-BERT 编码后得到其对应的向量表示形式,即Sems ={Sem1,Sem2,…,Semk},k =6,k为得到的义原数量。 为每一个义原权重分配一个权重βj(如图1 中Entity-Attention 所示),从而计算实体的向量为
其中,βj被定义为
将每个实例中的实体进行如上计算,即可得到该实例的向量表示{ω1,ω2,…,ωn,Semh,Semt}。
对于每个关系类型,原型网络采用实例的平均向量作为关系原型。 但是,在现实世界中,每个关系类型的不同实例与该关系类型的相关性并不是一样的。 特别是在少样本场景中,由于缺少训练数据,一个实例的表示形式与其他实例的表示形式相差很远,这将导致相应原型的巨大偏差。 如果训练集中存在噪声数据,或者一种关系类型存在多种语义,这将会对结果的准确率产生非常大的影响。 为了解决上述问题,根据相关性的大小对输入的实例分配不同的权重,从而减少噪声的影响。 对于训练时支持集S中的每一个实例向量,为其分配一个权重αj(如图1 中Sentence-Attention 所示),从而计算原型向量的方法变为
其中,αj被定义为
其中,f(·) 为一个线性层,☉为将两个矩阵的对应元素进行相乘的操作,σ(·) 为一个激活函数,这里使用的是tanh(·) 函数保证计算的结果在[1,-1]范围内,sum{}用来对向量所有元素求和。 通过训练实例级的注意力机制,支持集中的实例特征与查询实例特征越相似,将获得更高的权重,最终计算的原型向量更接近这些实例。
2.5 算法实现
对于支持集输入的句子,首先将头实体和尾实体输入HowNet 网络,解析得到不同的义原,然后将得到的义原和实例输入CLUE-BERT 模块进行编码。 此时得到的输出包含实例和实体的编码,先使用算法1 计算出每个义原的权重,将权重与对应的向量相乘,得到代表该实体的向量表示;同理,使用算法2 进行权重计算,可以得到类型的向量表示;对查询集输入的句子,进行如上的计算得到一个向量表示;最后将两个向量使用欧几里德距离计算相似度。 由于交叉熵损失函数常应用于多分类任务中,因此训练过程中选择其作为目标函数,通过反向传播调整模型的权重,该损失函数表达式如下
其中,c为计算出的相似度,class为类别数。
算法1Entity-Attention 算法
算法2Sentence-Attention 算法
3 实验与结果分析
3.1 实验数据集
以Li 等[16]手动标注的数据集FinRE 为基础,重新构建了支持少样本学习的中文数据集。 该数据集一共有44 种关系,其中30 种关系用来训练,14种关系用来测试和验证。 为保证实验结果的准确性,在测试集中出现的关系类型,不会被划分到训练集中。 为了验证基于注意力机制的原型网络的有效性,在数据集中人工地添加0%、10%、30%、50%的噪声数据,这些数据在训练时将会被当成正确的数据进行训练。
3.2 参数设置
实验中所有的参数设置如表1 所示,对于训练文本中的每个实例,单词数量大于40 的,截取前40 个,不足的则以“[PAD]”填充。 对于词嵌入,使用CLUE-BERT 预训练好的轻量级模型对输入的文本序列进行编码,该模型包含35 kB 的中文词汇,输入词向量的维度为312,设置原始原型网络的迭代次数为30 000 次。 所有模型都在训练集上进行训练,然后选择在验证集上表现最佳的模型在测试集上进行测试。
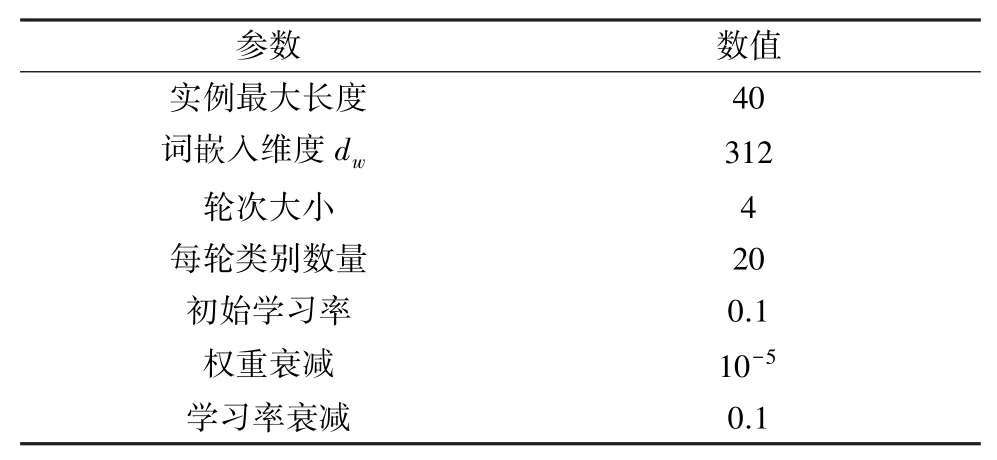
表1 参数设置
3.3 结果分析
为了证明基于实例级注意力机制的小样本关系抽取方法对抗噪声的有效性,通过计算该模型对关系实例抽取的准确率来评测模型的效果,结果如表2 所示,分别是在0%、20%、30%、50%的噪声数据下,使用原始的原型网络(Proto)和基于注意力机制的原型网络(Proto-att)得到的关系抽取的准确率。 可以看出,在少样本关系抽取中,随着关系类别的增加,准确率会随之下降;随着每个关系类别的实例增多,准确率会上升,但并不是无限上升,当达到某一个水平时,上升速率趋近饱和,增加实例的数量对准确率的提升不再有明显优势。 与原型网络相比较,当存在噪声数据时,基于双重注意力机制的原型网络会有更好的性能表现。
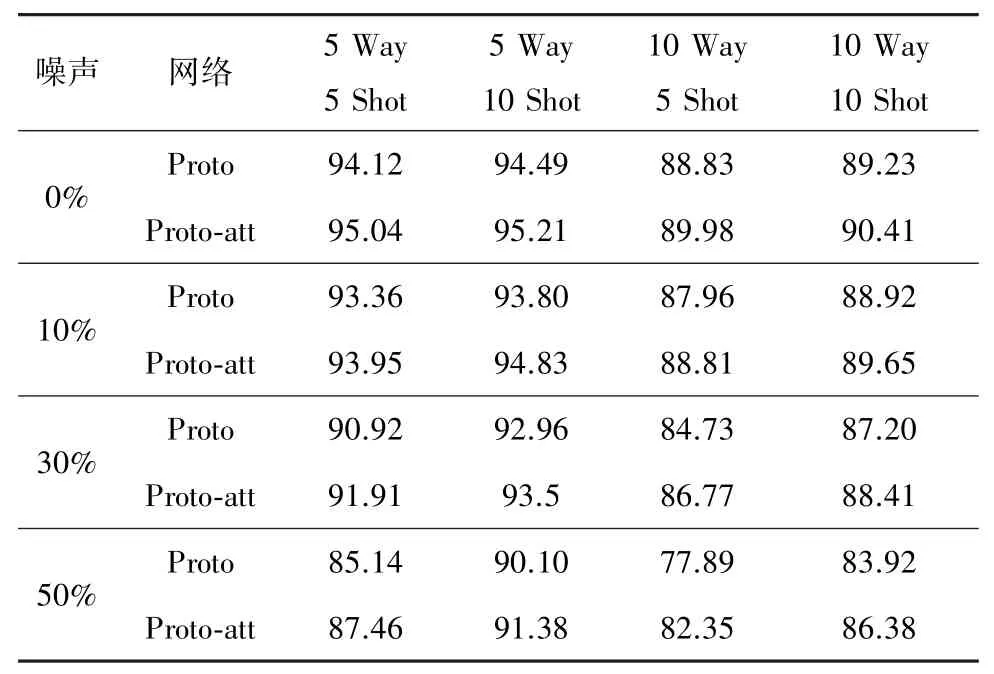
表2 关系抽取准确度比较 %
表3 是基于HowNet 的双重注意力机制的小样本关系抽取模型与其他模型,在没有添加噪声数据情况下抽取准确率的对比,实验证明了基于HowNet的双重注意力机制的小样本关系抽取模型在抽取准确率方面相较于其他模型有一定的提升,使用的基线模型如下:
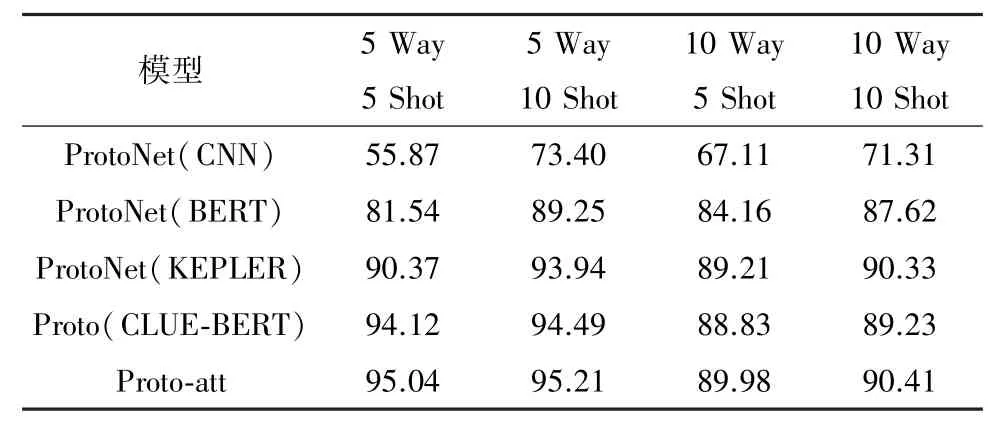
表3 各模型在FinRE 数据集上准确率对比 %
(1) ProtoNet(CNN)[22]是利用卷积神经网络作为编码器,将非线性地映射到向量空间,最后衡量欧式距离做分类。
(2) ProtoNet(BERT)是利用Google 发布的原生预训练语言模型BERT,将整个句子编码到统一的语义空间中,利用预训练的优势能极大提升训练的效率。
(3) ProtoNet(KEPLER)利用了Wang 等[28]在预训练语言模型的基础上,结合知识图谱将知识嵌入到预训练语言模型中,在预训练过程中对整个语言模型进行优化。
(4) Proto(CLUE-BERT)利用了Xu 等[19]在BERT 的基础上对预训练语言模型的改进,使用了大量的中文语料库进行训练,在中文的语言建模、预训练或生成型任务等方面具有优秀的表现。
4 结束语
本文重新构建了中文关系抽取数据集FinRE,使之适合于少样本关系抽取。 使用CLUE-BERT 对中文文本进行编码,并引入了HowNet 语义网络,使用双重注意力机制的原型网络模型对该数据集进行了评估实验。 在数据集中掺杂不同比例的噪声数据,实验结果表明,基于注意力机制的原型网络有更好的效果以及鲁棒性。
