基于深度学习的智能产品说明AI客服设计
2023-09-20秦沛聪潘威华通信作者石宝源
秦沛聪,潘威华(通信作者),石宝源,钟 健,刘 鑫
(1 广州理工学院 计算机科学与工程学院 广东 广州 510540) (2 广州方硅信息技术有限公司 广东 广州 510032) (3 深圳雷霆信息技术有限公司 广东 深圳 518054)
0 引言
随着现代生活节奏的加快,人们面临着越来越多的功能复杂的产品。为了更好地理解这些产品,产品说明书和对说明书的解答变得越来越必要。基于深度学习的智能产品说明人工智能(artificial intelligence,AI)客服是一套关于产品说明书的自动化AI客服系统,可以帮助大众解决产品说明书中的问题。该系统采用友好的图形系统、深度学习和语言规则生成系统,实现了面向大众的智能问答客服。与市面上大多数AI客服系统不同的是,基于深度学习的智能产品说明AI客服不仅面向开发者,也适用于非互联网企业,使用成本相对较低。因此,基于深度学习的智能产品说明AI客服应时而生,成为帮助消费者更好地理解产品的有效工具。
1 研究现状
AI客服是一种基于人工智能技术的客服系统,它可以智能化地处理用户的问题并提供满意的解决方案。目前,AI客服系统已经成为越来越多企业的必备工具。自然语言处理技术是AI客服的关键技术。近年来,自然语言处理技术取得了长足的进步,如能够识别多种语言的机器翻译技术、语音识别技术等,这使得AI客服系统的语音和文字处理能力得到了大幅提升。
1.1 国外研究现状
近些年来,国外的研究者们凭借深度学习、自然语言处理等技术,在对话设计及自然语言处理领域取得了一系列的研究成果[1]。其中首推谷歌的智能助手Google Assistant、苹果的Siri和亚马逊的Alexa。这些系统基于自然语言处理技术、深度学习模型和智能推荐技术等,能够有效地处理用户问题并提供个性化的建议和服务。同时,国外的研究机构和企业也在探索如何实现更加自然、流畅的语音交互和多模态交互,在AI客服领域展现出了极高的创新能力。AI客服系统必须能够像人类一样基于语音和文字进行交互,并且在交互过程中能够准确把握用户的需要,进行高质量、智能化的响应。国外学者们在语种识别、机器翻译、人工智能跨语言交流等方面做了大量的探索,为AI客服系统在跨语言和跨文化领域的应用提供了广阔的空间。
1.2 国内研究现状
国内对AI客服的研究也紧跟发展,多家大型企业和研究机构都开展了相关研究,如百度宣布推出AI客服“度小美”,使用深度学习和自然语言处理技术,提供自然语言交互,能够识别语音和文字输入,快速响应客户问题;阿里巴巴旗下的AI客服机器人“阿里小蜜”也获得了广泛的应用和好评,它可以根据用户的语音和输入分析问题,提供精准的解答和服务。这些AI客服系统的问答能力、智能化程度和用户体验等方面均得到了广泛的认可和好评,大幅提升了服务效率和用户满意度。此外,国内的一些科研机构和企业也在AI客服领域取得了一些重要的研究成果。例如,中国科学院计算技术研究所推出的“中科声韵AI客服”利用语音识别、自然语言处理等技术自动回答顾客问题,并不断学习用户喜好、实现更智能的服务;深圳市联合创新研究院还推出了“联想智客”AI客服系统,该系统可以对话聊天、语音识别、文字处理等方面达到较高水平,为客户提供个性化、智能化的服务。
2 产品说明AI客服应用优势
产品说明AI客服是人工智能技术在客户服务领域的应用,它是一种基于人工智能技术的新型客服服务形态,可以通过自然语言处理、语音识别、机器学习等技术,模拟人类进行沟通和交流,为客户提供高效、便捷、个性化的服务。相较于传统的人工客服,产品说明AI客服具有以下优势。
(1)提高服务效率:AI客服应用可以实现24 h不间断的服务,不受地域和时间限制,从而大大提高了服务效率和响应速度。可以快速处理大量相似的问题,让客户更快速地得到满意的回答。
(2)降低运营成本:采用AI客服可以极大地降低企业的客服成本。AI客服只需要一定的初期投入和后期维护费用,为企业节省了大量人力资源。
(3)实现个性化服务:AI客服可以根据用户上传的文档生成专属客服,通过学习和分析用户的交互记录,不断优化自身,提高服务质量。
(4)便捷性:AI客服通过语音识别和自然语言处理技术实现了与用户的自然交互,无需用户下载APP或登录网站即可获取所需的服务。
综上所述,产品说明AI客服具有较多的优势。因此,越来越多的企业正开始花大量资金和人力将AI客服技术应用于客户服务领域。未来,随着人工智能技术不断进步,AI客服技术将会取得更加广泛的应用和发展[2]。
3 技术简介与架构设计
3.1 技术简介概要
本系统通过采用Spring Boot框架和Mybatis框架进行开发,为WEB管理端、微信小程序和APP提供后台服务。基于项目的需求,使用nginx作为高效的中转服务器,采用AlibabaDruid作为为数据库的连接池管理链接,使用Redis作为系统日志系统以及高效缓存的中间件。除此之外,在MVC分层思想下,使用wepy通过数据调用,设计视图,实现微信小程序前端和使用Vue实现后台管理系统。
问题的问答主要分以下两个功能。
第一是通过规则生成问答:(1)通过jieba分词库将后台管理输入的产品说明书进行分词,根据词语权重分出问答;(2)再将每个词语摘出,通过说明书中问答的权重对词语进行重新排列组合形成问答句子;(3)最后使用已有的句子到互联网中进行知识爬取,再次获取到问答。
第二是通过深度学习生成问答:使用深度学习库Keras构造Char-RNN模型和深度学习库Pytorch构造seq2seq模型同时进行对抗训练,不断重构loss,训练数据来源后台管理输入的产品说明书和用户在使用过程中产生的一系列非结构化数据,例如查找记录、页面停留时长等信息。最后通过两个模型的对抗预测生成问答。
通过使用规则和深度学习生成的问答做递归预测,以确保数据的准确。同时使用Elasticsearch 作为QA的搜索引擎,生成的问答将会存入到Elasticsearch数据库中 ,系统也会提问的问题在Elasticsearch在进行全文的检索,以便快速准备的返回搜索结果。
3.2 深度学习端技术架构
深度学习端使用“TensorFlow+Keras+Pytorch+Pandas”架构关系,通过利用现有深度学习框架的特点,创新性地实现了在seq2seq模型下的静态图模型和动态图模型做对抗训练,重构loss,极大提高准确性。同时初始化时每一个文档都同时生成一个基于TensorFlow的静态图seq2seq模型和基于Pytorch的seq2seq动态图模型,当两个模型生成完成后,使用Pandas进行数据处理,得出模型对抗训练的数据。调起两端模型预测,将预测结果再导入Keras进行训练,从而重构loss生成第三个seq2seq模型,深度学习技术架构如图1所示。
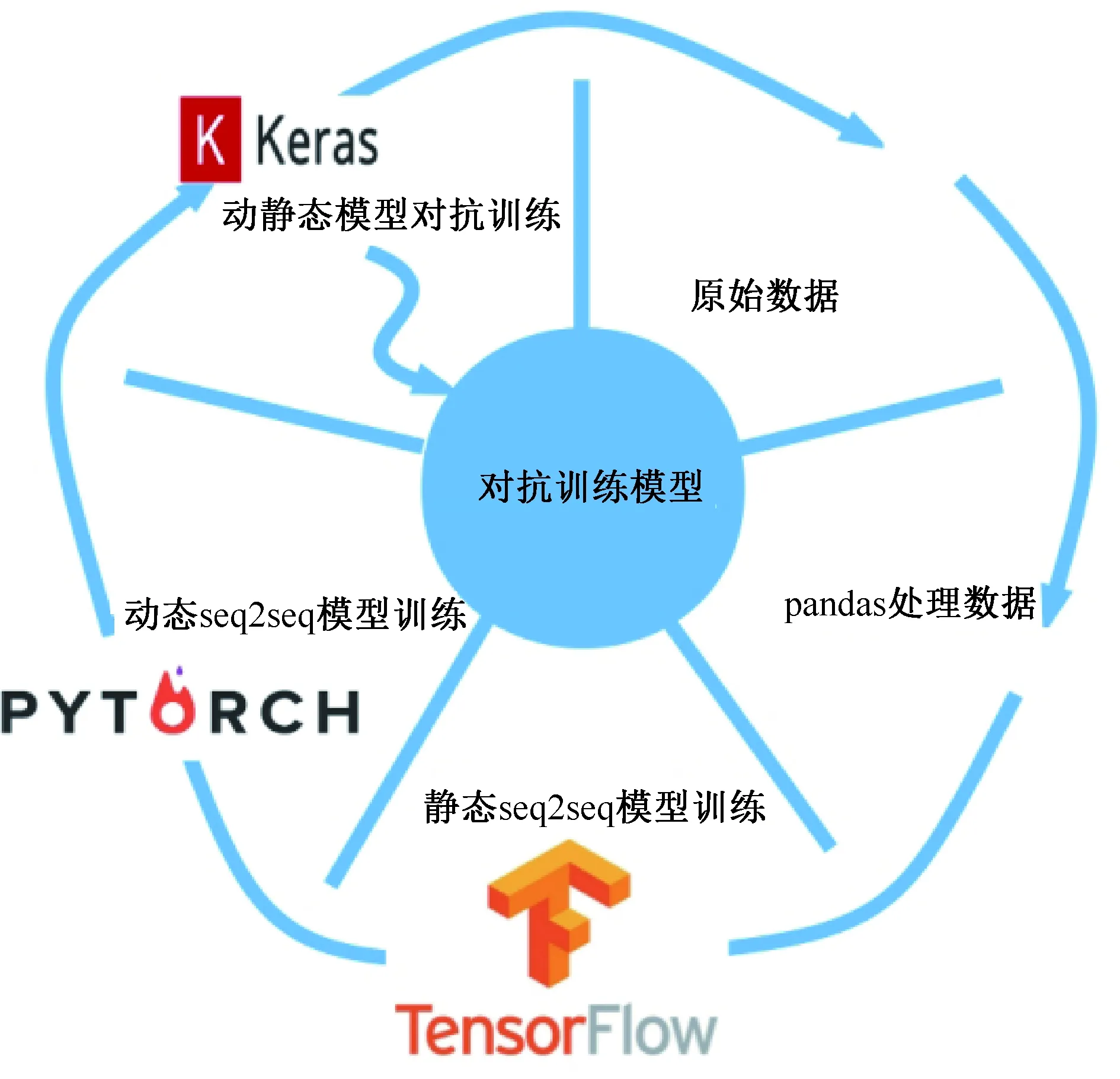
图1 深度学习技术架构图
3.3 用户端技术架构
客户端使用“React Native + wepy + Vue.js”,APP开发使用React Native作为跨平台开发,微信小程序使用wepy作为组件化开发,后台管理客户端使用Vue.js开发,用户端技术架构如图2所示。
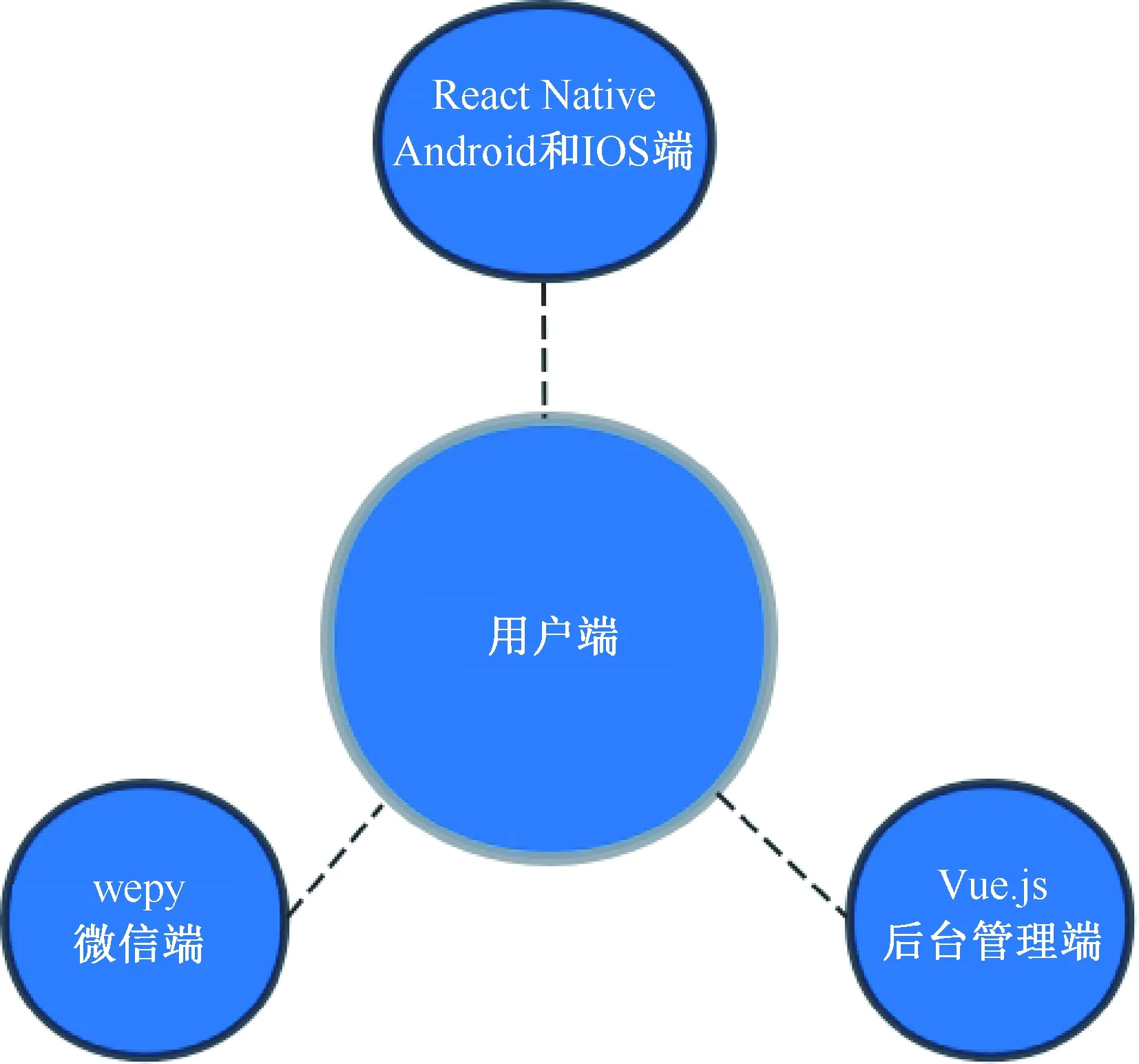
图2 用户端技术架构图
3.4 服务端技术架构
服务端使用“Spring boot + MyBatis”架构,关系数据库采用MySql数据库,数据库ORM映射中间件使用MyBatis,Redis 提供高效日志、缓存以及搜索服务,RabbitMQ作为消息队列持久性服务,MongoDB负责记录用户产生的非结构化数据,同步产品文档信息。客户端调用接口均遵循REST API接口规范,通信协议使用HTTP,服务端技术架构如图3所示。
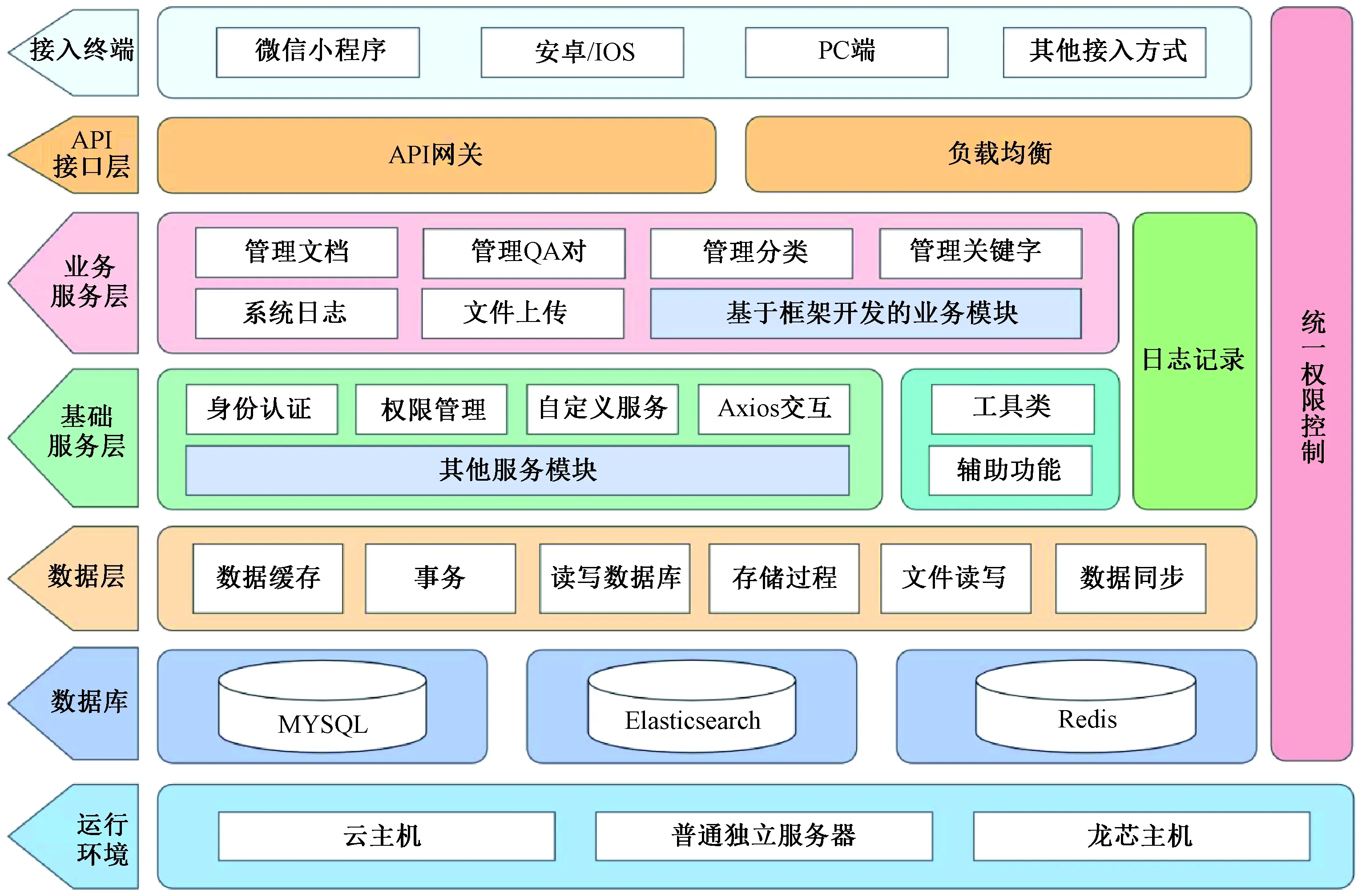
图3 服务端技术架构图
整个系统应用划分为四个相对分离的逻辑层,每一层都是相互独立的。
3.4.1 API接口层
服务端第一层为API接口层,该层提供了提供API网关和负载均衡两个功能。API网关通过对外暴露API接口,提供前端需求的请求接口,对后端服务的统一管理和保护;负载均衡通过对请求进行分发,超时服务中断,将请求压力分散到多个服务容器上,提高系统的稳定性。
在API接口层中,服务端提供前端的请求接口,用户进行操作使得前端对服务端发送请求,这些请求会首先进入nginx流量网关,nginx会对请求进行筛选,随后将通过筛选过滤的请求转发到gateway业务网关,对请求做统一的处理,其中包括了统一认证,统一鉴权,请求限流,最后经由注册中心,直到目标服务完成路由转发。该层中的负载均衡,采用CDN来做负载均衡,通过发布机制将内容同步到大量的缓存节点,并在DNS服务器上进行扩展,找到离用户最近的缓存节点作为服务提供节点。出于性价比,可靠性,稳定性的考虑,该系统选择阿里云的CDN服务实现。
3.4.2 业务服务层
服务端第二层为业务服务层,该层是整个系统中实现具体业务逻辑的核心部分,包含了Web后台管理系统、分类管理、文档管理、QA对管理、关键字管理、文档上传等管理功能,以及基于框架开发的业务模块。
Web后台管理系统通过模板渲染实现后台管理功能,对系统进行维护和管理;分类、文档、关键字等管理功能则提供了对数据的管理和查询;QA对管理则提供了对问题和答案的管理和校对。其中,系统核心功能是基于深度学习生成QA对服务,该功能在第四节进行详述。
3.4.3 基础服务层
服务端第三层为基础服务层,该层的基础服务能够辅助构建系统,提供开发使用的工具类,实现业务逻辑和基础服务的解耦,提高功能的拓展性和重用性。
在基础服务层中,服务端封装了研发人员和其他层需要用到的工具类和服务,如:API接口层中API网关中的身份认证、权限管理服务、基于Axios的REST API接口服务;业务服务层中文档上传工具类,基础增删改查数据服务类;数据层中访问不同数据库的工具类;以及自定义服务类和工具类:等等。
3.4.4 数据层
服务端第四层为数据层,该层通过Dao持久层间接存储数据和访问数据库,系统采用了MySQL、Elasticsearch和Redis三种数据库来支持数据的处理和存储。
Redis数据库用于保存用户登录状态,用户登录后,提高用户体验和安全性。具体实现流程:用户登录时,前端携带用户信息请求登录接口,服务器端将Token存进Redis并返回给用户Token,客户端携带token后端查询Redis是否存在,实现单点登录。
MySQL数据库作为系统主要的数据存储方式,通过使用ORM对象关系映射进行面向对象的调用而不直接SQL语句,保障代码的可读性,同时避免SQL注入等风险[3],为系统的基础数据存储和管理做保障。
Elasticsearch主要用于文本数据的全文搜索、聚合分析、实时查询等场景,支持对大量的非结构化或半结构化数据的索引、搜索和分析。系统可以将基于深度学习生成的问答QA对以json格式存储在Elasticsearch数据库中,并对用户输入的提问,在Elasticsearch库中进行全文索引。
4 核心功能问答生成原理
设计原理概述:将已经有的产品说明书作为数据基础,通过规则生成和深度学习生成,实现AI问答数据。
实现目的:实现尽可能准确的回答和尽可能多的回答。能够回答出导入说明书所没有的答案。
自然语言处理规则生成原理:
(1)文档结构树,主题/段落/语句分割。
(2)实体提取、关键词提取、语义特征提取。
(3)语句结构分析:同位语结构、动词修饰名词结构、句型分析。
(4)摘要提取、语句压缩和融合。
(5)问题模式分类。
(6)问题生成(语义模板法、ML生成法、深度学习)。
(7)问句泛化:关键词替换。
(8)句法转化:WH移动、主谓倒置等将陈述句转换为问句。
(9)问题语义完成度分析。
深度学习生成原理:
(1)构建基于TensorFlow的循环神经网络,训练seq2seq模型,生成静态图模型。
(2)构建基于Pytorch的循环神经网络,训练seq2seq模型,生成动态图模型。
(3)在开发过程中,创新地探索出:利用静态图和动态图各自的特点,使用静态图模型和动态图模型做对抗预测,过程中不断重构loss,效果准确率极高,但对抗训练消耗时间稍长。
该系统设计参考了ApplyingDeepLearningToAnswerSelection:AStudyAndAnOpenTask的论文[4],从文中论述的网络结构中,选择了效果相对较好的其中一个来实现,网络描述如图4所示。
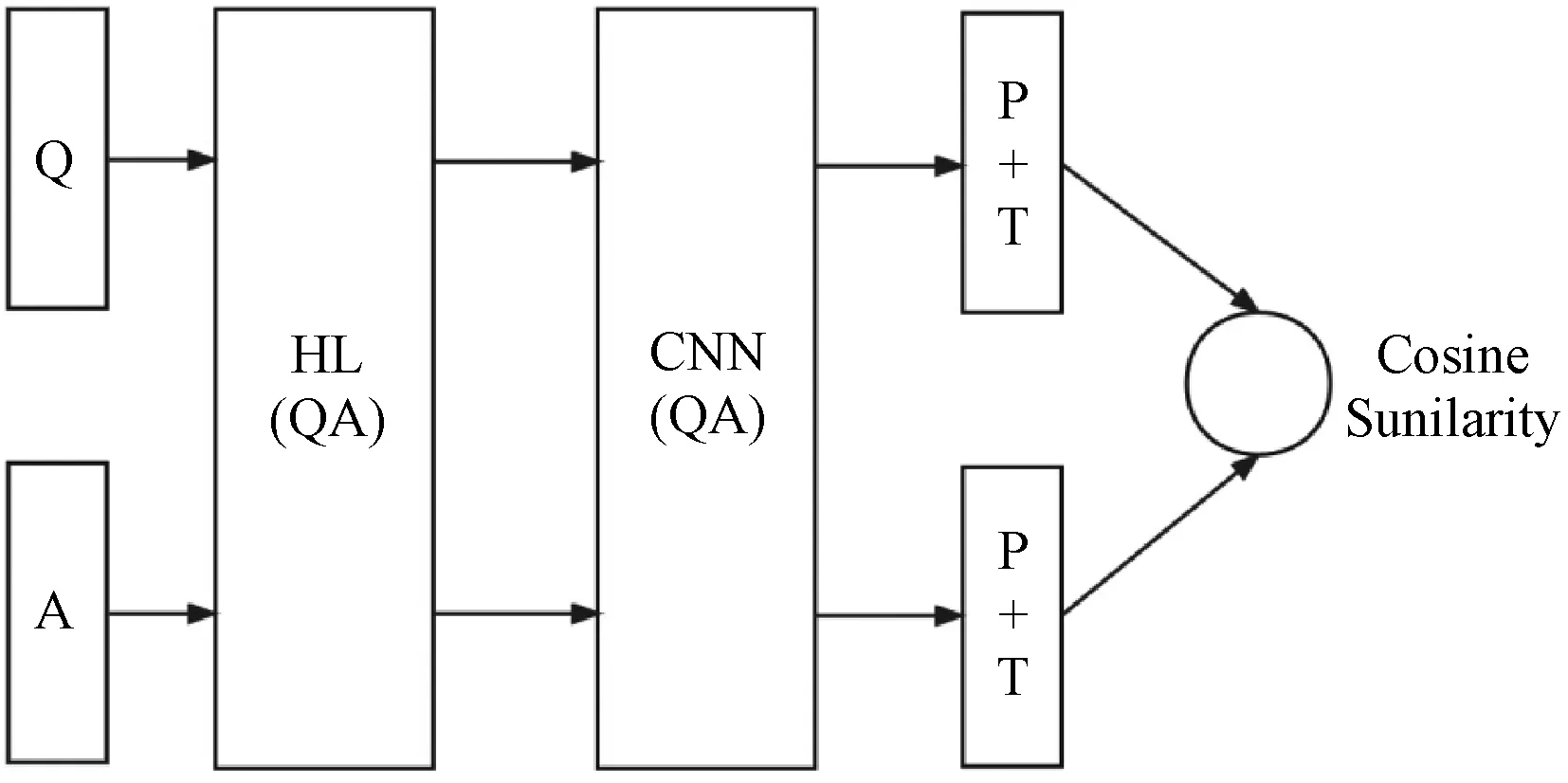
图4 网络描述图
图4的逻辑描述如下。
Q&A:共用一个网络,网络中包括HL,CNN,P+T和Cosine_Similarity,HL是一个g(W*X+b)的非线性变换,CNN是卷积神经网络,P是max_pooling,T是激活函数Tanh,最后的Cosine_Similarity表示将Q&A输出的语义表示向量进行相似度计算。
详细描述下从输入到输出的矩阵变换过程:
Qp:[batch_size, sequence_len],Qp是Q之前的一个表示(在上图中没有画出)。所有句子需要截断或padding到一个固定长度(因为后面的CNN一般是处理固定长度的矩阵),例如句子包含3个字ABC,选择固定长度sequence_len为100,则需要将这个句子padding成ABC...(100个字),其中的就是添加的专门用于padding的无意义的符号。训练时都是做mini-batch的,所以这里是一个batch_size行的矩阵,每行是一个句子。
Q:[batch_size, sequence_len, embedding_size]。句子中的每个字都需要转换成对应的字向量,字向量的维度大小是embedding_size,这样Qp就从一个2维的矩阵变成了3维的Q
HL层输出:[batch_size, embedding_size, hl_size]。HL层:[embedding_size, hl_size],Q中的每个句子会通过和HL层的点积进行变换,相当于将每个字的字向量从embedding_size大小变换到hl_size大小。
CNN+P+T输出:[batch_size, num_filters_total]。CNN的filter大小是[filter_size, hl_size],列大小是hl_size,这个和字向量的大小是一样的,所以对每个句子而言,每个filter出来的结果是一个列向量(而不是矩阵),列向量再取max-pooling就变成了一个数字,每个filter输出一个数字,num_filters_total个filter出来的结果当然就是[num_filters_total]大小的向量,这样就得到了一个句子的语义表示向量。T就是在输出结果上加上Tanh激活函数[5]。
Cosine_Similarity:[batch_size]。最后的一层并不是通常的分类或者回归的方法,而是采用了计算两个向量(Q&A)夹角的方法[6]。如网络损失函数所示,m是需要设定的参数margin,VQ、VA+、VA-分别是问题、正向答案、负向答案对应的语义表示向量。损失函数的意义就是:让正向答案和问题之间的向量cosine值要大于负向答案和问题的向量cosine值[7],大多少,就是margin这个参数来定义的。cosine值越大,两个向量越相近,所以通俗地说这个Loss就是要让正向的答案和问题愈来愈相似,让负向的答案和问题越来越不相似。
网络损失函数:
L=max{0,m-cos(VQ,VA+)+cos(VQ,VA-)}
(1)
5 结语
总体而言,随着人工智能技术的不断发展,AI客服系统将会越来越广泛地应用于各行各业。基于深度学习的智能产品说明AI客服系统作为其中的一种创新型AI客服系统,其用途和价值也引起了广泛的关注。通过提供自动化的AI模型和深度学习技术,基于深度学习的智能产品说明AI客服系统在满足用户问答需求的同时,也减少了企业的人力和成本,实现了双赢的局面。此外,该系统的友好图形界面和面向大众的智能问答模式,也为许多用户带来了便利和快捷的体验。随着AI技术的不断进步,相信未来基于深度学习的智能产品说明AI客服系统将为更多企业提供更加高效、智能、易用的AI客服服务,推动企业发展和提升用户满意度。
