基于智能优化算法的自然语言语义相关度计算模型
2023-09-20行久红
行久红
(郑州科技学院大数据与人工智能学院 河南 郑州 450064)
0 引言
语义相关度在广义角度上分析,指的是两个词语之间的相关程度,能够从某种程度上反映词语之间的关联性[1]。通俗来说,即能够通过一个词语,联想到另外一个意思相近的词语[2]。传统的语义相关度多数采用布设语境的方式完成,在该语境下,计算并分析两个词语同时出现的可能性,进而根据计算分析结果衡量词语语义相关度[3]。此种计算衡量方式具有一定的弊端,容易将语义相关度与语义相似度混淆[4]。经过众多学者研究发现,语义相似度指的是两个不同词语之间存在的相似性,而语义相关度指的是两个不同词语之间的关联,具有显著差异[5]。根据以往学者的研究结论可以得知,若两个不同的词语语义相似,它们之间的语义也一定相关,反之,若词语语义相关,但是其语义不一定相似。通过该结论可以得出:语言语义相似度属于语义相关度计算的重要组成部分。科学合理的语义相关度计算方法至关重要,能够为现代化信息检索、海量文本分析、自然语言处理研究、自然语言机器翻译等领域提供有力的数据支持,属于一项基础性的研究工作。智能优化算法能够为语义相关度计算提供一定的帮助,通过简单信息处理单元的交互作用,求解分布式问题,收敛速度较快,在多设计变量方面应用优势显著。
基于此,为了提高自然语言语义相关度计算方法的可行性,优化相关度计算结果,本文引入智能优化算法,设计了一种全新的自然语言语义相关度计算模型。
1 自然语言语义相关度计算模型设计
1.1 选取自然语言文本编码器
本文设计的基于智能优化算法的自然语言语义相关度计算模型中,首先,需要根据自然语言文本的具体情况与特征,选取与之适配度较高的编码器,通过文本编码器,解决后续语义相关度计算模型训练收敛问题,激励模型的运行。综合考虑后,本文选取卷积神经网络(convolutional neural networks,CNN)文本编码器,包含了卷积计算的前馈神经网络,具有良好的性能优势。首先利用自然语言文本编码器,选择并创建一个完整的局部计算块,将其遍历在整个相关度计算网络中。其次将计算块包含的所有节点,添加到网络下层结点中,使用过滤器,扫描其他位置的输出节点,使各个节点的权重与偏移量共用。利用CNN编码器,构建自然语言文本矩阵,输入相应的数据信息,并陈列数据信息。在此基础上,使用一个8×8的卷积核,对文本图像进行卷积计算,获取其卷积特征,通过不同的通道(channels),匹配图像RGB颜色模型。抓取图像中的细小零件,组装成完整的图片信息。对自然语言文本进行向量化操作,提取语言文本中的重要语义信息。由于多数自然语言的文本长度为固定值,在语义信息提取时,可以对卷积核的宽度进行设定。施加不同权重的卷积核,在自然语言文本中滑动,尽量全面提取自然语言文本中的重要语义信息。最后添加maxpooling操作,减少CNN自然语言文本编码器的拟合,提高自然语言文本中语义信息提取的精度。
1.2 自然语言文本数据集处理与融合
完成自然语言文本编码器选取后,实现了自然语言文本中重要语义信息提取的目标。接下来,对等待计算语义相关度的自然语言文本数据集进行处理与融合,为后续语义相关度计算模型构建提供基础保障。
对自然语言文本数据集进行全方位的识别与分析,找出语义相关度计算模型可能无法识别的文字化信息。自然语言文本数据集处理主要包括三个部分,分别为自然语言文本停用词去除处理、自然语言文本归一化处理、自然语言文本向量化处理,需要特别注意,以上处理方式仅针对中文自然语言文本数据集,而英文自然语言文本数据集处理中,需要采用Jieba工具包,进行文本分词操作。
(1)自然语言文本数据集停用词去除处理。停用词主要包括文本数据集中的部分功能词,例如介词、连词等无任何实际意义的词语,还有词汇词,即使用极其广泛,但可有可无的词语。采用MATLAB软件,生成有针对性的停用词表,以智能化与自动化的过滤方式,过滤删除以上两类停用词,节省存储空间,提高自然语言文本数据集词语的搜索效率。
(2)自然语言文本数据集归一化处理。将数据集中存储格式不同的各个文本进行归一化处理,使文本长度保持一致,达到自然语言文本规定的长度。
(3)自然语言文本数据集向量化处理。将自然语言文本中的文字,经过词嵌入表的转换作用,转换为高维稠密向量,并将其作为输入层,输入到后续构建的语义相关度计算模型中。设定自然语言文本数据集向量为固定长度,该长度需要囊括大部分自然语言文本的长度,在此基础上,对各个文本的长度进行补充,初步向量化文本的内容,获得文本一维向量,生成自然语言文本词向量库。
完成自然语言文本数据集处理后,接下来,对文本数据集进行融合。将多个数据集进行一致化处理,统一其内容与特征,转换器处理格式,将数据集中海量不同类型的数据进行融合,进而扩大数据集。除了能够融合数据类型以外,还能够融合数据功能,逐步扩充完善自然语言文本数据集,提高数据集的泛化能力。设定自然语言文本数据集融合采用的编程语言为python,采用的工具包为pandas。将用户输入的自然语言文本数据集作为孪生网络模型的输入层,通过孪生网络模型,比对融合后的数据集文本特征,使自然语言文本数据集处理与融合的结果达到最优化目的。
1.3 基于智能优化算法构建自然语言语义相关度计算模型
基于上述自然语言文本数据集处理与融合完成后,实现了文本数据格式一致化的目标,为相关度计算模型构建提供了基础保障。在此基础上,利用智能优化算法,计算自然语言语义相关度,构建语义相关度计算模型。设计智能优化算法的运行流程,如图1所示。
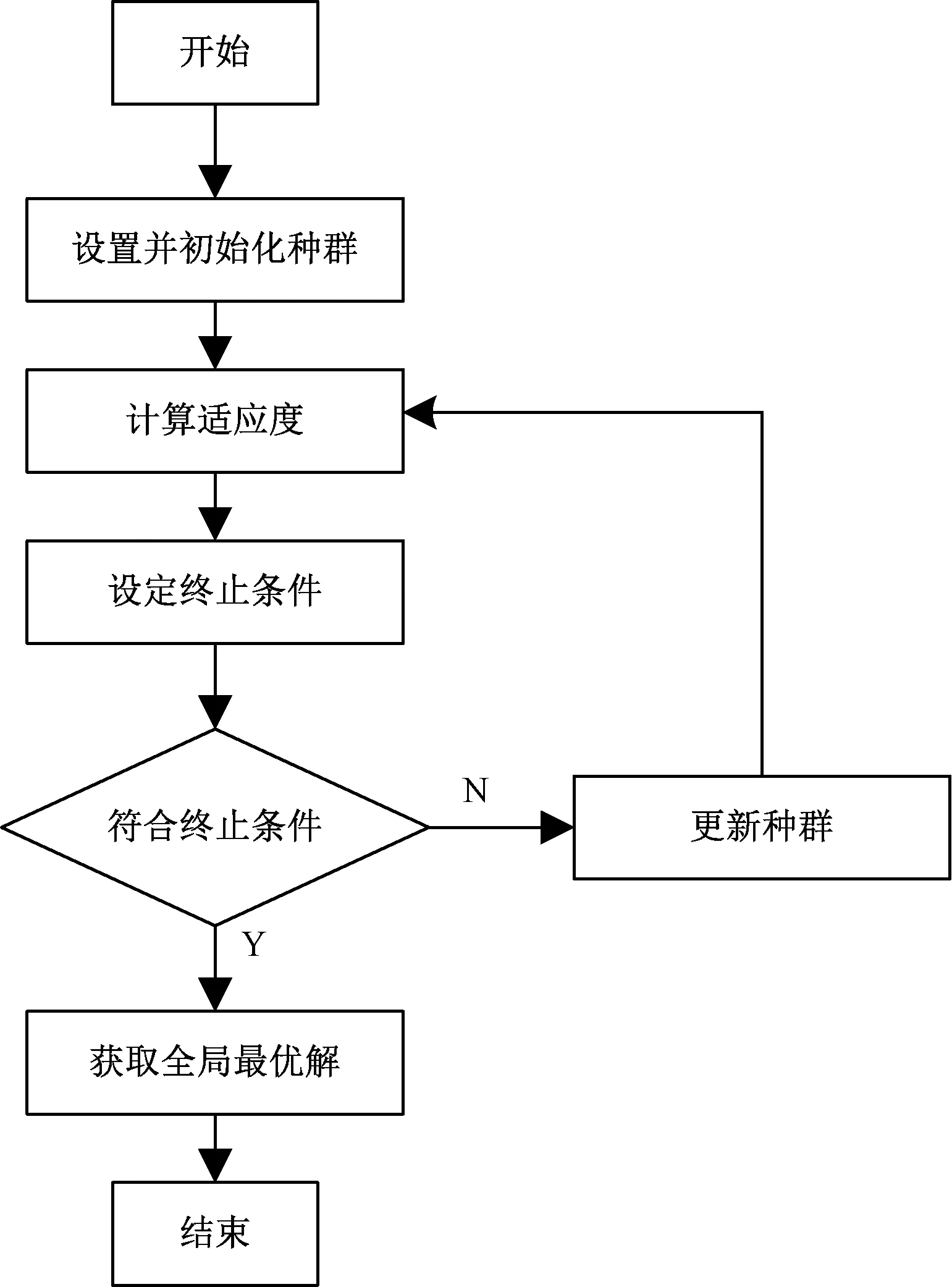
图1 智能优化算法运行流程
如图1所示,首先基于群体智能优化算法,设置并初始化自然语言文本种群。其次根据文本种群初始化结果,计算种群的适应度函数。设定智能优化算法的终止条件,将种群的适应度函数计算结果与设定的终止条件进行对比。若符合智能优化算法的终止条件,则输出智能优化算法的全局最优解;若不符合智能优化算法的终止条件,则更新种群,并删除原始解决方案,寻找另一个全新的解决方案,再次计算种群适应度,直至满足算法终止条件为止。通过智能优化算法的不断迭代,获取最终满意度良好的最优解,完成智能优化算法的整体流程。在此基础上,利用智能优化算法,寻找自然语言文本的义原最优解,根据文本义原的上下位关系,构建自然语言义原层次结构体系,利用语义相关度S表示。设定自然语言文本中2个义原在层次结构体系中的路径距离为d,其语义相关度计算表达式为:
S(p1,p2)=δ/(d+δ)
(1)
其中,p1、p2分别表示自然语言文本中的两个义原;δ表示语义相关度计算中的一个可调节参数。通过计算,得出文本语义相似度。根据语义相关度,将自然语言文本中义原的重要性进行分类,分类结果如表1所示。

表1 自然语言义原分类
由表1可知,本文设计的自然语言义原分类结果,将分类结果的4个义原值进行线性叠加,得出2个自然语言词语M1、M2的整体相关度,计算表达式为:
(2)
其中,β表示相关度计算模型的可调节参数。通过计算表达式,得出自然文本义原的综合相关度结果,使其文本相关度依次递减,全面提高自然语言语义相关度计算结果的精度,完成相关度计算模型设计的目的。
2 实验分析
2.1 实验准备
上述内容,便是本文利用智能优化算法,设计的自然语言语义相关度计算模型的全部流程。在此基础上,进行了如下文所示的实验分析,检验提出计算模型的可行性与应用效果,避免直接投入使用后存在异常,降低相关度计算结果的精确度。此次实验以自然语言领域本体作为实验数据,该领域本体是结合自然语言研究指南对语言的权威说明,通过protege生成的。在实验开始前,选取实验所需的工具,搭建实验测试环境。本次实验所需的工具及说明,如表2所示。

表2 实验工具及说明
使用ThinkServer rd430服务器,搭建此次实验测试的OpenStack环境。设置服务器的内存为64 G DDR3;硬盘为2.8 T RAIDO;系统为Ubuntu 16.04LTS;网卡为1个万兆网卡,3个千兆网卡;开发平台为Tensorflow框架;开发语言为Python3.6;字向量训练工具为Word2vec。对自然语言本体概念数据集进行全方位的存储管理,通过Jena接口的解析功能,解析自然语言本体数据。利用自然语言信息内容、语言属性与语义距离等因素,分别计算自然语言领域中概念对之间的语义相关度。由于自然语言网页文本较长,数量较多,为了避免影响实验结果的准确性,本文将所有语言词语对划分为了10组,避免实验结果存在偶然性。
2.2 结果分析
为了提高实验结果的说服性,在实验中,引入对比分析的方法原理,将上述本文提出的基于智能优化算法的自然语言语义相关度计算模型设置为实验组,将黄承宁等[2]1152提出的基于深度学习表示的相关度计算方法、薛毅等[3]112-113提出的基于卷积神经网络的相关度计算方法分别设置为对照组1与对照组2,分别对3种方法的应用效果作出检验。选取斯皮尔曼相关系数作为此次实验的评价指标,在广义角度上指的是语言语义相关度等级变量之间的皮尔逊相关系数,其数值越大,表示语言语义相关度计算结果精度越高,方法的有效性越高。评价指标计算表达式为:
(3)
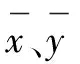
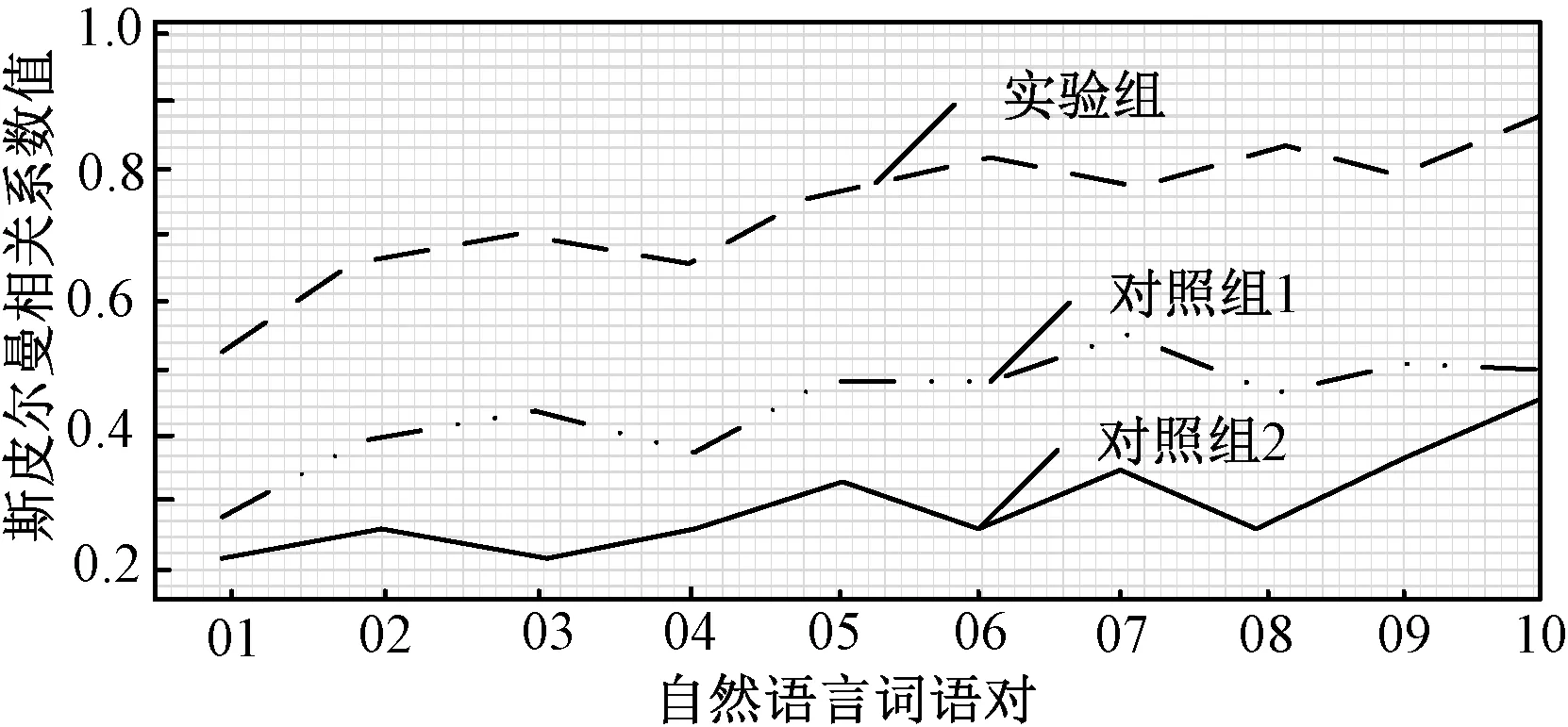
图2 实验评价指标对比示意图
图2中,01表示rooster-voyage自然语言词语对;02表示noon-string自然语言词语对;03表示glass-magician自然语言词语对;04表示forest-graveyard自然语言词语对;05表示asylum-madhouse自然语言词语对;06表示furnace -stove自然语言词语对;07表示magician-wizard自然语言词语对;08表示journey-voyage自然语言词语对;09表示cemetery-woodland自然语言词语对;10表示shore woodland自然语言词语对。通过图1的评价指标对比结果可以看出,本文提出的基于智能优化算法的自然语言语义相关度计算模型应用后,较另外两种方法相比,各组自然语言词语对的斯皮尔曼相关系数值均较高,表明其语义相关度计算结果更加精确,提出计算模型的有效性与可行性均较高,可以投入大规模使用。
3 结语
综上所述,为了改善传统自然语言语义相关度计算模型在实际应用过程中,计算结果精度较低、计算流程复杂的问题。本文在传统相关度计算模型的基础上,引入智能优化算法,作出了改进设计。通过研究,充分地利用了网络资源,提高了语言语义相关度计算结果的精度,在自然语言文本聚类、分类方面优势显著。提出计算模型的实用性较强,能够应用于自然语言释义识别任务中,结合义项向量使用,提取更深层次的语义特征,进而形成完整的文本语义特征向量,性能表现良好,计算精度与效率较高,具有良好的应用前景。
