基于图表示学习的领域知识图谱推理技术研究
2023-09-18隋国华李陶然
隋国华,李陶然,刘 昊,陈 林,汪 卫
(1.中国石油化工股份有限公司 胜利油田分公司物探研究院,山东 东营 257022;2.复旦大学 计算机科学技术学院,上海 200438)
0 概述
知识图谱作为符号主义发展的产物,被认为是许多人工智能系统的重要组成部分[1]。知识图谱的本质是由蕴藏在图片、文本、音频、数据库中的海量知识组成的大规模异构语义网络,其使用实体与关系进行知识表示,并通过三元组或图数据结构的形式进行存储[2]。知识图谱的概念一经提出就受到商业和学术界的广泛关注,也因此诞生了许多具有代表性的知识图谱,如百科类通用知识图(Freebase、DBpedia、YAGO 等)、概念图谱(Probase IsA)以及领域特定知识图谱(GeoNames 等)[3]。在医学方面,生物医学发展至今已经具备了一套完善的知识体系,包括且不限于药物、基因、疾病、蛋白、通路等实体及其之间的相互关系,也随之诞生了一些较为有名的医疗数据集,如DrugBank[4]、Yamanishi_08[5]、Chem2Bio2RDF[6]等。知识图谱的概念被提出后,这些数据集也陆续被转变为对应的领域知识图谱,并应用于各类医学图谱的研究中。
文献[3]介绍了知识图谱的研究方向。知识图谱天然具备不完整性,这主要是由于图谱中的知识一般都是通过规则或深度学习模型从结构化与非结构化的原始数据中自动抽取而来,原始数据的信息缺失、规则的不完备以及模型的错误预测都会导致最终知识的缺失。此外,现实世界中的知识会随着时间不断变化,新知识不断产生的同时已有的部分知识也会失效。以上两点原因使得封闭世界假设在知识图谱上不再成立[2],因此,近五年来,知识图谱补全(Knowledge Graph Completion,KGC)与关系预测(Relation Prediction,RP)成为图谱研究的热点分支。上述两者本质上都是基于已知的事实或知识推断得出隐藏事实或知识的过程[7],因此,可以将它们归为知识图谱推理。然而,在领域知识图谱的推理方面,现有的主流推理模型多数是针对缺失信息的百科知识图谱迁移而来,在领域知识图谱上的应用具有很大的局限性。例如,百科图谱的实体类别缺失迫使相关研究采用同构的处理方式,这必然会导致语义信息的丢失进而影响推理性能。而领域知识图谱存储的知识往往较为完备,针对领域图谱的模型研究应当利用其异构性。此外,现有的推理模型仅考虑图谱本身包含的信息,通过统计的方法学习其中蕴含的特征,忽略了人为定义的先验规则在推理任务中能提供的帮助。领域知识图谱往往包含更多的领域相关语义信息,如何将领域知识作为先验知识来指导模型推理同样值得研究。
本文以医学领域知识图谱为例,分析领域图谱区别于百科图谱的显著特点,提出一种基于翻译的TransSep 模型,通过为不同类别的节点分配特定的独立表示空间来提升模型的表达能力。同时,考虑到现有研究大多忽略了关系预测与三元组分类2 个推理任务之间的关联性,提出一种将两者联合训练、迭代负采样的训练策略,从而提高关系预测与三元组分类的效果。在此基础上,基于元路径(meta-path)的思想将领域知识融合到知识推理的过程中,进一步提高模型的推理性能。
1 相关工作
知识图谱表示学习是知识图谱研究中非常重要的一个领域,其主要任务是学习图谱中实体与关系的一种低维度表示,并将其应用到各类下游任务中。目前表示学习的相关工作主要分为以下几种:
1)基于翻译的知识图谱表示学习。
TransE[8]是知识图谱表示学习的经典模型,它基于翻译的思想,将关系建模为头实体到尾实体的翻译,即对于一个三元组,如果头实体向量加上关系向量与尾实体向量距离越近,则该三元组的得分越高。后来的许多研究均参考翻译距离的思想,并针对不足之处进行了改进,如:TransR[9]将实体与关系嵌入到2 个不同的向量空间,以解决实体与关系共用同一个嵌入空间的局限性;TransH[10]将实体与关系映射到一个超平面,以更好地拟合一对多、多对多等复杂关系。
2)基于相似度的知识图谱表示学习。
TransF[11]将翻译距离改为翻译相似度,使用向量点积进行衡量。基于语义相似度思想的模型DistMult[12]将TransE[8]中的加法距离改为乘法 距离,其受益于交换律,在对称关系较多的图谱中表现出了更好的性能。
3)基于神经网络的知识图谱表示学习。
NTN 模型[13]先利用多层感知机对原始向量进行转换,再与关系向量进行双线性变换,以此来提高模型的特征枚举空间;ConvE[14]使用卷积神经网络层来学习实体与关系之间的深层特征关系。
4)基于随机游走的知识图谱表示学习。
近几年,基于随机游走的模型(如DeepWalk[15]、Node2vec[16]等)也受到了广泛的关注与研究。通过假设“图中距离相近的节点应具有相似特征”,以图谱中的每一个实体作为起点,通过随机访问邻居节点得到随机游走序列,使用自然语言处理(Natural Language Processing,NLP)领域的词向量嵌入模型来预训练实体的嵌入表示。虽然随机游走模型在一些实体相关的下游任务中能取得较好的表现,但是实体之间的关系往往远比NLP 领域中词与词之间的前后文关系更复杂。随机游走完全抛弃了实体的类型信息以及关系类型信息,较难被应用于关系预测、子图预测等任务中。在此基础上,文献[17]针对异构信息网络中相似性搜索任务提出了元路径的概念,文献[18]通过预定义的元路径来指导随机游走序列生成策略,提出Metapath2vec/Metapath2vec++的随机游走改进模型。
5)基于图卷积网络的知识图谱表示学习。
受到卷积神经网络在计算机视觉领域良好表现的启发,图神经网络模型旨在通过类似卷积操作的GNN 层,使每一个实体聚合周边邻居实体的特征[19]。目前,被广泛使用的图神经网络可以分为基于频域特征的图卷积神经网络(Graph Convolution Neural Network,GCN)与基于空域特征的图注意力神经网 络(Graph Attention Neural Network,GAT)两大类[20]。GCN[21]基于图信号处理理论设计了图卷积层,利用邻接矩阵的拉普拉斯变换来聚合邻居节点的信息。GAT[22]通过在图神经网络中引入注意力层,让模型自动学习邻居实体对于中心实体的重要程度,越重要的邻居特征越容易被聚合。
不同的知识图谱表示学习推理模型虽然在表示空间、关系映射方式、三元组得分函数定义上各有不同,但是这些模型几乎都具有一个相同的特点,即将所有实体都嵌入到一个相同的表示空间中。在面对实体类别完备的领域知识图谱时,这种做法会在一定程度上造成类别信息损失,进而影响模型的学习能力。
2 模型设计
本文提出一种基于翻译的推理模型TransSep,该模型针对领域知识图谱而设计,模型通过为不同类别的实体建立各自独立的向量空间,有效处理图谱的异构性,同时使用交替迭代负采样的训练策略,通过关系预测与三元组分类2 个任务对模型进行联合训练,最后将领域知识通过元路径引入TransSep。本文模型框架如图1 所示。

图1 TransSep 模型框架Fig.1 Framework of TransSep model
2.1 实体表示空间与映射翻译距离
2.1.1 领域知识图谱的特点
以医学领域知识图谱为例,精准医学知识图谱本体图如图2 所示,图中数字为对应的实体数量。该图谱与百科知识图谱的不同之处主要体现在如下4 个方面:

图2 精准医学知识图谱本体结构Fig.2 Ontology structure of precise medical knowledge graph
1)不同类别实体数量差异较大。
图2 展示了图谱实体数量分布,此分布符合生物医学客观知识规律,该特点会导致部分关系的头尾实体数量不均,这一特点被称为图谱的不平衡性[23]。如果建模时没有考虑关系的不平衡性,则可能导致关系翻译或映射能力不足,进而导致推理效果下降。同时,实体类别的巨大数量差异直接导致了三元组数量的巨大差异,调查发现最大差异可达150 多倍。
2)实体类别唯一且类别之间没有重叠或包含关系。
医疗图谱中的每个类别都存在特异性,如基因(Gene)与蛋白(Protein)在医学领域是完全独立的2 个概念,不存在一个既是基因又是蛋白的物质。基于此特点,可对每种不同类型的实体使用维度特异的独立表示空间,在提升图谱嵌入枚举空间与灵活性的同时还能将类别信息融合到模型中。另外,图谱中没有对每个类别再做细分,如药物对蛋白质的作用可以进一步细分为51 种不同的子关系。细分类别对推理性能的影响也值得探索。
3)类型之间关系确定,且以非对称关系为主。
该特点同样源自于生物医学客观知识,如基因与蛋白2 种类别之间的联系必然是基因指导蛋白编码,而非其他。该特点意味着某些对头尾实体顺序不敏感的模型可能在此图谱中表现不佳。
4)存在明星实体与边缘实体。
明星实体指度(Degree)显著高于其他节点的实体,边缘实体则相反。例如基因实体中有5 个明星基因可以分别导致500 多种不同的疾病,但是同时也有66 247 个边缘基因没有任何疾病记录。在推理过程中,度越高的实体越会出现在三元组集合中,被训练的次数越多,越容易得到最优解甚至产生过拟合。另外,医疗图谱中也存在孤立节点,该类节点无法在关系推理中提供任何有价值的信息,因此,在进行推理时需要将它们去除。
2.1.2 独立表示空间
在第2.1.1 节中提到,医疗知识图谱不存在类别缺失和包含关系,因此,可以将各个类别分配到各自的特征空间中,定义如下:
其中:h、t分别代表三元组头尾实体的嵌入向量;femb为模型的嵌入层;ℎ、t表示实体编号;type(e)代表实体e的类别。
嵌入层也可以由图1(b)直观地表示,可以看出,不同类型的实体被嵌入到维度不尽相同的独立向量空间中,这种特定于实体类别的独立表示空间的模型结构能增强模型的表示能力。对于实体数量较多的实体类别(如Gene),可以赋予更高的向量维度,进而拟合更复杂的语义关系;反之,将实体数量较少的实体类别映射到较小的维度,可以在防止过拟合的同时加速收敛。此外,由于每一个实体在其类别嵌入空间中仅学习自己区别于其他同类别实体的语义特征,因此,该结构还能在一定程度上融合实体类别信息,避免实体嵌入到同一空间后造成的类别信息丢失问题。
2.1.3 映射翻译距离与得分函数
对于关系预测任务,需要为关系定义一种表示形式(如翻译距离、语义相似度),并基于此定义一个三元组的得分函数,得分越高的三元组越可能是正确的知识。本文基于第1 节中的翻译距离思想,提出映射翻译距离模型,该模型使用特定于实体类别的独立表示空间,并将关系r视为头实体ℎ 表示空间到尾实体t表示空间的一种翻译:
使用基于映射翻译距离表示关系,可以有效应对图谱中的不平衡性问题。由于头尾实体的数量存在差距,翻译模型会导致经过关系翻译后的头实体局限于尾实体中的一小片空间。而本节将2 种类型实体之间的关系建模为模式映射,可以将头实体空间中的节点映射(翻译)到尾实体空间的对应语义位置,从而有效解决上述局限性问题。
本文也使用翻译距离作为三元组的得分函数,即头实体ℎ 经过关系r映射(翻译)后,在尾实体嵌入空间与尾实体t的距离,距离越小三元组得分越高,因此,得分函数定义为映射翻译距离的相反数:
对于关系预测任务,本文采用现有研究中主流的margin-base 损失函 数[8,10-11,15,23,26]作为模 型的训 练目标,该损失函数通过随机负采样,使得正三元组样本的得分与负三元组样本的得分差尽可能大,并通过间隔参数γ来判断结果优劣。损失函数如下:
2.2 三元组特征空间
已有研究对于三元组分类任务的处理本质上与关系预测是相同的,其做法一般是直接基于三元组得分函数设置一个阈值,得分超过阈值的三元组视为正确,反之为错误,然后利用验证集分类准确率确定阈值的取值[10,23]。这种做法仅利用了关系预测任务训练出的得分函数作为一种三元组分类的依据,实际类似评估推理任务学习能力好坏的一个指标,而非一个新的任务。本文认为三元组分类是一个可以单独进行训练的重要任务:一方面,一个优秀的三元组分类器可以在关系推理前快速过滤掉分类为负的样本,缩小预测时的搜索空间;另一方面,三元组分类可以与关系预测相结合,互相指导对方的负采样过程,第2.3 节将具体讨论这一点。因此,本文提出三元组特征空间,将头实体与尾实体通过关系r投射到三元组空间中,并在该空间中训练一个三元组分类器。具体来说,对于每一种关系类型r,训练2 个映射矩阵2 个映射矩阵分别将头实体与尾实体向量从其原始嵌入空间中映射到三元组空间Rd,并将两者映射后的向量相连接,得到三元组的向量表示,如下:
其中:htriple、ttriple分别指头尾实体映射到三元组空间的特征向量;“‖”指向量连接操作。在得到三元组的向量表示后,将其输入一个分类器,预测该三元组是否正确。为了简化模型,本文采用单全连接层加Sigmoid 激活函数作为分类器,并使用上述关系预测任务中预训练的实体嵌入表示作为其初始特征向量,该模型的损失函数如下:
其中:y(i)代表第i个样本的标签;fθ代表三元组分类函数。
2.3 联合训练迭代负采样
第2.2 节中提到,三元组分类能在训练过程中与关系预测任务相结合,互相指导对方的负采样过程。具体来说,在关系预测任务中排名靠前的负样本,应使其在三元组分类任务中尽可能地被判别为负例,而在三元组分类任务中误判为正的负样本,应使其在关系预测任务中拥有更低的得分。通过将这2 个任务相结合,在每一个训练轮次中,关系预测任务与三元组分类任务对实体嵌入向量进行交替训练并指导下一个轮次中对方的负采样,可以在互相提升对方效果的同时学习到一个适用于2 个任务的更优的实体嵌入表示。式(10)、式(11)给出负采样三元组的定义:
2.4 元路径信息融合
推理模型TransSep 本质上仅基于图谱自身统计信息,只能学习到图谱本身所包含的结构与关系特征,而先验的逻辑规则往往能提供丰富的语义信息,因此,本节从元路径的角度出发,将领域知识融合到TransSep 模型中。
2.4.1 医学图谱中的元路径
元路径定义为异构图谱上由某些种类的实体和关系共同构成的一条序列,用来描述序列头尾实体之间的相似度或关联程度。一条由元路径构成的序列可以定义如下:
其中:T、R分别代表图谱的节点类型和关系类型。
表1 列举了几条精准医学图谱上的元路径,其语义可以表示为:P1代表“2 个不同的药可以治疗同一种疾病”;P3代表“2 种药各自治疗的疾病是由同一种基因造成的”。

表1 预定义的元路径 Table 1 Pre-defined meta-paths
对于医学图谱推理任务,元路径可以提供丰富的规则信息,例如在预测“一个药能治疗哪个疾病”时,通过元路径P1进行随机游走可以得到多条形如“Drug→Disease→Drug→…→Disease→Drug”的游走序列。当某药物与某疾病可以通过多条游走序列连通时,则该药物通常可以治疗该疾病。这种模式在医学图谱或其他通用图谱中都是普遍存在的,其表达的语义为“若许多其他药物能和药物A 共同治疗某种疾病,且这些其他药物又能治疗疾病B,则药物A 也有可能治疗疾病B”。因此,预定义若干元路径,可以使得推理模型在预测某一实体的关系时考虑元路径上其他实体对关系的影响,以获得更好的推理结果。
2.4.2 基于元路径的统一实体嵌入预训练
图嵌入预训练模型被证明可以有效提升各种下游任务的效果[12,16,27]。受此启发,本文使用第1 节中提到的Metapath2vec++模型对推理模型中随机初始化的实体嵌入向量进行预训练。Metapath2vec++模型的前提假设为“出现在同一条元路径上的相邻实体拥有相似特征”,正符合医学图谱推理中实体间应存在的关系。Metapath2vec++基于skip-gram 算法,其要求所有嵌入向量维度统一,无法直接适用于TransSep 模型。因此,本文在模型中加入统一实体嵌入预训练层用以兼容Metapath2vec++。具体来说,该层先对所有类别的实体利用Metapath2vec++预训练嵌入到一个统一的高维表示空间中,然后每一种实体类别再分别映射到该类别的独立表示空间中,定义如下:
其中:epre表示实体e经过Metapath2vec++预训练后的嵌入向量;e为式(1)定义的独立表示空间向量;dpre为统一 的预训 练表示 空间维 度;dτ为实体e对应类别τ=type(e)的独立表示空间维度。加入基于元路径的统一实体嵌入预训练层后,整个模型的结构如图1(a)所示。预训练模型的损失函数如下:
其中:ecenter表示skip-gram 窗口中的中心节点嵌入向量;epos与eneg分别表示窗口内的邻居节点与负采样节点的嵌入向量为负采样的概率分布。
2.4.3 基于元路径的图注意力聚合
基于元路径的图注意力聚合包括如下2 个方面:
1)元路径内的图注意力聚合。
受到文献[28-29]的启发,在推理模型中加入图注意力神经网络层(GAT)不仅可以聚合元路径邻居实体的特征信息,还能学习每个元路径邻居对特定关系预测任务的重要程度。因此,本文进一步对TransSep 模型进行改进,在关系预测模型中融入元路径图注意力神经网络层,以充分利用元路径提供的规则信息。
对于一个实体e与元路径P,所有从e出发通过该元路径能到达的实体e'(包含e自身)构成了该实体e在该元路径P上的邻居实体集合,记为N Pe。考虑到主流的注意力算法要求相同维度的特征向量,因此,本文基于Bahdanau 注意力对GAT 层进行改进。具体来说,对于一个实体e与其在元路径P上的邻居e',e'对e的重要程度定义如下:
其中:τ 与τ′分别为e与e'的向量长度。得到所有元路径邻居对实体e的重要程度后,使用Softmax 计算每个邻居的权重:
最后对元路径邻居的特征进行加权平均,得到实体e经过该GAT 层聚合邻居特征后的输出,如下:
由于上述GAT 层的作用是学习一个元路径内部邻居实体相互之间的重要性并聚合邻居特征,因此,可以称其为元路径内的图注意力层,图1(c)直观地展示了该层结构。
2)元路径间的图注意力聚合。
元路径内的图注意力层可以让实体聚合一条元路径模式内邻居节点的特征。然而,预定的元路径可以存在不止一条,当同一个实体同时出现在多条元路径中时,不同元路径提供的语义信息的重要程度也不同。因此,还需要一个元路径间的图注意力层聚合同一实体来自不同元路径中的信息。具体来说,假设存在n条元路径{P1,P2,…,Pn},实体e经过元路径内的图注意力层后输出为{eP1,eP2,…,eP}n,记第i条元路径的重要程度为,其定义如下:
此时可以通过Softmax 得到每条元路径的权重αPi,然后加权得出元路径间GAT 层的输出特征向量:
在关系预测模型中加入上述元路径内与元路径间图的注意力层后,式(4)中的三元组得分函数变为如下:
3 实验验证
3.1 实验数据
本文实验数据来自近年来国家重点研发计划“精准医学知识图谱构建”项目产出的精准医学知识图谱,项目组在过去几年中从医疗序列关系、医学词典、诊断指南等信息源中构建出包含12 个类别、300 多万个实体以及接近500 万条关系的领域知识图谱。
3.2 对比模型与评价指标
对比模型选取翻译距离模型TransE[8]及其变体CONVTRANSE[30]和SIM+GCN+CONVTRANSE[31]、语义相 似度模 型DistMult[12]及其变 体TriModel[32]和ComplEx[33],另外还加入没有元路径指导的随机游走模型Node2vec[16]。当连续3 个轮次的平均验证集损失不再下降时,认为模型已经收敛。
实验使用的评价指标如下:
1)MR(Mean Rank)。MR 表示对于所有测试集三元组,正确的实体ℎ 或t在所有实体中排名的平均值。该指标越小,说明模型越能赋予正三元组高置信度。
2)Hit@N。Hit@N表示正 确实体ℎ 或t排在前N名的概率。该指标越大,说明模型的推理效果越好。N通常的取值包括1、3、10、50 等,现有研究一般使用Hit@10 作为实验结果对比标准[34]。
3)F1 值。F1 值反映了模型的精确率和召回率,当两者都高时,F1 值才会取得较高的值。
3.3 实验结果分析
3.3.1 TransSep 本体结构性能评估
由于医学图谱中存在大量一对多的关系,因此对于一个测试集三元组(ℎ,r,t),可能存在多个实体e满足(ℎ,r,e)∈G,且e≠t,这些正样本会有较高的得分而排在预测结果中较前的名次,从而对测试集中尾实体t的排名造成较大影响,因此,本文所有实验结果均采用将上述所有正样本e排除后的指标,后续不再特别声明。实验结果如表2 所示,其中,最优数据用加粗标注,次优数据用下划线标注。从表2 可以看出,本文提出的TransSep 模型在关系预测任务中各项指标表现均优于其他主流模型。
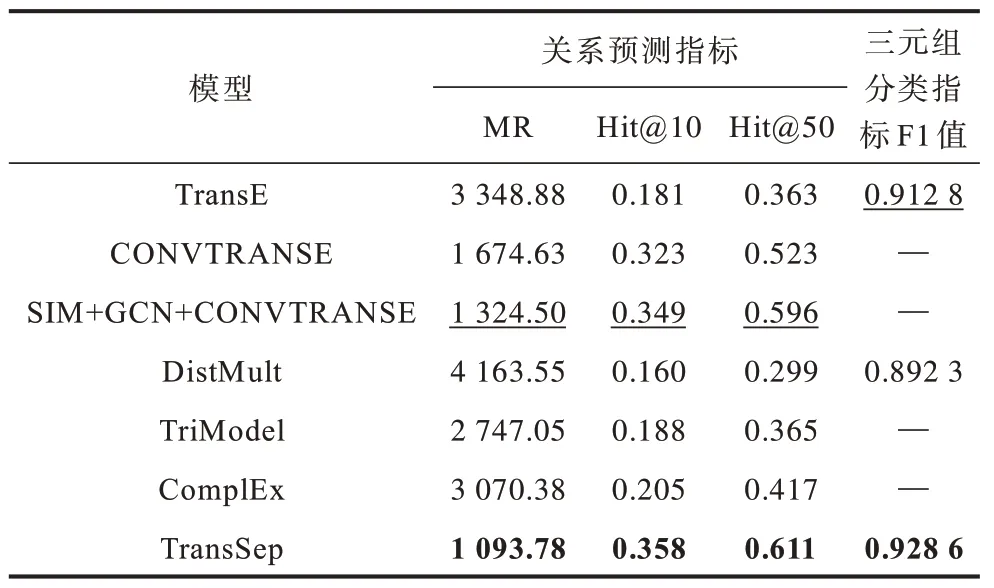
表2 关系预测的实验结果 Table 2 Experimental results of relation prediction
3.3.2 引入元路径的TransSep 性能评估
本节对加入元路径图嵌入预训练后的模型进行实验,基于生物医学背景知识,共预定义3 条metapath,其路径与语义依据如下:
1)表1 中的P1,2 种药能治疗同一种疾病,3 个元素间应具有相关联的特征。
2)表1 中的P3,2 种药分别能治疗同一基因引起的2 种疾病,5 个元素间应该具有相关联的特征。
3)Protein→Gene→Disease→Gene→Protein,2 种蛋白分别由2 个能导致同一疾病的基因编码,5 个元素间应具有相关联的特征。
模型的预训练过程使用小批次随机梯度下降方式,并采用噪声对比估计来加速训练过程。实验结果如表3 所示。

表3 元路径的实验结果 Table 3 Experimental results of meta-path
在 表3 中,MP2v 是仅使 用Metapath2vec++的TransSep模型,MPAtt 是仅使 用GAT 的TransSep 模型。从表3 可以看出,没有元路径指导的随机游走模型Node2vec[16]预训练对关系预测任务具有一定的提升效果,但是对三元组分类没有明显帮助,而加入元路径信息的Metapath2vec++相比随机游走模型进一步优化了关系预测模型的表现,同时也在一定程度上提升了三元组分类的效果。
相比预训练,元路径注意力层对关系预测任务的提升效果更加明显,这主要是由于元路径注意力层参数更复杂,使其能更有效地表示元路径邻居之间的相互关系。同时,相比预训练,该层的参数可以不断训练,因此,能更好地学习元路径对具体任务提供的信息。由于两者分别在数据输入层和编码层与TransSep 相融合,因此可以将两者全部融入推理模型中。从实验结果可以看到,融合两者的模型取得了最优表现。
此外,无论是预训练还是注意力层,元路径对三元组分类任务的效果提升都较为有限。本文认为这是由于不引入元路径的TransSep 模型已经对“三元组是否正确”这一粗粒度问题的判断较为准确,而元路径中包含的额外规则信息仅能对更细粒度的预测任务提供帮助,即“在正确的三元组中,哪个三元组的置信度更大”。虽然元路径信息的融合使得模型变得更复杂,但是考虑到关系预测是图谱推理任务中最重要的部分,本文认为引入额外的预训练过程是合理且有意义的做法。
4 其他研究
4.1 数据集划分
大多数的深度学习任务可以完全随机地对所有样本进行训练集与测试集的划分。然而,知识图谱推理任务却由于表示学习的不可迁移性而不具备上述特性。举例来说,如果一个实体的度很小或仅为1,则当其被掩盖划分进测试集时,训练集中将失去关于该节点的大部分乃至全部信息,导致模型难以预测该关系。医疗图谱存在明星节点与边缘节点的异质性,基于上述考虑,本文进一步研究数据集划分对医疗图谱推理结果的影响,分别针对明星实体(度大于200)、普通实体(度介于2 与200 之间)、边缘实体(度等于1)以及随机划分测试集这4 种情况下的推理效果进行实验,结果如表4 所示。
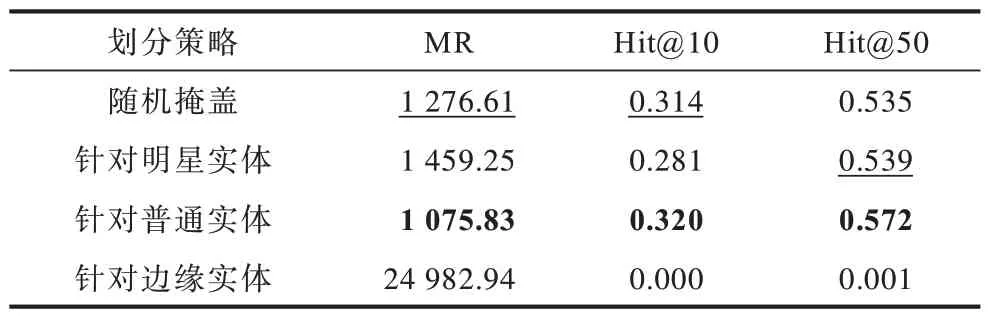
表4 数据集划分的实验结果 Table 4 Experimental results of datasets partition
实验结果验证了上述观点,即边缘实体仅有的关系特征被掩盖后,其嵌入向量无法得到学习,模型也无法对其进行预测,而模型对明星实体的关系预测表现也较差,本文认为这是由于明星实体呈现的关系过于复杂,模型更容易欠拟合。从上述结果中可以得出结论,推理模型较难应对图谱中存在的异质性问题,因此,不同的数据集划分策略对推理结果会产生不同的影响。在进行推理任务对比研究时应固定训练集与测试集,以避免数据集划分对结果造成干扰。
4.2 关系拆分
第2.1.1 节提到医疗图谱中的类别可以进一步拆分,本节对此进行实验,比较Target 关系是否拆分对关系预测效果的影响,结果如表5 所示。

表5 关系拆分的实验结果 Table 5 Experimental results of relation partition
从表5 可以看出,将Target 关系拆分成51 种子关系后,模型效果有显著提升,这是由于模型的关系枚举空间大幅增加,不再受限于使用单一关系映射来表示所有药物与蛋白之间的联系。这一结果表明,更具体的关系不仅可以在模型中融合更多的语义特征,还能提升模型的表示能力。因此,在未来的研究中可以从生物医学角度考虑将每种关系拆分成子关系的可能性,以提高关系推理的效果。
4.3 元路径设计
元路径中规则的语义信息也会造成模型效果的差异,现有大多数关于元路径的研究[17-18,29]中都使用类似表1 中P1的简单语义元路径,也有一些研究[35]将元路径设计为包含多种类别实体的复杂模式。本文设计并对比分析4 种不同的元路径对推理模型效果的影响,分别对应 简单1-hop 关系(如P1、P2)、2-hop 关系(如P3)以及复杂关系模式(如P4),具体如表1 所示,其中,P4表示生物医学领域的一种典型链路,其语义可以理解为“一个基因编码了一个蛋白,当其发生突变时会导致一种疾病(由于蛋白异常表达),另有一种药是该蛋白的靶向药(抑制蛋白),因此,此药可以治疗该疾病”,在上述语义示例中可以看出,基因、蛋白、疾病、药这4 个实体具有强烈的相互关系。
实验共分3 组进行,为了保证实验中所有实体类别都出现在元路径中,每组实验可能使用不止一条元路径。实验结果如表6 所示,可以看出,包含生物学意义与更丰富语义信息的元路径P4对推理模型的效果提升最大。
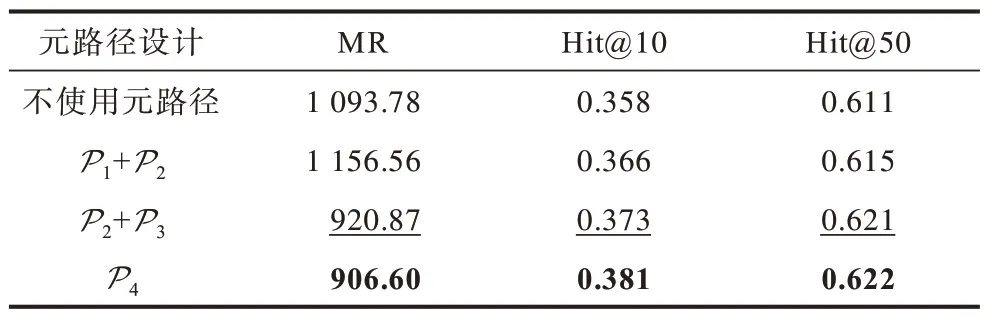
表6 不同的元路径设计对推理效果的影响 Table 6 The impact of different meta-path designs on inference effect
基于上述结论,本文提出以下2 点建议:
1)包含更多语义的复杂模式比简单元路径更能在全局上提供信息,且该模式应尽可能具备某种现实意义。以此为依据设计元路径可以提升元路径规则对推理模型的影响。
2)可以将不同关系类型的推理任务进行拆分,即对每种类型的关系(或多个具有强相互关联的关系)训练不同的推理模型,并引入包含该特定关系的元路径以提升其推理效果。
4.4 元路径选取
增加元路径的数量也会带来一些问题:
1)增加元路径的数量会直接导致模型复杂度提升。假设实体的数量为n,实体类别的数量为N,预训练窗口大小为k,实体的平均嵌入维度为d,则每增加1 条元路径,都会使得预训练的样本数量增加kn,图注意力层的训练参数数量增加Nd2。
2)增加元路径的数量意味着每个实体拥有的平均元路径邻居数量增多,由于GAT 层难以并行计算,因此过多的元路径无论对模型的训练还是预测都会造成很大的计算开销。
3)过多的元路径可能会导致模型表示能力下降,尤其是在预训练过程中,增加元路径数量就要求实体的嵌入向量能表示出更多的复杂关系,每条不同的元路径都可能将嵌入向量往不同的方向优化,导致模型对每一条元路径规则的拟合效果都不理想。
出于上述考虑,本文对元路径的数量进行实验。具体来说,对于表1 中定义的4 条元路径,实验依次测试不使用元路径以及在模型中分别融入{P1}、{P1,P2}、{P1,P2,P3}、{P1,P2,P3,P4}时的推理效果,实验结果如表7 所示。

表7 元路径数量对推理效果的影响 Table 7 The impact of the number of meta-paths on inference effect
从表7 可以看出,在前3 条元路径增加的过程中,模型由于获得了更多的规则信息,表现出了更好的推理效果。然而,对于P4,即使第4.3 节中证明了该元路径比前3 条更有效,在前3 条的基础上将其加入后也没有较为明显的效果提升,还显著增加了模型的计算开销。因此,在设计与选择元路径时,需要在元路径的数量、模型的计算开销、推理的效果之间取得一个平衡。结合表7 结果与第4.3 节中的结论,本文认为在医疗图谱推理任务的实际应用中,应倾向于较少的元路径数量,每条元路径应尽可能符合某种生物学意义,或对特定类型的关系预测具有指导作用,且元路径应能覆盖所有的实体类别,以便提供更多的语义信息。同时,考虑到医疗图谱中并非所有关系类型都是可推理的,也有一部分关系缺乏推理的实际应用价值,因此,可以进一步明确推理的关系类型,针对每种关系训练不同的模型以获得更优的效果。
5 结束语
本文基于知识图谱表示学习技术,以精准医学知识图谱为例,针对领域知识图谱推理任务进行研究。首先,阐述知识图谱嵌入与知识图谱推理的各类主流模型结构、方法论及其局限性;然后,考虑到上述模型在领域知识图谱中缺乏迁移与泛化能力,分析所研究的领域图谱区别于通用百科图谱的结构特点,并基于翻译距离原则提出针对领域图谱优化的推理模型TransSep,该模型在推理任务中取得了较好的表现;最后,考虑到生物医学本身作为一个研究型学科,其知识体系中的一些规律可以作为先验规则融合到深度学习推理模型中,为推理任务提供更多的语义信息,因此,基于异构网络中元路径的概念,将领域规则融合到TransSep 模型中,进一步提升关系预测任务的效果。
本文的工作对于在领域图谱中使用图嵌入与深度学习技术进行推理具有一定的启发。随着知识图谱的发展,工业级知识图谱的应用正在快速普及[7],而某一领域中的领域规则往往容易得到。如何针对特定领域设计更优的推理模型、在模型中融合领域内部规则信息以及对领域规则进行选择,将是下一步的重点研究方向。
