基于文本挖掘的社交网络用户精神疾病筛查
2023-09-18张鑫衍
张鑫衍


摘 要:随着移动互联网的普及,公众更加频繁地使用社交网络分享生活并表达思想和感情。推特作为拥有全球最大用户基数的社交平台,沉淀了非常丰富的用户和文本信息。文章使用Sentiment140数据集对推特文本信息进行分析,从不同角度对数据集进行探索性数据分析,并通过F1值评估对比不同的特征提取方法和分类算法,最终确定了最佳的特征提取和分类参数。文章使用的分析流程和分析结果可作为文本情感挖掘的参考,为基于文本信息的情感分类任务以及精神疾病如抑郁症等的诊断提供助力。
关键词:社交网络;文本挖掘;自然语言处理;数字疗法;精神疾病筛查
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2023)15-0157-05
Mental illness screening of social network users based on text mining
ZHANG Xinyan
(Yangtze River Delta Center for Medical Device Evaluation and Inspection of National Medical Products Administration, Shanghai 200135, China)
Abstract: With the popularity of mobile internet, the public is more frequent to use social networks to share their lives and express their thoughts and feelings. As a social platform with the world's largest user base, Twitter has accumulated a wealth of user and text information. This paper uses the Sentiment140 dataset to analyze the Twitter text information, analyzes the exploratory data of dataset from different aspects, and evaluates and compares the different feature extraction methods and classification algorithms by F1 value, and determines the best feature extraction and classification parameters finally. The analysis process and analysis results used in this paper can be used as a reference for text sentiment mining, and provide assistance for the task of sentiment classification based on text information and the diagnosis of mental diseases such as depression.
Keywords: social network; text mining; Digital Therapeutics(DTx); Mental illness screening; Natural language processing
0 引 言
抑郁症是现在最常见的一种心理疾病,以连续且长期的心情低落为主要的临床特征,是现代人心理疾病中最重要的类型。抑郁症的临床表现为心情低落和现实过得不开心,情绪长时间的低落消沉,从一开始的闷闷不乐到最后的悲痛欲绝,自卑、痛苦、悲观、厌世,感觉活着的每一天都是在折磨自己,消极,逃避,最后甚至有自杀倾向和行为。患者患有躯体化症状。胸闷,气短。根据世界卫生组织2019年底发布的报告,抑郁症的发病率仅次于世界第一大严重的缺血性心脏病,在世界排名前十位的使人丧失劳动能力的疾病中,抑郁症甚至名列首位,这无疑成为社会安定的巨大隐患。目前全世界抑郁症患者人数为3.22亿人,患病率为4.4%。据不完全统计,我国抑郁症患者超过9 000万人,同时,抑郁症患者人数也在逐年攀升。由于多种社会因素的影响,抑郁症的确诊率低,很多患者罹患抑郁癥后并未及时进行检查和诊断,即使进行了检查和诊断,由于病耻感和公众对该疾病的误解等因素,对抑郁症的干预和治疗也往往并不及时有效。同时,抑郁症的确诊也存在一些困难。抑郁症的诊断主要应根据病史、临床症状、病程及体格检查和实验室检查,典型病例诊断一般不困难,一般采用ICD-10和DSM-IV诊断标准进行判别,但抑郁症存在诸多分型,同时由于抑郁症的临床表现容易和其他类型的精神疾病混淆,这些因素都给确诊抑郁症带来了困难。
随着社交网络的蓬勃发展,现代人越来越依赖数字世界。同时,海量的线上文本信息为多种基于文本信息的应用提供了可能,如网络舆情分析、精神疾病辅助诊断等。近年来越来越多的研究聚焦于使用社交网络信息对用户的情感和精神状态进行判断。从来源上看,社交网络的来源丰富,如微博[1-5]、
推特[6-11],及其他来源如雅虎[12]等。从研究的具体问题看,研究的问题多样,包括情感分析[13,14]、精神疾病如抑郁症的诊断[1-4,7,15,16]及多任务(multi-task, MT)(如文献[6]设计了一个多任务分类器同时对文本的情感和抑郁状态进行判别、文献[17]中对图像和文本数据进行多模态融合,并设计了一个同时判别用户性别和情感状态的多任务分类器)。此外,特征提取和分类的算法也多种多样,主要分为两类,一类基于传统机器学习方法如支持向量机(support vector machines, SVM)应用非常广泛[1,2,9,16],此外,随着大数据时代的来临,深度学习方法也得到越来越多的使用,如文献[1,3,16]等使用Word2Vec生成词向量[15],使用长短期记忆网络(Long short-term memory, LSTM)进行分类任务[6],利用双向门控循环单元(Bidirectional gated recurrent unit, BiGRU)和注意力机制(Attention Mechanism)进行分类任务[17],
利用门控循环单元(Gated recurrent unit, GRU)和残差网络(Residual Network, ResNet)进行分类任务。目前索引到的文章中使用的推特数据集普遍在万条数据的级别,如文献[6]中采集了10 659条推特文本[18],文献[18]中采集了90 000条推特数据,文献[9]中采集了12 741條数据,只有文献[8]中采集了94 707 264条数据达到千万级别。一般而言,数据量越大,所蕴含的信息就越丰富,因此本文中采用Sentiment140数据集,该数据集含有160万条数据集,为文本挖掘提供了丰富的素材。
1 实验方法
1.1 数据集
本文中采用Sentiment140数据集,包含2009年4月6日到2009年6月25日共659 775位推特用户发表的160万条推特数据,语言为英语。该数据集包含6个字段,分别是标签(也称极性,Polarity)、推特ID、发表时间戳、标示、用户名、推特文本。标签分为正向标签(Positive)和负向标签(Negative),表示本条推特文本的情感状态。数据集中共有80万条正向数据和80万条负向数据,分类均衡。
1.2 预处理
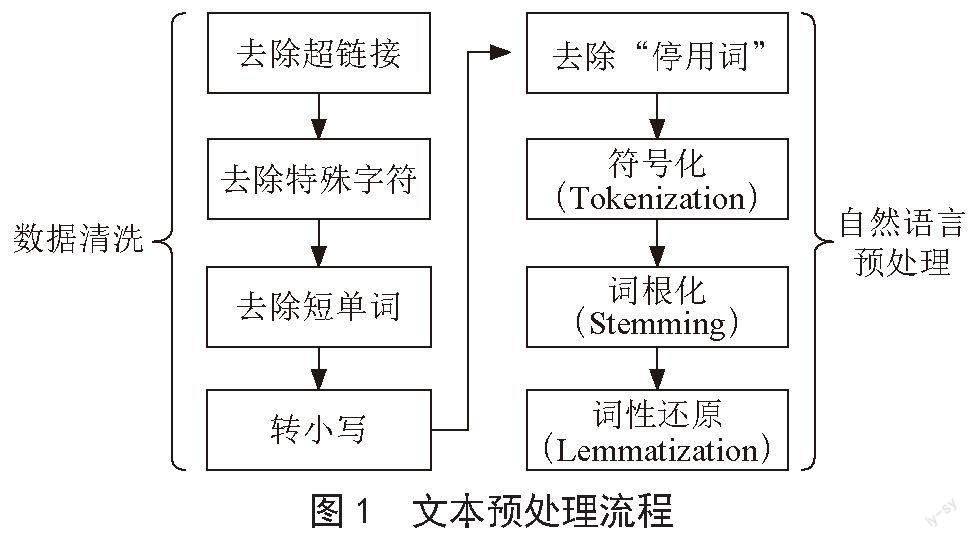
原始文本数据无法直接用于分类任务,因推特文本的多源、异构特征,如推特数据中包含短链接、表情、不规范拼写(如用“yeeeeees”表示“yes”)等,不具有实际含义,需要去除。因此对数据进行预处理,流程如图1所示。
首先进行数据清洗,去除无语义的信息。去除短单词是基于这样一个假设:即过短的单词(字母个数小于4个)含有有效信息的概率很小,因此去除这些无关信息可以提高分类器的表现。转小写是数据清洗必要的一个步骤,在后续特征提取部分,如使用词袋模型,统一小写后的文本可以确保相同含义的单词被视为一个语义单元,如“Monkey”和“monkey”在语义上是一致的,首先需要在形式上将其统一以便后续的特征提取。
仅有数据清洗是远远不够的,还需要使用一些自然语言处理技巧进行进一步的处理,本文使用NLTK[19]工具包对推特文本进行进一步的处理,首先,去除停用词,英语中的停用词包含“A”“the”“is”“are”“having”等,这些单词主要起到承接作用,本身并无语义。然后进行“符号化”,此处使用空格分隔直接将单词作为元素进行符号化。最后进行词根化和词形还原,这两步的作用和转小写类似,将语义相同但形式不同的单词进行归一化,如“go”和“went”具有相同的语义,只是因为事态不同而显示为不同的形式,通过词形还原可以做到这一点。
1.3 特征提取
文档的特征提取是进行情感判别前的关键一步,合适的特征提取方法可以很好地提升分类器的表现。文档是一系列单词的有序不定长列表。最常见的文档特征描述方法为词袋模型(bag of words),词袋模型的思想是文档为一个包裹着词语的容器,通过容器中的词语的计数等统计量来将文档向量化(vectorization)。必须说明的一点是,词袋模型和其他一些文档模型一样,是一种有损模型,即建模过程中会丢失一些信息。由于自然语言的特点(非结构化、歧义性、容错性、易变性、简略性),无损地对文档进行建模是不可能的,只能使用合适的建模方式来尽可能地保留文档的信息。词袋模型最常用的统计指标为词频,即统计一个单词在文档中出现的次数,除此之外,还可以选择布尔词频、TF-IDF、词向量等作为统计指标。一般而言,词频向量适合主题较多的数据集;布尔词频适合长度较短的数据集;TF-IDF适合主题较少的数据集;词向量适合处理OOV(Out Of Vocabulary)问题严重的数据集。除词袋模型外,神经网络模型也能无监督地生成文档向量,比如AutoEncoder和RBM等。使用深度学习生成地文档向量一般表现优于词袋向量,但计算开销也更大。
特征提取部分分别使用CountVectorizer和TF-IDF(term frequency–inverse document frequency)两种词袋模型进行特征提取。其中CountVectorizer即为使用词频作为统计指标地词袋模型,而TF-IDF(词频-倒排文档频次)除考虑词频外,还综合考虑词语的稀有程度,因此,TF-IDF属于多文档方法。
除使用不同指标的词袋模型外,同时考虑一元语言(1-gram)模型和二元语言模型(2-gram)对提取效果的影响。基于N-gram的方法是把文档进行排序,并使用大小为N的窗口对文档进行分割。简单地说,基于一元语言模型分割后的元素为单词,而基于二元语言模型分割后的元素为2个单词组成的序列,以此类推。
本文使用Scikit-learn库[20]提供的工具进行特征提取。
1.4 分类器选择
分类器对比XGBoost、逻辑斯蒂回归(Logistic
Regression, LR)和线性SVC(linear support vector classifier)三种算法在不同特征提取参数下的F1值。
XGBoost算法是对GBDT(Gradient Boosting Decision Tree)算法的优化,两者都是基于提升(boosting)的方法。其优势在于高效可拓展和鲁棒性强。但其面对高维数据时,无法很好地捕捉其特征,此外,在数据量很大的情况下,深度学习算法相比XGBoost优势明显。逻辑斯蒂回归算法主要用于解决二分类问题,用来表示某件事情发生的可能性。由于本次任务为二分类任务,因此采用逻辑斯蒂回归作为分类算法之一。逻辑斯蒂回归算法具有实现简单、速度快、资源需求低等优势,其缺点在于容易欠拟合,一般而言模型表现不太佳,只能处理二分类问题且必须线性可分。线性SVC是基于SVM并使用线性核的分类器,SVM通过对特征空间划分超平面进行分类,其优点在于样本量要求低,鲁棒性强。
2 探索性数据分析
2.1 时间分布
首先对数据的时间分布进行可视化,分别从日期和一天中的小时两个维度进行展示,如图2所示。
图2中可发现大量推特数据集中发表于2009-5-29到2009-6-2以及2009-6-5到2009-6-20。此外,
可以發现部分日期没有或很少有推特发表,如2009-5-23到2009-5-25以及2009-5-27。从情感状态分布上看,大部分时间正向情感的推特数据量大于负向情感的推特数据量,但从2009-5-17后全部推特数据均为负向数据。
从一天内发表时间点看,正向和负向推特的时间点分布趋于一致,在8—20时之间为下降趋势并至低估,然后开始上升。值得注意的是,正向推特在8—20时时间范围内少于负向推特,但在其他时间段尤其是凌晨22至次日5时前,正向推特数量远高于负向推特。一个可能的猜测是,8—20时为工作时间,负向推特的发出人可能因各种原因无法聚焦个人生活与工作,因此以社交网络为发泄口表达负面情绪;而在凌晨等休息时间,娱乐活动可以激发人的乐观情绪,因而此时段发出的推特更倾向于正向情绪。但此猜测并无进一步的依据,如需探究则要有进一步的数据支持。
2.2 词云分析
首先对高频词进行词云绘制,词频越高的词语在词云图中越大。图3中可以看到正向推特中“Love”的词频很高,而负向推特中“miss”摆在了比较显眼的位置。
此外,我们对标签进行分析,推特中标签指的是以“#”为开头的单词,一般推特用户会以标签表明推特的主题,因此,标签对于判断推特信息的主题或相关的话题十分重要。实际上从图4的可视化结果看也是如此。在负向推特词云中,“fail”的词频很高,“fail”意为失败,是一个具有强烈感情色彩的词语,因此,可以想见,分析标签中蕴含的信息对文本情感分析至关重要。
3 实验结果
我们通过F1值对算法进行评估,并通过10折(10 Fold)交叉验证抑制随机因素,确保结果可以反映算法的平均表现。训练集和测试集的划分方式为分层随机划分,比例为测试集20%,训练集80%。结果如表1所示。
从表1可以得出结论逻辑斯蒂回归在各种参数配置下均取得了最佳的效果,且在使用一元TF-IDF方法进行特征提取时取得了最佳的F1值,为76.1%。
4 结 论
本文使用百万级别的推特数据集,对数据集从不同维度开展探索性数据分析,并使用不同特征提取与分类方法对算法进行评估。最终得到最佳的特征提取方法(一元TF-IDF)和最佳的分类器(逻辑斯蒂回归)。鉴于本次进行实验的特征提取方法和分类器均为传统机器学习方法,在将来的工作中拟引入基于深度学习的特征提取方法(如Word2Vec)以及分类方法(如LSTM),进行更加全面的评估。
本文的方法可以用于基于文本信息的用户情感分析以及精神障碍筛查与辅助诊断,具有广阔的应用前景。基于社交网络文本的精神状态判定是对目前基于量表的精神疾病的诊断方法的很好的补充,同时,社交网络文本相比量表数据,具有客观性强、易获取、成本低等优势。有理由相信,随着相关研究的进展,社交网络文本挖掘精神分析将会对人民精神健康做出更大的贡献。
参考文献:
[1] 方振宇.基于抑郁词典的社交网络心理障碍检测方法 [J].电脑知识与技术,2017,13(7):244-247.
[2] 王垚,贾宝龙,杜依宁,等.基于词向量的多维度正则化SVM社交网络抑郁倾向检测方法 [J].计算机应用与软件,2022,39(3):116-120.
[3] 查国清,胡超然,孙铭涛,等.抑郁症网络社交与疑似抑郁微博初步筛选算法 [J].计算机工程与应用,2022,58(1):158-164.
[4] 刘定平,张雪燕.基于社交网络信息的用户抑郁症倾向识别 [J].统计理论与实践,2021(9):14-21.
[5] LI L,ZHANG Q,WANG X,et al. Characterizing the Propagation of Situational Information in Social Media During COVID-19 Epidemic: A Case Study on Weibo [J].IEEE Transactions on Computational Social Systems,2020,7(2):556-562.
[6] GHOSH S,EKBAL A,BHATTACHARYYA P. What Does Your Bio Say? Inferring Twitter Users Depression Status From Multimodal Profile Information Using Deep Learning [J].IEEE Transactions on Computational Social Systems,2022,9(5):1484-1494.
[7] DE CHOUDHURY M,GAMON M,COUNTS S,et al. Predicting Depression via Social Media [J].Proceedings of the International AAAI Conference on Web and Social Media,2021,7(1):128-137.
[8] ZHOU J,ZOGAN H,YANG S,et al. Detecting Community Depression Dynamics Due to COVID-19 Pandemic in Australia [J].IEEE Transactions on Computational Social Systems,2021,8(4):982-991.
[9] GUPTA P,KUMAR S,SUMAN R R,et al. Sentiment Analysis of Lockdown in India During COVID-19: A Case Study on Twitter [J].IEEE Transactions on Computational Social Systems,2021,8(4):992-1002.
[10] KAUSAR M A,SOOSAIMANICKAM A,NASAR M. Public Sentiment Analysis on Twitter Data during COVID-19 Outbreak [J/OL].International Journal of Advanced Computer Science and Applications,2021,12(2)[2023-02-11].http://thesai.org/Publications/ViewPaper?Volume=12&Issue=2&Code=IJACSA&SerialNo=52.
[11] SHEN G,JIA J,NIE L,et al. Depression detection via harvesting social media: a multimodal dictionary learning solution [C]//IJCAI'17:Proceedings of the 26th International Joint Conference on Artificial Intelligence.Melbourne:AAAI Press,2017:3838-3844.
[12] HIRAGA M. Predicting Depression for Japanese Blog Text [C]//Proceedings of ACL 2017, Student Research Workshop.Vancouver:ACL,2017:107-113.
[13] 周法國,孙冬雪.融入情感和话题信息的中文方面级情感分析 [J].计算机应用研究,2022,39(12):3614-3619+3625.
[14] CAI W,GAO M,JIANG Y,et al. Multi-Source Domain Transfer Discriminative Dictionary Learning Modeling for Electroencephalogram-Based Emotion Recognition [J].IEEE Transactions on Computational Social Systems,2022,9(6):1604-1612.
[15] 张梦娜,王君岩,龙洋,等.基于社交媒体中文本信息的早期抑郁症检测 [J].中国生物医学工程学报,2022,41(1):21-30.
[16] 刘德喜,邱家洪,万常选,等.利用准私密社交网络文本数据检测抑郁用户的可行性分析 [J].中文信息学报,2018,32(9):93-102.
[17] SUMAN C,CHAUDHARI R,SAHA S,et al. Investigations in Emotion Aware Multimodal Gender Prediction Systems From Social Media Data [J].IEEE Transactions on Computational Social Systems,2022:1-10.
[18] NASEEM U,RAZZAK I,KHUSHI M,et al. COVIDSenti:A Large-Scale Benchmark Twitter Data Set for COVID-19 Sentiment Analysis [J].IEEE Transactions on Computational Social Systems,2021,8(4):1003-1015.
[19] BIRD S,KLEIN E,LOPER E. Natural Language Processing with Python:Analyzing Text with the Natural Language Toolkit [M].OReilly Media,Inc.,2009.
[20] PEDREGOSA F,VAROQUAUX G,GRAMFORT A,et al. Scikit-learn:Machine Learning in Python [J].The Journal of Machine Learning Research,2011,12(1):2825-2830.
