基于卷积神经网络的顶岗实习管理系统数据挖掘研究
2023-09-15蔡传军童绪军
蔡传军,童绪军
(安徽医学高等专科学校 公共基础学院,安徽 合肥 230601)
顶岗实习是高等教育不可或缺的组成部分,为有效监控学生的顶岗实习情况,大多数学校都开发了顶岗实习管理系统,通过学生上传的实习报告和实习评价结果记录顶岗实习情况,确保校内指导教师了解学生的整体工作状况[1-3]。但是,随着校内顶岗实习管理系统使用年数的增加,系统内会积累大量数据,会降低数据的利用效率[4]。现代数据挖掘技术的进步,使数据的查找和分析效率有了明显提升。针对顶岗实习管理系统,设计合理的数据挖掘方法成为当前的研究重点,但是现有的数据挖掘方法难以满足院校的顶岗实习数据管理需求[5]。为解决这一问题,本研究提出了一种基于卷积神经网络的数据挖掘方法,可精准提取所需的顶岗实习数据,为顶岗实习管理工作打下基础。
1 设计方法
1.1 建立实习管理系统数据仓库
顶岗实习管理系统内包含的数据多种多样,需要建立面向主题的数据仓库,作为后续数据挖掘的基础。以数据主题作为宏观分析条件[6],对实习管理系统内包含的数据进行聚类分析,形成多个数据单元,再通过数据加工和集成处理,以满足数据仓库集成特性的要求。因此,在数据仓库的创建过程中,将数据加工和数据集成归纳为一个复杂的环节,先提取原始数据的矛盾点,再以此为核心将应用数据结构转换为面向主题的数据结构[7]。本研究提出的数据挖掘方法以数据仓库为基础组织结构,首先对顶岗实习管理系统中提取出的各类数据进行处理,形成基础数据集,然后分析基础数据所呈现出的时间变化趋势,对基础数据进行分类、归纳和加工,结合时间控制机制形成历史数据集,再与基础数据集相结合形成综合数据。
由于学生顶岗实习工作所涉及的外部部门较多,即外部数据较多,所以在建立数据仓库时,还需要将这些外部数据单独划分出来,与外部数据源进行对比验证,确保外部数据的真实性[8]。同时,需要设计一个集成数据处理器,连接数据仓库与外部数据源,后者所包含的数据发生改变后,可同步更新数据仓库信息。本研究所构建的数据仓库,采用如图1所示的基本逻辑结构。
从图1可以看出,一个数据仓库的组成包括仓库设计、数据获取、数据管理和数据访问4个环节,分别负责定义仓库环境、解析外部数据源、数据分布管理与更新维护,以及向管理人员提供数据报告。
1.2 设计数据特征提取机制
针对建立的数据仓库设计一种分布式数据结构,以实现目标数据的模糊分布式存储。由于顶岗实习管理系统内包含的部分数据存在交互性[9],数据挖掘过程中又存在较多扰动影响因素,且这些影响因素具有时变性特点,因此本研究提出运用模糊聚类技术,融合不同特征维度的数据,形成包含关联规则项约束条件的数据信息流模型[10],具体表达式为
xn=x(t0+nΔt)=h(t0+nΔt)+θn,
(1)
式中:x表示顶岗实习管理系统数据信息流模型;n表示关联规则项数量;t0表示初始时刻;Δt表示变化时刻;h(·)表示多维数据结构模型函数;θ表示数据测量误差。在此基础上,采用分布式结构模型,将顶岗实习管理系统的数据表述为以下分布函数:
(2)
式中:u表示目标数据;z表示数据存储结构的阶数;α表示数据采集时间窗口宽度。
按照顶岗实习管理系统数据采集时间,结合式(2)构建具有分布式特点的时态结构模型,将四元组条件下提取的关联规则项特征转换为五元组关联规则项,得到数据挖掘所需要的关联规则知识[11],并给出特征标志函数。引入统计回归分析思想,针对顶岗实习管理系统数据,形成非线性时间序列数据组合模型。
针对具有连续性特点的顶岗实习管理系统数据,本研究应用连续模板匹配技术,深入分析分布式数据结构,对子结构数据进行融合处理。在实际操作过程中,需要针对非线性时间序列数据组合模型,提取其中包含的大数据节点,并针对每个节点提取闭频繁项集特征。通过极限学习方法,对上述提取出的特征项进一步分析得到全局最优解,结合待挖掘数据所属链路的负载情况,获取数据特征估计值。针对线性规划模型所涉及的数据进行特征提取,经过小波熵分解算法处理后,与数据特征估计值相结合,建立数据特征提取机制,得到数据关联规则特征提取结果。
1.3 构建卷积神经网络挖掘模型
可以将数据挖掘当成一个简单的分类问题,根据上述数据关联规则特征提取结果,将给定的数据集划分为多个子集,每个数据子集具有不同的主题和属性。根据数据挖掘要求,将数据仓库内的数据分为目标数据和非目标数据,其中目标数据即数据挖掘结果。采用神经网络训练的方式,描述数据属性与数据分类结果之间的联系,并构造一个分类决策树。
依托关联规则特征,提出一种以卷积神经网络为基础的数据挖掘模型,将每个数据关联规则特征看作模型输入值,通过卷积层、池化层和全连接层进行传递[12],并通过神经元运算输出最终结果,具体模型如图2所示。

图2 卷积神经网络数据挖掘模型Fig.2 Convolutional neural network data mining model
在图2所示的卷积神经网络数据挖掘模型计算过程中,输入数据和输出数据之间存在直接对应关系,但二者的实际关系是间接性的,造成这种现象的原因是输出误差。为提高卷积神经网络数据挖掘结果的准确性,并提高模型运算效率,以网络训练误差最小化为目标,建立相应的关系强化约束条件。这部分强化约束条件的主要功能是提升网络训练模型的学习能力,可以将其描述为诱导型约束模式,采用以下的约束引入方式:
(3)
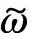
依托卷积神经网络构造的决策树,设置约束条件,包括权值约束和导数关系约束。权值约束的计算需要从偏导数入手,对卷积神经网络中乘积项的权值进行限制,保持权值固定不变,以保证数据挖掘的准确性。权值约束所对应的模型为
(4)
式中:S表示权值约束误差;D表示卷积神经网络内所有结构的连接权重。
导数关系约束的存在是为了降低各属性导数值的变化频率,最大限度降低数值变化对数据挖掘结果的影响,同时有利于每个有用属性的导数值呈现出均匀单调变化特点,便于判断数据分类结果的误差。导数关系约束模型的建立,需要先求解偏导数与输入数据所对应的线性回归曲线,并对比回归曲线上每个样本点的预测值和偏导数,得出约束误差计算结果:
(5)
式中:c表示样本点;φ表示输入层内神经元;F表示输入值;K表示样本点总数量;A、B表示偏导数与输入值组成的线性回归常数。将上述两个约束条件融入卷积神经网络数据挖掘模型中,得到符合要求的数据挖掘结果。
1.4 获取数据挖掘聚类结果
在上述卷积神经网络模型的基础上,融合模糊分类器,结合特征压缩方法实现顶岗实习管理系统数据的降维处理,再融入模糊聚类方法,以低开销为原则获取数据挖掘聚类结果。
分类器融合方法中,单个分类器为第0层,多分类器融合为第1层分类器,第1层分类器是模糊系统μ1。假设得到符合要求的数据挖掘结果具有λ个模式类,λ={λ1,λ2,…,λn},在融合模糊分类器中,需要将第0层分类器的输入样本εi转换为第1层分类器模糊系统μ1的输入样本,因此第0层的样本和模式类λ各个分类器的输出样本可表示为
(6)
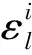
(7)
获取训练集后,采用冗余数据的高阶累积量特征压缩处理方法对数据聚类中心进行计算:
V={vij|i=1,2,…,I,j=1,2,…,J|},
(8)
式中:vij为冗余数据中第i个干扰向量;j为加权权重,可定义冗余数据的降维目标函数ρ。
设ri为第i类冗余信息特征状态,那么数据挖掘聚类结果
(9)
从顶岗实习管理系统中提取部分数据,分别构建测试样本集和训练样本集,并提取数据特征分布集和数据关联规则特征数量作为数据挖掘模型的输入数据。经过卷积神经网络的运算,可得出数据分类挖掘结果,步骤如下:①针对待识别的顶岗实习管理系统数据进行分析,获取规则项特征点;②针对卷积神经网络分类构造树,设置合理的加权值;③运用特征压缩方法进行降维处理,实现特征的分离、压缩处理;④设置合理的收敛条件,当数据分类挖掘结果满足条件时停止网络模型迭代计算,输出当前挖掘数据,若不满足收敛条件,则需要重复迭代计算步骤,直到满足收敛要求。
2 实验
2.1 实验数据
为验证本研究提出的基于卷积神经网络的顶岗实习管理系统数据挖掘方法的有效性,以某学院内的顶岗实习管理系统为研究对象,对系统内的数据进行挖掘。本实验所采用的顶岗实习管理系统内包含多种数据,具体功能结构如图3所示。

图3 顶岗实习管理系统功能结构Fig.3 Functional structure of post practice management system
为保证数据挖掘实验顺利进行,采用网络爬虫对顶岗实习管理系统内业务子系统和统计子系统的数据进行采集,获取实验数据集。采集数据是从该管理系统内直接导出的,保存为csv格式。
考虑到对原始导出数据直接进行实验分析会出现个人隐私泄露和数据不完整的问题,因此在实验准备阶段,需要对这些数据进行脱敏处理。将顶岗实习管理系统导出数据中的身份证号、通信地址等信息标注为隐私数据,从实验数据集内剔除,最终得到有效实验数据2 745条,从中随机选择1 000条数据作为测试数据集,再选择1 000条数据作为验证数据集,整理剩余数据形成训练数据集,作为后续实验的基础。
2.2 参数设置
本实验环境设置为Linux Ubuntu 18.04,依托TensorFlow框架,建立以卷积神经网络为基础的数据挖掘模型,模型相关参数如表1所示。

表1 模型参数Tab.1 Model parameters
运用卷积神经网络进行数据挖掘时,实验数据会划分为多个批次,按照批次来更新模型参数。批大小会对数据挖掘结果产生直接影响,批设置得过大会造成运行时内存不足,太小又会导致模型收敛性较差。因此,除了表1设置的模型参数,还需要在固定参数条件下,分析不同批大小对模型损失的影响,确定最合理的批大小。分别设置批大小为8、16、32、64、129、256,不同条件下模型损失影响情况如表2所示。

表2 批大小对模型损失的影响Tab.2 Impact of batch size on model loss
从表2可以看出,同样的批大小下,验证损失和测试损失极为相似,但是训练损失最初极小,随着批大小的增大而不断提升。这是因为模型在训练的过程中,会主动拟合训练数据集。本实验定义批大小时,着重观察验证损失和测试损失变化情况,可以看出当批大小为64时,二者达到最小值,分别为0.36和0.35,故设置批大小为64。
2.3 数据挖掘性能对比
模型参数设置完成后,运用卷积神经网络模型展开数据挖掘测试。在2 000条测试数据中,对顶岗实习管理系统中学生综合能力评价数据进行挖掘,同时采用基于决策树和基于一维卷积网络的方法进行数据挖掘。在相同的实验环境下,获取3种方法的数据挖掘结果(表3)。
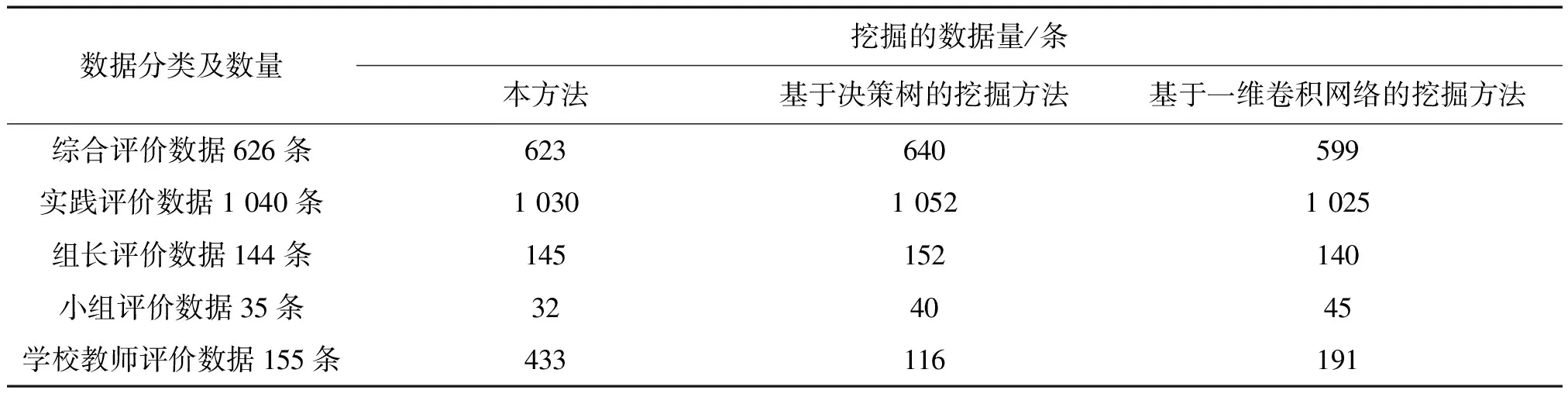
表3 数据挖掘结果对比Tab.3 Comparison of data mining results
以表3数据为基础,将数据挖掘的泛化误差作为衡量数据挖掘方法性能的指标,具体计算公式如下:
(10)
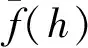
以不同方法得到的数据挖掘结果为基础,采用公式(6)进行计算,得到如图4所示的泛化误差对比结果。
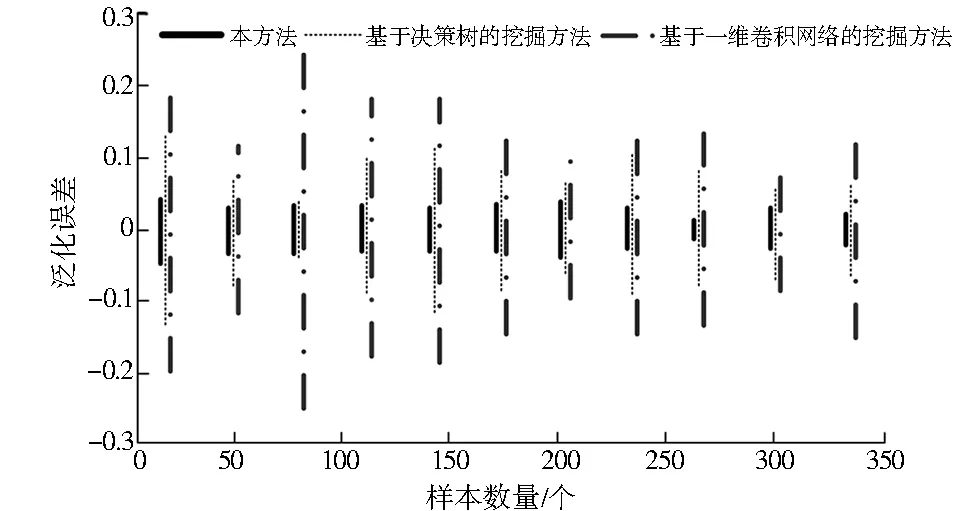
图4 不同数据挖掘方法的泛化误差对比Fig.4 Comparison of generalization errors of different data mining methods
根据图4可知,基于卷积神经网络的数据挖掘方法在实际应用过程中泛化误差控制在[-0.05,0.05],基于决策树方法的数据挖掘结果泛化误差为[-0.14,0.13],基于一维卷积网络方法的数据挖掘结果泛化误差为[-0.27,0.25]。本研究所提方法与其他两种方法相比泛化误差较小,能够保持在[-0.05,0.05],这说明以卷积神经网络为核心的数据挖掘方法挖掘精度较高,可以获取更加准确的数据挖掘结果。
3 结语
为从顶岗实习管理系统中准确提取所需要的数据,设计了一种以卷积神经网络为核心的数据挖掘模型。经实验验证,采用所提方法的泛化误差比传统方法有了大幅度降低,达到了预期目标。
