基于改进卷积神经网络的番茄品质分级方法
2023-09-15阮子行张金玲
阮子行, 黄 勇,, 王 梦, 史 强, 张金玲
(1.新疆农业大学机电工程学院,新疆 乌鲁木齐 830052; 2.新疆工程学院机电工程学院,新疆 乌鲁木齐 830023)
中国是亚洲地区番茄产量最大的国家,同时也是世界上番茄产量最大的国家,番茄在中国农作物中的种植面积占比较高,其中在2020年仅中国新疆地区的番茄产量便达到8.242×106t[1]。新疆地区番茄的种植面积连续多年保持在46 667 hm2以上,但是纵观整个中国,番茄的产业化水平仍较低,加工产品的附加值也较低,是中国番茄产业遇到的重要问题[2],其中番茄精确的品质分级技术是亟待解决的重要问题之一。近年来,为了提高农产品品质分级的作业效率,从而解决劳动力不足的问题,农产品品质分级成为农业的重点工作之一[3]。高精度的农产品分级不但可以提高生产效率,而且可以提高农产品的整体质量,使其更有利于长期存储[4-5]。品质检测的手段有很多种,随着图像处理与机器视觉的发展,基于机器视觉和深度学习的品质分级技术已经成为研究热点[6]。本研究旨在从番茄外部品质分级的角度出发,通过深度学习手段为番茄品质分级提供一种新方法。
目前,国内外学者在农产品品质分级方面做了大量工作,其中Blasco等[7]开发的机器视觉算法基于贝叶斯估计分割水果与背景,并通过尺寸、颜色、茎的位置和外部瑕疵的检测在线评估橙子、桃子和苹果的质量,该分类系统经过在线测试苹果,在批量分类水果时获得了良好的性能,瑕疵检测、尺寸估计的准确度分别为86%、93%。Sayed等[8]提出了1种基于海洋捕食者算法(MPA)和卷积神经网络的柑橘病害分类的新混合方法。MPA用于找到批量大小、退出率、退出期和最大训练批次,在柑橘病害分类方面的整体准确率可达100%,表明所提出的基于MPA优化的ResNet50具有优越性。Bhole等[9]基于迁移学习的预训练SqueezeNet模型,根据缺陷、形状、大小和成熟度等参数对杧果进行评估分级,2份数据集分别为杧果果实的RGB图像和热图图像,测试结果表明,该系统对2份数据集的分类准确率分别为93.33%、92.27%,RGB图像、热图图像的训练时间分别为30.03 min、7.38 min。何进荣等[10]通过对经典网络模型进行优化,采用经典的卷积结构作为苹果外部特征提取器,并采用批量归一化的方式优化模型,采集了19 500张图片,按照3∶1的比例划分数据集,结果显示,DXNet模型的分级准确率达到97.84%。胡发焕等[11]采用形态学手段将目标脐橙与背景分离,并捕捉脐橙的果面缺陷、尺寸、表面颜色等特征,将其输入支持向量机,训练后的品质分级识别率达到90.5%,并且实时性较好。
本研究拟以分选台常见的6种番茄样本作为研究对象,设计改进网络结构,并通过批量归一化和注意力机制对其进行优化,研究优化后的模型整体性能与批量归一化、注意力机制对模型的影响,以期探究不同优化算法和单一背景数据集对网络模型性能的影响。
1 材料与方法
1.1 数据集
本试验中的所有番茄样本均购自新疆乌鲁木齐番茄市场,番茄品种为樱桃番茄,灯光由普通室内照明用日光灯提供,采用一加8手机进行图像采集,番茄的外观形态共6种,详见图1。

图1 常见番茄的外观形态Fig.1 Common types of tomatoes
经过筛选后,数据集中共有1 455张图片,各类番茄的具体图片数量见表1。为了获得更好的训练效果,在网络训练前对原始数据进行一些处理。(1)由于不同网络模型中图片数据的输入尺寸不同,所以要根据不同网络模型将图片数据放缩至规定尺寸和格式,本研究中的图片均采用JPG格式[12]。(2)由于大量数据样本可以增加模型训练的准确度,本研究拟通过任意角度旋转剪切、增强对比度、引入噪声和水平翻转等手段进行数据增广[13-14]。增强后的各类样本图片数据集数量如下:正常番茄1 758张,绿柄番茄1 650张,霉变番茄1 698张,破裂番茄900张,未成熟番茄1 554张,软烂番茄1 170张,共计8 730张,并用数字1~6给不同外观形态的番茄编号,如表1所示。
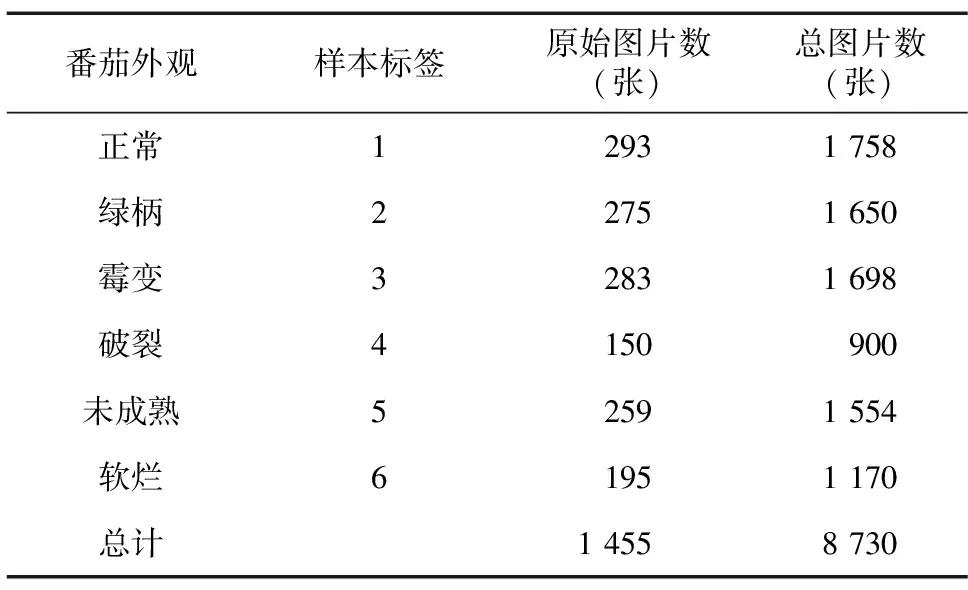
表1 番茄样本图片的原始数量及增广后的数量
1.2 试验环境
模型搭建和训练所用试验环境如下:电脑操作系统为64位Win10家庭版,软件平台采用Matlab 2022a中的深度网络设计器(Deep learning toolbox),显卡为NVIDIA GeForce RTX 3050 Laptop(4 G显存),计算统一设备架构(CUDA)版本为11.6.0,CUDNN版本为11.3,采用三星16 G内存、三星512 G固态硬盘。本网络训练均基于Matlab2022a平台,采用图形加速器加速进行训练,试验批次(Batch size)为16次,训练轮数为30轮,迭代次数为9 810次。
2 卷积神经网络模型的构建
2.1 网络模型结构
2.1.1 卷积层结构 本研究设计的卷积网络选取6个卷积层,分别为Conv1、Conv2、Conv3、Conv4、Conv5、Conv6,其中前5个卷积层的作用是捕捉图像信息特征,第6个卷积层采用1×1的卷积核,其主要作用是实现通道维度的变化,减少参数量并结合激活函数引入更多非线性特征[15-16]。其中卷积核尺寸、步长、各个卷积核数量及Padding参数见表2。

表2 网络中各个卷积层参数
本网络中的激活函数均采用ReLU激活函数,采用4个池化层(其中3个为最大池化层,1个为全局平均池化层)和1个全连接层,本研究图片数据集中的番茄共有6种分类类型,因此将最后全连接层节点数设为6个。
2.1.2 全连接层 目前常见的卷积神经网络有很多种,其中LeNet、AlexNet和VGGNet这3种卷积神经网络发布得较早,其网络结构没有分支,相对其他网络结构更为简洁。第1次利用大批量图像数据集完成深层卷积神经网络结构的便是AlexNet网络,它正式打开了深度学习的大门,该网络的权重层有8层(5层卷积层、3层全连接层),进行1 000种分类时模型可计算的参数量为6.09×107[17-18]。对AlexNet网络参数量进行分析,结果见表3。

表3 AlexNet网络各层参数
对AlexNet网络各层参数进行统计可以发现,全连接层参数数量为58 631 144个,占整个网络参数数量的96.17%,5层卷积层的参数量占比不足4.00%。参数过多使得训练过程对设备的要求更高,造成计算效率降低,更容易出现过拟合,并且也限制了网络在移动平台中的布置[19-20]。
结合经典网络AlexNet的网络参数表可以看出,全连接层中包含整个网络的绝大多数参数信息,需要用其他结构代替,从而进行优化改进。孙俊等[21]、张华鹏[22]针对AlexNet模型数据参数庞大的问题,通过全局平均池化层代替全连接层的方式优化了AlexNet网络模型参数,使得模型参数的内存需求仅为2.6 MB。另一种结构采用1×1的卷积操作来实现,1×1的卷积操作可以在保证参数量为1的同时实现网络通道数的变换,并配合非线性激活函数引入更多非线性特性[23-24]。
结合以上2种方式,本研究设计的卷积神经网络结构首先使用1×1的卷积操作以增加通道数,经过全局池化层降低参数量,通过全连接层将上一层的全局池化层进行全连接,并传递给Softmax分类函数实现分类输出,该模型结构相较于拥有3个全连接层的结构,参数量可以得到极大减少,训练时可使图形处理器(GPU)中CUDA内存占用率由原来的70%~80%降至30%~40%。
2.2 网络模型结构的优化
2.2.1 引入批量归一化层优化[25]在卷积神经网络中,当底层网络梯度发生微小改变时,经过激活函数及一系列线性映射后,上层梯度会发生较大幅度的变化,随着网络层数的增加,这种变化会不断被放大,网络也会不断适应梯度的变换,导致网络越来越难以被训练。批量归一化(Batch normalization, BN)操作是将这些输入值规范化至1个合适范围内,在不影响梯度变换大趋势的前提下降低网络整体大幅度变化带来的不确定性,可以增加数据的稳定性。数据的稳定传递可以加快模型训练的速度,降低网络对参数的敏感程度,使得由超参数造成的网络变化规律更加明显,网络学习更加稳定。在本网络中选择在Conv2、Conv4及Conv6后增加批量归一化操作,批量归一化公式如下:
(1)
(2)
(3)
式中:X为输入数据;Y为输出数据;β、r分别是平移参数、缩放参数,在反向传播中训练得到;ε>0,且是很小的数;m为输入数据数量;u为输入数据的均值;δ为输入数据的标准差。
网络的整体结构如图2所示。

图2 本研究设计的神经网络结构Fig.2 Neural network structure designed in this study
2.2.2 通过注意力机制优化[26]敏锐度指人视网膜对不同物体具有的信息处理能力,表现为重点关注某些部分而忽视某些部分。在神经网络中,通过给予不同特征不同权重来实现注意力的分配,将更多计算资源分配至更重要的任务中,从而更加高效地实现信息处理[27]。
图3为压缩激励注意力模型结构,该模型学习卷积过程中通道之间的相关性,从而实现注意力分配,具体分为3个部分。(1)压缩(Squeeze)。是通过1个全局平均池化层将特征图压缩为1×1×C的向量,再经全连接层(FC)把神经元数量减少,该操作通过减少特征图的宽、高从而降低计算量,除去过多的无用信息,其中降维系数(r值)选择16。(2)激励(Excitation)。压缩后C/r个通道数的特征图,由激活函数ReLU激活,赋予每个通道不同的权重,再经FC将C/r个通道恢复成C个通道,得到1×1×C尺寸的数据。最后由Sigmoid激活函数使各个通道的权重归一化。此时该向量与输入特征图有相同的通道数,并且每个通道的权重不同。(3)Scale操作。得到1×1×C向量后,与输入特征图的W×H×C进行Scale操作,赋予输入特征图权重,得到不同权重的W×H×C特征图。
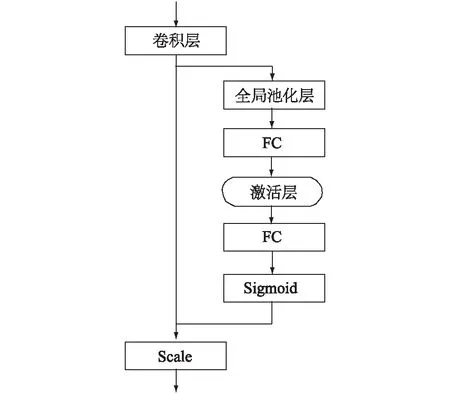
FC:全连接层;Sigmoid:一种函数名称;Scale:通道权重相乘。图3 压缩激励注意力模型结构Fig.3 The structure of the squeeze excitation attention model
引入压缩激励模块(SE模块)进一步提升网络模型的精度,在图2神经网络结构的基础上,在卷积层1、卷积层2、卷积层3、卷积层4、卷积层5后均加入SE注意力机制模块,以此优化整个网络结构。
3 结果与分析
3.1 混淆矩阵分析
选用数据增广后的6类番茄样本数据,共计8 730张图片,按照4∶1的比例划分为训练集与测试集,并按照网络输入大小裁剪为227像素×227像素×3(宽×高×通道数)的尺寸,图4为本研究设计的卷积神经网络对6种不同番茄外观形态进行分类的混淆矩阵。

图4 本研究模型的混淆矩阵Fig.4 The confusion matrix of the model constructed in this study
对样本进行测试后分别计算精确度(P)、召回率(R)、精确度和召回率的调和平均数(F1),其公式如下:
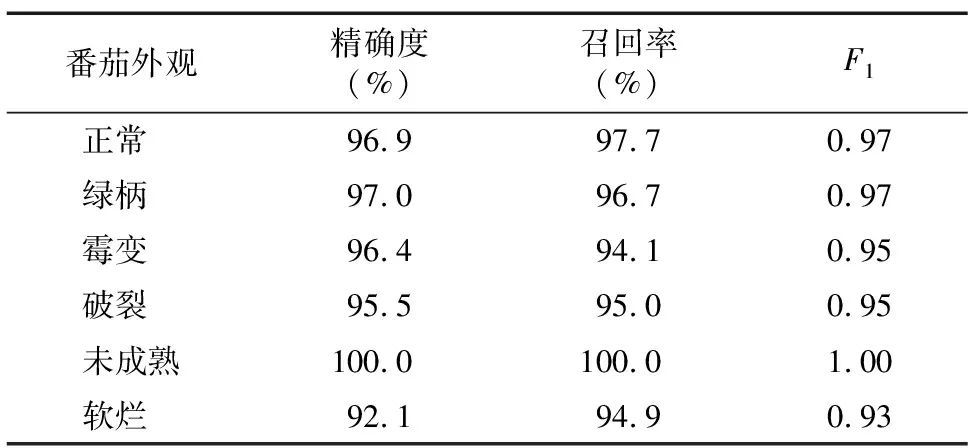
表4 6类番茄评估指标的对比
(4)
(5)
(6)
式中:TP代表预测为正的正样本;FP代表预测为正的负样本;FN代表预测为负的正样本。
表4为6类番茄外观形态的3种分级评估指标参数,其中未成熟番茄的外观形态分级效果最精确,软烂番茄的外观形态分级效果最差,6类番茄外观形态的综合分类精确度(表5中的测试精度)达到96.57%,表明本研究设计的神经模型对番茄各个外观形态的识别能力均较强。
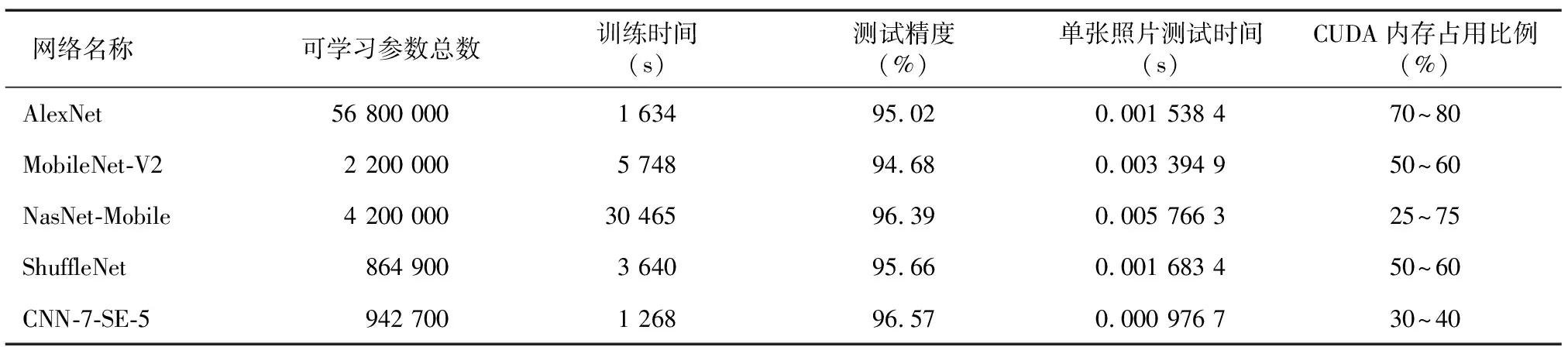
表5 5种模型训练参数的对比
本研究设计并优化后的网络以CNN-7-SE-5作为记号。将目前常见的4种神经网络模型输出节点数微调后,用以自建番茄数据集训练网络,并与本研究设计的网络模型的训练数据进行对比。从图5a可以看出,该网络模型在收敛速度上相较于AlexNet、MobileNet-V2、NasNet-Mobile、ShuffleNet 4种模型更快,迭代500次左右就优先达到90%的训练精度(准确率),并且整体训练精度变化稳定,没有大幅度的变化,最终5种模型的训练精度都在95%以上。图5b可以看出,本研究设计的模型也是收敛最快的,迭代1 000次左右便最先将损失值降至0.25,最终5种模型的损失值均在0.13左右。

a:训练精度曲线;b:训练损失曲线。图5 5种模型训练曲线Fig.5 Five model training curves
本研究设计的模型结构,以自建的6种番茄外观形态分类数据为数据集进行模型训练,得到表5中的数据。可以看出,该模型在识别精度上相较于经典模型并没有明显优势,但是在参数量、单张照片测试时间及训练时间上的优势明显,训练时间减少了22%~96%,测试精度提高了0.18~1.89个百分点,单张照片测试时间减少了37%~83%,此外,CUDA内存占用比例也得到了一定程度的降低。
3.2 试验模型性能探讨与分析
3.2.1 优化后操作对网络模型的影响 分别对优化后的网络模型(引入SE模块、批量归一化)和未优化的网络模型进行训练与测试,对比在相同数据集、环境、超参数条件下2种模型的训练精度和损失值随迭代次数的变化趋势。如图6所示,在模型训练过程中共迭代9 810次,加入SE模块和批量归一化后的网络模型在前2 000次迭代中的收敛速度明显优于未优化网络的模型,训练好的模型在测试集中的测试精度也由未优化的93.99%提升至优化后的96.57%,提高了2.58个百分点。
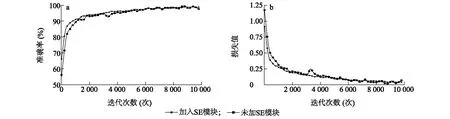
a:训练精度曲线;b:训练损失曲线。图6 模型优化前后性能对比曲线Fig.6 Performance comparison curves before and after model optimization
图6显示,与优化后的网络相比,未优化的网络在训练过程中准确率与损失值变化波动起伏较大,通过本研究中的优化操作可以使网络模型的训练更加稳定,更有利于网络模型的建立,在测试精度、网络训练稳定性上都能得到一定程度的提升,说明本研究的优化方式是十分有效的。
3.2.2 注意力机制对网络模型性能的影响 为了验证注意力机制SE模块对具体目标的影响,对比番茄外观形态原图和3种网络的Conv5层中激活区域最大特征的通道图(AlexNet网络、本研究设计的未加SE模块的网络、本研究设计的增加SE模块后的网络)。由于AlexNet网络与本研究设计的网络同为采用5层卷积层提取特征的网络,因此选用AlexNet网络进行对比。图7b为AlexNet网络Conv5层中激活区域最大的特征图,对比原图(图7a)可以明显看出,正向激活区域主要集中在番茄左上角高光区域及周边区域。由图7c可以看出,本研究设计的网络在未加入SE注意力机制时,Conv5层最大激活区域图中整个正向区域相较于图7b明显增加,包含在整个番茄四周。由图7d可以看出,加入SE注意力机制的Conv5层最大激活区域中的激活区域得到进一步增加,整个番茄区域中绝大部分都被正向激活,使得目标特征得到更多关注,也避免了番茄表面局部特征和背景噪音的干扰,能够增强网络分类的泛化能力与鲁棒性。

a:原图;b:AlexNet网络激活;c:未加SE模块激活;d:加SE模块激活。图7 3种模型的Conv5层激活区域对比Fig.7 Comparison of the activation regions of the Conv5 layer of the three models
3.2.3 优化算法对模型性能的影响 在相同数据集、参数设置的情况下,分别采用SGDM、Adam、RMSprop这3种常见的优化算法对改进后的卷积神经模型进行网络训练对比。从图8可以看出,在前1 000次迭代中,3种优化算法的训练精度曲线和损失曲线基本保持重合;在迭代次数达到1 000次后,3条曲线的轨迹开始发生变化,其中SGDM优化算法的训练精度曲线增加幅度和速率都高于采用Adam、RMSprop优化算法的卷积模型;损失值降低幅度和速率也高于采用Adam、RMSprop优化算法的卷积模型。采用SGDM、Adam、RMSprop 3种优化算法的最终模型测试精度分别为96.57%、94.56%、94.28%。由此可见,SGDM优化算法相较于Adam、RMSprop优化算法更适合本模型,测试精度分别提高了2.01个百分点和2.29个百分点,因此在本研究中,SGDM优化算法是更好的选择。

a:训练精度曲线;b:训练损失曲线。图8 3种优化算法对应的训练曲线Fig.8 Training curves corresponding to the three optimization algorithms
3.2.4 单一背景数据集对网络性能的影响 通过传统的图像处理手段,先进行滤波降噪,消除噪声干扰,再通过在RGB和HSV颜色空间的不同算子实现了6种类型番茄与背景的分割,其中注意避免高亮区域对背景分离的干扰,结合RGB空间和YIQ空间两个空间信息特点,利用布尔运算实现目标的完整分割,大部分情况分割效果较好,如图9所示。通过对比两组数据集在相同模型下的训练效果可以发现,单一黑色背景数据集训练出的模型测试精度为96.97%,相较于未去除背景的数据集测试精度提高了0.40个百分点,可以推测背景中存在影响学习分类的噪声,影响了模型的学习,移除背景后减少了背景干扰,使得分类精度得到提升。

第1行的3张图从左到右依次为去除背景的正常番茄、去除背景的绿柄番茄、去除背景的霉变番茄,第2行的3张图从左到右依次为去除背景的破裂番茄、去除背景的未成熟番茄、去除背景的软烂番茄。图9 消除背景的6种番茄Fig.9 Six tomato samples without background
消除背景后,虽然测试精度得到小幅度提升,但是提升幅度并不明显,可能是仍有部分数据并未很好地实现背景分割导致,详见图10。由于光线照射原因导致背景明暗程度不一致,使得番茄目标不能从背景中完全分割出来,整体数据样本存在小部分数据不一致,存在的部分背景在训练过程中会引入不确定的干扰因素,导致训练精度提升并不明显。
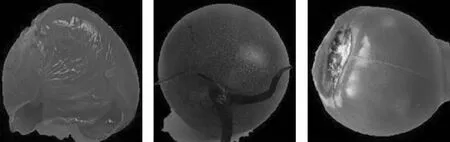
3张图从左到右依次为未完全去除背景的破裂番茄、未完全去除背景的绿柄番茄、未完全去除背景的霉变番茄。图10 背景未完全分割的番茄样品Fig.10 Tomato sample image with incompletely segmented background
4 结 论
以自采集的6类番茄外观形态数据集为研究对象,通过数据增广对数据进行6倍扩增,构建并优化卷积神经网络算法,对6类不同品质番茄图像进行检测与分类,讨论网络模型训练效果并与其他模型进行对比,探究归一化操作、注意力SE机制、3种优化算法、数据单一背景等对模型性能的影响,得到如下结论:
(1)本研究设计的卷积神经网络结构中使用1×1的卷积层和全局平均池化层并通过1个全连接层实现所有神经元的全连接,并传递给Softmax分类函数实现分类输出,与3个全连接层相比,此结构的参数量可以得到极大降低,训练时使得GPU中的CUDA内存占用比例得到了一定程度的降低。
(2)利用批量归一化和压缩激励模块(SE模块)进行网络结构优化后,与未优化的网络模型相比,优化后的网络模型测试精度提高了2.58个百分点。并且对比传统经典AlexNet、MobileNet-V2、NasNet-Mobile、ShuffleNet 4种网络模型,具有收敛速度更快、模型体积更小、计算量更少等优势,训练时间减少了22%~96%,测试精度提高了0.18~1.89个百分点,单张照片测试时间降低了37%~83%。
(3)采用批量归一化和注意力机制优化后的网络训练过程更加稳定,模型注意力更多集中在番茄整体上,正向激活区域也更多,在一定程度上降低了背景干扰,提升了算法的鲁棒性和泛化能力。
(4)探究3种优化算法SGDM、Adam、RMSprop对模型的影响,结果表明,SGDM优化算法的模型测试精度相较于Adam、RMSprop优化算法分别提高了2.01个百分点和2.29个百分点,可见SGDM优化算法更适合该网络模型与数据集。为了探究单一背景对模型性能的影响,通过图像处理去除数据集背景,重新训练后模型的准确率提高到96.97%,相较于未去除背景的数据集测试精度提高了0.40个百分点,可见去除背景在一定程度上降低了背景噪点的干扰,使得模型准确度得到提升。
