基于联邦学习的下肢康复评估算法与实现
2023-09-13梁朝晖朱笑笑曹其新马燕红徐义明
梁朝晖,朱笑笑+,曹其新,马燕红,徐义明
(1.上海交通大学 机械与动力工程学院,上海 200240;2.上海交通大学附属第六人民医院 康复医学科,上海 200233)
0 引 言
由于涉及到病人隐私与信息安全等问题,目前在康复医疗领域中不同医疗机构所采集的患者数据无法互通,导致难以训练出一个泛用性强、准确度高的神经网络模型。针对这一问题,联邦学习提供了解决思路。联邦学习是一种在各客户端节点上进行分布式训练,再在服务器端对全局模型进行整合更新的机器学习框架。联邦学习期间,所有本地数据都保存在所属机构内部而无需对外开放,从而实现数据隐私保护。可见,将联邦学习技术应用于康复领域有助于打破不同机构之间的数据孤岛状态,通过多方协同训练出泛用性强、准确度高的下肢康复评估模型。
由此,本文提出一种基于联邦学习的下肢康复评估算法,搭建联邦学习系统并设计GRU-Inception康复评估神经网络模型进行训练,实现下肢损伤部位分类及康复情况评分任务。
1 相关工作
随着计算机技术发展,已有国内外学者利用神经网络模型进行康复评估。闫航等[1]提出Pose-AMGRU模型,利用摄像系统采集到的视频信息提取人体姿态,实现康复动作识别。罗坚等[2]通过深度传感器采集得到的点云数据,结合人体特征语义,设计一种Conv GRU网络实现下肢异常步态检测。王金甲等[3]利用可穿戴设备采集患者下肢运动数据,并设计相应的卷积神经网络,实现对帕金森症患者的冻结特征识别任务。
上面的研究中可以看出,在利用传感器采集到足够的康复数据后,康复评估算法的研究多集中于神经网络模型的设计以及实现上。然而由于医疗机构之间数据不互通,这些方法往往难以在实际的医疗领域应用当中取得满意效果。针对患者与医疗机构的数据隐私问题,目前已有国内外学者将联邦学习[4]应用在医疗领域中,展开相关研究工作。Lee J等[5]利用联邦学习平台,在不共享患者信息情况下实现跨机构的患者相似性学习。Liu D等[6]开发一种两阶段联邦学习方法,对跨机构病例进行患者表征学习。王生生等[7,8]在联邦学习框架下完成了医学影像检测及分割等任务。
针对上面研究中康复评估神经网络模型所存在的数据安全问题,结合联邦学习的隐私保护训练机制,本文所提出的基于联邦学习的下肢康复评估算法能在本地数据不外泄的情况下高效完成模型训练,并取得较好的损伤分类以及评分结果,有助于提升模型在实际康复医疗场景下的表现。
2 算法设计与实现
2.1 整体系统框架
本文采用客户端-服务器架构来搭建联邦学习系统,其整体框架如图1所示。每个客户端节点代表一个医疗机构接入到联邦学习系统内。服务器作为联邦学习的核心节点,与各个客户端节点构成双向通讯链路。服务器部署在可信的第三方云平台上。联邦学习的模型训练过程分为初始化、客户端选择、模型广播、本地训练、全局更新等阶段。
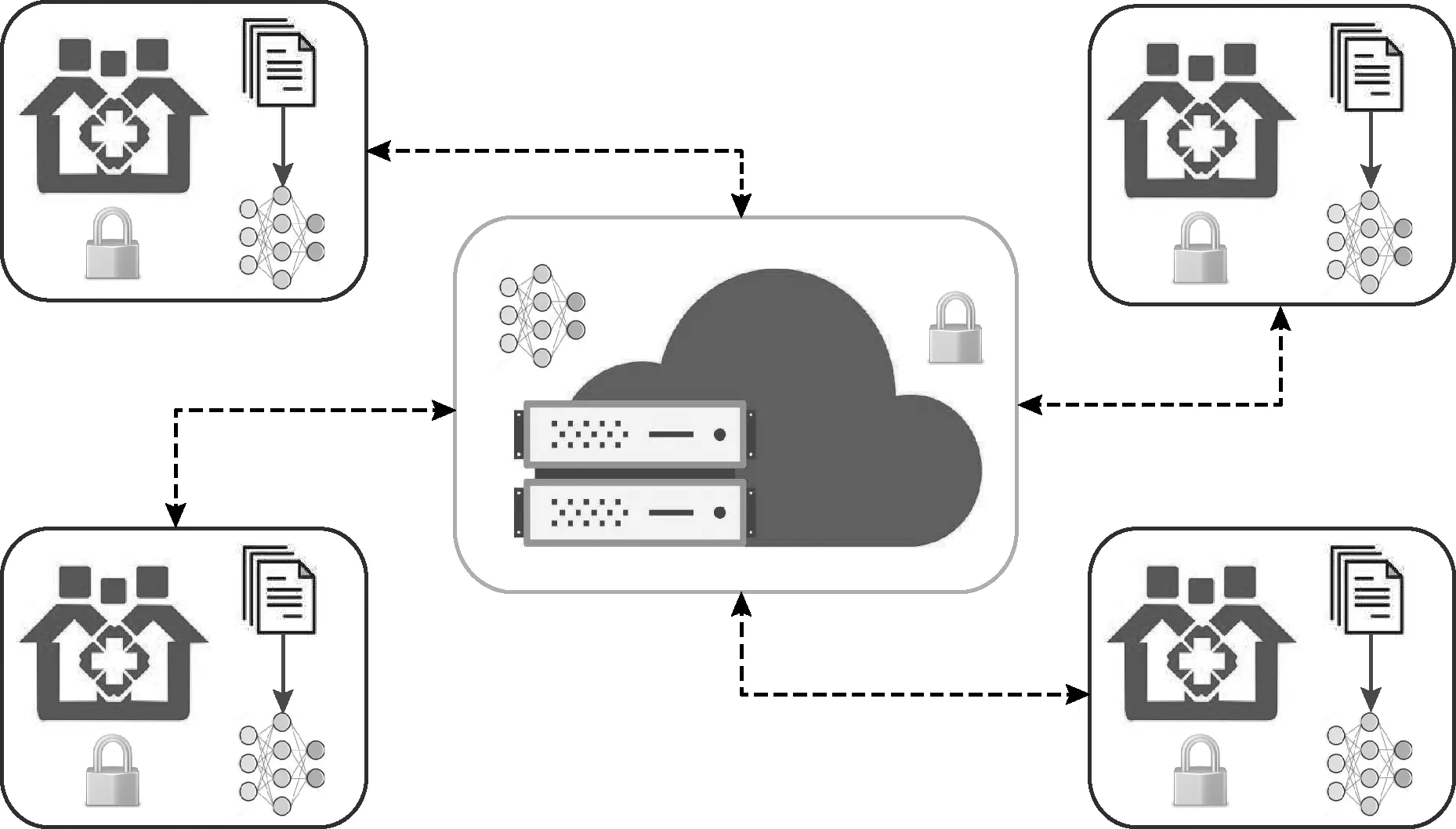
图1 联邦学习整体框架
训练开始前,服务器首先进行初始化,设定联邦学习参数。为提高通讯效率,每一轮训练开始前需要进行客户端选择,选中的客户端可参与本轮训练。选择完成后,服务器向选中客户端广播发送上一轮全局模型。各客户端将该模型作为初始值,利用本地数据及resSGD优化器对其进行训练。模型更新值需经量化编码压缩后才上传服务器,减轻通讯负担。最后服务器端基于高斯差分隐私机制对模型更新值进行聚合来实现全局更新,得到本轮全局模型。至此一轮训练完成,当达到设定训练轮数或触发其它终止条件后联邦学习结束。
针对下肢康复评估问题,本文设计了GRU-Inception网络模型来实现下肢损伤分类与评分。该模型利用GRU提取输入的时序关节角度数据特征,并采用多个Inception模块级联而成的分类器处理得到受测者下肢损伤部位分类结果以及康复评分结果。通过建立联邦学习系统并对所设计的GRU-Inception网络模型进行训练,本文所提出的基于联邦学习的下肢康复评估算法有助于打破医疗机构间的数据壁垒,在保护数据隐私的基础上通过跨机构多方协同训练来提升模型效果。
2.2 客户端节点选择机制
在联邦学习系统当中,模型训练过程被分布到大量客户端节点上。每个通讯轮次中,上行(客户端→服务器)和下行(服务器→客户端)传输都需要占用大量网络带宽及传输时间。在保证模型训练效果基础上,本系统利用客户端节点选择机制来减少每轮参与训练客户端节点数目,提高联邦学习效率。该机制综合考虑各客户端节点网络连接情况、新增患者数据量以及上次参与训练间隔时间等因素,计算出本轮参与训练的客户端节点列表。其中网络条件好,数据量多,训练间隔时间长的节点更有可能纳入本轮训练节点列表中。算法具体流程如下:
算法:客户端选择
输入:节点队列d1,d2, 参与训练客户端数K, 评分权重w1,w2, 本轮轮次t;
输出:参与训练客户端节点列表list;
步骤1 初始化,若t=1, 将所有节点加入d1。
步骤2 下标i为队列编号,当tmodi=0, 则服务器向队列di里的节点发送请求,列入候选。
步骤3 若某节点限定时间内无反馈,则将其移动到d2。 其它节点加入d1并计算其得分
scorek=w1×numk+w2×interk
(1)
其中,下标k代表该节点的编号;numk为该节点新增数据量;interk为该节点距离上次参与训练的轮次间隔。
步骤4 将得分top-K的节点加入本轮参与训练的客户端节点列表list。
2.3 本地训练与模型压缩
参与训练的客户端节点列表通过选择机制产生后,服务器将上一轮的全局模型广播发送给各个选中客户端节点。客户端节点接收全局模型,并利用本地数据以及resSGD优化器进行训练。在第t+1轮,客户端节点本地训练步骤如下:
算法:本地训练
输入:上轮全局模型Wtg; 学习率lr; 本地训练迭代次数epoch; 限制项参数μ;
输出:局部模型参数更新ΔWt+1k, 其中上标t+1代表联邦学习轮次,下标k表示客户端节点编号,k∈[1,K];
步骤1 初始化局部模型参数W0k=Wtg。
步骤2 设定学习率lr, 迭代次数epoch, 输入批大小bs, 设定均方误差函数MSELoss。
步骤3 设定自定义优化器resSGD,其更新方法为
Updres=μ(We-1k-W0k)
(2)
Wek=We-1k-lr(grad+Updres),e∈[1,epoch]
(3)
其中,上标e为客户端迭代次数,Updres为限制项,grad为本次迭代训练的梯度。
步骤4 进行本地训练,直至预设迭代次数epoch后训练结束,返回局部模型参数更新
ΔWt+1k=Wepochk-W0k
(4)
下肢康复评估任务既包括损伤部位的多标签分类问题,也涉及到评估分值的回归问题。而本地训练中所采用的均方误差损失函数能对各类别的预测概率与真值进行对比,符合下肢康复评估模型任务要求。在resSGD优化器中,加入如式所示(2)的限制项,其目的是使本地训练更新后的局部模型和全局模型之间不至于相差过大,防止客户端节点数据异构和系统异构导致模型发散问题,保证局部模型和全局模型的收敛一致性[9]。
当模型文件较大时,如果直接将本地训练后的局部模型更新值上传服务器,可能会导致网络带宽受限的客户端节点占用过多通讯时间,影响模型聚合更新进程。作为一个折中方案,本系统利用量化编码压缩算法,牺牲一定精度来对局部模型更新参数进行压缩。量化编码压缩算法分为两步:随机正交变换以及量化编码,其流程如下:
算法:模型压缩
输入:局部模型参数更新ΔWt+1k∈p×q, 且k∈[1,K];t+1为本轮训练轮次;K为本轮参与训练的客户端数;
输出:压缩模型更新参数ht+1k∈1×pq; 随机种子seedt+1k; 最大值及最小值hmint+1k,hmaxt+1k;
步骤1 将局部模型更新参数展开成向量
Hk=flatten(ΔWt+1k)
(5)
步骤2 生成随机种子
seedt+1k=rand()
(6)
步骤3 通过QR分解随机矩阵,获取随机正交矩阵
mk=randmatrix((pq,pq),seed)
(7)
Qk,Rk=QR(mk)
(8)
步骤4 向量随机正交变换
h*k=Qk×Hk
(9)
步骤5 向量各个分量进行量化,最终得到ht+1k
hmint+1k=min(h*k),hmaxt+1k=max(h*k)
(10)
ht+1k[i]=int(65535(h*k[i]-hmint+1k)hmaxt+1k-hmint+1k)-32768
(11)
式(9)中的随机正交变换步骤目的是使变换后的向量在各维度上的尺度较为一致,减少量化编码带来的损失。Suresh等[10]的研究表明,如果在量化之前对向量应用随机旋转(用随机正交矩阵乘以待量化的向量),可使量化误差降低一定比例。原始模型更新参数数据类型为32位浮点数,通过量化步骤将其映射到-32 768~32 767范围内的整数区间当中,即可使用16位整型数来表示。后续通过尺度因子以及压缩后的整型向量,可对原始浮点数向量进行还原恢复。量化编码方法以牺牲一定精度为代价可获取较好的压缩效果,将待传输的模型文件大小降为50%,从而大大减轻服务器与客户端节点之间的传输压力,加速联邦学习进程。
2.4 高斯差分隐私全局更新
在服务器节点获取到客户端节点所上传的局部模型更新后,需要利用全局更新算法计算出一个全局模型,完成本轮次的训练。本系统已在客户端本地训练的resSGD优化器中引入限制项,从而保证局部模型和全局模型的收敛性,因此在全局更新阶段采用联邦平均算法[11]即可获得较好效果。然而若服务器遭遇数据攻击,第三方可能从局部模型参数更新中推断出客户端节点的训练贡献,甚至存在原始数据泄漏的风险。为解决这一问题,本系统在联邦平均算法基础上引入高斯差分隐私机制来保护数据安全,并在计算过程中进行因子缩放来对噪声进行限制,保证模型可用性。
差分隐私主要技术手段是往原始数据中添加一定的噪声实现混淆,确保其满足隐私要求。在差分隐私技术中,利用高斯噪声实现ε-δ差分隐私的方法被称为高斯机制。给定隐私算法M,其定义域为D,值域为R。当算法M对任意两个数据t,t′∈D得到结果t*∈R时,若满足下面不等式,则算法M满足ε-δ差分隐私
Pr[M(t)=t*]≤eε×Pr[M(t′)=t*]+δ
(12)
其中,Pr为概率分布函数;ε为隐私预算,和噪声呈负相关关系,和数据可用性成正相关关系;δ为松弛项,表示系统对差分隐私失效的容忍度。
σ=Δ2f2ln(1.25/δ)ε
(13)
M(D)=f(D)+N(0,σ2)
(14)
其中,Δ2f是函数f在L2范数下的敏感度,函数N(0,σ2) 生成均值为0方差为σ2的随机高斯噪声。综合上述高斯差分隐私机制及联邦平均算法,本系统中服务器节点全局更新算法流程如下:
算法:高斯差分隐私全局更新
输入:压缩模型更新参数ht+1k; 随机种子seedt+1k; 最大值及最小值hmint+1k,hmaxt+1k; 噪声阈值th; 隐私预算ε; 容忍度δ; 最大通讯轮数U; 上一轮全局模型Wtg;
输出:本轮全局模型Wt+1g, 其中上标t+1代表联邦学习轮次;
步骤1 将压缩模型更新参数进行反量化
h*k[i]=hmaxt+1k-hmint+1k65535(ht+1k[i]+32768)+hmint+1k
(15)
其中,i∈[1,pq] 代表向量各分量
步骤2 根据随机种子生成正交矩阵进行反变换,并将参数向量还原为矩阵形式
mk=randmatrix((pq,pq),seedt+1k)
(16)
Qk,Rk=QR(mk)
(17)
Hk=QTk×h*k
(18)
ΔWt+1k=unflatten(Hk)
(19)
步骤3 高斯噪声计算
将函数敏感度限制为各客户端参数更新的L2范数中值,后续通过缩放来限制噪声
Δ2f=median(ΔWt+1k2),k∈[1,K]
(20)
根据式(13)计算高斯噪声标准差σ,并为各客户端计算缩放因子
Sk=min(1,Δ2f/ΔWt+1k2)
(21)
步骤4 全局更新计算
ΔWg=1K∑Kk=1(Sk×ΔWt+1k+N(0,σ2))
(22)
Wt+1g=Wtg+ΔWg
(23)
步骤5 计算噪声强度并判断是否继续训练
ps=(Wt+1g2)2pq,pn=σ2/K
(24)
snr=10*lg(ps/pn)
(25)
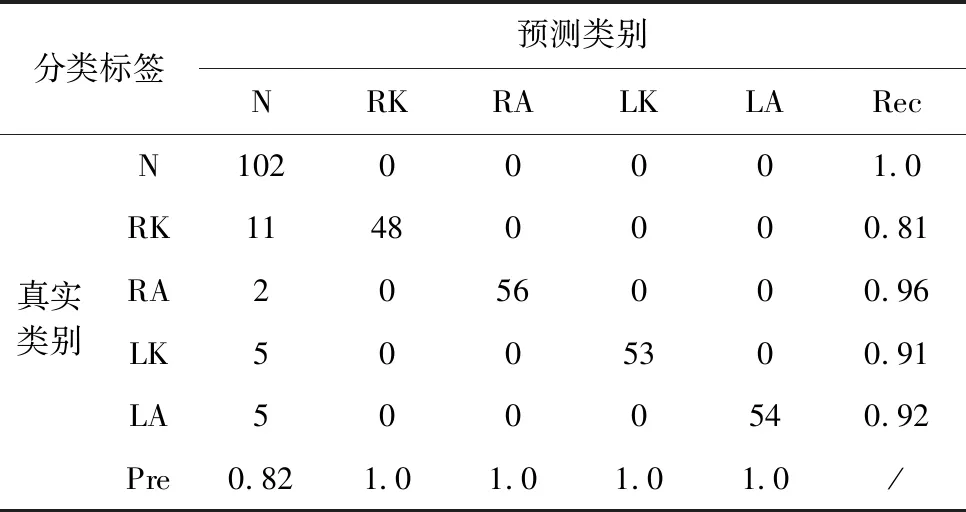
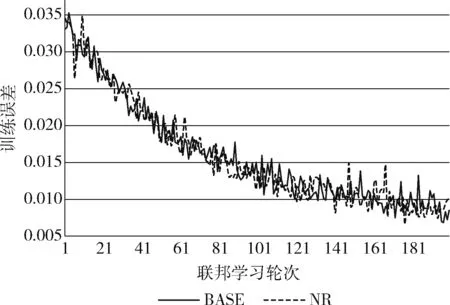
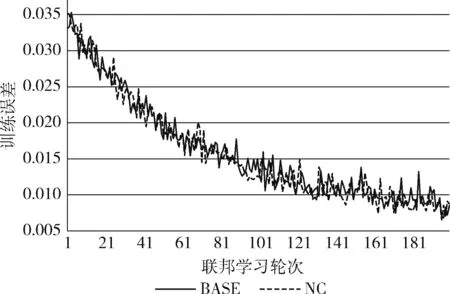
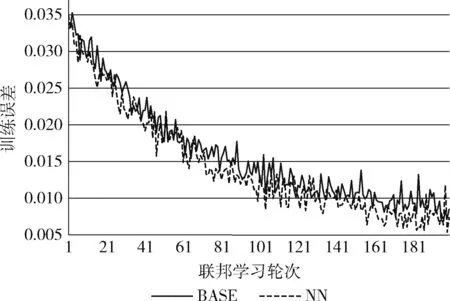
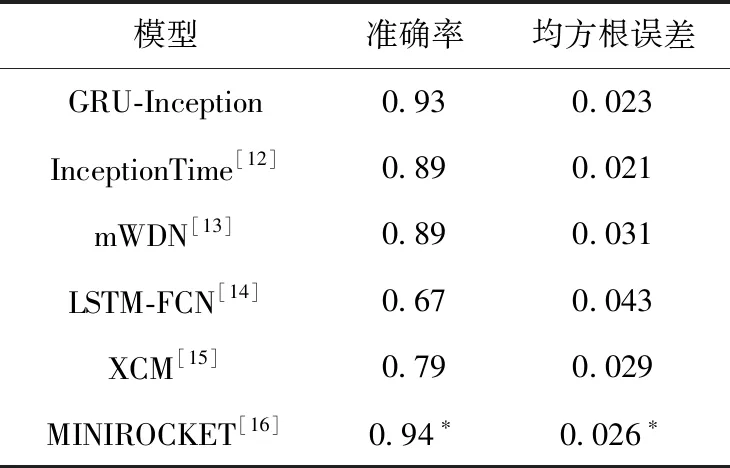
cond=(snr (26) 其中,snr为本次全局更新的信噪比;cond为训练继续条件,若为假则联邦学习停止。 在进行康复评估前,需要利用运动捕捉系统来采集受测者步行时的下肢运动参数。康复医学上常用参数包括:左右侧髋关节屈伸角、左右侧膝关节屈伸角以及左右侧踝关节屈伸角共计6个关节角度。完成数据采集后,在上海市第六人民医院康复科医生指导下确立如下康复评估任务:第一,对下肢损伤部位进行识别分类,包括正常、左右膝关节损伤、左右踝关节损伤共5个类别;第二,对康复程度进行评分,分数高说明康复情况良好。因此下肢康复评估可视为一个多分类及评分回归问题,其输入为6个关节角度200帧时间序列,输出为5类关节损伤分类结果及对应康复评分结果。 针对以上问题,本文设计一种结合循环神经网络与卷积神经网络的时间序列多分类与评分模型,即GRU-Inception模型。该模型分为循环神经网络特征提取模块以及卷积神经网络分类预测模块,整体结构如图2所示。卷积神经网络分类预测模块中的Inception单元,其结构如图3所示。 图2 GRU-Inception模型结构 图3 Inception单元结构 GRU-Inception模型中采用GRU来实现特征提取模块。GRU能有效捕捉时间序列当中的依赖关系,提取时序特征。输入数据张量形状为 (B,V,S),B代表输入批大小,V代表输入变量维度,S代表输入序列时间步数。GRU隐藏层尺寸为hs, 表示特征提取所得的状态张量维数。经特征提取模块处理后,输出状态张量形状为 (B,S,hs)。 GRU-Inception模型中分类预测模块由卷积神经网络InceptionTime[12]实现。如图2所示,该模块通过连接6个Inception单元组成,每隔3个单元引入残差连接,防止深度增加导致模型退化及梯度消失。如图3所示,每个Inception单元由3个并列卷积层及一个最大池化层拼接组成。 最后,利用全连接层来整合输出张量形状,利用Softmax层进行指数归一化,形成独热编码作为输出结果。独热编码one_hot这5个分量分别代表该样本在5个类别上的预测概率,进一步计算即可得到分类结果class_id及评分结果score class_id=argmax(one_hot) (27) score=one_hot[normal_id]one_hot[class_id] (28) 其中,函数argmax用于找出独热编码向量里最大值的索引编号。 本数据集在上海市第六人民医院一线康复科医生合作下进行数据采集和标注工作。本数据集利用Xsens可穿戴式动捕设备来进行下肢运动数据捕捉,采集时分别将7个可穿戴传感器佩戴在骨盆中央、左右侧大腿股骨中段、左右侧小腿胫骨中段以及左右侧脚跟跟骨处。随后进行站姿标定,确定传感器与肢体相对位姿。接下来进行数据记录,受测者在平地上行走,采集得到关节角度步态数据。 关节角度采集频率为40 Hz,每帧采集得到左右髋关节屈伸、左右膝关节屈伸以及左右踝关节屈伸共计6个角度。后续处理中每隔5 s,即200帧数据,划分为一个样本,并在医生协助下进行数据标注工作。数据标注工作分为分类和评分两步,数据集共分为5个类别:正常N、右膝损伤RK、右踝损伤RA、左膝损伤LK、左踝损伤LA。根据受测者康复程度不同,评分分值范围为0.6~1.0。最后计算得到该样本1×5独热编码来代表各类别概率。例如,独热编码(0.45,0.55,0,0,0)代表其正常概率为0.45,右膝损伤概率为0.55,其它概率为0。因此该样本分类结果为右膝损伤,评分为0.45/0.55=0.82。本数据集共有样本1698份,均通过上文所述方法获得,各类样本数量与比例见表1。 表1 下肢康复数据集 本实验基本设置如下:每轮训练客户端迭代次数epoch=3; 批大小设置为B=64; 学习率设置为lr=0.01; 通讯轮数U=200; 优化器限制项参数μ=0.1; 压缩类型compression=int16。 对于高斯差分隐私机制相关的参数,设置隐私预算ε=1; 容忍度δ=0.1; 噪声阈值th=10。 本实验在Ubuntu 20.04系统上进行;深度学习框架为Pytorch 1.9.1;编程环境为Python 3.7;CPU为英特尔Core i7-9750;GPU为英伟达GeForce RTX 2060;显存为6 G;内存为8 G。 GRU-Inception模型在联邦学习框架上进行200轮训练后,在测试集上对其进行验证。如表2所示,本实验按照5种类别进行结果整理,其中Pre、Rec代表各类别分类精确率、召回率;TP代表各类别识别正确的样本数;FP代表其它类别误识别为本类别的样本数;FN代表本类误识别为其它类别的样本数,则 Pre=TPTP+FP,Rec=TPTP+FN (29) 表2 GRU-Inception模型联邦学习分类结果 对模型的整体表现进行分析,在测试集上模型的总体准确率为Acc=0.93。准确率代表预测正确样本数占测试集样本总数的比值,即 Acc=num(pred=gt)num(total) (30) 采用均方根误差对模型康复评分效果进行分析,结果为RMSE=0.023。均方根误差计算如下 RMSE=∑mi=1(yi-xi)2/m (31) 其中,y,x分别代表预测分值以及真值分值,下标i代表样本编号,m代表样本数。 除了对模型整体效果进行实验,本文对联邦学习过程中各重要步骤分别进行验证。在本地训练过程中,resSGD优化器在随机梯度下降基础上引入限制项,防止本地更新后的局部模型和全局模型相差过大导致模型发散。对带限制项的resSGD优化器效果进行验证,误差曲线对比如图4所示,带限制项的resSGD优化器为BASE,不带限制项的SGD优化器为NR(no restriction)。 图4 是否使用限制项优化器对比 由图4可见,是否使用限制项优化器其整体误差曲线相似。但在训练开始及结束阶段,不使用限制项时模型训练误差有相对较大幅度的波动。在测试集上进行对比,加入限制项时模型Acc=0.93,RMSE=0.023;不加限制项时模型Acc=0.90,RMSE=0.025。由于不同节点梯度相差较大,全局更新时波动与震荡难以避免,严重时会影响模型收敛。带限制项的resSGD优化器可减少训练时模型参数波动幅度,提升收敛稳定性与模型性能。 在客户端与服务器通讯阶段,为减轻网络传输负担,加快模型传输速度,采用int16量化编码压缩。对量化编码压缩效果进行验证,误差曲线对比如图5所示,使用编码压缩为BASE,不使用编码压缩为NC(no compression)。 图5 是否使用量化编码压缩对比 由图5可见,是否使用编码压缩其整体误差曲线十分接近。在测试集上进行对比,使用编码压缩时模型Acc=0.93,RMSE=0.023;不使用编码压缩时模型Acc=0.93,RMSE=0.021。本模型中各层参数最大最小值相差基本小于50,而int16类型范围为65 536,进行量化压缩时可保证1e-3的精度。因此,量化编码压缩后的模型精度损失较小,但文件大小可降为50%,大幅减轻传输压力。 在全局更新阶段,为保护数据隐私,在联邦平均算法基础上加入高斯噪声实现差分隐私机制。对高斯差分隐私机制进行验证,误差曲线对比如图6所示,使用高斯机制的联邦平均算法为BASE,普通联邦平均算法为NN(no noise)。 图6 是否使用高斯差分隐私机制对比 由图6可见,无噪声时模型训练误差低于添加高斯噪声。在测试集上进行对比,添加噪声时模型Acc=0.93,RMSE=0.023;无噪声时模型Acc=0.93,RMSE=0.025。添加高斯噪声虽使模型训练误差增加,收敛速度变慢,但在测试集上其表现接近甚至略优于无噪声。可见适当添加高斯噪声既能保护数据隐私安全,防止信息泄漏,又可以使模型过拟合程度减轻,泛化性能得到一定的改善。 为验证GRU-Inception模型在下肢康复数据集上的表现,将其与一些最新时序网络模型经联邦学习后在测试集上进行比较,结果见表3。 表3 不同模型对比 表3可见,GRU-Inception在评分准确度上略低于InceptionTime,但分类预测准确率有较大提升。对比mWDN、LSTM_FCN与XCM,GRU-Inception模型在下肢康复数据集上的整体表现更好。而MINIROCKET虽在单节点训练时效果突出,但联邦学习时该模型不收敛,说明其对参数扰动较为敏感。实验结果表明,经联邦学习训练后GRU-Inception模型在下肢康复数据集上综合表现较优。除某些对参数扰动比较敏感的模型外,本文构建的联邦学习系统对各类模型结构适应性强,适用范围广。 本文提出一种基于联邦学习的下肢康复评估算法,用于保护数据隐私安全并进行模型训练与康复评估。联邦学习系统的搭建上,本文采用客户端选择机制及量化编码压缩算法提高通讯效率,设计带限制项的resSGD优化器保证模型收敛,最后利用高斯差分隐私实现数据保护。在此基础上设计了GRU-Inception模型完成康复评估任务。 实验结果表明,本文提出的基于联邦学习的下肢康复评估算法整体表现较优,有助于打破医疗机构之间的数据壁垒,使多方协同训练出准确度高、泛用性好的康复评估模型成为可能。2.5 GRU-Inception模型设计
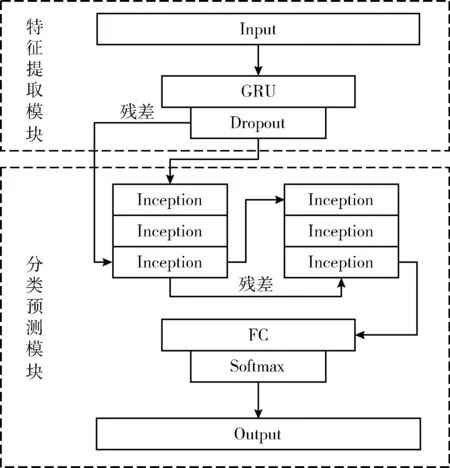
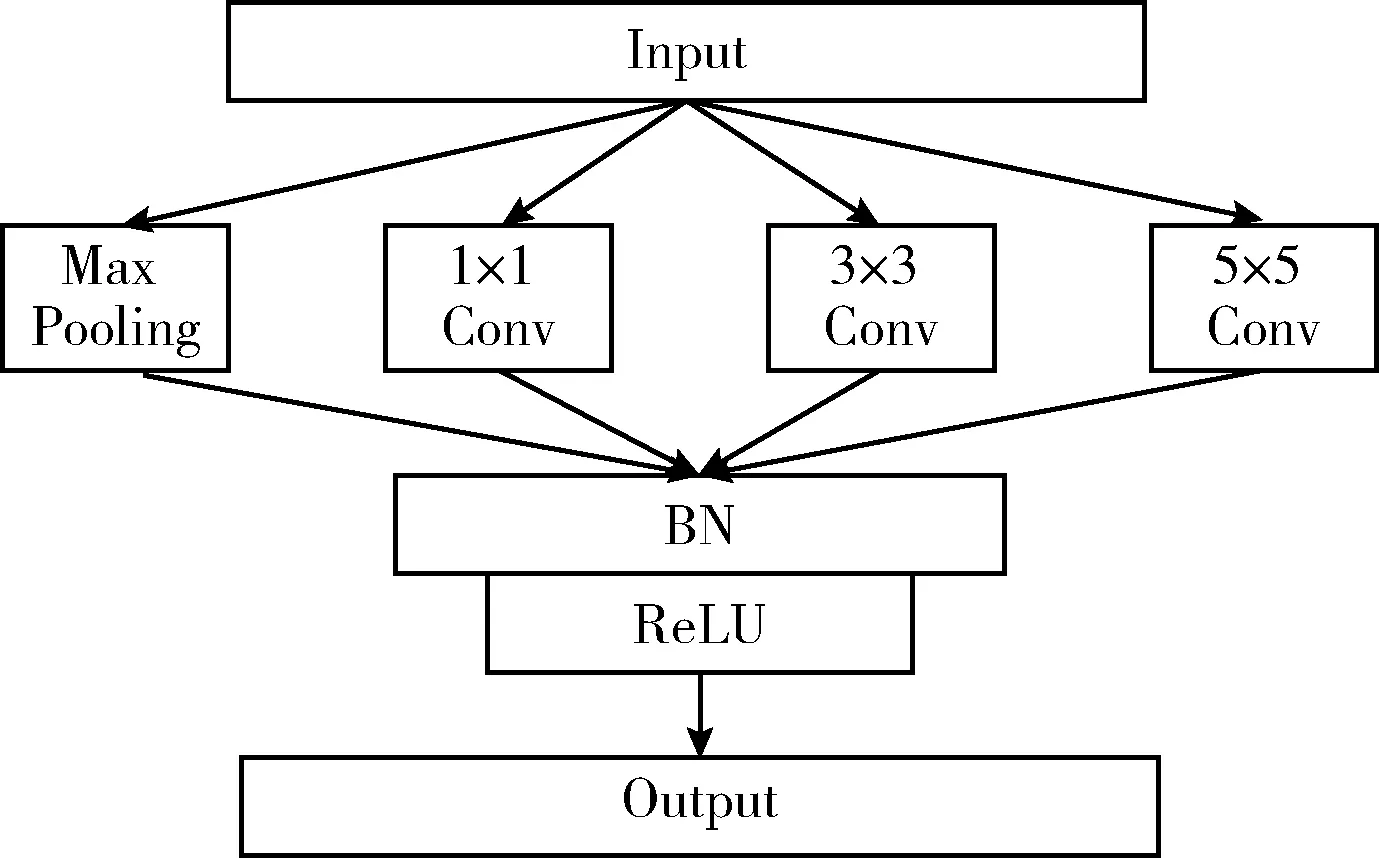
3 实验验证与结果分析
3.1 下肢康复数据集
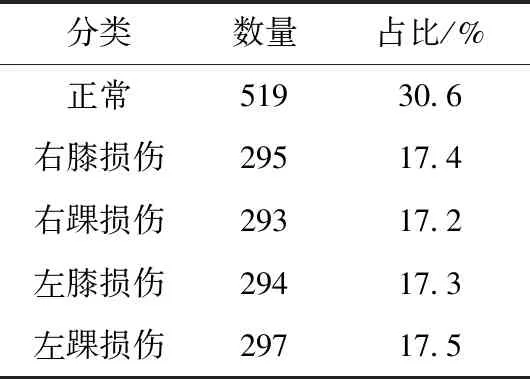
3.2 实验参数与环境

3.3 实验与分析
4 结束语
