应对复杂光照下的高精度表情识别方法
2023-09-13李嘉乾
李嘉乾,张 雷
(江苏理工学院 机械工程学院,江苏 常州 213001)
0 引 言
表情识别是人工智能的一个重要研究方向。表情识别主要有两类方法:基于传统特征提取方法和基于深度学习的方法。传统特征提取的几种方法有:PCA[1]、LBP[2]和HOG[3],这些算法主要通过先对面部进行建模,再进行特征的提取与匹配。姚丽莎等[4]通过使用LBP进行特征的提取,并使用支持向量机进行表情分类,用以检测固定场景中表情的变化,提高了识别率,但在其它场景表现不佳。杨恢先等[5]通过结合梯度信息改进局部二值化特征提取,改善了单一局部二值化特征对于中心噪声的敏感性,但无法克服相似表情识别精度低的问题。
欧中亚等[6]结合随机森林与PCA特征提取方法,通过融合欧氏距离和明氏距离两种距离计算方法求取样本均值,以寻找局部最优的样本中心,取得了一定的效果,但过度优化了类内差异,而导致丢失了一部分的类间差异,导致没有取得理想的识别精度。
深度学习算法是通过建立神经网络模型,并使用大量的数据集对网络进行训练,使得深度模型可以获得图像更深层次的特征。目前深度学习模型由于其泛化性能好,在表情识别中逐渐取代传统算法,但对于一些小数据集,模型难以训练拟合所以精度较低。目前的主流改进方法是将传统算法与深度模型结合。丁名都等[7]使用HOG和卷积神经网络搭建双通道网络进行特征提取,并通过构建特征融合网络取得了不错的识别精度,但其没有针对分类器进行优化,导致对于具有相似特征的样本分类效果不佳。薛建明等[8]通过先提取关键区域特征再融合,将融合的特征输入卷积神经网络中进行特征提取与分类,由于其算法着重提取关键区域,因此相似表情的识别率上有了较大的提高,但是对于光照的鲁棒性有所欠缺。
本文为了在提升光照的鲁棒性时兼顾提高相似表情的识别精度,基于残差结构[9]提出一种双通道残差网络模型。在通道一改进光照鲁棒性;在通道二改进全局的特征提取能力。在特征融合网络中通过交叉验证确定鲁棒的特征融合网络的系数;最后引入中心损失[10]联合Softmax函数设计联合算法,在公开数据集CK+[11]、Oulu-CASIA[12]和JAFEE[13]数据集上进行实验。并与主流算法进行了比较,验证了本文算法的优越性。
1 双通道残差网络图像处理模块
改进的双通道网络模型结构如图1所示,主要分为双通道图像处理模块和特征融合与分类模块,前者由图像预处理与双通道网络组成,后者由特征融合网络和分类器组成。
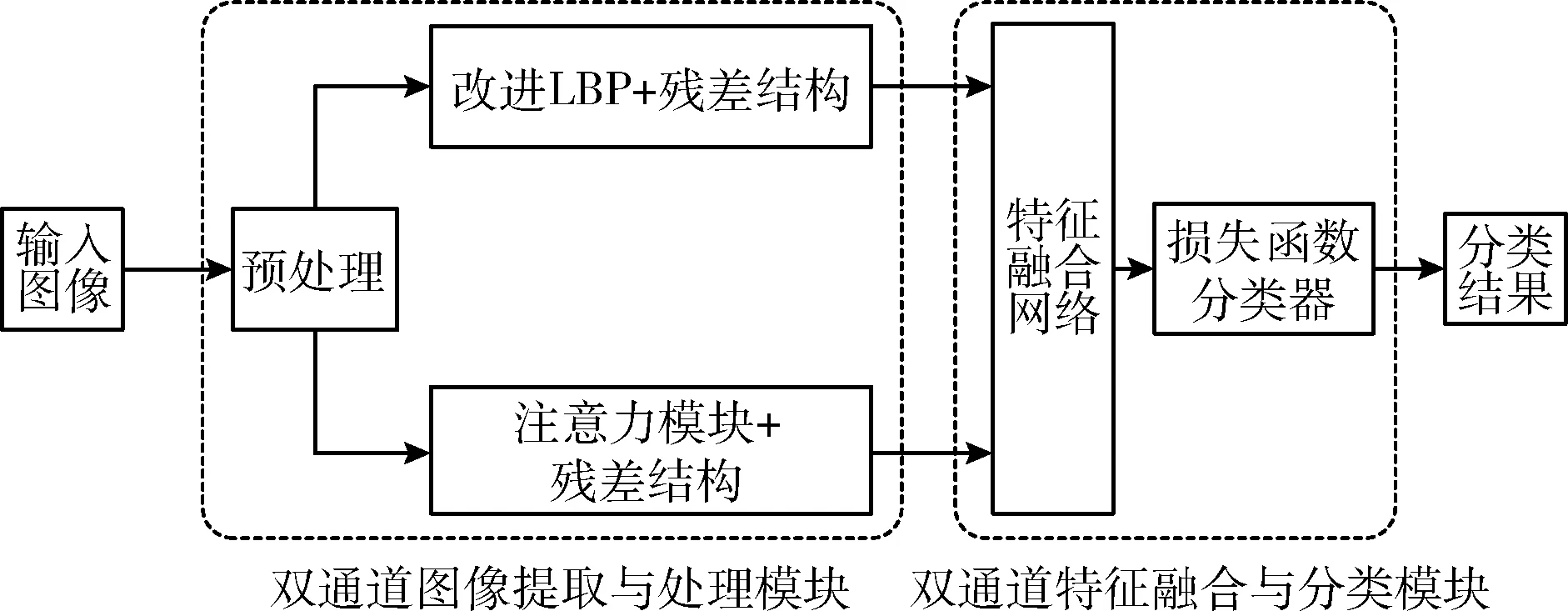
图1 改进的残差网络模型结构
1.1 图像预处理
为让使后续网络减少计算量,需要对输入图像进行预处理,预处理结果将直接影响最终的识别结果,本文采用的预处理方法主要有以下两个步骤:
步骤1 输入图像旋转矫正:由于实际场景中,采集的表情图像可能存在角度差异的问题,为了避免此类问题对特征提取的影响,需要对输入图像进行旋转矫正,定义旋转矩阵如公式(1)所示
(f′x,f′y)=[fx,fy][cosθsinθ-sinθcosθ]
(1)
其中,θ表示图像需要进行矫正的旋转角度,通过两个眼睛中心连线与水平方向的夹角确定;fx、fy代表输入图像初始的定位的双眼坐标;f′x、f′y代表进行旋转矫正后的双眼坐标。
步骤2 图像降维:经分析表情模型的训练与识别主要是依靠提取图像的纹理信息和面部的五官等信息,色彩对于检测的准确度几乎没有影响,通过灰度化操作将输入的3个通道RGB图像转换为一个通道灰度图以降低通道数;通过降低通道数,不仅保存了图像的绝大部分信息,也降低了后续网络的计算复杂度。
1.2 改善光照的LBP特征提取
目前开源的LBP算子的定义是:在输入的待检测图像上任选一个边长像素值为3的正方形块,将比较的阈值预先设定成中心区域的像素值,并将其与周围的8个像素值相比较,如果此时被比较的像素值小于中心像素值,就把当前位置像素点编号设为0,而其它情况则设置为1,通过将中心点的灰度值与当前区域所有点的灰度值进行对比,产生8位二进制数,即该区域中心点的LBP值,并用这个值来反映该区域的纹理信息。LBP值计算如式(2)所示
ULBP(xc,yc)=∑p-1p=02Ps(ip-ic)
(2)
式中:(xc,yc) 为中心像素点C的坐标,ic表示中心点的灰度值,ip表示中心点邻域的灰度值。
由定义可知LBP算子在灰度范围内具有单调不变性,即对于光照的变化非常的鲁棒。一个完整的LBP算子编码的过程如图2所示。

图2 LBP算子编码过程
LBP算子作为图像纹理表示的一种极其有效的方法,这使得LBP特征具有很强的分类能力。但是,在提取中心像素值时,对噪声比较敏感,且在表征图像整体特征方面较为欠缺。具体改进方法如下:按照顺时针次序将LBP算子中心点像素值的平方与它周围各邻域点像素值的平方相减,再按照上下排列比较的方式,定义若上值大于等于下值,则生成值1,反之则生成值0。具体过程如图3所示。

图3 改进的LBP算子编码过程
图3为改进的LBP算子编码过程,由此生成了8位二进制的局部特征描述序列。通过此种方法生成的局部特征描述序列,其优势在于不仅仅比较了相邻点与中心点的像素值,也比较了各个相邻点之间的像素值。这样的好处是既保证了相邻点与中心点像素值之间的联系,又兼顾到了各个相邻点像素值之间的关系。在保留其对微小特征的敏感性的基础上,进一步提高提取面部纹理特征的能力。在不同光照情况下,传统的LBP特征提取与改进后的LBP特征提取对比效果如图4所示。

图4 传统LBP与改进的LBP特征提取在不同光照下的效果对比
为了更直观体现此改进方法的有效性,分别将传统LBP与改进的LBP后接结构相同的残差网络结构在公开数据集CK+上进行实验,实验结果如图5所示。

图5 传统LBP特征提取与改进的LBP特征提取在CK+的精度曲线
通过实验发现,改进的LBP算子和传统的LBP算子在同一数据集上的精度都在12个epoch后收敛,并且总体识别精度有了比较大的提高,分析并对比实验结果发现,此改进在应对不同的光照和对细小纹理的特征提取方面都获得了提高。该实验说明了此方法是针对传统LBP算子的有效改进。
1.3 改进的注意力机制模块
注意力机制作为一种模拟人脑注意力的理论,通过对模型中不同关注部分赋予不同的权重,从中抽取出更关键的信息。目前已有关注网络中通道信息的通道注意力模块[14]和关注图像空间位置信息的空间注意力模块[15]。
但由于通道注意力模块和空间注意力模块各自关注的特征不同,存在一定的缺陷;而如果简单的叠加这两个模块,达不到预想的结果,为此提出了一种改进的注意力模块,其改进过程是:首先将前卷积层输出的尺度为C维、水平长度为W,垂直长度为H的特征,作为注意力模块的输入,并从垂直和水平两个方向进行平均池化,而后将池化后的两种特征进行相加合并并进行卷积操作;合并卷积后的特征通过批量归一化和非线性处理后再度从垂直和水平两个方向进行卷积操作,得到两个方向的分量卷积特征,之后通过sigmoid函数计算并合并为新的特征。这样处理后的特征不仅兼顾了通道域和空间域上的注意力特征,并且通过对垂直和水平方向的卷积操作得到更深层次的特征。其计算原理如图6所示。

图6 改进的注意力模块计算过程
1.4 基于残差结构的注意力模块
增加卷积层可以提取到更深的图像特征信息,但同时会大量增加模型的参数与运算复杂度,为了能提取到更深层次的特征,且不增加过多模型参数,引入ResNet结构,残差结构与改进的注意力模块方式结合如图7所示。
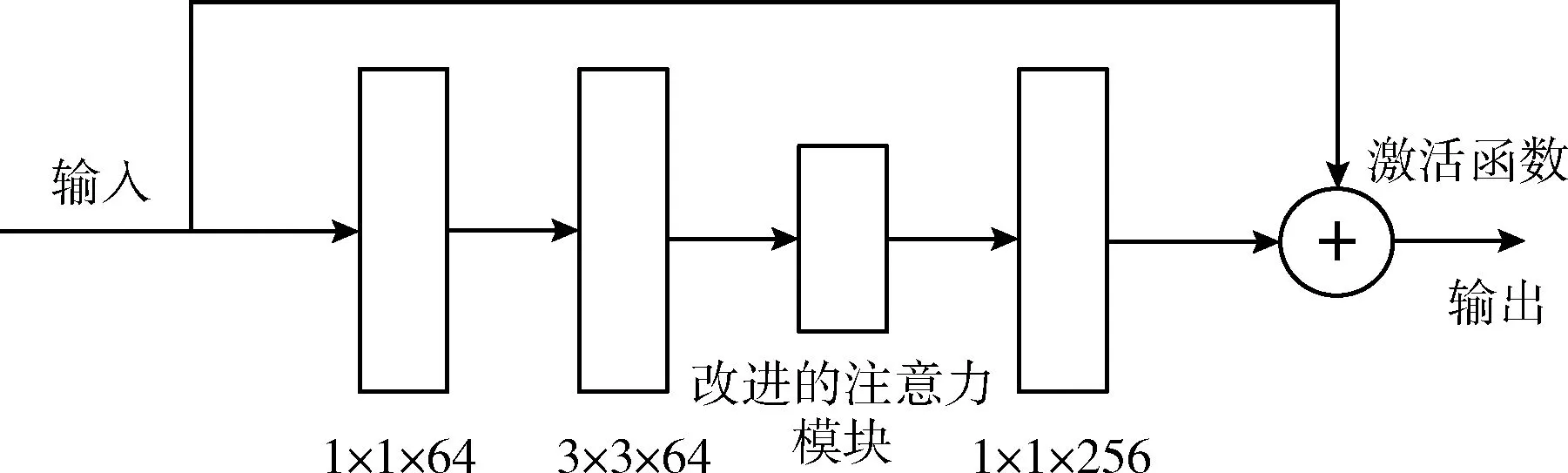
图7 CA模块在残差网络中的位置
同时为了更直观体现此改进方法的有效性,分别将ResNet-10和ResNet-10+改进注意力模块在公开数据集CK+上进行实验验证,由于受原生的ResNet-10层数的限制,实验效果截取了前20个迭代循环的准确率—模型损失曲线,其实验结果如图8所示。
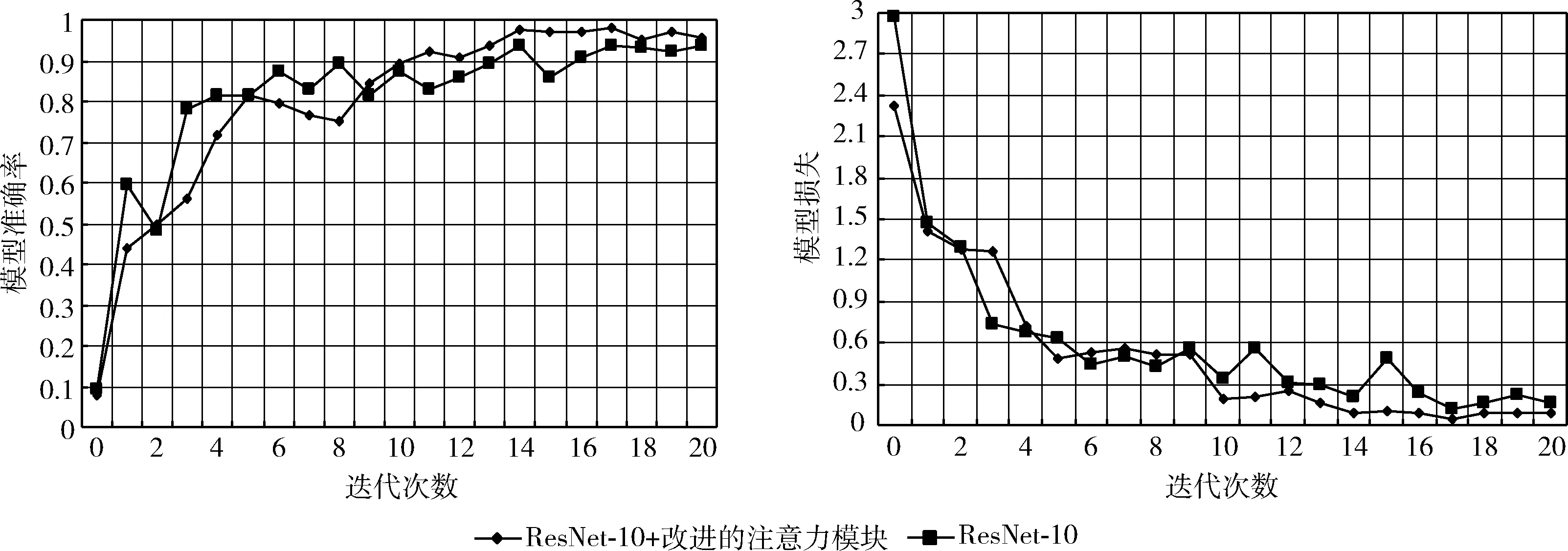
图8 ResNet-10与ResNet-10+改进的注意力模块在CK+上的准确率—模型损失曲线
分析准确率—模型损失曲线,发现两者曲线波动都较大,这是因为两者只迭代了20次。但通过对比不难发现,在ResNet-10中增加改进注意力模块后,其准确率曲线精度上升的更快且精度更高,即此方法可以加快模型的收敛,并且通过对比两者的模型损失曲线,发现添加改进注意力模块后模型损失曲线波动更小,即模型的鲁棒性能更棒。该实验说明了此方法是针对模型的有效改进。
2 双通道残差网络特征融合与分类模块
2.1 双通道残差网络结构
目前主流的特征提取网络都是基于卷积神经网络而衍生,本文借鉴了DeepID3[16]与ResNet-10结构,并重新设计了特征提取网络,通道一使用改进的LBP特征提取而后连接ResNet进一步获取特征图;通道二同样使用ResNet,在每个卷积层和批量归一化层后添加改进的注意力模块。之后连接特征融合网络和改进的损失函数输出分类结果。双通道残差网络设计结构如图9所示。
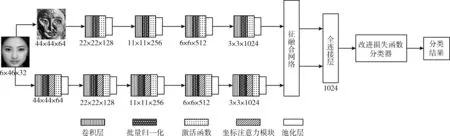
图9 改进的双通道残差网络
其中,卷积层用于提取输入的不同特征,使用ReLU激活函数增加稀疏性,缓和过拟合;在卷积层和池化层之间加入批量归一化层,用于提高训练速度,降低过拟合风险;并且在通道二的每个批量归一化层后面加入CA模块,进一步提取重要特征;池化层降低模型参数量,优化模型的后续计算量;特征融合网络通过实验确定融合系数,进行特征的融合;全连接层连接所有特征,将输出值送入分类器进行分类。
2.2 特征融合网络
搭建特征融合网络的主要作用是为了使前置网络提取到的特征经过融合后,输出更能表征图像的特征并提升其鲁棒性。
本文采取了加权融合方式构造特征融合网络,通过设置加权系数β对通道一网络和通道二网络加权求和得到双通道输出特征
Qw=β·Qx+(1-β)·Qy
(3)
式中:Qw为融合后得到的特征,Qx为通道1输出的特征,Qy为通道2输出的特征,β的最优值通过在Oulu-CASIA、CK+、JAFEE这3个公共的表情数据集上进行交叉实验获得。将融合后的特征输入全连接层,并连接分类器输出分类结果。
2.3 改进Softmax损失函数
2.3.1 Softmax损失函数
Softmax损失是一种用来应对多分类问题的监督学习算法,其对于训练集中每个样本的k个估计概率如式(4)所示
Ls=-1m(∑mi=1logewTy(i)x(i)∑kl=1ewTlx(i))
(4)
其中,m为最小批次中训练样本的数量,k为分类的个数,x(i)、y(i) 表示第i个训练样本及其标签,wTlx(i) 表示当前第l个样本经过网络训练后的输出,分母的作用是正则化,用以确保每个向量的输出值都在[0,1]之间。
但对于表情识别问题,Softmax损失虽然可以保证类间差异最大化,但不能保证类内差异最小化。对于图像的相似特征,Softmax损失并不能很好区分。例如,单一的神经网络后接Softmax损失作为分类器并不能很好区别猫和狗,有时甚至会误判,因为其有较多相似的特征。为此,需要提升分类器在相似特征间的区分度以提高分类准确度。
2.3.2 改进方法
在Softmax损失函数引入中心损失以改进,中心损失的作用是可以针对类内间距做优化,使得类内间距减小。在保留了原来的分类模型的基础上,又为每一个类指定一个类别中心,即同一类的图像对应的特征都尽量地靠近和自己相同的类别中心,对于不同的类别中心则尽量远离。中心损失函数如式(5)所示
Lc=12∑mi=1xi-cy(i)22
(5)
其中,m为最小批次中训练样本的数量,xi表示第i个训练样本,cy(i)为y(i) 类的样本中心。改进后的Softmax损失函数如式(6)所示
L=LS+λLC=-1m(∑mi=1logewTy(i)x(i)∑kl=1ewTlx(i))+λ2∑mi=1xi-cy(i)22
(6)
式中:λ添加在中心损失函数之前用于平衡两者;当λ越小,则中心损失趋于零,此时类内差异占整个目标函数的比重就越小;当λ越大,则中心损失占比越大,此时类内差异占整个目标函数的比重就越大。通过改进参数λ, 使得输出的面部表情特征类间分散、类间聚合化,以提高表情分类精度。
在训练开始时,首先初始化池化层和loss层的参数:其中,W为初始权重,θC为初始卷积层参数,{cy(i)|y(i)=1,2,3,…,n} 为第n个样本的样本中心,同时输入参数:λ、α和学习率μt, 其中迭代的次数t初始化为0,总迭代次数为T。 则反向传播的计算公式为
∂Lt∂xti=∂LtS∂xti+λ·∂LtC∂xti
(7)
W的更新公式为
Wt+1=Wt-μt∂L∂Wt
(8)
样本中心的更新公式为
ct+1y(i)=cty(i)-α·Δcty(i)
(9)
θC的更新公式为
θt+1C=θtC-μt∑mi=1∂Lt∂xti·∂xti∂θtC
(10)
根据以上分析,Softmax损失函数与中心损失函数联合计算方法步骤如算法1所示。
算法1:Softmax损失函数与中心损失函数联合计算方法
初始化:总迭代次数T, 收敛精度ε, 迭代次数t=0
步骤1 计算联合损失去L(t):L(t)=L(t)s+L(t)c;
步骤2 计算反向传播误差;通过式(7)对每一张图片求解;
步骤3 计算参数W,通过式(8)对每时刻的W求解;
步骤4 对每个不同的类别,通过式(9)更新样本中心;
步骤5 更新参数θC, 通过式(10)计算最新参数;
步骤6t←t+1, 若t=T或 |θt+1C-θtC|≤ε, 则结束;否则,返回步骤1。
3 实验验证与结果分析
3.1 实验环境及数据集介绍
本文所使用环境及计算机配置为Intel Core i7 8700、32 G内存、NVIDIA 3080显卡10 G显存,软件平台为Python3.6、TensorFlow-gpu 1.3.1、NVIDIA CUDA 10.0、cuDNN 7.4.1库。
为了更好和其它主流算法比较,本文在对参数调优后,选用Oulu-CASIA、CK+、JAFEE这3个公共的表情数据集进行实验,各数据集及各表情数量见表1。
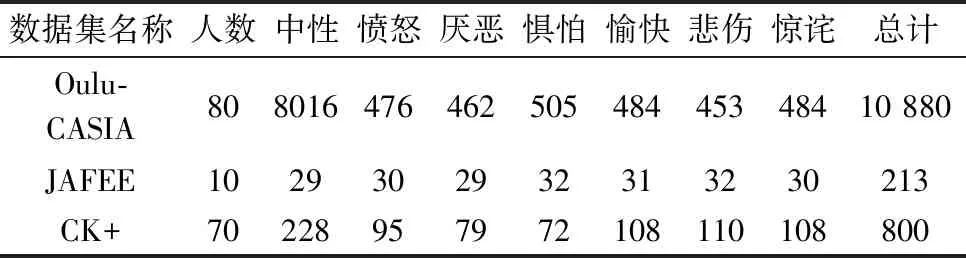
表1 各数据集表情种类及数量
由于各数据集样本数量相差巨大,故需要针对性的对数据集进行数据增广。其目的是,使得各样本数据量较为平均,并使得训练的模型具有更好的鲁棒性。
首先分析数据集:以Oulu-CASIA数据集为例,其中中性的表情占其总数的近74%,而其它6种表情数量差别不大。对于训练网络而言,若同一批次训练样本数较小,有可能会导致这一批次训练的图片几乎全为此种单一种类的图片,不利于网络学习其它表情特征且会导致模型损失曲线波动幅度较大;为此,需要针对性的对Oulu-CASIA数据集中其它表情进行数据增广。而对于JAFEE数据集,其表情分布较为均匀,但其主要的问题是由于数据集数量不够使得模型不能收敛,故对全部表情进行数据增广。CK+数据集中性表情较其它表情数量在两倍至3倍,故也需要对其进行针对性的数据增广。具体处理方式如下:
(1)Oulu-CASIA表情数据集包含7种表情,分别包含厌恶、愤怒、惧怕、愉快、悲伤和惊诧以及中性表情。其中一共包括10 880个样本。选取其它6种表情样本共2864张,进行数据增广,一共生成了14 320张数据集,增广后的数据集样本量为22 336张。其中训练集20 886张,验证集1450张。
(2)CK+表情数据集同样包含7种表情,同样包含厌恶、愤怒、惧怕、愉快、悲伤和惊诧以及中性表情。其中一共包括800个样本。进行数据增广,一共生成了12 000个样本,其中训练集10 800张,验证集1200张。
(3)JAFEE表情数据集是由日本人和白种人面部情绪图像构成的数据集,包含厌恶、愤怒、惧怕、愉快、悲伤和惊诧以及中性表情。其中一共包括213个样本。进行数据增广,一共生成了10 650个样本,其中训练集9585张,验证集1065张。
针对以上分析,对于以上3个数据集使用的数据增强方式及参数见表2。

表2 双通道卷积神经网络参数设置
以数据集中某表情图片为例,其数据增强过程及数据增强后的结果如图10所示。

图10 部分数据集原图与数据增强的效果
3.2 双通道网络参数设置
双通道网络的训练基本参数包含每一批次训练量(Batch-size)、基础学习率(Base-learning rate)、学习率动量(Momentum)、随机失活(Dropout)。网络采用带动量的学习率,将初始学习率设置为0.01,并采用自适应学习率不断进行修正。考虑到显卡性能及显存,将Batch-size设置为32。Momentum设为0.9。为使得模型在训练中减少过拟合现象,并使输出结果具有一定的稀疏性,将Dropout设置为0.5。双通道残差网络参数设置见表3。
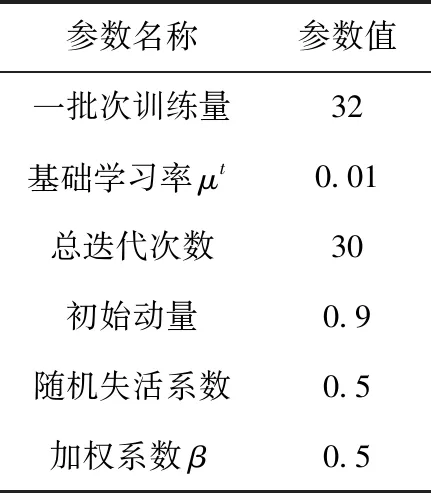
表3 双通道残差网络参数设置
对于特征融合网络加权系数β的确定,方法是通过对数据集进行分块后交叉验证来获得最优解。为了使实验结果尽可能准确,本文采用20组交叉验证方法在原始公开数据集Oulu-CASIA、CK+和JAFEE数据集上进行验证,将数据集分为20份,取其中19组作轮流训练的训练集,1份作为验证集,20次结果的均值作为加权系数β的平均结果。分别在以上数据集上迭代10个循环后的实验结果如图10所示。
由图11综合分析可知,对于CK+和JAFEE数据集,加权系数β取0.5时识别精度最高;对于Oulu-CASIA数据集,加权系数β取0.7时识别精度最高;经过将3个数据集一起训练并对比最优值发现,当加权系数β取0.5时,对3个数据集都能取得较高的识别精度。

图11 加权系数β与识别准确率关系曲线
分析不同数据集的加权系数β曲线的波动幅度与最优值不同的原因:
(1)加权系数β曲线波动幅度不同的原因:对于CK+与JAFEE数据集,对比两者曲线,JAFEE数据集的曲线比CK+数据集的曲线波动更小,这是因为其数据内各样本数量平均,在网络设置的每一批次训练量的情况下,不会出现某一种标签过多的情况从而影响模型的收敛;而对于Oulu-CASIA数据集,其中性表情样本数量和其它表情样本数量有十倍以上的差距,在某一训练批次中甚至会出现全是中性表情的极端情况,而下次训练批次又出现了上一批次中未出现过的其它标签的表情,这也导致了其加权系数曲线波动最大;
(2)加权系数β最优值不同的原因:分析CK+与JAFEE在加权系数β取0.5时取得最优值,而对于Oulu-CASIA数据集却是在0.7时取最优值,经过反复实验论证,发现其中中性表情的数量较其它数量过多,并且这些中性表情虽是是同一个表情标签,但同标签的中性表情之间存在比较大的差异,即同一标签的类内间距较大。结合通道一在提取特征中更注重的纹理和微小特征的提取,这就需要给通道一输出的特征更高的加权系数,以保证特征融合后的准确度;
(3)综上分析,若以某一实际使用场景为例:例如如果对于智能驾驶中的驾驶员面部检测场景,考虑到驾驶员在更长时间还是处于中性的表情,这个时候Oulu-CASIA数据集的数据结构更合理。但为了兼顾其它两个数据集的数据结构,且为了更大程度上增加对相似表情的区分精度,为此选择了对于3个数据集都能取较高精度的加权系数β。
3.3 实验结果分析与对比
3.3.1 实验结果
在数据增广后的CK+、JAFEE和Oulu-CASIA数据集上用验证集进行实验,经过30个epochs,得到对应的损失(loss)和识别率(accuracy),分别如图12(a)、图12(b)和图12(c)所示。
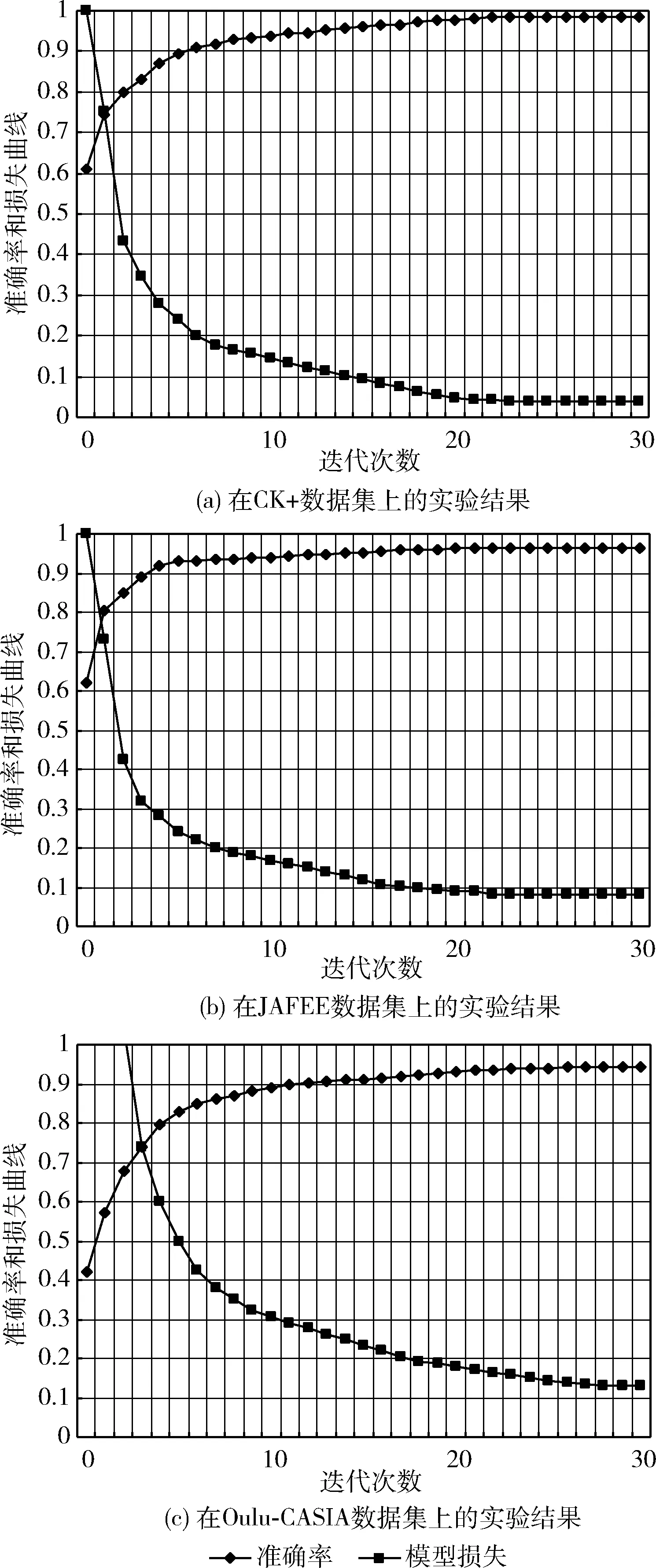
图12 3个数据集的识别率和损失率
其中,CK+数据集经过26个epochs后收敛;JAFEE这3个数据集经过21个epochs后收敛;Oulu-CASIA数据集经过28个epochs后收敛。迭代完30个epochs后准确率见表4。
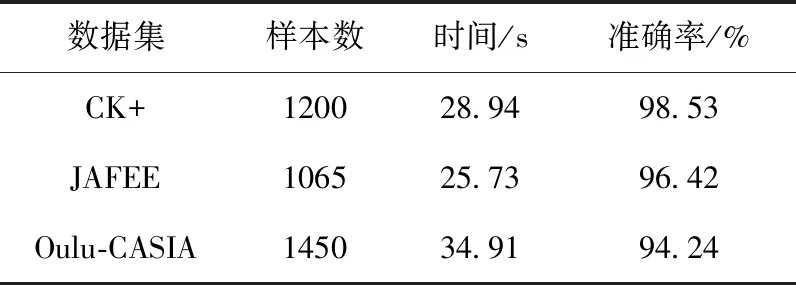
表4 本文方法识别准确率
分析表4,本文方法的检测帧率在3个数据集上的平均帧率为41.9 FPS,达到实际使用场景最低30 FPS的要求。但是考虑到在实际的使用场景中,可能会出现掉帧的情况,所以在实时性上还有很大的优化空间。
3.3.2 与局部二值与支持向量机方法比较
在公开数据集CK+数据集上使用单通道局部二值与支持向量机方法[16]进行测试,并与本文方法的模型进行比较。两种不同方法在CK+数据集上的混淆矩阵如图13所示。

图13 两种方法在CK+上的混淆矩阵
通过分析混淆矩阵数据,本文方法对比局部二值与支持向量机方法在愤怒表情上识别率提高了14.64%,在惧怕表情上识别率提高了12.96%,悲伤表情上识别率提高了15.52%;在厌恶、开心和惊讶表情的识别准确率方面也有了一些提升;结合数据集中部分易混淆样本如图14所示,分析原因:对于数据集中容易混淆的愤怒、悲伤和惧怕这3种表情,其表情变化部分多集中在眉头、眼睛和嘴角且具有较多的相似特征。具体表现为:对于愤怒和惊讶表情,其双眼圆睁,嘴巴张大;对于愤怒和悲伤表情,其眉头紧缩,嘴角下拉。故对于此类表情,传统算法很难从中找出决定隶属于不同表情的决定性特征。

图14 数据集中部分易混淆样本
从整体的实验结果分析,对于以上3个数据集中的6种表情识别率在基本都在90%以上,尤其愤怒、惧怕和悲伤这3个表情识别率提升显著,结果表明,本文的方案具有较大的提升。
3.3.3 与其它深度学习方法比较
为了比较本文方法与其它深度学习方法在面部表情识别上的性能,设计了另一组实验,同样在公开CK+数据集上进行实验,与其它基于深度学习方法进行对比,见表5。
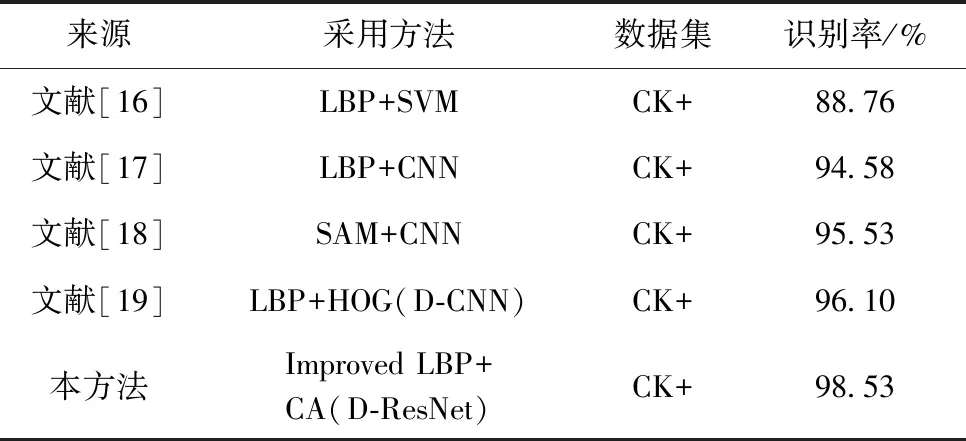
表5 在CK+数据集上识别率比较
通过复现并分析已有的方法,其中,文献[16]采取局部二值化方法与支持向量机的方式进行表情识别,其识别精度低于基于深度学习的其它算法,并且由于依赖手工提取特征,使得其泛化能力较差,但其由于设计简单,不依赖GPU对算力要求不高,且运行速度最快,适用于一些即时性高且要求精度不高的场景;文献[17]采用局部二值化方法后连接CNN进行表情识别,精度相比SVM方法有所提高,但并未对其全卷积结构进行优化导致运行速度较慢;文献[18]使用全局与局部图像作为输入,在CNN中添加空间注意力机制模块,并利用多尺度的方法取得了较高的精度,但其只关注了空间域上的信息,而将通道进行池化压缩,导致其损失了通道上的信息;文献[19]使用LBP和HOG两种特征提取算子构建双通道特征网络,兼顾了轮廓和纹理的特征并取得了较高的精度,但分析其识别错误的图像,发现其对于不同光照的表情的鲁棒性不够好。
4 结束语
为解决传统表情识别算法光照鲁棒性差和相似表情区分度低的问题,本文提出了一种改进的双通道残差网络,首先在通道一改进LBP算子,在保留其对于纹理特征、微小特征的敏感性的基础上提高其光照鲁棒性;接着在通道二嵌入改进的注意力模块,提升其全局特征提取能力。之后通过建立特征融合网络将两个通道的特征进行融合,设置加权系数平衡两个通道提取的特征,使得提取的结果可以更为全面地表征面部表情,通过多次交叉验证实验取平均值的方式确定了对于不同数据集最为鲁棒的加权系数,并结合数据集和网络模型深入分析了不同数据集的加权系数取值。由于标准数据集中存在相当多具有相似特征的表情,但它们的表情标签是不同的,这对于分类任务来说是十分不利的。本文引入中心损失并设计联合算法,进一步提高了相似表情之间的区分度,进而提高了总体表情识别精度。在3个数据集(CK+、JAFEE和Oulu-CASIA)上分别到达98.53%,96.42%和94.24%的识别准确率,实验结果表明本文提出的改进方案对比传统特征提取算法和其它深度学习方法在面部表情识别方面不仅提升了光照鲁棒性,并且提升了对于相似表情的区分度。
