混合扩张卷积和注意力机制的路面裂缝检测
2023-09-13瞿中,李明
瞿 中,李 明
(重庆邮电大学 计算机科学与技术学院,重庆 400065)
0 引 言
路面裂缝检测对延长路面寿命和保证路面结构安全具有重要的意义。近年来,国内外学者已提出了一系列自适应的裂缝检测算法。早期裂缝检测算法大多都基于数字图像处理技术。Zhou等[1]提出一种基于小波变换的裂缝检测算法。Li等[2]提出了一种基于K-means聚类的路面裂缝分割算法。Qu等[3]提出了一种基于改进遗传规划的裂缝检测算法。但是对于数字图像处理技术来说,绝大多数方法对于特征提取的处理都采用手工提取,其针对性较强,泛化能力较弱,不能很好适配所有噪声情况下的裂缝图像。
近年来一些基于深度学习的裂缝检测算法层出不穷。Yang等[4]提出一种基于特征金字塔的裂缝检测算法。Qu等[5]提出了一种基于注意力机制和多特征融合的裂缝检测算法。Zhou等[6]提出一种高精度的裂缝检测模型,该模型使用条形池化减少特征损失并使用注意力机制提高模型识别精度。基于深度学习的裂缝检测算法会随着网络层数的增加导致分辨率降低,可供提取的有效局部和全局特征变少,成为精度提升的瓶颈。
本文提出了一种基于混合扩张卷积和空间-通道注意力机制的路面裂缝检测算法。该算法基于改进的U-Net[7]网络,在编码阶段,使用空间-通道注意力机制增强裂缝特征,抑制非裂缝特征。混合扩张卷积可以在保持输入图像分辨率不变的前提下扩大网络模型感受野,而在卷积神经网络深层部分,由于不断对图像进行降采样操作来扩大感受野,造成了图像在获取特征时大量局部特征信息丢失。因此在深层网络阶段使用混合扩张卷积来扩大感受野,提取图像的全局特征。在解码阶段引入深监督学习融合多尺度特征,使最终预测结果更接近路面真实情况。
1 混合扩张卷积和注意力机制的路面裂缝检测
在进行裂缝检测时,需要被识别的类别只有裂缝和非裂缝两种,故可以对每个像素点进行类别区分,即二分类的操作。对于输入的图像,经过裂缝检测网络后都能输出相应的预测图。在预测图中,裂缝像素为白色,非裂缝(背景)像素为黑色。
1.1 网络模型
本文提出的裂缝检测网络模型结构如图1所示,该网络采用改进的U-Net网络作为主干网络。在编码阶段,使用空间-通道注意力机制(spatial-channel attention mechanism,scSE)增强对裂缝特征的关注。该模块结合了空间注意力机制(spatial attention mechanism,sSE)和通道注意力机制(Channel attention mechanism,cSE),能够有效的增强裂缝特征,抑制非裂缝特征。在网络中间部分,采用混合扩张卷积模块(hybrid dilated convolution,HDC)来提取更多的裂缝特征。混合扩张卷积对于输入图像并没有进行降采样的操作,其卷积核大小要比一般的卷积核要大很多,既可以在保持输入图像分辨率不变的前提下扩大模型感受野,获取到更多的全局特征,又不会增加模型的参数量。在解码阶段,使用深监督学习获取多尺度裂缝特征,并经过卷积核大小为1×1的卷积进行处理。最终,使用多尺度特征融合模块(multi-scale feature fusion,MFF)对提取的裂缝特征进行融合,使最终的预测结果更接近路面的真实状况。在训练网络模型时,输入一张大小为256×256的裂缝图像,输出一张同样大小的裂缝预测图,并使用概率值来确定该像素属于裂缝或非裂缝。概率值为1代表该像素属于裂缝,概率值为0代表该像素属于非裂缝。
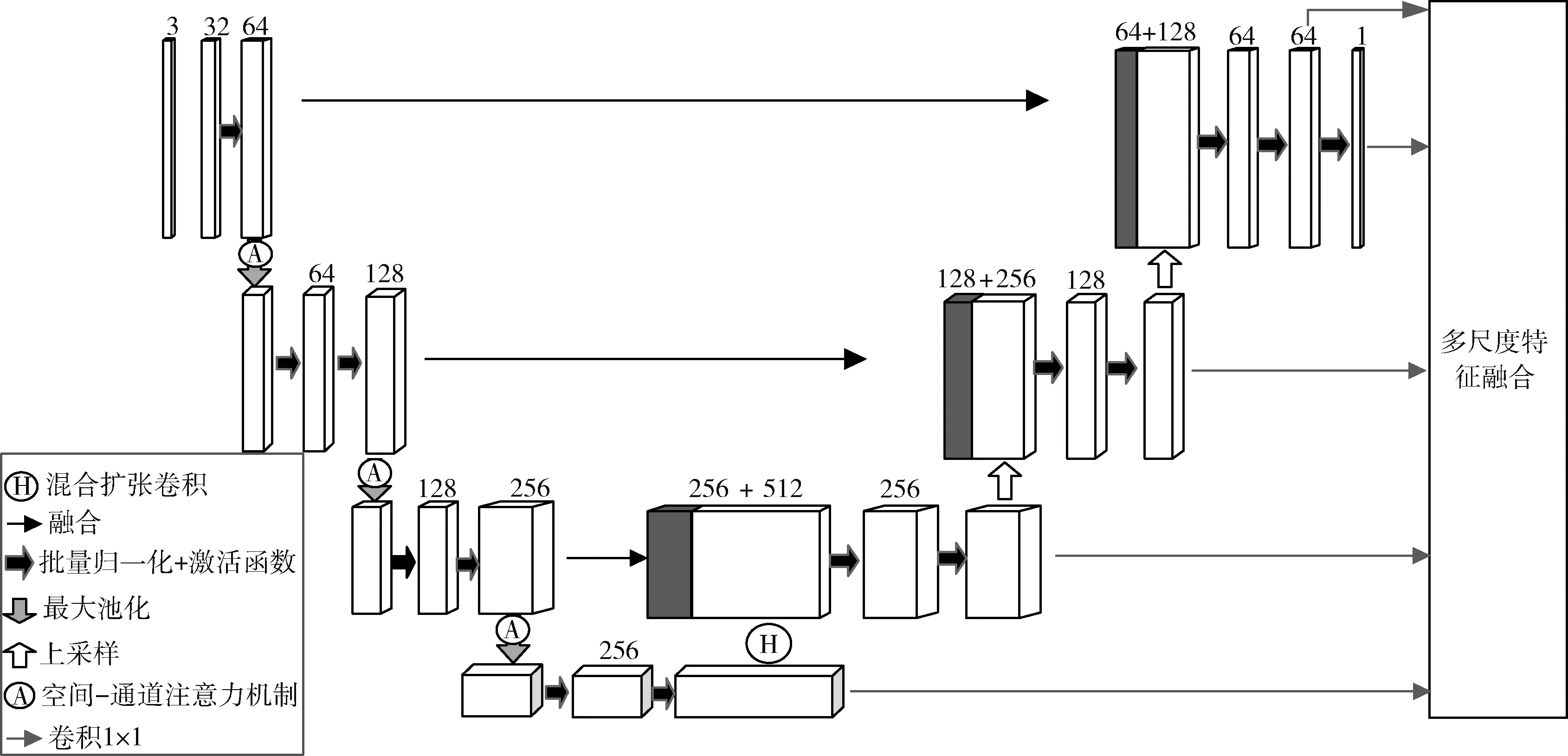
图1 裂缝检测网络模型结构
1.2 混合扩张卷积
由于网络模型频繁的下采样操作,降低了输入图像的分辨率,导致随着模型深度的加深,图像的局部特征信息也被逐渐丢失。当前主流的裂缝检测算法都采用卷积神经网络的方式来进行特征的提取,但随着网络层数的增加,能够提取到的特征也变得越来越少,造成随着网络的逐步加深,模型的参数量越来越大,但对模型精度的提升并没有明显帮助甚至降低模型的检测精度和速度。为了避免该现象的发生,一些裂缝检测算法引入空洞卷积来解决感受野变小的问题。空洞卷积可以减少下采样的使用,避免部分细节特征的丢失。虽然空洞卷积的引入避免了感受野的减小,但是也带来了新的问题-棋盘问题。所谓棋盘问题就是连续的卷积层使用相同空洞率(Dilated Rate,r),如图2(a)所示(三层卷积核大小为3×3的连续卷积层,空洞率都为2),部分像素将不参与中心像素的计算,整体呈网格状向外扩张,破坏特征信息的连续性。对于裂缝检测而言,裂缝图像背景复杂,裂缝拓扑结构多变,如果连续的卷积层都使用相同的空洞率,尽管在低层卷积层中使用空洞卷积扩大网络的感受野可以提取更多的裂缝特征,但是随着网络层次的加深,顶层的卷积层会变的过于稀疏,造成无法检测细裂缝的同时宽裂缝的局部特征也会丢失,使得检测准确率大大降低。
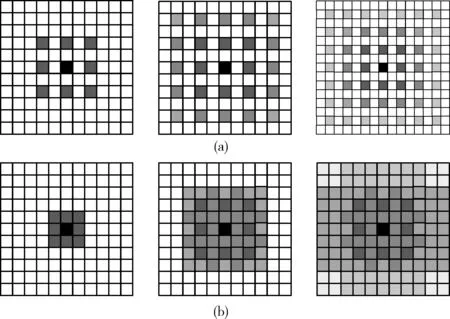
图2 空洞卷积问题
为了解决该问题,引入了混合扩张卷积[8],如图2(b)所示(三层卷积核大小为3×3的连续卷积层,空洞率分别为1、2、3)。混合扩张卷积的目的是为了让最后的感受野覆盖整个区域。混合扩张卷积需满足以下条件:①叠加的卷积层空洞率不能有大于1的公约数;②每组空洞率按照从小到大的方式排列,下组采用相同模式,即[1、2、3、1、2、3]循环结构;③N个卷积核大小为K×K的空洞卷积,其空洞率为[r1、r2……ri……rn],定义两个非零点之间最大距离如式(1)所示
Mi=max[Mi+1-2ri,Mi+1-2(Mi+1-ri),ri]
(1)
Mn=rn, 需满足M2≤K。 例如卷积核大小为K=3,r=[1、2、5],M2=2, 满足M2≤K。 混合扩张卷积在不增加额外的模块的情况下自然地扩大网络的感受野,而且能够自然地融入网络的原始层中,可以稳健地提取上下文语义信息和不同类型的裂纹特征。
本文中提出的混合扩张卷积模块如图3所示,由3部分组成,每部分空洞卷积空洞率为1、2、5。每部分包括两层1×1的卷积,一层卷积核大小为3×3的空洞卷积和一层大小为3×3的卷积,每层卷积后进行批量归一化操作。本文将混合扩张卷积模块引入编码-解码网络的中间部分,该模块能够自然融入网络中,能够有效地在保证扩大网络的感受野的同时减少局部和长距离裂缝特征的丢失。混合扩张卷积模块不仅能够解决传统空洞卷积存在的问题,还能自然而然融入到网路模型中,减少了网络模型的参数量。
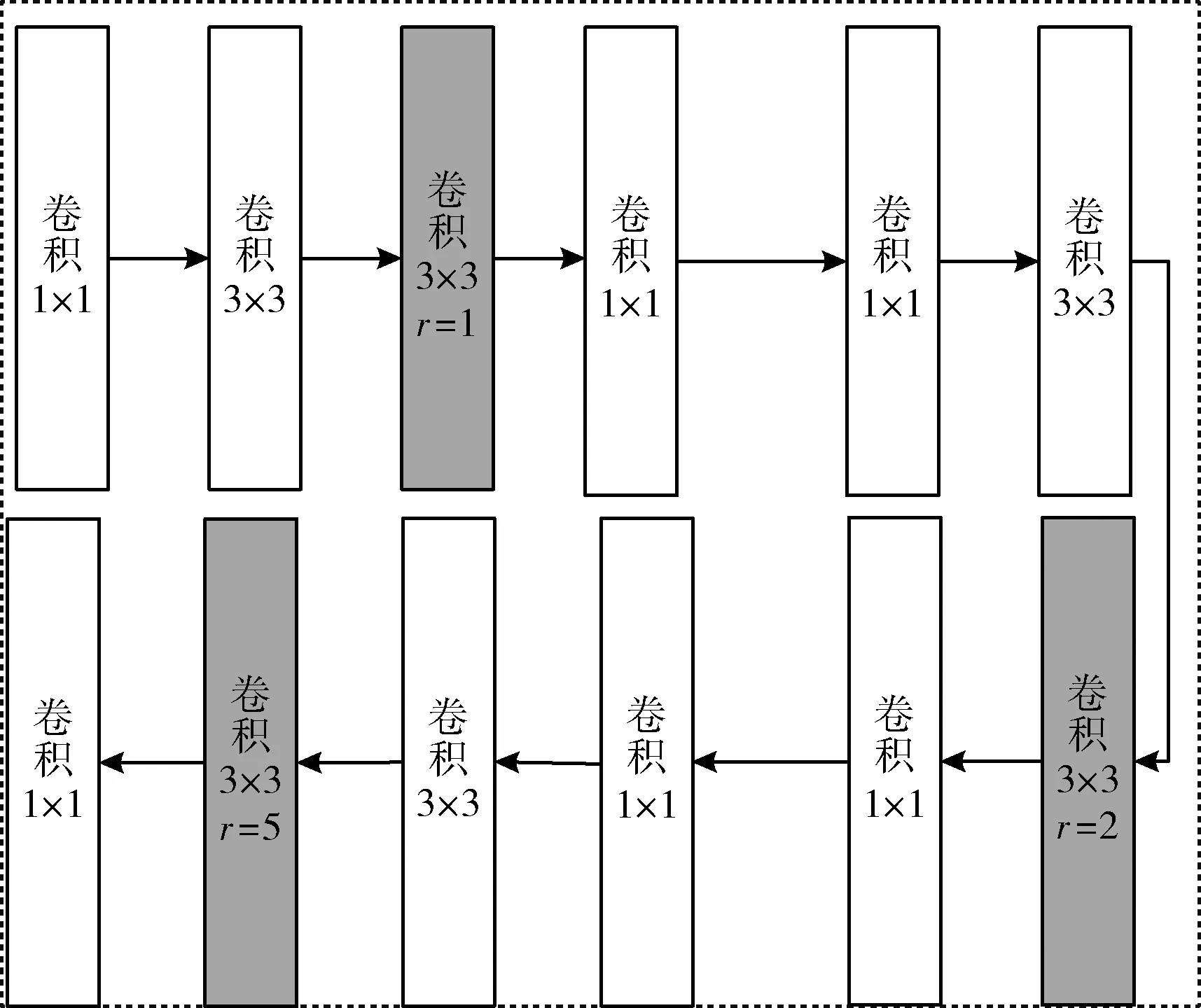
图3 混合扩张卷积模块
1.3 注意力机制
注意力机制被广泛应用到卷积神经网络上,虽然卷积神经网络可以通过卷积操作来获取图像的裂缝特征,但是由于裂缝图像本身裂缝像素较少,且存在大量的冗余噪声,因此模型可能关注点会被这些噪声所干扰,而注意力机制恰好可以使得模型在提取特征时定位到感兴趣区域,降低噪声对模型特征提取的影响。本文中使用的空间-通道注意力机制模块[9]如图4所示,该模块结合了通道注意力机制和空间注意力机制,可以更好增强裂缝特征,抑制非裂缝特征,减少噪声的影响。
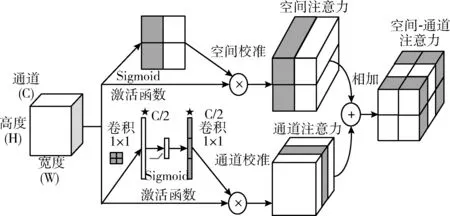
图4 空间-通道注意力机制模块
空间注意力机制主要是对目标的定位,之后对定位到的目标进行选择,选择正确的定位点并排除错误的目标定位点,之后将注意力关注到正确的位置,降低模型对非必要像素的关注和检测,保留图像的关键信息。通道注意力机制的操作是对图像的各个通道进行兴趣点的关注,学习图像各个通道维度的信息特征。两者的区别在于在不同维度和角度来关注图像的裂缝特征信息,通道注意力机制分为Squeeze和Excitation操作。Squeeze操作将各通道的全局特征作为该通道的表示,使用全局平均池化生成各通道的统计量。Excitation操作通过在通道维度上提取裂缝的有效性息,计算各个通道上对于裂缝的关注程度。空间-通道注意力机制模块就是将空间注意力机制和通道注意力机制相加,能够得到更精准的特征图。
对于裂缝检测而言,由于路面复杂的背景以及裂缝拓扑结构的多变性,空间-通道注意力机制能够更好增强裂缝特征,抑制非裂缝特征,提取更多的裂缝特征。本文将空间-通道注意力机制模块运用在编码的下采样阶段,每个下采样阶段使用该模块可以减少下采样时裂缝特征的丢失,有效增强裂缝特征,抑制非裂缝特征。
1.4 多尺度特征融合
在许多检测工作中,不同深度和尺度的特征图所包含的有效信息各不相同,对检测精度都有着不同程度的影响。在卷积神经网络中,低层特征包含更多的局部信息特征,包含更多的细节,但是语义较低,噪声较大。高层特征语义信息较强,但是分辨率很低,由于频繁的下采样操作丢失了许多局部细节特征。对于裂缝检测而言,由于裂缝本身的结构特性与周围噪声特性较为相似,即使是人眼检测也难以很好将其和背景噪声分开,因此这一特性是当前裂缝检测领域所遇到的难点。在裂缝检测网络中,低层的卷积层可以提取到较多的裂缝特征,但是这些特征图受路面复杂背景环境的影响会存在很多的噪声、黑斑和污垢等。在经过多层的卷积层和池化层处理之后,高层的卷积可以从这些低层卷积层提取的特征图中提取到更高级特征,其噪声、黑斑和污垢也会随之减少,但是随着网络层次的加深许多细小的裂缝就会丢失,这样就造成高层提取的特征图丢失过多的细节特征,导致检测的结果与路面真实情况相差甚远。由此可以看出,不同卷积层得到的特征图有各自的优缺点,但是不同层之间可以相互补充,将低层提取的特征图与高层提取的特征图进行融合来提高裂缝检测的精度。
为了解决该问题,本文提出了多尺度特征融合,如图5所示。每一层输出的特征图使用卷积核大小为1×1的卷积进行处理,再上采样到输入图像的大小,最后融合不同层次特征图得到最终的预测图。多尺度特征融合模块融合多尺度和多层次的特征使最终的预测图更接近路面真实状况。
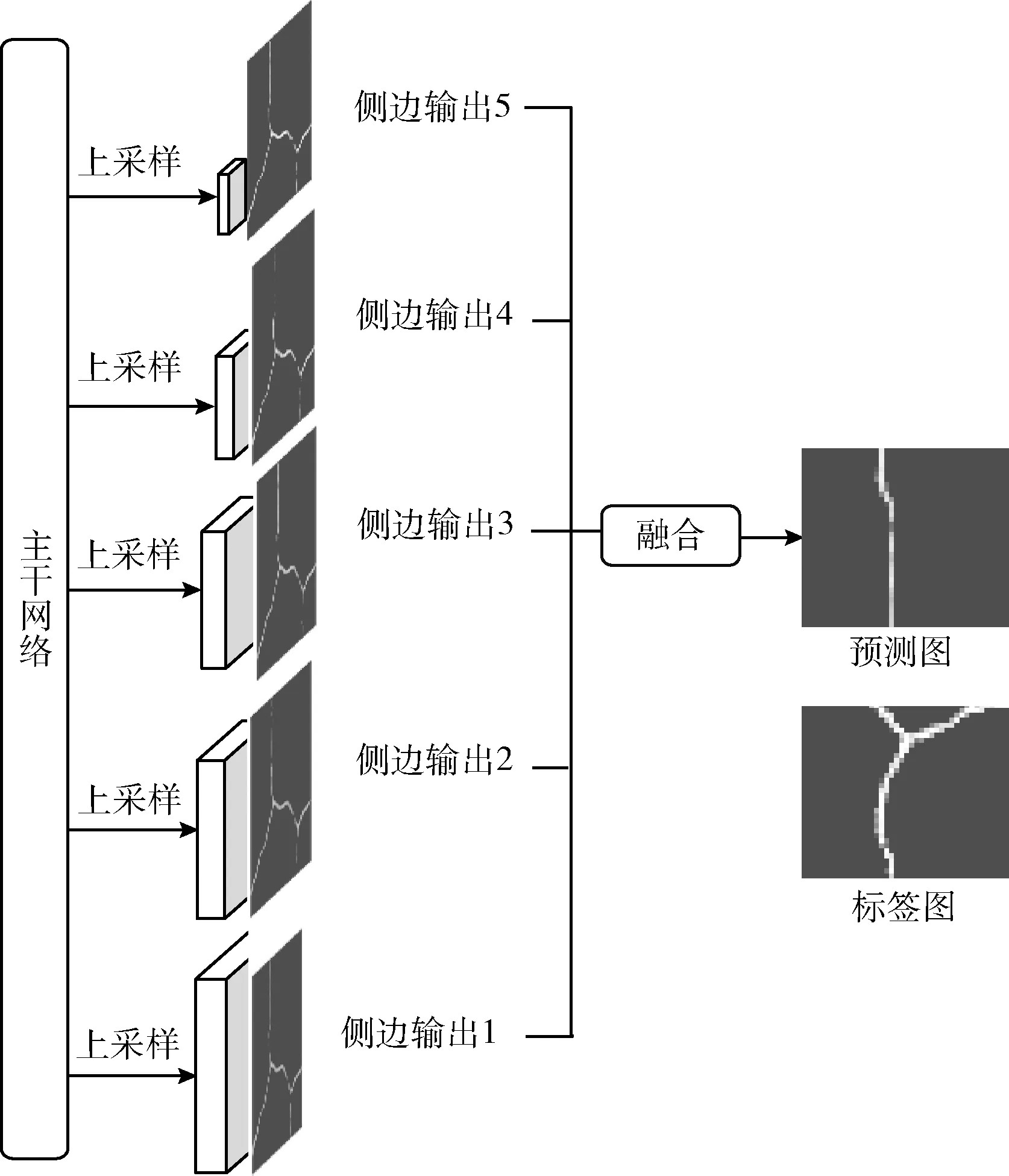
图5 多尺度特征融合模块
2 实 验
2.1 数据集
(1)DeepCrack:Liu等[10]建立了一个名为DeepCrack的公共路面数据集。该数据集由537张人工标注的路面裂缝图像,其中300张用来训练,237张用来测试。对于一些光滑的路面裂缝图像,裂缝和背景之间有明显的区分,这种类型的裂缝比较容易检测[11]。对于一些粗糙的路面裂缝图像,裂缝有明显的遮挡,亮度不均匀,甚至有些裂缝表面有污渍,因此裂缝和背景之间的区分度相对而言并不明显,即使是人眼也很难对其进行区分,这类裂缝成为了当前裂缝检测领域的检测难点。为了更好训练本文的模型,训练数据集的规模大小是至关重要的影响点,但由于当前公开的裂缝检测数据集规模都比较小,会对模型的训练造成一定程度的精度降低,因此在训练前对数据集采用数据增强的方式进行了扩充。对当前DeepCrack训练数据集中的每幅图像进行8次角度旋转以及水平旋转,旋转角度为[45°、90°、135°、180°、225°、270°、315°、360°],最终每幅图像都扩充为16幅,即将数据集扩充到16倍大小。同时,为了使得模型能够快速训练并收敛,将训练数据集中的图像缩放到比例为256×256大小。数据集的扩充只是为了能够增强模型的精确度和泛化能力,因此在测试阶段并没有对测试数据集进行数据的扩充操作。
(2)CFD:CFD数据集[12]由118张480×320像素的图像组成。每张图像都有手动标记的裂纹轮廓。本文采用该数据集作为测试集对模型进行测试。
(3)CRACK500:Yang等[4]提出了一个名为CRACK500的路面裂缝数据集。该数据集由1124张尺寸大小为640×360的路面裂缝图像组成,每张图像有较为复杂的背景。本文使用该数据集作为测试集来验证所提出的网络。
2.2 对比实验
为了验证所提出的裂缝检测算法的有效性,将所提出的裂缝检测算法与现有的裂缝检测、边缘检测以及图像分割算法进行对比。本文的对比实验在相同的实验参数配置以及硬件环境条件下进行,考虑到数据集训练时间以及效果的因素,本文采用DeepCrack训练数据集进行训练,并在3个公开的数据集DeepCrack、CFD和Crack500上进行了测试。在训练期间,将每个输入图像都缩放为256×256大小进行训练,并将学习率设置为le-4,且最终的侧边损失权重固定为[0.5、0.75、1、0.75、0.5],并采用动态调整学习率的方式来进行训练,在每100个epoch的时候将学习率设置为之前的0.1倍,权重衰减为2e-4,epoch设置为700,并且每50个epoch保存一次模型。所有实验均在配备Tesla-V100-SXM2-32 GB GPU和4核Inter(R)Xeno(R)Sliver 4214 CPU的服务器上进行的。
(1)HED:整体边缘检测网络(holistically-nested edge detection,HED)[13]是一种新的边缘检测算法,裂缝的检测可以被视为边缘检测任务,定位裂缝的边缘细节特征,并将其识别出来。
(2)DeepCrack:DeepCrack[10]网络模型使用VGG16作为骨干网络,同时使用深监督模型训练的方式来提高网络的精确度和泛化能力,该模型具有5个侧边网络,其损失函数的最终值为所有侧边网络损失值权重和。
(3)DeepCrackT:DeepCrackT[14]采用SegNet作为模型的骨干网络,SegNet网络是一种端到端的语义分割网络模型,将裂缝检测任务使用语义分割算法来进行解决,因为是对单个像素点进行预测,因此可以很好提高网络模型的检测精度,将模型的检测提升到毫米级别。因为该算法与DeepCrack重名,为了区分它们,将该算法命名为DeepCrackT。
(4)FPHBN:特征金字塔和分层提升网络(feature pyramid and hierarchical boosting network,FPHBN)[4]是基于HED网络改进的裂缝检测网络,其最主要的创新是将特征图金字塔模型和分层推进模型纳入到网络模型中,提高了网络模型的检测精度和泛化能力。
(5)DeepLab v3+:DeepLab v3+[15]在原有的DeepLab v3的基础上增加了一个简单有效的解码器来修正分割结果,尤其是目标的边界。
(6)CrackSegNet:CrackSegNet[16]由骨干网络、扩张卷积、空洞金字塔池化和跳跃连接模块组成。这些模块可以用于高效的多尺度特征提取、聚合和分辨率重建,增强了网络的分割能力。
(7)CrackW-Net:CrackW-Net[17]通过卷积神经网络实现跳跃级往返采样块结构,从而构建了一种新的像素级别的语义分割网络用于裂缝检测。
2.3 评估指标
在深度学习中通常需要建立各种网络模型来解决具体问题,但是对于模型的好坏以及其性能需要一定的评估指标来进行评估。因此为了评估裂缝检测的效果以及所提出的网络模型的好坏,本文使用准确率(Precision,P)、召回率(Recall,R)和F-score(F)作为评估指标。
准确率主要针对预测结果而言,代表所有被预测为正的样本中实际为正样本的概率。召回率主要针对原样本而言,代表实际为正的样本中被预测为正样本的概率。在实际的检测中,希望得到高准确率、高召回率的预测结果,但是通常情况下可以发现精确率高的模型往往召回率会降低,当提高召回率的时候,精确率又会降低。因此需要平衡两者来度量模型的好坏,同时还可以通过精确率和召回率的最终预测数值来对模型进行分析,判断模型精度降低的原因,并针对具体问题和具体问题产生的原因来采取相应的措施。F-score结合了准确率和召回率,当两者达到最高时取得平衡。此外,检测结果中被正确检测并判断为裂缝像素点个数的称为真正例(true positives,TP),检测结果中将背景像素误检为裂缝像素点个数的称为假正例(false positives,FP),检测结果中被正确检测并判断为背景像素的个数称为真反正例(true negatives,TN),检测结果中将裂缝像素误检为背景像素点个数称为假反正例(false negatives,FN)。综上所述,Precision、Recall、F-score如式(2)、式(3)、式(4)所示
Precision=TPTP+FP
(2)
Recall=TPTP+FN
(3)
F-score=2×Precision×RecallPrecision+Recall
(4)
由于F-score结合了准确率和召回率,能够很好平衡两者之间关系,故本文使用F-score作为最终结果。
2.4 实验结果与分析
为了验证所提出网络的有效性,将本文提出的网络以及HED、DeepCrack、DeepCrackT、FPHBN、DeepLab v3+、CrackSegNet、CrackW-Net固定在同一硬件环境及参数初始化条件,并使用DeepCrack训练集进行训练之后,分别在DeepCrack、CFD和CRACK500数据集测试,在DeepCrack、CFD和CRACK500这3个数据集上不同网络的检测结果图像如图6所示。此外,本文使用所提出的评估指标对不同的算法进行评估,对比实验评估结果评估结果见表1,在DeepCrack、CFD和CRACK500数据集上的准确率-召回率曲线如图7所示。

表1 对比实验评估结果
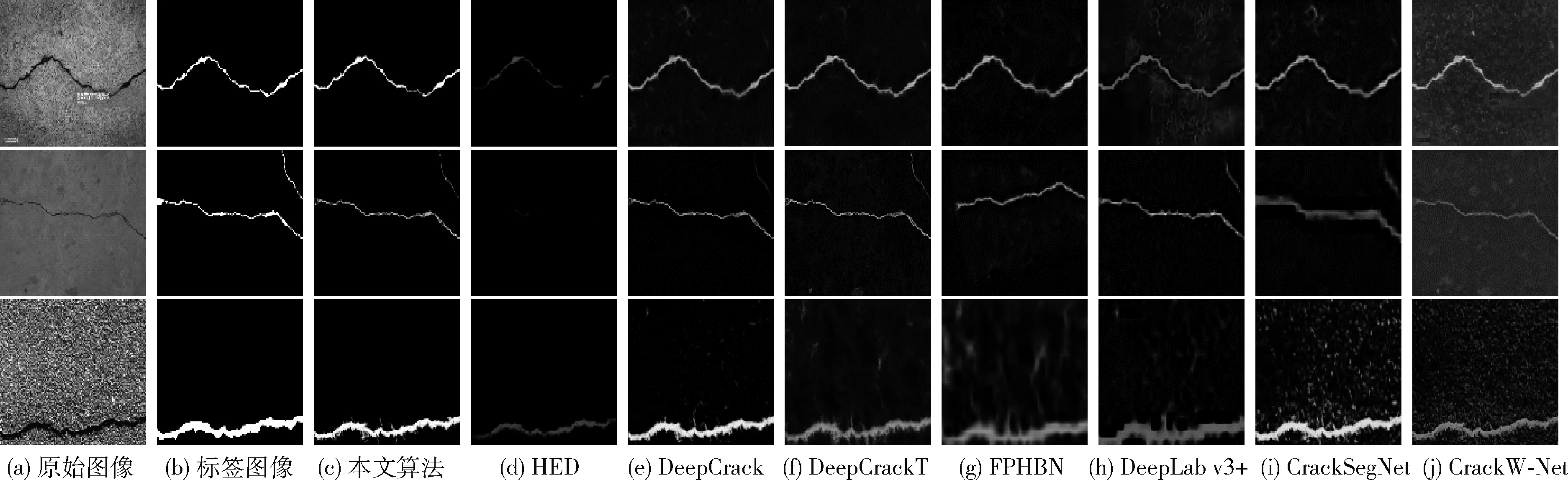
图6 自上而下分别是在DeepCrack、CFD和CRACK500这3个数据集上不同网络的检测结果图像
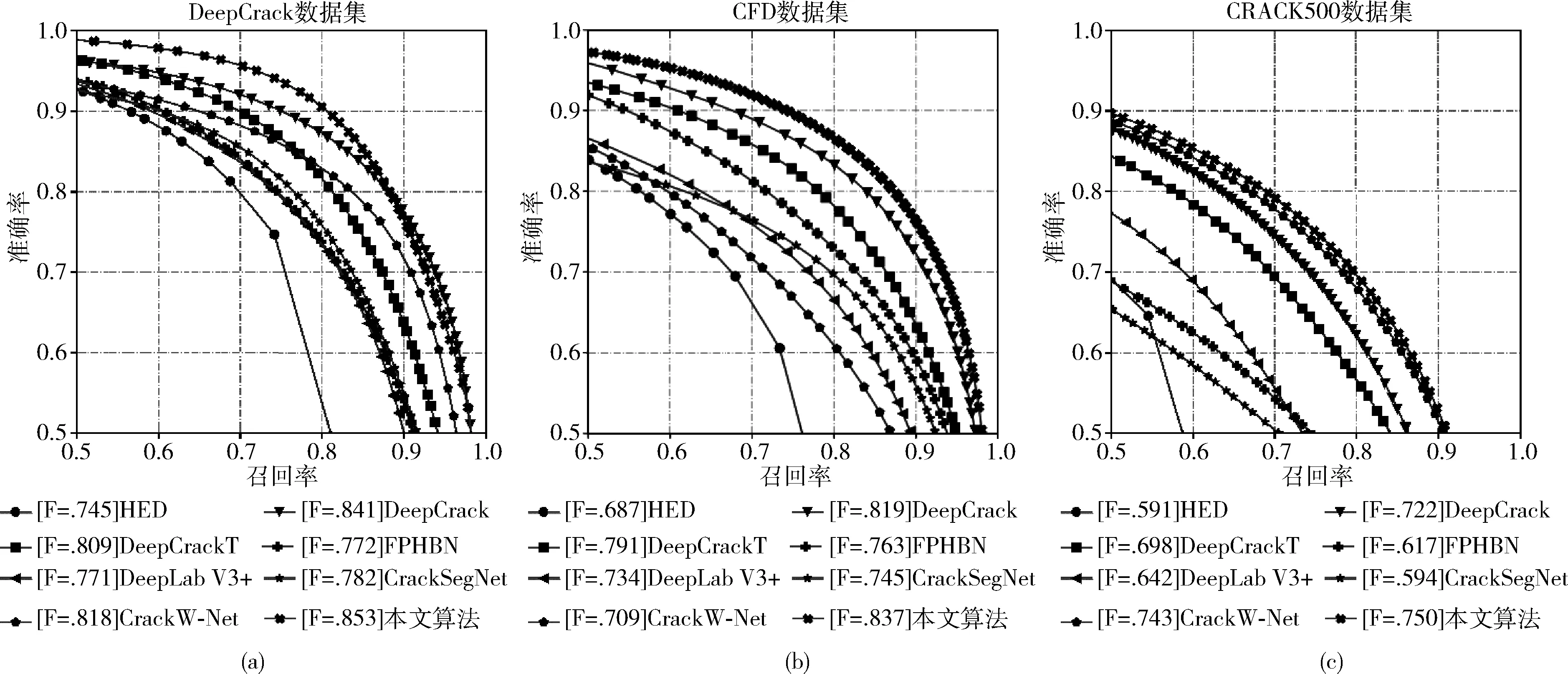
图7 在DeepCrack、CFD和CRACK500数据集上的准确率-召回率曲线
(1)在DeepCrack上的实验结果:从表1中和图7(a)可以看到在相同的实验条件下,本文所提出的算法优于其它算法,达到了最高的F-score值。相比较于HED、DeepCrack、DeepCrackT、FPHBN、DeepLab v3+、CrackSegNet、CrackW-Net分别提高10.76%、1.13%、4.41%、8.07%、8.19%、7.03%、3.51%
(2)在CFD上的实验结果:从表1中和图7(b)可以看到在相同的实验条件下本文所提出的算法优于其它算法,达到了最高的F-score值相比较于HED、DeepCrack、DeeCrackT、FPHBN、DeepLab v3+、CrackSegNet、CrackW-Net分别提高了15.02%、1.81%,4.61%、7.37%、10.35%、9.19%、12.84%。
(3)在CRACK500上的实验结果:从表1中和图7(c)可以看到在相同的实验条件下本文所提出的算法优于其它算法,达到了最高的F-score值,相比较于HED、DeepCrack、DeepCrackT、FPHBN、DeepLab v3+、CrackSegNet、CrackW-Net分别提高了15.87%、2.78%、5.25%、13.34%、10.78%、15.62%、0.74%。F-score值在该数据集上相对于其它两个数据集有所下降。
从视觉角度出发,根据图6可知,本文算法提取的裂缝细节保存完整,预测结果受噪声影响较小,与路面真实情况较为接近。从客观角度出发,由表1和图7可以看出,本文所提出的算法的各项评估指标高于其它算法。因此,无论从视觉角度还是评估指标来看,本文所提出的算法在复杂的背景下能够对裂缝特征进行准确的提取,具有较好的检测效果。
2.5 消融实验
本文使用增减引入的模块并在DeepCrack数据集上进行消融实验来验证模块有效性。消融实验评估结果见表2,其中U-Net表示使用最原始的U-Net网络去提取裂缝,U-Net+HDC表示在U-Net基础上引入混合扩张卷积模块,U-Net+HDC+scSE表示U-Net+HDC基础上引入空间-通道注意力机制模块,本文算法表示在U-Net+HDC+scSE的基础上使用多尺度特征融合。由表2可知,本文所提出的模块都能提高裂缝检测的准确率,当结合混合扩张卷积,空间-通道注意力机制结合和多尺度特征融合时,达到的效果最好。
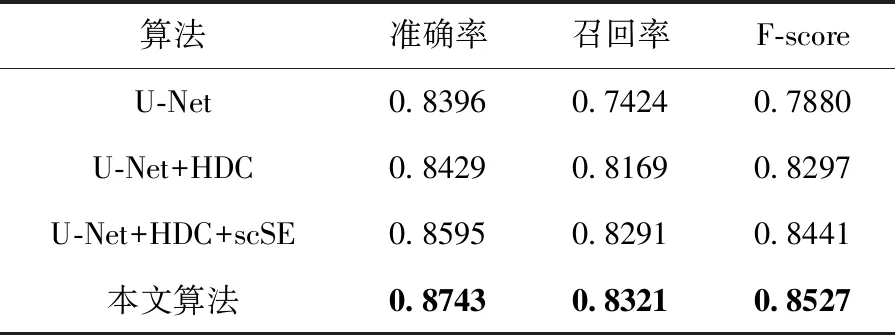
表2 在DeepCrack数据集上的消融实验评估结果
3 结束语
本文提出了一种基于混合扩张卷积和空间-通道注意力机制的路面裂缝检测算法,解决了复杂背景下路面裂缝检测困难的问题。首先将空间-通道注意力机制融入主干网络来提取裂缝特征。其次在网络的中间部分引入混合扩张卷积模块,实现在增加网络的感受野的同时减少局部特征的丢失。最后使用多尺度特征融合对提取的裂缝特征进行融合,使最终预测结果更接近路面真实情况。最终本文算法在公开数据集上预测的F-score值充分地验证了本文算法的有效性。
