融合知识的小片段代码相似性比较模型
2023-09-13庞建民
夏 冰,周 鑫,庞建民+,岳 峰,单 征,3
(1.信息工程大学 网络空间安全学院,河南 郑州 450001;2.中原工学院 前沿信息技术研究院,河南 郑州 450007;3.信息工程大学 嵩山实验室,河南 郑州 450007)
0 引 言
二进制代码相似性比较技术广泛应用于无源代码软件安全分析中[1],如bug搜索、恶意软件分析检测、补丁生成分析和软件窃取检测等方面。以OpenSSL(open secure sockets layer)统计分析为例,二进制代码中小于5条指令的基本块数量占比53%,不超过5个基本块组成的二进制函数占比70.69%。这些较少基本块组成的小片段代码,由于携带指令序列较短,控制流程图简单,有限的语义信息使得当前二进制代码相似性比较方案准确性差,因此如何提升小片段代码相似性比较准确率对软件安全分析具有重要意义。
软件是人类在工作中用特定语言创造出来的,是人类知识得以延续的新载体。软件知识并不随软件编译优化和跨平台的改变而改变,因此知识的稳定性、可重复性和可预测性[2]能准确反映代码间相似性比较结果。基于该思想,在二进制代码知识分析基础之上,融合代码中的函数嵌入和知识嵌入,提出一种二进制小片段代码相似性比较模型BSM(binary snippet code similarity model)。
本文贡献如下:①提出一种二进制函数代码知识学习方法。方法将切分后的函数代码知识看作单词,基本块序列上携带的知识序列看作句子,送入序列神经网络得到知识嵌入;②提出一种融合知识嵌入和函数嵌入的二进制代码小片段相似性比较模型。实验结果表明,相较于当前最优的函数嵌入方案,模型可显著提升二进制小片段代码相似性比较结果,验证集上准确率达到98.37%。
1 相关工作
1.1 二进制代码
二进制代码是指源代码经过编译链接后,可被CPU直接执行的机器代码。编译生成的二进制目标文件通常由多个二进制函数组成并按照线性地址LA(linear address)存储。一段线性地址范围可表示一个二进制函数F(binary function),如图1“Add”函数LA范围为0x00401410-0x004014C4。LA范围内的机器代码称之为二进制片段代码。为讨论方便,本文将二进制函数F等价于二进制片段代码。二进制函数F由至少一个基本块BB(basic block)组成并在控制流图CFG(control flow graph)作用下表达函数功能。CFG可用一个二元组(N,E)描述,其中N是有穷节点集合,每个节点表示函数内一个基本块BB;E是边集合,表示基本块之间的“True-False”调用连接关系。二进制函数既可用线性地址LA上的指令序列表示,也可以用CFG表示,两种表示是等价的。以“Add”函数为例,图右上半部是函数线性地址的指令序列表示,图右下半部是函数流程图CFG表示。二进制代码的线性地址序列表示和流程图表示如图1所示。

图1 二进制代码的线性地址序列表示和流程图表示
本文将由较少数量基本块组成的二进制函数称之为小片段代码S(snippet code)。小片段代码S在二进制软件中占比较高,以OpenSSL和Linux操作系统内核为例,基本块数量范围在[1,3]的函数数量分别占比二进制函数总量的56.60%和54.55%。基本块数量范围在[1,5]的二进制函数占比更高,分别高达67.84%和70.69%。基本块占比见表1。

表1 基本块占比/%
1.2 二进制代码相似性比较
随着自然语言处理和深度学习的兴起,二进制代码天然的线性地址布局为基于序列分析方案提供优势,将线性地址上的指令序列喂入序列神经网络模型得到函数嵌入向量,二进制代码相似性计算就转换为向量间比较。文献[3]提出的αDiff方案对函数上的原始字节序列进行编码生成函数嵌入;文献[4]提出的ZEEK方案将二进制函数中的每个基本块分割成多个串(strand)并向量化,利用全连接网络判定两个函数是否属于同一类。文献[5]在汇编指令级上捕获连续基本块内的程序行为集合并编码为向量,采用基于树的机器学习模型来预测两个函数相似概率值。文献[6]把指令看作单词,基本块看作句子,利用循环神经网络RNN(recurrent neural network)实现基本块间相似性比较。文献[7]类似文献[6]的思路,通过机器翻译NMT(neural machine translation)技术实现基本块间相似性比较。SAFE(self-attentive function embedding)方案[8]将函数指令序列喂入双向循环神经网络BRNN(bi-directional recurrent neural network)得到函数嵌入。文献[9]将组成指令的操作码和操作数看作词,基本块看作句子,基本块间随机游走路径看作段落,加权不同路径生成函数嵌入。
二进制代码用CFG表示后,代码相似性计算问题就转换为图相似性比较问题。Gemini[10]提出属性控制流图,采用人工方式抽取基本块特征,利用structure2vec技术生成函数嵌入,但方案不考虑少于10个基本块的函数;I2V(instruction 2 vector)[11]采用无监督方式生成基本块嵌入,利用structure2vec技术生成函数嵌入,但方案将函数基本块数量设置为150;文献[12]提出指令依赖关系图。文献[13]融入语义感知、结构感知、顺序感知等信息,使用BERT[14](bidirectional encoder representations from transformers)模型生成函数嵌入。
以上方案在基本块较多的代码上具有较高相似性结果,但是在小片段代码比较上却具有较低准确率[1,15]。由于小片段代码指令序列较短,深度学习的不可解释特性使得两个不相似的小片段函数产生高度相似结果。同时,图节点数量较少,节点间调用逻辑简单,节点属性可利用较少,再加上同一份源代码可编译到不同平台上,因此需要引入稳定的外部信息,增强并提升跨平台代码相似性比较的准确性。
2 问题定义和函数知识学习
本章主要给出二进制代码相似性定义,提出一种二进制函数知识学习方法。
2.1 二进制代码片段相似性
两个二进制函数F1和F2相似是指相同的源代码s编译生成的结果F1s和F2s是相似的,记作F1≈F2。 二进制代码相似性挑战在于编译转换过程的多样性。转换过程可利用不同的编译器c如gcc、clang,可携带不同的编译选项-O[0,1,2,3],可生成不同平台(如X86、ARM)的二进制函数。

在指令、基本块的表示学习实现上,可通过word2vec等词向量生成模型将指令用向量表示;基于指令学习表示,将基本块内的指令序列喂入RNN等序列学习模型后可得到基本块嵌入。一旦得到指令嵌入或基本块嵌入,函数可借助序列学习或者图神经网络学习生成最终函数嵌入。
2.2 函数知识学习
知识在软件体上无处不在,通过开源或者版本更新等方式传承下来。有经验的软件开发者,为了调试和调用方便,通常给函数取一个代表其功能含义的名字如SendData、Sort,并在函数内调用应用程序接口API(application programming interface)或者其它已实现的函数来加速实现软件功能。这些函数名和API名,是软件开发者将人类工作经验通过语言赋能在软件体上,清晰地表达了函数的高级语义功能。为描述方便,本文将函数名和API名统称为函数名,将软件开发者工作经验称之为函数代码知识。
为保持函数命名风格一致,编译器会对函数名进行特殊处理,如名为“_ZNSt22condition_variable_anyD2Ev”的函数,其中字符串_ZNSt22、D2Ev是编译器在编译过程中增加的内容。对于这些函数名,需借助第三方工具如cxxfilt、undname等,使其恢复为“condition_variable_any”。有经验的软件开发者通常采用两种函数名命名风格。一种是首字母小写,后面单词首字母大写,这种命名风格称之为camelCase骆驼拼写法(如setFlagWithResult)。一种是通过“_”分隔符将每个单词拼接在一起,这种命名风格称之为SnakeCase蛇形命名法(如Set_Flag_With_Result,即用下划线将单词连接起来)。函数名称越长,携带的知识越多。
函数名称太长不利于构建知识字典,因此需要进行知识切分。假定较长函数知识主要通过两种不同的命名风格进行描述,分析其规律可使其长名字切分成多个token。如二进制函数内部调用了函数“Set_Flag_With_Result”和API“SetSockOpt”,该函数代码知识切分后则有“set flag with result set sock opt ”7个token组成。这样,通过少数常用token的组合可表达多个函数知识,如“set”出现在上述函数名和API名中。切分不仅能保持命名的不变性,又有助于构建知识字典防止OOV(out of vocabulary)问题出现。将函数代码知识切分生成的token序列看作一行句子,借助word2vec词向量生成模型,可将各个token知识转换成向量表示。
这样,函数知识学习算法流程描述如下:首先提取CFG上简单路径,路径上的每个点代表基本块;接着提取基本块包含的函数代码知识(如API序列、引用函数名);随后将一条简单路径上所有函数代码知识进行切分形成一个序列;最后,将序列看作句子,喂入词向量生成模型得到知识学习表示结果。具体实现见3.4节。
采用简单路径提取、切分和学习函数知识,有下列好处:一是token序列形成的句子可反映某一执行时刻函数的动态特性;二是遍历得到的所有执行路径可以充分表达函数功能的全面性;三是每个token都能够学习到函数知识序列的前后上下文语义,保持其命名的完整性。第4章实验与结果分析表明,二进制代码融合知识学习表示后,可显著提升代码相似性比较的准确性。
3 实现和训练
3.1 整体方案
BSM模型整体方案由函数嵌入和知识嵌入两部分组成。BSM模型结构如图2所示。
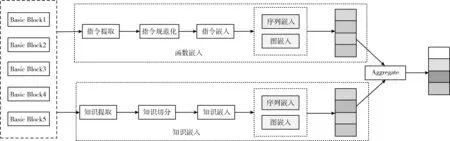
图2 BSM模型结构

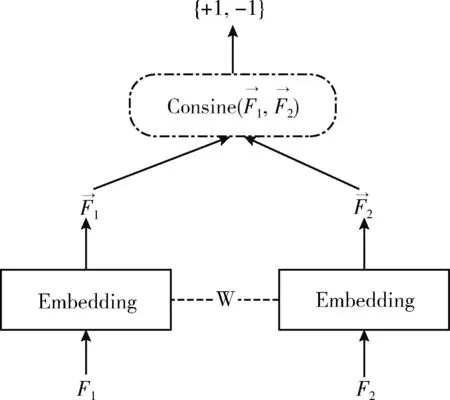
图3 孪生网络架构
3.2 数据集
类似Gemini、SAFE和I2V方案,本文采用OpenSSL作为基础数据集。选择OpenSSL1.1两个版本(f、m)的源代码,采用gcc编译器并携带不同的编译选项-O[0,1,2,3],分别编译到X86平台、ARM平台上;接着利用Radare2逆向分析工具分别提取函数基本块和函数代码知识,将来自相同源代码的两个二进制函数定义为相似并标记为+1,形成一对函数。为保持数据集平衡,通过随机方式构建相同数量的不相似函数对并标记为-1,共计得到401 050对X86平台函数,900 490对跨平台函数。
小片段代码数据集是满足一定条件的基础数据集的子集。在小片段代码数据集构建上,仅仅保留X86平台基础数据集中不超过3个基本块的函数对、X86平台基础数据集中不超过5个基本块的函数对和跨平台基础数据集中不超过5个基本块的函数对,分别得到Dataset_A、Dataset_B和Dataset_C数据集。小片段代码数据集见表2。
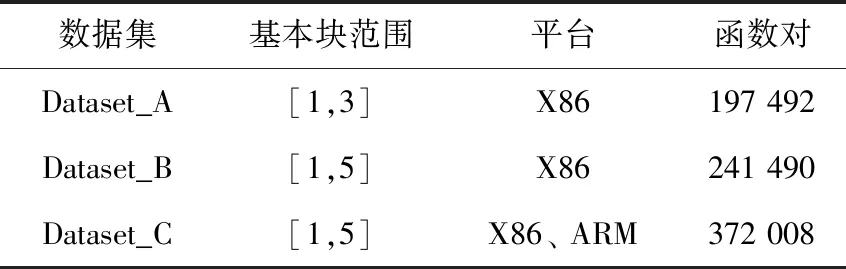
表2 小片段代码数据集

3.3 基准Baseline
为便于分析对比,用BSMSAFE表示本文BSM模型是在SAFE函数嵌入基础之上通过融合知识嵌入的方式得到。同样,可得到对应的比较模型BSMi2v和BSMGemini。
同SAFE、Gemini、I2V一样,将准确率作为衡量模型的对比标准。每训练一轮,则在验证数据集上计算当前验证准确率Val Auc。如果当前验证准确率最高,则进行测试数据集计算,得到测试准确率Test Auc。通过这种方式,得到每种模型的最优验证集准确率Val Auc和最优测试集准确率Test Auc。
3.4 参数设置与训练
为生成token向量,本文采用基于Skip-gram策略的word2vec词向量模型将每个token转换为向量形式。利用2.2节的方法对文献[16]中提供的464个二进制文件,利用Radare2工具提取并生成二进制函数控制流程图CFG后,借助NetworkX提取图中简单路径,将其一条路径上携带的函数代码知识切分后看作一行句子。将生成的8400万行句子作为数据集,喂入word2vec词向量模型进行词向量训练,最终得到包含8756个token的知识词向量词典。word2vec全局参数设置如下:token词向量设置为96维,滑动窗口大小设置为5,词频设置为5。
为做到在相同实验条件下开展方案间对比,基于表2小片段代码数据集,模型采用SAFE[8]提供的指令词向量词典和本文训练得到的token知识词向量词典,将Adam作为优化器,均方误差MSE(mean square error)作为损失函数。
4 实验与结果分析
本章在单平台序列表示学习相似性任务、单平台图表示学习相似性任务和跨平台相似性任务上给出模型间比较结果。
4.1 单平台序列表示学习相似性任务对比
本任务选择Dataset_A作为数据集,从序列学习角度对比BSMSAFE和SAFE模型。在序列长度设置上,Dataset_A设置指令序列长度60,30个token知识(超出部分截断,不足部分补齐)。指令序列学习模型采用携带注意力机制的双向GRU,函数嵌入结果64维。模型训练50轮,每批数据大小为250。基本块范围[1-3]序列表示学习模型间比较见表3。
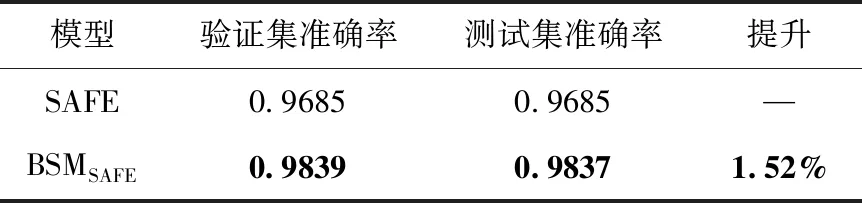
表3 基本块范围[1-3]序列表示学习模型间比较
从表3的BSMSAFE与SAFE对比来看,融合知识表示学习的BSMSAFE模型提升了准确率,在Dataset_A测试集上准确率高达98.37%。鉴于SAFE采用携带注意力机制的GRU方案,因此BSM同时对比了RNN、BiLSTM等序列神经网络模型。与SAFE不同的是,这些模型不携带注意力机制。未携带注意力机制的序列表示学习模型间比较见表4。
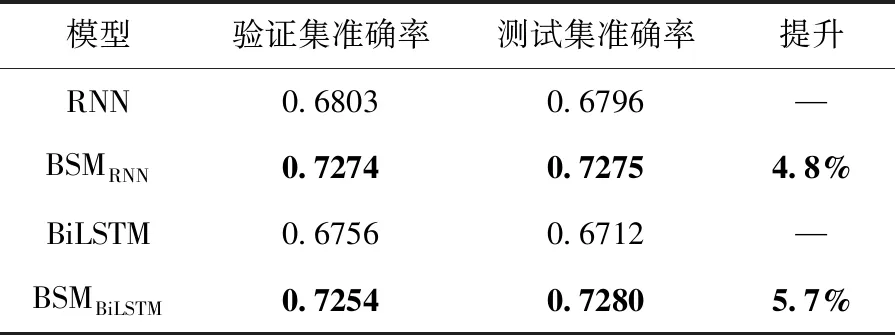
表4 未携带注意力机制的序列表示学习模型间比较
对比未融合函数知识表示的RNN和BiLSTM模型,BSM在Dataset_A上准确率分别提升4.8%和5.7%。同时进一步发现,携带注意力机制的BSMSAFE序列模型准确率在二进制小代码片段上为98.37%,高于RNN模型30.4%。这说明注意力机制能够聚焦二进制代码相似性比较任务更为关键的信息,提升任务准确率。
4.2 单平台图表示学习相似性任务对比
本次任务选择Dataset_B作为数据集,在X86单平台上从图嵌入学习角度,对比BSMGemini和Gemini模型,BSMI2V和I2V模型。图嵌入训练参数设置如下:基本块指令序列最大长度为20,基本块数量为5,函数最多30个token知识,函数嵌入结果64维,训练10轮,每批数据大小为250。单平台图表示学习方案间比较见表5。
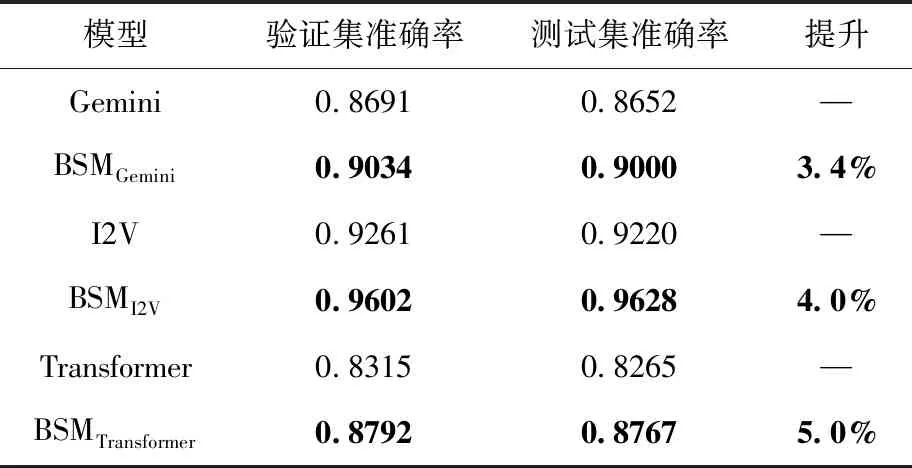
表5 单平台图表示学习方案间比较
如表5实验结果所示,融合知识嵌入的BSM模型准确率均有显著提升。BSMGemini模型准确率比Gemini模型提升3.4%,BSMI2V模型准确率比I2V模型上提升4.0%。Transformer作为当前比较火热的编码模型,本文也进行了对比,发现基本块上采用Transformer编码方案,在准确率上不如I2V采用的携带注意力机制的BiLSTM方案。分析其原因可能在于Transformer机制在于仅仅考虑注意力,而基本块上的指令天然具有序列含义。也或许Transformer在编码和解码同时采用的时候性能最佳。这也进一步说明最优的、最先进的神经模型,还需要在二进制代码相似性比较任务上给出最佳实践。
对比表3和表5,发现序列学习表示模型优于图嵌入表示模型,如BSMSAFE模型准确率高于BSMGemini模型8%,BSMSAFE模型准确率高于BSMI2V模型2%,说明利用节点邻居更新节点表示的图神经网络GNN在简单结构图上并不足以捕获函数丰富的语义。从表5发现,BSM未在Dataset_A数据集上做验证比较。这是因为,数据集分析发现基本块数量范围[1-3]中,85%的函数仅仅携带一个基本块,对于包含2个基本块的函数可用一个序列表示,包含3个基本块的函数最多表现为2条序列。
4.3 跨平台相似性任务对比
为验证函数知识不随平台改变而改变,代码越相似性知识越稳定的特性,BSM模型在跨平台相似性任务上分别对比SAFE模型、Gemini模型和I2V模型。即在跨平台数据集Dataset_C上,从序列嵌入学习角度对比SAFE,从图嵌入学习角度对比Gemini和I2V。模型全局参数和单平台保持一致。跨平台方案间比较见表6。

表6 跨平台方案间比较
表6对比发现,融合知识嵌入的BSM方案在跨平台上有较大准确率提升,BSMGemini在准确率方面优于Gemini方案6.2%,BSMI2V在准确率方面优于I2V方案4.7%,BSMSAFE在准确率方面优于SAFE方案4.1%。这说明知识的不变特性有助于缩小跨平台指令带来的语义鸿沟。
同时,对比表5和表6发现,融合知识表示学习的BSM方案在准确率提升幅度上跨平台要高于单平台,如BSMGemini和Gemini方案对比中跨平台准确率提升是6.2%,单平台提升是3.4%,说明知识不随平台改变而改变,相对指令巨大差异来讲知识具有跨平台稳定特性。
4.4 不同知识学习表示对比
将提取到的函数代码知识分别从序列学习表示和图学习表示角度生成知识嵌入,验证不同知识表示学习方式给模型带来的影响。在图学习表示实现上,采用补齐或者截断的方式,设置基本块token知识序列长度为5,将其得到的基本块嵌入利用structure2vec技术生成知识嵌入。在序列学习表示实现上,按照基本块线性地址存储顺序提取函数代码知识,并设置函数token知识序列长度为30(采用补齐或者截断的方式),采用携带注意力机制的BiLSTM技术生成知识嵌入。经过实验验证,知识图学习表示在提升模型准确率上不如知识序列学习表示,存在2%左右的差距。
综上,3个任务实验结果表明,本文提出的BSM模型对比基于线性地址序列函数嵌入和基于基本块逻辑调用图函数嵌入均表现出色,知识表示学习可提升二进制小代码片段相似性比较结果,验证了知识并不随软件编译优化和跨平台的改变而改变。融合知识表示可更准确反映代码间相似性比较结果。
5 结束语
本文借鉴软件携带并传承人类知识经验的思想,提取二进制代码片段上的函数代码知识,利用知识的跨平台遗传稳定特性,提出一种融合知识嵌入和函数嵌入的二进制代码小片段相似性比较模型。在3个数据集上进行单平台和跨平台对比实验,结果表明模型能提升小片段代码相似性比较结果的准确性。当前本文函数代码知识仅考虑函数名和API,作为软件开发者工作经验的知识还包括变量名、变量类型,因此,从二进制代码中提取这些表达软件开发者经验的高级知识有助于代码相似性比较。在下一步研究工作中,将借助调试信息预测[17]、函数命名推理[18]和多文件函数交互[19]等高级语义或语用信息,为完成代码相似性、代码搜索等下游任务提供知识增强服务。
