无监督与有监督相结合的粤语分词方法
2023-09-13苏振江张仰森胡昌秀黄改娟
苏振江,张仰森,2+,胡昌秀,黄改娟,2
(1.北京信息科技大学 智能信息处理研究所,北京 100192;2.北京交通大学 国家经济安全预警工程北京实验室,北京 100044)
0 引 言
目前,国内对于中文文本的分词算法的研究日渐成熟,很多相关研究都取得了相当不错的效果,但针对少数民族语言的分词研究工作相对较少。而网络信息中方言及少数民族的语言使用存在一定的普遍性,通常具有地域特征,例如在港澳和两广地区,粤语受到广泛的应用。与此同时,也应关注到针对港澳这类政治敏感地区,有效地对以粤语形式发表的网络信息进行监管分析,以达到保障信息安全、国防安全的目的具有重要的社会意义。粤语作为中国文化中最具特色的方言之一,具有独特的声调、发音和语法结构,通过更好的分词算法提升对粤语相关论坛和新闻网站内容的分析效果,能够更加快速有效地获悉当地舆情动向,为将来的民情民愿获取和政策决策辅助提供技术上的支撑。
因此,利用粤语社交媒体的短文本数据,进行特征提取与模型构建,设计并实现一种有效的分词算法,提升粤语分词准确性,对以粤语为研究对象的自然语言处理任务研究具有重要意义。
1 相关工作
与其它汉语方言不同,粤语创造了一套较完备的方言文字书写系统,粤语的文字书写系统可以分为通用汉字和粤语特殊用字两个部分,因为有相似的部分,所以现有的中文分词研究对粤语分词研究的开展具有相当大的启发意义。目前主流的中文分词方法主要分为3大类:基于规则的分词方法[1,2]、基于机器学习的分词方法[3-5]以及基于深度学习的分词方法[5-9]。袁向铎[10]依据构建的知识库采用双数组trie树的字符串匹配方法对中文地址进行初步分词,又设计了基于地址组成规则的分词结果处理算法来对其进行消除歧义、推导验证等处理,大大提高了分词的准确率。虽然基于规则的分词方法简单、便于操作,但单纯基于规则的分词准确率不高,未能解决未登录词识别和分词歧义。邢付贵等[11]通过互信息、信息熵、位置成词概率多特征融合的新词发现方法从大规模古籍文本中建立基础词典与候补词典,形成含有349 740个字词的集成古文词典CCIDict,并应用CCIDict实现古文的多种分词算法。虽然基于统计的分词方法可以很好地识别高频未登录词和交集型消除歧义,但是统计模型复杂度高,运行周期长,依赖人工特征提取。Tian Y等[12]提出了一种通过在训练过程中考虑不同的字符组并基于BERT的用N-gram表示增强的中文文本编码器,ZEN。ZEN能够综合字符序列和包含的单词或短语的综合信息,证明了ZEN在一系列中文NLP任务中的有效性。与其它已发布的编码器相比,ZEN使用更少的资源,并在大多数任务上表现更优越的性能。深度学习模型能大大提高中文分词的准确度,但其依赖训练预料,分词速度和跨领域分词等方面依然存在短板。
针对于粤语的相关工作,Wang Z等[13]构建了2019冠状病毒疾病相关粤语假新闻集,实证了基于深度学习的方法效果表现略优于传统的机器学习在TF-IDF特征上的方法效果。Shen A等[14]作为Lihkg在线论坛为语料库,提出一种基于字符嵌入和中文分词的主题矢量化方法,以MLP(多层感知器)神经网络为位置主题模型,该方法和模型能够有效识别论坛所讨论活动的时间和位置。Wu Bing[15]提出了一种新颖的粤语风格文本情绪分析方法,即情绪增强注意(LSTM-SAT),将情感知识引入基于深度学习的长短时记忆网络的注意力机制中,但其在中文分词部分仍然用的是正向最大匹配算法,在分词效果上还有很大的提升空间。
总的来说,方言等地方特色语言的计算机领域相关工作研究较少,尤其是粤语,大多研究都是语言学家语义语法层面上的总结和论证。就目前针对粤语相关工作来看,还存在以下问题:一方面,针对粤语内容的研究较少,如粤语内容的话题检测与追踪等领域,未将中文研究成果应用于粤语文本处理当中。另一方面,直接利用的粤语语料还相对较少,大批量获取分词预处理好的粤语语料仍有难度,一定程度上影响实验效果。
2 字库建设
2.1 字库选取
一直以来,粤语字与其它方言字一样,缺乏相应的规范标准。对于粤语字是否需要规范这个问题,从民间到学界都曾有过不同的意见。但从学习、理解及应用的角度来说,粤语字的规范是很有必要的。粤语在日常使用的过程中问题主要表现为繁简体混用和繁简体不对应,前者可以通过繁简转换的方法来解决,但后者会出现有字无码的现象。多年来,国家出台了相关字符集,具体包括:《图文电视广播用汉字编码字符集·香港子集》(GB/T15564—1995)及香港特区政府公布的《香港增补字符集》(HKSCS-1999至2016)。其中,《香港增补字符集-2016》共收录5033个字符,增录了400多个粤语字,这对粤语字在电脑中的使用起到了十分重要的作用。侯兴泉与吴南开在《信息处理用字词规范研究》一书中收录了1000多个粤语字。所以选择一个包含粤语字更全的字符集可能会对文本存储和处理带来便利。
本文根据《香港增补字符集-2016》、《信息处理用字词规范研究》中收录的共10589个粤语常用字进行解码再转码操作,各字符集比较结果见表1。GB18030与UTF-8收录的粤语常用字差别不大,但UTF-8的编码格式在中文研究领域更为常用,其中经调研使用utf8 mb4字符编码对繁体较多的粤语有更好的支撑效果。因此,本文选取utf8 mb4字作为字库编码格式。
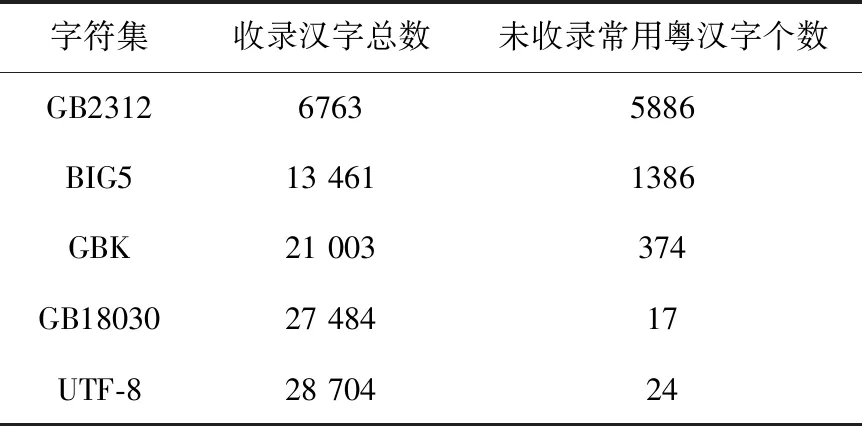
表1 字符集收录粤语常用字统计
2.2 数据采集
本文数据源主要包括粤语主流社交媒体的用户发言信息、粤语新闻网站的新闻报道、用户评论以及粤语书籍资料4大类。其中,主流社交媒体的用户发言信息选取的数据源包括Twitter、微博等社交媒体;新闻及新闻评论主要选取自的是《巴士的报》网站;粤语书籍主要是网络小说。本文选取这3类数据源时从3个方面保证了实验结果的普适性:第一选取的文本长度涵盖短、中、长3类文本;第二选取的类型包括口语化的日常网络用语、粤语书籍以及用语规范的新闻报道;第三选取的文本主题没有固定范围,涵盖日常生活、娱乐新闻等多个方面。
技术上采用Scrapy的爬虫框架进行数据采集,爬取的数据主要是粤语主流社交媒体的用户发言信息、粤语新闻新闻报道以及用户评论。主流社交媒体网站为了缓解自身服务器的负载压力往往会限制单个IP的访问频率以及在超过单个IP访问上限时进行封禁的反扒策略。因此在访问时需要制定相应爬虫策略,具体采集方法如下:
(1)统一不同数据源写入数据库格式,设置代理服务以及将爬虫部署外网服务器;
(2)按时间线顺序将待爬取粤语新闻及社交媒体用户发言的URL置入待爬取列表;
(3)逐个取出待爬取集合中的URL进行爬取;
(4)查看爬取结果。如果被限制访问,将URL置入待爬取集合,并更换代理,重新进行第(3)步。如果爬取成功,则写入数据库。
2.3 词库构建及特征选取
在缺乏高质量分词语料的情况下,使用词频、凝结度(互信息)与边界熵等基于统计方法作为初步的分词策略。其中,凝结度能描述字与字之间关联程度,也就是成词可能性,如式(1)、式(2)所示
Fi1(w1,2,…,i)=P(w1,2,…,i)P(w1)P(w2,…,i)
(1)
…
Fii-1(w1,2,…,i)=P(w1,2,…,i)P(w1,…,i-1)P(wi)
(2)
其中,F表示凝结度的值,w1,2,…,i代表选取子串的有序集合,P(w) 代表该子串在整体语料集中出现的概率。由此可得,式(1)、式(2)中的Fi描述的都是同一个子串内部不同凝结度的计算方式,当子串w1,2,…,i所有的切分方式出现频率的乘积远大于其整词w1,2,…,i的出现频率情况下,表明该子串w1,2,…,i的成词的可能性非常大。因此,充分考虑到互联网语言以及粤语的时效性,句子中不同长度的子串都有成词的可能。
根据图1可得随着词的长度增加,词本身出现次数会相应减少。现代汉语语料库多字词词频及概率如图1所示。
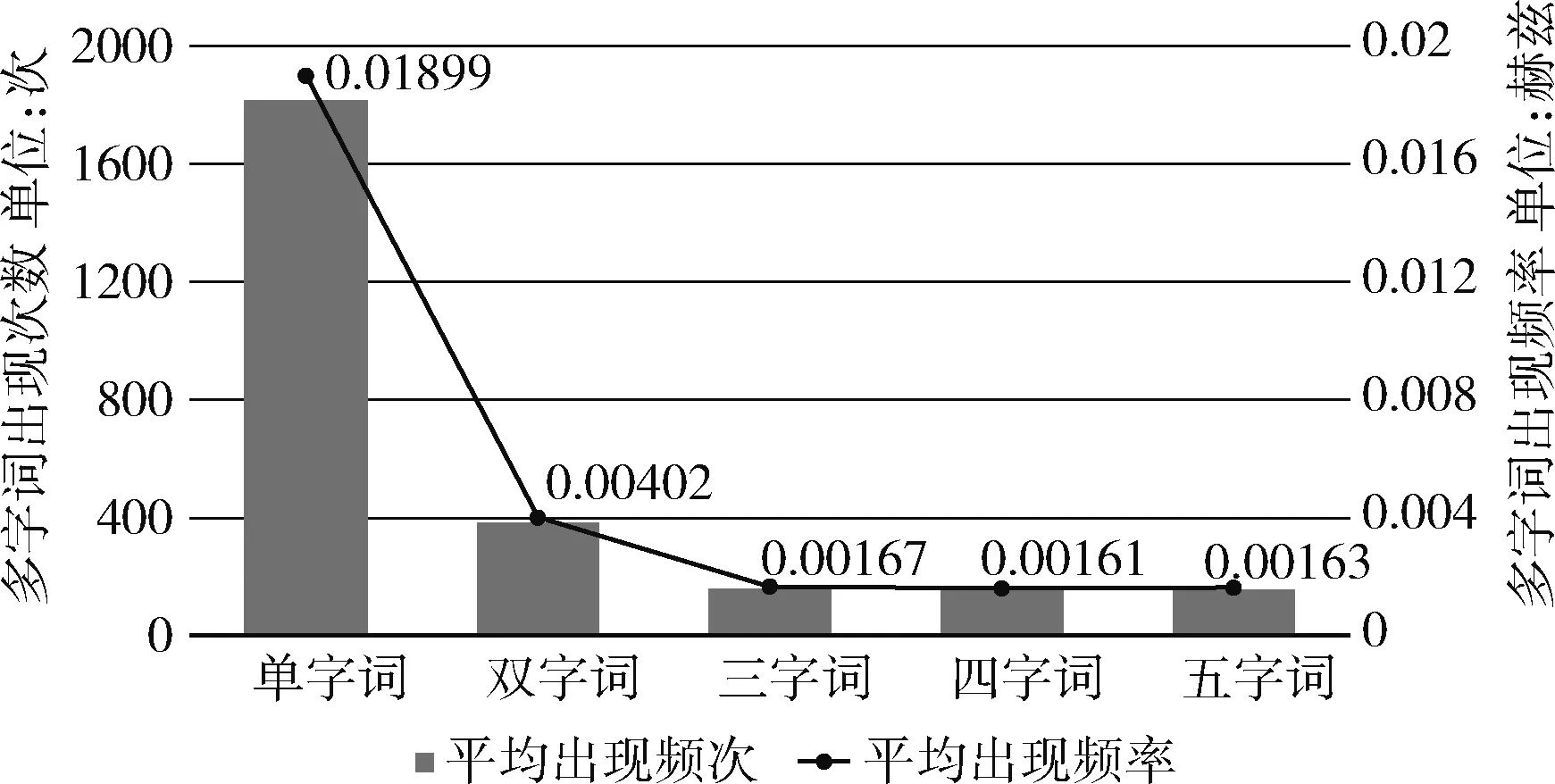
图1 现代汉语语料库多字词词频及概率
图2可得,一般4字以上的词(除专有名词以外)出现的概率较小。现代汉语语料库多字词词频占比统计如图2所示。
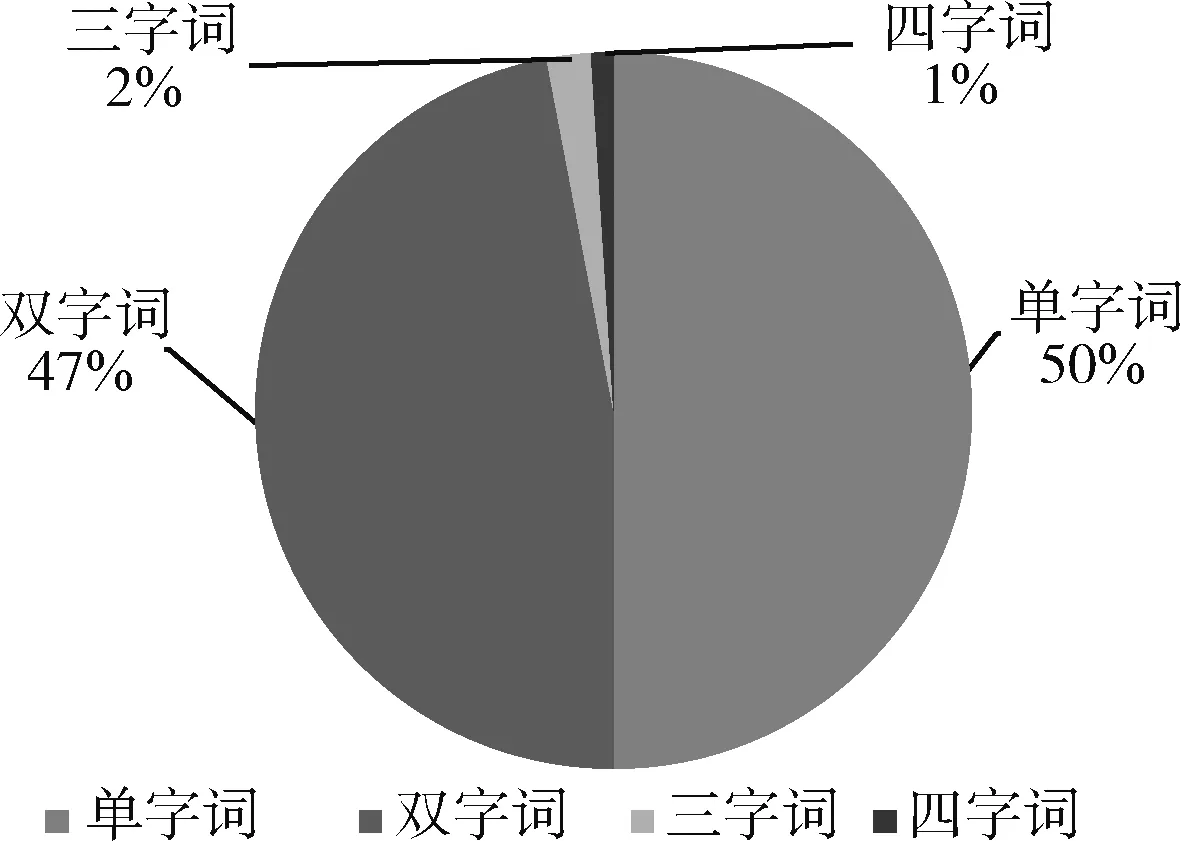
图2 现代汉语语料库多字词词频占比统计
同时,通过对汉语语料库中4字以上词的分析可得,按照更细粒度的分词标准这些词一般都能拆解成多个较短词。由于粤语是汉语方言的一种,在构建粤语词库时,选词的最大长度设置成4会更加合适。
设置阈值要考虑不同长度的多字词对阈值的影响,并且由图2、图3所示词频也能作为选词标准帮助筛选。不同参数下的成词率散点图如图3所示。

图3 不同参数下的成词率散点图
并且随着词本身长度的增加其凝结度集 {Fi} 内凝结度的计算方式也相应增多,凝结度集内部值的变化可能性增大。在理想情况下,凝结度集的值都普遍偏高时,说明该词的成词可能性越高或者其上位多字词成词的可能性就越高。相反,当凝结度集中出现过小值时,说明该词成词的可能性较小。这时需要用左右信息熵来进行筛选,主要目的就是形容左右邻字的丰富程度,如式(3)、式(4)所示
EL(W)=-∑P(XW|W)·log2P(XW|W)
(3)
ER(W)=-∑P(WY|W)·log2P(WY|W)
(4)
其中,EL与ER表示W字的左右信息熵,而P(XW|W) 表示左邻字X在W的所有的左邻字中的概率。当EL与ER特别高时,说明字W的左邻字X与右邻字Y非常丰富,以W开头的词存在上位词的概率低。根据实验结果,提取其中的多字词表见表2,可以发现提取的词既具备当下热词也具备方言词汇,如肺炎、曱甴等。

表2 词库示例
3 无监督分词方法研究
3.1 基于二元词频的初筛分词
通过大规模数据的文本处理构建二元字典以及多字词词库,将其分别应用在初筛分词和分词修正的实践上。其中,二元字典以七元组形式如式(5)所示
Di=(w1,w2,f1,2,F1,2,S1,2,e1,e2)
(5)
其中,w1与w2表示两字,f1,2表示两字出现频数,F1,2表示两字出现频率,S1,2表示两字之间的凝结度,e1与e2分别表示w1左信息熵与w2右信息熵。在2.3小节构建粤语词库时,本文应用式(1)中对凝结度集 {Fi} 整体都高于阈值的子串进行筛选。但如果两字之间的凝结度低于某阈值就说明两字之间的成词可能性较小,存在分词界限的可能性就高。利用此方法作为分词依据,将粤语语料根据二元字典进行处理,通过两字之间的凝结度Fi进行切分。
此方法在分词上已经初具效果,在图4中虽然没能将“佢/就”和“一個/筆盒”等词正确切分,但只根据二元字典进行计算省去了三元以及多元的考虑,节省了大量计算时间。并且“畀心機”的出现频次也相当的高,表明该方法具备能将任意长词给切分出来的能力。初筛分词结果如图4所示。

图4 初筛分词结果
3.2 基于多元词频的二次分词
对于初筛分词结果,已将待分词序列切分成有限个待分词子序列,只要将每个待分词子序列优化为最优分词结果,即可达到全局最优分词序列,即整句的最优分词序列。针对待分词子序列,本文应用基于词频的双向匹配分词算法进行优化。其分词过程主要分为双向分词和分词序列选择两部分,具体算法步骤如下:
算法1:基于词频的双向匹配分词算法
输入:由初筛分词得到有限个待分词子序列 {Sj}, 其中Sj=(w1,…,wk),wk表示子序列中第k个字。
输出:
(1)正向最大匹配的分词:对Sj利用粤语多字词库利用正向最大匹配算法进行匹配。以Sj为例,Iflen(Sj)>2: 选取以首字开始的二字词到四字词逐一对词库的进行匹配,选取匹配中的最长词记为f1, 如果没有匹配到将单字同样记为fm, 继续对后续字迭代该过程,得到Sj正向最大匹配的分词结果Fj=(f1,…,fm)。
(2)逆向最大匹配的分词:同正向最大匹配的分词,从最后面字符开始,得到Sj逆向最大匹配的分词结果Ej=(e1,…,em)。
(3)基于词频的评分:利用词库得到了Fj与Ej两种分词结果,利用词频对分词序列结果Fj与Ej进行评分,得到socre*j(Fj) 和socre*j(Ej)。 具体计算如公式(6)所示
socre*j(Fj)=∏mx=1-logP(fx)
(6)
(4)选择最优解:选择最小的socre*j作为Sj最优分词序列,对接下来Sj+1,…,Sj+k重复上述过程进行计算,得到全句最优序列 {S′j}。
(5)合并连续的单字词,输出序列 {S′j}。
图5的二次分词结果中虽然没能将“佢/就”和“一個/筆盒”等词正确切分,但只根据二元字典进行计算省去了三元以及多元的考虑,节省了大量计算时间。并且“畀心機”的出现频次也相当的高,表明该方法具备能将任意长词给切分出来的能力。二次分词结果如图5所示。

图5 二次分词结果
3.3 基于语法规则和语言特性的分词修正
经过基于词频的最大双向匹配算法得到了全句最优序列 {S′j}, 但 {S′j} 全是应用无监督的方法进行实现的,没有验证 {S′j} 在句法结构上的合理性。因此,利用有向无环图(DAG)分析句法结构,验证 {S′j} 在句法结构上的合理性,提高分词结果的准确性。本文2.3小节提到利用互信息来描述词内部连接的紧密程度,本节继续利用词级别的互信息来描述词与词之间的关联程度。
以句子为单位,分别计算分词序列 {S′j} 中任意两词的互信息,将超过阈值的两个词进行连接,形成能够描述分词序列 {S′j} 中各词相关程度的一个有向无环图。遍历每各句子中存在的路径,如果路径中非相邻的词通过边连接到下一个词且存在跳跃的词,就在两词之间插入 {S′j} 进行表示发生过跳跃,最终得到关于该句的各个插槽句型模板。对例句进行边的计算和连接,得到如图6所示的词互信息关联,再借由此生成图7所示的插槽句型模板。
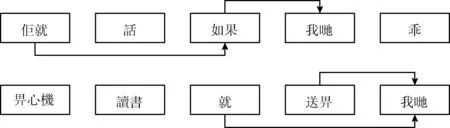
图6 词互信息关联
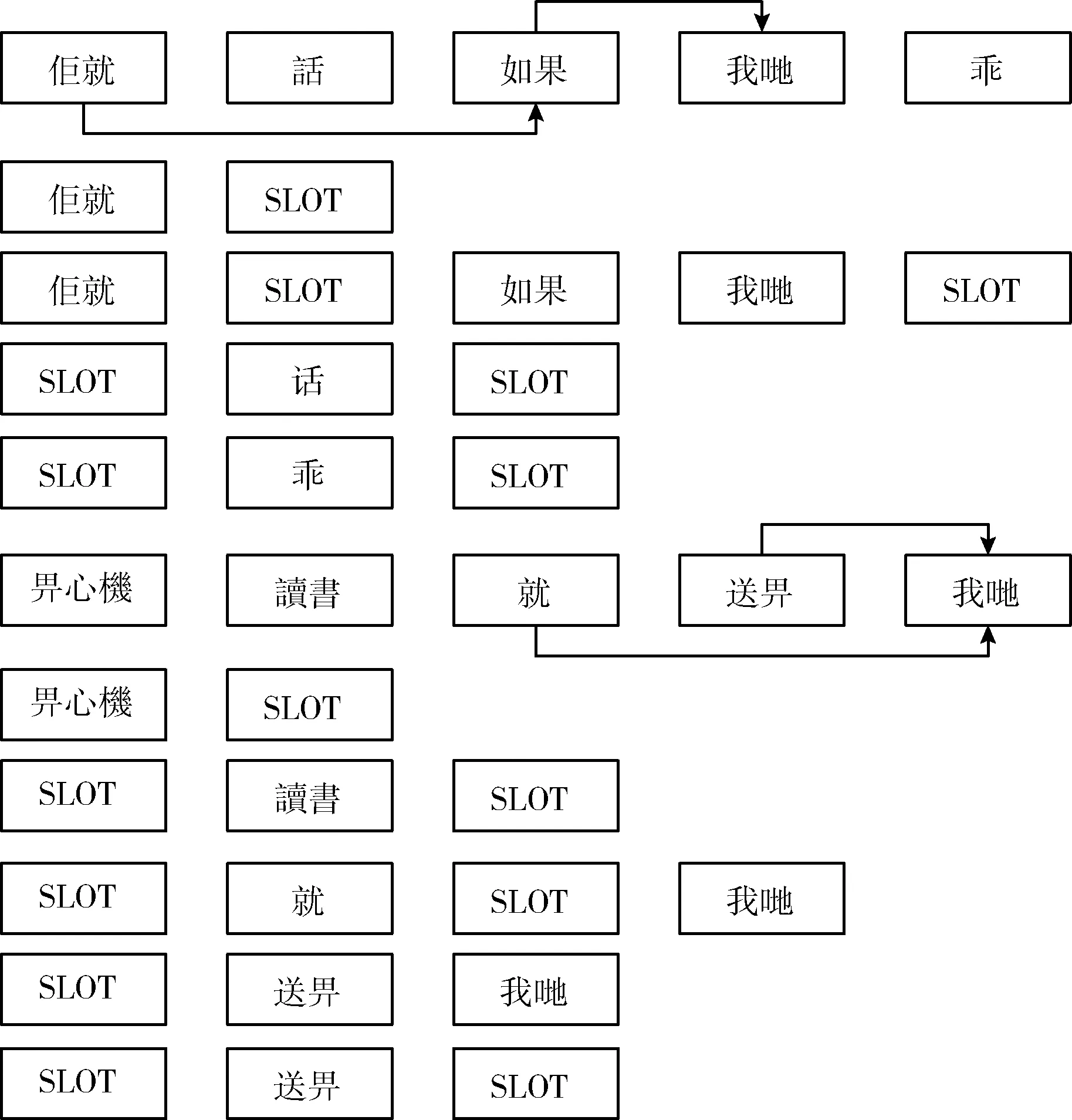
图7 插槽句型模板
统计所有语料中可能存在的插槽句型模板,并对记录相同插槽句型模板的出现频次进行排序,核对排名靠前插槽句型模板是否符合分词规范,将不符合分词规范的插槽句型模板进行修改。从图7可以看出,以包含“佢就”的句型模板为例,虽然该两字前两步没有被正确切分,但该两字的句型模板在整体语料中出现次数排名靠前,出现10万多次。针对该问题进行分词修正,将其分为“佢/就”,并应用修正到全部拥有此句型模板句子中。同理,本文对出现频次前10%的模板进行分析,对出现的分词错误进行修改,一定程度上提升了整体 {S′j} 的准确率。因此,针对出现高频的共性语句进行排序和分析,不仅更容易发现共性问题,也降低了人工校对的工作量,短时间内就能达到效果上的提升。
4 有监督的分词方法研究
上述的分词过程需要不断查找词库,存在处理时间长、过程繁琐的问题,可以利用深度学习模型对无监督的分词方法的效果进行固化,达到简化分词流程、减少分词时长的效果。因此,本文应用3层架构的深度学习模型框架来实现对分词序列的标注,Bert-BiLSTM-CRF模型如图8所示。

图8 Bert-BiLSTM-CRF三层模型架构
模型的输入以字为单位的整句,输出是每个字对应的预测标签。首先在Bert层,将输入的代分词粤语文本,将其通过Bert模型将字序列 {w1,…,wi} 映射为对应的特征向量 {v1,…,vi}。 然后,将映射后的序列字向量 {v1,…,vi} 作为BiLSTM层的输入,通过拼接BiLSTM层的前向运算和后向运算的结果向量,得到每个字向量的隐层向量表示,将隐层向量进行降维,输出维度大小为原文本字数的向量,向量中每个维度对应的数值表示每个字对应的各个标签的得分。最后,引入CRF层进行标签预测。如表3所示,在进行语料标注时,采用六位词的标注方法对数据集中的每个实体进行字级别的位置标注,相比于四词位和二词位标注集,六词位标注集更能有效地表现字在词语中的词位信息,表达能力更强。

表3 类词位标注集的定义
最后将CRF层的结果输出,将其每个字位置所对应的各个标签类别作为预测结果。
5 实验分析
5.1 数据集


表4 数据集规模介绍
5.2 分词实验结果分析
将章节3、章节4所涉及的实验采取SIGHAN bakeoff2005的评测标准对评测结果进行测试,该评测标准包括精确率P、召回率R、综合评分F值、未登录词召回率R-OOV、词表词召回率R-IV这5个指标。其中未登录词召回率与词表词召回率受粤语词库和分词步骤影响都比较高,不具有对比和参考意义,将其它3个指标得到的实验结果见表5。
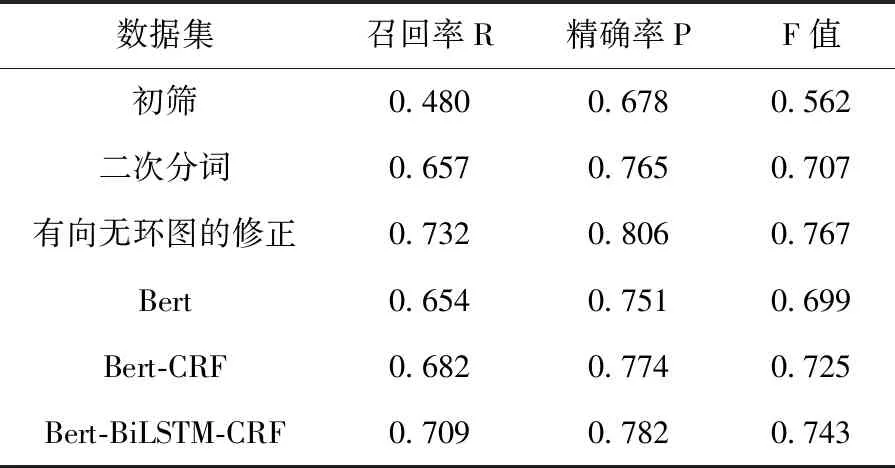
表5 实验结果
本文在3.1小节中,利用凝结度作为分词依据,将粤语语料中每个句子分成若干个序列,并以此作为初筛分词的结果,该结果的F值能达到0.562。F值能达到这个数值的原因不仅是在分词时反向利用凝结度,将紧密程度不够的两字之间添加分词界限,还因为用于分词的凝结度是根据语料本身的计算而得,更能适应语料本身。限制F值上升的原因是仍存在凝结度值不低于阈值但存在分词界限的地方未被找到的问题。阈值过低,影响原有的正确切分的数量,从而导致精确率增高与召回率降低;阈值过高,错误切分的数量增多,从而导致精确率降低和召回率升高。
为了解决这个问题,保证F值的同时,本文在3.2节引入2.3小节构建的粤语词库,对句子中每个序列进行基于词频的双向最大匹配算法进行分词优化。该步骤能利用粤语词库中已确定的词进行双向匹配择优选择结果,提高语料切分整体的F值14.5个百分点。该步骤切分的效果主要受限于粤语词库的质量。从语料本身提取的词库处理该语料时,理论上是不存在未登陆词的,但在建立词库时候词库筛选掉的词会作为未登录词影响匹配的效果。所以,在切分的时候也充分考虑到该种情况的影响,对最后的结果中的连续单字符进行合并。
经过基于词库的二次分词得到了新的分词语料,在F值上仍有提升的空间。经过对分词结果的观察,仍存在像“佢就”此类常用搭配,想要从优化词库质量改善效果需要投入大量人工总结修正的工作。但是想要对分词结果有个短时间内的提升,可以转换角度从语法结构入手,去改善粤语词库中没有常用单字词对分词结果的影响。于是利用词之间互信息,找到出现频率高共性大的句型,批量修改里面存在的分词错误。由于只分析修改了前10%句型,但还是获得了相比较于应用词库之后的结果6个百分点的提升。这部分工作虽然还有提升空间,但仍说明该处理预训练语料的方法在粤语文本上具有效果。
最后,将得到的预分词语料通过有监督的深度学习模型进行训练得到最终的分词模型。有监督的深度学习设置了3组对照实验,Bert预训练模型的基线模型、Bert-CRF模型以及Bert-BiLSTM-CRF融合模型。根据表5的实验结果可知,Bert-BiLSTM-CRF的分词效果明显优于其它两种模型,能够将F值稳定在0.743左右。比较Bert与Bert-CRF的实验结果,在拼接CRF模型后F值提高了0.026,这主要是因为CRF模型能够利用分词标签序列之间的关联性,像“B B1E…”的标签不能通过模型有效输出,进而提高分词的准确率。比较Bert-CRF与Bert-BiLSTM-CRF的实验结果,在Bert与CRF直接拼接BiLSTM模型后F值提高了0.018,引入的BiLSTM能够将Bert模型得到的句子每个字的向量表示进一步语义编码,抓住了更多上下文的信息,增强了句子的语义表达,进而提高了分词模型的分词效果。对于目前主流模型的比较也可以发现,分词效果仅是小程度的提成,即使普通的Bert模型也能达到近0.7的F值,也从侧面印证了该分词流程的有效性。
对于CANCORP的语料,其分词标准粒度较细,对分词的准确度稍有影响,单独在自建标注数据集CSBC上的效果有0.05的提升。单从快速构建分词模型来看已经达到了快速可用的标准,虽然效果比起中文成熟分词模型的准确率还有待提升,但此过程实现不管是对缺乏分词语料和开源分词模型的粤语来说,对其它语言从零构建分词模型具有借鉴意义的。
6 结束语
本文提出了一种面向粤语的通用分词方法,利用无监督与有监督结合的方式构建了一套工程化、流程化的粤语分词模型,解决了在缺乏预处理粤语分词语料的情况下如何训练分词模型的问题。
本文所设计的实验还存在诸多不足和待优化之处,从粤语方言本身来说,实际的分词效果受语料影响较大。另外,从分词效率来说,还有很多待优化地方,比如可将二元字典转化为Tire树,会提高检索效率。这些都是下一步工作中需要研究与改进的地方。
