基于类名引导的弱监督文本分类
2023-09-13周悦尧奚雪峰崔志明盛胜利仇亚进
周悦尧,奚雪峰,3+,崔志明,盛胜利,仇亚进
(1.苏州科技大学 电子与信息工程学院,江苏 苏州 215000;2.苏州市科技局 苏州市虚拟现实智能交互及应用重点实验室,江苏 苏州 215000;3.苏州科技大学 苏州智慧城市研究院,江苏 苏州 215000;4.德州理工大学 计算机学院,得克萨斯州 拉伯克市 79401)
0 引 言
文本分类是自然语言处理中的核心基础,广泛应用于情感分析[1]、意图识别[2]等典型任务。近年来,循环神经网络[3](recurrent neural network,RNN)、卷积神经网络[4](convolutional neural network,CNN)、层次注意力网络[5](hierarchical attention network,HAN)以及BERT[6]预训练模型都在文本分类任务上取得了十分优异的成绩,受到学界及工业界的重点关注。要训练一个性能良好的有监督分类模型,至少需要消耗数十万的高质量标注文档。然而这样的标注文档常常需要大量标注人员和文档专家的协同配合标注,时间和人力成本巨大。由此造成高质量标注数据的缺乏,是有监督分类模型难以大规模落地的重要原因。
为解决上述问题,研究者提出了弱监督文本分类方法。当用户无法提供大量标注文档时,也可以通过为分类模型提供少量种子词的方式训练模型达到应用要求。例如类别名称为Sports,用户给这个类别提供高度相关的种子词可以是basketball、football、athletes,从而模型基于这些种子词对属于Sports的文档进行分类。然而这种方法的局限性在于,相关种子词需要依赖对语料库非常熟悉的专家才能准确提供。
受此启发,为进一步解决标注数据稀缺问题,本文提出一种基于类名引导的弱监督文本分类(weakly supervised text classification based on class name guidance,CNG)方法。该方法使用类名作为监督源,无需标注数据,可以根据用户提供的类别名称生成种子词,为文档生成伪标签并训练文档分类器。同时,根据排名分数对种子词集进行扩展,模型使用迭代的方法不断改进性能。本文工作的主要贡献有:①设计了一种基于类名生成高质量种子词的方法;②提出了一种迭代的弱监督文本分类框架;③在公开数据集NYT和20 Newsgroups上取得了出色的成绩。
1 相关工作
1.1 词向量模型
无论是英文还是中文,词语都是自然语言处理中最基本的单元。词向量技术可以将文本表示为表达文本语义的向量。典型的词向量技术有Word2Vec[7]、GloVe[8]、ELMo[9]、BERT等。Word2Vec借助词的上下文得到词的向量表示,但是它只考虑词的局部信息;GloVe利用共现矩阵并考虑词的整体信息来得到词的向量表示,但是无法适用于词的不同语境;ELMo能够学习到单词在不同语境中的变化,但是它使用的语言模型是LSTM(long short-term menory),无法做双向推理,且并行计算能力较差。在ELMo的基础上,BERT具有更强的双向推理和并行计算能力,但是它得到的单词向量表示存在各向异性,即词向量会不均匀分布,导致词向量之间的距离不能很好地表示语义相似性。
1.2 文档分类器
文本分类是自然语言处理中一个长期研究的问题。主流的深度神经网络文本分类TextRNN[3]模型通过对文本的逐字分析,将语义存储于隐藏层中,可以很好地捕捉文本的上下文语义,但是模型存在偏差,后面的词会比前面的更占优。TextCNN[4]模型通过一维卷积来提取句子的特征表示,具备强大的浅层文本抽取能力,但是受限于固定filter,针对长文本效果不佳。CRNN[10]模型丢弃了传统 CNN中使用的池化层并用LSTM进行替代,以捕捉文本间的长距离依赖关系。文本分类的层次注意力网络模型[5],首先将注意力机制[11](Attention Mechanism)应用到文档中的句子,然后拓展应用到句子中的单词,从而找到文档中最重要的句子和单词。
1.3 弱监督文本分类方法
弱监督文本分类方法的提出,是为解决标注数据稀缺的问题。弱监督文本分类方法的监督源是各种形式的种子信息,其中Cai等[12],Miyato等[13]和Xu等[14]的方法使用一些已标注的训练文档;Wang等[15],Meng等[16],Chu等[17]和Tao等[18]的方法使用类别名称;Meng等[19]和Dheeraj等[20]的方法使用专家提供的种子词。Cai等提出的PTE将标注文档作为种子信息,使用标注和未标注的数据学习文本向量,利用逻辑回归模型进行分类;Chu等提出的Dataless将类名作为种子信息,通过将标签和文档嵌入语义空间,计算文档和潜在标签之间的语义相似度,对文档进行分类;Tao等提出的Doc2Cube将类名作为种子信息,并通过学习维度感知嵌入来执行多维文档分类;Dheeraj等提出的ConWea将种子词作为种子信息,利用语境化表示技术进行语境化文本分类。
2 基于类名引导的弱监督文本分类
本文提出一种弱监督文本分类方法CNG http://github.com/orabB/CNG,从类名出发并结合种子词,使用无监督词向量模型Word2Vec学习向量表示,对类名和语料库之间的关系进行建模;通过语义相关性和语义特异性来设计排名分数并生成种子词,采用迭代方式为未标注文档生成伪标签,训练文本分类器HAN,并结合训练结果扩展种子词。CNG方法能够基于语义相似性和语义特异性生成高质量的种子词,进一步解决标注数据稀缺问题;同时,迭代的训练框架能够提升模型的泛化能力。
如图1所示,本文所提CNG方法一共分为种子词生成,生成伪标签和文档分类器以及种子词扩展3个主要模块。
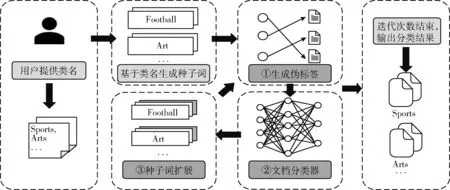
图1 方法架构
2.1 种子词生成
本节详细描述候选词集的生成,以及通过排名机制挑选出高质量的种子词。关于如何界定高质量的种子词,本方法联合考虑单词的语义相关性和语义特异性。种子词w对于类的标签名l来说,首先要满足w和l语义相关,其次w较l而言更加具体且排他。例如football和ball,football属于ball一类,但是football更具体,football是一种具体的ball,它也只能属于ball一类。下面分析如何对单词和文档进行建模,以及如何设计种子词排名机制。
2.1.1 候选词集的生成
本文提供的监督源是类名,在弱监督文本分类任务中极具挑战。CNG使用Skip-Gram[21]模型学习语料库中所有单词的m维向量表示。同时为了能够更加高效地捕捉其中的语义关联,CNG将所有的m维向量都进行单位化操作,并通过vMF分布[22]建模语料库中单词m维向量和标签l的关联。分布表达式如下
f(xw,ul,kl)=exp(kluTlxw)km/2-1l(2π)m/2Im/2-1(kl)
(1)
其中,xw是语料库中单词的m维向量,Im/2-1(kl) 是m/2-1阶的第一类修正贝塞尔函数。vMF分布有平均方向和集中参数两个参数,在这里标签名向量ul被作为平均方向,其它单词在标签名附近的集中程度kl被作为集中参数。所有单位向量都会分布在单位超球体上,与标签名语义相关的单词都会聚集在标签名周围,如图2所示。
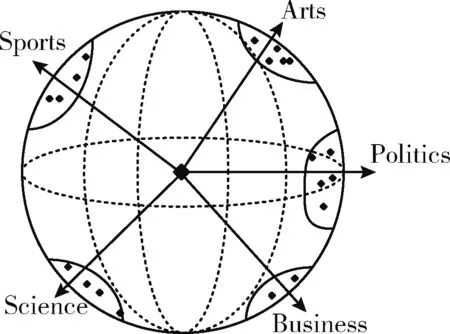
图2 vMF分布
通过向量余弦相似度获取一组与标签名l高度语义相关的单词Wk。计算公式如下
Wk=argmaxWksim(w,l)
(2)
sim(w,l)=cos(w,l)=w·l|w|·|l|
(3)
其中,单词Wk的获取并不是无止尽的,界定值ts被用来作为不同类别之间不能共享单词的最大数字,单词Wk的数量不能超过这个数值。
Word2Vec中有CBOW和Skip-Gram两种模型,CBOW模型的主要工作是根据给定的上下文去预测输入的单词,其核心功能与本节工作相悖,故不采用。CNG采用的Skip-Gram模型的主要工作是根据输入给定的中心词,首先通过隐藏层权重矩阵的计算,最后通过softmax输出预测的上下文,Skip-Gram的模型结构如图3所示。
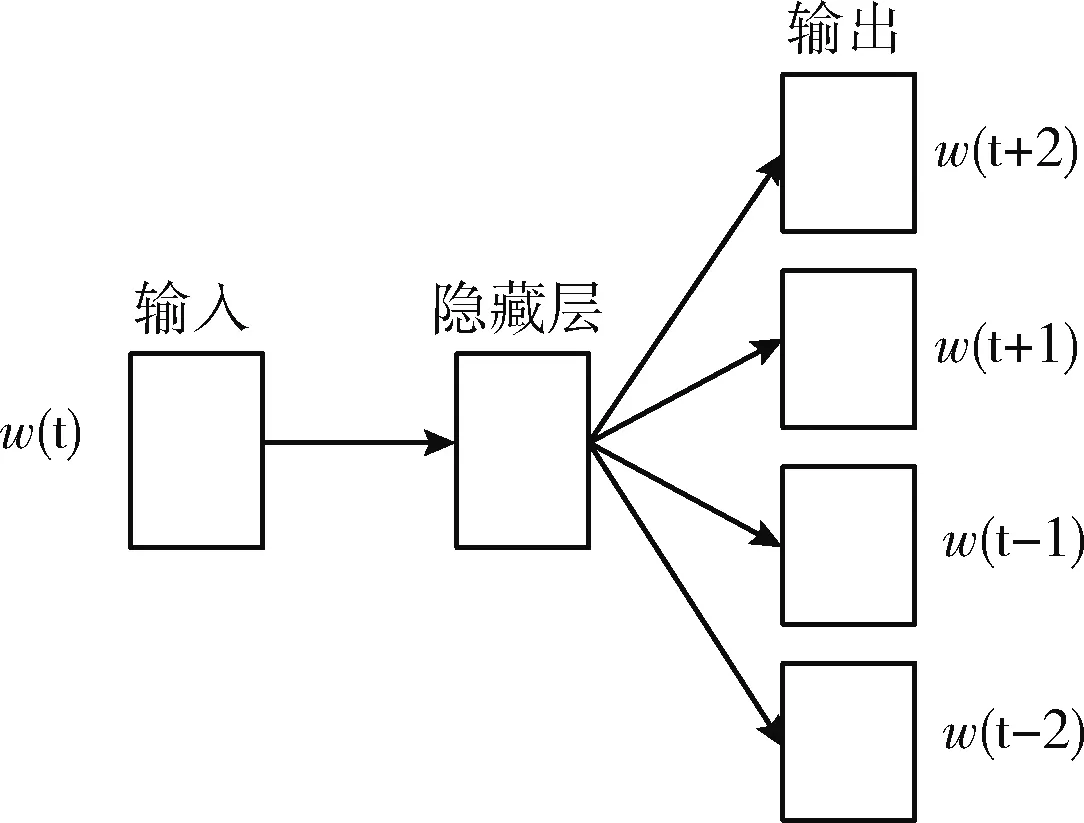
图3 Skip-Gram模型结构
2.1.2 种子词的挑选
至此生成的候选词集已经满足语义相关性的要求,但要生成高质量的种子词还需联合考虑语义特异性。词集样例见表1。
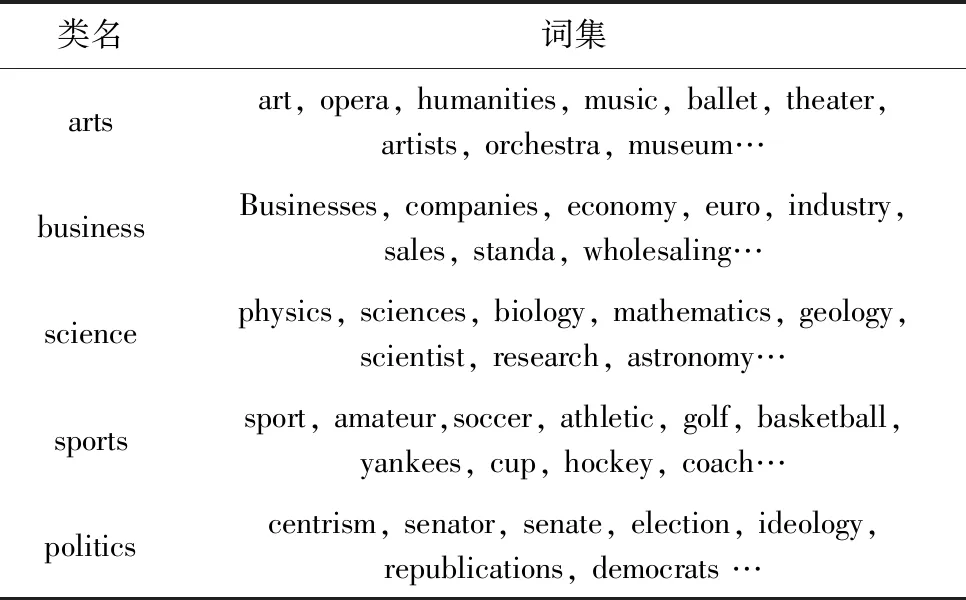
表1 词集样例
如果单词v的含义包含了另一个单词w含义,那么单词v的所有上下文特征也会在单词w中出现。使用标量SCw,l将单词w与标签名l关联,SCw,l越大时,表明单词w的语义较标签名l而言更具体且排他。标量SCw,l计算公式如下
SCw,l=∑f∈F(w)∩F(l)RFF(w,f)+RFF(l,f)∑f∈F(w)RFF(w,f)+∑f∈F(l)RFF(l,f)
(4)
其中,F(w),F(l) 是活动特征,RFF是着眼于最突出特征的权重函数。为方便下一步计算,CNG将单词的SCw,l值进行归一化操作,以此得到语义特异性分数,计算公式如下
SSw,l=SCw,l∑SCwi,l
(5)
其中,SSw,l是词集中的单词的语义特异性分数,取值范围为[0,1]。
利用学习到的语义相关性和语义特异性来进行综合考虑,特定类的理想种子词应该与该类语义高度相关并且排他。因此,高质量的种子词被确定为与标签l具有较高的语义相关性和语义特异性的词,最终种子词排名分数计算如下
Rw,l=sim(w,l)×SSw,l
(6)
2.2 生成伪标签和文档分类器
首先为部分未标注文档生成伪标签以此来预训练文档分类器,之后在未标记的文档上精炼文档分类器。
2.2.1 生成伪标签
对于给定的文档Di,它属于标签名l的概率和它的种子词的排名分数成正比。计算公式如下
P(l|Di)∝∑w∈Di∩SwlfDi,w×Rw,l
(7)
其中,fDi,w是单词w在文档Di中的词条频率,Swl是词集,Rw,l是种子词的排名分数。在首次迭代中,CNG使用第一次的生成排名分数,而在接下来的迭代中则使用扩展分数。因此,对于文档Di的伪标签分配将按照如下公式
l(Di)=argmaxlP(l|Di)
(8)
2.2.2 文档分类器
CNG方法的重点在于对弱监督种子信息的处理和应用,使用层次注意力网络模型(HAN)作为文档分类器。整个网络可以被看作两部分,词注意力部分以及句子注意力部分。HAN可以先关注文档中的句子,找到文档中的重要句子;然后关注句子中的单词,识别句子中的重要单词;接着使用生成的伪标签在未标记的文档数据上训练一个HAN模型。对于文档Di,它估计的每个标签名l的预测概率将被用于后续种子词的扩展。分类器模型如图4所示。
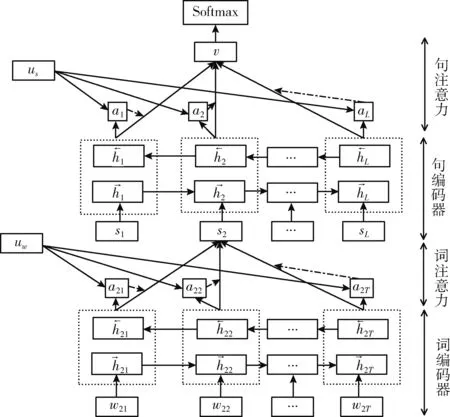
图4 文档分类器模型
2.3 种子词扩展
传统的种子驱动方法都遵循迭代框架,它们使用启发式方法生成伪标签,学习文档和类之间的映射,并扩展种子集。CNG结合文档及其预测的标签名概率,从每个标签名候选词的排名分数出发,使用排名前几位的候选词来扩展种子词。扩展的种子词也应当具有高度的语义相关性,同时不会属于多个标签的种子词集。除此以外,扩展的种子词在预测的文档中应该有较高的出现频率。
2.3.1 出现频率
要想成为标签名l的扩展种子词,它必须在标签名l的文档中大量出现。这里需要计算单词w在所有标签l的文档中出现的平均频率,平均频率的衡量标准如下
AF(l,w)=fl,wNuml
(9)
其中,Numl是被预测为标签名l的文档总数,fl,w是单词w在被预测为标签名l的文档中的出现频率。
2.3.2 扩展分数
将出现频率与上文的排名分数相结合,得到单词w关于标签名l的排名分数。基于这个排名分数,就可以为标签名l扩展新的高质量的种子词。扩展分数如下
R(l,w)=Rw,l×AF(l,w)
(10)
其中,Rw,l,AF(l,w) 分别是上文提到的排名分数和平均频率。
种子词扩展具有适应性,每个标签有不同数量的扩展种子词。在第一次迭代中,只使用词集里排名前几位的单词作为种子词,其它单词则将作为下一步迭代的候选扩展种子词。
在扩展各个标签的种子词之后,生成伪标签并训练分类器。这个过程在T次迭代中反复进行。
3 实 验
在两个公开数据集NYT数据集和20 Newsgroups数据集上,对提出的方法CNG与现有的方法进行对比评估,数据集都进行弱监督分类设置。
3.1 环境设置
实验使用的环境与配置见表2。

表2 实验环境与配置
3.2 数据集

3.2.1 NYT数据集
NYT数据集抓取了纽约时报从2009年11月到2010年1月的所有商业文章,其文本分类数据集分为5个类,共计13 081个文档,平均长度778,具体如图5(a)所示。
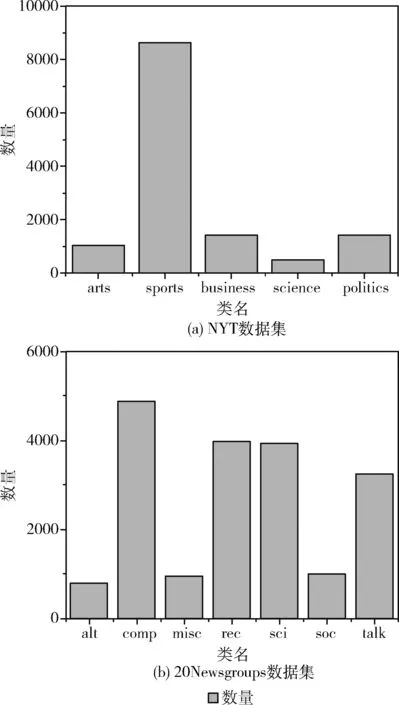
图5 数据集数量分布
3.2.2 20Newsgroups数据集
20Newsgroups数据集是用于文本分类、文本挖据和信息检索研究的国际标准数据集之一,其文本分类数据集分为7个大类,共计18 828个文档,平均长度303,具体如图5(b)所示。
3.3 评价指标
考虑到两个数据集不平衡的标签分布,采用F1-score作为评估指标(micro-F1和macro-F1),它是统计学中用来衡量分类模型精确度的一种指标,用于测量不均衡数据的精度,可以同时兼顾分类模型的精确率和召回率。在实验中使用sklearn.metrics包的f1_score()方法进行统计。
3.4 实验设置
所有的对比方法都严格按照原始论文中描述的参数来进行复现。对于CNG,鉴于它是迭代的训练过程,参数仅仅是迭代次数T,因此将迭代次数T设置为8。
3.5 迭代次数
图6是迭代次数和方法效果的关系图,其中图6(a)是NYT数据集的结果,图6(b)是20Newsgroups数据集的结果。
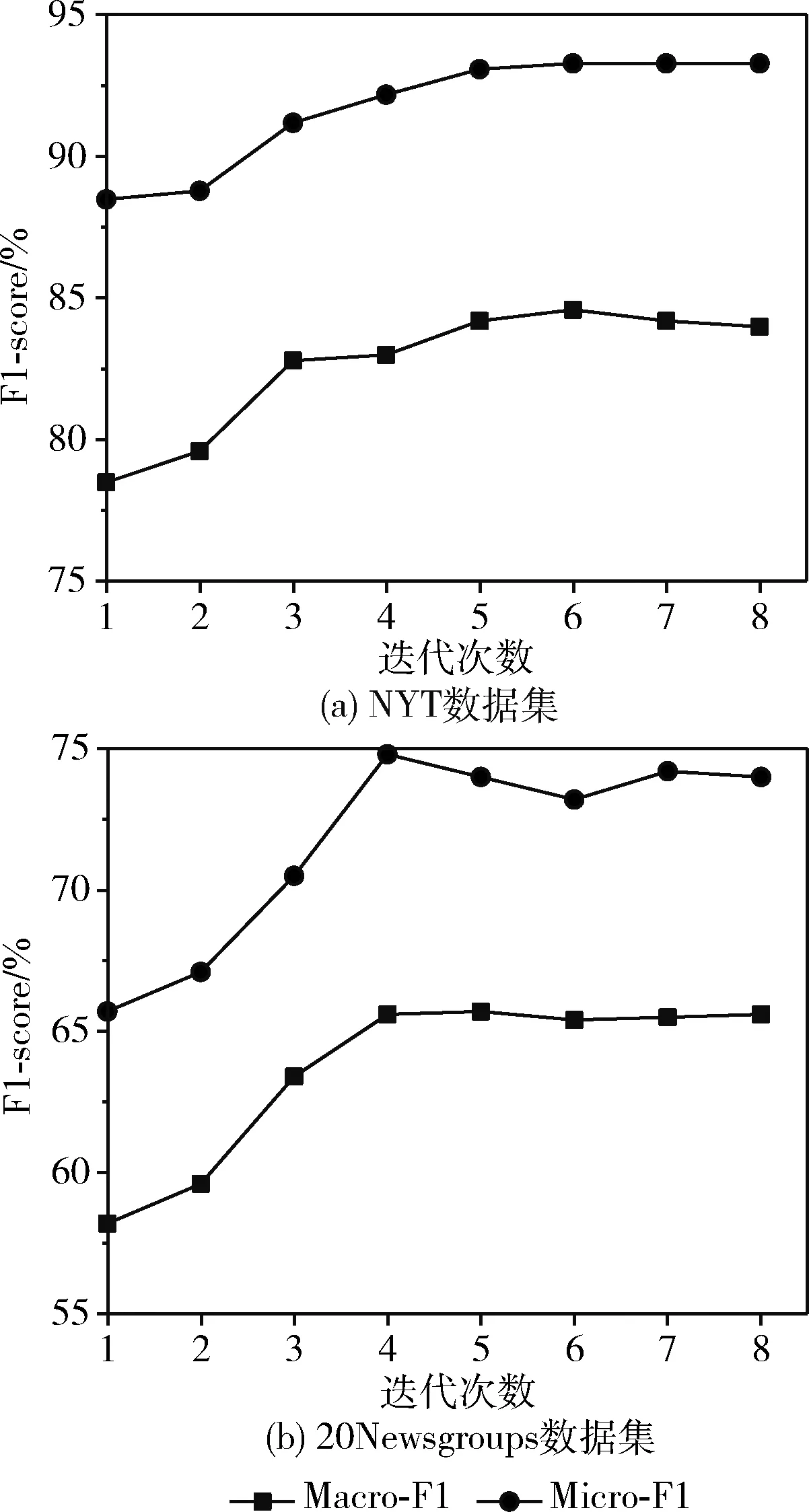
图6 迭代次数和方法效果关系
在本文的方法中,迭代次数T是唯一的超参数。从图中可以观察到,虽然第一次迭代的训练表现处于较低的水平(第一次迭代是未使用扩展种子词的训练),但是在接下来的迭代中训练表现攀升,实验结果验证了种子词扩展的有效性。从全局来看,在第五次迭代左右,F1-score逐渐平缓,表明在5次迭代后,扩展的种子词无法对模型产生进一步的影响,模型效果收敛。
3.6 词向量模型对比
本文使用的Word2Vec与以下两种词向量模型进行比较:采用BERT与GloVe代替Word2Vec作为CNG方法的词向量模型。
Word2Vec:本文使用的是其中的Skip-Gram模型,通过最大化使用中心词预测其上下文单词的概率。
GloVe:通过分解全局单词共现矩阵来学习单词向量,其中共现定义在固定大小的上下文窗口上。
BERT:BERT是一种先进的预训练语言模型,提供上下文化的单词向量。它可以预测随机隐藏的单词和连续的句子关系。
图7是在两个数据集上的实验对比图,其中图7(a)为NYT数据集的结果,图7(b)为20Newsgroups数据集的结果。

图7 词向量实验对比
如图7所示,Word2Vec表现最佳,GloVe表现稍次之。无监督词向量模型在标注数据稀缺的情况下表现出色。尽管BERT在有监督任务中性能出色,但在弱监督条件下,它的表现明显较差。原因在于BERT向量存在各向异性,向量不均匀地分布,这使语义相似度的计算存在偏差,从而导致性能不佳。
3.7 文档分类器对比
本文使用HAN分类器与CNN分类器进行比较:采用CNN代替HAN作为CNG方法的文档分类器。
HAN:基于词汇层级和句子层级来考虑文本的特征,同时采用注意力机制将选择模型分类的重点。
CNN:通过一维卷积来提取句子的特征表示。
图8是在两个数据集上的实验对比图,其中图8(a)为NYT数据集的结果,图8(b)为20Newsgroups数据集的结果。

图8 分类器实验对比
实验验证了CNG方法的通用性,可以兼容不同的文档分类器。从图中可以得知,HAN模型在两个数据集上的表现更佳,CNN模型在20Newsgroups数据集上的差距较小。而20Newsgroups数据集的长度稍短,没有放大CNN在长距离依赖关系的不足。
3.8 对比方法
本节将提出的CNG方法与近年来最先进的弱监督方法进行对比。
LOTClass[16]:该方法提出一种基于预训练语言模型BERT的弱监督文本分类模型,把类别名称作为监督源,查找类别指示词并训练模型预测其隐含类别,最后经过自训练达到分类目的。
Dataless:该方法仅仅使用类别名称作为监督源,它利用维基百科并使用显式语义分析来派生标签和文档的向量表示。最后每个文档都基于文档-标签的相似性进行标记。
Doc2Cube:该方法也使用类别名称作为监督源,迭代地执行标签、术语和文档的联合嵌入,通过学习感知维度的嵌入,从而进行多维文档的分类。
WeSTClass[19]:该方法可以使用多种种子信息作为监督源,它利用种子信息生成伪文档,先通过神经网络模型进行预训练,然后在未标注文档上对模型进行精炼,从而达到分类目的。
PV-DM[23]:该方法首先学习语料库中所有的句向量表示(句向量继承了Word2Vec词向量的特点,而且更具优势),并通过聚合句向量,得出标签表示。最后每个文档都会被分配与该文档最相关的标签。
WeSHClass[24]:该方法提出一种反映类别分类的分层神经网络模型,把种子词作为监督源,通过局部分类器预训练和全局分类器自训练来完成分类。
CNG-NoGen:该方法是CNG方法的消融版本,采用基于距离度量的种子词生成方式代替联合考虑语义特异性和语义相关性生成种子词的方式,其它模块不变。
3.9 结果分析
由表3的实验结果表明,提出的方法CNG在所有对比的弱监督方法中取得了更高的F1值。在NYT数据集上的Macro-F1值为84.2%,Micro-F1值为93.3%,在20Newsgrops数据集上的Macro-F1值为65.7%,Micro-F1值为74.0%。所有弱监督分类方法在两个数据集上的Micro-F1都明显大于Macro-F1,表明在两个数据集中,它们在小样本量的类别上分类效果更差。以CNG方法为例,在分配伪标签以及预训练之后,没有足够的数据让分类模型泛化,从而无法取得更好的效果。

表3 实验结果/%
(1)从表中可以得知,Dataless、Doc2Cube等未使用深度神经网络模型的传统方法分类效果不佳。它们缺少深度神经网络模型的多层计算能力,对分类文本中的特征信息、上下文语义环境等重要因素考虑不足,实验结果表明深度神经网络模型在弱监督文本分类任务上的有效性。然而PV-DM与使用深度神经网络的WESTClass等方法相比,其实验结果在部分指标上更具优势。在标注数据不足的弱监督环境下,句向量对于文本的语义表示有积极的作用。
(2)与仅以类别名称作为监督源的方法相比,实验验证了从类名出发,结合生成的高质量种子词方法的有效性。以单一种子信息作为监督源的方法在性能上已经接近瓶颈。CNG在NYT数据集上的表现最佳,Macro-F1值为84.2%,Micro-F1值为93.3%;但是在20news数据集上的Macro-F1值仅次于LOTClass方法,差距为6.8%。
(3)与把种子词作为监督源的方法相比,实验结果表明了CNG中高质量种子词生成及扩展方法的有效性。在迭代训练过程中,CNG学习上次迭代过程中成功预测的经验,以此来修正分类器并扩展种子词,从而不断地对方法进行精炼,最终达到更佳效果。
(4)WESHClass提出的分层标签分类结构,针对种子信息进一步细分,将种子信息组织成分层结构,对种子信息处理方面提供了非常好的思路。但是因为该结构采用的LSTM在隐藏状态会丢失一些重要特征,它使用LSTM生成的伪文档会对分类结果造成负面影响,所以在数据集上表现不是特别好。
(5)CNG-NoGen与CNG相比,性能存在差距。在弱监督文本分类任务中,方法能否对种子信息进行最大程度的利用是决定性能的关键点之一。距离度量的方式能够捕捉与类名语义相关的单词,但是单纯的语义相关无法处理部分单词一词多义的现象。例如,space的单词释义有空间、空格和太空等,这使得模型的输入存在误差,从而影响分类效果。而联合考虑语义相关性和语义特异性的方式不仅要求单词与标签名高度的语义相关性,还要求语义高度排他(单词没有歧义)。
(6)可以从表中观察到,弱监督文本分类方法在20 Newsgroups数据集上的表现不佳。原因在于NYT数据集上文档平均长度是20 Newsgroups数据集上文档平均长度的2倍多;由于20 Newsgroups数据集中多为较短的新闻语料,文本内部的依赖关系不突出,CNG方法无法凸显HAN分类器在长文本语料中处理复杂语料的能力,因此无法取得良好的表现。然而使用预训练语言模型BERT的LOTClass方法在Macro-F1和Micro-F1上取得了大于70%的成绩,它在文本平均长度303的20Newsgroups数据集上凭借BERT的多层Transformer更好地提取特征,从而取得更出色的分类效果。
4 结束语
本文提出一种基于类名引导的弱监督文本分类方法CNG,其核心策略在于从类名出发并结合种子词生成。CNG方法首先学习语料库中单词的向量表示,利用类别名称生成种子词,然后生成伪标签,迭代地使用文档分类器和种子词扩展来进行文本分类。在两个公开数据集上的实验结果表明了CNG方法的有效性,有望缓解标注数据稀缺的问题。在未来的研究中,计划探索更为有效的监督信息,同时也考虑如何融合不同来源的监督信息,以此来提高方法的性能,进一步降低标注数据缺乏所带来的影响。
