基于Python的中医药数据挖掘中标准数据集的加工-以高血压治疗数据为例
2023-09-08田颖郭栋彭伟范晓艳张晨岳朱俊潼
田颖,郭栋,彭伟,范晓艳,张晨岳,朱俊潼
中医药独特的理论体系使得其现代化研究面临着巨大的困难。中医药循证需要的不仅是随机对照试验(RCT),而是多样性的证据。基于日常医疗数据挖掘的医疗信息数据已经成为当今时代中医学研究的主要证据源头。中医药数据挖掘和其它商业类数据挖掘相似,整个过程需要计算机科学、统计学、中医学等多个学科的交叉融合。受到计算机语言以及数据分析能力欠缺的限制,面对海量的数据,有80%的时间和精力是花费在数据预处理和预加工阶段。目前虽有不少研究采用数据挖掘(DM)技术,借助中医传承辅助平台/利用相关软件进行关联规则分析、聚类分析、主成分分析和因子分析等得到了有意义的结果[1-11],但总体大规模的病例数据挖掘较少,研究方法较为单一,创新性不足。如何快速高效的实现数据的预处理,降低中医药DM的门槛,是广大中医人普遍面临的问题。
Python作为计算机编程语言,提供了高效的高级数据结构,还能简单有效地面向对象编程[12]。Python相对易学易读,且免费开源、用途广泛,目前已成为非计算机专业人员最受欢迎的程序设计语言之一。笔者以本院高血压病例的医疗信息系统数据层面的数据挖掘流程为例,重点展示如何利用Python高效快速的实现中医药数据挖掘中的标准数据集的加工。目前笔者尚未看到国内外该方面详细的操作流程的文献报道。
1 数据来源
利用日常诊疗数据来开展临床研究,需从两个维度考虑:数据获得和研究方法。
1.1 数据库的链接整合我院信息系统(HIS)、实验室信息管理系统(LIS)、医学影像存档于通讯系统(PACS)和电子病历系统(EMR)数据汇总,构建形成完整的医院医疗信息数据仓库。
1.2 数据来源选择我院最近1年的高血压住院和门诊患者就医的相关信息。包括患者基本信息、住院和门诊电子病历系统、用药信息和辅助检查信息。
1.3 确定研究目标和挖掘对象在选择数据前,需明确DM目标。目的不同,所要构建的模型也不同。本研究以原发性高血压作为第一主诊断的住院和门诊患者为挖掘对象,分析高血压患者的临床流行病学特征、主要证型归类、中药处方和西药处方的用药规律及建立相关风险的预测模型。
1.4 数据挖掘的技术和工具数据挖掘有多种方法和工具,本文重点介绍重点应用Python语言实现数据集的预处理。
1.5 技术路线对于数据挖掘的完整流程要有个明确的思路,以下技术路线供参考,本文主要探讨的内容是“数据预处理”阶段(图1)。
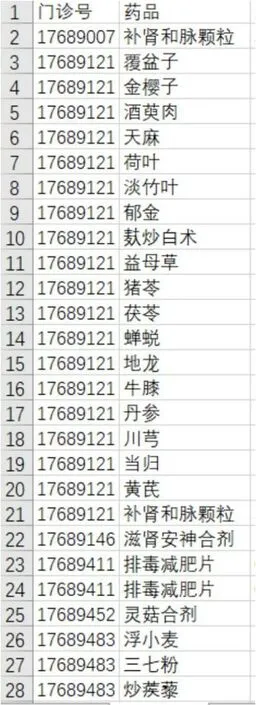
图1 以行分布的中药使用信息

图1 数据挖掘技术路线图
2 数据预提取及正式提取
数据正式提取前,需要明确筛选的重要的数据项目,以满足后期数据挖掘的需要。Excel表格对行和列的存储是有限度的,一个人的记录可能就有上百行上百列的信息。可以先采用预提取的方式,少量提取几十人的信息,查看预提取出的表格信息并进行设计整理,在保证研究目标的需要的前提下尽量简化数据条目,进一步明确要提取的病历字段。这期间需要与负责数据库系统的工程师反复沟通讨论数据提取的形式,特别是中药处方的信息,每个人的用药有几种到十几种不等,具体可以按照行/列的形式抽取,以哪种形式抽取要看个人对后期对数据预处理的便利。预抽取数据明确后即可以正式提取。
3 中药大数据的规范处理
数据提取的载体一般是Excel,刚抽取出来的数据是比较杂乱无章的(图2),需针对数据的各种问题进行规范化的预处理。需要根据中医药大数据的特点,利用中医药专业知识门诊和住院病历的文本进行结构化信息提取;规范中药名称;规范高血压的诊断证型;对四诊和主诉相关术语进行规范和拆分等,直到对数据质量满意为止。这是对中医药大数据预处理的重要工作。
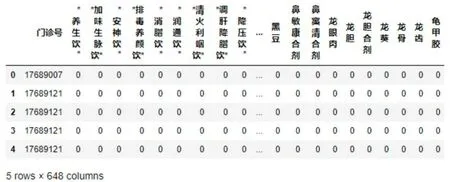
图2 中药使用转换后的数据格式
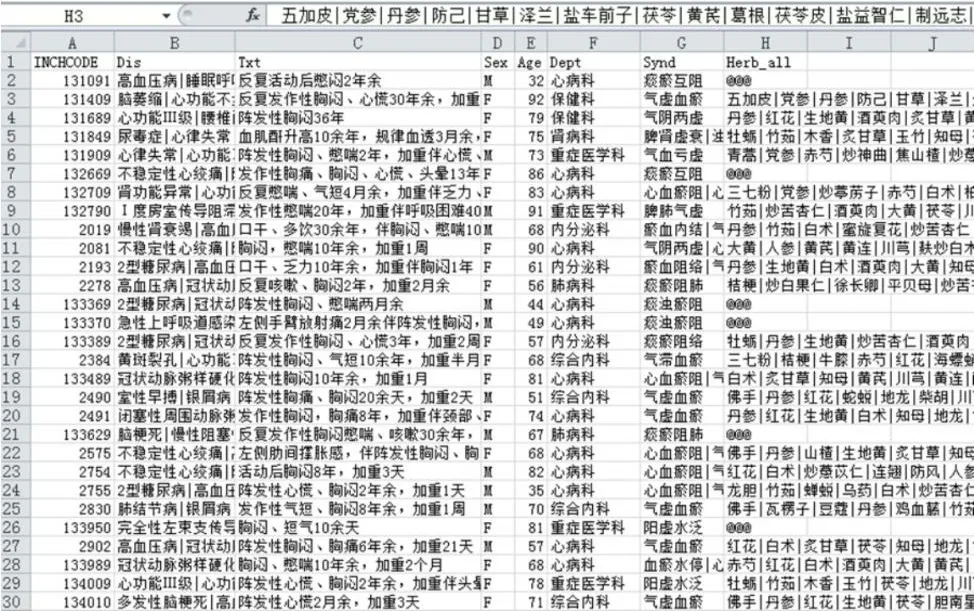
图2 刚抽取出的原始数据集
3.1 对主诉和四诊相关术语进行规范和拆分祖国医学并没有高血压这一病名,根据临床主要表现、病理机制、证候及转归,目前比较一致的认为,高血压应属祖国医学“头痛”、“眩晕”的范畴。因此根据《中医内科学》对眩晕、头痛的认识,认为高血压主诉以“头痛”、“头胀”、“眩晕”为主症,以“头昏沉”、“胸闷”、“耳鸣”、“心悸”、“失眠”为次症进行规范和拆分。高血压四诊和证型关系比较大,在提取术语方面建议作如下描述:以“面色潮红”、“面红耳赤”、“腰膝酸软”、“急躁易怒”、“舌红苔黄”、“舌红苔少”、“脉弦”、“脉数”为主要相关术语。
3.2 电子病历文本的结构化信息提取根据我院电子病历系统模板,按照发病时间、诱发原因、主要症状、加重因素、缓解方式时间和伴发症状做分段提取,比如“近两月”、“劳累后”、“头胀痛”、“情绪波动后加重”、“休息后轻度缓解”、“伴头昏沉、眩晕”。
3.3 对中药名称的规范处理根据《中国药典》2020年版[13]对数据库中的中药名称统一命名,对中药材再加工后的名称、炮制物及提取物统统以该中药材名称录入。如“炒神曲”、“三七粉”、“茯苓皮”、“水牛角浓缩粉”等分别统一命名为“神曲”、“三七”、“茯苓”、“水牛角”等。
3.4 对高血压诊断证型的规范参照眩晕病(原发性高血压)在《中医内科临床诊疗指南》[14]中对证型的分类,把多种辨证分型统一归类到四个主要的分型包括肝火亢盛证、痰瘀互结证、阴虚阳亢证和肾气亏虚证,不能归入上面四类的归入其他类。
3.5 数据库的构建数据库构建要兼顾全面与时效的平衡性,收集研究对象的相关记录,关键变量优先收集。通过结构化的信息采集,把变量信息导入数据库。用Epidata软件和excel建立数据库,变量维度遵循临床问题结构化六要素原则(Population,研究对象 ;Intervention,干预措施;Comparison,对照措施; Outcome,结局;Study design,研究类型;Time frame,观察时间;PICOST)。变量类别包括基线变量、随访变量和结局变量。
3.6 质量控制重视保证数据质量,这是把真实世界数据转变为真实世界证据的前提。因此,质量控制应尽量前置且贯穿临床研究的全过程。原始数据的采集及对混杂因素的处理是真实世界研究质量控制的关键。
3.6.1 研究设计阶段①全面考虑确定的/潜在的影响因素、混杂因素:除考虑传统的年龄、性别等混杂因素外,还需考虑病程、其它用药、高血压共病/合并症等其它影响因素。②提前制定数据收集计划、统计分析计划:数据收集前提前制定计划的主要目的是以防漏失重要变量,影响结果分析的真实性和可靠性。
3.6.2 研究实施阶段数据采集前,制定研究者手册,建立规范统一的数据采集方法明确操作流程,制定标准操作规范,培训相关信息提取人员,确保提取方法一致,减少各种偏倚。①数据的规范性:对原始数据进行数据清理和预处理时,变量的记录格式要统一;疾病的现病史、既往史、诊断、中医证型的诊断要明确和统一,实验室检测方法要统一,中医四诊信息、用语的规范要参考标准等。②数据的准确性和真实性:采取双人双数据库录入原则,保证提取到的数据与既有数据库中的数据一致。数据导出过程中,随机抽取一定比例的数据与原始数据进行人工核对。③保证数据的可溯源性:保存最早导出的原始数据库,保存数据处理的所有记录,包括来源于文字信息提取的结构化处理过程证据链接。④准确的测量、收集暴露/结局并全面、准确的收集关注的影响因素、混杂因素。⑤研究方案要贯穿于研究实施的全过程,并在此过程中不断修正和优化。
4 利用Python实现数据的预加工并构建适合DM的标准数据库
数据的进一步加工是为了将其转换成适合挖掘的形式,即建立起适合高血压中医药数据挖掘相关算法的标准格式的各种存储数据表,通常80%的精力都耗费在这一步。每例患者即几百条数据,成千上万条的大数据人工整理耗时太长,此时可以借助Python语言等计算机科学工具,将准备好的数据转化为适合挖掘算法的分析模型。通过简单模式化的代码,即可以高效快速的建立适合数据挖掘相关算法的标准格式的多种存储数据表。
提取出来的医疗信息包括基本信息、检验结果、诊断信息、中药处方信息、西药处方信息等几个分开的表格。以下重点介绍如何有效利用Python语言快速实现中药处方用药的数据库构建及表格合并的数据集的加工。如在做中药处方用药特征挖掘常用的关联规则分析/聚类分析/因子分析等之前,首先需要把每一味中药的文本数据转换为数值型变量,需要在Excel中建立以高血压患者ID号为行变量,中药具体名称为列变量,以0和1代替有无使用该中药的二分类格式输入单元格,建立共词矩阵的数据表。
4.1 长表格数据的处理初始数据集见图1。该中药信息提取的信息特征是同一位患者不同的处方草药单独占一行,该表格中的中药院内制剂和中药饮片没有分开,数据处理完再行筛选。
目标:列出每例患者用到的中药名称,并把同一列不同行的草药名称放在同一行中。
最终呈现:患者ID(门诊号),所有提取出的中药名称(0表示未使用该种草药,1表示使用该种草药)。
代码实现:
①把中草药进行one-hot编码,调用pandas模块:import pandas as pd
# 导入数据
Data=pd.read_excel('E:\门诊中药.xlsx')
Data=pd.get_dummies(columns=['药品'],data=data)
# data.head()
Columns=list(map(lambda x: x[3:] if '药品' in x else
x,list(data.columns)))
data.columns =columns
# 输出前5行,查看数据,图2
data.head(5)
②整理数据为需要的格式(去掉“中药名称_”):
#=逻辑:如果列名中出现“中药名称”,就取第
5个字符后的内容,否则保留原列名。
Columns=list(map(lambda x: x[5:] if '中药名称' in x
else x,list(data.columns)))
data.columns=columns
③最终按“患者ID”分类,并汇总起来保存为csv文件,方便后续处理:
data.groupby(['患者ID']).sum()
Data=(data !=0)×1
dataxi=(dataxi !=0) ×1.to_csv('患者中药使用情况
(01处理后).csv')
#输出前5行,查看最终呈现的目标数据,图3
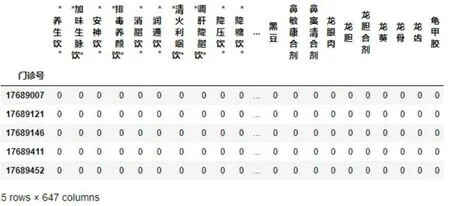
图3 中药处方用药的行呈现矩阵转换数据
data.head(5)
4.2 表格合并因检验结果信息包括检验项目的分类和检验结果报告,属于三维信息,无法和其它表格的二维信息合并,需单独分析。另外中药处方和西药处方信息合并后数据庞大,表格无法承载,故中药和西药表格分别和基本信息及诊断合并,Python处理过程一致。以下以中药为例,把高血压门诊患者基本信息、诊断信息和以上处理后的患者中药使用情况合并到一个表格。
代码实现:
病案号与中草药01对应
import pandas as pd
data1=pd.read_excel('E:\门诊诊断.xlsx')
# 输出前5行,查看数据
data.head(5),图4,图中的NaN表示该单元格为空缺。

图4 门诊诊断信息
# 合并
data_ =data.merge(data1,on='门诊号')
# 输出前5行,查看数据
data.head(5),图5
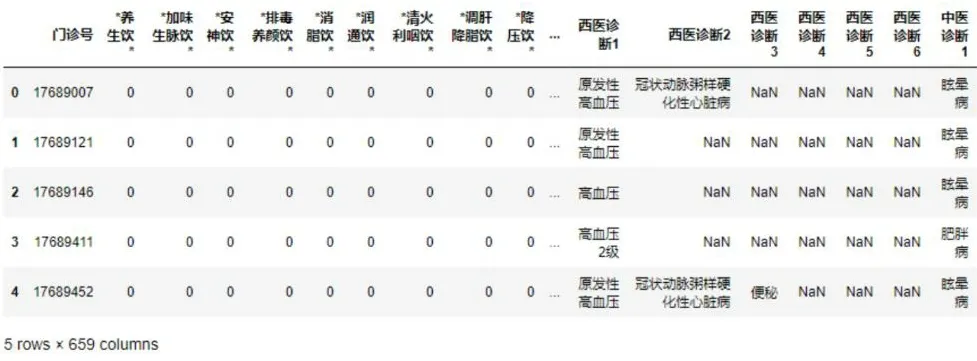
图5 中药信息和诊断信息的合并
Info=pd.read_excel('E:\门诊基本信息.xlsx',index_
col =1)
# 输出前5行,查看数据
data.head(5),图6
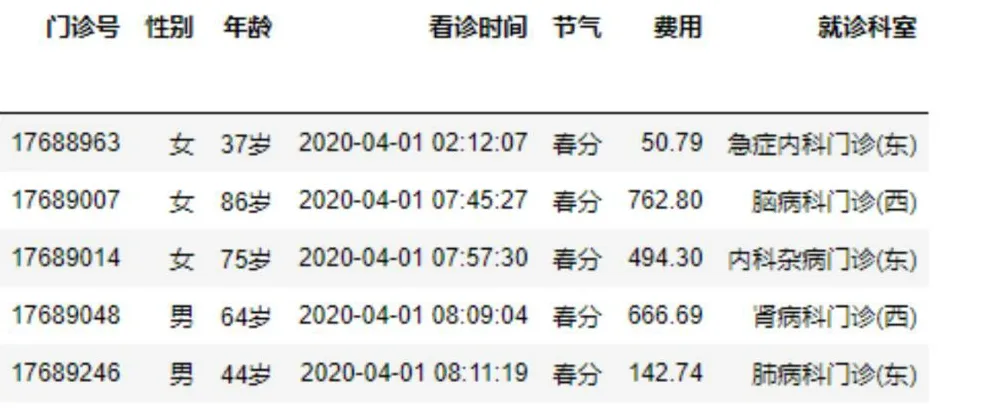
图6 门诊基本信息
Newd=info.merge(data_, on ='门诊号')
newd.to_csv('E:\合并中药.csv')
最终呈现的合并后信息见图7。
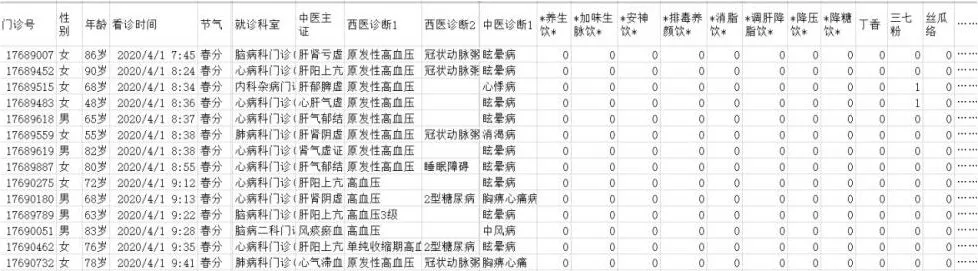
图7 合并后信息
4.3 宽表格数据的处理初始数据集见图8。该表格中药提取的信息特征是同一例患者不同的处方中药单独占一列,一例患者的数据占据一行。

图8 以列分布的中药使用信息
目标:把组方中的每种中药变为哑变量,one-hot编码形式。
代码实现:
import pandas as pd
import numpy as np
def maketable(sheet):
data=pd.read_excel('E:\高血压.xlsx',sheet_
name=sheet)
drug=data.iloc[:,1:].T
data=data.applymap(lambda x: x.strip(' ') if
type(x)=str else x)
l=[ ]
for i in range(1,data.shape[1]):
l+=[i for i in set(data.iloc[:,i])]
l=list(set(l))
l.remove(np.nan)
dic={ }
for i in range(len(l)):
dic[l[i]]=i
mtx=np.zeros((drug.shape[1],len(l)))
drug=drug.applymap(lambda x: dic.get(x,-1))
for i in range(drug.shape[1]):
for j in filter(lambda x: x>0,drug[i].to_list()):
mtx[i,int(j)]=1
mtx=pd.DataFrame(mtx).astype(int)
mtx.columns=l
mtx.index=data['住院号']
mtx.to_csv('{}.csv'.format(sheet))
pass
sheet_list=['Sheet1']
for i in sheet_list:
maketable(i)
处理后最终呈现的中药使用矩阵格式数据见图9。
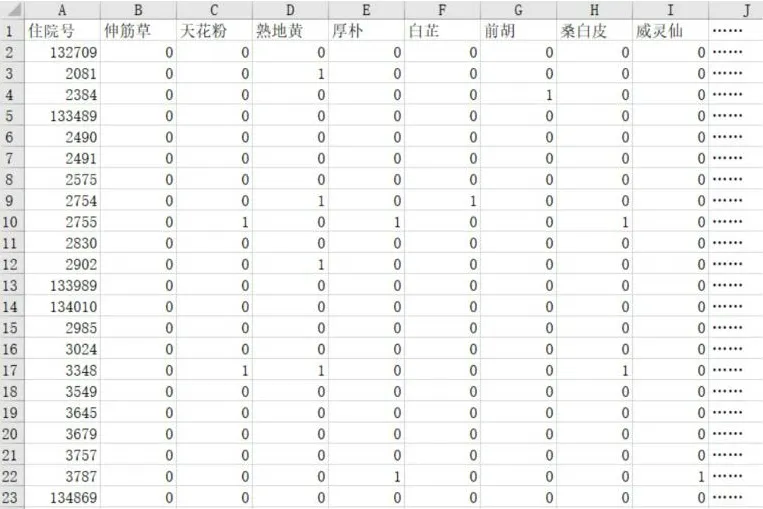
图9 中药使用情况的矩阵格式数据
以上Python处理过程中的代码可以复制粘贴以实现其它类似数据集的加工,此过程可以大大节省中药大数据的预处理时间,以最近提取的我院2020年全年的住院和门诊上万条中药数据为例,只用几分钟即可处理完毕,若人工整理或需要几个月的时间。
5 数据的初步分析
标准数据集构建后,首先要对数据进行初步的描述分析,很多中医药DM研究没有对研究对象进行基本的人口学特征和临床流行病学特征的初步分析,这是不合适的。任何研究的最终目的都要用到人身上,要善于总结规律,发现新问题,以便于临床诊疗和预测,可以采用易学实用的SPSS软件对数据源进行初步分析和统计量的计算。考虑到真实世界研究的混杂因素偏多,研究中可能需要用到回归分析、广义方程模型和倾向性评分等高级统计方法。此外,数据初步描述阶段,可利用Excel的数据透视表进行频数的统计等简单的分析和数据透视图的可视化分析,让数据结果更为直观。
6 数据挖掘
标准数据库构建之后,就要对所得到的经过转化的数据进行深度挖掘。借助中医学和统计学专业知识,选择恰当的算法即确定所用的数据挖掘模型,得出有价值的结果和结论,达到个人的研究目的。DM过程中可能会用到多种数据挖掘和统计的方法及工具,反复尝试多种挖掘方法并在临床中验证以达到预期的最优结果。算法应用方面,logistic回归、Cox回归等常被用于数据的初步分析阶段,用于疾病的相关病因分析及预测模型等;关联规则分析的Appriori算法被广泛应用于中医的药方规则提取;聚类分析、主成分分析、因子分析等常用作药物处方的分类、证型的归类和降维等;决策树、人工神经网络、贝叶斯网络等常用于病情转归的预测。
7 结果分析及可视化呈现
结果分析是数据挖掘的重要环节,数据挖掘结果在实际运用中需要反复求证,以检验其合理性,需要与专家之间建立广泛的交流,将各种挖掘的结论与他们的医疗经验进行求证,以检验挖掘方法的合理性。结果出来后,利用可视化技术可以将结果显示得更加清晰直观,并对其进行解释和评估,更加有利于预期的目标[15]。Python和R语言均提供了丰富的数据可视化库,在数据可视化方面都有其独特的优点。当前较为普遍的观点认为Python在机器学习的数据挖掘方面优于R语言,而R在作图方面则优于Python,其ggplot数据可视化包功能强大,其它工具如GraphPad、Excel等亦可实现简单作图。
8 讨论
现今,我国医疗领域已经掀起了一场数据挖掘革命浪潮[16]。中医药的个体化诊疗特点使得循证中医药研究更多的开始转向真实世界的临床实践。中医药的数据挖掘在中医药各领域的探索积极有效。有了信息技术,病历和随访数据可以更高效地存储和提取,从而实现更广泛的数据挖掘。如从医学数据中寻找潜在的关系或模式,获得有关患者诊断和治疗的有效信息;同时还可挖掘名老中医用药经验、核心处方、用药规律及对证候类型的规范聚类等;还可以对中药进行卫生经济学评价;考虑到中医药在慢病治疗中的优势,可以分析患者的流失率/二次/多次回归保持治疗的依从性的相关因素等等;通过医疗大数据的分析,还可以为政府决策提供依据。
目前数据挖掘技术发展水平和与中医药结合的深度和广度还未能改变中医药数据难处理的大格局,尽管中医药的数据挖掘开展已经很久,但庞大复杂的临床历史数据依然是制约中医药快速发展的瓶颈。大部分的医疗信息数据挖掘还比较零散,数据量比较小,在大数据的预处理和深入分析能力方面十分欠缺。归根结底还是因为临床人员在统计学及人工智能方面技术的不足,希望本文提供的用Python编码实现的数据预加工能给临床数据挖掘提供帮助。总之,数据挖掘只有在把握中医特有的“整体观”理论背景和“辨证论治”两大特色的思维规律的前提下,才能在保证研究方向合理的同时,将真实世界研究的中医药数据处理能力提高到新的水平。数据挖掘的最终目的还是要为实现中医学从“经验医学”走向“循证医学”的现代化研究搭建起新的桥梁,把中医药学术提升到一个新阶段,从而推动中医药事业高质量发展。
