基于登录行为分析的失陷邮箱检测技术研究
2023-09-07赵建军汪旭童刘奇旭
赵建军,汪旭童,崔 翔,刘奇旭
(1.中国科学院 信息工程研究所,北京 100089;2.中国科学院大学 网络空间安全学院,北京 100089;3.中关村实验室,北京 100089)
1 引 言
电子邮件是现代企业办公环境中必不可少的工具之一。邮件往来能够反映出一个企业的人员结构,邮件内容能够反映出员工的工作内容,这些正是攻击者渴望获取的情报。近年来,高级持续性威胁(Advanced Persistent Threat,APT)组织活动日益猖獗,邮箱是其窃取情报、横向移动的首要目标之一。在ATT&CK矩阵[1]中,使用电子邮箱相关技战法的APT组织共20余个,超过总数的15%。此外,不断泄露的用户数据也为攻击者提供了大量的邮箱账号和密码[2]。除被公开的数据外,还有更多的数据正在黑市和暗网中被攻击者收集、交换和交易,这就导致大量邮箱处于随时可被攻击者接管的风险之中。攻击者可以通过失陷邮箱来窃取用户甚至企业的工作内容和成果,或者根据人际关系来进行横向移动钓鱼攻击。失陷账号存在时间越长,对企业和组织的危害越大,因此及时发现这类失陷账号尤为重要。
目前,学术界关于电子邮件的研究大多集中在垃圾邮件、钓鱼邮件的检测和过滤上[3-6]。垃圾邮件、钓鱼邮件检测和失陷邮箱发现是在同一场景下的两个不同方向。垃圾邮件、钓鱼邮件的检测侧重对邮件内容的检测,重点关注实时防御能力;失陷邮箱发现则是侧重对失陷结果的检测,重点支撑损失评估和溯源取证相关工作。文中涉及的研究侧重后者。
在失陷邮箱发现的相关研究中,大多数检测方法都是面向具体的一种攻击过程(如鱼叉钓鱼、暴力破解、横向移动等)。例如,2016年,HU等[7]参考社交网络领域相关技术,采用社交关系图拓扑分析的方法,借鉴并改进出度、Pagerank等5个指标对邮件往来关系进行评价。基于邮箱收发日志,将邮件往来关系异常的账户判定为失陷账户,该方法的平均准确度约为60%。2017年,HO等[8]使用邮件样本、网络日志(HTTP日志)、邮箱登录日志作为分析数据,基于发件人信誉和邮件中统一资源定位系统(Uniform Resource Locator,URL)的域名信誉对邮件可疑程度进行评价,通过比对HTTP日志,追踪用户访问钓鱼链接并输入账户口令的情况来确认邮箱是否失陷。2018年,杨加等[9]提出一种面向校园网场景下的失陷邮箱检测方法。该方法分析邮箱登录日志,使用登录频率阈值确定暴力猜解源IP地址,通过对账号和IP地址对应关系的熵值进行聚类,将恶意IP地址归为同一组织。同时,该方法通过对IP地址地理位置变化及异常时间登录次数设定阈值来发现异常登录行为。检测横向移动钓鱼邮件的方法同样能够用来检测失陷邮箱,但前提是攻击者存在发件行为,如果攻击者的目的只是窃取邮件,那么就无法检测到此类失陷邮箱。2019年,HO等[10]结合文献[7]和文献[8]的方法,使用随机森林来分类邮件是否为横向移动钓鱼邮件。该方法使用3组特征:邮件接收人相似性、发件人信誉和URL信誉。通过分析多个恶意邮件发件人是否存在因果关系来推测攻击是否成功。
除邮箱账号外,其他形式的在线网络服务也会面临账号失陷的威胁。社交网络的兴起和不断发展,吸引了大量关注和资金。攻击者对社交网络的非法使用能够为其带来丰厚的利益,如滥发广告、售卖热搜和点赞等。这些获取利益的方式都需要大量账号的支持,因此催生了各种针对社交网络用户账号的攻击,例如恶意注册、账号劫持、暴力猜解等。目前,学术界已经存在有关防御此类攻击的技术研究[11-15],其思路和方法也能够扩展到失陷邮箱的检测中。
攻击者在窃取邮件内容或发送横向移动钓鱼邮件时,必然首先通过POP3、IMAP、SMTP或者Webmail等方式登录邮箱,即在失陷邮箱的登录行为中必然存在除邮箱所有者以外的登录行为(可疑登录行为)。若可疑登录行为可被提取和比较,则可在多个邮箱之间纵向对比其相似性。当可疑登录行为在多个邮箱账户内出现且相似时,可以依据其共性来发现同一批失陷的邮箱群,并关联到攻击者。因此文中的研究重点是寻找攻击行为共性可能出现的方面,以及如何利用该共性检测失陷邮箱。
2 登录行为的时空分析
邮箱的登录日志能够反映出邮箱的登录行为。最基本的,登录日志应包含邮箱地址、登录IP地址和登录时间等。其中IP地址属于空间属性,其相关的特征有归属城市、经纬度等;登录时间属于时间属性。当登录日志的记录时间足够长且信息足够充分时,统计特征会暴露出攻击者在入侵多个失陷邮箱时的共性,将从时间和空间的角度来研究该共性的刻画方法。
2.1 邮箱失陷模型
将邮箱账号作为目标的攻击者主要可分为两类:以窃取信息、投递木马为主要目标的APT组织和以获取收益为主的互联网黑产。二者在实施攻击时的共同点是:在一定时期内,将某个企业或组织的所有邮箱账户均视为目标。前者以任务为驱动,即在攻击任务开始后一段时间内,以期获得尽可能多的邮箱账号来窃取目标企业或者组织的工作内容和人员架构。后者以数据为驱动,即在其获取新的泄露数据后,立即对邮箱账号和密码进行验证,储备为其攻击资源。
基于此类攻击场景,给出邮箱失陷模型,如图1所示。在该模型中,多个攻击者可能同时针对同一批目标,且每个攻击者可能使用一个或多个IP地址来实施攻击,因此难以仅通过IP地址来关联攻击行为。为解决这个问题,将登录行为的两个属性(登录地址和登录时间)作为分析和关联对象,即通过分析各邮箱中异常的一个或多个IP地址是否具备地理位置的空间相似性或登录时间的同步性来确定邮箱是否失陷。
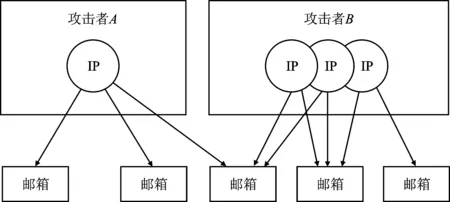
图1 邮箱失陷模型
2.2 攻击行为的空间相似性
攻击者为了防止自己被溯源,几乎不会使用自身所处的网络作为攻击出口。公有的云服务器由于其易于获取、可随时丢弃的特点,成为攻击者首选的攻击设施。此类云服务器以虚拟机的形式在使用时即时创建,在用户弃用时彻底删除,几乎不会留下任何操作痕迹,并且相比于个人终端肉鸡、物联网僵尸节点等具备更好的可操作性和稳定性。目前国内外常见云服务提供商都在常见的大型数据中心(如位于香港、新加坡、东京等地)提供可选节点。对于国内的组织和企业来说,来自这些位置的登录行为是比较可疑的。例外的是,用户自身配置了境外的代理服务器来登录邮箱,但在文中所针对的攻击模型中,这种行为难以造成多个账号的异常具有同步性。
笔者采用的空间相似性的判定思路是:假设邮箱i和邮箱j的常用登录位置(可信)接近,且邮箱i和邮箱j的非常用登录位置(可疑)也接近,认为邮箱i和邮箱j具备空间相似性。常用地特征用来将邮箱关联到一个企业或组织,尤其是当日志数据中的邮箱地址是匿名地址时,难以确定哪些邮箱属于同一个企业或组织,这时常用地特征显得更加重要;异常地特征用来将攻击者所使用的一个或多个IP关联到同一个组织。当一批待分析的日志数据中,大量邮箱具备相近的常用地和异常地,即这些邮箱属于同一个企业或组织且均被若干地理位置邻近的IP地址登录过时,满足所述的邮箱失陷模型,这些邮箱存在失陷的可能。
2.2.1 空间相似性指标
具体地,从邮箱登录日志中提取某个邮箱账号中登录次数最多的IP地址记作该邮箱的常用IP地址,提取登录次数最少的IP地址记作该邮箱的异常IP地址。通过计算两个邮箱之间常用IP地址地理位置间的距离与异常IP地址地理位置间的距离之和,即可量化此两个邮箱的空间相似性,具体计算为
s(i,j)=dis(fi,fj)+dis(ai,aj) ,
(1)
其中,s表示邮箱i和邮箱j的空间相似度计算函数,dis表示两个IP地址地理位置距离的计算函数,fi和fj分别表示邮箱i和邮箱j中的常用IP地址,ai和aj分别表示邮箱i和邮箱j中的异常IP地址。在计算距离时,可使用IP地址地理位置数据库获取IP地址对应的经纬度,再根据经纬度来计算两个点的地理距离。
为使空间相似性指标更加准确,在提取常用地和异常地特征时,选取多个常用IP地址和异常IP地址。在计算时,首先列举邮箱i的常用地IP地址到邮箱j的常用地IP地址的所有可能组合,其次分别计算所有距离并取最小值,对于异常地的计算与之类似。则此时邮箱i和邮箱j的空间相似度可以表示为
(2)
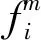
空间相似性指标代表了两个账户之间最相近的空间位置关系,该指标越小,此两个账户常用地IP地理位置越接近,且异常登录IP地址地理位置也接近。选择IP地址间的距离而不是直接根据IP地址归属城市来判断空间相似度的原因在于,对于面积较小且较集中的城市群,地理位置邻近的IP地址可能归属于不同的城市,导致无法将其关联到同一类中,造成漏报。此外,经纬度相对城市更加客观,避免了IP信息数据库中因“城市、区县等”定义模糊带来的影响。
当若干邮箱两两之间的空间相似度都接近,且该邮箱群体的数量很多时,则可确定此邮箱群存在失陷可能。因此,对失陷邮箱群的检测,可以通过划分具有相近空间相似度的邮箱社区来实现。
2.2.2 图构建与社区划分
将邮箱账户作为节点,将邮箱间的空间相似度作为节点间边连接的依据,可构建一个图来表示待分析邮箱之间的空间邻近关系。具体地,在构建图时,引入一个阈值来确定两个邮箱之间是否存在一条边的连接。当邮箱i和邮箱j的空间相似性指标小于阈值时,此两个邮箱之间连接一条边,反之则不连接。阈值的确定会影响最终的结果,阈值过大时会引入较多误报,阈值过小则会引起漏报。由于空间相似性指标通过计算两地间的距离得出,因此在设定阈值时需考虑登录地点的偏离范围。根据文献[16]的统计,国内主要城市的通勤空间半径平均约为30 km,因此设定该阈值为30。
空间相似度图G的构建过程可以描述为
(3)
图构建完成后,使用Louvain算法对该图进行社区划分。Louvain算法是一种基于聚类的社区划分算法,能够快速有效地辨别有层次的社区结构从而对大型网络进行社区划分,具有快速、准确的特点,被认为是性能最好的网络或图的发现算法之一[17]。与传统的聚类方法(如k-means和基于密度的聚类)相比,社区划分算法可以更灵活地选择和调整距离指标,并可以通过控制节点间边的连接来调节图的规模,以达到更好的聚类效果。
2.2.3 异常排名与信誉机制
对于邮箱是否确实失陷的问题,只能通过向邮箱所有者亲自确认或者关联威胁情报中的威胁标识(Indicators of Compromise,IoCs)。但在实际工作中,向邮箱所有者确认是不现实的,加之威胁情报又仅能披露部分恶意IP地址,使得对这一问题很难给出是和否的判断。因此,从失陷邮箱检测的目的性(评估损失、溯源攻击)出发,参考DAS[8]的思路,给出一个按失陷可能性排序的邮箱列表,当工作人员需要调查取证时,可为其提供一个优先级的参考。
经过上述图构建和社区划分后,可得到若干社区,同一个社区内的邮箱的空间行为都较为相似。参考上述邮箱失陷模型,被同一攻击者入侵的邮箱账号将会被划分到同一个社区内;对于其他邮箱账户,其空间特征复杂多样,没有规律,使得这些账户呈现出分布于不同的社区且社区内邮箱账户节点数较少的特点。因此可以依据社区规模对邮箱账户初步排序,即社区内节点数越多,越符合邮箱失陷模型,该社区被入侵的可能性就越高。
对于社区内的邮箱可疑度排序,引入了一个IP地址信誉评估机制。邮箱的常用IP地址和异常IP地址的信誉之差越大,说明该邮箱的常用IP地址越可信,异常IP地址越可疑,即该邮箱的排名应处于更靠前的位置。涉及多个常用地和多个异常地时,先计算所有常用IP地址信誉的平均值,再与所有异常IP地址信誉的平均值做差。
在具体计算IP地址的信誉时,使用3个特征:登录天数比率平均值FA、登录次数比率平均值FB和登录方式个数指数FC。仅当一个IP地址登录过较多邮箱数且在每个邮箱中都较活跃时,才具有较高的信誉值。反之,如果一个IP地址登录过很多邮箱,但都不活跃,则较可疑。同时,一个IP地址被多个正常用户使用时,登录所用的协议更加随机,因此特征FC数的值越大越可信。具体地,针对某一IP地址的登录天数比率平均值的计算表示为
(4)

(5)
针对某一IP地址的登录方式个数指数的计算表示为
FC(p)=0.1×2l-1,
(6)
其中,l表示登录方式个数。
最终,针对某一IP地址的信誉r计算表示为
r(p)=log(FC(p)(FA(p)+FB(p))) 。
(7)
基于节点数量规模对社区可疑性进行排名,再辅以基于信誉机制的社区内账户排名,最终得到一个按照可疑度排序的邮箱列表,为工作人员提供优先级参考。
2.3 攻击行为的时间同步性
基于节2.1中提及的邮箱失陷模型,攻击者针对同一企业或组织的攻击活动有可能集中在一段时期内。遭到入侵的邮箱账户在此期间内的登录行为,会与之前后一定时期内的行为存在差异,且该差异会同时出现在多个邮箱中。因此在该场景下的分析思路是,找到某个邮箱的与其他时间段登录行为不同的时间段,并调查其他邮箱在该时间段内是否也同样存在异常。
2.3.1 IP地址变化频率
当邮箱账户只被其所有者登录时,登录IP地址的变化可能不剧烈,或变化频率较稳定。当所有者和攻击者同时登录邮箱账户时,则可能会产生交替的登录行为,导致该时期的频率变化与以往不同,如图2所示。

图2 攻击者和所有者交替登录造成IP地址频繁改变
对一段时期内“登录几次后变化IP地址”这一指标进行统计,可以得到一个序列用来描述该时期内的IP变化情况,称为“IP地址频次描述序列”。以图2为例,当只有邮箱所有者登录时,该序列可表示为[0,0,2,1,0,1],意为在这段时期内,登录1次和登录2次后改变IP地址的情况有0个,登录3次后改变IP地址的情况有2个,登录4次后改变IP地址的情况有1个,……,登录次数超过5次后改变IP地址的情况有1个。而当邮箱所有者和攻击者同时登录该邮箱账户时,该序列变为[8,4,1,1,0,0],出现了巨大差异。在此例中,使用的统计频次阈值为5,即将同一IP地址登录次数超过5次的情况合并,因此序列的长度为统计频次阈值+1。
考虑到现实场景中,邮箱所有者可能同时使用多个客户端或者Webmail来登录邮箱,自身存在客户端之间的交替登录行为,因此在计算IP地址频次描述序列时,须按各登录方式(协议)分别进行,最大程度降低自身行为带来的干扰。
2.3.2 异常窗
将邮箱的登录日志按照等时间段分割为N段,每个时间段称为一个“窗”,则在统计完每段的IP地址变化频率后,可得到一个长度为N×(统计频次阈值+1)的二维序列。考虑工作日与双休日邮箱用户的登录频率可能不同,将以周为单位来划分统计时间段,即将窗大小设置为一周,将工作日与双休日视作一个整体来统计。
在N个IP地址频次描述序列中,若存在一个序列与其他序列存在较大差异,且其他序列又较为相似,则此时该序列异常,称为“异常窗”,一个示例如图3所示。示例中,t表示时间,纵坐标表示同一IP地址的登录频次。
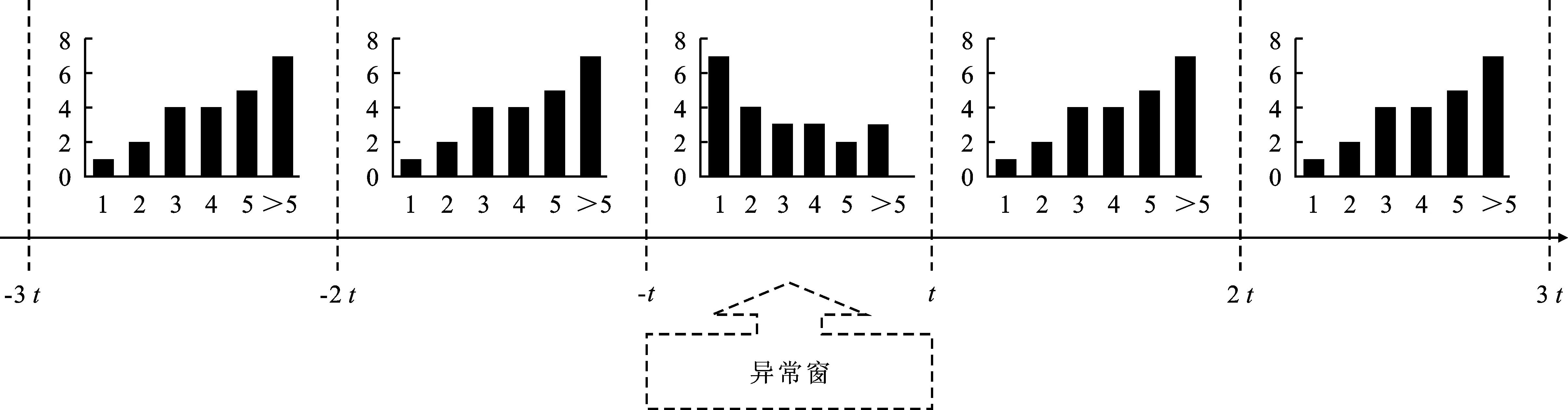
图3 异常窗
检测异常窗可以通过能够检测异常点的聚类算法来解决,使用DBScan算法。DBScan算法是一种基于密度的空间聚类算法,属于无监督聚类算法,该算法能够将具有足够密度的区域划分为簇,并找出噪声点(异常点)[18]。
DBScan有两个关键参数:社区最大半径Epsilon和社区最小点数minPts。Epsilon决定了两个点的距离小于多少时才会划分到同一个簇。在文中的研究场景中,设定该值为所有点两两距离的平均值,避免该值设置过大导致无法发现异常点,或者该值设置过小导致异常点过多。在计算两点之间的距离时,采用欧式距离度量。参数minPts设定为2(算法默认值),表示在社区半径内至少有2个点时,视作一个簇。
相较于聚类结果,文中更加关注异常点。在聚类完成后,将异常点标识为1,其他点标识为0,即可得到一个长度为N的序列,例如[0,0,0,0,0,0,0,1,0,1,0,0,0,0,0,0,0],表示日志共划分为17周,在第8周和第10周中,登录行为出现异常。当对所有邮箱进行检测后,即可得知每周有哪些邮箱存在异常。
2.3.3 异常排名机制
登录失陷邮箱的IP地址可能有多个,其中包含所有者和攻击者的IP地址。为进一步筛选IP地址,文中定义如下规则来缩小范围:假设邮箱i中第n周为异常周,对于本周登录过该邮箱的一个IP地址a,当a同样登录过邮箱j且当周不是异常周,或a在除第n周外的其他周登录过邮箱i且当周不是异常周时,认为该异常周不是由a造成的,因此在衡量失陷可能性时将a排除,不考虑a的影响。
若在多个异常周中都出现同一个IP地址,则这个IP地址较为可疑,且异常周的个数越多,可疑程度越大,也即与该IP地址关联的邮箱的失陷可能性越大。因此,引入了一个指数形式的指标(邮箱异常指数)用来评价邮箱失陷的可能性。具体地,首先统计每个IP地址在所有邮箱的所有周内的异常周个数,由于统计范围包含自身异常周,因此该计数≥1;其次,按式(8)计算指数和:
(8)
其中,m标识邮箱异常指数;i∈I,I为登录过该邮箱且未被排除的IP地址集合;wi表示存在IP地址i的异常周的个数。
将一个异常周内的所有邮箱的异常指数的和作为该异常周的异常指数,便可对异常周进行排序。在排序异常周时,可将各种登录方式(协议)的分析结果进行混合,以综合判定异常情况。若异常周内只有一个异常邮箱,则不对该异常周排序。当一个邮箱同时出现在多个异常周时,取排名靠前的作为最终结果。
3 实验与结果分析
3.1 数据集
文中使用的数据集由5个不同规模和起止日期的邮箱登录日志组成,在对原始日志进行预处理后,提取登录方式、登录时间、登录IP地址和邮箱账号4个基本特征,其中登录方式包括Web(通过登录Webmail访问邮箱)、POP3、IMAP和SMTP。为了消除DHCP客户端造成的IP地址浮动,尽可能地减少邮箱所有者和攻击者自身IP变化带来的影响,除统计IP地址变化频次外,在其他过程中将IP地址转化为相应的子网进行统计和分析。NUR等[19]的研究表明,互联网中使用最频繁的是/24子网,因此在转化时,将IP地址转化为对应的/24子网。数据集的总体情况如表1所示。
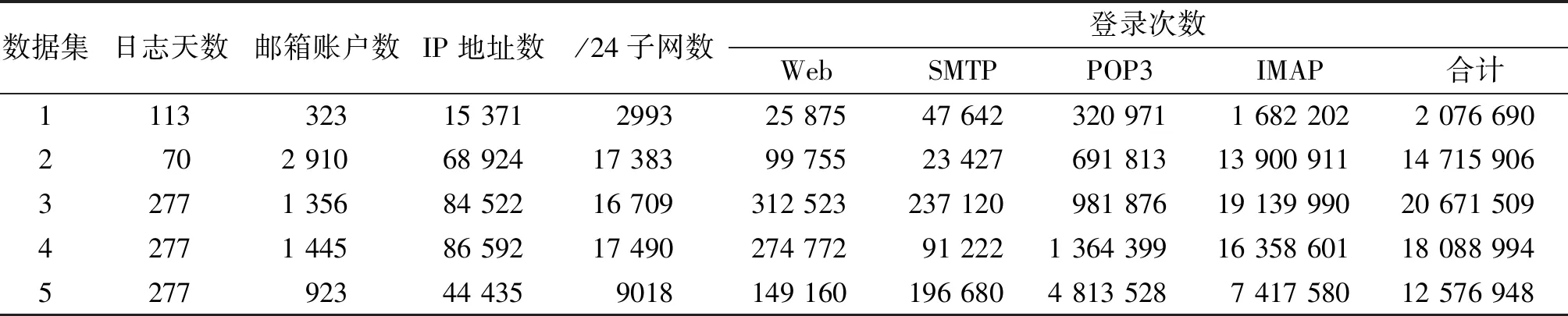
表1 数据集总体情况
3.2 实验结果与分析
在没有其他参考依据或无法向邮箱所有者确定的情况下,使用威胁情报中的IoCs来匹配可疑IP是一种常规做法。匹配时需要考虑到IoCs的滞后性和时效性,如果日志中的某个IP地址的登录时间在相关IoCs发布时间之前,且不早于发布时间6个月前,则认为该IP地址是恶意的。使用开源威胁情报Alienvault-OTX[20]作为参照,在匹配了5个数据集的所有IP地址(共299 844个)之后,均没有IP地址被标识为恶意。这一结果也反映出仅依赖威胁情报时的局限性。因此,将匹配范围扩大,使用/24子网作为匹配范围,即若登录IP地址的同子网IP地址存在匹配结果,就将该/24子网视作恶意子网。匹配结果如表2所示,其中已对恶意子网进行匿名化处理。在统计恶意子网时,若恶意子网所在地区是邮箱账号常用地,则认为该结果是由于匹配范围不准确造成的,不进行统计。
从威胁情报匹配结果来看,数据集1和数据集5的失陷情况非常符合节2.1中提到的邮箱失陷模型,因此在验证文中的分析方法时,将重点关注在此两个数据集上的检测结果。
3.2.1 时空分析结果
在对5个数据集分别按照上述时间和空间分析方法进行检测并基于表2中的统计进行验证后,空间相似性分析结果如表3所示,时间同步性检测结果如表4所示。

表4 时间同步性分析结果
从空间相似性分析结果可以看出,所输出的邮箱个数,已经较原始邮箱数有大幅缩减,并且在各数据集中排名靠前的社区内均包含失陷的邮箱。在排名前5的社区中,除数据集4外,在其他数据集中的检出率均达到了60%及以上,在数据集1中更是高达约78%。数据集4中的失陷邮箱未检出是因为关联的恶意IP地址相距较远,不存在空间相似性,被排在了靠后的位置。笔者在对数据集1的检出结果进行分析时发现,所检出的异常地均不属于子网B,原因是子网B在其所登录的邮箱中的登录次数较多,在计算空间相似度时,该子网没有被当做异常地子网。
在时间同步性的检测结果中,除数据集1中的最大异常周指数远高于其他数据集外,在其他数据集上的表现均不理想。为研究其原因,笔者对所有恶意子网的行为进行了分析。在对每个恶意子网的登录次数、登录方式、登录时间等进行分析后发现,在所有的恶意子网中,只有数据集1中的子网B在其登录过的每个邮箱中,都具有较多的登录次数且都集中在6天内,这足以造成IP地址频次描述序列的改变。因此在时间同步性检测中,能够成功检测出该子网造成的失陷邮箱。在表4展示的结果中,排名第一的异常周即为子网B的活跃时间,其登录过的每一个邮箱,均在本周内出现异常。其他恶意子网的登录次数普遍较少,均少于15次,难以造成IP地址频次描述序列的异常,因此未能检出。由于数据集1中的子网B和子网A在登录方式、登录频率、目标邮箱上均有不同,因此认为此两个恶意子网对应2个攻击者。
从上述结果可以看出,当实际失陷情况符合节2.1中所述邮箱失陷模型时(数据集1和数据集5),文中提出的时间和空间两个分析角度能够成功检出失陷邮箱并且具有互补性。若攻击者在每个邮箱中的登录次数较少,则虽登录行为不足以引起IP频次变化,但此时登录IP会被判定为异常地,用空间分析方法能够检测出;反之,若登录次数普遍较多,则虽登录IP地址不会被判定为异常地,但邮箱所有者和攻击者的交替登录行为必然会改变IP地址变化频次,此时可使用时间分析方法进行检测。
3.2.2 对比分析
为验证所提方法的先进性,将与DAS[8]在仅使用登录日志时的表现进行比较。当一次登录事件发生时,DAS使用两个特征:① 该登录事件之前,从登录IP地址对应城市登录过的用户数;② 该登录事件之前,当前用户从IP地址对应城市登录过的次数。DAS的计分算法是:统计所有事件中,每一个特征值都高于当前事件的事件个数,最终以该事件个数作为得分并按降序排序输出。由于DAS所输出的是可疑的登录事件排名而非邮箱排名,因此对DAS进行了部分修改。首先,将每个数据集中的前1/8数据作为DAS的启动数据;其次,将IP地址转化为/24子网;最后,将同一个邮箱的所有登录事件中最可疑的5个登录事件的得分的平均值,作为该邮箱的最终得分。这就相当于对于真实失陷的邮箱,排除了异常不明显的登录行为,即相当于优化了DAS的检测结果,使可能失陷的邮箱排在更靠前的位置。
为综合评价所提出的空间和时间的分析结果,将由空间分析和时间分析所输出的两个邮箱列表交替合并为一个邮箱列表后,再与DAS进行比较。由于文中的检测方法和DAS所输出的邮箱账户的个数不同,考虑对比的合理性,设计了一种比较方法:选取两种方法输出的排名靠前的相同数量的邮箱列表进行比较,并以列表中的失陷邮箱的命中个数作为评价指标。对应于检测方法在实际的应用场景中,考虑分析成本和时间限制,假定安全分析人员在一定时间内仅能人工分析部分邮箱账户,则此时在待分析对象中,应尽可能多地包含可能失陷的邮箱。因此要求在文中与DAS所输出的邮箱列表中,失陷邮箱应尽可能排在靠前的位置。以数据中邮箱总数的10%、20%、30%作为负载限制分别统计文中方法和DAS的命中率后,结果如表5所示。
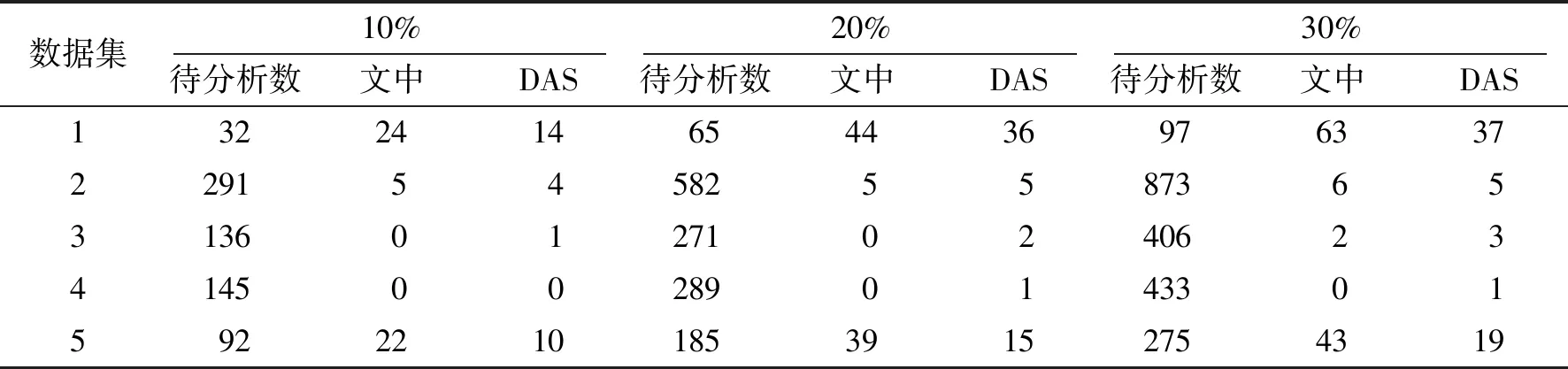
表5 文中方法与DAS命中率
从结果中可以看出,在待分析目标邮箱规模相同时,文中的方法优于DAS,尤其是在数据集1和数据集5中,文中的方法检测出的失陷邮箱个数远高于DAS。
3.2.3 未公开恶意子网检测结果
除与公开的威胁情报进行匹配外,笔者对每个数据集中排名靠前的社区中的邮箱和异常指数较大的异常周内的邮箱进行了人工分析。
分析发现,在数据集1中排名第一的社区中,除恶意子网A外,还存在未公开的恶意子网N。恶意子网N在社区1中登录过4个邮箱,在整个登录日志中共登录过8个邮箱。该子网登录方式与恶意子网A相同,且在每个邮箱中的登录次数均为1次,登录行为与恶意子网A极为相似,因此笔者认为,恶意子网N与恶意子网A属于同一个攻击者。
在数据集2中排名第一的社区中,存在未公开的恶意子网O,在社区1中登录过6个邮箱,在整个登录日志中共登录过15个邮箱。登录方式全部一致,且在每个邮箱登录3次至4次后,就换到下一个邮箱。该行为疑似攻击者使用自动化脚本批量验证账户和密码。
在数据集5中排名第一的社区中,存在未公开的恶意子网P,在社区1中登录过3个邮箱,在整个登录日志中共登录过7个邮箱。该子网与恶意子网M地理位置、登录方式相同,时间集中且行为相似,因此笔者认为,恶意子网P与恶意子网M属于同一个攻击者。
在数据集5中排名第二的社区中,存在未公开的恶意子网Q,在社区1中登录过4个邮箱,在整个登录日志中共登录过12个邮箱。该子网在每个邮箱中的登录方式一致,登录次数类似,且时间集中。但因其与恶意子网M、P的登录方式不同,因此笔者认为该恶意子网对应另外一个攻击者。
在数据集3中异常指数最大的异常周内,存在2个邮箱的异常指数超过1 000,且其登录的IP地址存在交集,并几乎在同一时间终止登录行为,推测为这2个邮箱在失陷后被注销。
3.3 实验小结
对于活动不频繁的邮箱账户入侵行为,攻击者所使用的IP地址(子网)被成功判定为异常登录IP地址(子网),利用其空间相似性,成功将失陷的邮箱账户划分到了同一社区;对于登录次数较多的账户入侵行为,攻击者的登录造成了IP地址变化频率的剧烈波动,利用异常时间同步性,成功定位到了异常周。
综合考虑空间和时间检测结果时,以30%的负载为例,待分析邮箱共有2 084个,相比原始邮箱个数(6 975个)减少了4 891个,此时检测结果中共包含114个失陷邮箱。对于安全分析人员而言,即在减少约70%工作量的情况下,能够发现约60%的失陷邮箱,节省了大量时间。由于检测结果中几乎覆盖了所有的恶意子网,因此在更加理想的情况下,若分析人员能够根据已发现的失陷邮箱,定位到恶意IP地址(子网),再根据该IP地址(子网)关联到所有被登录过的失陷邮箱,则在同等工作量的情况下,能够发现约98%的失陷邮箱。
此外,所提出的方法还检测出已知攻击者的未公开恶意子网2个,新发现攻击者3个。
4 结束语
根据APT攻击组织以及互联网黑产等攻击者在入侵邮箱账户时的行为特点,首先提出一个邮箱失陷模型,归纳了此类攻击行为在利用受害者邮箱时具有共性。其次,针对该邮箱失陷模型,从空间和时间的角度分析登录行为中存在的空间相似性和时间同步性,并设计了相应的方法来检测异常的登录行为,最终输出按照失陷可能性排序的邮箱列表,为安全研究人员在实地调查、取证时提供优先级参考。为验证方法有效性,在5个不同规模和起止日期的登录日志数据集上进行实验。结果表明,所提出的方法能够成功检测出失陷邮箱,检测效果好于同类检测系统DAS,并且具备发现未知恶意子网和攻击者的能力。
